
Cómo aprovechar al máximo las capacidades de SQL es el tema de este artículo. Este artículo intenta encontrar un enfoque único, enfatizando que a través del pensamiento de procesamiento de datos flexible y divergente, se pueden resolver escenarios de datos complejos utilizando la sintaxis más básica.
I. Introducción
1.1 Intención original
Cómo utilizar MaxCompute (ODPS) SQL de manera eficiente y aplicar la sintaxis básica de SQL al extremo.
Hoy en día, cuando Big Data es tan popular, no sólo el personal profesional de datos necesita tratar con SQL con frecuencia, sino que incluso los estudiantes no técnicos, como los de productos y operaciones, utilizarán SQL en mayor o menor medida. ?, y entonces se vuelve particularmente importante aprovechar el poder de los datos.
MaxCompute (ODPS) SQL se ha desarrollado con bastante madurez hoy en día. Como dialecto SQL, su sintaxis SQL es totalmente compatible y tiene un conjunto muy rico de funciones integradas. Admite funciones de ventanas, funciones definidas por el usuario, tipos definidos por el usuario y muchos otras funciones avanzadas, que se pueden aplicar de manera eficiente en varios escenarios de procesamiento de datos.
Cómo aprovechar al máximo las capacidades de SQL es el tema de este artículo. Este artículo intenta encontrar un enfoque único, enfatizando que a través del pensamiento de procesamiento de datos flexible y divergente, se pueden resolver escenarios de datos complejos utilizando la sintaxis más básica.
1.2 Adecuado para la multitud
Ya sea principiante o experimentado, este artículo puede resultar útil, pero es más adecuado para lectores intermedios y avanzados.
Este artículo se centra en el pensamiento de procesamiento de datos y no involucra demasiada sintaxis de alto nivel. Al mismo tiempo, para evitar divergencias en el tema, las funciones y características gramaticales involucradas en el artículo no se presentarán en detalle. sus propias decisiones basadas en sus propias circunstancias.
1.3 Estructura del contenido
Este artículo presentará temas como la generación de secuencias, la transformación de intervalos, la permutación y combinación y la discriminación continua, y adjuntará casos para explicar aplicaciones prácticas. Existe una ligera dependencia entre cada tema, por lo que es mejor leerlos en secuencia.
1.4 Información inmediata
Las declaraciones SQL involucradas en este artículo solo utilizan las características de sintaxis básica de MaxCompute (ODPS) SQL. En teoría, todo SQL se puede ejecutar en la última versión. Al mismo tiempo, se señala especialmente que problemas como el entorno operativo y la compatibilidad No están dentro del alcance de este artículo.
2. secuencia numérica
Las secuencias son una de las formas de datos más comunes y las que se encuentran en escenarios reales de desarrollo de datos son básicamente secuencias finitas. Esta sección comenzará con la secuencia creciente más simple, descubrirá el método general y lo extenderá a escenarios más generales.
2.1 Secuencia común
2.1.1 Una secuencia creciente simple
Primero, se presenta un escenario de secuencia entera creciente simple:
- A partir del valor 0;
- Cada valor posterior aumenta en 1;
- Fin del valor 3;
¿Cómo generar una secuencia que satisfaga las tres condiciones anteriores? Eso es [0,1,2,3].
De hecho, hay muchas formas de generar esta secuencia y aquí hay una solución simple y general.
-- SQL - 1
select
t.pos as a_n
from (
select posexplode(split(space(3), space(1), false))
) t;
Del fragmento de SQL anterior, podemos saber que generar una secuencia creciente solo requiere tres pasos:
1) Genere una matriz de longitud adecuada y no es necesario que los elementos de la matriz tengan un significado real;
2) Utilice la función UDTF poseexplode para generar un subíndice de índice para cada elemento de la matriz;
3) Obtenga el subíndice índice de cada elemento. Los tres pasos anteriores se pueden extender a escenarios de secuencia más generales: secuencia aritmética y secuencia geométrica. A continuación se proporcionará directamente la plantilla de implementación final basada en esto.
