Tabla de contenido
2. Nsys y NSight analizan el rendimiento del modelo
3. Cargue el modelo QAT y analice la optimización subyacente de TRT.
4. Utilice la poligrafía para analizar el modelo.
5. Operación práctica: utilice TensorRT para optimizar el modelo
Establecer diferentes estrategias de cuantificación para VGG
Vista previa del próximo contenido:
Implementación del modelo de aprendizaje profundo Aceleración OpenVINO
1. Análisis TensorRT
Análisis del rendimiento de inferencia del modelo: utilice herramientas como TensorRT Profiler, PyTorch Profiler, TensorFlow Profiler, etc. para realizar un análisis detallado del rendimiento de inferencia del modelo, incluido el tiempo de inferencia, el uso de memoria, el rendimiento y otros indicadores. Estas herramientas pueden ayudar a identificar cuellos de botella en el modelo para optimizar el modelo y la configuración del sistema.
Perfiles de PyTorch :
-
PyTorch Profiler es una herramienta de análisis de rendimiento proporcionada por el marco PyTorch, que se utiliza para evaluar y optimizar el rendimiento de los modelos PyTorch.
-
Proporciona un análisis de rendimiento detallado de la ejecución del modelo, incluida información sobre propagación hacia adelante, propagación hacia atrás, carga de datos, uso de memoria y más.
PyTorch Profiler también proporciona algunas funciones, como análisis de tensor, utilización de GPU, asignación de memoria, etc., para ayudar a comprender el rendimiento del modelo durante el entrenamiento y la inferencia.
import torch
from torch.profiler import profile, record_function, ProfilerActivity
# 定义PyTorch模型和示例输入
model = ...
input_data = ...
# 使用PyTorch Profiler进行性能分析
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], record_shapes=True) as prof:
with record_function("推理"):
# 执行推理过程
output = model(input_data)
print(prof.key_averages().table(sort_by="self_cpu_time_total")) En el código anterior, utilizamos PyTorch Profiler para el análisis de rendimiento. Al empaquetar bloques de código en profileun administrador de contexto, podemos registrar datos de rendimiento. activitiesLos parámetros especifican el tipo de actividad que debe registrarse, como CPU y CUDA. Al utilizar record_functionadministradores de contexto, podemos marcar bloques de código críticos en los resultados de la creación de perfiles. Finalmente, prof.key_averages().table()imprima la tabla de datos de rendimiento registrada por Profiler llamando a la función.
Perfilador TensorRT:
#include <iostream>
#include <NvInfer.h>
#include <NvInferProfiler.h>
int main()
{
// 创建TensorRT的Profiler对象
nvinfer1::Profiler profiler;
// 创建TensorRT的Builder对象和NetworkDefinition对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
nvinfer1::INetworkDefinition* network = builder->createNetwork();
// 设置Profiler对象到Builder中
builder->setProfiler(&profiler);
// 构建TensorRT的Engine
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
// 创建TensorRT的执行上下文
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
// 进行推理,性能数据会被Profiler记录
context->enqueue(...); // 填充输入数据并执行推理
// 打印Profiler记录的性能数据
profiler.print(std::cout);
// 释放资源
context->destroy();
engine->destroy();
network->destroy();
builder->destroy();
return 0;
}Impresión TRT con estructura de red optimizada y precisión
Al utilizar la API TensorRT de Python, puede utilizar los objetos tensorrt.IBuildery tensorrt.INetworkDefinitionpara obtener información optimizada de la estructura de la red y utilizar scripts de Python para evaluar la precisión.
import tensorrt as trt
# Step 1: 创建Logger对象
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# Step 2: 创建Builder对象和Network对象
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network:
# Step 3: 使用ONNX解析器解析模型
with trt.OnnxParser(network, TRT_LOGGER) as parser:
model_path = "resnet18.onnx"
with open(model_path, "rb") as model:
parser.parse(model.read())
# Step 4: 配置推理引擎
builder.max_workspace_size = 1 << 30 # 设置最大工作空间大小为1GB
engine = builder.build_cuda_engine(network)
# Step 5: 打印网络结构信息
print("TensorRT optimized network:")
print(network.num_layers, " layers in the network.")
# Step 6: 精度评估
# 进行推理并与原始模型的推理结果进行比较
# ...
print("TensorRT engine created successfully!") En TensorRT, puede nvinfer1::ICudaEngineobtener información optimizada de la estructura de la red a través de objetos y también puede evaluar la precisión del modelo comparando los resultados de la inferencia antes y después de la optimización.
