Directorio de artículos
Problemas de encuentro
Utilicé el modelo 7b de llama2 en el servidor para ajustar mi propio conjunto de datos, pero como el servidor del laboratorio no puede acceder a la red externa, encontré problemas al cargar el modelo.
OSError: We couldn't connect to 'https://huggingface.co' to load this file,
couldn't find it in the cached files and it looks like meta-llama/Llama-2-7b-hf
is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at
'https://huggingface.co/docs/transformers/installation#offline-mode'.
Solución
El primer paso
es ir a la página de inicio de Huggingface del modelo que desea utilizar: https://huggingface.co/meta-llama/Llama-2-7b-hf/tree/main y descargar manualmente los archivos que contiene a su local computadora, como se muestra en la siguiente figura:
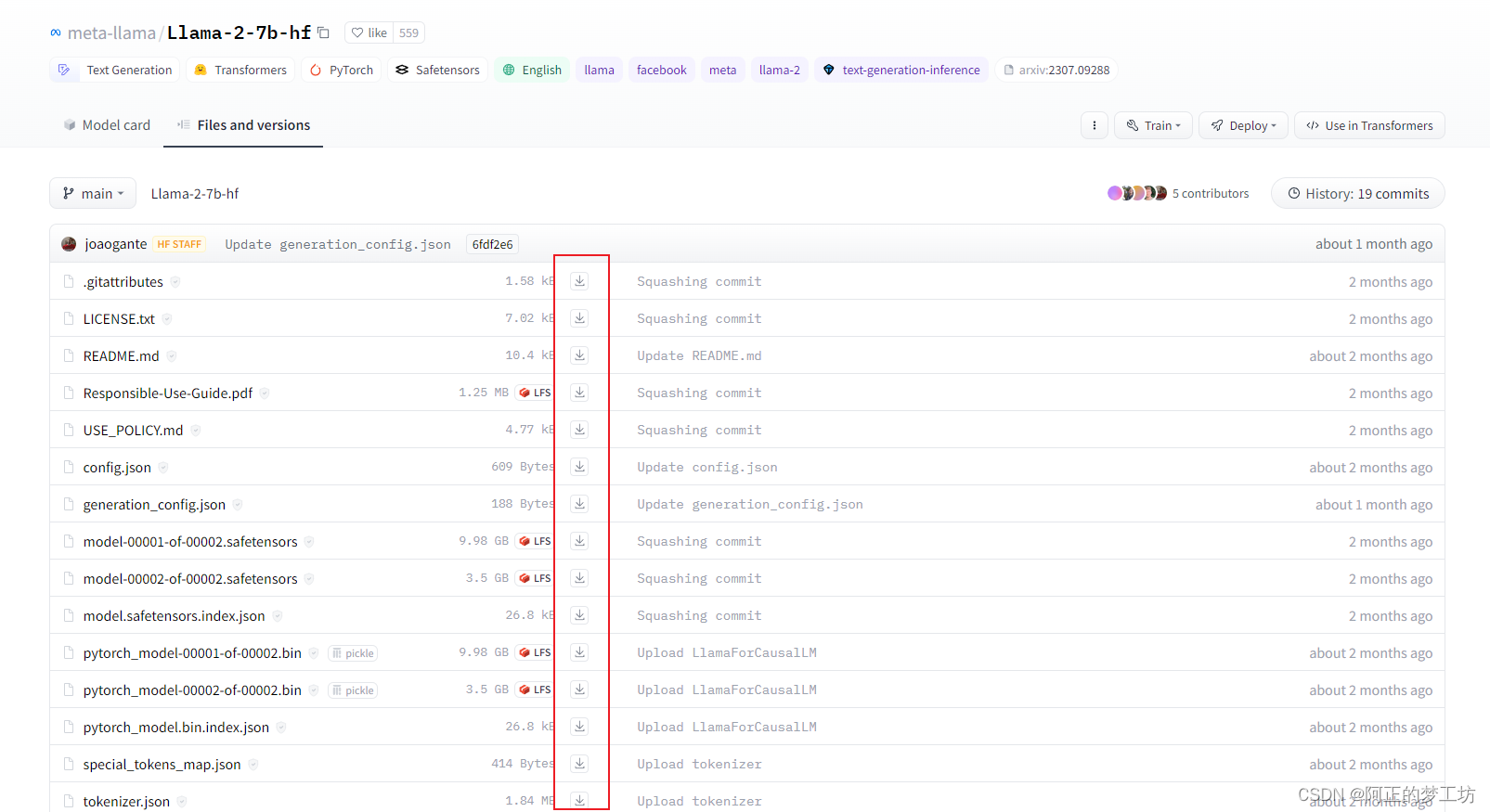
colóquelo en la carpeta llamada Llama-2-7b-chat-hf
El segundo paso
es usar WinSCP (u otro software para cargar archivos al servidor) para cargarlos en el servidor. Los parámetros del modelo y el código se colocan en el mismo directorio. El tercer paso es cambiar MODEL_NAME en el código

a
un from_pretrainedrelativo ruta, como se muestra en el siguiente código.
# MODEL_NAME = "meta-llama/Llama-2-7b-hf"
MODEL_NAME = "./Llama-2-7b-chat-hf"
def create_model_and_tokenizer():
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
use_safetensors=True,
quantization_config=bnb_config,
trust_remote_code=True,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
return model, tokenizer
Después de las operaciones anteriores, los parámetros del modelo se pueden cargar normalmente.
referencia
[1] https://blog.csdn.net/weixin_42209440/article/details/129999962