2.1.2 Progresión aritmética

Implementación de SQL:
-- SQL - 2
select
a + t.pos * d as a_n
from (
select posexplode(split(space(n - 1), space(1), false))
) t;2.1.3 Secuencia geométrica

Implementación de SQL:
-- SQL - 3
select
a * pow(q, t.pos) as a_n
from (
select posexplode(split(space(n - 1), space(1), false))
) t;Consejo: También puede utilizar directamente la secuencia de funciones del sistema MaxCompute (ODPS) para generar rápidamente una secuencia.
-- SQL - 4
select sequence(1, 3, 1);
-- result
[1, 2, 3]2.2 Ejemplos de escenarios de aplicación
2.2.1 Restaurar nombres de familias de columnas de dimensiones en cualquier combinación de dimensiones
En escenarios de análisis multidimensional, se pueden utilizar funciones de agregación de alto orden, como cubo , resumen , conjuntos de agrupación , etc., para realizar estadísticas de agregación sobre datos en diferentes combinaciones de dimensiones.
descripción de la escena
Existe una tabla de registro de acceso de usuarios visit_log. Cada fila de datos representa un registro de acceso de usuarios.
-- SQL - 5
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武汉', 'Android',
'2024-01-01', '102', '湖南', '长沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵阳', 'Android',
'2024-01-03', '101', '湖北', '武汉', 'IOS'
)
-- 字段:日期,用户,省份,城市,设备类型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;Ahora, para las columnas de tres dimensiones de provincia, ciudad y tipo de dispositivo tipo_dispositivo, las visitas del usuario en diferentes combinaciones de dimensiones se obtienen mediante estadísticas de agregación de conjuntos de agrupaciones . Pregunta: 1) ¿Cómo saber de qué columnas de dimensión se agrega un resultado estadístico?
2) Si desea generar el nombre de la columna de dimensión agregada para la visualización del informe posterior y otros escenarios, ¿cómo debe manejarlo?
Soluciones
Se puede resolver con la ayuda de GROUPING__ID proporcionado por MaxCompute (ODPS), y el método principal es implementar GROUPING__ID a la inversa.
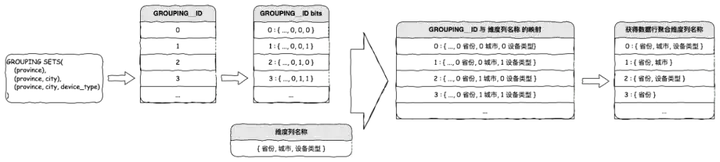
1. Prepare todos los GROUPING__ID.

| GRUPO__ID | bits |
| 0 | {..., 0, 0, 0} |
| 1 | {..., 0, 0, 1} |
| 2 | {..., 0, 1, 0} |
| 3 | {..., 0, 1, 1} |
| ... | ... |
| 2n2n | ... |

2. Prepare todos los nombres de las dimensiones.

{ dim_name_1, dim_name_2, ..., dim_name_n }3. Asigne GROUPING__ID al nombre de la columna de dimensión.
