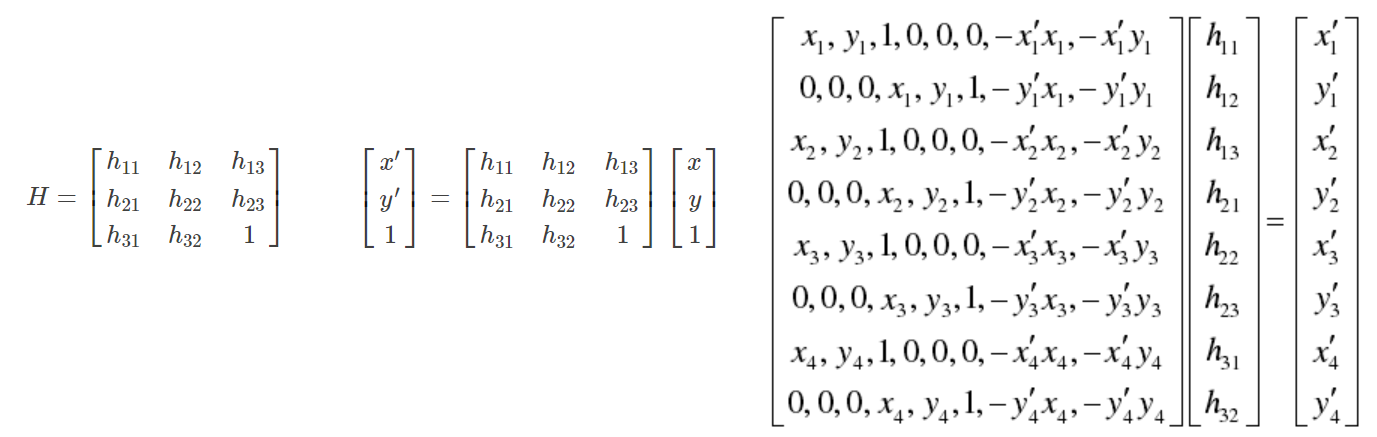notas de estudio de opencv 6 - características de imagen [harris + SIFT] + coincidencia de características
- Características de la imagen (transformación de características invariantes de escala SIFT)
-
- espacio de escala de imagen
-
- pirámide de resolución múltiple
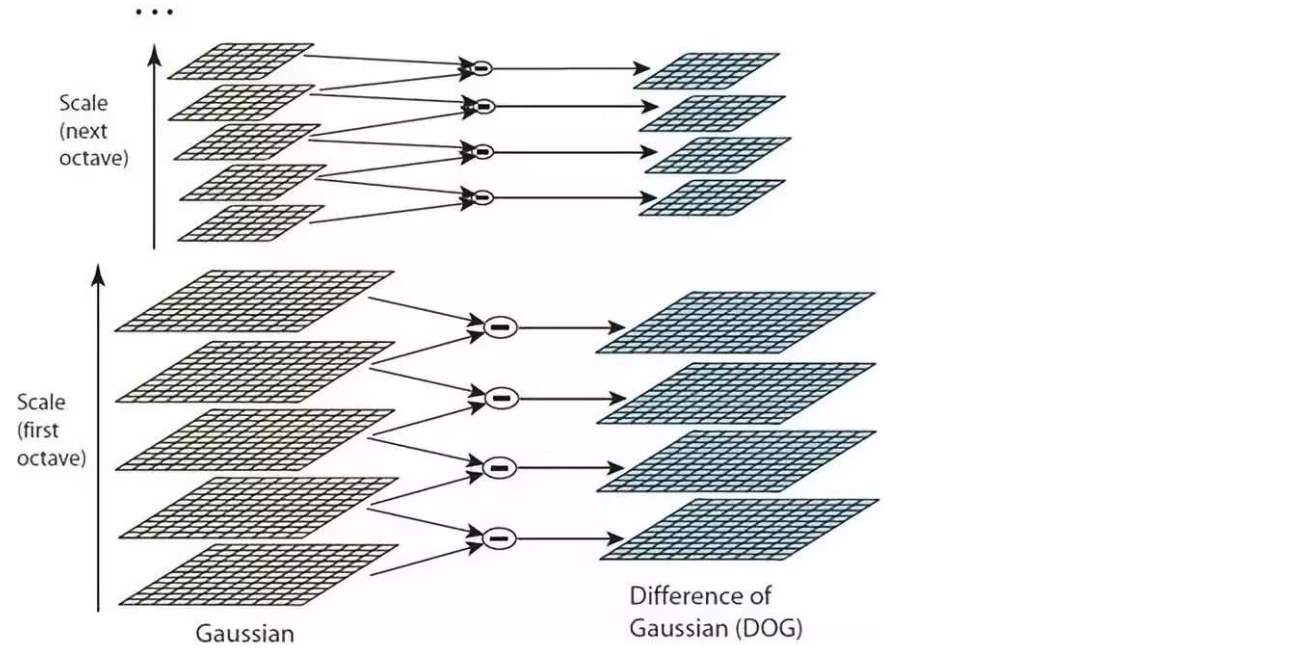
- Diferencia de la pirámide gaussiana (DOG)
- Detección de valores extremos en el espacio DoG
- Posicionamiento preciso de puntos clave.
- Eliminar respuestas dudosas
- La dirección principal del punto característico.
