1. Introducción a ZGC
1.1 Introducción
ZGC es un recolector de basura de baja latencia y es la vanguardia de la tecnología de recolección de basura de Java. Si comprende ZGC, puede decir que comprende la tecnología de recolección de basura más avanzada de Java.
ZGC ha estado en constante desarrollo desde su introducción como característica experimental en JDK11.
A partir de JDK14, ZGC comienza a admitir Windows.
En JDK15, ZGC ya no es una característica experimental y puede ponerse oficialmente en producción.
En la última biblioteca de código abierto JDK, apareció el código ZGC recopilado por generaciones y se espera que se publique oficialmente en un futuro cercano. Creo que el rendimiento de ZGC será aún mejor para entonces.
Figura 1 ZGC recopilado por generaciones
Como se muestra arriba, JDK21 ya tiene la característica de ZGC generacional.
1.2 Características de ZGC
1.3 Fase de recolección de basura
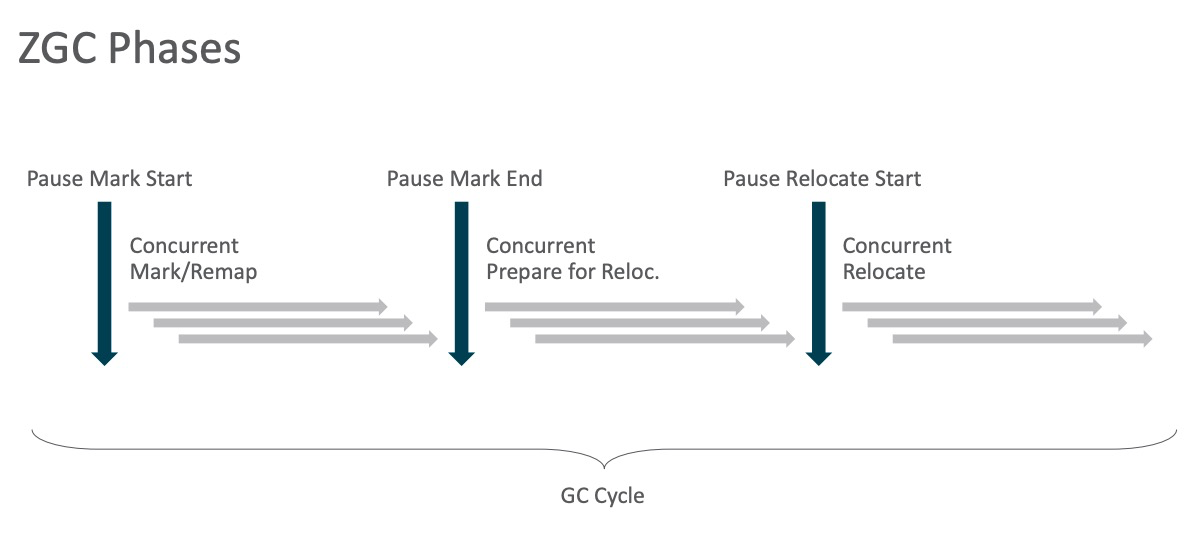
Figura 2 Proceso de operación ZGC
Como se muestra en la figura anterior, existen principalmente las siguientes etapas: marcado inicial, marcado concurrente / reasignación concurrente, reasignación preliminar concurrente, reasignación inicial y reasignación concurrente. El análisis principal esta vez es la parte "marcado concurrente / reasignación concurrente" de el código fuente.
