Notas de referencia: Notas en papel: Clasificación semisupervisada con redes convolucionales gráficas_blog-CSDN de blog de hongbin_xu
Matriz laplaciana y regularización_regularización laplaciana_blog de solicucu-blog CSDN
Prefacio
Red neuronal convolucional: Inspirada en el cerebro humano, al identificar un objeto, primero identifica el borde, luego la forma y finalmente determina el tipo de objeto. La red neuronal convolucional aprovecha las características del reconocimiento cerebral para establecer una red neuronal multicapa. La capa inferior identifica las características de los objetos y varias características de bajo nivel forman características de nivel superior. Finalmente, la clasificación se realiza mediante una combinación. de características multicapa.
Una red neuronal convolucional (CNN) típica consta de capas convolucionales, capas de agrupación y capas completamente conectadas. La capa convolucional se usa para extraer características, la capa de agrupación se usa para reducir la dimensionalidad y el sobreajuste, y la capa completamente conectada se usa para generar el resultado final. Los objetos de investigación suelen ser estructuras espaciales regulares, como oraciones ordenadas o la clasificación de perros y gatos. Estas características se pueden representar mediante matrices. Para imágenes con invariancia de traducción, mover una ventana pequeña a cualquier posición no afecta la estructura interna y se puede utilizar CNN para extraer características. RNN se usa generalmente para información de secuencia como PNL. Sin embargo, todavía hay muchos datos de estructuras espaciales irregulares en la vida, como las estructuras moleculares, que pueden considerarse datos de dimensión infinita y no tienen invariancia de traducción. Estas estructuras espaciales irregulares son difíciles de representar con núcleos de convolución fijos. Cada nodo es único, lo que invalidará CNN y RNN. GCN ha diseñado un conjunto de métodos para extraer características de los datos del gráfico, que es esencialmente un extractor de características. El artículo ( Clasificación semisupervisada con redes convolucionales de gráficos ) utiliza la teoría de gráficos espectrales y utiliza los valores propios y vectores propios de la matriz laplaciana para estudiar las propiedades de los gráficos.
El aprendizaje semisupervisado significa que solo una parte de los datos del conjunto de muestra contiene etiquetas y la clasificación de los datos sin etiquetar se infiere de los datos con etiquetas existentes. Dado un conjunto de datos, se puede mapear en un gráfico. Cada dato en el conjunto de datos corresponde a un nodo. Dado que un gráfico puede corresponder a una matriz, esto nos permite analizar algoritmos de aprendizaje semi-supervisados basados en la matriz. Pero esto tiene dos problemas: primero, suponiendo que hay n muestras, la complejidad es n^2, lo que dificulta el procesamiento de datos a tan gran escala. En segundo lugar, el proceso de composición solo puede utilizar conjuntos de muestras, y agregar nuevas muestras requiere reconstruir y volver a etiquetar la imagen original.
El objetivo de este artículo es resolver el problema del aprendizaje semisupervisado. Este artículo utiliza la red neuronal f (X, A) para codificar la estructura del gráfico y entrenar los nodos etiquetados en el objetivo supervisado.
1. Introducción
Consideramos el problema de clasificar nodos en un gráfico, donde las etiquetas se aplican sólo a un pequeño subconjunto de nodos. El problema se plantea como aprendizaje semisupervisado, en el que la información de las etiquetas se suaviza en un gráfico mediante alguna forma de regularización explícita basada en gráficos. Por ejemplo, la fórmula (1) utiliza el término de regularización laplaciana en la función de pérdida:
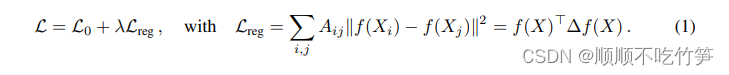
Representa la pérdida supervisada con etiquetas en el gráfico.
- f(.) representa una función diferenciable similar a una red neuronal
- λ es un factor de ponderación
- X es
una matriz de vectores de características de nodos
- A representa la matriz de adyacencia del gráfico.
Representa la matriz de grados de A, que es una matriz diagonal
- Δ = DA representa el gráfico laplaciano no normalizado de un gráfico no dirigido.
Esto tiene dos beneficios: introducimos una formulación de propagación hacia adelante simple y de buen comportamiento para redes neuronales de gráficos y mostramos cómo se puede motivar a partir de una aproximación de primer orden de la convolución de gráficos espectrales. En segundo lugar, demostramos cómo esta forma de modelo de red neuronal basado en gráficos se puede utilizar para la clasificación semisupervisada de nodos en gráficos. La desventaja es que se basa en el supuesto de que los nodos conectados pueden compartir la misma etiqueta. Esta suposición puede limitar las capacidades de modelado porque los bordes del gráfico no necesariamente necesitan codificar las similitudes de los nodos, sino que pueden contener información adicional.
2 Convolución aproximada rápida en gráficos
Esta sección considera redes convolucionales de gráficos multicapa (GCN):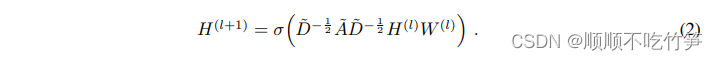
- A es la matriz de adyacencia del gráfico.
, es A más un bucle automático
-
Sí
, la matriz de grados
es una matriz diagonal.
¿Es la matriz de peso entrenable para una capa específica?
- σ(.) es la función de activación, como ReLU(.)=max(0,.)
∈
es la matriz de activación de la capa l, que puede considerarse como la salida de la capa l-1, y
=X
A continuación se mostrará que esta forma de propagación directa puede excitarse mediante una aproximación de primer orden de un filtro espectral local en un gráfico.
2.1 Convolución espectral
Consideramos la convolución espectral en un gráfico. Para una señal de entrada x∈ , tome el parámetro θ∈ en el dominio de Fourier
y establezca un filtro
![]()
- U es la matriz de vector propio del laplaciano normalizado del gráfico
- Matriz laplaciana:
- El valor propio Λ es una matriz diagonal,
que es la transformada de Fourier en el gráfico
- Puede entenderse
como la función de valor propio de L, es decir
El costo de calcular la fórmula (3) es muy costoso y la complejidad es O ( ). Además, calcular la descomposición propia de L es muy costoso. Para evitar este problema,
se puede utilizar
la expansión truncada de los polinomios de Chebyshev para proporcionar una buena aproximación al orden k.

