" Krypton se origina en Krypton en el universo DC . Es la ciudad natal de Superman y lleva el nombre del elemento kriptón ".
introducción
En los últimos años, además de los complejos requisitos de análisis, el negocio interno de Byte también ha presentado mayores requisitos para las capacidades de servicio en línea de datos en tiempo real. La mayoría de las empresas tienen que utilizar múltiples sistemas para manejar diferentes cargas de trabajo. Aunque pueden satisfacer las necesidades, también generan el problema de la coherencia de los datos en diferentes sistemas. El ETL entre múltiples sistemas también desperdicia muchos recursos. Al mismo tiempo, También es difícil para I + D. En términos de personal, también tienen que aprender a mantener múltiples sistemas. Para resolver este problema, iniciamos el proyecto Krypton, que es una nueva generación de sistema de análisis de servicios en tiempo real para empresas complejas (HSAP: Hybrid Serving and Analytical Processing), con la esperanza de hacer frente a escenarios complejos de análisis de big data y al mismo tiempo cumplir con Necesidades comerciales de servicios en línea de datos en tiempo real.
Enlace del artículo: https://www.vldb.org/pvldb/vol16/p3528-chen.pdf
Antecedentes e introducción
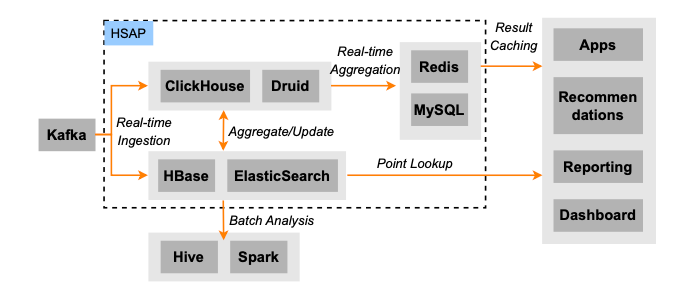
La imagen de arriba es la arquitectura de back-end publicitaria típica de Byte: los datos fluyen a diferentes sistemas a través de Kafka. Para los enlaces fuera de línea, los datos generalmente fluyen hacia Spark/Hive para su cálculo y los resultados se importan a sistemas como HBase/ES/ClickHouse a través de ETL para proporcionar servicios de consulta en línea. Para enlaces en tiempo real, los datos ingresarán directamente a HBase/ES para brindar servicios de consulta en línea de alta concurrencia y baja latencia, mientras que los datos fluirán a ClickHouse/Druid para brindar servicios de agregación de consultas en línea. El problema que esto trae es el mencionado en la introducción: los datos se almacenan de forma redundante en múltiples copias, lo que genera muchos problemas de coherencia y un gran desperdicio de recursos. Para resolver este problema, diseñamos Krypton (HSAP). Los objetivos de diseño del sistema tienen varios puntos principales:
-
ajustable. Esperamos diseñar un sistema que pueda hacer frente a diversas cargas de trabajo. Para diferentes cargas de trabajo, cada componente del sistema se puede escalar libremente.
-
Alta concurrencia y baja latencia. Para hacer frente a las necesidades de los escenarios de servicio en línea, el sistema debe poder cumplir con los requisitos de concurrencia de millones de niveles y latencia de milisegundos.
-
Los datos son fuertemente consistentes. Nuestros clientes esperan que los datos se puedan importar de forma atómica y admitan Snapshot Read.
-
Alta puntualidad. La mayoría de los usuarios necesitan que los datos sean visibles en el nivel de menos de un segundo. En algunos escenarios de servicio, los usuarios necesitan que los datos sean visibles en el nivel de milisegundos.
-
Importación de alto rendimiento. En escenarios de big data, el rendimiento de las importaciones es muy crítico.
-
Soporte SQL estándar. Muchos usuarios han migrado desde sistemas como MySQL, por lo que la compatibilidad con ANSI SQL es fundamental para la migración de usuarios.
Resumen del sistema
modelo de datos

Como se muestra en la figura, Krypton admite dos niveles de partición: el primer nivel se llama Partición y el segundo nivel se llama Tableta. Cada nivel admite la estrategia de partición Rango/Hash/Lista. Cada tableta contiene un conjunto de conjuntos de filas y los datos internos de cada conjunto de filas se ordenan según la clave de clasificación definida en el esquema. El conjunto de filas tiene el concepto de número de versión. Las filas correspondientes a la misma clave primaria pueden existir en múltiples copias en diferentes conjuntos de filas. Al leer, varias versiones de datos se fusionarán en una copia de acuerdo con diferentes algoritmos de fusión. La versión de confirmación de la tableta es el número de versión máximo del conjunto de filas en la tableta. Por ejemplo, la versión de confirmación de la tableta 2 en la figura anterior es el número de versión 21 del conjunto de filas 5. Cada consulta llevará el número de versión de los datos para lograr la lectura instantánea.
Según diferentes algoritmos de fusión, Krypton admite tres modelos de tablas:
-
Tabla duplicada: hay varias copias de la misma fila.
-
Tabla única: el sistema necesita definir una clave primaria (PK), solo habrá una copia de la misma PK y la versión superior sobrescribe la versión inferior.
-
Tabla agregada: similar a la tabla única, es necesario definir PK, pero se puede personalizar el algoritmo de combinación de varias filas con la misma PK y diferentes columnas.