#include <iostream>
#include <NvInfer.h>
#include <NvOnnxParser.h>
int main() {
// Step 1: 创建Logger对象
nvinfer1::ILogger* logger = new nvinfer1::ILogger(nvinfer1::ILogger::Severity::kWARNING);
// Step 2: 创建Builder对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(*logger);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// Step 3: 使用ONNX解析器解析模型
nvinfer1::IOnnxParser* parser = nvinfer1::createParser(*network, *logger);
const char* model_path = "resnet18.onnx";
parser->parseFromFile(model_path, static_cast<int>(nvinfer1::ILogger::Severity::kWARNING));
// Step 4: 配置推理引擎
builder->setMaxWorkspaceSize(1 << 30); // 设置最大工作空间大小为1GB
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
// Step 5: 打印网络结构信息
std::cout << "TensorRT optimized network:" << std::endl;
std::cout << network->getNbLayers() << " layers in the network." << std::endl;
// Step 6: 释放资源
network->destroy();
parser->destroy();
builder->destroy();
std::cout << "TensorRT engine created successfully!" << std::endl;
return 0;
}
Obtenga network->getNbLayers()la cantidad de capas de red optimizadas e imprima la información de la estructura de la red.
En cuanto a la evaluación de la precisión, normalmente es necesario utilizar datos de inferencia para la inferencia y compararlos con los resultados de la inferencia del modelo original. Tenga en cuenta que, dado que TensorRT optimiza la red, la precisión optimizada puede ser ligeramente diferente a la del modelo original. En algunos casos, para mejorar la precisión, es posible que sea necesario realizar más entrenamiento (ajuste fino) del modelo optimizado.
2. Nsys y NSight analizan el rendimiento del modelo
NSys y NSight son herramientas proporcionadas por NVIDIA para analizar el rendimiento y la depuración de las aplicaciones GPU. Pueden proporcionar información sobre los cuellos de botella en el rendimiento y el potencial de optimización de los modelos de aprendizaje profundo. Aquí hay una breve introducción a NSys y NSight:
-
NSys:
-
NSys es una herramienta de análisis de rendimiento de línea de comandos que se utiliza para analizar el rendimiento y la utilización de recursos de las aplicaciones GPU.
-
Puede proporcionar información sobre varios indicadores de la GPU, como el rendimiento informático, el uso de la memoria, la utilización del ancho de banda, etc.
-
NSys también admite múltiples modos de análisis, incluida la vista de línea de tiempo, vista estadística, etc., para ayudar a realizar un análisis en profundidad y comprender el rendimiento de la aplicación.
-
-
NSight:
-
NSight es un entorno de desarrollo integrado (IDE) para el desarrollo de GPU, que incluye componentes como NSight Systems y NSight Compute.
-
NSight Systems se utiliza para analizar y optimizar el rendimiento general de las aplicaciones GPU, proporcionando vista de línea de tiempo, seguimiento de pila de llamadas, uso de recursos y otras funciones.
-
NSight Compute se utiliza para analizar y optimizar el rendimiento de las aplicaciones CUDA, proporcionando análisis a nivel de instrucción, análisis del núcleo, utilización de recursos y otras funciones.
-
NSight también proporciona funciones de depuración de GPU, incluida la depuración de puntos de interrupción, visualización de variables, seguimiento de acceso a la memoria, etc.
-
Para utilizar NSight Systems y las herramientas NSight Compute, debe asegurarse de que el controlador NVIDIA y el paquete de software NSight estén instalados y configurados correctamente, y que el código se ejecute en una GPU NVIDIA habilitada para CUDA. Al realizar un análisis de rendimiento, se recomienda establecer el volumen de datos y el número de iteraciones lo suficientemente pequeños para obtener resultados rápidamente y realizar ajustes.
Enlace de referencia: (262 mensajes) Introducción y uso de NVIDIA Nsight Systems_Blog-CSDN de AliceWanderAI
3. Cargue el modelo QAT y analice la optimización subyacente de TRT.
La tecnología QAT (Quantization-Aware Training) es un método de entrenamiento para la cuantificación de modelos de aprendizaje profundo . Su propósito es considerar el impacto de la cuantificación en el rendimiento del modelo durante el proceso de entrenamiento del modelo, de modo que el modelo aún pueda mantener una buena precisión después de la cuantificación.
