
I. Introducción
Aunque el desarrollo de software siempre ha estado comprometido con la búsqueda de características eficientes, legibles y fáciles de mantener, estas características son como un triángulo imposible, entrelazadas entre sí, una está menguando y la otra está menguando. Al igual que los lenguajes de bajo nivel (como el lenguaje ensamblador y C) pueden mantener un rendimiento de ejecución eficiente, pero tienen deficiencias y desventajas en cuanto a legibilidad y mantenibilidad, mientras que los lenguajes de alto nivel (como Java y Python) tienen deficiencias y desventajas. en legibilidad y mantenibilidad. Funciona bien en términos de rendimiento, pero se queda corto en términos de eficiencia de ejecución.
Desarrollar las ventajas de la ecología del lenguaje y compensar sus deficiencias siempre ha sido una dirección de evolución de los lenguajes de programación.
Los diferentes lenguajes de programación tienen diferentes características y protocolos. Tomemos el lenguaje JAVA como ejemplo para desglosar los puntos de conocimiento y las habilidades prácticas que fácilmente se pasan por alto durante el proceso de desarrollo pero que deben dominarse.
2 conceptos básicos
En 1999, la misión de la NASA a Marte fracasó: en esta misión, el software del sistema de vuelo del Mars Climate Explorer utilizó la unidad métrica Newton para calcular la potencia del propulsor, mientras que la cantidad de corrección de dirección y la entrada de empuje por parte del personal de tierra. Los parámetros del detector utilizaron la unidad británica de libra de fuerza, lo que provocó que el detector ingresara a la atmósfera a una altura incorrecta y finalmente se desintegrara.
Este fue un accidente causado por el conflicto entre los estándares internacionales (ganado) y la localización (libras). Esto lleva al tema de que los programas deben prestar atención a la mantenibilidad. Dado que la producción de software a menudo requiere la colaboración de varias personas, la mantenibilidad es una parte importante del consenso colaborativo. Con respecto a este aspecto, los dos aspectos en los que la gente piensa más fácilmente son los nombres y las anotaciones, los discutiremos a continuación.
2.1 Acerca de los nombres
Según los hábitos de lectura, el método de denominación variable del programa debe superar el problema del espacio entre palabras, para conectar diferentes palabras y, en última instancia, lograr el efecto de crear una nueva "palabra" que sea fácil de leer. Los métodos de denominación comunes incluyen los siguientes:
- Caso serpiente : también llamado denominación subrayada, use guiones bajos y palabras en minúscula, por ejemplo: my_system;
- Caso camello (caso camello): distingue entre mayúsculas y minúsculas según la primera letra de la palabra y se puede subdividir en caso camello grande y caso camello pequeño, como: MySystem, mySystem;
- Nomenclatura húngara (caso HN): atributo + tipo + descripción, como: nLength, g_cch , hwnd;
- Caso Pascal (caso Pascal): todas las primeras letras están en mayúscula, lo que equivale a la nomenclatura del caso del gran camello, como: MySystem;
- Caso espinal : use un guión, por ejemplo: mi-sistema;
- Tapas de estudio : mayúsculas y minúsculas, sin reglas concisas, como: mySYSTEM, MYSystem;
Clasificadas según el tamaño de la audiencia y la popularidad, la nomenclatura del caso del camello y la nomenclatura de la serpiente son más populares, después de todo, tienen ventajas en cuanto a legibilidad y facilidad de escritura.
2.1.1 Diccionario de nombres
Conocer el significado tras ver el nombre: Un buen nombramiento es una especie de comentario.