Arquitectura

Como se muestra en la figura anterior, la arquitectura de Krypton tiene las siguientes características:
-
Separación de almacenamiento y cálculo.
-
Los datos de Krypton se almacenan en Cloud Store, como HDFS, la interfaz de almacenamiento de objetos estándar S3, etc.; los metadatos también se almacenan en sistemas de almacenamiento externos, como ZK y sistemas KV distribuidos.
-
-
Separación de lectura y escritura.
-
El servidor de ingestión es responsable de importar los datos y el servidor de compactación es responsable de fusionarlos periódicamente. Después de importar los datos, el servidor de ingesta escribirá WAL y los datos ingresarán al búfer de memoria. Cuando el búfer esté lleno, se descargará en una columna y se almacenará en el archivo en la tienda en la nube, y los nuevos datos se se registrará en el Meta Server y se actualizará la versión de confirmación de la tableta relacionada.
-
El Coordinador y el Servidor de datos forman un enlace de lectura. El Coordinador accederá al MetaServidor para obtener el número de versión más reciente del esquema y los datos, generará un plan de ejecución distribuido y lo enviará al Servidor de datos. El Servidor de datos es responsable de la ejecución del Plan de consulta. El procesador de consultas de Krypton adopta el modo de ejecución MPP.
-
Para brindar una mejor visibilidad de los datos, admitimos la función de lectura sucia, lo que significa que el servidor de datos puede acceder directamente a los datos en la memoria del servidor de ingesta, lo que brinda visibilidad de datos a nivel de milisegundos.
-
-
Cache
-
Para cumplir con los requisitos de baja latencia del servicio en línea, admitimos la caché de metadatos, la caché de planes y la caché de resultados en Cooridinator. Data Server admite internamente caché de datos de varios niveles, incluidos medios DRAM, PMEM y SSD. Para reducir los fallos, también admitimos la función de precalentamiento de la caché. Los nuevos datos se notificarán al servidor de datos para que se carguen antes de que se registren en el metaservidor.
-
vista materializada
La Vista Materializada (MV) juega un papel muy importante tanto en la escena de Servicio como en la escena AP. Según sus propias características arquitectónicas, Krypton implementa una estrategia MV fuertemente consistente en tiempo real de una sola tabla, y MV no necesita mantener la misma estrategia de partición que la tabla base.
Mantenimiento MT
Dentro del servidor de ingesta, cuando sea necesario vaciar los datos de la memoria de la tabla base, se ejecutará MV Query para convertir esta parte de los datos de la memoria en datos MV. Los datos de MV y los datos de la tabla base se vaciarán atómicamente. Después del éxito , se registrará en el MetaServidor y actualizará atómicamente los números de versión de la tabla Base y MV, asegurando la coherencia de los datos entre MV y la tabla Base.
Reescritura de consultas
Aquí presentamos un escenario de reescritura relativamente especial, que también proviene del negocio interno de Byte. La consulta original agrega datos dentro de una ventana de tiempo, como el siguiente SQL:

Dado que la cantidad de datos que deben agregarse es relativamente grande, los requisitos en línea para dicha latencia de consulta son relativamente altos, por lo que utilizamos MV para acelerar la ejecución de esta consulta. El método específico es el siguiente:
-
Cree dos MV para la tabla original, uno agregado por día y otro agregado por hora.
-
Divida la ventana de tiempo en Consulta en tres partes:
-
2022- 05-01 00:00:00 - 2022-05-09 00:00:00
-
2022-05-09 00:00:00 - 2022-05-09 14:00:00
-
2022-05-09 14:00:00 - 2022-05-09 14:12:15
-
-
Para la ventana de tiempo 2.a, consulte directamente el MV a nivel de día, la ventana de tiempo 2.b, consulte el MV a nivel de hora y la ventana de tiempo 2.c, consulte la tabla detallada y finalmente combine los resultados de la tres partes juntas.
El Optimizador completa automáticamente toda la reescritura de la consulta sin que el usuario se dé cuenta.
Derivación automática del modelo de datos
Además, como tabla especial, MV también puede optar por utilizar diferentes modelos de tabla. Krypton puede derivar automáticamente el modelo de tabla MV en función del modelo de tabla base y la consulta MV, lo que reduce la carga del usuario.