La cuantificación del modelo tradicional se realiza una vez completado el entrenamiento, convirtiendo el modelo de punto flotante entrenado en un modelo de baja precisión (como INT8 o INT4). Sin embargo, dado que la cuantificación introducirá errores de cuantificación, este método puede provocar una disminución de la precisión.
La tecnología QAT permite que el modelo se adapte a entornos de razonamiento de baja precisión al introducir errores de cuantificación durante el proceso de entrenamiento y utilizar métodos de cálculo de cuantificación simulados. En concreto, la tecnología QAT incluye principalmente los siguientes pasos:
-
Función de pérdida relacionada con la cuantificación: durante el proceso de entrenamiento del modelo, se introduce una función de pérdida relacionada con la cuantificación para considerar el impacto del error de cuantificación en la precisión del modelo. De esta forma, el modelo se irá adaptando gradualmente a las características de baja precisión durante el proceso de entrenamiento.
-
Cálculo de cuantificación simulado: durante el proceso de propagación hacia adelante, los valores de activación y los valores de peso se simulan y cuantifican con una precisión baja especificada. De esta manera, el modelo puede obtener características cuantificadas durante el proceso de entrenamiento y reducir la pérdida de precisión causada por la cuantificación.
-
Cuantización dinámica: durante el proceso de entrenamiento, el método de cuantificación dinámica se puede utilizar para ajustar dinámicamente los parámetros de cuantificación, como el rango de cuantificación o el factor de escala, para adaptarse mejor a los cambios en los datos.
La ventaja de la tecnología QAT es que puede optimizar el efecto de cuantificación del modelo durante el proceso de entrenamiento y reducir la pérdida de precisión después de la cuantificación, logrando así un mayor rendimiento y un tamaño de modelo más pequeño durante la inferencia. Dado que la tecnología QAT tiene en cuenta el error en el proceso de cuantificación, las características cuantificadas se pueden integrar en el modelo durante el entrenamiento, en lugar de simplemente convertir el modelo de punto flotante entrenado en un modelo cuantificado.
Para cargar un modelo QAT (Quantization Aware Training) y analizar las optimizaciones subyacentes de TensorRT, se requieren los siguientes pasos:
-
Cree un motor TensorRT y cargue el modelo QAT: use la API C++ o Python de TensorRT para crear un motor TensorRT basado en el modelo QAT.
-
Ejecute el modelo QAT: utilice el motor TensorRT para realizar inferencias en el modelo QAT, que se puede realizar ingresando datos de simulación.
-
Analice la optimización de TensorRT: utilice herramientas como NSight Systems y NSight Compute para realizar un análisis de rendimiento a nivel de sistema y a nivel de kernel de la inferencia de TensorRT para ver el efecto de optimización subyacente de TensorRT.
Código de implementación:
El uso de la tecnología QAT en PyTorch se puede torch.quantization.quantize_dynamicimplementar mediante funciones de PyTorch.
import torch
import torchvision
import torch.quantization
# Step 1: 加载训练数据和模型
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
model = torchvision.models.resnet18(pretrained=True)
model.eval() # 将模型设置为评估模式
# Step 2: 量化感知训练
qat_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
# Step 3: 训练模型
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(qat_model.parameters(), lr=0.001, momentum=0.9)
for epoch in range(5):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
# 使用量化感知训练的模型进行前向传播
outputs = qat_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(train_loader)}")
# Step 4: 导出量化感知训练后的模型
torch.save(qat_model.state_dict(), "qat_model.pth")
Código de implementación de C++:
#include <iostream>
#include <NvInfer.h>
#include <NvOnnxParser.h>
int main() {
// Step 1: 创建Logger对象
nvinfer1::ILogger* logger = new nvinfer1::ILogger(nvinfer1::ILogger::Severity::kWARNING);
// Step 2: 创建Builder对象和Network对象
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(*logger);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// Step 3: 使用ONNX解析器解析QAT模型
nvinfer1::IOnnxParser* parser = nvinfer1::createParser(*network, *logger);
const char* model_path = "qat_model.onnx";
parser->parseFromFile(model_path, static_cast<int>(nvinfer1::ILogger::Severity::kWARNING));
// Step 4: 配置推理引擎
builder->setMaxWorkspaceSize(1 << 30); // 设置最大工作空间大小为1GB
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
// Step 5: 分析TensorRT优化
// 使用NSight Compute等工具对TensorRT推理进行性能分析
// ...