Para cada valor en la matriz incremental GROUPING__ID, asigne cada bit binario del valor al subíndice de la secuencia de nombres de dimensiones y genere todos los nombres de dimensiones con los bits 0 correspondientes. Por ejemplo:
GROUPING__ID:3 => { 0, 1, 1 }
维度名称序列:{ 省份, 城市, 设备类型 }
映射:{ 0:省份, 1:城市, 1:设备类型 }
GROUPING__ID 为 3 的数据行聚合维度即为:省份implementación de SQL
-- SQL - 6
with group_dimension as (
select -- 每种分组对应的维度字段
gb.group_id, concat_ws(",", collect_list(case when gb.placeholder_bit = 0 then dim_col.val else null end)) as dimension_name
from (
select groups.pos as group_id, pe.*
from (
select posexplode(split(space(cast(pow(2, 3) as int) - 1), space(1), false))
) groups -- 所有分组
lateral view posexplode(regexp_extract_all(lpad(conv(groups.pos,10,2), 3, "0"), '(0|1)')) pe as placeholder_idx, placeholder_bit -- 每个分组的bit信息
) gb
left join ( -- 所有维度字段
select posexplode(split("省份,城市,设备类型", ','))
) dim_col on gb.placeholder_idx = dim_col.pos
group by gb.group_id
)
select
group_dimension.dimension_name,
province, city, device_type,
visit_count
from (
select
grouping_id(province, city, device_type) as group_id,
province, city, device_type,
count(1) as visit_count
from visit_log b
group by province, city, device_type
GROUPING SETS(
(province),
(province, city),
(province, city, device_type)
)
) t
join group_dimension on t.group_id = group_dimension.group_id
order by group_dimension.dimension_name;| nombre_dimensión | provincia | ciudad | tipo de dispositivo | recuento_visitas |
| provincia | Hubei | NULO | NULO | 3 |
| provincia | hunan | NULO | NULO | 2 |
| provincia | Sichuan | NULO | NULO | 1 |
| ciudad provincial | Hubei | Wuhan | NULO | 2 |
| ciudad provincial | hunan | Changshá | NULO | 1 |
| ciudad provincial | hunan | shaoyang | NULO | 1 |
| ciudad provincial | Hubei | Xiaogan | NULO | 1 |
| ciudad provincial | Sichuan | Chengdú | NULO | 1 |
| Provincia, ciudad, tipo de equipo. | Hubei | Xiaogan | Mac | 1 |
| Provincia, ciudad, tipo de equipo. | hunan | Changshá | IOS | 1 |
| Provincia, ciudad, tipo de equipo. | hunan | shaoyang | Androide | 1 |
| Provincia, ciudad, tipo de equipo. | Sichuan | Chengdú | ventanas | 1 |
| Provincia, ciudad, tipo de equipo. | Hubei | Wuhan | Androide | 1 |
| Provincia, ciudad, tipo de equipo. | Hubei | Wuhan | IOS | 1 |
3. Intervalo
Los intervalos tienen características de datos diferentes en comparación con la secuencia, pero en aplicaciones prácticas, el procesamiento de secuencia e intervalo tiene muchas similitudes. Esta sección presentará algunos escenarios de intervalos comunes y soluciones comunes abstractas.
3.1 Operaciones de intervalo comunes
3.1.1 Segmentación de intervalos

Implementación de SQL:
-- SQL - 7
select
a + t.pos * d as sub_interval_start, -- 子区间起始值
a + (t.pos + 1) * d as sub_interval_end -- 子区间结束值
from (
select posexplode(split(space(n - 1), space(1), false))
) t;3.1.2 Cruce de intervalos
Se sabe que los dos intervalos de fechas se cruzan ['2024-01-01', '2024-01-03'] y ['2024-01-02', '2024-01-04']. preguntar:
1) ¿Cómo fusionar dos rangos de fechas y devolver el nuevo rango combinado?
2) ¿Cómo saber qué fechas son fechas de cruce y devolver el número de cruces para esa fecha?
Hay muchas maneras de resolver el problema anterior, aquí hay una solución simple y general. La idea central es combinar los métodos de generación de secuencia y segmentación de intervalos para descomponer primero el intervalo de fechas en la unidad de procesamiento más pequeña, es decir, una secuencia compuesta de múltiples fechas, y luego hacer estadísticas basadas en la granularidad de las fechas. Los pasos específicos son los siguientes:
1) Obtener el número de días incluidos en cada intervalo de fechas; 2) Dividir el intervalo de fechas en un número correspondiente de secuencias de fechas crecientes en función del número de días incluidos en el intervalo de fechas;
3) Cuente los intervalos fusionados y el número de cruces a través de series de fechas.
