Dirección de código abierto:
- github: https://github.com/sagframe/sagacity-sqltoy
- casa rural: https://gitee.com/sagacity/sagacity-sqltoy
- Complemento de idea (se puede recuperar e instalar directamente en idea): https://github.com/tresfish/sqltoy-idea-plugins
- Proyecto de andamios sqltoy: https://gitee.com/momoljw/sss-rbac-admin
- proyecto lambda sqltoy: https://gitee.com/gzghde/sqltoy-plus
Actualizar contenido
1. Corregir los defectos bajo la estrategia de clave primaria de secuencia gaussdb.
2. Eliminar el procesamiento de conversión de ancho completo a medio ancho de algunos símbolos especiales en SQL en SqlUtil. El marco no realiza demasiado procesamiento implícito. 3. Optimización de la
paginación. agrega el parámetro skip-zero-count="true" (el valor predeterminado es falso), de modo que cuando el total de registros en el caché sea 0, pueda volver a consultar para obtener el recuento. Gracias @Yuchen por los comentarios
.
s qltoy-orm es una fusión de JPA y superquery
parte APP
- CRUD objetivado similar a JPA, carga en cascada de objetos, nuevas incorporaciones y actualizaciones
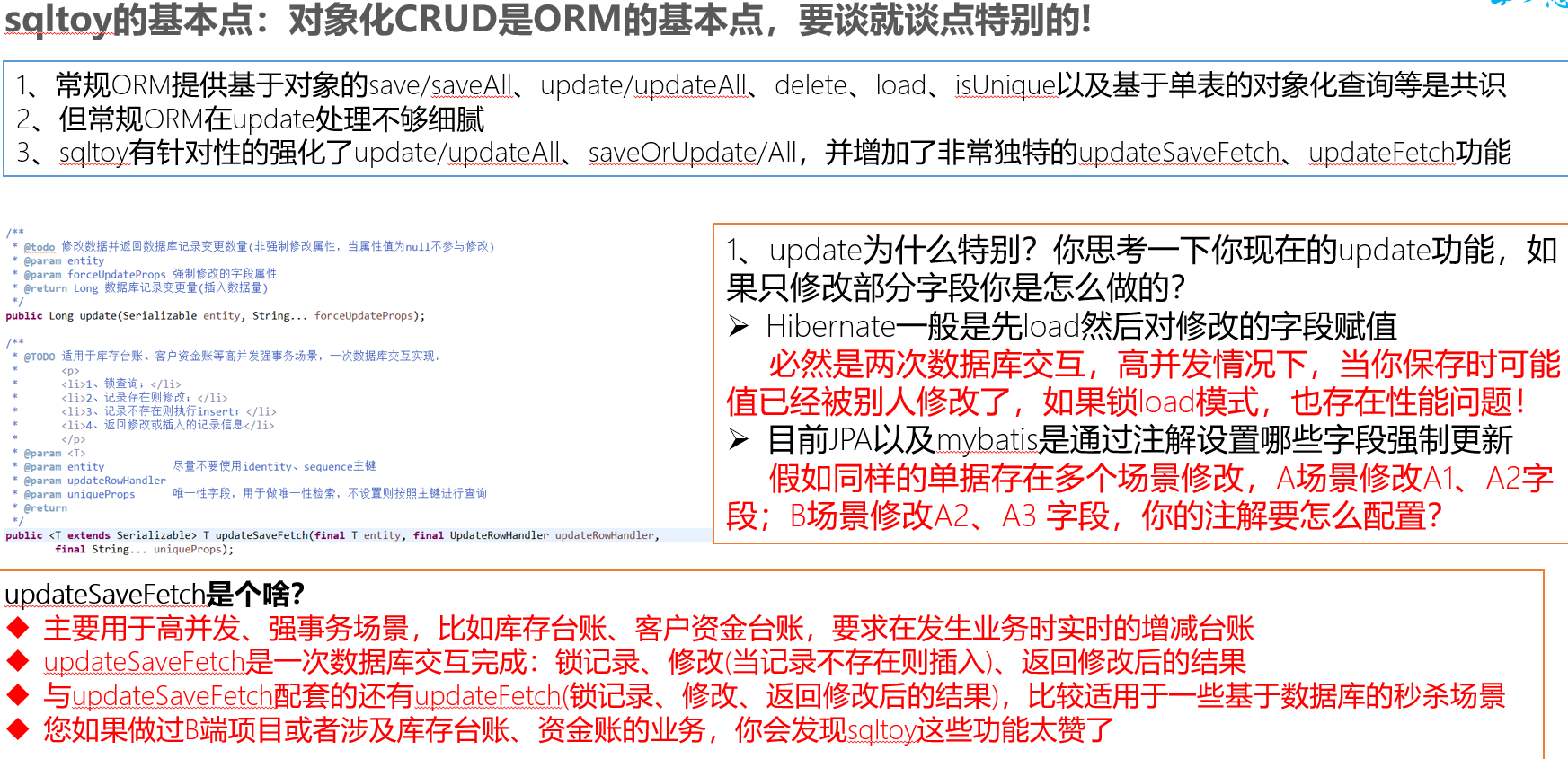
- Fortalezca la operación de actualización y proporcione capacidades de modificación de campos elásticos. A diferencia de hibernar, cargar primero y luego modificar, la modificación se completa en una interacción de base de datos, lo que garantiza la precisión de los datos en escenarios de alta concurrencia.
