Autor: Yuan Yi
Knative es un marco de orquestación de aplicaciones sin servidor de código abierto basado en Kubernetes. Su objetivo es desarrollar estándares de orquestación de aplicaciones sin servidor multiplataforma y nativos de la nube. Las funciones principales de Knative incluyen elasticidad automática basada en solicitudes, reducción a 0, administración de múltiples versiones, liberación en escala de grises basada en tráfico, impulsada por eventos, etc.
La elasticidad es la capacidad central de Serverless. Entonces, ¿qué capacidades de elasticidad únicas ofrece Knative, como el marco de aplicaciones Serverless de código abierto más popular en la comunidad CNCF? Este artículo le brindará una comprensión profunda de la implementación flexible de Knative. (Nota: este artículo se basa en la versión Knative 1.8.0 para su análisis)
Knative proporciona KPA (Knative Pod Autoscaler) de implementación elástica automática basada en solicitudes y también admite HPA en K8. Además, Knative proporciona un mecanismo de expansión elástica flexible que puede expandir la implementación elástica según sus propias necesidades comerciales. Aquí también presentaremos la combinación con MSE para lograr una elasticidad precisa y la combinación con AHPA para lograr una predicción de elasticidad basada en solicitudes.
Primero, presentamos la flexibilidad nativa más atractiva de Knative: KPA.
KPA elástico automático basado en solicitudes
La elasticidad basada en la CPU o la memoria a veces no refleja completamente el uso real del negocio, pero según la cantidad de concurrencia o la cantidad de solicitudes procesadas por segundo (QPS/RPS), para los servicios web, puede reflejar más directamente el rendimiento del servicio Knative proporciona capacidades de resiliencia automática basadas en solicitudes. Para obtener el número actual de solicitudes de servicio, Knative Serving inyecta un contenedor proxy QUEUE (queue-proxy) en cada Pod, que es responsable de recopilar indicadores de concurrencia (concurrencia) o recuento de solicitudes (rps) del contenedor del usuario. Después de que Autoscaler obtenga estos indicadores con regularidad, ajustará la cantidad de Pods en la implementación de acuerdo con el algoritmo correspondiente para lograr la expansión y contracción automática en función de las solicitudes.
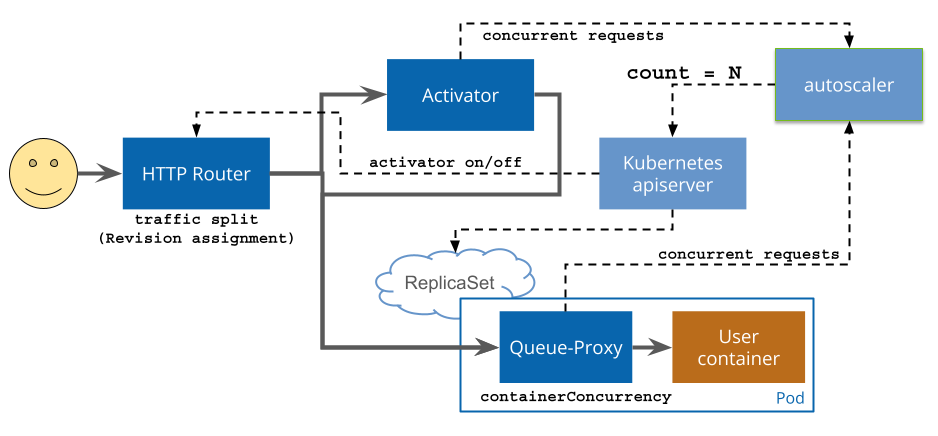
Fuente de la imagen: https://knative.dev/docs/serving/request-flow/
Algoritmo de elasticidad basado en el número de solicitudes.
Autoscaler realiza cálculos elásticos basados en el número promedio de solicitudes (o simultaneidad) de cada Pod. De forma predeterminada, Knative usa elasticidad automática según la cantidad de concurrencia, y la cantidad máxima predeterminada de Pods de concurrencia es 100. Además, Knative también proporciona un concepto llamado porcentaje de utilización objetivo, que se denomina utilización objetivo. El rango de valores es 0 ~ 1 y el valor predeterminado es: 0,7.