Implementación de SQL:
-- SQL - 8
with dummy_table as (
select stack(
2,
'2024-01-01', '2024-01-03',
'2024-01-02', '2024-01-04'
) as (date_start, date_end)
)
select
min(date_item) as date_start_merged,
max(date_item) as date_end_merged,
collect_set( -- 交叉日期计数
case when date_item_cnt > 1 then concat(date_item, ':', date_item_cnt) else null end
) as overlap_date
from (
select
-- 拆解后的单个日期
date_add(date_start, pos) as date_item,
-- 拆解后的单个日期出现的次数
count(1) over (partition by date_add(date_start, pos)) as date_item_cnt
from dummy_table
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t;| fecha_inicio_merged | fecha_end_merged | fecha_superposición |
| 2024-01-01 | 2024-01-04 | ["2024-01-02:2","2024-01-03:2"] |
¡Hazlo un poco más difícil!
Cómo resolver el problema anterior si hay varios intervalos de fechas y se desconoce el estado de intersección entre los intervalos. Ahora mismo:
1) ¿Cómo fusionar varios rangos de fechas y devolver varios rangos combinados nuevos?
2) ¿Cómo saber qué fechas son fechas de cruce y devolver el número de cruces para esa fecha?
Implementación de SQL:
-- SQL - 9
with dummy_table as (
select stack(
5,
'2024-01-01', '2024-01-03',
'2024-01-02', '2024-01-04',
'2024-01-06', '2024-01-08',
'2024-01-08', '2024-01-08',
'2024-01-07', '2024-01-10'
) as (date_start, date_end)
)
select
min(date_item) as date_start_merged,
max(date_item) as date_end_merged,
collect_set( -- 交叉日期计数
case when date_item_cnt > 1 then concat(date_item, ':', date_item_cnt) else null end
) as overlap_date
from (
select
-- 拆解后的单个日期
date_add(date_start, pos) as date_item,
-- 拆解后的单个日期出现的次数
count(1) over (partition by date_add(date_start, pos)) as date_item_cnt,
-- 对于拆解后的单个日期,重组为新区间的标记
date_add(date_add(date_start, pos), 1 - dense_rank() over (order by date_add(date_start, pos))) as cont
from dummy_table
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t
group by cont;| fecha_inicio_merged | fecha_end_merged | fecha_superposición |
| 2024-01-01 | 2024-01-04 | ["2024-01-02:2","2024-01-03:2"] |
| 2024-01-06 | 2024-01-10 | ["2024-01-07:2","2024-01-08:3"] |
3.2 Ejemplos de escenarios de aplicación
3.2.1 Estadísticas basadas en cualquier período de tiempo
descripción de la escena
Existe una tabla de plan de pago de usuario usuario_repago. Un dato en esta tabla indica que el usuario reembolsará el yuan de pago todos los días dentro del intervalo de fechas especificado [fecha_inicio, fecha_final].
-- SQL - 10
with user_repayment as (
select stack(
3,
'101', '2024-01-01', '2024-01-15', 10,
'102', '2024-01-05', '2024-01-20', 20,
'103', '2024-01-10', '2024-01-25', 30
)
-- 字段:用户,开始日期,结束日期,每日还款金额
as (user_id, date_start, date_end, repayment)
)
select * from user_repayment;¿Cómo contar el pago total adeudado por todos los usuarios todos los días durante cualquier período de tiempo (por ejemplo: 2024-01-15 al 2024-01-16)?
Soluciones
La idea central es convertir el intervalo de fechas en una secuencia de fechas y luego realizar estadísticas resumidas basadas en la secuencia de fechas.
implementación de SQL
-- SQL - 11
select
date_item as day,
sum(repayment) as total_repayment
from (
select
date_add(date_start, pos) as date_item,
repayment
from user_repayment
lateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val
) t
where date_item >= '2024-01-15' and date_item <= '2024-01-16'
group by date_item
order by date_item;| día | pago_total |
| 2024-01-15 | 60 |
| 2024-01-16 | 50 |
4. Disposición y combinación.
La permutación y combinación son métodos de organización de datos comúnmente utilizados para datos discretos. Esta sección presentará los métodos de implementación de permutación y combinación respectivamente, y se centrará en el procesamiento de datos mediante combinación con ejemplos.