1.4 Lea el código fuente con preguntas en mente
2. Código fuente
2.1 Entrada
La entrada del código fuente de todo el ZGC es la función ZDriver::gc
void ZDriver::gc(const ZDriverRequest& request) {
ZDriverGCScope scope(request);
// Phase 1: Pause Mark Start
pause_mark_start();
// Phase 2: Concurrent Mark
concurrent(mark);
// Phase 3: Pause Mark End
while (!pause_mark_end()) {
// Phase 3.5: Concurrent Mark Continue
concurrent(mark_continue);
}
// Phase 4: Concurrent Mark Free
concurrent(mark_free);
// Phase 5: Concurrent Process Non-Strong References
concurrent(process_non_strong_references);
// Phase 6: Concurrent Reset Relocation Set
concurrent(reset_relocation_set);
// Phase 7: Pause Verify
pause_verify();
// Phase 8: Concurrent Select Relocation Set
concurrent(select_relocation_set);
// Phase 9: Pause Relocate Start
pause_relocate_start();
// Phase 10: Concurrent Relocate
concurrent(relocate);
}Entre ellos, concurrent() es una definición de macro.
// Macro to execute a termination check after a concurrent phase. Note
// that it's important that the termination check comes after the call
// to the function f, since we can't abort between pause_relocate_start()
// and concurrent_relocate(). We need to let concurrent_relocate() call
// abort_page() on the remaining entries in the relocation set.
#define concurrent(f) \
do { \
concurrent_##f(); \
if (should_terminate()) { \
return; \
} \
} while (false)Entonces podemos saber que la función de marcado concurrente es concurrent_mark
void ZDriver::concurrent_mark() {
ZStatTimer timer(ZPhaseConcurrentMark);
ZBreakpoint::at_after_marking_started();
//开始对整个堆进行标记
ZHeap::heap()->mark(true /* initial */);
ZBreakpoint::at_before_marking_completed();
}2.2 Proceso de marcado concurrente
2.2.1 Marcado Concurrente
Siguiente vistazo a ZHeap::heap()->mark
void ZHeap::mark(bool initial) {
_mark.mark(initial);
}más abajo
void ZMark::mark(bool initial) {
if (initial) {
ZMarkRootsTask task(this);
_workers->run(&task);
}
ZMarkTask task(this);
_workers->run(&task);
}Aquí se utiliza un marco de tareas y la lógica de ejecución de la tarea está en ZMarkTask.
class ZMarkTask : public ZTask {
private:
ZMark* const _mark;
const uint64_t _timeout_in_micros;
public:
ZMarkTask(ZMark* mark, uint64_t timeout_in_micros = 0) :
ZTask("ZMarkTask"),
_mark(mark),
_timeout_in_micros(timeout_in_micros) {
_mark->prepare_work();
}
~ZMarkTask() {
_mark->finish_work();
}
virtual void work() {
_mark->work(_timeout_in_micros);
}
};La función específica ejecutada aquí es trabajo, mira down_mark->work
void ZMark::work(uint64_t timeout_in_micros) {
ZMarkCache cache(_stripes.nstripes());
ZMarkStripe* const stripe = _stripes.stripe_for_worker(_nworkers, ZThread::worker_id());
ZMarkThreadLocalStacks* const stacks = ZThreadLocalData::stacks(Thread::current());
if (timeout_in_micros == 0) {
work_without_timeout(&cache, stripe, stacks);
} else {
work_with_timeout(&cache, stripe, stacks, timeout_in_micros);
}
// Flush and publish stacks
stacks->flush(&_allocator, &_stripes);
// Free remaining stacks
stacks->free(&_allocator);
}Stripe aquí es una tira marcada y stacks es una pila local de subprocesos.
Mire hacia abajo el método work_with_timeout
void ZMark::work_with_timeout(ZMarkCache* cache, ZMarkStripe* stripe, ZMarkThreadLocalStacks* stacks, uint64_t timeout_in_micros) {
ZStatTimer timer(ZSubPhaseMarkTryComplete);
ZMarkTimeout timeout(timeout_in_micros);
for (;;) {
if (!drain(stripe, stacks, cache, &timeout)) {
// Timed out
break;
}
if (try_steal(stripe, stacks)) {
// Stole work
continue;
}
// Terminate
break;
}
}Puede ver que hay un bucle aquí, que seguirá obteniendo datos de la tira marcada hasta que termine o se acabe el tiempo. Este es el bucle principal del marcado tricolor ZGC. A continuación, observe la función de drenaje. Drenar significa vaciar. Aquí, el puntero se toma de la pila y se marca hasta que la pila esté vacía.