Tomando como ejemplo la elasticidad basada en la concurrencia, el número de Pods se calcula de la siguiente manera:
POD数=并发请求总数/(Pod最大并发数*目标使用率)
Por ejemplo, el número máximo de Pods simultáneos en el servicio se establece en 10. En este momento, si se reciben 100 solicitudes simultáneas y el uso objetivo se establece en 0,7, el Autoscaler creará 15 POD (100/(0,7*10 ) es aproximadamente igual a 15).
Mecanismo de implementación de reducción a 0
Cuando se utiliza KPA, cuando no hay solicitudes de tráfico, la cantidad de Pods se reducirá automáticamente a 0; cuando haya solicitudes, la cantidad de Pods se ampliará desde 0. Entonces, ¿cómo sucede esto en Knative? La respuesta es mediante el cambio de modo.
Knative define dos modos de acceso a solicitudes: Proxy y Serve. Proxy Como sugiere el nombre, modo proxy, es decir, la solicitud será reenviada por proxy a través del componente activador. El modo de servicio es un modo de solicitud directa, que solicita directamente desde la puerta de enlace al Pod sin pasar por el proxy activador. Como se muestra abajo:
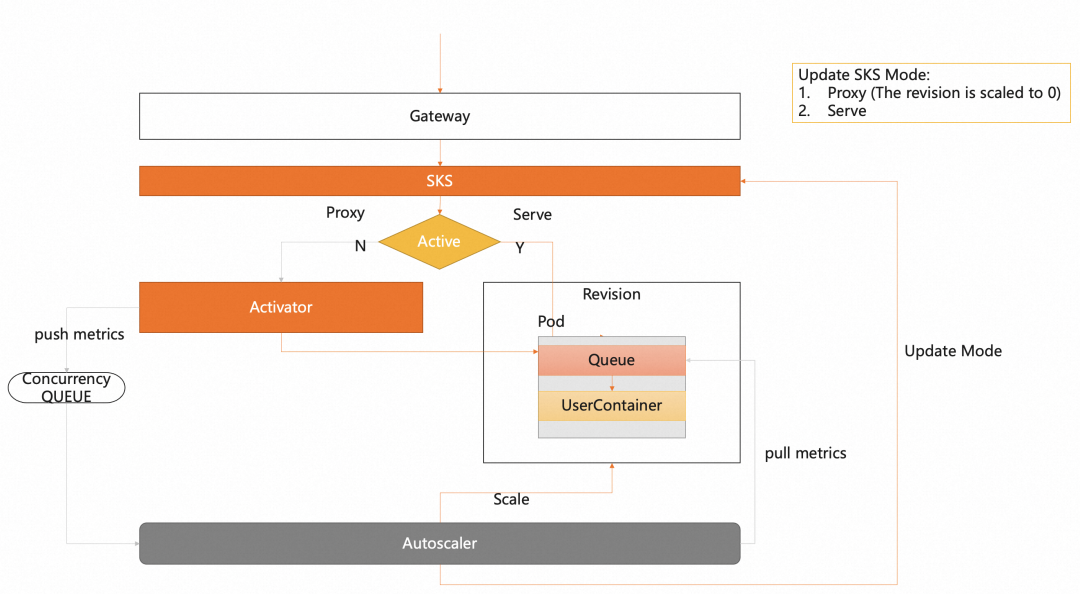
El cambio de modo lo realiza el componente del escalador automático. Cuando la solicitud es 0, el escalador automático cambiará el modo de solicitud al modo Proxy. En este momento, la solicitud se enviará al componente activador a través de la puerta de enlace. Después de recibir la solicitud, el activador pondrá la solicitud en la cola y presionará indicadores para notificar al escalador automático para la expansión. Cuando el activador detecte que el Pod está listo para ampliación, reenviará la solicitud. El escalador automático también determinará el Pod listo y cambiará el modo al modo Servir.
Hacer frente al tráfico intenso
Cómo hacer rebotar recursos rápidamente bajo tráfico repentino
KPA implica dos conceptos relacionados con la elasticidad: estable (modo estable) y pánico (modo de pánico). Con base en estos dos modos, podemos entender cómo KPA puede lograr una elasticidad refinada en función de las solicitudes.
Primero, el modo estable se basa en el período de ventana estable, que es de 60 segundos de forma predeterminada. Es decir, la cantidad promedio de Pods simultáneos se calcula dentro de un período de 60 segundos.
