2023 MathorCup College Mathematical Modeling Challenge – Big-Data-Wettbewerb
Track B Halbfinale: Nachfrageprognose für E-Commerce-Einzelhändler und Problem der Bestandsoptimierung
Frage 1
Ziel: Entwickeln Sie einen Nachschubplan basierend auf prognostizierten Verkäufen.
Hintergrund: Bestandszählungszyklus NRT=1, Durchlaufzeit LT=3 Tage korrigiert.
Anfangsbedingungen: Der Eröffnungsbestand aller Waren beträgt 5, und die Haltekosten und Knappheitskosten stehen im positiven Zusammenhang mit dem Warenpreis.
Strategie: Regelmäßige Bestandszählungsstrategie (s, S).
Datenverarbeitung: Notwendigkeit, historische und prognostizierte Nachfrage zu kombinieren.
Aufgabe: Bereitstellung des Nachschubplans vom 16.05.2023 bis zum 30.05.2023 (tägliche s- und S-Werte).
Zielindikatoren: Kosten senken, Servicelevel verbessern und Lagerumschlagstage reduzieren.
Frage 2
Ziel: Verfassen Sie einen zusammenfassenden Bericht über Nachfrageprognosen und Bestandsoptimierungsprobleme für E-Commerce-Einzelhändler.
Inhaltliche Anforderungen: Der Bericht muss die Vor- und Nachteile der Teamlösung klären.
Anhangsbeschreibung
Ergebnistabelle 4: Ergebnistabelle zur Bestandsauffüllung, einschließlich Händlercode, Produktcode, Lagercode, Datum, Bestandsentscheidungsvariablen (s und S) , Felder wie der Anfangsbestand des aktuellen Tages, der Endbestand des Tages, der prognostizierte Bedarf und die Nachschubmenge.