Procesador de consultas
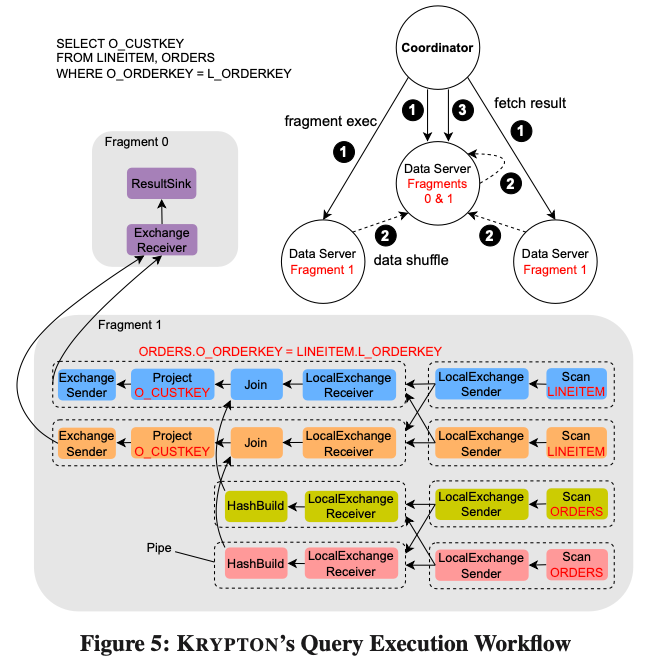
Krytpon implementa un motor de vectorización basado en Push y adopta un marco de ejecución de programación asincrónica basado en Coroutine. Tomando la figura anterior como ejemplo, se muestra el proceso de ejecución de una Consulta. El Coordinador generará Fragmentos de la Consulta optimizada y los entregará a un grupo de Servidores de Datos para su ejecución. Por ejemplo, la consulta en la imagen de arriba genera dos conjuntos de fragmentos: fragmento 0 y fragmento 1. El Fragmento 1 es responsable de ejecutar el Escaneo de las dos tablas y realizar Colocate Join. Los resultados generados se barajan al Servidor de Datos donde se encuentra el Fragmento 0. El Fragmento 0 es responsable de agregar los datos y luego tomarlos periódicamente del Coordinador. El fragmento 1 se dividirá internamente en varias tuberías, cada tubería consta de un conjunto de operadores y la lógica de ejecución de estas tuberías no se bloqueará. Se conectan diferentes tuberías a través de un operador de intercambiador local, y diferentes tuberías pueden establecer diferentes grados de concurrencia.
Caché de consultas y estadísticas
-
Caché de consultas
-
Mantenimiento de la caché : para evitar el uso de datos caducados, se agrega información del número de versión a la clave de caché y un subproceso en segundo plano la compara periódicamente con la versión de los datos en el metaservidor y elimina la entrada de caché caducada.
-
Plan/Estadísticas/ Caché de resultados : el plan de consulta se almacenará en caché en el Coordinador. La información de estimación de selectividad de algunos fragmentos de consulta también se almacenará en caché. Finalmente, los resultados de la ejecución de la consulta también se almacenarán en caché. Esto generalmente se usa cuando los datos son no se actualiza con frecuencia En escenarios donde hay muchas consultas idénticas. Además, Krypton también almacenará en caché algunos resultados intermedios de la ejecución de la Consulta, que otras Consultas pueden utilizar de manera más efectiva.
-
-
Estadísticas
-
Estadísticas incrementales : Krypton mantiene dinámicamente el NDV del recuento de filas y columnas de la tabla. NDV utiliza HLL para realizar cálculos delta. Cuando el servidor de ingestión vacía los datos, calculará el recuento de filas y el NDV HLL de los datos en la memoria y los enviará al Meta Server.
-
Muestreo dinámico: para la estimación de la selectividad del filtro, Krypton enviará directamente un fragmento del plan de consulta de muestra durante la etapa del plan para recopilar información estadística. En el conjunto de prueba TPCH-1T, la estimación estadística de los datos de la muestra y el valor estadístico del soporte los datos solo difieren en un 1 %, la sobrecarga ejecutada por la consulta de muestra no supera el 2 % del tiempo de ejecución. Además, una vez ejecutada nuestra Consulta, recopilará información estadística ligera y devolverá los resultados al Coordinador para ayudar al optimizador a actualizar la información estadística.
-
Control de concurrencia
Krypton utiliza una combinación de métodos estáticos y dinámicos para determinar la simultaneidad de la ejecución de consultas.
-
En la fase de Plan, el Optimizador determinará la concurrencia del nivel de Fragmento y el nivel de Tubería en función de la cantidad de Servidores de Datos, lo que puede evitar la sobrecarga adicional causada por la modificación dinámica del Plan y puede eliminar el Intercambiador Local tanto como sea posible. para evitar la mezcla de datos.
-
En la fase de ejecución, cada tubería corresponde a una tarea de ejecución, y la tarea se entregará a un subproceso Coro correspondiente para su ejecución. La concurrencia de ejecución específica y el orden de ejecución los determina dinámicamente el programador Coro subyacente en función del sistema actual. condiciones. Podemos establecer diferentes Prioridades para diferentes Tareas. Cuando encuentre una tarea con una prioridad más alta, Coro-scheduler reducirá dinámicamente la cantidad de coro-threads correspondientes a la tarea en progreso. Además, en comparación con pthread, Coro-thread tiene mucha menos sobrecarga de cambio de contexto y las operaciones de IO pueden ser asincrónicas, lo que puede aprovechar al máximo la CPU.
Aislamiento de recursos
Las cargas de trabajo de Serving y AP son bastante diferentes, por lo que el aislamiento de recursos es muy importante para escenarios de cargas de trabajo mixtas. Krypton implementa una estrategia de aislamiento de recursos de dos niveles.