- Generar descripciones de características
- función tamiz opencv
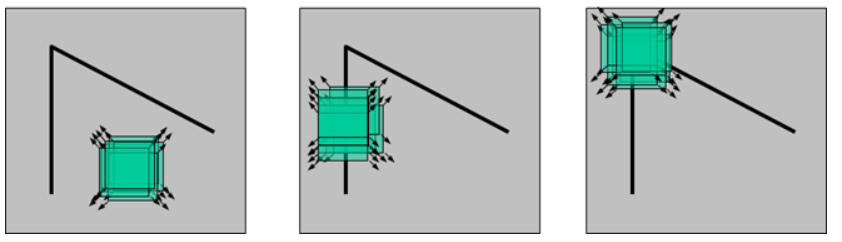
- Características de la imagen: detección de esquinas de Harris
- coincidencia de características
Características de la imagen (transformación de características invariantes de escala SIFT)
espacio de escala de imagen
Dentro de un cierto rango, no importa si el objeto es grande o pequeño, el ojo humano puede distinguirlo, sin embargo, es difícil que una computadora tenga la misma capacidad, por lo que para que la máquina tenga una comprensión unificada de los objetos a diferentes escalas, es necesario considerar las características de las imágenes que existen a diferentes escalas.
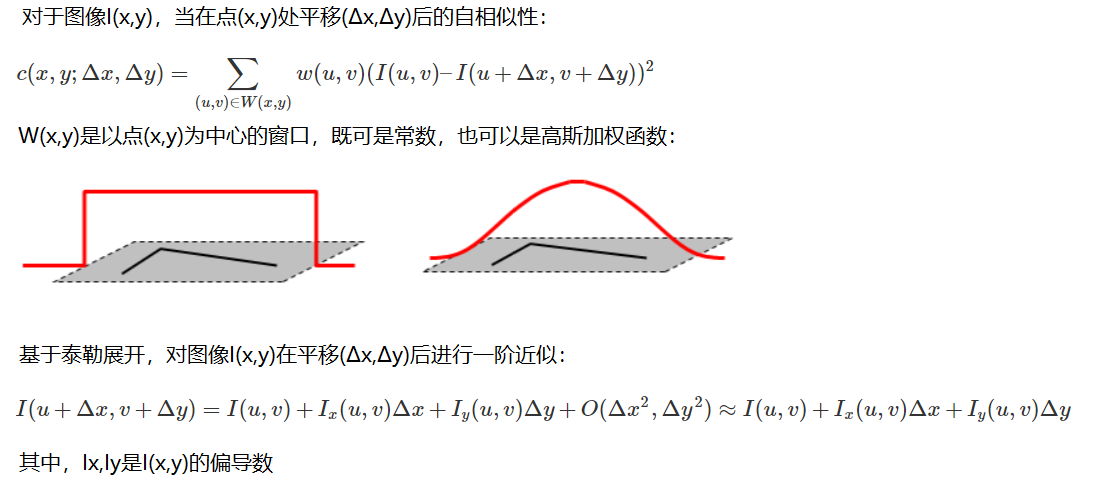
La adquisición del espacio de escala generalmente se logra mediante el desenfoque gaussiano.
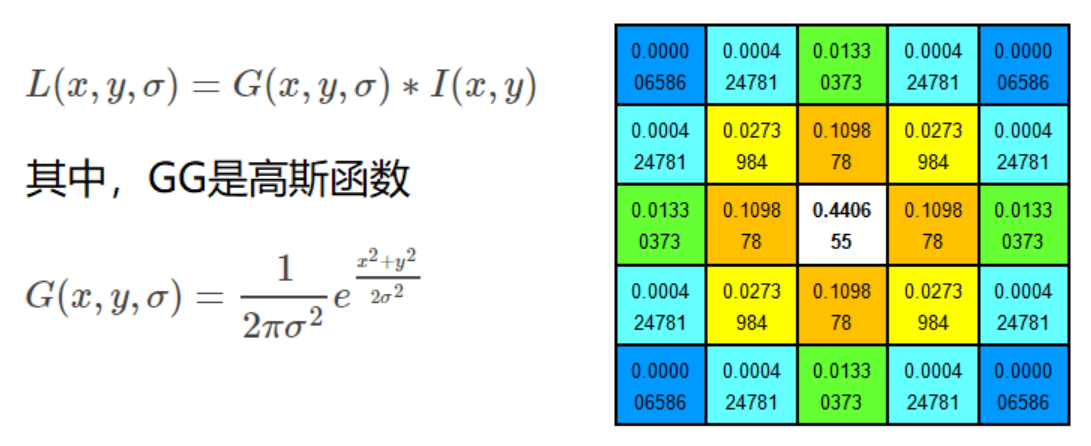

Las funciones gaussianas con diferentes σ determinan la suavidad de la imagen. Un valor mayor de σ corresponde a una imagen más borrosa.