template <typename T>
bool ZMark::drain(ZMarkStripe* stripe, ZMarkThreadLocalStacks* stacks, ZMarkCache* cache, T* timeout) {
ZMarkStackEntry entry;
// Drain stripe stacks
while (stacks->pop(&_allocator, &_stripes, stripe, entry)) {
//标记和跟随
mark_and_follow(cache, entry);
// Check timeout
if (timeout->has_expired()) {
// Timeout
return false;
}
}
// Success
return !timeout->has_expired();
}Puede ver que los datos se obtienen de la pila y luego se marcan y marcan de forma recursiva hasta que se vacía la pila.
Dado que hay un lugar para tomar datos de la pila, debe haber un lugar para colocar datos en la pila. Primero escribamos este punto, llamado "punto de registro 1".
Luego mira hacia abajo a la función mark_and_follow
void ZMark::mark_and_follow(ZMarkCache* cache, ZMarkStackEntry entry) {
// Decode flags
const bool finalizable = entry.finalizable();
const bool partial_array = entry.partial_array();
if (partial_array) {
follow_partial_array(entry, finalizable);
return;
}
// Decode object address and additional flags
const uintptr_t addr = entry.object_address();
const bool mark = entry.mark();
bool inc_live = entry.inc_live();
const bool follow = entry.follow();
ZPage* const page = _page_table->get(addr);
assert(page->is_relocatable(), "Invalid page state");
// Mark
//标记对象
if (mark && !page->mark_object(addr, finalizable, inc_live)) {
// Already marked
return;
}
// Increment live
if (inc_live) {
// Update live objects/bytes for page. We use the aligned object
// size since that is the actual number of bytes used on the page
// and alignment paddings can never be reclaimed.
const size_t size = ZUtils::object_size(addr);
const size_t aligned_size = align_up(size, page->object_alignment());
cache->inc_live(page, aligned_size);
}
// Follow
if (follow) {
if (is_array(addr)) {
//递归处理数组
follow_array_object(objArrayOop(ZOop::from_address(addr)), finalizable);
} else {
//递归处理对象
follow_object(ZOop::from_address(addr), finalizable);
}
}
}Hay dos funciones para mirar aquí. Veamos primero página->mark_object y luego follow_object. En cuanto a follow_array_object, es similar a follow_object, por lo que no lo presentaremos en detalle.
página->mark_object código fuente es el siguiente
inline bool ZPage::mark_object(uintptr_t addr, bool finalizable, bool& inc_live) {
assert(ZAddress::is_marked(addr), "Invalid address");
assert(is_relocatable(), "Invalid page state");
assert(is_in(addr), "Invalid address");
// Set mark bit
const size_t index = ((ZAddress::offset(addr) - start()) >> object_alignment_shift()) * 2;
return _livemap.set(index, finalizable, inc_live);
}Puede ver que aquí se utiliza un mapa para almacenar la información finalizable e inc_live (nueva en vivo) de todas las direcciones de objetos.
const size_t index = ((ZAddress::offset(addr) - start()) >> object_alignment_shift()) * 2;
Según este código, el tamaño del mapa en vivo es aproximadamente un tercio del tamaño de alineación del objeto de todo el montón y luego se multiplica por 2. La información almacenada en este mapa es muy importante: en ZGC, la información de este mapa juzga si una dirección ha sido marcada y si un objeto está vivo.
Vuelva al paso anterior y continúe mirando la función follow_object
void ZMark::follow_object(oop obj, bool finalizable) {
if (finalizable) {
ZMarkBarrierOopClosure<true /* finalizable */> cl;
obj->oop_iterate(&cl);
} else {
ZMarkBarrierOopClosure<false /* finalizable */> cl;
obj->oop_iterate(&cl);
}
}Aquí hay dos ramas basadas en finalizable. Mirando el nombre de oop_iterate, podemos adivinar lo que hace, que es iterar los punteros en el objeto, pero después de todo es una suposición. Los detalles dependen de la verificación del código.