- Modificación en cascada mejorada, que proporciona opciones de operación para eliminar primero o invalidar primero y luego sobrescribir.
- Se agregaron las funciones updateFetch y updateSaveFetch para fortalecer el procesamiento de transacciones sólidas y escenarios de alta concurrencia, similares al libro mayor de inventario y al libro mayor de capital, para lograr una interacción con la base de datos, completar la consulta de bloqueo, insertar si no existe, modificar si existe y devolver el resultados modificados.
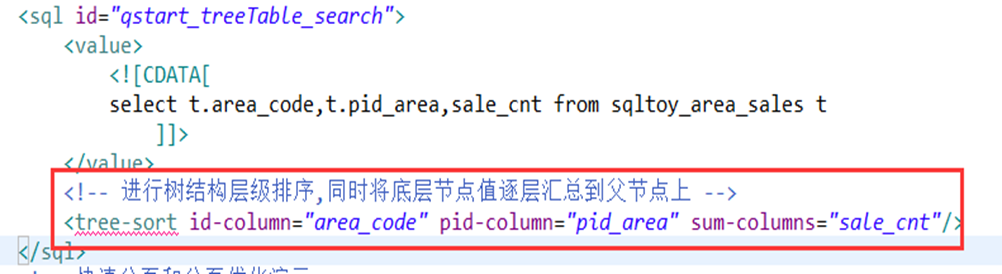
- Se agregó encapsulación de estructura de árbol para facilitar la unificación de consultas recursivas de datos de estructura de árbol en diferentes bases de datos.
- Admite fragmentación de bases de datos y tablas, múltiples estrategias de clave primaria (soporte adicional para claves primarias comerciales generadas según reglas específicas basadas en Redis), almacenamiento cifrado y verificación de versión de datos.
- Proporciona asignación de atributos públicos (creador, modificador, hora de creación, hora de modificación, inquilino), procesamiento de tipo extendido, etc.
- Proporciona filtrado y asignación unificados para múltiples inquilinos, introducción de parámetros de permiso de datos y verificación no autorizada.
parte de consulta
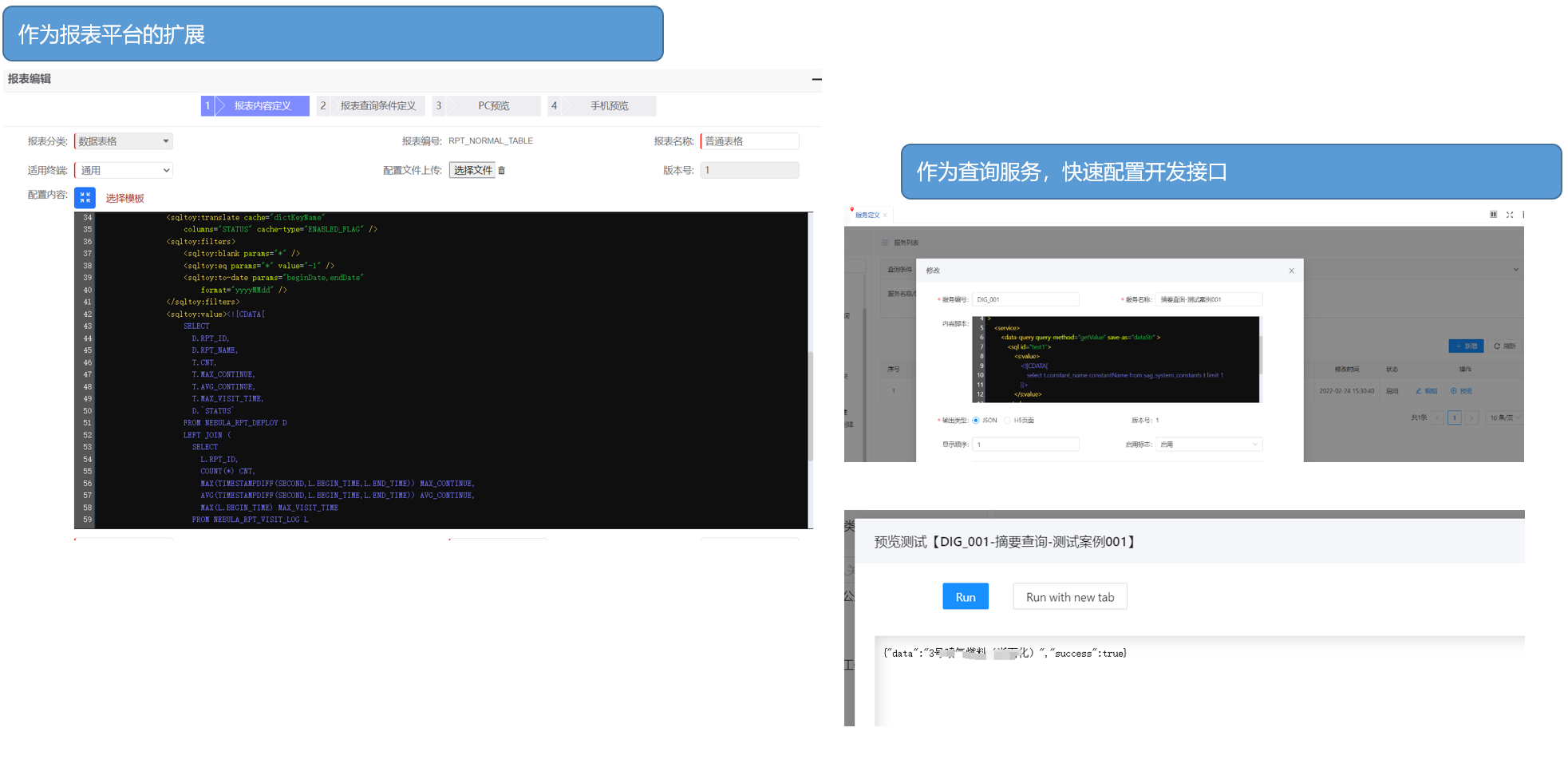
- El método de escritura SQL extremadamente intuitivo facilita una rápida migración bidireccional desde el código del cliente <-->, facilitando cambios y mantenimiento posteriores.
