
Python es un gran lenguaje. Es uno de los lenguajes de programación de más rápido crecimiento en el mundo. Ha demostrado ser útil una y otra vez en funciones de desarrollador y en funciones de ciencia de datos en todas las industrias. Todo el ecosistema de Python y sus bibliotecas lo convierten en una opción adecuada para usuarios (principiantes y avanzados) de todo el mundo. Una de las razones de su éxito y popularidad es su poderosa colección de bibliotecas de terceros que lo mantienen dinámico y eficiente.
En este artículo, veremos algunas bibliotecas de Python para tareas de ciencia de datos distintas de las más comunes como panda, scikit-learn y matplotlib. Aunque bibliotecas como panda y scikit-learn se usan comúnmente en tareas de aprendizaje automático, siempre es beneficioso comprender otros productos Python en este campo.
Wget
Extraer datos de la web es una de las tareas importantes de un científico de datos. **Wget es una utilidad gratuita que se puede utilizar para descargar archivos no interactivos de Internet. Admite los protocolos HTTP, HTTPS y FTP, así como la recuperación de archivos a través del proxy HTTP. **Dado que no es interactivo, funciona en segundo plano incluso si el usuario no ha iniciado sesión. Entonces, la próxima vez que quieras descargar todas las imágenes de un sitio web o una página, wget puede ayudarte.
Instalar:
`$ pip install wget`
ejemplo:
import wget
url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
filename = wget.download(url)
100% [................................................] 3841532 / 3841532
filename
'razorback.mp3'
### Pendulum
Para aquellos de ustedes que se sienten frustrados al lidiar con las fechas y horas en Python, Pendulum es para ustedes. Es un paquete de Python que simplifica las operaciones de fecha y hora . Es un reemplazo simple para las clases nativas de Python . Consulte la documentación para un aprendizaje más profundo.
Instalar:
`$ pip install pendulum`
ejemplo:
import pendulum
dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
print(dt_vancouver.diff(dt_toronto).in_hours())
3
aprendizaje desequilibrado
Se puede ver que la mayoría de los algoritmos de clasificación funcionan mejor cuando el número de muestras en cada clase es básicamente el mismo, es decir, es necesario mantener el equilibrio de datos. Sin embargo, la mayoría de los casos de la vida real son conjuntos de datos desequilibrados, lo que tiene un gran impacto en la fase de aprendizaje y las predicciones posteriores del algoritmo de aprendizaje automático. Afortunadamente, esta biblioteca está diseñada para solucionar este problema. Es compatible con scikit-learn y forma parte del proyecto scikit-lear-contrib. Intente utilizar esto la próxima vez que encuentre un conjunto de datos desequilibrado.
Instalar:
pip install -U imbalanced-learn# 或者conda install -c conda-forge imbalanced-learn
ejemplo:
Consulte la documentación para conocer métodos de uso y ejemplos.
texto flash
En las tareas de PNL, la limpieza de datos de texto a menudo requiere reemplazar palabras clave en oraciones o extraer palabras clave de oraciones. Normalmente, esto se puede hacer utilizando expresiones regulares, pero puede resultar engorroso si el número de términos que se buscan es de miles. El módulo FlashText de Python se basa en el algoritmo FlashText y proporciona una alternativa adecuada para esta situación. Lo mejor de FlashText es que el tiempo de ejecución es el mismo independientemente de la cantidad de términos de búsqueda. Puedes aprender más aqui.
Instalar:
`$ pip install flashtext`
ejemplo:
Extraer palabras clave:
from flashtext import KeywordProcessorkeyword_processor = KeywordProcessor()# keyword_processor.add_keyword(<unclean name>, <standardised name>)keyword_processor.add_keyword('Big Apple', 'New York')keyword_processor.add_keyword('Bay Area')keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')keywords_found['New York', 'Bay Area']
Reemplazar palabras clave:
keyword_processor.add_keyword('New Delhi', 'NCR region')new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')new_sentence'I love New York and NCR region.'
Fuzzywuzzy
El nombre de esta biblioteca suena extraño, pero fuzzywuzzy es una biblioteca muy útil cuando se trata de coincidencia de cadenas. Se pueden implementar fácilmente operaciones como calcular el grado de coincidencia de cadenas y el grado de coincidencia de tokens, y también se pueden hacer coincidir fácilmente los registros almacenados en diferentes bases de datos.