pirámide de resolución múltiple
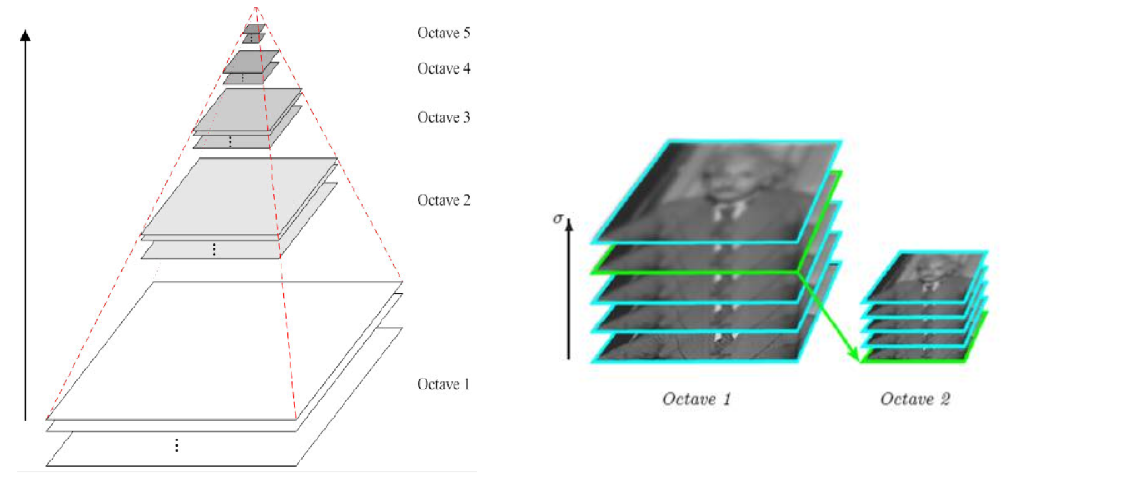
Diferencia de la pirámide gaussiana (DOG)
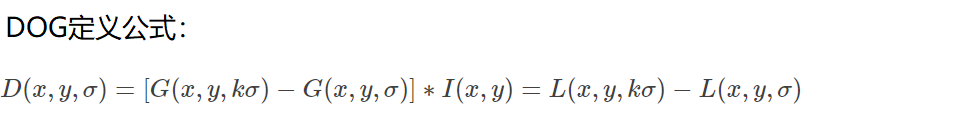
Detección de valores extremos en el espacio DoG
Para encontrar el punto extremo del espacio de escala, cada punto de píxel se compara con todos los puntos adyacentes en su dominio de imagen (mismo espacio de escala) y dominio de escala (espacio de escala adyacente), cuando es mayor (o menor que) todos el correspondiente Cuando es un punto adyacente, el punto es el punto extremo. Como se muestra en la figura siguiente, el punto de detección medio debe compararse con 8 píxeles en el vecindario de 3 × 3 de la imagen donde se encuentra, y 18 píxeles en las áreas de 3 × 3 de las capas superior e inferior adyacentes, para un total de 26 píxeles. .
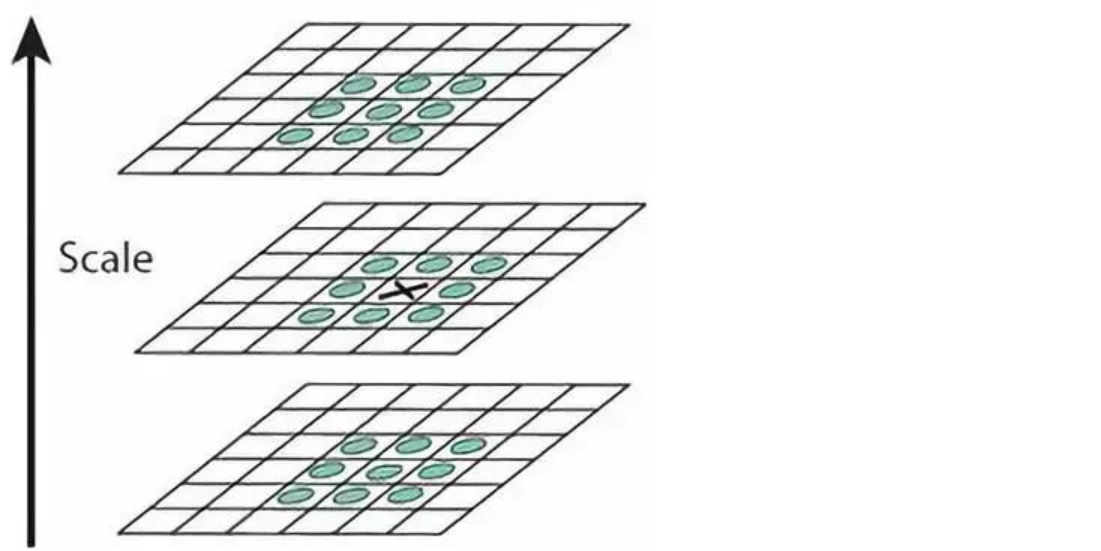
Posicionamiento preciso de puntos clave.
Estos puntos clave candidatos son puntos extremos locales en el espacio DOG, y estos puntos extremos son puntos discretos. Una forma de ubicar con precisión los puntos extremos es realizar un ajuste de curva en la función DoG del espacio de escala y calcular sus puntos extremos, logrando así precisión Posicionamiento de puntos clave.
