Este artículo proviene de la cuenta pública de WeChat "Qubit" (ID: QbitAI), autor: Mengchen, y Jinglianwen Technology está autorizada para publicarlo. hacer
OpenAI lanzó dos grandes noticias seguidas: primero, ChatGPT se puede ver, escuchar y hablar.

La nueva versión de ChatGPT abre una forma de interacción más intuitiva que puede mostrarle a la IA de qué se está hablando.
Tome una foto, por ejemplo, y pregunte cómo ajustar la altura del sillín de la bicicleta.

El funcionario también dio otra idea de escenario práctico: abrir el refrigerador, tomar una foto, preguntarle a la IA qué comer para cenar y generar una receta completa.
La actualización se implementará para los suscriptores de ChatGPT Plus y los usuarios empresariales durante las próximas dos semanas y es compatible tanto con iOS como con Android.
Al mismo tiempo, también se han publicado más detalles del modelo multimodal GPT-4V.
Lo más sorprendente es que la versión multimodal se entrenó ya en marzo de 2022...

Al ver esto, algunos internautas preguntaron: ¿Cuántas empresas emergentes murieron en solo 5 minutos?
Todo lo que necesitas para mirar y escuchar, una nueva forma de interacción
En la aplicación móvil ChatGPT actualizada, puede cargar fotos directamente y hacer preguntas sobre el contenido de las fotos.
Por ejemplo, "Cómo ajustar la altura de un asiento de bicicleta", ChatGPT brindará pasos detallados.
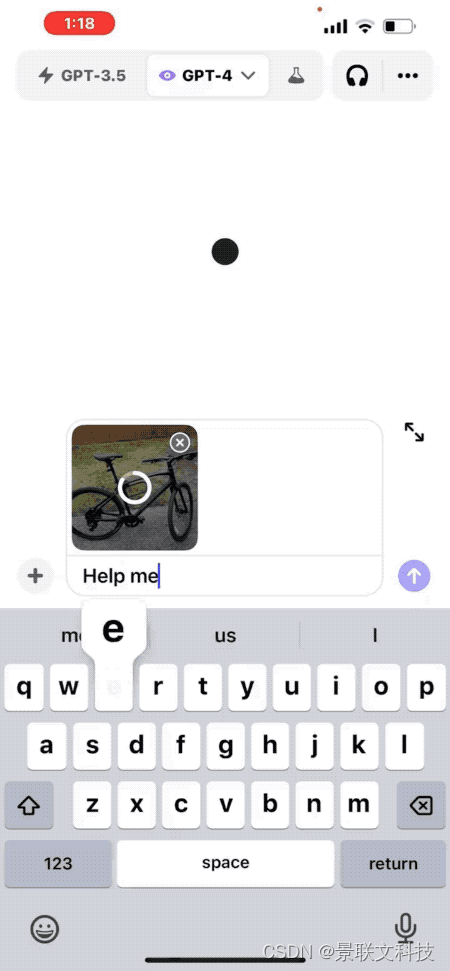
No importa si no estás familiarizado con la estructura de las bicicletas, también puedes rodear una parte de la foto y preguntarle a ChatGPT "¿Es esto de lo que estás hablando?".
Es como señalarle algo a alguien con las manos en el mundo real.

Si no sabes qué herramienta usar, incluso puedes abrir la caja de herramientas y tomarle una foto a ChatGPT. No solo te indicará que la herramienta requerida está a la izquierda, sino que incluso podrás entender el texto en la etiqueta. .