Zusammenfassung von Problem 1 Die Methoden, von denen das Team glaubt, dass sie übernommen werden können, sind: Lösung von Planungsproblemen basierend auf simuliertem Tempern; Lösung von Planungsproblemen basierend auf genetischen Algorithmen; Verwendung der Bestandsverwaltungstheorie, wie z. B. der Economic Order Quantity (EOQ). Modell; Vorhersagemodelle basierend auf maschinellem Lernen; Vorhersagemodell basierend auf modifiziertem maschinellem Lernen
Das Team wählt mindestens drei Methoden aus, um das Problem separat zu lösen.
mbd.pub/o/bread/mbd-ZZeckpxs
Excel-Datei mit Produktpreisdaten:
Diese Datentabelle enthält die Produktnummer (product_no) und den entsprechenden Preis (price).
Die Vorhersageergebnistabelle enthält die folgenden Informationen:
Händlernummer (Verkäufernummer)
Produktnummer (Produktnummer)
Lagernummer (warehouse_no)
Datumsbereich (Datum), der hier angezeigte Datumsbereich reicht vom 16.05.2023 bis zum 30.05.2023
Nachfrage prognostizieren (forecast_qty)
Originaldaten visualisieren:
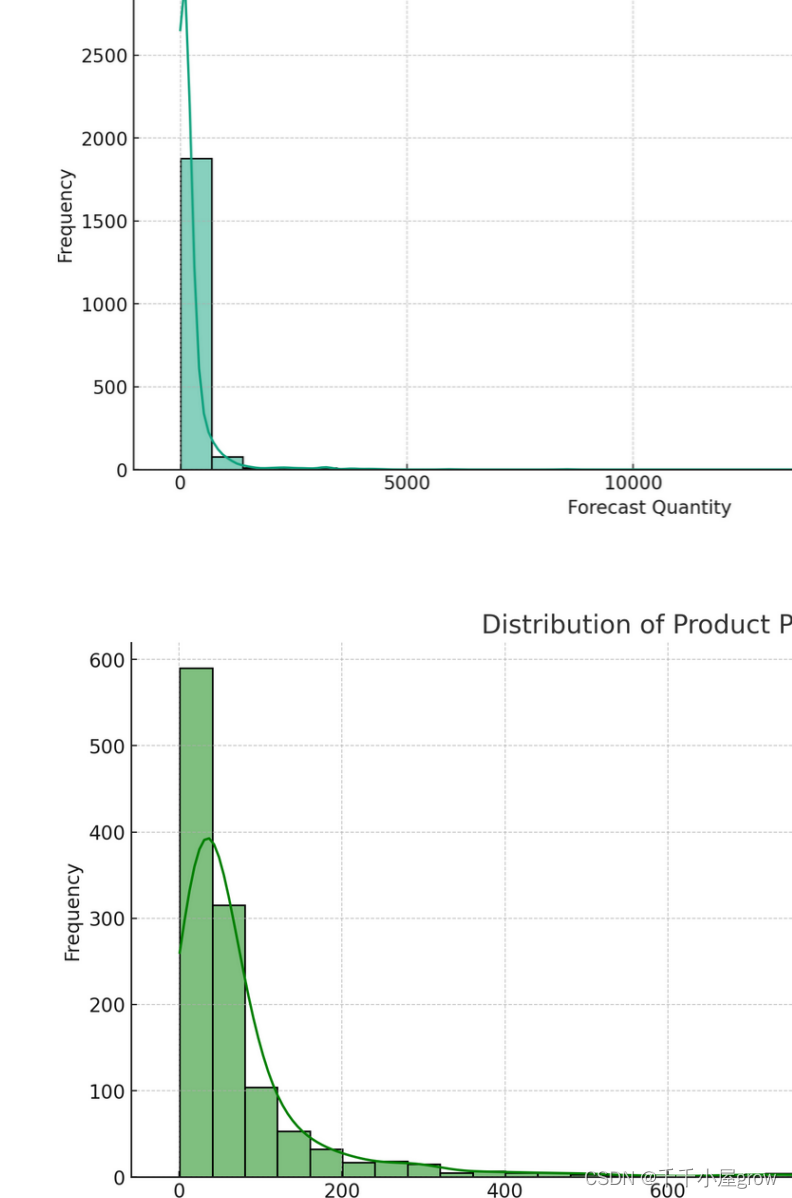
Verteilung der prognostizierten Nachfrage: Dieses Diagramm zeigt die Verteilung der prognostizierten Nachfrage. Sie können das Verbreitungsgebiet und die zentrale Nachfragetendenz erkennen.
Verteilung der Rohstoffpreise: Dieses Diagramm zeigt die Verteilung der Rohstoffpreise. Anhand dieses Diagramms können wir die Schwankungen und zentralen Trends der Rohstoffpreise verstehen.
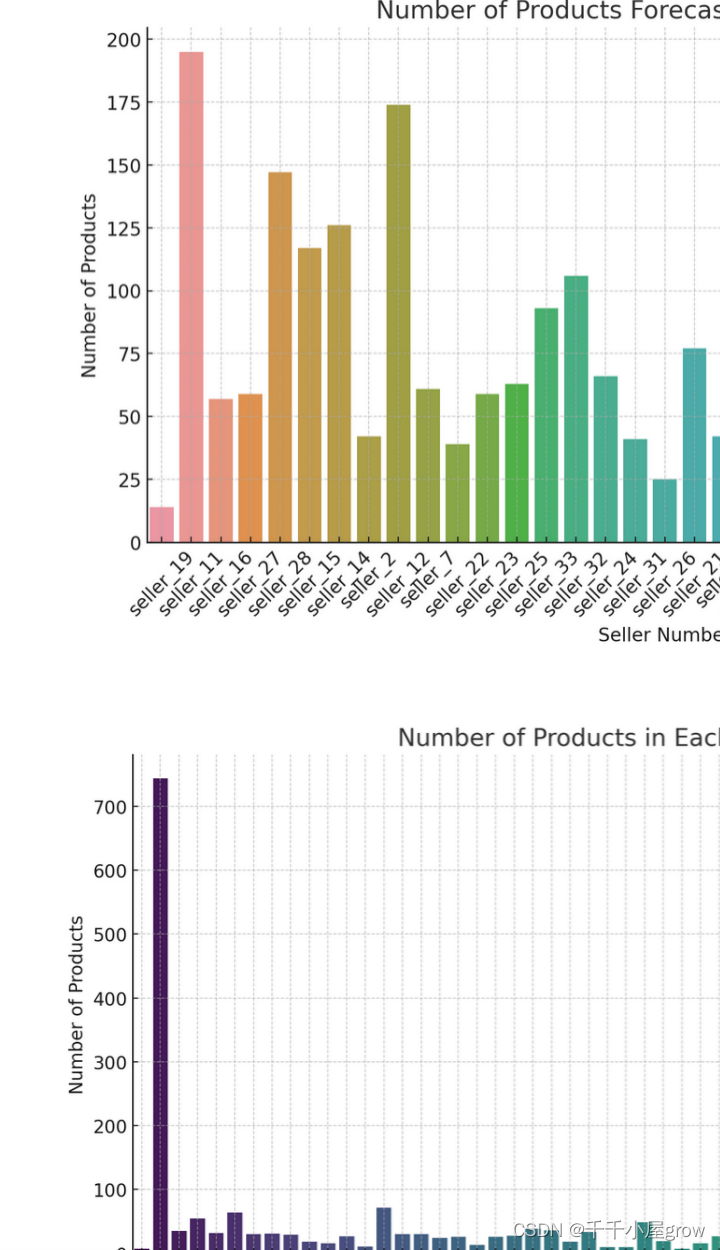
Prognostizierte Produktmengen pro Händler: Dieses Diagramm zeigt die prognostizierten Produktmengen für jeden Händler. Dies hilft zu verstehen, welche Händler eine größere Anzahl an Produkten haben und möglicherweise mehr Aufmerksamkeit benötigen.