Se recomienda que los estudiantes de I + D memoricen los nombres de los escenarios comerciales comunes en la industria. Por supuesto, alguien ya los ha resumido para nosotros, por lo que no entraré en demasiadas explicaciones aquí. Aquí hay un extracto para su referencia:
Denominación de clases de gestión : Bootstrap, Starter, Processor, Manager, Holder, Factory, Provider, Registrar, Engine, Service, Task
Denominación de clases de propagación : contexto, propagador
Denominación de clases de devolución de llamada : controlador, devolución de llamada, disparador, oyente, consciente
Denominación de clases de monitoreo : métrica, estimador, acumulador, rastreador
Nomenclatura de clases de gestión de memoria : Allocator, Chunk, Arena, Pool
Denominación de clases de detección de filtros : tubería, cadena, filtro, interceptor, evaluador, detector
Denominación de clases estructurales : caché, búfer, compuesto, contenedor, opción, parámetro, atributo, tupla, agregador, iterador, lote, limitador
Denominación de patrones de diseño comunes : estrategia, adaptador, acción, comando, evento, delegado, constructor, plantilla, proxy
Nomenclatura de clases de análisis : convertidor, resolución, analizador, personalizador, formateador
Denominación de clases de red : paquete, codificador, decodificador, códec, solicitud, respuesta
Denominación CRUD : Controlador, Servicio, Repositorio
Denominación de clases auxiliares : Util, Helper
Otros nombres de clases : Modo, Tipo, Invocador, Invocación, Inicializador, Futuro, Promesa, Selector, Reportero, Constantes, Accesor, Generador
2.1.2 Prácticas de denominación
¿ Cuáles son las reglas comunes de nomenclatura para proyectos ? Diferentes idiomas pueden tener diferentes hábitos. Tome la convención de nomenclatura del caso camel del lenguaje Java como ejemplo:
La especificación es relativamente abstracta. Primero echemos un vistazo a ¿cuáles son los malos nombres?
Además de las especificaciones estándar, también hay algunos casos reales que nos preocupan durante el proceso de desarrollo real.
1. Al definir una variable miembro, ¿debería utilizar un tipo contenedor o un tipo de datos básico?
Los valores predeterminados de las clases contenedoras y los tipos de datos básicos son diferentes: el primero es nulo y los valores predeterminados del segundo son diferentes según el tipo. Desde una perspectiva rigurosa de datos, el valor nulo de la clase contenedora puede representar información adicional, haciéndola más segura. Por ejemplo, puede evitar el riesgo de NPE causado por tipos básicos de unboxing automático y el riesgo de procesamiento anormal de la lógica empresarial. Por lo tanto, las variables miembro deben utilizar tipos de datos envolventes y los tipos de datos básicos se utilizan en el contexto de las variables locales.
2. ¿Por qué no se recomienda que las variables miembro de tipo booleano comiencen con is?
En realidad, existen regulaciones claras sobre la definición de métodos getter/setter en Java Beans. De acuerdo con la especificación JavaBeans(TM), si se trata de un parámetro ordinario llamado nombre de propiedad, su setter/getter debe definirse de la siguiente manera:
public <PropertyType> get<PropertyName>();
public void set<PropertyName>(<PropertyType> p)Sin embargo, la variable de tipo booleano nombrePropiedad sigue un conjunto diferente de principios de nomenclatura:
public boolean is<PropertyName>();
public void set<PropertyName>(boolean p)Debido a las diferencias en la forma en que varios marcos RPC y herramientas de serialización de objetos manejan las variables de tipo booleano, es fácil causar problemas de portabilidad del código. Existen problemas de compatibilidad entre las bibliotecas de serialización json más comunes, Jackson y Gson. La primera atraviesa todos los métodos getter de la clase a través de la reflexión y obtiene las propiedades del objeto a través de la intercepción del nombre del método, mientras que la segunda utiliza directamente la reflexión para iterar sobre las propiedades en este clase. Para evitar el impacto de esta diferencia en el negocio, se recomienda que no comiencen todas las variables miembro para evitar resultados de serialización impredecibles.
3. ¿Ves qué efectos secundarios puede causar el uso de mayúsculas y minúsculas?
El lenguaje JAVA en sí distingue entre mayúsculas y minúsculas, pero al operar archivos con rutas y nombres de archivos, los nombres y rutas de archivos aquí no distinguen entre mayúsculas y minúsculas, esto se debe a que el sistema de archivos no distingue entre mayúsculas y minúsculas. Un escenario típico es que cuando usamos una plataforma de administración de código como git y cambiamos el nombre del archivo en mayúsculas en la ruta del paquete a minúsculas, git no se puede actualizar. Para evitar problemas innecesarios, se recomienda usar palabras en minúsculas en el paquete. ruta Varias palabras se definen a través de una jerarquía de rutas.
4. ¿Las clases en diferentes paquetes jar entrarán en conflicto entre sí?
Aquí nos centramos en la segunda situación. Esta situación es probable que ocurra cuando el sistema se divide y reconstruye. El proyecto original se copia y luego se elimina, lo que da como resultado que algunas herramientas o clases de enumeración tengan las mismas rutas y nombres que las originales. cuando terceros que llaman dependen de estos dos sistemas al mismo tiempo, es fácil tender una trampa para futuras iteraciones. Para evitar este tipo de problemas, debe crear una ruta de paquete única para el sistema.