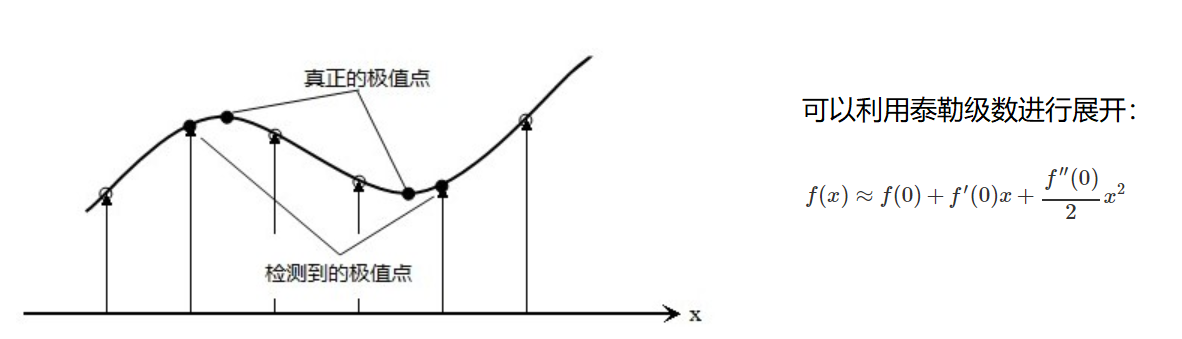
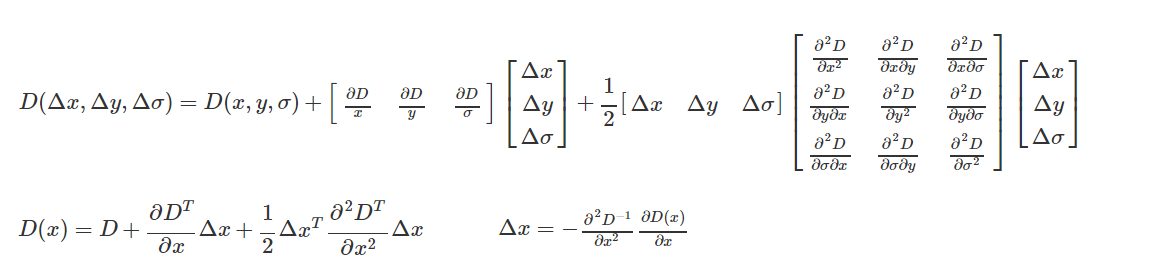
Eliminar respuestas dudosas

La dirección principal del punto característico.

Cada punto característico puede obtener tres datos (x, y, σ, θ), a saber, posición, escala y dirección. Los puntos clave con múltiples direcciones se pueden copiar en varias copias y luego los valores de dirección se asignan a los puntos característicos copiados respectivamente. Un punto característico genera múltiples puntos característicos con las mismas coordenadas y escalas, pero en diferentes direcciones.
Generar descripciones de características
Después de completar el cálculo del gradiente de los puntos clave, el histograma se utiliza para contar el gradiente y la dirección de los píxeles en la vecindad.
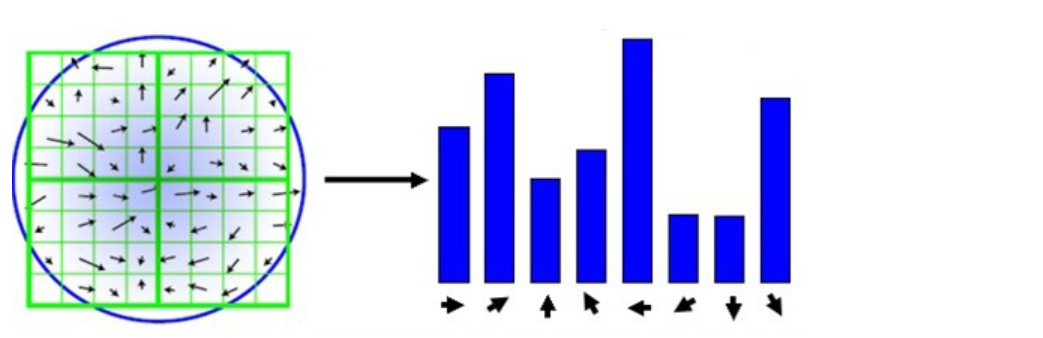
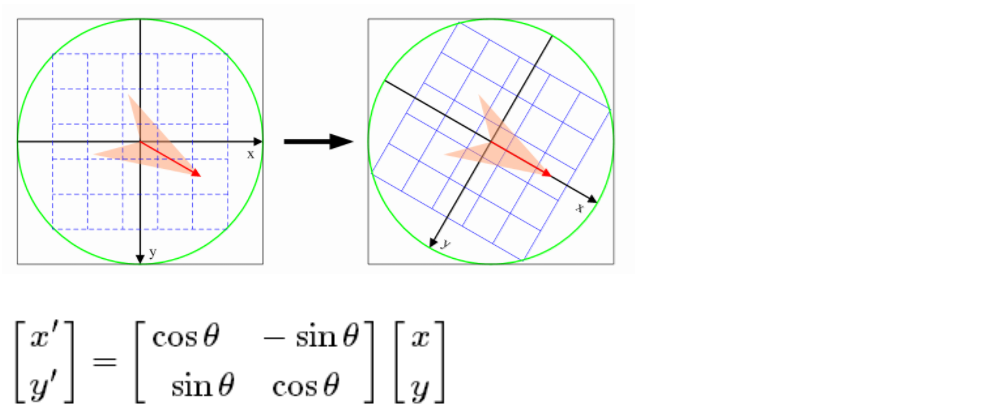
Para garantizar la invariancia de rotación del vector de características, el punto de característica debe tomarse como el centro y el eje de coordenadas debe girarse en un ángulo θ en el vecindario cercano, es decir, el eje de coordenadas debe girarse hacia la dirección principal. del punto característico.