Anzahl der Produkte pro Lager: Dieses Diagramm zeigt die Anzahl der Produkte in jedem Lager. Dies hilft bei der Analyse der Bestandsverteilung über verschiedene Lager.
Die häufigsten Produktpreise (Top 10): Dieses Diagramm zeigt die häufigsten Produktpreise und ihre Häufigkeit. Dies kann uns helfen, die Schlüsselbereiche der Preisverteilung zu verstehen.
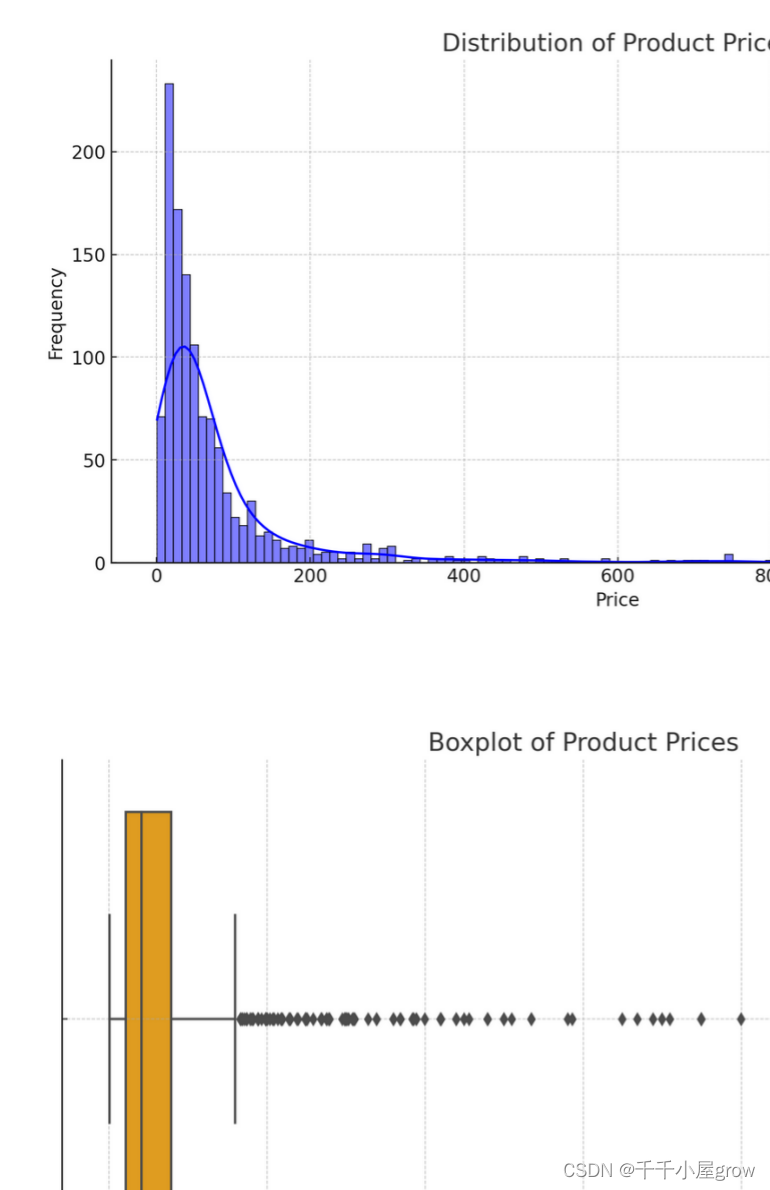
Preisverteilungsdiagramm: Dieses Histogramm zeigt die Verteilung der Rohstoffpreise und enthält eine KDE-Kurve (Kernel Density Estimate), die dabei helfen kann, den allgemeinen Verteilungstrend der Preise zu verstehen.
Preis-Boxplot: Dieser Boxplot bietet eine fünfstellige Zusammenfassung der Rohstoffpreise (Minimum, erstes Quartil, Median, drittes Quartil, Maximum) und mögliche Ausreißer.