4.1 Operaciones comunes de permutación y combinación
4.1.1 Disposición
Dada la secuencia de caracteres ['A', 'B', 'C'], se pueden seleccionar 2 caracteres repetidamente de esta secuencia cada vez. ¿Cómo obtener todas las permutaciones?
Se puede resolver con la ayuda de múltiples vistas laterales y la implementación general es relativamente simple.
-- SQL - 12
select
concat(val1, val2) as perm
from (select split('A,B,C', ',') as characters) dummy
lateral view explode(characters) t1 as val1
lateral view explode(characters) t2 as val2;| permanente |
| Automóvil club británico |
| AB |
| C.A. |
| licenciado en Letras |
| CAMA Y DESAYUNO |
| antes de Cristo |
| California |
| CB |
| CC |
4.1.2 Combinación
Dada la secuencia de caracteres ['A', 'B', 'C'], se pueden seleccionar 2 caracteres repetidamente de esta secuencia cada vez. ¿Cómo obtener todas las combinaciones?
Se puede resolver con la ayuda de múltiples vistas laterales y la implementación general es relativamente simple.
-- SQL - 13
select
concat(least(val1, val2), greatest(val1, val2)) as comb
from (select split('A,B,C', ',') as characters) dummy
lateral view explode(characters) t1 as val1
lateral view explode(characters) t2 as val2
group by least(val1, val2), greatest(val1, val2);| peine |
| Automóvil club británico |
| AB |
| C.A. |
| CAMA Y DESAYUNO |
| antes de Cristo |
| CC |
Consejo: También puede utilizar directamente las combinaciones de funciones del sistema MaxCompute (ODPS) para generar combinaciones rápidamente.
-- SQL - 14
select combinations(array('foo', 'bar', 'boo'),2);
-- result
[['foo', 'bar'], ['foo', 'boo']['bar', 'boo']]4.2 Ejemplos de escenarios de aplicación
4.2.1 Estadísticas de comparación de grupos
descripción de la escena
Tabla de conversión de estrategias de entrega existente. Un dato en esta tabla representa el volumen de pedidos generado por una determinada estrategia de entrega en un día.
-- SQL - 15
with strategy_order as (
select stack(
3,
'2024-01-01', 'Strategy A', 10,
'2024-01-01', 'Strategy B', 20,
'2024-01-01', 'Strategy C', 30
)
-- 字段:日期,投放策略,单量
as (dt, strategy, order_cnt)
)
select * from strategy_order;¿Cómo crear grupos de comparación por pares según las estrategias de entrega y comparar y mostrar el estado de conversión único de diferentes estrategias mediante comparación de grupos?
| grupo de comparación | estrategia de entrega | Convertir una cantidad única |
| Estrategia A-Estrategia B | Estrategia A | xxx |
| Estrategia A-Estrategia B | Estrategia B | xxx |
Soluciones
La idea central es extraer dos estrategias sin duplicación de la lista de todas las estrategias de entrega, generar todos los resultados combinados y luego asociar la tabla estrategia_orden que agrupa los resultados estadísticos.
implementación de SQL
-- SQL - 16
select /*+ mapjoin(combs) */
combs.strategy_comb,
so.strategy,
so.order_cnt
from strategy_order so
join ( -- 生成所有对比组
select
concat(least(val1, val2), '-', greatest(val1, val2)) as strategy_comb,
least(val1, val2) as strategy_1, greatest(val1, val2) as strategy_2
from (
select collect_set(strategy) as strategies
from strategy_order
) dummy
lateral view explode(strategies) t1 as val1
lateral view explode(strategies) t2 as val2
where val1 <> val2
group by least(val1, val2), greatest(val1, val2)
) combs on 1 = 1
where so.strategy in (combs.strategy_1, combs.strategy_2)
order by combs.strategy_comb, so.strategy;| grupo de comparación | estrategia de entrega | Convertir una cantidad única |
| Estrategia A-Estrategia B | Estrategia A | 10 |
| Estrategia A-Estrategia B | Estrategia B | 20 |
| Estrategia A-Estrategia C | Estrategia A | 10 |
| Estrategia A-Estrategia C | Estrategia C | 30 |
| Estrategia B-Estrategia C | Estrategia B | 20 |
| Estrategia B-Estrategia C | Estrategia C | 30 |
5. Continuo
Esta sección presenta principalmente problemas de continuidad y se centra en describir escenarios activos continuos comunes. Para la actividad continua de tipos estáticos y la actividad continua de tipos dinámicos, se explican respectivamente diferentes soluciones de implementación.
