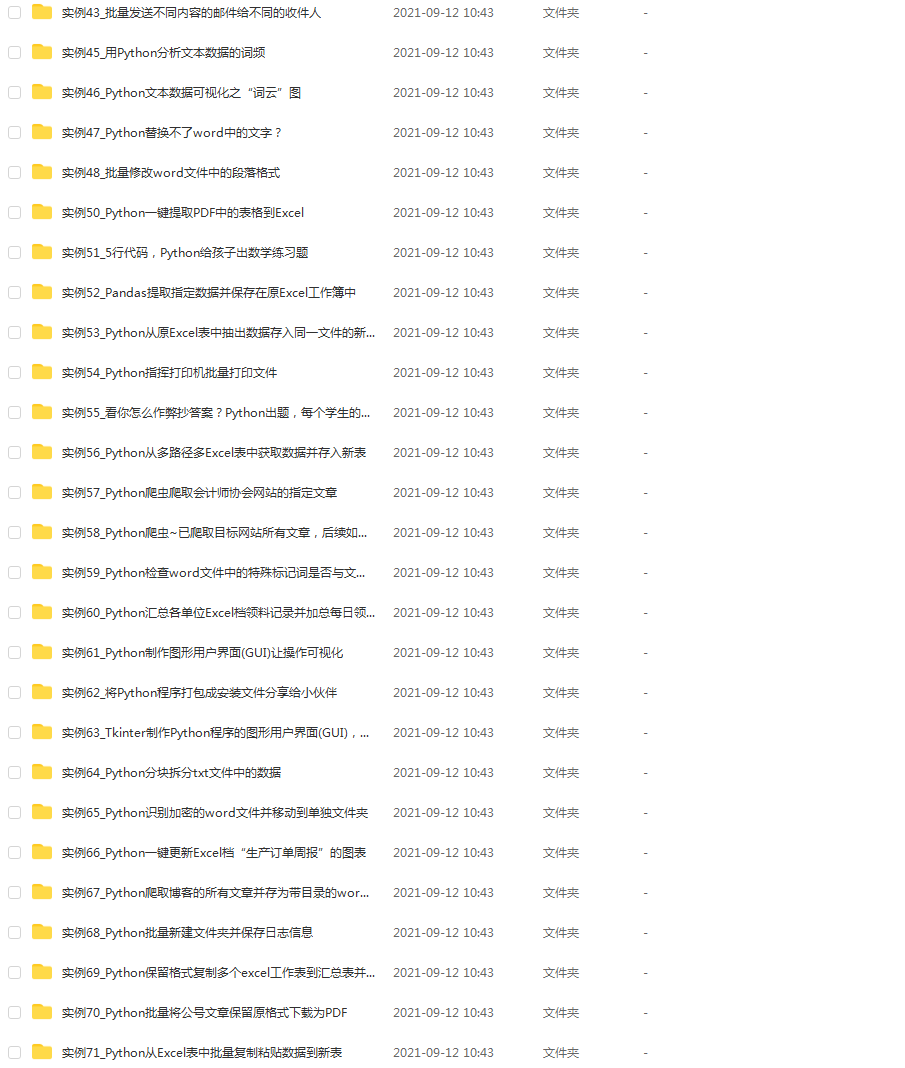
- 꼭 읽어야 할 목록 -
많은 책이나 튜토리얼은 필요하지 않습니다.파이썬 크롤러에 관해서는 이 8권이면 충분합니다.





- 웹사이트 블로그 -

본 프로젝트는 주요 웹사이트의 시뮬레이션된 로그인 방법 및 크롤러 프로그램을 연구하고 공유하기 위한 목적으로 주요 웹사이트의 일부 로그인 방법 및 일부 웹사이트의 크롤러 프로그램을 수집합니다.
URL: https://awesome-python

"Python3 웹 크롤러 및 개발 실습"의 저자는 이 블로그에서 자신의 크롤러 사례와 경험을 공유하며 내용이 매우 풍부합니다.
홈페이지: https://cuiqingcai.com
Scraping.pro

Scraping.pro는 전문 컬렉션 소프트웨어 평가 사이트로, scrapy, octoparse 등 다양한 해외 상위 컬렉션 소프트웨어 평가 글을 담고 있습니다.
홈페이지: http://www.scraping.com/
scraping.pro

와 비교하여 Kdnuggets는 비즈니스 분석, 빅 데이터, 데이터 마이닝, 데이터 과학 등을 포함하여 더 넓은 범위를 포괄합니다.
홈페이지: https://www.kdnuggets.com/
Octoparse

Octoparse는 강력한 무료 수집 소프트웨어로, 블로그에서 다양한 콘텐츠를 제공하고 이해하기 쉽기 때문에 예비 웹사이트 수집 사용자에게 더 적합합니다.
홈페이지: https://www.octoparse.com
빅데이터 뉴스