El modo de pánico se basa en el período de la ventana de pánico, que se calcula mediante el período de la ventana de estabilidad y los parámetros de porcentaje de la ventana de pánico. El valor de porcentaje de ventana de pánico es 0 ~ 1 y el valor predeterminado es 0,1. El método de cálculo del período de ventana de pánico es: período de ventana de pánico = período de ventana estable * porcentaje de ventana de pánico. El valor predeterminado es 6 segundos. Calcule el número promedio de Pods simultáneos en un período de 6 segundos.
KPA calculará la cantidad requerida de Pods en función de la cantidad promedio de Pods simultáneos en modo estable y modo de pánico.
Entonces, ¿qué valor se utiliza realmente para que la elasticidad surta efecto? Esto se juzgará en función de si la cantidad de Pods calculados en modo de pánico excede el umbral de pánico PanicThreshold. El umbral de pánico se calcula mediante porcentaje de umbral de pánico / 100. El parámetro porcentaje de umbral de pánico tiene como valor predeterminado 200, lo que significa que el umbral de pánico tiene como valor predeterminado 2. Cuando la cantidad de Pods calculada en modo pánico es mayor o igual a 2 veces la cantidad actual de Pods listos, la cantidad de Pods en modo pánico se usará para la validación elástica; de lo contrario, se usará la cantidad de Pods en modo estable.
Obviamente, el modo pánico está diseñado para hacer frente a situaciones de tráfico repentinas. En cuanto a la sensibilidad elástica, se puede ajustar a través de los parámetros configurables mencionados anteriormente.
Cómo evitar que Pod explote debido al tráfico repentino
La capacidad de solicitud de ráfaga (target-burst-capacity) se puede configurar en KPA para hacer frente al Pod que se ve abrumado por tráfico inesperado. Es decir, mediante el cálculo del valor de este parámetro, podemos ajustar si la solicitud cambia al modo Proxy, utilizando así el componente activador como búfer de solicitud. Si el número actual de pods listos * el número máximo de concurrencias - la capacidad de solicitud de ráfaga - el número de concurrencias calculadas en modo de pánico < 0, significa que el tráfico de ráfaga excede el umbral de capacidad, luego cambie al activador para el almacenamiento en búfer de solicitudes. Cuando el valor de la capacidad de solicitud de ráfaga es 0, el activador se cambiará solo cuando el Pod se reduzca a 0. Cuando es mayor que 0 y el porcentaje de objetivo de concurrencia del contenedor se establece en 100, las solicitudes siempre pasarán por el activador. -1 indica capacidad de ráfaga de solicitudes ilimitada. Las solicitudes siempre pasarán por el activador.
Algunos consejos para reducir los arranques en frío
Escalado retrasado
Para Pods con altos costos de inicio, el KPA se puede utilizar para reducir la frecuencia de expansión y contracción del Pod estableciendo el tiempo de reducción del retraso del Pod y la reducción del Pod en 0 período de retención.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/scale-down-delay: ""60s"
autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56
Reduzca la tasa de uso objetivo para calentar recursos
La configuración del uso del umbral objetivo se proporciona en Knative. Al reducir este valor, la cantidad de Pods que exceden el uso real requerido se puede expandir por adelantado y la capacidad se puede expandir antes de que la solicitud alcance el número concurrente objetivo, lo que indirectamente puede calentar los recursos. Por ejemplo, si containerConcurrency se establece en 10 y el valor de utilización objetivo se establece en 70 (porcentaje), Autoscaler creará un nuevo Pod cuando el número promedio de solicitudes simultáneas en todos los Pods existentes llegue a 7. Debido a que un Pod tarda una cierta cantidad de tiempo en estar listo, al reducir el valor de utilización objetivo, el Pod se puede expandir con anticipación, lo que reduce problemas como los retrasos en la respuesta causados por arranques en frío.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target-utilization-percentage: "70"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56
Configurar KPA
A través de la introducción anterior, comprendemos mejor el mecanismo de funcionamiento de Knative Pod Autoscaler. A continuación, presentaremos cómo configurar KPA. Knative proporciona dos formas de configurar KPA: modo global y modo de revisión.