// Step 6: 释放资源
network->destroy();
parser->destroy();
builder->destroy();
std::cout << "TensorRT engine created successfully!" << std::endl;
return 0;
}
4. Utilice la poligrafía para analizar el modelo.
Polygraphy es una herramienta de código abierto para la inferencia y optimización de modelos de aprendizaje profundo. Proporciona funciones ricas, que incluyen conversión de modelos, análisis de rendimiento de inferencia, visualización de modelos, comparación de modelos y evaluación de la precisión de la inferencia.
pip install polygraphySuponemos que ya tenemos un archivo de modelo (como un archivo de motor ONNX o TensorRT) y queremos usar Polygraphy para analizar el rendimiento de inferencia del modelo.
-
Análisis de rendimiento de inferencia:
Utilice
polygraphy runcomandos para analizar el rendimiento de inferencia del modelo. El siguiente es un ejemplo sencillo que demuestra cómo utilizar Polygraphy para el análisis del rendimiento de inferencia del motor TensorRT:polygraphy run trt_engine.engine --benchEl comando anterior realizará
trt_engine.engineun análisis del rendimiento de la inferencia en el archivo del motor TensorRT denominado y generará información estadística sobre el rendimiento de la inferencia. -
Más características:
La poligrafía también proporciona muchas otras funciones, como conversión de modelos, evaluación de la precisión de la inferencia, comparación y visualización de modelos, etc. Se pueden utilizar diferentes subcomandos para realizar estas funciones. Por ejemplo:
polygraphy convertLas transformaciones del modelo se pueden realizar mediante comandos.- Utilice
polygraphy accuracyel comando para evaluar la precisión de la inferencia del modelo. - Utilice
polygraphy comparecomandos para comparar el rendimiento y la precisión entre diferentes modelos o motores de inferencia. - Utilice
polygraphy visualizecomandos para visualizar el modelo. - Puede utilizar
polygraphy --helpel comando para ver todos los subcomandos y opciones disponibles, así como los métodos de uso específicos.
Tenga en cuenta que Polygraphy es una herramienta poderosa y flexible que se puede configurar y ajustar de muchas maneras según sus necesidades. Para casos de uso más complejos, puede consultar la documentación oficial de Polygraphy para obtener información y ejemplos más detallados.
Enlace de referencia: (262 mensajes) Tutorial de instalación de poligrafía_blog de cosas técnicas-blog CSDN
Polygraphy es una herramienta de depuración de modelos de aprendizaje profundo que incluye API de Python y herramientas de línea de comandos. Sus funciones son las siguientes:
-
Utilice una variedad de backends para ejecutar cálculos de inferencia, incluidos TensorRT, onnxruntime y TensorFlow;
-
Compare los resultados del cálculo capa por capa de diferentes backends;
-
El motor TensorRT se genera a partir del modelo y se serializa en .plan;
-
Ver información capa por capa de la red modelo;
-
Modificar el modelo Onnx, como extraer subgrafos y simplificar el gráfico de cálculo;
-
Analice las razones del fracaso al convertir Onnx a TensorRT y divida y guarde los subgráficos en el gráfico de cálculo original que se pueden o no convertir a TensorRT;
-
Aislar la táctica de error del terminal TensorRT;
Ejemplo de uso:
polygraphy run yawn_224.onnx --onnxrt --trt --workspace 256M --save-engine yawn-test.plan --fp16 --verbose --trt-min-shapes 'data:[1,3,224,224]' --trt-opt-shapes 'data:[3,3,224,224]' --trt-max-shapes 'data:[8,3,224,224]' > test.txt
# 命令解析
polygraphy run yawn_224.onnx # 使用onnx模型
--onnxrt --trt # 使用 onnxruntime 和 trt 后端进行推理
--workspace 256M # 使用256M空间用于生成.plan 文件
--save-engine yawn-test.plan # 保存文件
--fp16 # 开启fp16模式
--verbose # 显示生成细节
--trt-min-shapes 'data:[1,3,224,224]' # 设定 最小输入形状
--trt-opt-shapes 'data:[3,3,224,224]' # 设定 最佳输入形状
--trt-max-shapes 'data:[8,3,224,224]' # 设定 最大输入形状
> test.txt # 将终端显示重定向test.txt 文件中
复制代码resultado: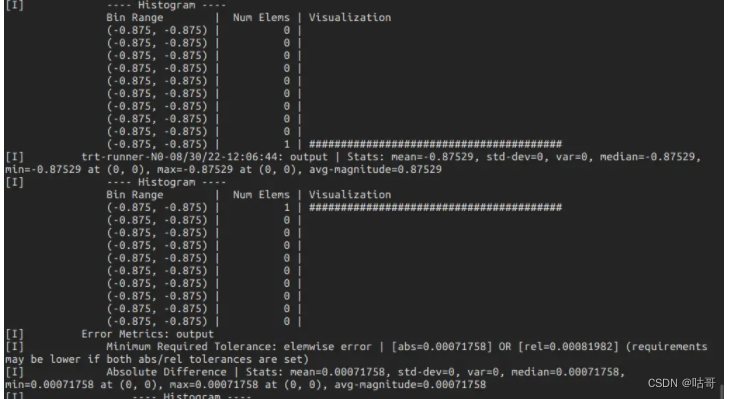
5. Operación práctica: utilice TensorRT para optimizar el modelo
Establecer diferentes estrategias de cuantificación para VGG
Puede utilizar la API y torch.quantizationlos módulos de cuantificación de PyTorch. PyTorch proporciona diferentes estrategias de cuantificación y opciones de configuración.