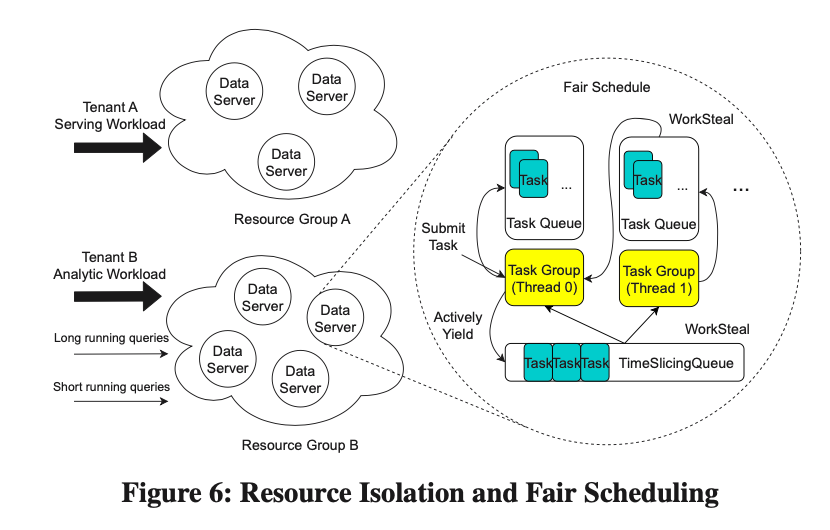
1.Aislamiento granular de recursos de la instancia DS
Dado que Krypton adopta un modelo de implementación nativo de la nube, cada instancia de DS corresponde a un contenedor, por lo que podemos dividir la instancia de DS en múltiples grupos de recursos y aislar diferentes cargas de trabajo a través de grupos de recursos. Debido a las características de separación de almacenamiento y cálculo de Krypton, varios grupos de recursos pueden compartir un dato. Para algunas consultas ETL temporales, Krypton puede extraer rápidamente algunos recursos para procesarlos y luego liberarlos después del procesamiento.
2. Aislamiento de recursos basado en Coro dentro de DS
Dentro del mismo grupo de recursos, también es necesario aislar diferentes consultas. Krypton proporciona una estrategia de programación justa basada en Coroutine. Como se muestra en la Figura 6, cada núcleo está vinculado a un grupo de tareas, que administra todas las tareas asignadas a él. Aquí, cada tarea corresponde a un subproceso Coro. Durante la ejecución, la tarea se envía a la cola de tareas local para esperar. Después ejecución, después de un período de tiempo t, la tarea local inconclusa se colocará en la cola de división de tiempo global. Cuando la cola de tareas local está vacía, el grupo de tareas correspondiente buscará tareas de la cola global, donde la prioridad de la cola global se basa en el tiempo de CPU consumido por cada tarea. Este es el principio básico del algoritmo de programación justa.
Optimización específica para escenarios de servicio
1.API ligera
En el escenario de publicación, cada consulta no suele ser muy compleja y la cantidad de resultados devueltos no es grande. Por lo tanto, cuando el Coordinador encuentre que se genera un Plan de Nodo Único, llamará directamente a la API Ligera del DS correspondiente para obtener el resultado. La API liviana evita el problema de múltiples comunicaciones RPC en consultas grandes y evita una gran cantidad de cambios de subprocesos.
2.Lectura sucia
Para escenarios con altos requisitos de puntualidad, proporcionamos la función Lectura sucia. Después de que el Coordinador envía la consulta al DS con la versión confirmada, el DS va a la memoria del servidor de ingesta para obtener los datos no confirmados y los fusiona con los datos confirmados después de regresar. Después de que el servidor de ingesta vacíe los datos de la memoria a HDFS, almacenará en caché esta parte de los datos durante un período de tiempo para garantizar que la solicitud de lectura sucia definitivamente pueda obtener la parte de los datos después de la versión confirmada, y habrá sin agujeros de datos.
Caché multinivel
Para cumplir con los requisitos de rendimiento, Krypton implementa una caché multinivel dentro del servidor de datos y puede usar DRAM, PMEM y SSD como medio de almacenamiento de la caché. Como se muestra en la figura siguiente, el módulo de caché contiene tres partes: índice de caché, política de reemplazo y motor de almacenamiento de caché.
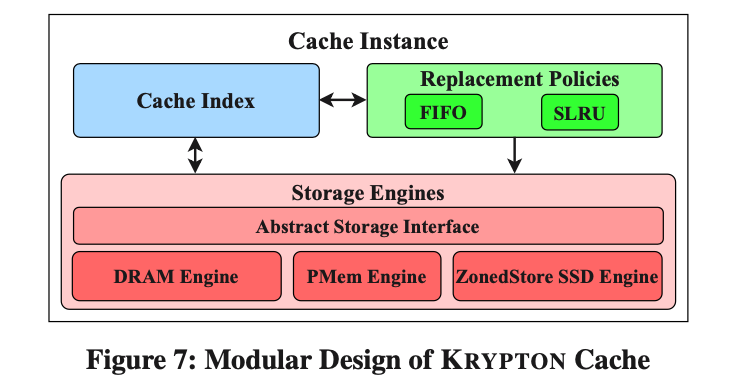
Política de reemplazo
AP a menudo necesita escanear una gran cantidad de datos, pero Serving tiene una localidad de acceso a datos obvia. Porque nuestra estrategia de reemplazo de caché debe tener características "anti-escaneo" para garantizar el rendimiento del servicio.
Elegimos SLRU como nuestra estrategia de reemplazo de caché. Además de la función "anti-escaneo", esta estrategia no requiere volver a bloquear para acceder a los datos que ya están en el caché. En comparación con el SLRU de MemCached, utilizamos una tabla hash sin bloqueo para almacenar el índice de caché, lo que reduce aún más el bloqueo. banda gastos venideros. En comparación con la estrategia FIFO, en el escenario de servicio, nuestra estrategia tiene una mejora del 28 % en la latencia P99.