ZMarkBarrierOopClosure Este nombre significa barrera, ya llegamos a la puerta de la pregunta 3 al principio y estamos a solo un paso de ella. Antes de entrar por la puerta de la barrera de lectura, tenemos que mover una gran piedra que bloquea la puerta ¿Cómo se conecta el método oop_iterate a ZMarkBarrierOopClosure?
2.2.2 Recorrido iterativo de objetos
Esta sección analizará la lógica interna de oop_iterate. Este es un proceso de rama. Si aún no desea conocerlo, puede omitirlo e ir directamente a la siguiente sección 2.2.3 Barrera de lectura.
Advertencia: Agárrate a los pasamanos, ¡el coche empieza a acelerar debajo!
Primero registre el tipo cl ZMarkBarrierOopClosure, lo registramos como "punto de registro 2".
Ingrese la función oop_iterate
template <typename OopClosureType>
void oopDesc::oop_iterate(OopClosureType* cl) {
OopIteratorClosureDispatch::oop_oop_iterate(cl, this, klass());
}más abajo
template <typename OopClosureType>
void OopIteratorClosureDispatch::oop_oop_iterate(OopClosureType* cl, oop obj, Klass* klass, MemRegion mr) {
OopOopIterateBoundedDispatch<OopClosureType>::function(klass)(cl, obj, klass, mr);
}más abajo
static FunctionType function(Klass* klass) {
return _table._function[klass->id()];
}El método de función está en una clase, _table es la instancia de objeto de esta clase, _function es una matriz, veamos cómo _function inicializa el valor.
public:
FunctionType _function[KLASS_ID_COUNT];
Table(){
set_init_function<InstanceKlass>();
set_init_function<InstanceRefKlass>();
set_init_function<InstanceMirrorKlass>();
set_init_function<InstanceClassLoaderKlass>();
set_init_function<ObjArrayKlass>();
set_init_function<TypeArrayKlass>();
}método de construcción de tablas y definición de función
Aquí hay varios objetos Klass, solo miramos el primero. Registremos temporalmente InstanceKlass como "punto de registro 3" y luego miremos set_init_function.
template <typename KlassType>
void set_init_function() {
_function[KlassType::ID] = &init<KlassType>;
}Mira hacia abajo a la función de inicio.
template <typename KlassType>
static void init(OopClosureType* cl, oop obj, Klass* k, MemRegion mr) {
OopOopIterateBoundedDispatch<OopClosureType>::_table.set_resolve_function_and_execute<KlassType>(cl, obj, k, mr);
}continuar
template <typename KlassType>
void set_resolve_function_and_execute(OopClosureType* cl, oop obj, Klass* k, MemRegion mr) {
set_resolve_function<KlassType>();
_function[KlassType::ID](cl, obj, k, mr);
}Continuar siguiendo set_resolve_function
template <typename KlassType>
void set_resolve_function() {
if (UseCompressedOops) {
_function[KlassType::ID] = &oop_oop_iterate_bounded<KlassType, narrowOop>;
} else {
_function[KlassType::ID] = &oop_oop_iterate_bounded<KlassType, oop>;
}
}Puede ver que hay UseCompressedOops aquí ¿ZGC admite punteros comprimidos? Los estudiantes interesados pueden estudiarlo en profundidad.
Mira hacia abajo en oop_oop_iterate_bounded
template <typename KlassType, typename T>
static void oop_oop_iterate_bounded(OopClosureType* cl, oop obj, Klass* k, MemRegion mr) {
((KlassType*)k)->KlassType::template oop_oop_iterate_bounded<T>(obj, cl, mr);
}Aquí puedes ver que se llama a la función oop_oop_iterate_bounded de KlassType. ¿Qué es KlassType? Es un tipo genérico, y uno de sus tipos reales es el InstanceKlass del punto de registro 3.
En la JVM, existe una clase Java común como modelo Klass de tipo InstanceKlass.