Suplemento: si depende de bibliotecas de terceros y hay un conflicto de clases, puede resolver el conflicto del paquete jar introduciendo la biblioteca de terceros jarjar.jar y modificando el nombre del paquete de uno de los archivos jar en conflicto.
5. ¿Cómo hacer un equilibrio entre la legibilidad de los nombres de variables y los recursos (memoria, ancho de banda) ocupados?
Puede utilizar herramientas de serialización de objetos como un gran avance, tomando como ejemplo el método de serialización común Json (Jackson):
public class SkuKey implements Serializable {
@JsonProperty(value = "sn")
@ApiModelProperty(name = "stationNo", value = " 门店编号", required = true)
private Long stationNo;
@JsonProperty(value = "si")
@ApiModelProperty(name = "skuId", value = " 商品编号", required = true)
private Long skuId;
// 省略get/set方法
}La función de la anotación @JsonProperty es cambiar el nombre de las propiedades comunes en JavaBean al nuevo nombre especificado durante la serialización. Esta implementación no tiene ningún impacto en la implementación empresarial. La operación de denominación original aún prevalece y solo entra en vigor cuando RPC externo requiere serialización y deserialización. De esta forma, se resuelve mejor el conflicto entre legibilidad y ocupación de recursos.
6. Para proporcionar parámetros de entrada y salida para servicios externos, ¿deberíamos utilizar objetos de clase o contenedores de mapas?
Desde una perspectiva de flexibilidad, los contenedores de mapas son estables y más flexibles. Desde la perspectiva de la estabilidad y la legibilidad, el contenedor de mapas es una caja negra. No sabes lo que hay dentro. Debes tener documentación auxiliar detallada para colaborar. Dado que las acciones de mantenimiento de documentos a menudo están separadas del código de ingeniería, el mecanismo Como resultado, es difícil garantizar la exactitud y actualidad de la información. Por lo tanto, todavía se recomienda utilizar objetos de estructura de clases para mantener las estructuras de parámetros entrantes y salientes.
2.2 Acerca de los comentarios
Los comentarios son un medio importante de comunicación entre programadores y lectores. Son explicaciones y explicaciones del código. Los buenos comentarios pueden mejorar la legibilidad del software y reducir el costo de mantenimiento del software.
2.2.1 Buenos comentarios
Jerárquico : anota y explica cada uno con su propio enfoque según diferentes granularidades, como sistema, paquete, clase, método, bloque de código, línea de código, etc.
Hay especificaciones : un buen código es mejor que muchos comentarios, que es la misma razón por la que solemos decir "la convención es mayor que la configuración". Es una buena forma estándar de utilizar bibliotecas de terceros como swagger para implementar anotaciones, es decir, documentos de interfaz ;
2.2.2 Malos comentarios
Para que los comentarios expresen con precisión y claridad la lógica funcional, el mantenimiento de los comentarios tiene costos de mantenimiento considerables, por lo que cuantos más comentarios, más detallados, mejor. A continuación se muestran algunos escenarios de malas anotaciones para facilitar la comprensión:
2.3 Acerca de las capas
El objetivo principal del diseño en capas del sistema es reducir la complejidad del sistema separando las preocupaciones, al mismo tiempo que mejora la reutilización y reduce los costos de mantenimiento. Por lo tanto, si comprende el concepto de capas, la mantenibilidad del sistema tendrá un esqueleto en gran medida.
2.3.1 Sistema de capas
Antes de que ISO (Organización Internacional de Normalización) formulara el modelo de comunicación de red de siete capas (Modelo de referencia de interconexión de sistemas abiertos, OSI/RM) en 1981, había muchas arquitecturas en las redes informáticas, entre las que se encontraban la estructura SNA (Arquitectura de red del sistema) de IBM y la DEC. La arquitectura de red digital DNA (Digital Network Architecture) es la más famosa.