modo global
El modo global puede modificar ConfigMap en K8: config-autoscaler. Para ver config-autoscaler, use el siguiente comando:
kubectl -n knative-serving get cm config-autoscaler
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "100"
container-concurrency-target-percentage: "70"
requests-per-second-target-default: "200"
target-burst-capacity: "211"
stable-window: "60s"
panic-window-percentage: "10.0"
panic-threshold-percentage: "200.0"
max-scale-up-rate: "1000.0"
max-scale-down-rate: "2.0"
enable-scale-to-zero: "true"
scale-to-zero-grace-period: "30s"
scale-to-zero-pod-retention-period: "0s"
pod-autoscaler-class: "kpa.autoscaling.knative.dev"
activator-capacity: "100.0"
initial-scale: "1"
allow-zero-initial-scale: "false"
min-scale: "0"
max-scale: "0"
scale-down-delay: "0s"
Descripción de parámetros:
| parámetro | ilustrar |
|---|---|
| contenedor-concurrencia-destino-predeterminado | El número máximo predeterminado de Pods simultáneos, el valor predeterminado es 100 |
| porcentaje-objetivo-de-concurrencia-de-contenedores | Uso objetivo de simultaneidad, 70 en realidad significa 0,7 |
| solicitudes-por-segundo-destino-predeterminado | Solicitudes predeterminadas por segundo (rps), valor predeterminado 200 |
| capacidad-de-ráfaga-objetivo | Capacidad de solicitud de ráfaga |
| ventana-establo | Ventana de estabilidad, predeterminada 60 s |
| porcentaje-de-ventana-de-pánico | Proporción de ventana de pánico, el valor predeterminado es 10, lo que significa que el período de ventana de pánico predeterminado es 6 segundos (60*0,1=6) |
| porcentaje-umbral-de-pánico | Relación de umbral de pánico, valor predeterminado 200 |
| tasa máxima de ampliación | La tasa máxima de expansión y contracción representa el número máximo de expansiones a la vez. El método de cálculo real es: math.Ceil (MaxScaleUpRate * readyPodsCount) |
| tasa de reducción de escala máxima | La tasa de escala máxima representa el número máximo de escalas a la vez. El método de cálculo real es: math.Floor (readyPodsCount / MaxScaleDownRate). El valor predeterminado 2 significa reducirse a la mitad cada vez. |
| habilitar escala a cero | Ya sea para comenzar a reducirse a 0, habilitado de forma predeterminada |
| período de gracia de escala a cero | El tiempo para reducirse elegantemente a 0, es decir, cuánto tiempo lleva retrasar la reducción a 0, el valor predeterminado es 30 segundos. |
| período de retención de pod de escala a cero | El pod se reduce a un período de retención de 0. Este parámetro es adecuado para situaciones en las que los costos de inicio del Pod son altos. |
| clase pod-autoscaler | Tipo de complemento elástico. Los complementos elásticos admitidos actualmente incluyen: kpa, hpa, ahpa y mpa (en el escenario de solicitud, admite la reducción a 0 con mse) |
| capacidad-activador | capacidad de solicitud del activador |
| escala inicial | Al crear una revisión, inicialice la cantidad de Pods para comenzar, el valor predeterminado es 1 |
| permitir-escala-inicial-cero | Si se permite que se inicialicen 0 pods al crear una revisión. El valor predeterminado es falso, lo que significa que no está permitido. |
| escala mínima | El número mínimo de Pods que se conservarán en el nivel de revisión. El valor predeterminado 0 significa que el valor mínimo puede ser 0 |
| escala máxima | La cantidad máxima de Pods que se pueden expandir en el nivel de revisión. El valor predeterminado 0 significa que no hay límite máximo de expansión |
| retraso de reducción de escala | Indica tiempo de escalado retrasado, el valor predeterminado 0 significa escalado inmediato |
Modo de versión de revisión
En Knative se pueden configurar indicadores de elasticidad para cada Revisión, algunos parámetros de configuración son los siguientes:
- Tipo de indicador
<!---->
-
- Anotaciones para cada indicador de revisión: autoscaling.knative.dev/metric
- Indicadores admitidos: "concurrencia", "rps", "cpu", "memoria" y otros indicadores personalizados
- Indicador predeterminado: "concurrencia"
<!---->
- umbral objetivo
<!---->
-
- autoescaling.knative.dev/target
- Valor predeterminado: "100"
<!---->
- El pod se reduce al período de retención 0
<!---->
-
- autoscaling.knative.dev/scale-to-zero-pod-retention-period
<!---->
- uso objetivo
<!---->
-
- autoscaling.knative.dev/target-utilization-percentage
El ejemplo de configuración es el siguiente:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "concurrency"
autoscaling.knative.dev/target: "50"
autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s"
autoscaling.knative.dev/target-utilization-percentage: "80"
Soporte para HPA
Para K8s HPA, Knative también proporciona soporte de configuración natural y puede usar capacidades de elasticidad automática basadas en CPU o memoria en Knative.