Lo siguiente no pertenece al código fuente de ZGC, por supuesto, sigue siendo el código fuente de jvm.
Ingrese la función oop_oop_iterate_bounded de InstanceKlass
template <typename T, class OopClosureType>
ALWAYSINLINE void InstanceKlass::oop_oop_iterate_bounded(oop obj, OopClosureType* closure, MemRegion mr) {
if (Devirtualizer::do_metadata(closure)) {
if (mr.contains(obj)) {
Devirtualizer::do_klass(closure, this);
}
}
oop_oop_iterate_oop_maps_bounded<T>(obj, closure, mr);
}abajo
template <typename T, class OopClosureType>
ALWAYSINLINE void InstanceKlass::oop_oop_iterate_oop_maps_bounded(oop obj, OopClosureType* closure, MemRegion mr) {
//非静态成员变量块起始位置
OopMapBlock* map = start_of_nonstatic_oop_maps();
//非静态成员变量块结束位置
OopMapBlock* const end_map = map + nonstatic_oop_map_count();
//对非静态成员变量块进行遍历
for (;map < end_map; ++map) {
oop_oop_iterate_oop_map_bounded<T>(map, obj, closure, mr);
}
}Puede ver que aquí se recorre iterativamente el bloque de variables miembro no estáticas de un objeto. continuar hacia abajo
template <typename T, class OopClosureType>
ALWAYSINLINE void InstanceKlass::oop_oop_iterate_oop_map_bounded(OopMapBlock* map, oop obj, OopClosureType* closure, MemRegion mr) {
T* p = (T*)obj->obj_field_addr<T>(map->offset());
T* end = p + map->count();
T* const l = (T*)mr.start();
T* const h = (T*)mr.end();
assert(mask_bits((intptr_t)l, sizeof(T)-1) == 0 &&
mask_bits((intptr_t)h, sizeof(T)-1) == 0,
"bounded region must be properly aligned");
if (p < l) {
p = l;
}
if (end > h) {
end = h;
}
for (;p < end; ++p) {
Devirtualizer::do_oop(closure, p);
}
}Aquí continuamos atravesando las variables miembro no estáticas de un objeto. Continúe mirando Devirtualizer::do_oop
template <typename OopClosureType, typename T>
inline void Devirtualizer::do_oop(OopClosureType* closure, T* p) {
call_do_oop<T>(&OopClosureType::do_oop, &OopClosure::do_oop, closure, p);
}continuar
template <typename T, typename Receiver, typename Base, typename OopClosureType>
static typename EnableIf<IsSame<Receiver, Base>::value, void>::type
call_do_oop(void (Receiver::*)(T*), void (Base::*)(T*), OopClosureType* closure, T* p) {
closure->do_oop(p);
}Continúa, pero deja de moverte. OopClosureType es un tipo de plantilla. ¿Cuál es su tipo real? Volviendo capa por capa, encontramos que era la barrera de lectura ZMarkBarrierOopClosure en el punto de registro 2, lo que nos devolvió al proceso principal de ZGC.
2.2.3 Leer barrera
Al ingresar a ZMarkBarrierOopClosure, como se puede ver en la sección anterior, el parámetro de entrada p de esta función es el puntero de la variable miembro no estática del objeto a marcar.
template <bool finalizable>
class ZMarkBarrierOopClosure : public ClaimMetadataVisitingOopIterateClosure {
public:
ZMarkBarrierOopClosure() :
ClaimMetadataVisitingOopIterateClosure(finalizable
? ClassLoaderData::_claim_finalizable
: ClassLoaderData::_claim_strong,
finalizable
? NULL
: ZHeap::heap()->reference_discoverer()) {}
virtual void do_oop(oop* p) {
ZBarrier::mark_barrier_on_oop_field(p, finalizable);
}
virtual void do_oop(narrowOop* p) {
ShouldNotReachHere();
}
};Continúe mirando mark_barrier_on_oop_field
//
// Mark barrier
//
inline void ZBarrier::mark_barrier_on_oop_field(volatile oop* p, bool finalizable) {
const oop o = Atomic::load(p);
if (finalizable) {
barrier<is_marked_or_null_fast_path, mark_barrier_on_finalizable_oop_slow_path>(p, o);
} else {
const uintptr_t addr = ZOop::to_address(o);
if (ZAddress::is_good(addr)) {
// Mark through good oop
mark_barrier_on_oop_slow_path(addr);
} else {
// Mark through bad oop
barrier<is_good_or_null_fast_path, mark_barrier_on_oop_slow_path>(p, o);
}
}
}Hay tres ramas aquí. No veamos primero el finalizable. Hay dos ramas según si el puntero es bueno o malo. Ambas ramas eventualmente llaman al método de procesamiento de ruta lenta mark_barrier_on_oop_slow_path.