- Admite traducción de caché y clave de coincidencia de caché inversa en lugar de una consulta difusa
- Proporciona capacidades de soporte entre bases de datos: conversión y adaptación automática de funciones en diferentes bases de datos, coincidencia automática de SQL multidialecto de acuerdo con el entorno real y pruebas de sincronización de múltiples bases de datos, lo que mejora enormemente las capacidades de producción.
- Proporciona funciones de consulta para escenarios especiales, como registros principales y registros aleatorios.
- Proporciona el mecanismo de consulta de paginación más potente: 1) Optimiza automáticamente las declaraciones de recuento; 2) Proporciona optimización de paginación basada en caché para evitar ejecutar consultas de recuento cada vez; 3) Proporciona paginación rápida única; 4) Proporciona paginación paralelizada
- Proporciona capacidades de subbase de datos y subtablas.
- Proporciona un valor extremadamente valioso en proyectos de gestión: cálculo de resumen de grupo, conversión de fila-columna (fila a columna, columna a fila), comparación año tras año, clasificación de árboles, algoritmos relacionados con el resumen de árboles, integración natural
- Proporciona encapsulación de estructura de datos jerárquica basada en consultas.
- Proporciona una gran cantidad de funciones auxiliares: desensibilización de datos, formateo, preprocesamiento de parámetros condicionales, etc.