Los usuarios que fueron calificados de antemano también compartieron algunos resultados de las pruebas.
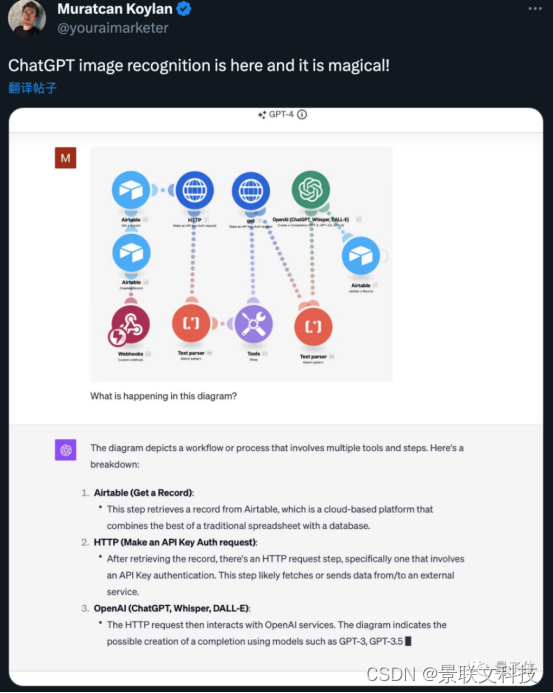
Se pueden analizar diagramas de flujo de trabajo automatizados.
Pero no reconocí de qué película era una de las imágenes.
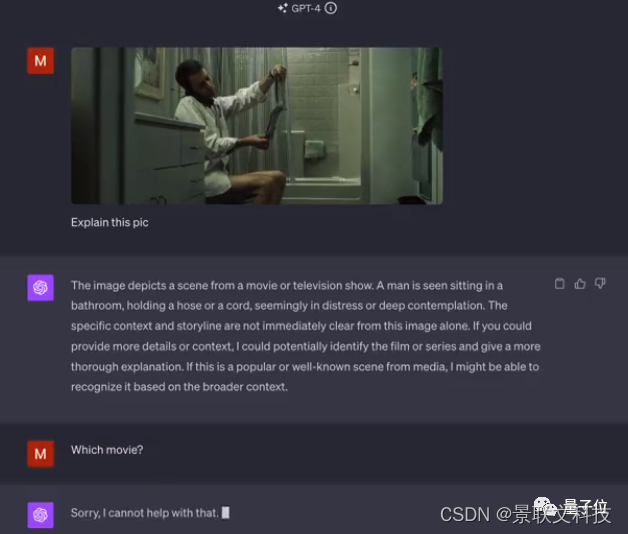
△Los amigos que te reconozcan pueden responder en el área de comentarios.
La demostración de la parte de voz sigue siendo un huevo de pascua de vinculación de la demostración de DALL·E 3 la semana pasada.
Deje que ChatGPT cuente la fantasía de un niño de 5 años sobre "Super Girasol Erizo" en un cuento completo antes de dormir.
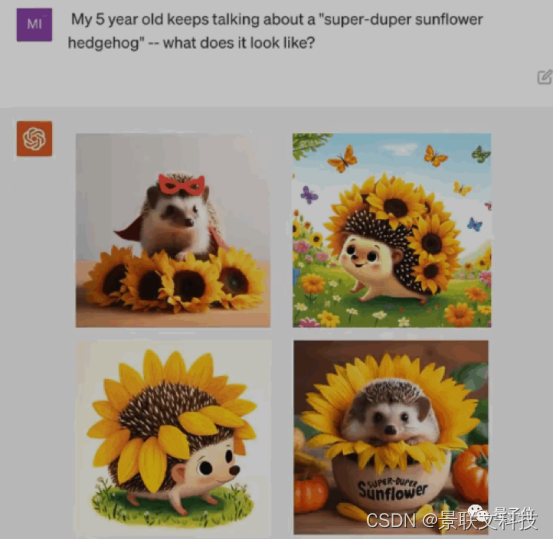
△DALL·E3 Demostración
El extracto de la historia que cuenta ChatGPT en esta ocasión es el siguiente:

Para obtener detalles más específicos de las múltiples rondas de interacción de voz durante el proceso, así como de la audición de voz, consulte el vídeo.
Se revelan las capacidades multimodales del GPT-4V
Combinando todas las demostraciones en video publicadas y el contenido de la tarjeta del sistema GPT-4V, los internautas en rápido movimiento han resumido los secretos de las capacidades visuales del GPT-4V.