Tome una ventana de 8x8 con la dirección principal después de la rotación como centro y encuentre la amplitud del gradiente y la dirección de cada píxel. La dirección de la flecha representa la dirección del gradiente y la longitud representa la amplitud del gradiente. Luego use una ventana gaussiana para ponderar y finalmente en cada 4x4 Dibuje un histograma de gradiente en 8 direcciones en un parche pequeño y calcule el valor acumulativo de cada dirección de gradiente para formar un punto semilla, es decir, cada característica se compone de 4 puntos semilla, y cada punto semilla tiene 8 direcciones información vectorial.
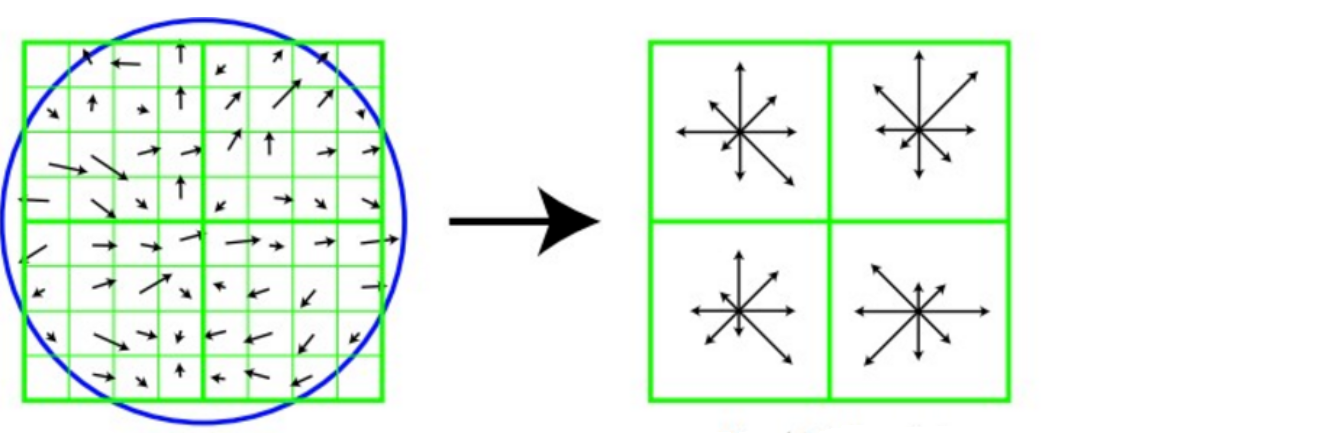
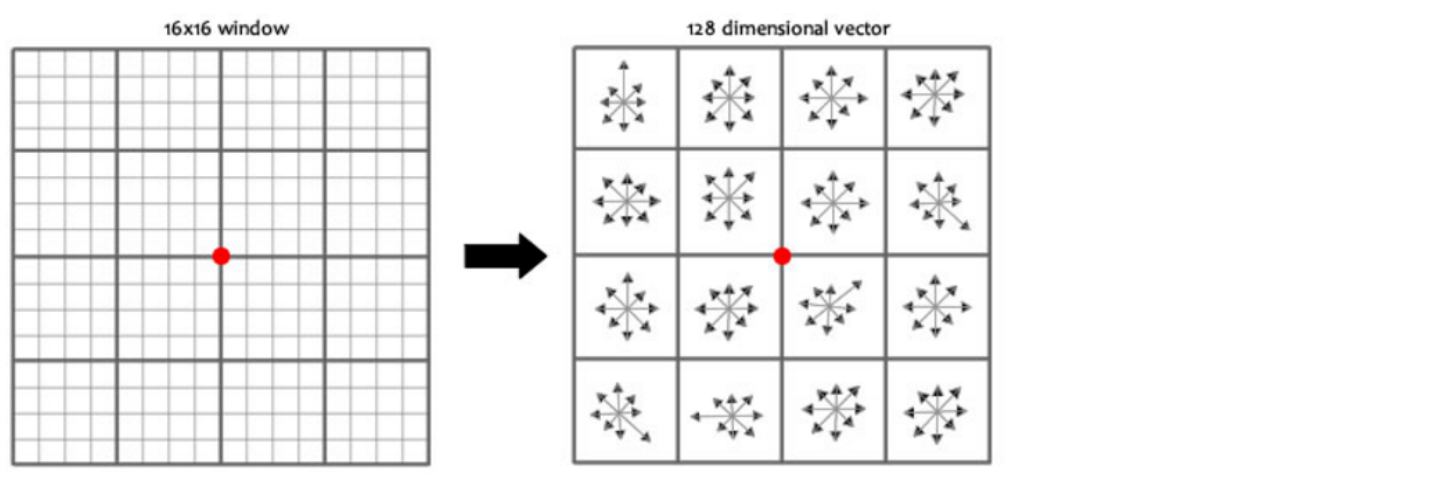
El documento recomienda utilizar un total de 16 puntos semilla de 4x4 para describir cada punto clave, de modo que un punto clave genere un vector de características SIFT de 128 dimensiones.