Preisdichtediagramm: Dieses Dichtediagramm zeigt die Wahrscheinlichkeitsdichteverteilung von Preisen und kann dabei helfen, die Form der Preisverteilung detaillierter zu verstehen.
Schritte zum Erstellen eines Nachschubmodells
- Datenintegration
Kombinieren Sie Rohstoffpreisdaten mit prognostizierten Nachfragedaten, um Kosten bei Nachschubentscheidungen zu berücksichtigen. - Bestimmen Sie die Wiederauffüllungsstrategie
Wir werden die periodische Bestandszählungsstrategie (s, S) verwenden.
Bestimmen Sie die s- und S-Werte jeder Ware basierend auf der vorhergesagten Nachfrage und dem Preis der Ware. - Bestandskosten berücksichtigen
Berücksichtigen Sie Lagerkosten (basierend auf Artikelpreisen und Lagerbeständen) und Fehlbestände (wenn die Nachfrage nicht gedeckt werden kann).
Ziel ist es, Kosten und Serviceniveau in Einklang zu bringen. - Modellimplementierung
Verwenden Sie Python, um dieses Modell zu implementieren.
Erwägen Sie die Verwendung der Bestandsverwaltungstheorie, wie etwa des Economic Order Quantity (EOQ)-Modells
Oder eines Prognosemodells, das auf maschinellem Lernen basiert.
Oder erstellen Sie Planungsgleichungen - Modelltests und -optimierung
Testen Sie die Leistung des Modells unter verschiedenen Parametern.
Optimieren Sie basierend auf Kosten, Lagerbeständen und Serviceniveaus. - Ergebnisausgabe
Ausgabe des Nachschubplans vom 16.05.2023 bis zum 30.05.2023
kombiniert prognostizierte Nachfragedaten und Rohstoffpreise, um den Nachschubpunkt (S-Wert) und den Zielbestand (S-Wert) für jeden Rohstoff zu berechnen. Hier basiert die Berechnung von s und S auf einfachen Annahmen
und muss die Haltekosten und die Kosten für nicht vorrätige Lagerbestände berücksichtigen, die auf der Grundlage des Warenpreises und des Warenpreises berechnet werden Verhältnis einstellen.
Nächster Schritt
Parameteranpassung: Passen Sie die Berechnungsmethoden von s und S entsprechend den spezifischen Anforderungen und Kostenüberlegungen an.
Modellvalidierung: Testen des Modells, um seine Genauigkeit und Gültigkeit sicherzustellen.
Optimierungsstrategie: Möglicherweise muss die Strategie weiter optimiert werden, um sie besser an die tatsächliche Situation anzupassen.