Anteriormente, los diferentes estándares propuestos por cada fabricante se basaban en sus propios equipos, los usuarios sólo podían utilizar productos de la misma empresa a la hora de elegir productos, porque diferentes empresas tienen diferentes estándares y pueden tener diferentes métodos de trabajo, lo que puede provocar incompatibilidades. entre productos de red de diferentes fabricantes. Si los productos de la misma empresa pueden satisfacer las necesidades de los usuarios, entonces depende de qué empresa sea más fuerte, más fuerte y más fácil de usar. Naturalmente, los usuarios no dirán nada. El problema es que una empresa no tiene razón. Todas Los productos sobresalen. Esto provocará un sufrimiento doloroso tanto para los fabricantes como para los usuarios. Por analogía con los protocolos de interfaz de carga de teléfonos móviles actuales (interfaz Micro USB, interfaz Tipo-c, interfaz Lightning), si siempre tiene varios cables de carga a mano, podrá comprender profundamente el significado del estándar.
2.3.2 Escalabilidad del software
La escalabilidad del software se refiere a la capacidad de un sistema de software para mantener su rendimiento original y expandirse para admitir más tareas cuando enfrenta presión de carga.
La escalabilidad puede tener dos aspectos, escalabilidad vertical y escalabilidad horizontal. La escalabilidad vertical mejora el rendimiento del sistema al agregar recursos en la misma unidad de negocio, como aumentar la cantidad de CPU del servidor, aumentar la memoria del servidor, etc. La escalabilidad horizontal se logra agregando múltiples recursos de unidades de negocios para que todas las unidades de negocios actúen lógicamente como una sola. Por ejemplo, el modelo de componentes distribuidos ejb, el modelo de componentes de microservicio, etc. pertenecen a este método.
Los sistemas de software deben considerar un diseño de escalabilidad eficaz al diseñar para garantizar un soporte de rendimiento suficiente ante la presión de carga.
Desde una perspectiva de escalabilidad, la estratificación del sistema cae más en la categoría de escalabilidad horizontal. En el desarrollo de sistemas J2EE, generalmente adoptamos una arquitectura en capas, que generalmente se divide en capa de presentación, capa empresarial y capa de persistencia. Una vez que se adoptan las capas, debido a que la comunicación entre capas causará una sobrecarga adicional, lo que se traerá a nuestro sistema de software es que la sobrecarga de procesamiento de cada negocio aumentará.
Dado que las capas generarán una sobrecarga adicional, ¿por qué necesitamos hacerlo?
Esto se debe a que existe un límite superior para mejorar el rendimiento y el rendimiento del software simplemente confiando en el escalamiento vertical de los recursos de hardware del montón y, a medida que la escala del sistema se expande, el costo del escalamiento vertical también será muy costoso. Cuando se adopta la estratificación, aunque se incurre en una sobrecarga de comunicación entre capas, es beneficioso para la escalabilidad horizontal de cada capa, y cada capa se puede escalar de forma independiente sin afectar a otras capas. Es decir, cuando el sistema necesita hacer frente a una mayor cantidad de acceso, podemos aumentar el rendimiento del sistema agregando múltiples recursos de unidades de negocio.
2.4 Resumen
Este capítulo habla principalmente sobre la necesidad de lograr un consenso unificado sobre nombres y anotaciones durante el proceso de desarrollo desde los aspectos de legibilidad y mantenibilidad. Además del consenso, el aislamiento de las preocupaciones también debe realizarse a nivel de diseño, lo que incluye la división de las responsabilidades del sistema, la división de las funciones de los módulos, la convergencia de las capacidades de las clases y la relación entre las estructuras de las entidades, todo debe estar bien. planificado.
Tres capítulos de práctica
Aprendamos de esos casos prácticos clásicos de varios indicadores de calidad importantes, como la escalabilidad, la mantenibilidad, la seguridad y el rendimiento del programa.
3.1 Definición de clase
3.1.1 Definición constante
Una constante es un valor fijo que no cambia durante la ejecución del programa. Puede utilizar enumeraciones (Enum) o clases (Class) para definir constantes.
Si necesita definir un grupo de constantes relacionadas, entonces es más apropiado utilizar una enumeración. Las enumeraciones tienen mayores ventajas en términos de seguridad y operatividad (apoyando el recorrido y la definición de funciones).
public enum Color {
RED, GREEN, BLUE;
}Si solo necesita definir una o varias constantes de solo lectura, es más conciso y conveniente utilizar constantes de clase.
public class MyClass {
public static final int MAX_VALUE = 100;
}3.1.2 Herramientas
Las clases de herramientas generalmente contienen métodos públicos comunes en un determinado campo no comercial, no requieren variables miembro de soporte y solo se utilizan como métodos de herramienta. Por lo tanto, lo más apropiado es convertirlo en un método estático, que no requiere creación de instancias y solo puede usarse para obtener la definición del método y llamarlo.