5.1 Estadísticas generales de actividad continua
descripción de la escena
Existe una tabla de registro de acceso de usuarios visit_log. Cada fila de datos representa un registro de acceso de usuarios.
-- SQL - 17
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武汉', 'Android',
'2024-01-01', '102', '湖南', '长沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵阳', 'Android',
'2024-01-03', '101', '湖北', '武汉', 'IOS'
)
-- 字段:日期,用户,省份,城市,设备类型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;¿Cómo obtener usuarios cuyas visitas consecutivas sean mayores o iguales a 2 días?
Al analizar la continuidad para los problemas anteriores, el resultado de obtener continuidad estará sujeto a exceder un umbral fijo , que se clasifica aquí como estadísticas de escena activa continua ordinaria donde la actividad continua es mayor que el umbral de N días .
implementación de SQL
Implementado en base a diferencias de fechas adyacentes (versión retrasada/adelante)
La implementación general es relativamente simple.
-- SQL - 18
select user_id
from (
select
*,
lag(dt, 2 - 1) over (partition by user_id order by dt) as lag_dt
from (select dt, user_id from visit_log group by dt, user_id) t0
) t1
where datediff(dt, lag_dt) + 1 = 2
group by user_id;| ID_usuario |
| 101 |
| 102 |
Implementación basada en diferencia de fechas adyacentes (versión ordenada)
La implementación general es relativamente simple.
-- SQL - 19
select user_id
from (
select *,
dense_rank() over (partition by user_id order by dt) as dr
from visit_log
) t1
where datediff(dt, date_add(dt, 1 - dr)) + 1 = 2
group by user_id;| ID_usuario |
| 101 |
| 102 |
Basado en el número de días activos consecutivos
Puede considerarse como una versión derivada de la implementación basada en diferencias de fechas adyacentes (versión ordenada) , que puede obtener más información, como el número de días activos consecutivos.
-- SQL - 20
select user_id
from (
select
*,
-- 连续活跃天数
count(distinct dt)
over (partition by user_id, cont) as cont_days
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
) t2
where cont_days >= 2
group by user_id;| ID_usuario |
| 101 |
| 102 |
Implementado en base a un intervalo activo continuo
Puede considerarse como una versión derivada de la implementación basada en diferencias de fechas adyacentes (versión ordenada) , que puede obtener más información, como intervalos activos continuos.
-- SQL - 21
select user_id
from (
select
user_id, cont,
-- 连续活跃区间
min(dt) as cont_date_start, max(dt) as cont_date_end
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
group by user_id, cont
) t2
where datediff(cont_date_end, cont_date_start) + 1 >= 2
group by user_id;| ID_usuario |
| 101 |
| 102 |
5.2 Estadísticas dinámicas de actividad continua
descripción de la escena
Existe una tabla de registro de acceso de usuarios visit_log. Cada fila de datos representa un registro de acceso de usuarios.
-- SQL - 22
with visit_log as (
select stack (
6,
'2024-01-01', '101', '湖北', '武汉', 'Android',
'2024-01-01', '102', '湖南', '长沙', 'IOS',
'2024-01-01', '103', '四川', '成都', 'Windows',
'2024-01-02', '101', '湖北', '孝感', 'Mac',
'2024-01-02', '102', '湖南', '邵阳', 'Android',
'2024-01-03', '101', '湖北', '武汉', 'IOS'
)
-- 字段:日期,用户,省份,城市,设备类型
as (dt, user_id, province, city, device_type)
)
select * from visit_log;¿Cómo obtener los dos usuarios activos continuamente más largos y generar los usuarios, los días activos continuos más largos y el rango de fechas activas continuas más largo?