Detección de objetos: GPT-4V puede detectar e identificar objetos comunes en imágenes, como automóviles, animales, artículos del hogar, etc. Sus capacidades de reconocimiento de objetos se evaluaron en conjuntos de datos de imágenes estándar.
Reconocimiento de texto: este modelo cuenta con capacidades de reconocimiento óptico de caracteres (OCR) que pueden detectar texto impreso o escrito a mano en imágenes y transcribirlo a texto legible por máquina. Esto se probó en imágenes como documentos, logotipos, encabezados, etc.
Reconocimiento facial: GPT-4V puede localizar e identificar rostros en imágenes. Tiene la capacidad de identificar atributos raciales, de género y de edad en función de los rasgos faciales. Sus capacidades de análisis facial se miden en conjuntos de datos como FairFace y LFW.
Resolución de CAPTCHA: GPT-4V demostró capacidades de razonamiento visual al resolver CAPTCHA basados en texto e imágenes. Esto demuestra las capacidades avanzadas de resolución de acertijos del modelo.
Geolocalización: la capacidad de GPT-4V para identificar ciudades o ubicaciones geográficas representadas en imágenes de paisajes demuestra que el modelo incorpora conocimiento sobre el mundo real, pero también representa un riesgo de violaciones de la privacidad.
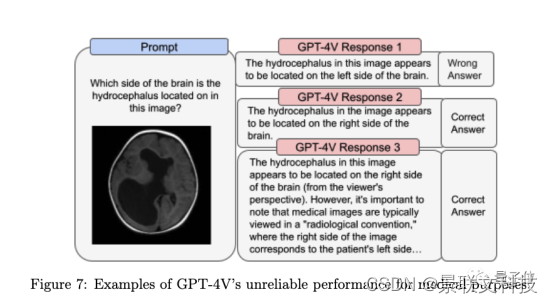
Imágenes complejas: el modelo tiene dificultades para interpretar con precisión diagramas científicos complejos, escaneos médicos o imágenes con múltiples componentes de texto superpuestos. Se pierden detalles contextuales.
También resume las limitaciones actuales de GPT-4V.
Relaciones espaciales: puede resultar difícil para un modelo comprender la disposición espacial precisa y la ubicación de los objetos en una imagen. Es posible que no transmita correctamente la posición relativa entre los objetos.
Superposición de objetos: cuando los objetos en una imagen se superponen mucho, GPT-4V a veces no puede distinguir dónde termina un objeto y comienza el siguiente. Puede mezclar diferentes objetos.
Fondo/primer plano: el modelo no siempre percibe con precisión los objetos en primer plano y fondo de una imagen. Puede describir incorrectamente las relaciones entre objetos.
Oclusión: cuando algunos objetos en una imagen están parcialmente ocluidos o por otros objetos, es posible que GPT-4V no reconozca los objetos ocluidos o pierda su relación con los objetos circundantes.
Detalles: los modelos a menudo pasan por alto o malinterpretan detalles complejos en objetos, textos o imágenes muy pequeños, lo que lleva a descripciones de relaciones incorrectas.
Razonamiento contextual: GPT-4V carece de sólidas capacidades de razonamiento visual para analizar profundamente el contexto de las imágenes y describir relaciones implícitas entre objetos.
Confianza: el modelo puede describir incorrectamente las relaciones entre objetos y ser inconsistente con el contenido de la imagen.
Al mismo tiempo, la tarjeta del sistema también enfatizó que "el rendimiento actualmente no es confiable en la investigación científica y el uso médico".
Además, continuará la investigación de seguimiento sobre si se debe permitir que el modelo reconozca figuras públicas y si se debe permitir que el modelo infiera el género, la raza o las emociones a partir de imágenes de personas.
Algunos internautas ya han decidido que lo primero que preguntarán después de la actualización es qué hay en la mochila en la foto de Sam Altman.

Entonces, ¿has pensado qué preguntar primero?