Miremos directamente a la segunda rama a continuación.
template <ZBarrierFastPath fast_path, ZBarrierSlowPath slow_path>
inline oop ZBarrier::barrier(volatile oop* p, oop o) {
const uintptr_t addr = ZOop::to_address(o);
// Fast path
if (fast_path(addr)) {
return ZOop::from_address(addr);
}
// Slow path
const uintptr_t good_addr = slow_path(addr);
if (p != NULL) {
//指针自愈
self_heal<fast_path>(p, addr, good_addr);
}
return ZOop::from_address(good_addr);
}Este es el código lógico central de la barrera de lectura, aquí también vemos el puntero de autocuración.
Como se puede ver en este código, primero se realiza la verificación de la ruta rápida. Si fast_path (addr) devuelve verdadero, se devuelve directamente el objeto oop correspondiente a addr. Si la verificación de ruta rápida falla, se realiza una verificación de ruta lenta, se pasa addr a la función slow_path y el valor de retorno se almacena en la variable good_addr. Si el puntero entrante p no es nulo, llame a self_heal
Slow_path aquí es en realidad la función mark_barrier_on_oop_slow_path.
Aquí analizamos principalmente dos funciones, el procesamiento de ruta lento y la autorreparación del puntero. El proceso de procesamiento de ruta lento es relativamente largo, así que veamos primero la autorreparación del puntero.
template <ZBarrierFastPath fast_path>
inline void ZBarrier::self_heal(volatile oop* p, uintptr_t addr, uintptr_t heal_addr) {
if (heal_addr == 0) {
// Never heal with null since it interacts badly with reference processing.
// A mutator clearing an oop would be similar to calling Reference.clear(),
// which would make the reference non-discoverable or silently dropped
// by the reference processor.
return;
}
assert(!fast_path(addr), "Invalid self heal");
assert(fast_path(heal_addr), "Invalid self heal");
for (;;) {
// Heal
const uintptr_t prev_addr = Atomic::cmpxchg((volatile uintptr_t*)p, addr, heal_addr);
if (prev_addr == addr) {
// Success
return;
}
if (fast_path(prev_addr)) {
// Must not self heal
return;
}
// The oop location was healed by another barrier, but still needs upgrading.
// Re-apply healing to make sure the oop is not left with weaker (remapped or
// finalizable) metadata bits than what this barrier tried to apply.
assert(ZAddress::offset(prev_addr) == ZAddress::offset(heal_addr), "Invalid offset");
addr = prev_addr;
}
}Esto es relativamente simple, similar a la operación cas de Java, que cambia el puntero incorrecto por un puntero bueno y luego ejecuta la ruta rápida.
El puntero bueno lo devuelve la ruta lenta ejecutada anteriormente.
Siguiente mirada al camino lento.
//
// Mark barrier
//
uintptr_t ZBarrier::mark_barrier_on_oop_slow_path(uintptr_t addr) {
assert(during_mark(), "Invalid phase");
assert(ZThread::is_worker(), "Invalid thread");
// Mark
return mark<GCThread, Follow, Strong, Overflow>(addr);
}Aquí se vuelve a marcar el puntero que entra en la barrera de lectura.