Soporta múltiples bases de datos
- MySQL convencional, oracle, db2, postgresql, sqlserver, dm, kingbase, sqlite, h2, oceanBase, polardb, guassdb, tidb
- Soporte de base de datos distribuida olap: clickhouse, StarRocks, greenplum, impala (kudu)
- Soporte de búsqueda elástica, mongodb
- Todas las consultas de bases de datos basadas en sql y jdbc
Introducción a las funciones de sqltoy:
- Las ideas centrales de construcción de sqltoy
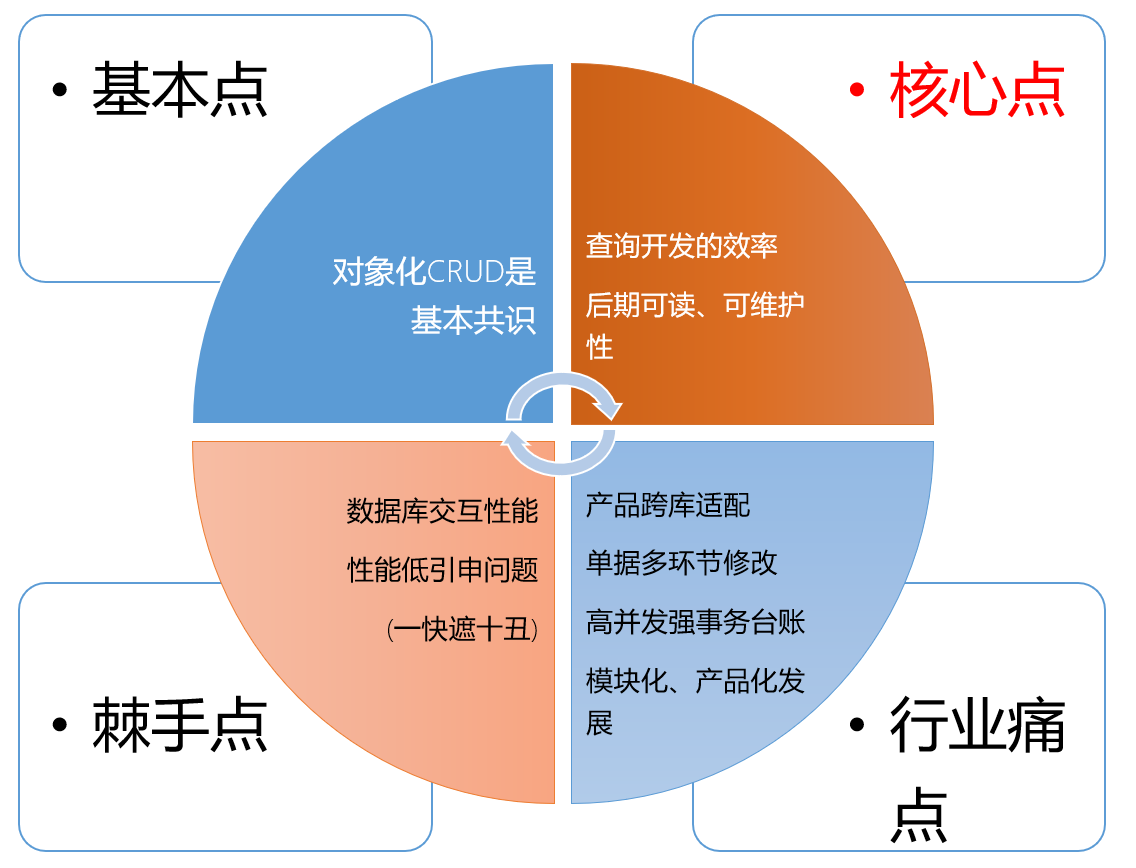
- Los puntos centrales de comparar sqltoy con mybatis (más): redacción de declaraciones de consulta, legibilidad y mantenibilidad
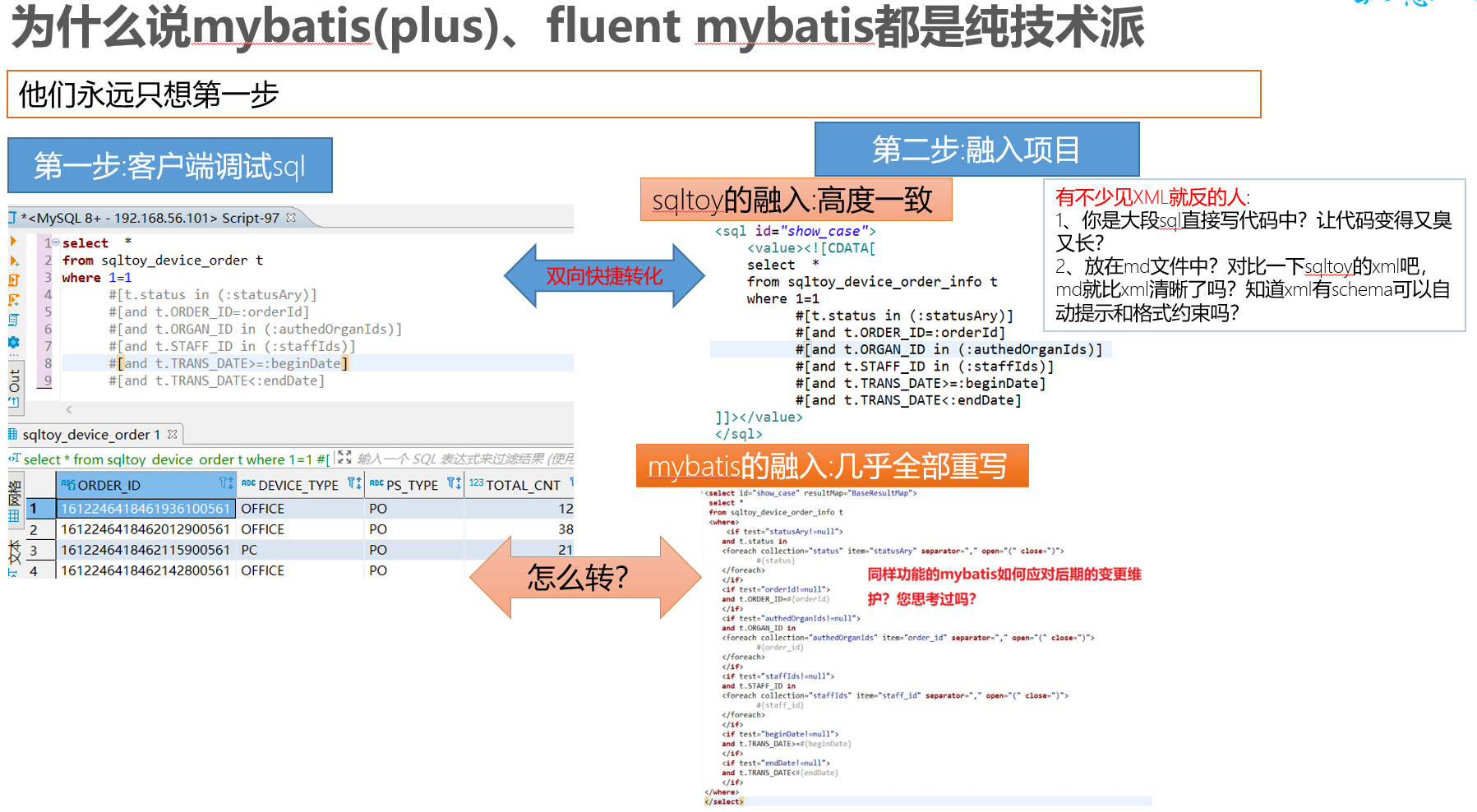
- La basura objetivada es la base, pero sqltoy tiene mejoras específicas: actualización, actualizaciónSaveFetch, actualizaciónFetch, etc.
- La traducción de caché de sqltoy reduce en gran medida las asociaciones de tablas y simplifica SQL, lo que permite que el rendimiento de sus consultas aumente geométricamente.
- La paginación definitiva también le ayuda a lograr una mejora significativa en el rendimiento de las consultas.
- Paginación rápida: @fast () se da cuenta de que primero se obtienen datos de una sola página y luego se realizan consultas relacionadas, lo que mejora enormemente la velocidad.