La razón por la que no se crea una instancia de la clase de herramienta es para ahorrar espacio en la memoria, porque la clase de herramienta proporciona métodos estáticos que se pueden llamar a través de la clase y no es necesario crear una instancia del objeto de clase de herramienta.
public abstract class ObjectHelper {
public static boolean isEmpty(String str) {
return str == null || str.length() == 0;
}
}Para lograr restricciones que no requieran objetos instanciados, es mejor agregar palabras clave abstractas para calificar la declaración al definir la clase . Es por eso que la mayoría de las clases de herramientas de código abierto como Spring se modifican con palabras clave abstractas.
3.1.3 JavaBean
Hay dos métodos de implementación comunes para la definición de JavaBean: escritura manual y generación automática.
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}Utilice el complemento lombok para mejorar la escritura de código Java a través de anotaciones y generar dinámicamente métodos get y set durante la compilación.
import lombok.Data;
@NoArgsConstructor
@Data
@Accessors(chain = true)
public class Person {
private String name;
private int age;
}El paquete de complementos también proporciona capacidades prácticas de programación en cadena como @Builder y @Accessors, que pueden mejorar la eficiencia de la codificación hasta cierto punto.
3.1.4 Clases inmutables
En algunos escenarios, para garantizar la estabilidad y coherencia de sus funciones y comportamientos, las clases están diseñadas para que no se puedan heredar ni anular.
La forma de definirlo es agregar la palabra clave final a la clase, ejemplo:
public final class String implements Serializable, Comparable<String>, CharSequence {
}Las siguientes son algunas clases que no se pueden heredar ni anular y que se utilizan en algunos middleware subyacentes:
java.lang.String
java.lang.Math
java.lang.Boolean
java.lang.Character
java.util.Date
java.sql.Date
java.lang.System
java.lang.ClassLoader3.1.5 Clases internas anónimas
Las clases internas anónimas se suelen utilizar para simplificar el código, su definición y uso suelen ocurrir en el mismo lugar, sus escenarios de uso son los siguientes:
public class Example {
public static void main(String[] args) {
// 创建一个匿名内部类
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("Hello, World!");
}
};
// 调用匿名内部类的方法
runnable.run();
}
}3.1.6 Declarar una clase
Una clase de declaración es un tipo o interfaz básico en el lenguaje Java, que se utiliza para definir el comportamiento o las características de la clase, algunas incluso son simplemente una declaración sin definiciones de métodos específicas.
3.1.7 Clase de registro
La clase Record tuvo una vista previa en Java14 y no se lanzó oficialmente hasta Java17. Según la descripción de JEP395, la clase Record es un portador de datos inmutables, similar a varios modelos, dto, vo y otras clases POJO que se usan ampliamente en la actualidad, pero el registro en sí ya no se puede asignar después de la construcción. Todas las clases de registros heredan de java.lang.Record. La clase Record proporciona un constructor de campo completo, acceso a atributos y métodos iguales, código hash y toString de forma predeterminada. Su función es muy similar al complemento lombok .
manera definida
/**
* 关键定义的类是不可变类
* 将所有成员变量通过参数的形式定义
* 默认会生成全部参数的构造方法
* @param name
* @param age
*/
public record Person(String name, int age) {
public Person{
if(name == null){
throw new IllegalArgumentException("提供紧凑的方式进行参数校验");
}
}
/**
* 定义的类中可以定义静态方法
* @param name
* @return
*/
public static Person of(String name) {
return new Person(name, 18);
}
}Uso
Person person = new Person("John", 30);
// Person person = Person.of("John");
String name = person.name();
int age = person.age();escenas a utilizar
Construya un objeto de almacenamiento temporal a través de Registro y ordene los objetos de la matriz Persona según la edad.
public List<Person> sortPeopleByAge(List<Person> people) {
record Data(Person person, int age){};
return people.stream()
.map(person -> new Data(person, computAge(person)))
.sorted((d1, d2) -> Integer.compare(d2.age(), d1.age()))
.map(Data::person)
.collect(toList());
}
public int computAge(Person person) {
return person.age() - 1;
}3.1.8 Tipo de sellado
La nueva característica Clases selladas introducida en Java 17 se utiliza principalmente para limitar la herencia de clases. Sabemos que existen dos tipos principales de restricciones sobre las funciones de herencia de clases:
Pero, obviamente, estas dos restricciones son muy estrictas y las clases selladas son un control más detallado de la herencia de clases.