función tamiz opencv
import cv2
import numpy as np
import matplotlib.pyplot as plt#Matplotlib是RGB
img = cv2.imread('test_1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
def cv_show(img,name):
b,g,r = cv2.split(img)
img_rgb = cv2.merge((r,g,b))
plt.imshow(img_rgb)
plt.show()
def cv_show1(img,name):
plt.imshow(img)
plt.show()
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
cv2.__version__ #3.4.1.15 pip install opencv-python==3.4.1.15 pip install opencv-contrib-python==3.4.1.15
'3.4.1'
Obtener puntos de características
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None)
img = cv2.drawKeypoints(gray, kp, img)
cv_show(img,'drawKeypoints')
# cv2.imshow('drawKeypoints', img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()

Funciones informáticas
kp, des = sift.compute(gray, kp)
print (np.array(kp).shape)
(6827,)
des.shape
(6827, 128)
des[0]
array([ 0., 0., 0., 0., 0., 0., 0., 0., 21., 8., 0.,
0., 0., 0., 0., 0., 157., 31., 3., 1., 0., 0.,
2., 63., 75., 7., 20., 35., 31., 74., 23., 66., 0.,
0., 1., 3., 4., 1., 0., 0., 76., 15., 13., 27.,
8., 1., 0., 2., 157., 112., 50., 31., 2., 0., 0.,
9., 49., 42., 157., 157., 12., 4., 1., 5., 1., 13.,
7., 12., 41., 5., 0., 0., 104., 8., 5., 19., 53.,
5., 1., 21., 157., 55., 35., 90., 22., 0., 0., 18.,
3., 6., 68., 157., 52., 0., 0., 0., 7., 34., 10.,
10., 11., 0., 2., 6., 44., 9., 4., 7., 19., 5.,