Escritura PMem asíncrona compatible con NUMA
PMem tiene ventajas en cuanto a latencia de lectura y rendimiento, pero el ancho de banda de escritura es el cuello de botella en el rendimiento. El ancho de banda de escritura de PMem es solo una sexta parte del ancho de banda de escritura de DRAM, que es inferior al nivel de acceso simultáneo del ancho de banda de lectura, y el rendimiento disminuirá drásticamente cuando se acceda a través de nodos NUMA.
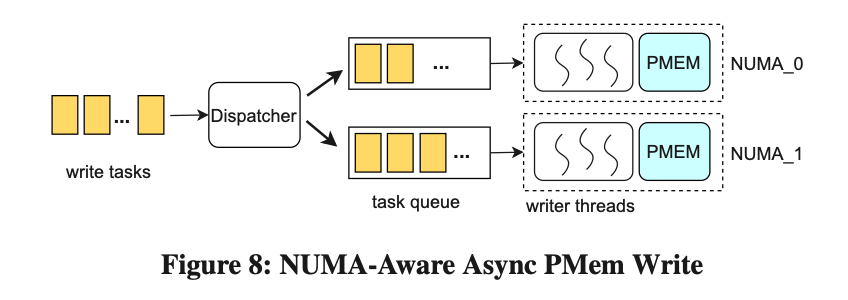
Krypton implementa una estrategia de escritura asincrónica basada en NUMA para mejorar el rendimiento de escritura de PMem. Como se muestra en la figura anterior, cada dispositivo PMem tiene un grupo de subprocesos de escritura correspondiente y está vinculado a un nodo NUMA, que es responsable de todas las escrituras en este dispositivo PMem. Las tareas de escritura asincrónicas se asignarán al grupo de subprocesos correspondiente para su procesamiento. Después de la prueba, cuando cada grupo de subprocesos tiene 3 subprocesos, el rendimiento de escritura de PMem mejora en un 23%.
Caché SSD basado en ZonedStore
SSD Cache permite a Krypton almacenar en caché tantos datos localmente como sea posible y puede calentarse rápidamente cuando se reinicia el sistema. Internamente, la mayoría de las cachés SSD utilizan almacenamiento KV con una arquitectura de árbol LSM similar a Rocksdb. Sin embargo, LSM Tree no está diseñado para cachés SSD, lo que provoca una gran pérdida de espacio y amplificación de lectura y escritura. Para resolver este problema, diseñamos ZonedStore.
ZonedStore divide el SSD en múltiples zonas del mismo tamaño, de las cuales solo se puede escribir en una. Los datos recién escritos se agregarán secuencialmente a la zona actualmente grabable, lo que puede reducir la amplificación de escritura dentro del SSD. Debido a que la mayoría de los elementos de caché en ZonedStore tienen más de 4 kb, esto nos permite colocar el índice de todos los elementos en la memoria para acelerar las consultas y reducir la amplificación de lectura. Para mejorar la velocidad de recuperación del índice durante el reinicio, escribiremos un segmento de resumen al final de la zona.
ZonedStore recupera espacio según la granularidad de la zona. La proporción de basura y la frecuencia de acceso de cada Zona se registrarán en los Metadatos de la Zona en la memoria. La estrategia de GC seleccionará una Zona con una alta proporción de basura y una baja tasa de acceso para el reciclaje. Para los elementos de caché eliminados, los marcaremos como eliminados temporalmente, porque los datos de caché en Krypton son inmutables, por lo que estos elementos de caché aún se pueden usar para proporcionar servicios en línea antes de reciclarlos. Para controlar la amplificación de escritura causada por GC, ZoneStore descartará directamente los datos válidos de la Zona reciclada.
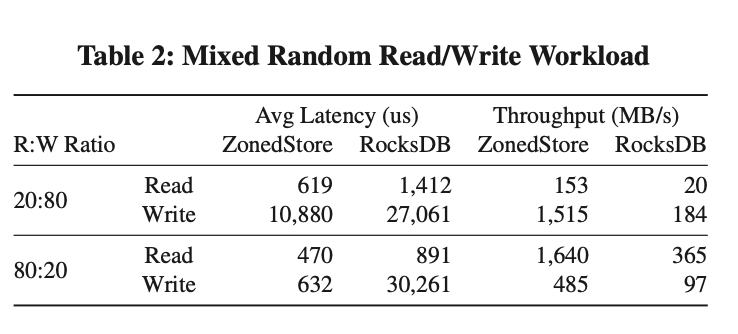
Como se puede ver en la figura anterior, no importa qué tipo de carga de trabajo, ya sea latencia o rendimiento, ZonedStore tiene una mejora relativamente grande en comparación con RocksDB.
Formato de almacenamiento
Para hacer frente a las cargas de trabajo de AP y Serving, Krypton diseñó su propio formato de archivo de almacenamiento. La página de datos (1 MB) es la unidad básica para la lectura y escritura de datos. El archivo completo se divide en tres partes: datos, índice y meta. Cada parte se divide según la columna. Al procesar la consulta, primero use el índice para filtrar la página de datos que debe leerse y luego acceda a la página de datos.
Algoritmos de codificación e índice
Krypton utiliza una variedad de codificación e índice de datos para acelerar el escaneo y la enumeración. Para localizar rápidamente la ubicación física de los datos, los usuarios pueden seleccionar el índice apropiado en DDL. Los índices admitidos por Krypton son los siguientes:
-
Índice ordinal: busque rápidamente la página de datos de destino según el número de fila.