Instalar:
`$ pip install fuzzywuzzy`
ejemplo:
from fuzzywuzzy import fuzzfrom fuzzywuzzy import process# 简单匹配度fuzz.ratio("this is a test", "this is a test!")97# 模糊匹配度fuzz.partial_ratio("this is a test", "this is a test!") 100
Se pueden encontrar ejemplos más interesantes en el repositorio de GitHub.
PyFlux:
El análisis de series de tiempo es uno de los problemas más comunes en el campo del aprendizaje automático. **PyFlux es una biblioteca de código abierto en Python creada para trabajar con problemas de series temporales. **Esta biblioteca tiene una serie de excelentes modelos de series temporales modernas, que incluyen, entre otros, los modelos ARIMA, GARCH y VAR. En resumen, PyFlux proporciona un enfoque probabilístico para el modelado de series temporales. Vale intentarlo.
Instalar:
`pip install pyflux`
ejemplo:
Consulte la documentación oficial para obtener ejemplos y usos detallados.
Ipyvolumen
La presentación de resultados también es un aspecto importante en la ciencia de datos. Poder visualizar los resultados será una gran ventaja. **IPyvolume es una biblioteca de Python que puede visualizar cuerpos y gráficos tridimensionales (como diagramas de dispersión tridimensionales, etc.) en cuadernos Jupyter y solo requiere una pequeña cantidad de configuración. **Pero todavía se encuentra en la etapa de versión anterior a la 1.0. Una metáfora más apropiada para explicar es: el volshow de IPyvolume es tan útil para matrices tridimensionales como lo es el imshow de matplotlib para matrices bidimensionales. Más disponibles aquí.
Usando pipa:
`$ pip install ipyvolume`
Usando Conda/Anaconda:
`$ conda install -c conda-forge ipyvolume`
ejemplo:
1. Animación

2. Representación de volumen

Estrellarse
**Dash es un marco Python eficiente para crear aplicaciones web. Está diseñado en base a Flask, Plotly.js y React.js, y está vinculado a muchos elementos de la interfaz de usuario modernos, como cuadros desplegables, controles deslizantes y gráficos. Puede usar código Python directamente para escribir análisis relevantes sin tener que usar javascript. Dash es excelente para crear aplicaciones de visualización de datos. **Estas aplicaciones luego se pueden representar en un navegador web. La guía del usuario está disponible aquí.
Instalar:
pip install dash==0.29.0 # 核心 dash 后端pip install dash-html-components==0.13.2 # HTML 组件pip install dash-core-components==0.36.0 # 增强组件pip install dash-table==3.1.3 # 交互式 DataTable 组件(最新!)
ejemplo:
El siguiente ejemplo muestra un gráfico altamente interactivo con funcionalidad desplegable. Cuando el usuario selecciona un valor en el menú desplegable, el código de la aplicación exporta dinámicamente los datos de Google Finance a un DataFrame de panda.
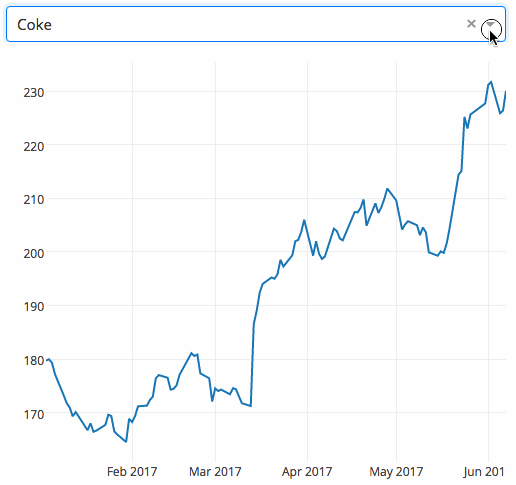
Gimnasia
**OpenAI's Gym es un conjunto de herramientas de desarrollo y comparación para algoritmos de aprendizaje por refuerzo. **Es compatible con cualquier biblioteca de computación numérica como TensorFlow o Theano. La biblioteca Gym es una herramienta esencial para probar conjuntos de problemas, también llamados entornos, que puede utilizar para desarrollar sus algoritmos de aprendizaje por refuerzo. Estos entornos tienen una interfaz compartida que le permite escribir algoritmos comunes.
Instalar:
`pip install gym`
ejemplo:
Este ejemplo ejecutará una instancia del entorno CartPole-v0 con un paso de tiempo de 1000, representando la escena completa en cada paso.
Resumir
Las útiles bibliotecas de Python de ciencia de datos anteriores las selecciono cuidadosamente yo, no las bibliotecas comunes como numpy y pandas. Si conoces otras bibliotecas, puedes dejar un mensaje en el área de comentarios.