Con el rápido desarrollo de la tecnología, nos encontramos en una era de explosión de datos. Como importante lugar de almacenamiento y procesamiento de datos, el número de centros de datos a hiperescala crece constantemente y la cantidad de datos que los acompañan también crece exponencialmente. Esto incluye no sólo datos brutos, sino también datos analizados y procesados. El aumento en el volumen de datos ha planteado mayores requisitos para la capacidad de almacenamiento y las capacidades de procesamiento y análisis de los centros de datos. Al mismo tiempo, con la aplicación de varios nuevos medios y tecnologías de almacenamiento, aunque el rendimiento y la eficiencia del centro de datos han mejorado, la gestión del centro de datos también se ha vuelto más compleja. La mayor complejidad de la red también significa que la gestión y el mantenimiento de la red se vuelven más difíciles. Cómo lograr una implementación simple y un mantenimiento conveniente, al mismo tiempo que se reduce la carga de trabajo y los costos de tiempo y se mejora el rendimiento general del sistema y la experiencia del usuario, se ha convertido en un desafío importante al que se enfrentan los centros de datos de gran escala actuales.
Para el almacenamiento distribuido, implementar un clúster completo y utilizable generalmente implica cuatro pasos: configurar la información del nodo, implementar el clúster, instalar software de administración e inicializar escenarios de aplicaciones. Cualquier paso requiere la intervención del personal de implementación. Solo completando la información de configuración se puede garantizar la ejecución normal de este paso. Especialmente el paso de configuración de la información del nodo requiere que el personal de implementación se conecte a cada nodo para modificar el archivo de configuración de la red del nodo, lo que seriamente afecta al clúster. Eficiencia de la implementación. Cuando se implementan múltiples clústeres, la información de configuración no se puede reutilizar, lo que resulta en la duplicación del trabajo por parte de los implementadores. Para resolver estos problemas, Inspur Information propone un método de operación e implementación automática con un solo clic basado en plantillas de configuración.
Método de implementación tradicional versus implementación automática con un solo clic
El método de implementación tradicional requiere que el personal de implementación participe en todo el proceso y debe completar la información de configuración paso a paso para activar el proceso correspondiente, lo que tiene muchas desventajas:
- Los pasos son engorrosos e ineficientes : para garantizar que cada nodo del clúster pueda conectarse a través de la red, el implementador debe completar la información de la red del nodo uno por uno a través del teclado y el monitor;
- Alto grado de participación manual y respuesta inoportuna : Para mejorar la eficiencia de la implementación, los implementadores a menudo deben prestar mucha atención a la finalización de cada paso. Los implementadores deben intervenir antes de que comience cada paso y activar la ejecución después de completar la información de configuración necesaria;
- El contenido de la configuración no se puede reutilizar. En la mayoría de los casos, se realizan configuraciones repetidas : cuando se crean varios clústeres, a menudo hay poca diferencia entre cada clúster en términos de información de la red de nodos, implementación del clúster, instalación del software de administración e información de configuración completada en los escenarios de la aplicación de inicialización. ., pero al implementar cada clúster, toda la información debe completarse nuevamente y no se puede reutilizar la información de configuración;
Para mejorar la eficiencia de la implementación, reducir el trabajo repetitivo y lograr la reutilización de la información de configuración entre clústeres, Inspur Information propone un método de operación e implementación automática con un solo clic basado en archivos de configuración: integre toda la información de configuración en el archivo de configuración y luego importe el archivo de configuración A uno de los nodos, el nodo completa automáticamente el análisis del archivo de plantilla, la interacción y configuración de la información de configuración del nodo, la implementación del clúster, la instalación del software de administración y los procesos de inicialización de la escena se activan automáticamente, evitando los pasos intermedios de espera. para que caduque la configuración manual y acorte el proceso de implementación. Se dedica el tiempo total, automatizando así la implementación del clúster.