- Optimizador de paginación: la optimización de página cambia las consultas de paginación de dos veces a 1,3 ~ 1,5 veces (no es necesario repetir el número total de registros que utilizan el caché para lograr las mismas condiciones de consulta dentro de un período determinado)
- El proceso de paginación de sqltoy para obtener el total de registros no es un simple recuento de selección (1) de (sql original); en cambio, determina inteligentemente si se convierte en: recuento de selección (1) de 'de la declaración posterior' y elimina automáticamente el orden más externo por
- sqltoy admite consultas paralelas: paralelo = "verdadero", consulta el número total de registros y datos de una sola página al mismo tiempo, lo que mejora enormemente el rendimiento
- Cálculos estadísticos convenientes entre bases de datos: rotación de datos
- Cálculo estadístico conveniente entre bases de datos: estadísticas del grupo Infinitus (incluidos resúmenes y promedios)
- Cómodos cálculos estadísticos entre bases de datos: año tras año y mes tras mes
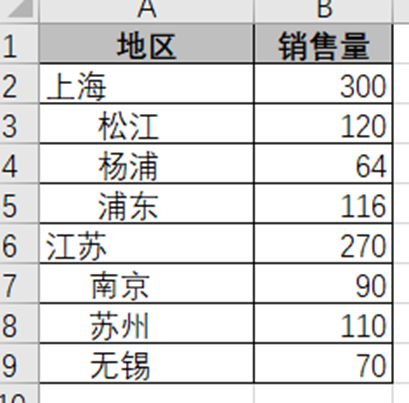
5. Clasificación y resumen de tablas de árbol
6. Integración ampliada