Al analizar la continuidad de los problemas anteriores, el resultado de obtener continuidad no es ni puede compararse con un umbral fijo, sino que cada uno utiliza la actividad continua más larga como un umbral dinámico , que se clasifica aquí como estadísticas dinámicas de escena activa continua .
implementación de SQL
Se puede ampliar según la idea de estadísticas de escenas activas continuas ordinarias . El SQL final se proporciona directamente aquí:
-- SQL - 23
select
user_id,
-- 最长连续活跃天数
datediff(max(dt), min(dt)) + 1 as cont_days,
-- 最长连续活跃日期区间
min(dt) as cont_date_start, max(dt) as cont_date_end
from (
select
*,
date_add(dt, 1 - dense_rank()
over (partition by user_id order by dt)) as cont
from visit_log
) t1
group by user_id, cont
order by cont_days desc
limit 2;| ID_usuario | días_continuos | cont_fecha_inicio | cont_date_end |
| 101 | 3 | 2024-01-01 | 2024-01-03 |
| 102 | 2 | 2024-01-01 | 2024-01-02 |
6. Extensión
Conduce a escenarios más complejos, que son combinaciones y variaciones del contenido de los capítulos anteriores de este artículo.
6.1 Intervalos continuos (divididos por el subintervalo más largo)
descripción de la escena
Hay una tabla de registros user_wifi_log para los usuarios existentes que escanean o se conectan a WiFi. Cada fila de datos representa el registro de un usuario que escanea o se conecta a WiFi en un momento determinado.
-- SQL - 24
with user_wifi_log as (
select stack (
9,
'2024-01-01 10:01:00', '101', 'cmcc-Starbucks', 'scan', -- 扫描
'2024-01-01 10:02:00', '101', 'cmcc-Starbucks', 'scan',
'2024-01-01 10:03:00', '101', 'cmcc-Starbucks', 'scan',
'2024-01-01 10:04:00', '101', 'cmcc-Starbucks', 'conn', -- 连接
'2024-01-01 10:05:00', '101', 'cmcc-Starbucks', 'conn',
'2024-01-01 10:06:00', '101', 'cmcc-Starbucks', 'conn',
'2024-01-01 11:01:00', '101', 'cmcc-Starbucks', 'conn',
'2024-01-01 11:02:00', '101', 'cmcc-Starbucks', 'conn',
'2024-01-01 11:03:00', '101', 'cmcc-Starbucks', 'conn'
)
-- 字段:时间,用户,WiFi,状态(扫描、连接)
as (time, user_id, wifi, status)
)
select * from user_wifi_log;Ahora necesitamos analizar el comportamiento del usuario: ¿Cómo dividir los diferentes intervalos de comportamiento WiFi de los usuarios ? satisfacer:
1) Los tipos de comportamiento se dividen en dos tipos: conexión (escaneo) y escaneo (conexión);
2) La definición de intervalo de comportamiento es: el mismo tipo de comportamiento y la diferencia de tiempo entre dos comportamientos adyacentes no excede los 30 minutos;
3) Se deben tomar diferentes intervalos de comportamiento siempre que cumplan con la definición;
| ID_usuario | Wifi | estado | hora_inicio | tiempo_fin | Observación |
| 101 | cmcc-starbucks | escanear | 2024-01-01 10:01:00 | 2024-01-01 10:03:00 | WiFi escaneado por el usuario |
| 101 | cmcc-starbucks | conectar | 2024-01-01 10:04:00 | 2024-01-01 10:06:00 | Usuario conectado a WiFi |
| 101 | cmcc-starbucks | conectar | 2024-01-01 11:01:00 | 2024-01-01 11:02:00 | Si han pasado más de 30 minutos desde la última conexión, se considera un nuevo comportamiento de conexión. |
El problema anterior es un poco más complejo y puede verse como una variante de la racha activa más larga introducida en Estadísticas dinámicas de actividad continua . Puede describirse como un problema de dividir el subintervalo más largo combinando el umbral de continuidad y la información contextual en la secuencia de comportamiento .