sealed class SealedClass permits SubClass1, SubClass2 {
}
class SubClass1 extends SealedClass {
}
class SubClass2 extends SealedClass {
}En el ejemplo anterior, SealedClass es una clase sellada que contiene dos subclases SubClass1 y SubClass2. En la definición de SubClass1 y SubClass2, debe usar la palabra clave extends para heredar de SealedClass y usar la palabra clave permits para especificar qué subclases permiten heredar. Al utilizar una clase sellada, puede garantizar que sólo las subclases que cumplan determinadas condiciones puedan heredar o implementar el protocolo o la especificación.
3.2 Definición del método
3.2.1 Método de construcción
Un constructor es un método especial que se utiliza para crear e inicializar objetos. El nombre del constructor debe ser el mismo que el nombre de la clase y no tener tipo de retorno. Al crear un objeto, puede llamar al constructor usando la nueva palabra clave.
public class MyClass {
private int myInt;
private String myString;
// 构造方法
public MyClass(int myInt, String myString) {
this.myInt = myInt;
this.myString = myString;
}
}Una característica importante de la implementación del patrón singleton es que los usuarios no pueden crear (nuevos) objetos a voluntad ¿Cómo lograr el control de seguridad? Declarar el constructor como privado es un paso imprescindible.
3.2.2 Reescritura de métodos
La anulación de métodos se refiere a redefinir un método con el mismo nombre en la clase principal en la subclase. La anulación de métodos permite a una subclase anular la implementación del método en la clase principal para implementar su propio comportamiento según las necesidades de la subclase.
class Animal {
public void makeSound() {
System.out.println("Animal is making a sound");
}
}
class Cat extends Animal {
@Override
public void makeSound() {
System.out.println("Meow");
}
}
public class Main {
public static void main(String[] args) {
Animal myCat = new Cat();
myCat.makeSound(); // 输出 "Meow"
}
}Una de las tres características principales del polimorfismo orientado a objetos, la reescritura de métodos es su núcleo.
3.2.3 Sobrecarga de métodos
Se definen varios métodos en una clase con el mismo nombre pero con diferentes listas de parámetros. La sobrecarga de métodos nos permite usar el mismo nombre de método para realizar diferentes operaciones y ejecutar una lógica de código diferente según los parámetros pasados al método.
public class Calculator {
public int add(int a, int b) {
return a + b;
}
public double add(double a, double b) {
return a + b;
}
}
public class Main {
public static void main(String[] args) {
Calculator calculator = new Calculator();
int result1 = calculator.add(2, 3);
double result2 = calculator.add(2.5, 3.5);
System.out.println(result1); // 输出 5
System.out.println(result2); // 输出 6.0
}
}3.2.4 Métodos anónimos
Java 8 introdujo expresiones Lambda, que se pueden utilizar para implementar funciones similares a los métodos anónimos. Una expresión lambda es una función anónima que puede pasarse como parámetro a un método o usarse directamente como una expresión independiente.
public static void main(String args[]) {
List<String> names = Arrays.asList("hello", "world");
// 使用 Lambda 表达式作为参数传递给 forEach 方法
names.forEach((String name) -> System.out.println("Name: " + name));
// 使用 Lambda 表达式作为独立表达式使用
Predicate<String> nameLengthGreaterThan5 = (String name) -> name.length() > 5;
boolean isLongName = nameLengthGreaterThan5.test("John");
System.out.println("Is long name? " + isLongName);
}3.3 Definición de objeto
3.3.1 Objeto único
Un objeto singleton es un objeto que se puede usar repetidamente, pero que solo tiene una instancia. Tiene las siguientes funciones:
Por ejemplo, utilice una enumeración para implementar el patrón singleton:
public enum Singleton {
INSTANCE;
public void someMethod() {
// ...其他代码...