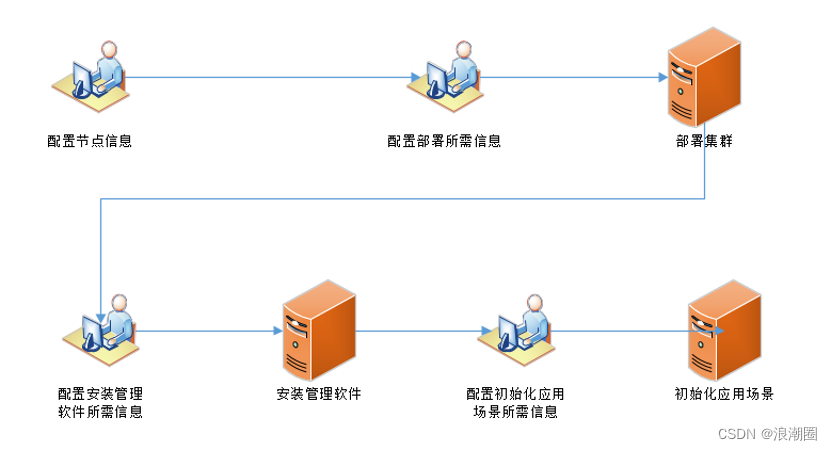
Diagrama de flujo de participación manual del método de implementación tradicional
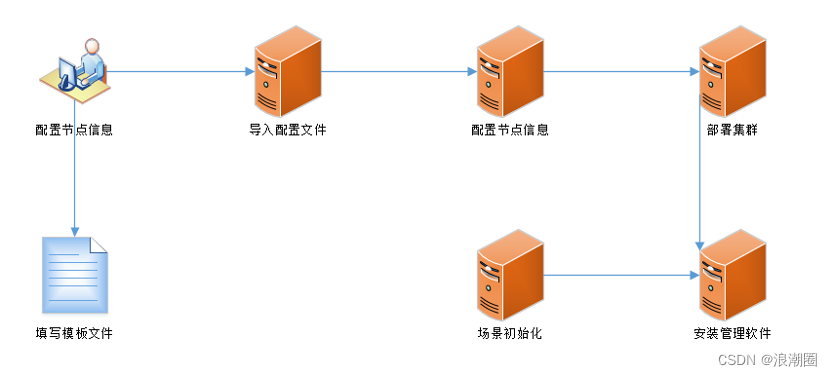
Diagrama de flujo de participación manual del método de implementación con un clic
Simplifique el proceso de configuración y mejore la eficiencia de la configuración.
La configuración de la información del nodo reemplaza el modo de interacción "humano-computadora" con la interacción entre nodos. Los nodos implementan la comunicación entre nodos a través del protocolo LLDP y transmiten información de la red del nodo. Cada nodo completa automáticamente la configuración de la información del nodo después de recibir la información. Tomemos como ejemplo la configuración de un clúster de 200 nodos:
| Implementación tradicional |
Implementación con un solo clic |
|
| Configurar la información del nodo |
200 nodos * 2 min/nodo = 400 min |
-- |
| Implementar clúster |
120min |
120min |
| Instalar software de gestión |
15 minutos |
15 minutos |
| Inicializar escenas usadas |
20 minutos |
20 minutos |
| Complete la plantilla de configuración |
-- |
30 minutos |
| Tiempo total invertido |
555 minutos |
185 minutos |
Admite el modo de implementación de línea de comando
El método de implementación tradicional se basa en el modo B / S. Solo puede completar la implementación del clúster, la instalación del software de administración y las operaciones de inicialización ingresando información de configuración en la página del navegador. Además de admitir la implementación de la página, la implementación con un solo clic también proporciona un método de implementación de línea de comando: puede cargar la información de la plantilla configurada en el nodo y luego usar el archivo de configuración como parámetro para ejecutar el comando en el nodo para completar el clúster. construcción, reduciendo así el tiempo requerido para construir el cluster.
Configure una vez y reutilice la información de configuración en múltiples clústeres
Durante la implementación en el sitio, a excepción de la información de la red del nodo, las otras configuraciones en diferentes sitios de usuarios son básicamente las mismas. Después de completar el llenado del archivo, se pueden realizar ajustes al implementar clústeres en diferentes sitios de clientes para lograr la reutilización de los archivos de configuración y evitar el llenado repetido de la información de configuración.
Como uno de los principales fabricantes de almacenamiento del mundo, Inspur Information se adhiere al concepto de "almacenamiento extremo, sabiduría incontable", se centra en los cambios en las necesidades de los clientes y reduce la complejidad del almacenamiento y los costos de mantenimiento a través de la exploración e innovación tecnológicas continuas, brindando a las empresas servicios más estables. Los servicios de almacenamiento inteligente y de alto rendimiento enriquecen las funciones del producto y hacen que su uso sea más eficiente. En el futuro, Inspur Information continuará acelerando la investigación, el desarrollo y la innovación de las funciones del sistema de almacenamiento, ayudará a los usuarios de miles de industrias en su transformación digital y liberará plenamente el valor de los datos.