-
Índice disperso: mínimo/máximo, filtro Bloom y filtro de cinta pueden filtrar rápidamente páginas de datos no válidas.
-
Índice de clave corta: utilice los primeros 36 bytes de la clave ordenada como clave de índice para crear un índice, que es un índice disperso especial.
-
Índice BitMap: los números de línea se pueden filtrar rápidamente según predicados equivalentes.
-
Omitir índice: puede localizar rápidamente la ubicación de los datos dentro de una página de datos.
Manejo de tipos anidados
Krypton se diferencia de Dremel en el procesamiento de tipos de datos compuestos: Dremel solo almacena nodos hoja, mientras que Krypton organiza todos los campos en forma de árbol B y almacena los datos de todos los campos de forma secuencial e independiente. En los nodos que no son hoja, se almacena información sobre la aparición (Ocurrencia) y la validez (Validez) de los nodos secundarios; en los nodos hoja, se almacenan datos. El número de apariciones (Ocurrencia) representa la suma del prefijo del número de apariciones del subcampo, logrando así una complejidad temporal O (1) al obtener el desplazamiento y la longitud de los datos repetidos. Por lo tanto, incluso en el caso de datos anidados y repetidos, todavía podemos lograr una eficiencia de búsqueda O(m), donde m es la profundidad del árbol de esquema. La validez se utiliza para distinguir si este campo está vacío o NULL. No almacenaremos ningún dato para el campo NULL, lo que mejora la eficiencia para almacenar datos dispersos. Comparado con Dremel, nuestro algoritmo tiene dos ventajas:
-
Los campos dispersos son más eficientes en el almacenamiento.
-
Mejor eficiencia de búsqueda para tipos compuestos repetidos.
Integración del motor de consultas
El diseño del formato de almacenamiento de Krypton está profundamente ligado a la ejecución de consultas. Para reducir IO tanto como sea posible, se utilizan ampliamente la materialización retrasada y la inserción de predicados. El filtrado de predicados y la poda de columnas se procesan en la capa de formato junto con los predicados del filtro de tiempo de ejecución push-down y los índices de archivos. Durante el proceso de lectura, primero se utiliza un predicado que puede coincidir con el índice para filtrar un conjunto de números de fila seleccionados (vector de selección). A continuación, utilizamos el marco de expresión para ejecutar predicados que no pueden coincidir con el índice, reducir aún más el número de fila seleccionado y realizar la poda de columnas. Finalmente, materializamos los datos en función de los números de fila en el Vector de selección. Además, Krypton también admite cálculos directamente sobre los datos codificados. En este momento, Format devolverá los datos codificados directamente a QE.

Hicimos una prueba comparativa con el formato Parquet en los conjuntos de datos TPC-H y Magnus. Magnus es un conjunto de datos sobre escenarios de ML dentro de Byte, que hace un uso extensivo de tipos de datos compuestos. Como puede verse en la tabla anterior, en comparación con Parquet, el rendimiento de lectura de Krypton Format aumentó un 21% en TPCH y un 40% en Magnus; en términos de tamaño de datos, en TPC-H, Krypton aumentó un 13%, principalmente porque Krypton interno indexación, pero en Magnus, Krypton se reduce en un 8%, lo que se beneficia principalmente del almacenamiento eficiente en tipos compuestos.
experimento
ambiente
-
Entorno experimental: YCSB Workload C + TPC-H 1T
-
Entorno de producción: escenario de Zhuxiaobang (Nota: plataforma integral de servicios y decoración del hogar ByteDance). Este es un escenario de servicio de funciones típico, que requiere un presupuesto agregado dentro de cualquier ventana de tiempo para cualquier función de un usuario determinado. Importación continua de datos, consulta en tiempo real, consulta QPS 10K/s
-
Configuración del clúster: 8 máquinas físicas (2,4 GHz, 48 núcleos, 96 vCPU, 128 G DRAM, 512 G PMEM, 2 TB NVME, 25 G NIC)
-
Coordinadores: 2 unidades
-
Servidores de datos: 3
-
Servidor de compactación: 1 unidad
-
Servidor de ingesta: 1
-
Servidor de metadatos: 1
Rendimiento híbrido
-
Aislamiento del grupo de recursos
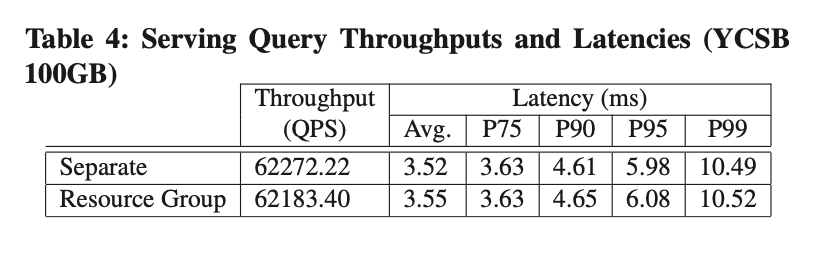

Creamos dos grupos de recursos para llevar la carga de trabajo de YCSB y TPCH respectivamente. Como se puede ver en la Tabla 4 y la Figura 9, en comparación con ejecutar YCSB y TPCH-1T por separado, no hay una pérdida obvia de rendimiento después de usar el grupo de recursos para el aislamiento.