#Vorläufiger Code
Pandas als pd importieren
Numpy als np importieren
Dateipfade
forecast_results_file_path = „Ergebnistabelle 1 – Prognoseergebnistabelle.xlsx“
product_price_file_path = „Rohstoffpreisdaten.xlsx“
Laden Sie die Prognoseergebnisdaten
Forecast_results_data = pd.read_excel(forecast_results_file_path)
Laden Sie die Produktpreisdaten
product_price_data = pd.read_excel(product_price_file_path)
Konstanten und Annahmen
initial_inventory = 5 # Anfänglicher Lagerbestand für alle Produkte
Lead_time = 3 # Durchlaufzeit in Tagen
review_period = 1 # Überprüfungszeitraum in Tagen< /span> shortage_cost_rate = 0,02 # Mangelkostensatz (Prozentsatz des Produktpreises)
holding_cost_rate = 0,01 # Lagerkostensatz (Prozentsatz des Produktpreises)
Prognosedaten mit Preisdaten zusammenführen
merged_data = Forecast_results_data.merge(product_price_data, on=‘product_no’, how=‘left’)
Funktion zur Berechnung von s- und S-Werten für jedes Produkt
def berechne_replenish_points(row):
Forecast_demand = row['forecast_qty']
price = row['price']< a i=3>holding_cost_per_unit = preis * holding_cost_rate shortage_cost_per_unit = preis * shortage_cost_rate return s, S
Wenden Sie die Funktion auf jede Zeile im Datenrahmen an
merged_data[[‘s’, ‘S’]] = merged_data.apply(lambda row: berechne_replenish_points(row), axis=1, result_type=“expand“)
Zeigen Sie den aktualisierten Datenrahmen an
merged_data.head()
Vorläufige Vorhersageergebnisse zur Visualisierung
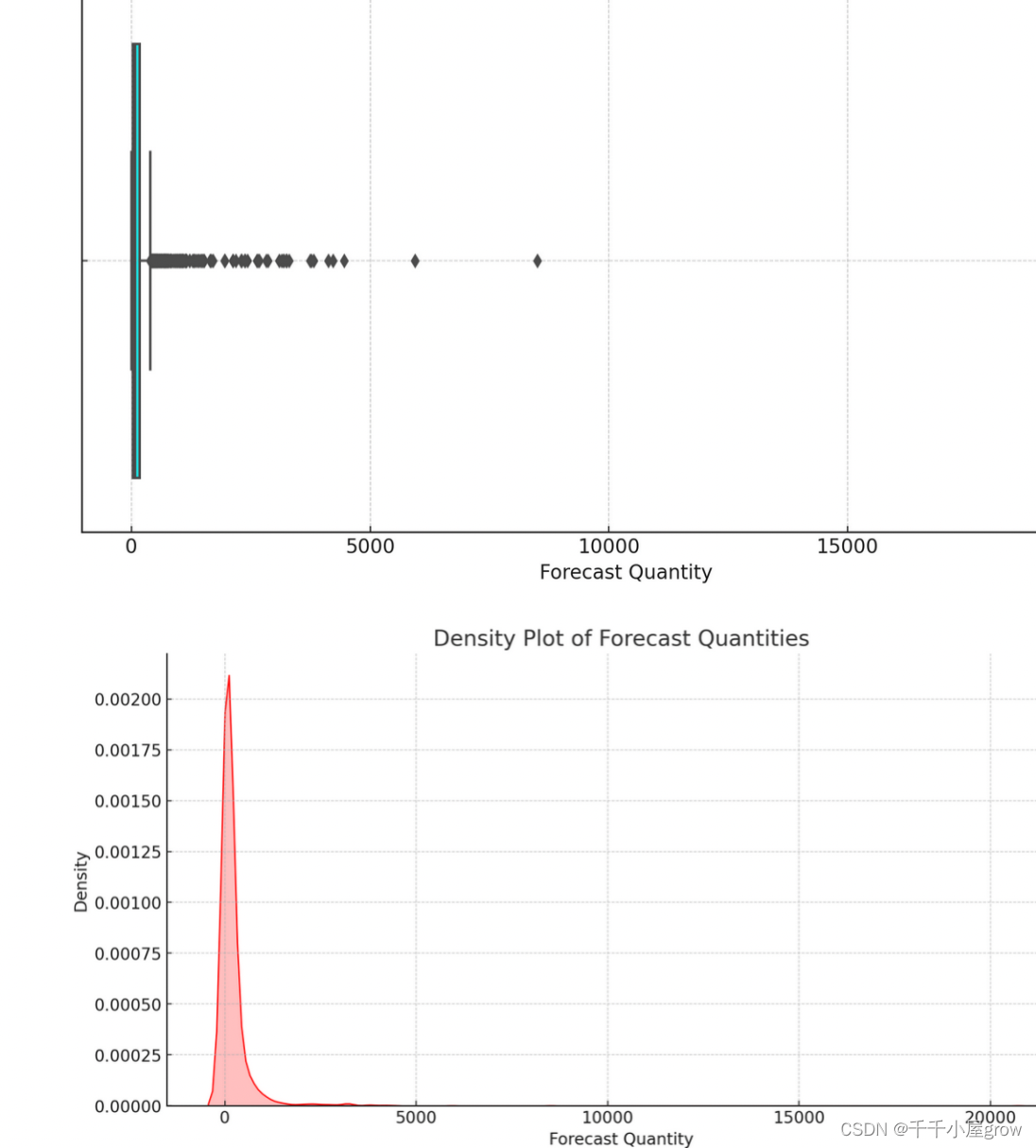
Verteilungsdiagramm der prognostizierten Menge: Dieses Histogramm zeigt die Verteilung der prognostizierten Menge und enthält eine KDE-Kurve (Kernel Density Estimate), um den Gesamtverteilungstrend der prognostizierten Menge besser zu verstehen.
Boxplot der vorhergesagten Mengen: Dieses Boxplot bietet eine fünfstellige Zusammenfassung der vorhergesagten Mengen (Minimum, erstes Quartil, Median, drittes Quartil, Maximalwerte) und mögliche Ausreißer.
Diagramm der prognostizierten Mengendichte: Dieses Dichtediagramm zeigt die Wahrscheinlichkeitsdichteverteilung der prognostizierten Mengen und bietet einen detaillierteren Einblick in die Form der prognostizierten Mengenverteilung.