La agrupación es una operación común en las redes neuronales convolucionales. La capa de agrupación imita el sistema visual humano para reducir la dimensionalidad de los datos y su esencia es la reducción de dimensionalidad . Después de la capa convolucional, la agrupación se utiliza para reducir la dimensión de la característica de la salida de la capa convolucional, reducir los parámetros de la red y los costos computacionales, y reducir el fenómeno de sobreajuste.
![]()



Max Pooling divide la imagen de entrada en varias áreas rectangulares y genera el valor máximo para cada subárea. Es decir, tomar el punto con mayor valor en el campo de aceptación local. De la misma forma, Average Pooling toma el promedio de los valores en el campo receptivo local.
El funcionamiento de la agrupación máxima se muestra en la siguiente figura: la imagen completa se divide en varios bloques pequeños del mismo tamaño (tamaño de agrupación) sin superponerse. Solo se toma el número más grande en cada bloque pequeño, se descartan otros nodos y se mantiene la estructura plana original para obtener el resultado.

La agrupación máxima se ejecuta por separado a diferentes profundidades y no requiere control de parámetros. Entonces la pregunta es ¿cuál es el papel de la agrupación máxima? ¿No hay impacto si se descarta alguna información?

La función principal de Max Pooling es reducir la resolución sin dañar los resultados del reconocimiento.
La agrupación MAX significa que para cada canal (suponiendo que hay N canales), el valor máximo del valor de píxel del mapa de características del canal se selecciona como representante del canal, obteniendo así una representación vectorial de N dimensiones. El autor utiliza el método de agrupación MAX en flask-keras-cnn-image-retrieval.

La agrupación MAX es ligeramente mejor que la agrupación SUM y la agrupación AVE. Sin embargo, la mejora de la recuperación de objetos mediante estos tres métodos de agrupación aún es limitada.
El rol de Max Pooling
Role 1: invariancia (invariancia
), esta invariancia incluye invariancia de traducción (traducción), invariancia de rotación (rotación), invariancia de escala (escala).
(1) traducción traducción