14., 26., 37., 28., 32., 92., 16., 2., 3., 4., 0.,
0., 6., 92., 23., 0., 0., 0.], dtype=float32)
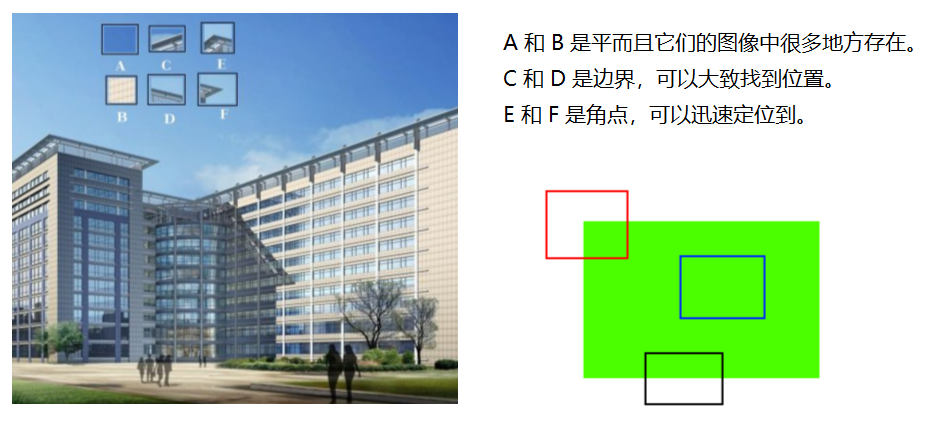
Características de la imagen: detección de esquinas de Harris
Fundamental
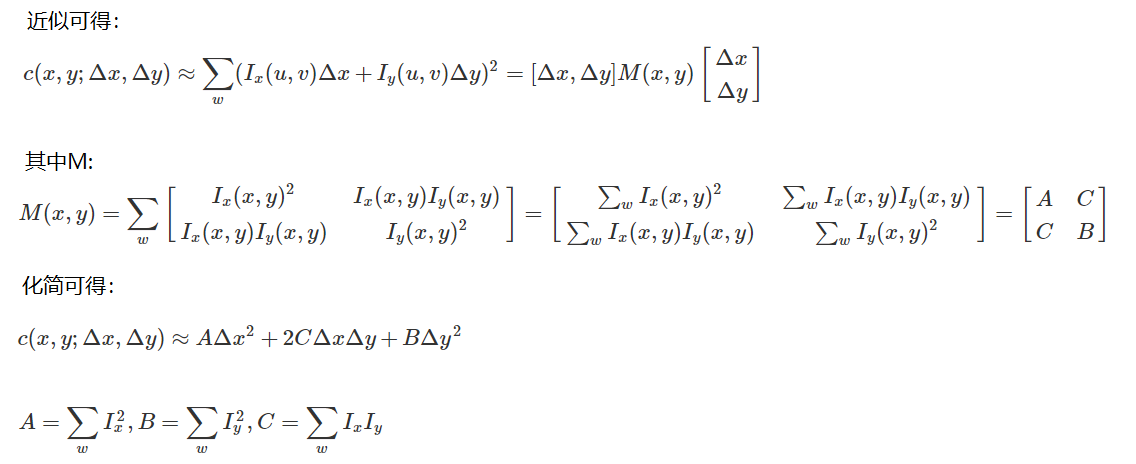
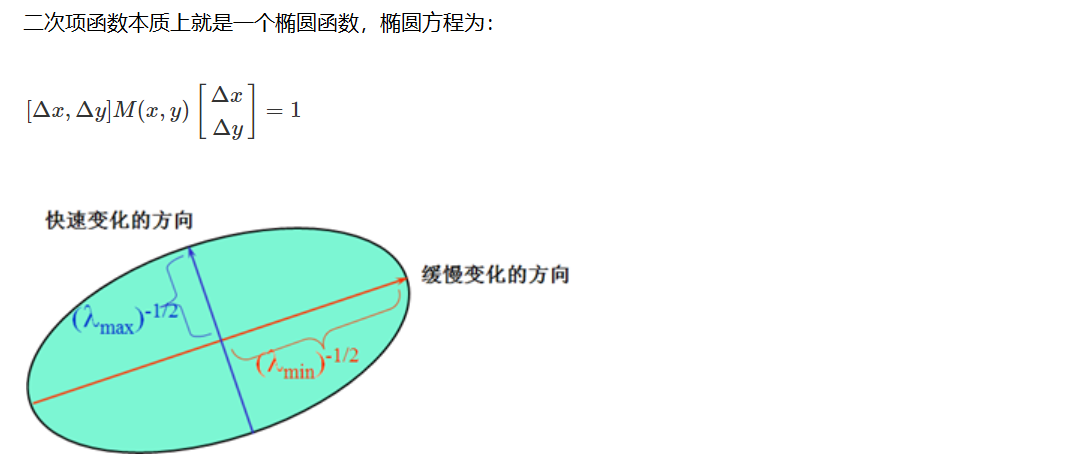
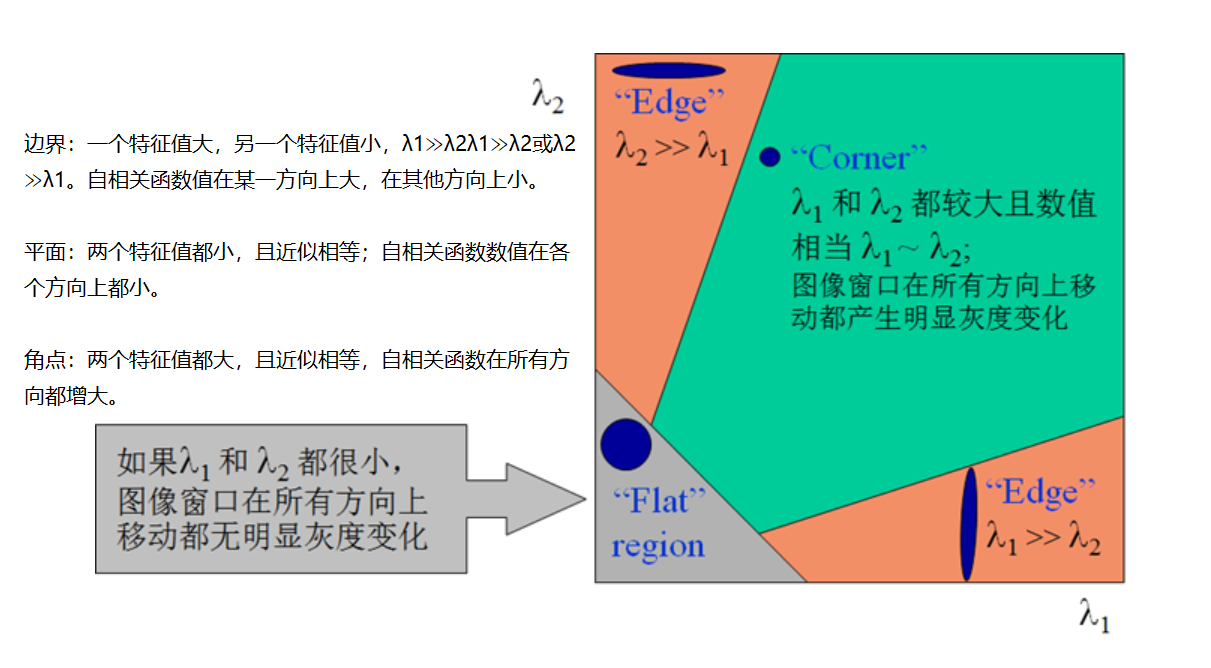

cv2.cornerHarris()
- img: Imagen de entrada con tipo de datos float32
- blockSize: el tamaño del área especificada en la detección de esquinas
- ksize: tamaño de ventana utilizado en la derivación de Sobel
- k: El valor del parámetro es [0,04,0.06]
import cv2
import numpy as np
import matplotlib.pyplot as plt#Matplotlib是RGB
img = cv2.imread('chessboard.jpg')
print ('img.shape:',img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print ('dst.shape:',dst.shape)
img.shape: (512, 512, 3)
dst.shape: (512, 512)
def cv_show(img,name):
b,g,r = cv2.split(img)
img_rgb = cv2.merge((r,g,b))
plt.imshow(img_rgb)
plt.show()
def cv_show1(img,name):
plt.imshow(img)
plt.show()
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
img[dst>0.01*dst.max()]=[255,255,255]
cv_show(img,'dst')
# cv2.imshow('dst',img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()

coincidencia de características
Emparejamiento de fuerza bruta
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
img1 = cv2.imread('box.png', 0)