- Configuración flexible basada en CPU
<!---->
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/metric: "cpu"
- Configuración flexible basada en memoria
<!---->
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/metric: "memory"
Mayor resiliencia
Knative proporciona un mecanismo de complemento flexible (clase pod-autoscaler) que puede admitir diferentes estrategias elásticas. Los complementos elásticos actualmente admitidos por Alibaba Cloud Container Service Knative incluyen: kpa, hpa, expansión y contracción elástica precisa mpa y ahpa con capacidades predictivas.
grupo de recursos reservados
Además de las capacidades nativas de KPA, brindamos la posibilidad de reservar grupos de recursos. Esta función se puede aplicar en los siguientes escenarios:
- ECS se mezcla con ECI. Si queremos utilizar recursos ECS en circunstancias normales y utilizar ECI para tráfico en ráfagas, podemos lograrlo reservando grupos de recursos. Por ejemplo, si un solo Pod maneja 10 solicitudes simultáneas y la cantidad de Pods en el grupo de recursos reservado es 5, entonces, en circunstancias normales, los recursos de ECS no pueden manejar más de 50 solicitudes simultáneas. Si la cantidad de concurrencia excede 50, Knative ampliará la cantidad de nuevos Pods para satisfacer la demanda y los recursos recientemente ampliados utilizarán ECI.
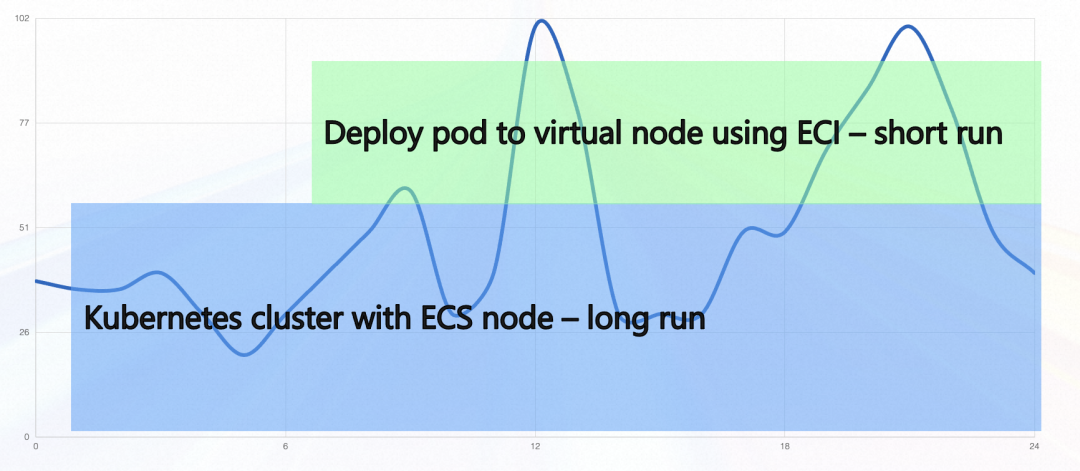
- Calentamiento de recursos. Para escenarios en los que se utiliza ECI por completo, el precalentamiento de recursos también se puede lograr reservando grupos de recursos. Cuando se utiliza una instancia reservada para reemplazar la instancia informática predeterminada durante los momentos de depresión del negocio, la instancia reservada se utiliza para proporcionar servicios cuando llega la primera solicitud, lo que también desencadenará la expansión de la instancia de especificación predeterminada. Una vez completada la expansión de la instancia de especificación predeterminada, todas las solicitudes nuevas se reenviarán a la especificación predeterminada. Al mismo tiempo, la instancia reservada no aceptará nuevas solicitudes y se desconectará después de que se procesen todas las solicitudes recibidas por la instancia reservada. . A través de este método de reemplazo continuo, se logra un equilibrio entre costo y eficiencia, es decir, se reduce el costo de las instancias residentes sin un tiempo de inicio en frío significativo.