-
Programación justa
Para verificar el efecto de la programación justa en la resolución de la competencia de recursos dentro del mismo grupo de recursos, ejecutamos TPCH-Q6 y Q21 bajo el mismo grupo de recursos, que representan consultas cortas y consultas largas respectivamente.
Todas las consultas comienzan con 1 Cliente y luego la cantidad de Clientes en el Q6 aumenta en 1, 2, 4 y 8.
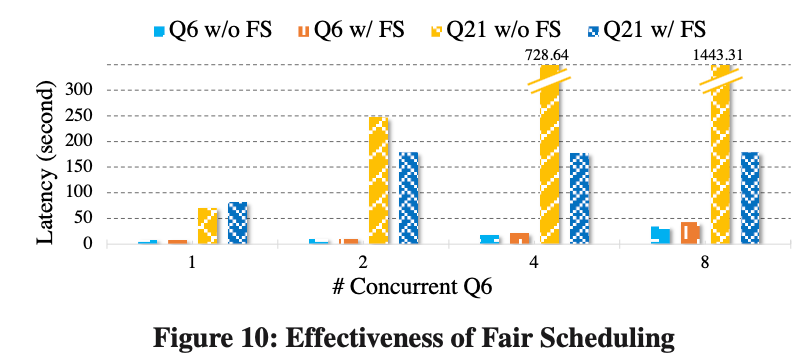
En la Figura 10, podemos ver:
-
Sin Programación Justa, a medida que aumenta la simultaneidad del T6, el desempeño del T21 retrocede significativamente;
-
Después de la programación justa, asignamos recursos a Q21 y Q6 al 20% y 80% respectivamente. La latencia de Q21 solo aumentó ligeramente con el número de clientes.
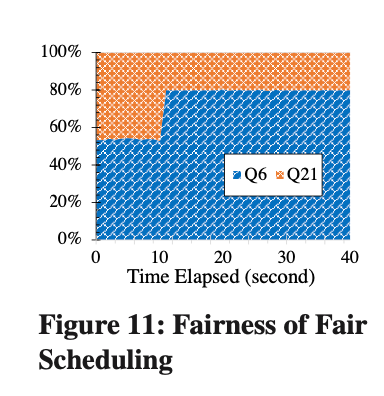
Como se puede ver en la Figura 11, cuando Q6 comienza a ejecutarse, Q6 no utiliza completamente sus propios recursos (80%), solo se utiliza alrededor del 53%, y Fair Scheduling puede asignar de forma adaptativa el 27% restante de los recursos. correr. A medida que aumenta el número de clientes de Q6, tanto Q6 como Q21 utilizan sus propios recursos.
-
Control de paralelismo adaptativo
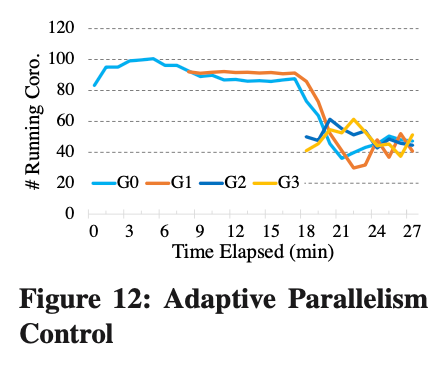
Para verificar el efecto de nuestro control de concurrencia adaptativo, utilizamos 4 clientes (G0 - G3) y cada cliente enviará Q6 repetidamente de acuerdo con la concurrencia máxima. Se puede ver en la Figura 12 que cuando solo hay G0, con suficientes recursos de CPU, se puede ejecutar de acuerdo con la concurrencia máxima. A medida que comenzamos G1 - G3, hay competencia por los recursos de la CPU y, finalmente, los subprocesos Coro que ejecuta cada Cliente también cambian dinámicamente.
Rendimiento de producción
-
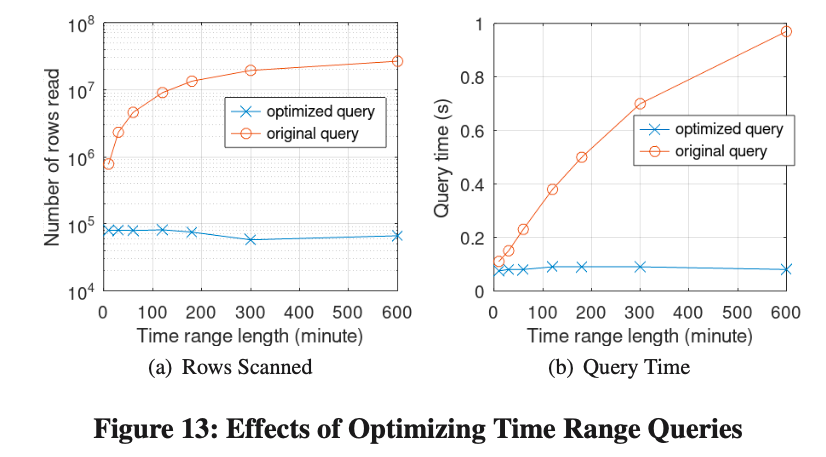
Efectos de optimizar las consultas de rango de tiempo
Para probar el efecto del uso de MV para reescribir consultas de rango de tiempo, utilizamos la carga de trabajo real de Online Live Xiaobang. La consulta es la siguiente:

Arreglamos la hora de finalización y luego cambiamos dinámicamente la hora de inicio. Todo el rango de tiempo osciló entre 10 minutos y 10 horas.