img2 = cv2.imread('box_in_scene.png', 0)
def cv_show(img,name):
b,g,r = cv2.split(img)
img_rgb = cv2.merge((r,g,b))
plt.imshow(img_rgb)
plt.show()
def cv_show1(img,name):
plt.imshow(img)
plt.show()
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
cv_show1(img1,'img1')

cv_show1(img2,'img2')

sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# crossCheck表示两个特征点要互相匹,例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是
#NORM_L2: 归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True) #蛮力匹配
partido 1 a 1
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)#排序
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None,flags=2)
cv_show(img3,'img3')

k mejores partidos
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)#1对K匹配
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
cv_show(img3,'img3')

Si necesita completar la operación más rápido, puede intentar usar cv2.FlannBasedMatcher
Algoritmo de consenso de muestra aleatoria (RANSAC)
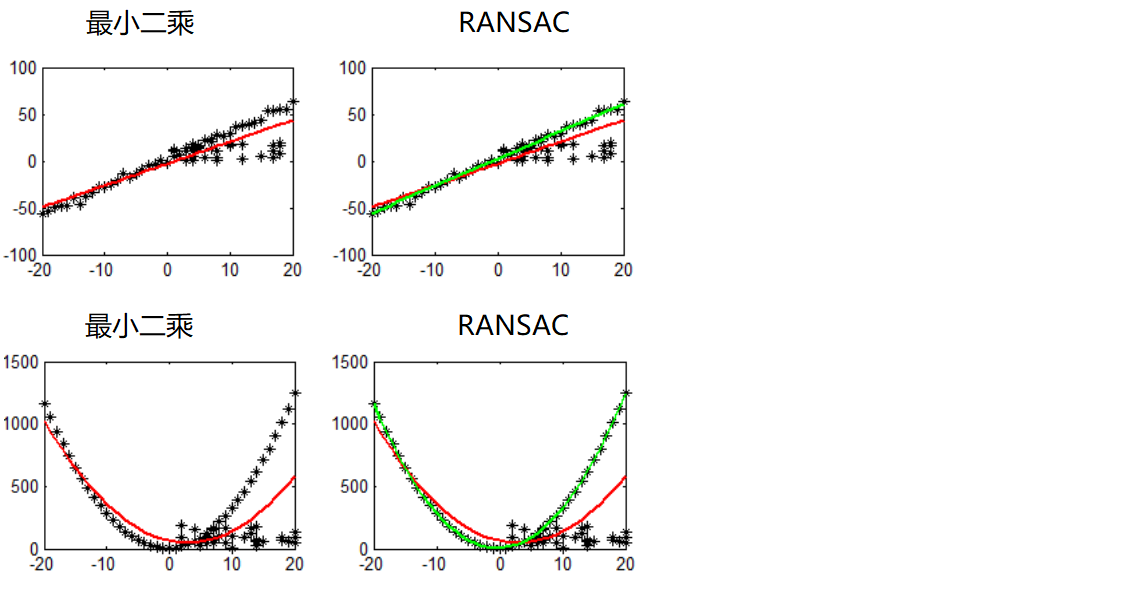
Seleccione puntos de muestra iniciales para el ajuste, proporcione un rango de tolerancia y continúe iterando
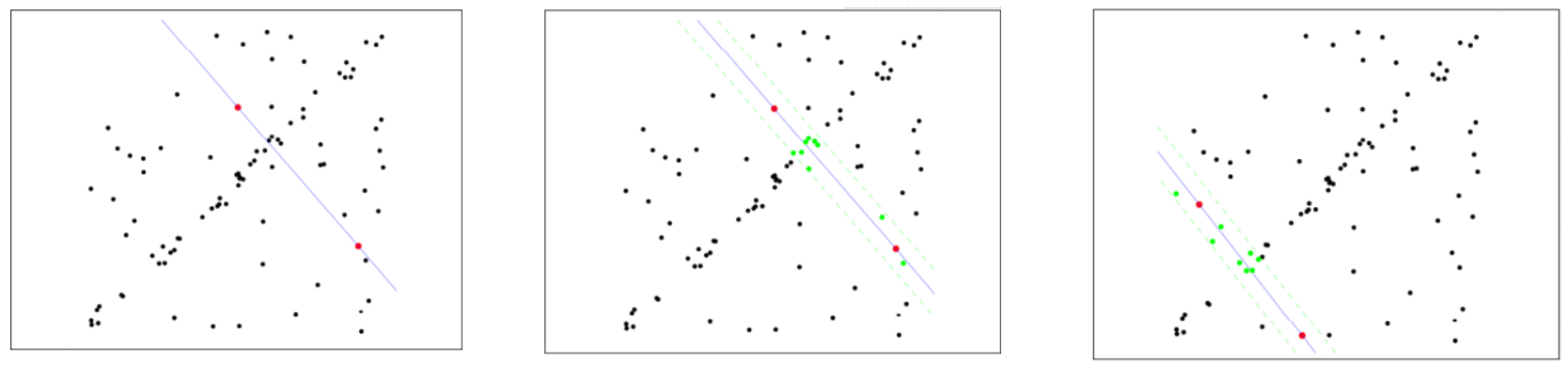
Después de cada ajuste, habrá un número correspondiente de puntos de datos dentro del rango de tolerancia. Encuentre la situación con el mayor número de puntos de datos, que es el resultado final del ajuste.
matriz de homografía