Los dos cuadros grandes de la izquierda de la imagen representan el número 1, pero sus posiciones son diferentes, el superior se traslada hacia la derecha para obtener el inferior. Después de la combinación, se obtuvieron los mismos resultados.
(2) rotación
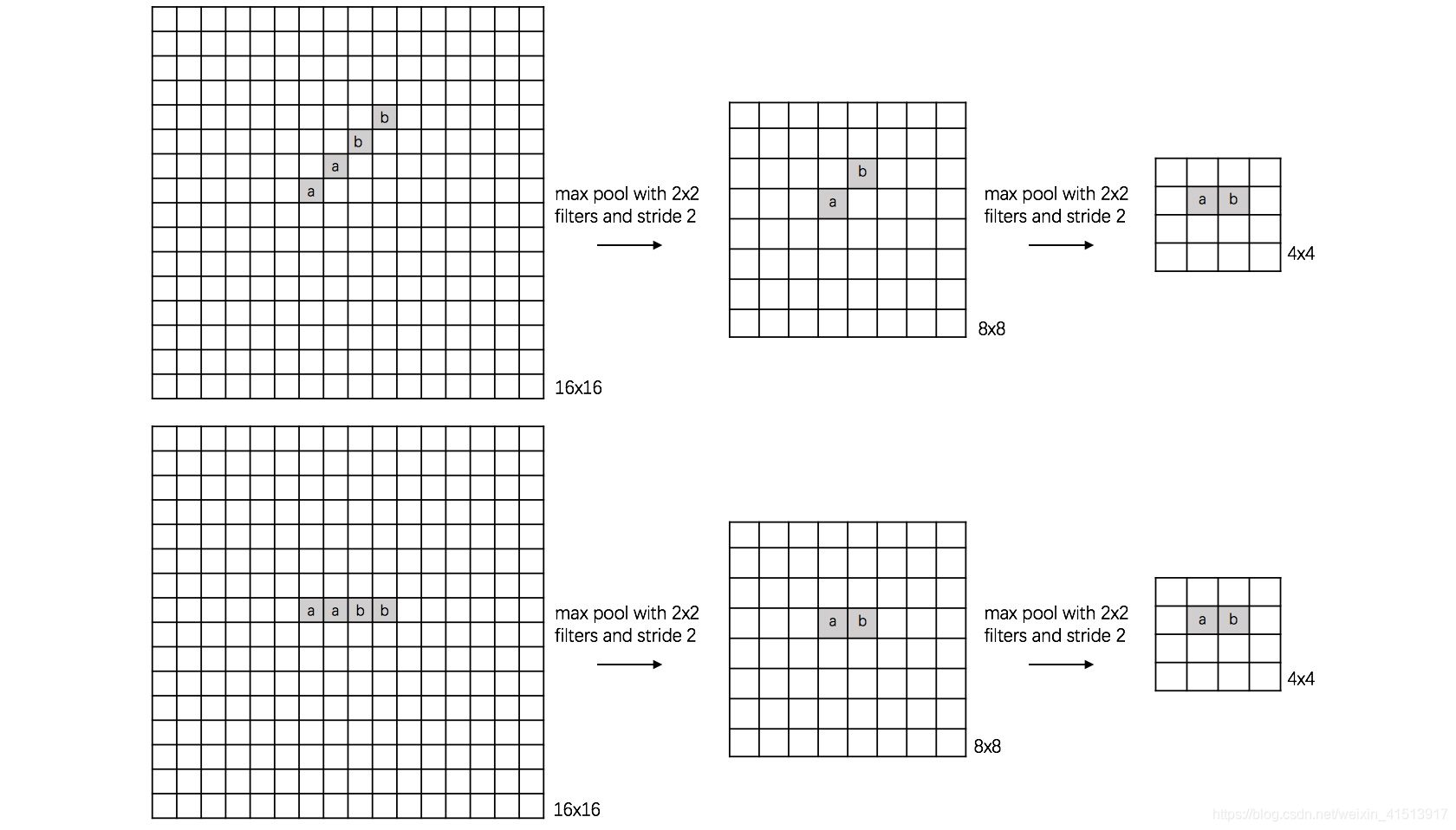
La imagen grande de la izquierda representa el carácter chino "一" (entendámoslo de esta manera, solo entiéndalo). Después de dos combinaciones se obtuvo el mismo resultado.
(3) escala

La imagen grande de la izquierda representa el número 0 y se obtiene el mismo resultado después de dos combinaciones.
Pongamos otro ejemplo:
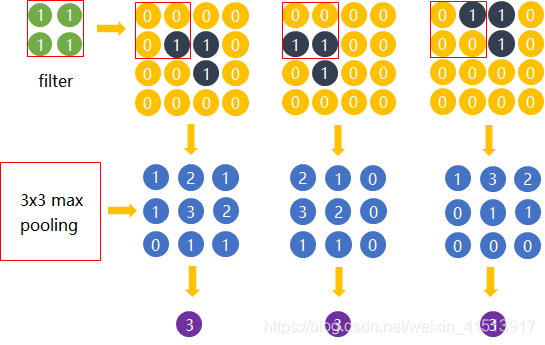
Considere la forma negra en el área amarilla: "Pliegue horizontal". Después del filtro 2*2, se obtiene una salida 3*3;
Después de una agrupación máxima de 3*3, todos obtuvimos una salida de 1*1 de 3.
Se puede ver que la forma del "pliegue horizontal" tiene el mismo resultado después de la agrupación, lo que reduce el tamaño de entrada de la siguiente capa, reduce la cantidad de cálculo y la cantidad de parámetros, y reduce la dimensión (reduce el mapa de características). tamaño).
Efecto 2: Ampliar el campo receptivo
puede tener alguna relación causal con la conclusión del Efecto 1.
En primer lugar, su primera función es reducir el tamaño del mapa de características y reducir los parámetros que deben entrenarse; en segundo lugar, debido a su efecto de reducción, los 4 píxeles anteriores ahora se comprimen en 1. Entonces, es equivalente a ver los 4 puntos anteriores a través de este punto 1. ¿No es esto simplemente ampliar el campo receptivo del mapa actual de una vez?
![]()