}
}3.3.2 Objetos inmutables
Los objetos inmutables en Java son objetos cuyo estado no se puede modificar una vez creados. Los objetos inmutables son objetos muy útiles porque aseguran que el estado del objeto sea consistente en todo momento, evitando así los problemas causados por la modificación del estado del objeto. Hay varias formas de implementar objetos inmutables:
Algunas operaciones de clases de contenedores también tienen clases contenedoras correspondientes para implementar la inmutabilidad de los objetos contenedores, como la definición de objetos de matriz inmutables:
Collections.unmodifiableList(new ArrayList<>());Cuando un objeto en el dominio se pasa como parámetro de entrada, se define como un objeto inmutable. Esto es muy importante para mantener la coherencia de los datos. De lo contrario, la imprevisibilidad de los cambios de atributos del objeto será muy problemática al localizar problemas.
3.3.3 Objeto tupla
Tupla es un concepto común en los lenguajes de programación funcionales. Una tupla es un objeto inmutable que puede almacenar múltiples objetos de diferentes tipos en un formato seguro. Es una estructura de datos muy útil que permite a los desarrolladores procesar múltiples elementos de datos de manera más conveniente y eficiente. Sin embargo, la biblioteca estándar nativa de Java no proporciona soporte para tuplas y debemos implementarla nosotros mismos o con la ayuda de una biblioteca de clases de terceros.
Implementación de dos tuplas
public class Pair<A,B> {
public final A first;
public final B second;
public Pair(A a, B b) {
this.first = a;
this.second = b;
}
public A getFirst() {
return first;
}
public B getSecond() {
return second;
}
}Implementación del triplete
public class Triplet<A,B,C> extends Pair<A,B>{
public final C third;
public Triplet(A a, B b, C c) {
super(a, b);
this.third = c;
}
public C getThird() {
return third;
}
public static void main(String[] args) {
// 表示姓名,性别,年龄
Triplet<String,String,Integer> triplet = new Triplet("John","男",18);
// 获得姓名
String name = triplet.getFirst();
}
}Implementación de múltiples grupos
public class Tuple<E> {
private final E[] elements;
public Tuple(E... elements) {
this.elements = elements;
}
public E get(int index) {
return elements[index];
}
public int size() {
return elements.length;
}
public static void main(String[] args) {
// 表示姓名,性别,年龄
Tuple<String> tuple = new Tuple<>("John", "男", "18");
// 获得姓名
String name = tuple.get(0);
}
}Tuple tiene principalmente las siguientes funciones:
1. Almacene múltiples elementos de datos: Tuple puede almacenar múltiples tipos diferentes de elementos de datos, que pueden ser tipos básicos, tipos de objetos, matrices, etc.;
2. Simplifique el código: Tuple puede hacer que el código sea más conciso y reducir la escritura de código repetido. A través de Tuple, podemos empaquetar múltiples variables en un objeto, reduciendo así la cantidad de código;
3. Mejorar la legibilidad del código: Tuple puede mejorar la legibilidad del código. A través de Tuple, podemos empaquetar múltiples variables en un objeto, haciendo que el código sea más legible;
4. Admite funciones que devuelven múltiples valores: Tuple puede admitir funciones que devuelven múltiples valores. En Java, una función solo puede devolver un valor, pero a través de Tuple, podemos empaquetar múltiples valores en un objeto y devolverlo;
Además de la personalización, las bibliotecas de clases de terceros que implementan el concepto de tupla incluyen: Google Guava, Apache Commons Lang, JCTools, Vavr, etc.
La Tuple de la biblioteca Google Guava proporciona más funciones y se utiliza ampliamente. Por ejemplo, para aclarar el significado de las tuplas, Guava proporciona el concepto de tuplas con nombre. Al dar nombres a las tuplas, puedes expresar el significado de cada elemento con mayor claridad. Ejemplo:
NamedTuple namedTuple = Tuples.named("person", "name", "age");3.3.4 Objetos temporales
Los objetos temporales se refieren a objetos que se necesitan temporalmente durante la ejecución del programa pero que tienen un ciclo de vida corto. Por lo general, estos objetos existen solo brevemente durante el uso y no requieren almacenamiento ni reutilización a largo plazo.
Las sugerencias de optimización para objetos temporales son las siguientes:
3.3.5 Valhalla
Como lenguaje de alto nivel, siempre ha habido una gran brecha en el rendimiento entre Java y el lenguaje C y el lenguaje ensamblador de nivel inferior. Para cerrar esta brecha, el proyecto Valhalla se lanzó en 2014 con el objetivo de llevar tipos de datos planos más flexibles a lenguajes basados en JVM.