En este punto, la lógica principal de la barrera de lectura realmente ha terminado. La siguiente es la lógica de marcado activada por la barrera de lectura.
2.2.4 Lógica de marcado activada por barrera de lectura
continuar
template <bool gc_thread, bool follow, bool finalizable, bool publish>
uintptr_t ZBarrier::mark(uintptr_t addr) {
uintptr_t good_addr;
if (ZAddress::is_marked(addr)) {
// Already marked, but try to mark though anyway
good_addr = ZAddress::good(addr);
} else if (ZAddress::is_remapped(addr)) {
// Already remapped, but also needs to be marked
good_addr = ZAddress::good(addr);
} else {
// Needs to be both remapped and marked
good_addr = remap(addr);
}
// Mark
if (should_mark_through<finalizable>(addr)) {
ZHeap::heap()->mark_object<gc_thread, follow, finalizable, publish>(good_addr);
}
if (finalizable) {
// Make the oop finalizable marked/good, instead of normal marked/good.
// This is needed because an object might first becomes finalizable
// marked by the GC, and then loaded by a mutator thread. In this case,
// the mutator thread must be able to tell that the object needs to be
// strongly marked. The finalizable bit in the oop exists to make sure
// that a load of a finalizable marked oop will fall into the barrier
// slow path so that we can mark the object as strongly reachable.
return ZAddress::finalizable_good(good_addr);
}
return good_addr;
}Las tres funciones a seguir aquí son ZAddress::good, remap y ZHeap::heap()->mark_object.
ZHeap::heap()->mark_object marca el objeto en el montón.
Veamos primero la lógica de ZAddress::good
inline uintptr_t ZAddress::offset(uintptr_t value) {
return value & ZAddressOffsetMask;
}
inline uintptr_t ZAddress::good(uintptr_t value) {
return offset(value) | ZAddressGoodMask;
}Se puede ver que solo se cambia el bit de marca del puntero, lo cual es relativamente simple y consistente con nuestra comprensión del proceso ZGC antes de leer el código.
2.2.5 Reasignación
Continuando con el método de reasignación de reasignación, aquí encontramos la pregunta inicial 5 [Proceso de reasignación concurrente en marcado concurrente de ZGC]
uintptr_t ZBarrier::remap(uintptr_t addr) {
assert(!ZAddress::is_good(addr), "Should not be good");
assert(!ZAddress::is_weak_good(addr), "Should not be weak good");
return ZHeap::heap()->remap_object(addr);
}continuar
inline uintptr_t ZHeap::relocate_object(uintptr_t addr) {
assert(ZGlobalPhase == ZPhaseRelocate, "Relocate not allowed");
ZForwarding* const forwarding = _forwarding_table.get(addr);
if (forwarding == NULL) {
// Not forwarding
return ZAddress::good(addr);
}
// Relocate object
return _relocate.relocate_object(forwarding, ZAddress::good(addr));
}Puede ver que la tabla de reenvío se verifica primero. Si la tabla de reenvío no existe, se devolverá un buen puntero directamente. Si existe, se realizará la operación de redistribución. El siguiente paso es la lógica de la redistribución. Este artículo analizará No lo explico en detalle. Se discutirá en el artículo sobre redistribución en el futuro. Introducción detallada.