La agrupación global significa que el tamaño de la ventana deslizante de la agrupación es tan grande como el tamaño de todo el mapa de características. El método de agrupación específico dentro de la ventana deslizante puede ser arbitrario, por lo que se subdividirá en agrupación promedio global, agrupación máxima global, etc.
![]()

La agrupación estocástica es una estrategia de agrupación mencionada en el artículo "Agrupación estocástica para la regularización de redes neuronales convolucionales profundas". La idea general es que solo los elementos del área de características se seleccionan aleatoriamente de acuerdo con sus valores de probabilidad, y la probabilidad de ser seleccionados es también alto grande.
![]()
Mix Pooling es una estrategia de agrupación que aprovecha tanto la agrupación máxima como la agrupación promedio. Dos estrategias de combinación comunes: empalmar Cat y superponer Add.
![]()

SoftPool es una variante de Pooling que puede mantener la funcionalidad de la capa de pooling y al mismo tiempo minimizar la pérdida de información causada por el proceso de pooling. La figura anterior muestra la fase de avance y la fase de retroceso de la operación SoftPool. El área 6 * 6 representa el mapa de activación a.

![]()
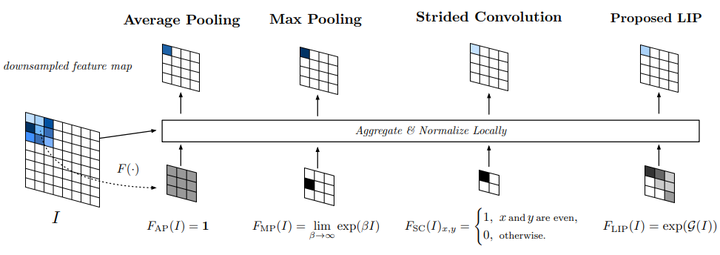
La agrupación basada en importancia local propone aprender automáticamente la importancia a través de una subred basada en características de entrada. Es capaz de determinar de forma adaptativa qué características son más importantes y al mismo tiempo mejora automáticamente las características de identificación durante el proceso de muestreo. La idea específica es aprender un mapa similar a la atención en el mapa de características original y luego realizar un promedio ponderado con la imagen original. Cabe señalar que el intervalo de muestreo en este caso es realmente fijo, lo que no se corresponde con la primera de las descripciones anteriores, pero el autor cree que, dado que la importancia es variable, se puede lograr un campo receptivo deformado.
![]()

S3Pool propone una estrategia de agrupación de posiciones aleatoria que integra Stochastic Pooling y Max Pooling.

![]()

La agrupación de gráficos se basa en campos aleatorios condicionales, que trata la agrupación de gráficos como un problema de agrupación de nodos y utiliza CRF para establecer relaciones entre las asignaciones de diferentes nodos. Este método se generaliza combinando información de topología de gráficos para que la agrupación de gráficos pueda controlar la agrupación por pares en CRF.
![]()

La agrupación de regiones de interés es una operación ampliamente utilizada en tareas de detección de objetos. Para cada región de interés de la lista de entrada, toma una parte del mapa de características de entrada correspondiente y la escala a un tamaño predefinido. Esto puede acelerar significativamente los tiempos de entrenamiento y prueba, permite reutilizar mapas de características de redes convolucionales y, al mismo tiempo, permite entrenar sistemas de detección de objetos de un extremo a otro.
10.Agrupación de SUMA
El método de representación de características de la capa intermedia basado en la agrupación SUM se refiere a sumar todos los valores de píxeles del mapa de características del canal para cualquier canal en la capa intermedia (por ejemplo, VGGNet16, pool5 tiene 512 canales), de modo que cada canal obtiene un valor numérico real, N canales eventualmente obtendrán un vector de longitud N, que es el resultado de la agrupación SUM.
11.Agrupación MOP
MOP Pooling se originó a partir de este artículo, uno de los cuales fue escrito por Yunchao Gong. Cuando estaba trabajando en él antes, leí algunos de sus artículos. Uno de los artículos más representativos es ITQ. El autor también escribió una nota especial. La idea básica de la agrupación MOP es multiescala y VLAD (para conocer el principio de VLAD, consulte la publicación de blog anterior del autor). Los pasos específicos de la agrupación son los siguientes:

12.Agrupación de CUERVO
Para la recuperación de objetos, cuando usamos CNN para extraer características, lo que queremos es extraer características en el área donde hay objetos. Al igual que cuando extraemos características locales como las características SIFT para construir vectores BoW, VLAD y FV, podemos usar MSER. , Saliencia, etc. Significa restringir las funciones SIFT a áreas con objetos. También basado en esta idea, cuando usamos CNN para realizar la recuperación de objetos, tenemos dos formas de refinar las características de la recuperación de objetos: una es realizar la detección de objetos primero y luego extraer las características de CNN en el área del objeto detectado; la otra es realizar la recuperación de objetos. primero la detección y luego extraemos las características CNN en el área del objeto detectado; una forma es aumentar el peso de las áreas de objetos y reducir el peso de las áreas que no son objetos mediante algún tipo de adaptación de peso. La agrupación CROW (ponderación multidimensional para características convolucionales profundas agregadas) es el último método. Al construir ponderaciones espaciales y ponderaciones de canal, la agrupación CROW puede aumentar el peso de las áreas de interés hasta cierto punto y reducir el peso de las áreas que no son objetos . Pesos. El proceso de construcción de representación de características específicas se muestra en la siguiente figura:

El proceso central son los dos pesos de peso espacial y peso de canal. Al calcular el peso espacial, el mapa de características de cada canal se suma y agrega directamente. Este peso espacial en realidad puede entenderse como un mapa de prominencia. Sabemos que a través del filtrado convolucional, los lugares con respuestas fuertes son generalmente los bordes de los objetos, etc. Por lo tanto, después de agregar y sumar múltiples canales, aquellas áreas con respuestas grandes y distintas de cero son generalmente las áreas donde se encuentran los objetos, por lo que Puede usarlo como el peso del mapa de características. Channel Weight toma prestada la idea de peso IDF, es decir, para algunas palabras de alta frecuencia, como "el", este tipo de palabra aparece con mucha frecuencia, pero en realidad no es muy útil para expresar información, es decir, el La cantidad de información que contiene es demasiado pequeña, por lo que en el modelo BoW, estas palabras vacías deben reducir su peso. Tomando prestado del proceso de cálculo del peso del canal, podemos imaginar una situación, como un canal, donde cada valor de píxel del mapa de características es distinto de cero y es relativamente grande. Visualmente, el área blanca ocupa todo el mapa de características, podemos pensar El mapa de características de este canal no nos permite ubicar el área del objeto, por lo que debemos reducir el peso de este canal. Para los canales donde el área blanca ocupa un área pequeña del mapa de características, Creo que es útil para el posicionamiento. Los objetos contienen mucha información, por lo que se debe aumentar el peso de este canal. Este fenómeno es particularmente consistente con la idea de IDF, por lo que el autor utiliza el peso IDF para definir el peso del canal.
En general, el diseño de Peso espacial y Peso de canal sigue siendo muy inteligente, pero dicho método de agrupación solo puede adaptarse al área de interés hasta cierto punto. Podemos echar un vistazo al mapa de calor de Peso espacial * Peso de canal:

Como se puede observar en lo anterior, las partes con pesos pesados se encuentran principalmente en la parte superior de la torre, esta parte se puede considerar como el área discriminada, por supuesto, también podemos ver que en otras áreas de la imagen, hay algunas distribuciones de peso relativamente grandes. Estas áreas son las que no queremos. Por supuesto, a juzgar por algunas otras imágenes que el autor ha visualizado, este método de agrupación colectiva no siempre tiene éxito. También hay algunas imágenes en las que el área muy ponderada no es el cuerpo principal del objeto en la imagen. Sin embargo, a juzgar por los resultados obtenidos en decenas de millones de bibliotecas, la agrupación colectiva aún puede lograr buenos resultados.
13.Agrupación de RMAC
El método de agrupación de RMAC proviene de Hervé Jégou (que es un buen amigo de Matthijs Douze). En este artículo, el autor propone un método de agrupación RMAC. La idea principal es similar a la agrupación MOP mencionada anteriormente. Utiliza un método de cambio de ventana para deslizar la ventana, pero en la ventana deslizante Al fusionar ventanas, la ventana deslizante no se realiza en la imagen, sino en el mapa de características (lo que acelera enormemente la extracción de características). Además, al fusionar características locales, la agrupación MOP utiliza el método VLAD para fusionar. , Mientras que la agrupación RMAC es más simple de procesar (simple no significa que el efecto no es bueno), y las características locales se agregan directamente para obtener las características globales finales. El método de ventana deslizante específico se muestra en la siguiente figura:

Fuente de imagen:
La figura muestra tres tamaños de ventana. 'x' en la figura representa el centro de la ventana. Para el mapa de características de cada ventana, el documento utiliza el método de agrupación MAX. Cuando L = 3, es decir, la figura Con las tres ventanas tamaños que se muestran en, podemos obtener 20 características locales. Además, si hacemos una agrupación MAX en todo el mapa de características, obtendremos una característica global, por lo que para una imagen, podemos obtener 21 características locales (si las características globales obtenidas también se consideran locales), estas 21 características locales se agregan y suman directamente para obtener las características globales finales. En el artículo, el autor comparó el impacto del número de ventanas deslizantes en mAP: de L = 1 a L = 3, mAP mejoró gradualmente, pero cuando L = 4, mAP ya no mejoró. De hecho, la función de la ventana diseñada en la agrupación RMAC es localizar la posición del objeto (la agrupación CROW localiza la posición del objeto a través del mapa de peso). Como se muestra en la figura anterior, existe una cierta superposición entre ventanas, y cuando finalmente se forman las características globales, se utiliza el método de suma y suma, por lo que podemos ver que podemos pensar que esas áreas superpuestas dan un mayor peso. .
Las 20 características locales y 1 característica global mencionadas anteriormente se fusionan y agregan directamente. Por supuesto, también podemos agregar estas 20 características locales y luego concatenarlas con la característica global restante. Durante el experimento real, se descubrió que el método de conexión en serie era entre un 2% y un 3% mejor que el método anterior. Probado en una biblioteca con un tamaño de 1 millón, la agrupación RMAC puede lograr buenos resultados y, en comparación con la agrupación Crow, no hay mucha diferencia entre los dos.
Aquí se le presenta la agrupación de redes neuronales. Bienvenido a recopilar el curso de CSDN Academy "De 0 a 1 Python Data Science Journey" . El curso tiene una gran cantidad de casos prácticos de modelado de ciencia de datos. Recuerde recopilar el curso.
Declaración de derechos de autor: el artículo proviene de la cuenta pública (modelo de control de riesgos de Python) y no se permite el plagio sin permiso. Cumpla con el acuerdo de derechos de autor CC 4.0 BY-SA; adjunte el enlace de la fuente original y esta declaración al reimprimir.
Enlaces de referencia:
https://arxiv.org/pdf/1611.05138.pdf
https://arxiv.org/pdf/1301.3557.pdf
https://arxiv.org/pdf/2101.00440.pdf
https://arxiv.org/ pdf/1908.04156.pdf
https://openreview.net/pdf?id=BJxg_hVtwH
https://deepsense.ai/region-of-interest-pooling-explained/
https://arxiv.org/abs/2009.07485
https:/ /www.jianshu.com/p/c3ba4ca849d3
https://blog.csdn.net/jiachen0212/article/details/78548667
https://www.cnblogs.com/ying-chease/p/8658351.html
https:// www.sohu.com/a/160924449_651893
https://www.cnblogs.com/guoyaohua/p/8674228.html
https://blog.csdn.net/dulingtingzi/article/details/79848625
https://blog.csdn .net/u010402786/article/details/51541465
https://blog.csdn.net/weixin_41513917/article/details/102514739
Descripción general de la agrupación sin orden multiescala para activaciones de CNN (MOP-CNN). Nuestra característica propuesta es una concatenación de los vectores de características de tres niveles: (a) Nivel 1, correspondiente a la activación de CNN de 4096 dimensiones para toda la imagen de 256256; (b) Nivel 2, formado extrayendo activaciones de 128128 parches y VLAD combinándolas con un libro de códigos de 100 centros; (c) Nivel 3, formado de la misma manera que el nivel 2 pero con 64*64 parches.