Todos sabemos que Java admite tanto tipos nativos como tipos de referencia. Los tipos de datos nativos se pasan por valor. La asignación y el paso de parámetros de función copiarán el valor. Después de copiar, no hay correlación entre las dos copias. Los tipos de referencia se pasan punteros en cualquier caso, y modificar el contenido señalado por el puntero afectará Todas las referencias. Valhalla introdujo los tipos de valor, un concepto entre los tipos primitivos y los tipos de referencia.
Dado que la mayoría de las estructuras de datos Java en una aplicación son objetos, podemos considerar a Java como un lenguaje intensivo en punteros. Esta implementación de objetos basada en punteros se utiliza para habilitar la identificación de objetos, que a su vez se utiliza para características del lenguaje como polimorfismo, mutabilidad y bloqueo. De forma predeterminada, estas propiedades se aplican a todos los objetos independientemente de si realmente son necesarios. Aquí es donde entran en juego los tipos de valores.
El concepto de tipos de valor es representar pura agregación de datos, lo que elimina la funcionalidad de los objetos normales. Entonces tenemos datos puros, no identidad. Por supuesto, esto significa que también perdemos la funcionalidad que se puede lograr mediante la identificación de objetos. Como ya no tenemos una identidad de objeto, podemos abandonar los punteros y cambiar el diseño general de la memoria de los tipos de valores. Comparemos el diseño de la memoria de tipo de valor y referencia de objeto.
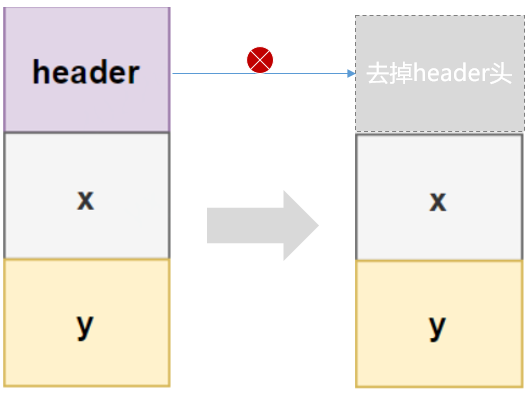
La información del encabezado del objeto se elimina y el tipo de valor ahorra 16 bytes de espacio en el encabezado del objeto en un sistema operativo de 64 bits. Al mismo tiempo, también significa renunciar a la identidad única del objeto (Identidad) y la seguridad de inicialización. Las palabras clave o métodos anteriores como esperar (), notificar (), sincronizado (obj), System.identityHashCode (obj), etc. no será válido y no podrá utilizarse.
Valhalla mejorará significativamente el rendimiento y reducirá las abstracciones con fugas:
En septiembre de 2023, el proyecto Valhalla todavía está en progreso y aún no se ha publicado ninguna versión oficial. Vale la pena esperar con ansias este proyecto innovador.
cuatro resumen
Este artículo resume el sentido común básico que se utiliza a menudo en el proceso de desarrollo de software y se divide en dos capítulos: conceptos básicos y práctica. Los conceptos básicos se centran en las convenciones de nomenclatura de clases, métodos, variables y los criterios para juzgar la calidad de los comentarios del código. . En el capítulo práctico se analizan conceptos técnicos comunes y prácticas de implementación desde los tres niveles de clases, métodos y objetos. Espero que este sentido común pueda traer algo de reflexión y ayuda a los lectores.
Lei Jun: La versión oficial del nuevo sistema operativo de Xiaomi, ThePaper OS, ha sido empaquetada. La ventana emergente en la página de lotería de la aplicación Gome insulta a su fundador. Ubuntu 23.10 se lanza oficialmente. ¡También podrías aprovechar el viernes para actualizar! Episodio de lanzamiento de Ubuntu 23.10: La imagen ISO fue "retirada" urgentemente debido a que contenía discurso de odio. Un estudiante de doctorado de 23 años solucionó el "error fantasma" de 22 años en Firefox. Se lanzó el escritorio remoto RustDesk 1.2.3. Wayland mejorado para soportar TiDB 7.4 Lanzamiento: Oficial Compatible con MySQL 8.0. Después de desconectar el receptor USB Logitech, el kernel de Linux falló. El maestro usó Scratch para frotar el simulador RISC-V y ejecutó con éxito el kernel de Linux. JetBrains lanzó Writerside, una herramienta para la creación de documentos técnicos.Autor: JD Retail Emily Liu
Fuente: Comunidad de desarrolladores de JD Cloud Indique la fuente al reimprimir