Código de muestra:
import torch
import torchvision
import torch.quantization
# Step 1: 加载VGG模型
model = torchvision.models.vgg16(pretrained=True)
model.eval() # 将模型设置为评估模式
# Step 2: 定义量化配置
# 可以设置不同层的量化配置,例如设置量化位数、量化范围等
quant_config = torch.quantization.default_qconfig
quant_config_dict = {
torch.nn.Conv2d: torch.quantization.default_qconfig,
torch.nn.Linear: torch.quantization.default_qconfig
}
# Step 3: 量化感知训练
qat_model = torch.quantization.quantize_dynamic(model, quant_config_dict, dtype=torch.qint8)
# Step 4: 导出量化感知训练后的模型
torch.save(qat_model.state_dict(), "qat_vgg_model.pth")
5.2.2 Construir un módulo de autoatención y diferentes versiones de TRT para optimizar la atención
Código:
import torch
import torch.nn as nn
import tensorrt as trt
import numpy as np
# Step 1: 构建Self-Attention模块
class SelfAttention(nn.Module):
def __init__(self, in_channels, key_channels, value_channels):
super(SelfAttention, self).__init__()
self.key_channels = key_channels
self.value_channels = value_channels
self.query = nn.Conv2d(in_channels, key_channels, kernel_size=1)
self.key = nn.Conv2d(in_channels, key_channels, kernel_size=1)
self.value = nn.Conv2d(in_channels, value_channels, kernel_size=1)
def forward(self, x):
query = self.query(x)
key = self.key(x)
value = self.value(x)
attention_map = torch.matmul(query.view(query.size(0), self.key_channels, -1).permute(0, 2, 1),
key.view(key.size(0), self.key_channels, -1))
attention_map = nn.functional.softmax(attention_map, dim=-1)
out = torch.matmul(attention_map, value.view(value.size(0), self.value_channels, -1))
out = out.view(x.size(0), self.value_channels, *x.size()[2:])
return out
# Step 2: 创建示例输入并导出模型为ONNX格式
model = SelfAttention(in_channels=64, key_channels=32, value_channels=32)
x = torch.randn(1, 64, 32, 32)
onnx_file = "self_attention.onnx"
torch.onnx.export(model, x, onnx_file, opset_version=11)
# Step 3: 使用TensorRT优化模型
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
with open(onnx_file, "rb") as model:
parser.parse(model.read())
builder.max_workspace_size = 1 << 30
engine = builder.build_cuda_engine(network)
# Step 4: 保存优化后的模型
trt_file = "self_attention.trt"
with open(trt_file, "wb") as f:
f.write(engine.serialize())
print("TensorRT engine created successfully and saved as:", trt_file)
Resumir:
Después de estudiar todo el artículo, creo que domina todo el proceso de desarrollo de tensorrt. Puede utilizar diferentes soluciones de optimización para mejorar el modelo de manera específica. Si necesita ampliar sus conocimientos más profundamente, deje un mensaje y comuníquese entre ellos. ¡Muchas gracias! ! ! !
PD: Es puramente para aprender y compartir experiencias, y no participa en operaciones de valor comercial. Si hay alguna infracción, ¡contáctenos a tiempo! ! !
Vista previa del próximo contenido:
-
Implementación del modelo de aprendizaje profundo Aceleración OpenVINO