-
,
representa el valor propio más grande de la matriz laplaciana L
es un coeficiente de Chebyshev
- Definición del polinomio de Chebyshev:
Volviendo a la definición de convolución de la señal x y filtro , podemos obtener:
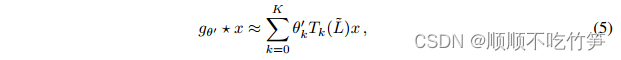
-
- k es el polinomio de orden k de la función laplaciana, que solo depende de nodos que están como máximo a k pasos del punto central.
2.2 Modelo lineal jerárquico
Se puede construir una red neuronal basada en convolución de gráficos superponiendo la fórmula (5). Cuando K = 1, es una función lineal en Laplaciano L. El artículo menciona que a través de esta forma de GCN, se puede aliviar el problema de sobreajuste de la estructura de vecindad local de gráficos con una distribución de grados de nodo muy amplia. Las características se pueden extraer apilando varias capas de este tipo.
En esta fórmula lineal de GCN (K = 1), se supone además que se puede predecir que los parámetros de la red neuronal pueden adaptarse a este cambio durante el proceso de entrenamiento. Bajo estas aproximaciones, la ecuación (5) se simplifica a:

proceso de prueba:
Matriz laplaciana L=D (matriz de grados)-A (matriz de adyacencia)
Prueba de regularización de la matriz laplaciana:

- Hay dos parámetros de filtro suma
,
que se pueden compartir en todo el gráfico.
- k es el número de capas convolucionales
- Limitar aún más el número de parámetros puede ayudar a reducir el sobreajuste

En este momento, el rango de valores propios es [0,2]. Cuando la red neuronal usa esta fórmula, puede causar inestabilidad numérica y explosión/desaparición del gradiente. Para resolver este problema, se introduce la siguiente técnica de normalización.
->
(es decir, agregar el bucle automático en la imagen)
Después de agregar la función de activación σ(.), podemos obtener , que es la fórmula 2.
Esta definición se puede generalizar a señales , que tienen canales de entrada C (es decir, cada nodo tiene un vector de características C-dimensional) y F y filtros o mapas de características, como se muestra en la siguiente figura.
![]()
es la matriz de parámetros del filtro
es la salida de la matriz de señal después de la convolución
3 Clasificación de nodos semisupervisados
Hemos introducido el modelo f (X, A) que propaga efectivamente información en el gráfico. Ahora volvemos al problema de la clasificación de nodos semi-supervisados. Ajustar el modelo f(.) lo hace más útil en situaciones donde la matriz de adyacencia contiene información que no está presente en X, como enlaces de citas entre documentos en una red de citas o relaciones en un gráfico de conocimiento. Como se muestra en la figura, el modelo general se utiliza para GCN multicapa para aprendizaje semisupervisado:
3.1 Ejemplo
El siguiente ejemplo considera la clasificación de nodos semisupervisados utilizando un GCN de dos capas en un gráfico con una matriz de adyacencia simétrica A. Primero calculamos el modelo de propagación directa usando:
![]()

La imagen de la izquierda es un diagrama esquemático de una red multicapa GCN utilizada para el aprendizaje semisupervisado. Hay entradas C en la capa de entrada, varias capas ocultas y características de salida F. La imagen de la derecha es el resultado de la visualización de la capa oculta del GCN de dos capas entrenado en el conjunto de datos de Cora. El color indica la clasificación del documento.
Aquí, definimos ![]() los parámetros que pertenecen a la capa de entrada a la capa oculta y
los parámetros que pertenecen a la capa de entrada a la capa oculta y ![]() los parámetros que pertenecen a la capa oculta a la capa de salida. La función de activación softmax se define como
los parámetros que pertenecen a la capa oculta a la capa de salida. La función de activación softmax se define como aplicada fila por fila. El error de entropía cruzada se utiliza para evaluar todos los datos etiquetados.
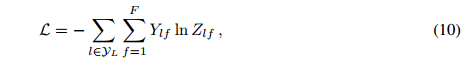
donde Yl es el conjunto de nodos etiquetados. La red neuronal utiliza el método de descenso de gradiente para entrenar a W0 y W1. Utilice el abandono para introducir aleatoriedad en el proceso de formación.
4 Resumen
Utilice la fórmula de Chebyshev para hacer un filtro de ajuste aproximado de orden k, basándose en los nodos circundantes con la longitud de paso más larga k, y considere más a fondo la influencia de los nodos circundantes en ellos, es decir, tome K = 1, y optimice aún más, tome , Para evitar las
explosiones de gradiente, se mejoraron y finalmente se definieron.