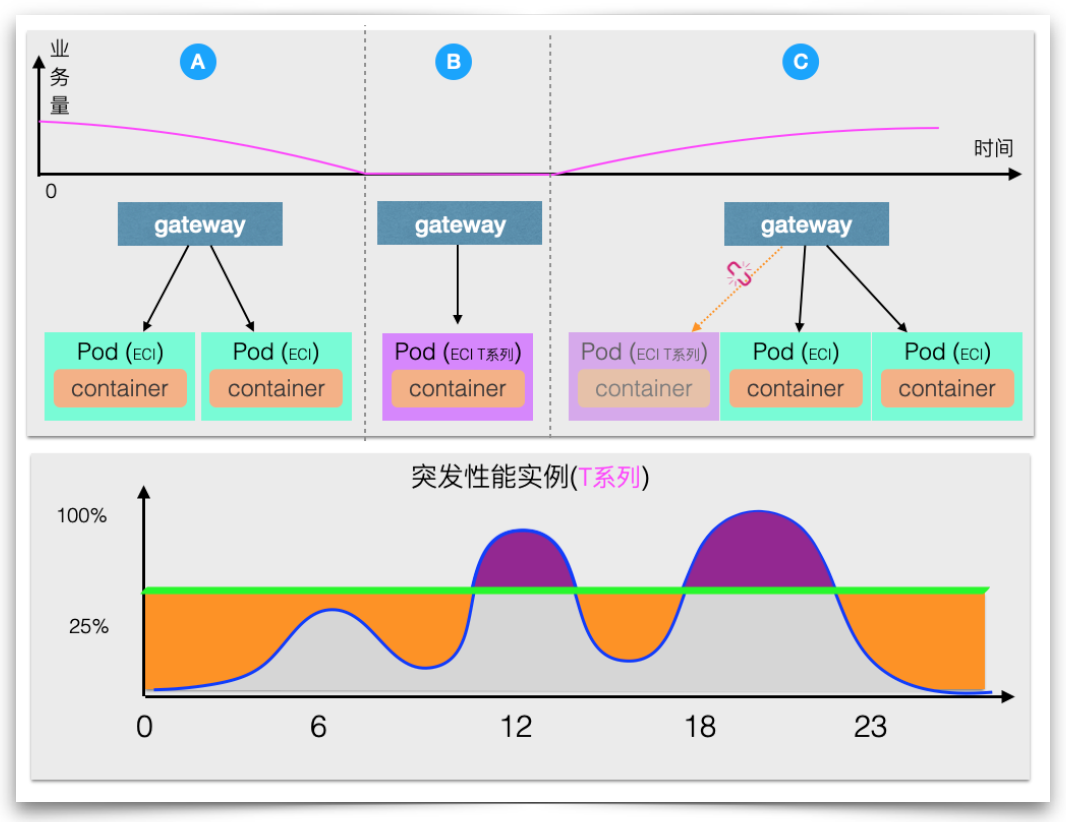
Expansión y contracción elástica precisa
La tasa de rendimiento de las solicitudes de procesamiento de un solo Pod es limitada. Si se reenvían varias solicitudes al mismo Pod, se producirá una excepción de sobrecarga en el lado del servidor. Por lo tanto, es necesario controlar con precisión la cantidad de procesamiento simultáneo de solicitudes de un solo Pod. . Especialmente en algunos escenarios AIGC, una sola solicitud ocupará muchos recursos de GPU y es necesario limitar estrictamente la cantidad de solicitudes simultáneas procesadas por cada Pod.
Knative se combina con la puerta de enlace nativa de la nube MSE para proporcionar una implementación de control elástico preciso basado en la concurrencia: el complemento elástico mpa.
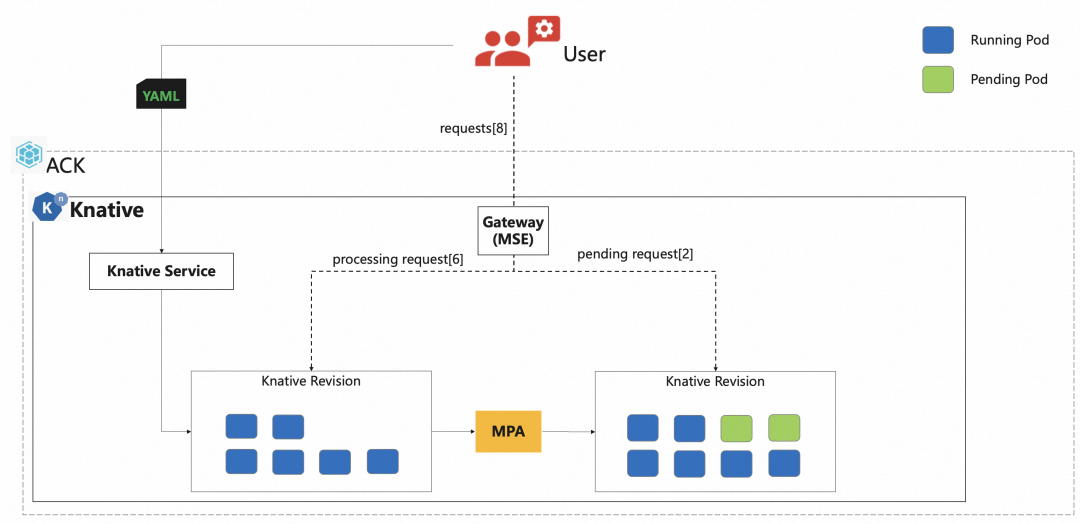
mpa obtendrá el número de concurrencia de la puerta de enlace MSE y calculará la cantidad requerida de Pods para la expansión y contracción, y la puerta de enlace MSE puede reenviar con precisión en función de las solicitudes.