implementación de SQL
Lógica central: usuarios grupales y WIFI, combinan umbrales de continuidad e información de contexto de secuencia de comportamiento para dividir intervalos de comportamiento.
pasos detallados:
1) Agrupe los datos por usuario y WIFI, y clasifique los datos en orden cronológico dentro de la ventana del grupo; 2) Atraviese dos registros adyacentes en la ventana del grupo en secuencia. Si la diferencia de tiempo entre los dos registros excede los 30 minutos, o el tiempo diferencia entre los dos registros Cuando el estado de comportamiento (estado de escaneo, estado de conexión) cambia, el intervalo de comportamiento se divide por el punto crítico. Hasta que se recorran todos los registros;
3) Resultado de salida final: usuario, WIFI, estado de comportamiento (estado de escaneo, estado de conexión), hora de inicio del comportamiento, hora de finalización del comportamiento;
-- SQL - 25
select
user_id,
wifi,
max(status) as status,
min(time) as start_time,
max(time) as end_time
from (
select *,
max(if(lag_status is null or lag_time is null or status <> lag_status or datediff(time, lag_time, 'ss') > 60 * 30, rn, null))
over (partition by user_id, wifi order by time) as group_idx
from (
select *,
row_number() over (partition by user_id, wifi order by time) as rn,
lag(time, 1) over (partition by user_id, wifi order by time) as lag_time,
lag(status, 1) over (partition by user_id, wifi order by time) as lag_status
from user_wifi_log
) t1
) t2
group by user_id, wifi, group_idx
;| ID_usuario | Wifi | estado | hora de inicio | hora de finalización |
| 101 | cmcc-starbucks | escanear | 2024-01-01 10:01:00 | 2024-01-01 10:03:00 |
| 101 | cmcc-starbucks | conectar | 2024-01-01 10:04:00 | 2024-01-01 10:06:00 |
| 101 | cmcc-starbucks | conectar | 2024-01-01 11:01:00 | 2024-01-01 11:03:00 |
Las condiciones de discriminación de continuidad en este caso se pueden extender a más escenarios, como escenarios de datos basados en diferencias de fechas, diferencias horarias, tipos de enumeración, diferencias de distancia, etc. como condiciones de discriminación de continuidad.
Conclusión
A través de un pensamiento de procesamiento de datos flexible y difuso, puede utilizar la sintaxis básica para resolver escenarios de datos complejos. Ésta es la idea a lo largo de este artículo. Este artículo proporciona soluciones relativamente generales para escenarios comunes como generación de secuencias, transformación de intervalos, permutación y combinación y discriminación continua, y explica aplicaciones prácticas con ejemplos.
Este artículo intenta encontrar un enfoque único y enfatiza el pensamiento de procesamiento de datos flexible. Espero que haga que los lectores se sientan más brillantes y realmente pueda ayudar a los lectores. Al mismo tiempo, después de todo, las capacidades personales son limitadas y las ideas pueden no ser necesariamente óptimas e incluso pueden producirse errores. Comentarios o sugerencias son bienvenidos.
Autor | Rigo
Haga clic para probar el producto en la nube de forma gratuita ahora y comenzar su viaje práctico en la nube.
Este artículo es contenido original de Alibaba Cloud y no puede reproducirse sin permiso.
阿里云严重故障,全线产品受影响(已恢复) 汤不热 (Tumblr) 凉了 俄罗斯操作系统 Aurora OS 5.0 全新 UI 亮相 Delphi 12 & C++ Builder 12、RAD Studio 12 发布 多家互联网公司急招鸿蒙程序员 UNIX 时间即将进入 17 亿纪元(已进入) 美团招兵买马,拟开发鸿蒙系统 App 亚马逊开发基于 Linux 的操作系统,以摆脱 Android 依赖 Linux 上的 .NET 8 独立体积减少 50% FFmpeg 6.1 "Heaviside" 发布