2.2.6 Volver al proceso de marcado de barrera de lectura
Luego, regrese al comienzo de 2.2.4 y continúe mirando ZHeap::heap()->mark_object
template <bool gc_thread, bool follow, bool finalizable, bool publish>
inline void ZHeap::mark_object(uintptr_t addr) {
assert(ZGlobalPhase == ZPhaseMark, "Mark not allowed");
_mark.mark_object<gc_thread, follow, finalizable, publish>(addr);
}continuar
template <bool gc_thread, bool follow, bool finalizable, bool publish>
inline void ZMark::mark_object(uintptr_t addr) {
assert(ZAddress::is_marked(addr), "Should be marked");
ZPage* const page = _page_table->get(addr);
if (page->is_allocating()) {
// Already implicitly marked
return;
}
const bool mark_before_push = gc_thread;
bool inc_live = false;
if (mark_before_push) {
// Try mark object
if (!page->mark_object(addr, finalizable, inc_live)) {
// Already marked
return;
}
} else {
// Don't push if already marked
if (page->is_object_marked<finalizable>(addr)) {
// Already marked
return;
}
}
// Push
ZMarkThreadLocalStacks* const stacks = ZThreadLocalData::stacks(Thread::current());
ZMarkStripe* const stripe = _stripes.stripe_for_addr(addr);
ZMarkStackEntry entry(addr, !mark_before_push, inc_live, follow, finalizable);
stacks->push(&_allocator, &_stripes, stripe, entry, publish);
}Aquí hay dos lógicas importantes: una es que los elementos marcados ya no se empujan y la segunda es que los elementos no marcados se empujan a la pila.
Recuerde el "punto de registro 1" anterior, aquí es donde el puntero empujado está en la pila y el puntero empujado se quitará en el siguiente ciclo de marcado.
En este punto, el proceso principal de marcado de tres colores ZGC se conecta de principio a fin y las flores están terminadas.
3. Revisión del problema
3.1 Preguntas iniciales
De las cinco preguntas anteriores, 1, 2, 4 y 5 ya se plantearon durante el proceso de análisis del código fuente, y la pregunta 3 requiere observar todo el proceso.
3.2 ¿Cómo evita ZGC las ofertas perdidas utilizando barreras de solo lectura?
3.2.1 ¿En qué circunstancias se rechazará la oferta?
Cuando concurran simultáneamente las dos situaciones siguientes:
3.2.2 ¿Cómo evitarlo?
Destruyendo la condición 1, esta es la solución de actualización incremental (Actualización incremental).
Destruyendo la condición 2, esta es la solución de instantánea original (Instantánea al principio, SAT B).
ZGC utiliza una solución de actualización incremental. Sin embargo, ¿no es la actualización incremental una nueva incorporación? Debería ser una barrera de escritura. ¿Cómo lograr una barrera de lectura?
De hecho, cuando se agrega una nueva referencia, la referencia debe haber sido leída antes desde algún lugar, por lo que la operación de lectura activa la barrera de lectura. En el código fuente anterior sabemos que hay un proceso de marcado en la barrera de lectura ZGC y automáticamente se devolverá un buen puntero, es decir, no hay objetos blancos en los punteros devueltos a través de la barrera de lectura, lo que fundamentalmente evita la condición 1.
4. Amplíe su pensamiento
La marca ZGC está en el puntero, no en el objeto. Cuando se recicla una región, para un objeto en esta región, es imposible obtener el puntero de otros objetos que apuntan a este objeto. Entonces, ¿cómo se puede saber si este objeto es? ¿vivo?
Esta pregunta requiere que conectemos el código de la fase de marcado y la fase de redistribución para obtener la respuesta.
5. Fin
Eso es todo para el análisis del código fuente del proceso de marcado concurrente de ZGC. Si lo encuentra inspirador o útil, dale me gusta y apóyalo ~
El autor del marco de código abierto NanUI pasó a vender acero y el proyecto fue suspendido. La primera lista gratuita en la App Store de Apple es el software pornográfico TypeScript. Acaba de hacerse popular, ¿por qué los grandes empiezan a abandonarlo? Lista de octubre de TIOBE: Java tiene la mayor caída, C# se acerca Java Rust 1.73.0 lanzado Un hombre fue alentado por su novia AI a asesinar a la Reina de Inglaterra y fue sentenciado a nueve años de prisión Qt 6.6 publicado oficialmente Reuters: RISC-V La tecnología se convierte en la clave de la guerra tecnológica entre China y Estados Unidos. Nuevo campo de batalla RISC-V: no controlado por ninguna empresa o país, Lenovo planea lanzar una PC con Android.Autor: JD Logística Liu Jiacun
Fuente: Comunidad de desarrolladores de JD Cloud Ziyuanqishuo Tech Indique la fuente al reimprimir