El ejemplo de configuración es el siguiente:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: mpa.autoscaling.knative.dev
autoscaling.knative.dev/max-scale: '20'
spec:
containerConcurrency: 5
containers:
- image: registry-vpc.cn-beijing.aliyuncs.com/knative-sample/helloworld-go:73fbdd56
env:
- name: TARGET
value: "Knative"
Descripción de parámetros:
| parámetro | ilustrar |
|---|---|
| autoscaling.knative.dev/clase: mpa.autoscaling.knative.dev | mpa indica que el indicador MSE se utiliza para expansión y contracción, y admite una reducción a 0. |
| autoscaling.knative.dev/max-scale: '20' | El límite superior del número de Pods de expansión es 20. |
| contenedorConcurrencia: 5 | Indica que el número máximo de concurrencias que puede manejar un solo Pod es 5 |
Pronóstico elástico AHPA
El servicio de contenedores AHPA (Advanced Horizontal Pod Autoscaler) puede identificar automáticamente ciclos elásticos y predecir la capacidad en función de indicadores comerciales históricos para resolver el problema del retraso elástico.
Actualmente, Knative admite la capacidad elástica de AHPA (Advanced Horizontal Pod Autoscaler). Cuando las solicitudes son periódicas, los recursos se pueden precalentar mediante predicción elástica. En comparación con la reducción del umbral de precalentamiento de recursos, AHPA puede maximizar la utilización de recursos.
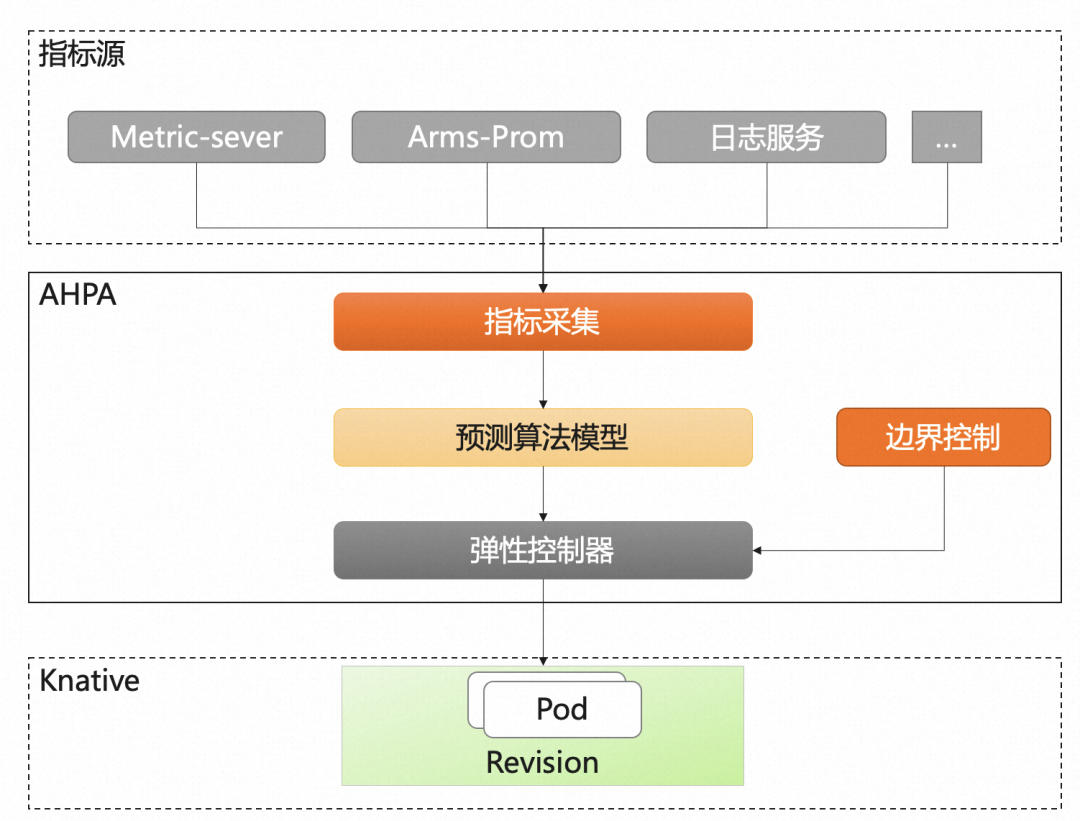
Además, dado que AHPA admite la configuración de indicadores personalizados, la combinación de Knative y AHPA puede lograr una elasticidad automática basada en la cola de mensajes y el retraso de respuesta rt.