-
Efectos de la API ligera
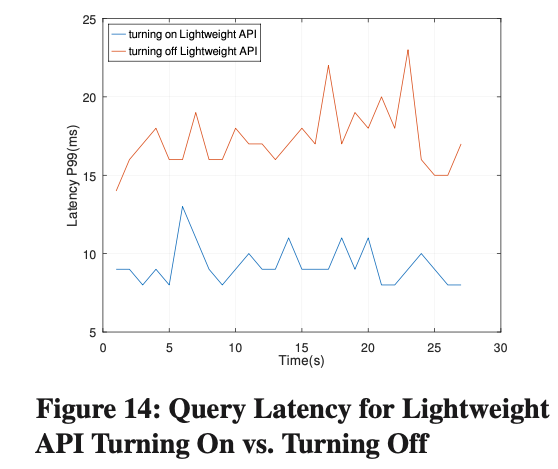
Comparamos y probamos la latencia en línea por debajo de 10 K QPS. Después de activar la API ligera, la latencia de Query P99 se redujo en un 45 %.
-
Actualización de los datos de la ingestión de streaming
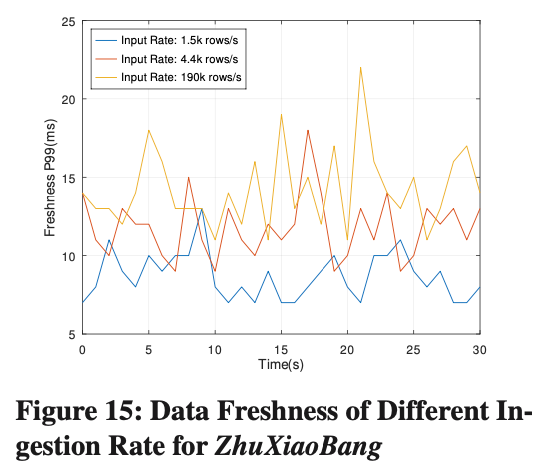
La actualización de los datos se define como el intervalo de tiempo entre el momento en que se importa un dato y el momento en que se puede consultar. Como se puede ver en la Figura 15, la latencia de Data Freshness P99 siempre se ha mantenido en alrededor de 15 ms y no cambiará a medida que aumente la tasa de importación.
-
Escenario de lectura/escritura en producción
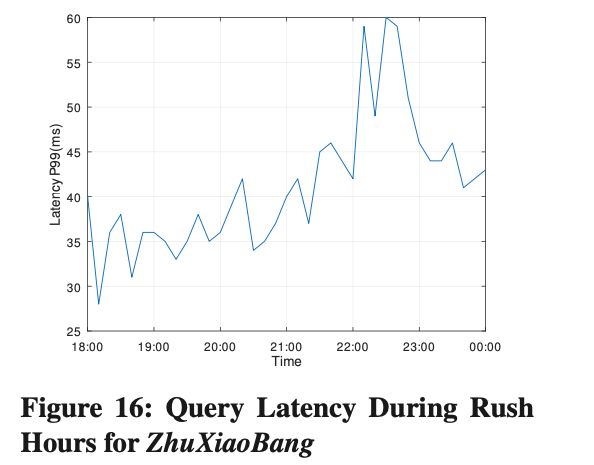
Zhuxiaobang es un escenario típico de lectura y escritura mixta. De 18:00 a 22:00 es el período pico todos los días. Durante este período, la tasa de importación aumenta en un 460% y el QPS de consulta aumenta en un 300%. Dado que Krypton adopta un sistema de lectura, arquitectura de separación de escritura, como se muestra en la Figura 16. La latencia de la consulta P99 no cambia mucho durante el período pico y permanece dentro de los 60 ms.
Resumir
A lo largo de todo el proceso de diseño, desarrollo y lanzamiento de Krypton, aprendimos muchas experiencias útiles:
-
La mayoría de los grupos comerciales de Krypton utilizaron Doris antes, y las herramientas ecológicas que rodean a Doris también son relativamente completas. Por lo tanto, decidimos desde el principio que el nivel de interfaz y el modelo de datos serían totalmente compatibles con Doris. Gracias a esto, los usuarios posteriores no encontraron mucha resistencia al migrar desde Doris, y algunos de los ecosistemas anteriores también pueden seguir utilizándose.
-
Encuentre oportunidades de optimización en escenarios de usuario. Por ejemplo, encontramos que algunos usuarios tienen un QPS alto, pero el modo de consulta es básicamente fijo, pero algunas condiciones de filtrado son diferentes. En este momento, la caché de resultados/plan juega un papel importante. También existen algunas tecnologías, como WAL que admite compresión y enlaces de escritura totalmente asíncronos, que desempeñan un papel muy importante en escenarios de escritura de alta velocidad.
-
Pruebe con tráfico en línea. Krypton es un sistema muy complejo y los usuarios suelen mostrarse escépticos sobre la estabilidad de los nuevos sistemas. Por lo tanto, desarrollamos un marco de doble lectura y doble escritura para el tráfico en línea: el tráfico en línea en escala de grises va a Krypton y el tráfico se cambia después de que el sistema se ejecuta de manera estable.