El ejemplo de configuración del uso de AHPA basado en rps es el siguiente:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: autoscale-go
namespace: default
spec:
template:
metadata:
labels:
app: autoscale-go
annotations:
autoscaling.knative.dev/class: ahpa.autoscaling.knative.dev
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/metric: "rps"
autoscaling.knative.dev/minScale: "1"
autoscaling.knative.dev/maxScale: "30"
autoscaling.alibabacloud.com/scaleStrategy: "observer"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1
Descripción de parámetros:
| parámetro | ilustrar |
|---|---|
| autoscaling.knative.dev/clase: ahpa.autoscaling.knative.dev | Especifique el complemento elástico AHPA. |
| autoscaling.knative.dev/metric: "rps" | Configure el indicador AHPA. Actualmente admite concurrencia, rps y tiempo de respuesta rt. |
| autoscaling.knative.dev/target: "10" | Establezca el umbral del indicador AHPA. En este ejemplo, el umbral de rps es 10, lo que significa que el número máximo de solicitudes por segundo procesadas por un solo Pod es 10. |
| autoscaling.knative.dev/minScale: "1" | Establezca el número mínimo de instancias de política elástica en 1. |
| autoscaling.knative.dev/maxScale: "30" | Establezca el número máximo de instancias de política elástica en 30. |
| autoscaling.alibabacloud.com/scaleStrategy: "observador" | Establezca el modo de escala automática. El valor predeterminado es observador. observador: Indica que solo observa, pero no realiza acciones de escalado reales. De esta manera podrá observar si AHPA está funcionando como se esperaba. Dado que la predicción requiere 7 días de datos históricos, el modo de creación de servicios predeterminado es el modo observador. automático: indica que AHPA es responsable de la expansión y reducción. Los indicadores y umbrales de AHPA se ingresan a AHPA y, en última instancia, AHPA decide si entran en vigencia. |
resumen
Este artículo comienza con la implementación elástica típica KPA de Knative y la presenta, incluido cómo implementar la elasticidad automática basada en solicitudes, reducir a 0, hacer frente al tráfico repentino y nuestra expansión y mejora de las funciones de elasticidad de Knative, incluidos los grupos de recursos reservados, precisión. elasticidad y predicción de elasticidad.capacidad.
Aquí también ofrecemos una actividad de experiencia usando Knative en la escena AIGC. Bienvenido a participar: ¡ven y desbloquea la imagen AI exclusiva de tu linda mascota! Hora del evento: 24/08/2023-24/09.
El autor del marco de código abierto NanUI pasó a vender acero y el proyecto fue suspendido. La primera lista gratuita en la App Store de Apple es el software pornográfico TypeScript. Acaba de hacerse popular, ¿por qué los grandes empiezan a abandonarlo? Lista de octubre de TIOBE: Java tiene la mayor caída, C# se acerca Java Rust 1.73.0 lanzado Un hombre fue alentado por su novia AI a asesinar a la Reina de Inglaterra y fue sentenciado a nueve años de prisión Qt 6.6 publicado oficialmente Reuters: RISC-V La tecnología se convierte en la clave de la guerra tecnológica entre China y Estados Unidos. Nuevo campo de batalla RISC-V: no controlado por ninguna empresa o país, Lenovo planea lanzar una PC con Android.¡Ven y desbloquea la imagen AI exclusiva de tu linda mascota!