빅데이터 뉴스는 Kdnuggets와 유사하며 주로 빅데이터 산업을 다루고 있으며, 웹사이트 수집은 그 아래 하위 항목입니다.
홈페이지: https://www.bigdatanews
분석 Vidya

빅 데이터 뉴스와 유사하게 Analytics Vidhya는 데이터 과학, 기계 학습, 웹 사이트 수집 등을 다루는 보다 전문적인 데이터 수집 웹 사이트입니다.
웹사이트: https://www.analyticsvidhya
- 크롤러 프레임워크 -
긁힌

웹사이트 데이터를 크롤링하고 구조화된 데이터를 추출하기 위해 작성된 애플리케이션 프레임워크입니다. 데이터 마이닝, 정보 처리 또는 기록 데이터 저장을 포함한 일련의 프로그램에서 사용할 수 있습니다.
홈페이지: https://scrapy.org
파이스파이더

Pyspider는 Python으로 구현된 강력한 웹 크롤러 시스템으로, 스크립트를 작성하고, 기능을 예약하고, 브라우저 인터페이스에서 실시간으로 크롤링 결과를 볼 수 있습니다.
백엔드는 일반적으로 사용되는 데이터베이스를 사용하여 크롤링 결과를 저장하고 정기적으로 작업 및 작업 우선 순위를 설정할 수도 있습니다.
URL: https://pyspider
Crawley

Crawley는 해당 웹사이트의 콘텐츠를 고속으로 크롤링할 수 있고 관계형 및 비관계형 데이터베이스를 지원하며 데이터를 JSON, XML 등으로 내보낼 수 있습니다.
웹사이트: http://crawley-cloud.com/
Portia
Portia는 프로그래밍 지식 없이도 웹사이트를 크롤링할 수 있는 오픈 소스 시각적 크롤러 도구입니다!
홈페이지: https://portia
신문(Newspaper)
신문은 뉴스, 기사, 컨텐츠 분석을 추출하는 데 사용될 수 있습니다. 멀티스레딩 사용, 10개 이상의 언어 지원 등
홈페이지: https://newspaper
Beautiful Soup

Beautiful Soup은 HTML이나 XML 파일에서 데이터를 추출할 수 있는 Python 라이브러리입니다.
즐겨 사용하는 변환기를 통해 일반적인 문서 탐색, 검색 및 수정 방법을 사용할 수 있습니다.
URL: https://BeautifulSoup/bs4/doc/
Grab
Grab은 웹 스크래퍼를 구축하기 위한 Python 프레임워크입니다.
간단한 5줄 스크립트부터 수백만 개의 웹 페이지를 처리하는 복잡한 비동기 웹 사이트 스크레이퍼까지 다양한 복잡성의 웹 스크레이퍼를 구축할 수 있습니다.
URL: http://grab-spider-user-manual
Cola
Cola는 분산 크롤러 프레임워크로, 사용자는 분산 작업의 세부 사항에 신경 쓰지 않고 몇 가지 특정 기능만 작성하면 됩니다.
프로젝트 주소: https://github.com/chineking/cola
- 도구 -
(1)바이올린
Fiddler는 Windows 플랫폼에서 최고의 시각적 패킷 캡처 도구이자 가장 잘 알려진 HTTP 프록시 도구이기도 합니다.
이 기능은 매우 강력하며 각 요청과 응답을 명확하게 이해하는 것 외에도 중단점 설정, 요청 데이터 수정, 응답 내용 가로채기 등의 작업도 수행할 수 있습니다.
링크: https://www.telerik.com/fiddler
(2)찰스
Charles는 macOS 플랫폼에서 최고의 패킷 캡처 및 분석 도구 중 하나입니다.
또한 간단하고 간단한 GUI 인터페이스를 제공하며 기본 기능에는 HTTP 및 HTTPS 요청 패킷 캡처가 포함되어 있으며 요청 매개변수 수정을 지원합니다. 최신 Charles 4도 HTTP/2를 지원합니다.
링크: https://www.charlesproxy.com/
(3)애니프록시
AnyProxy는 NodeJS를 기반으로 구현된 Alibaba의 오픈 소스 HTTP 패킷 캡처 도구입니다.
장점은 보조 개발을 지원하고 요청 처리 논리를 사용자 정의할 수 있다는 것입니다.JS를 작성할 수 있고 일부 사용자 정의 처리가 필요한 경우 AnyProxy가 매우 적합합니다.
GitHub 주소: https://alibaba/anyproxy
(4)미트프록시
mitmproxy는 SSL을 지원하는 Python 기반의 패킷 캡처 도구입니다. 크로스 플랫폼이며 명령줄 대화형 모드를 제공합니다.
GitHub 주소: https://mitmproxy/
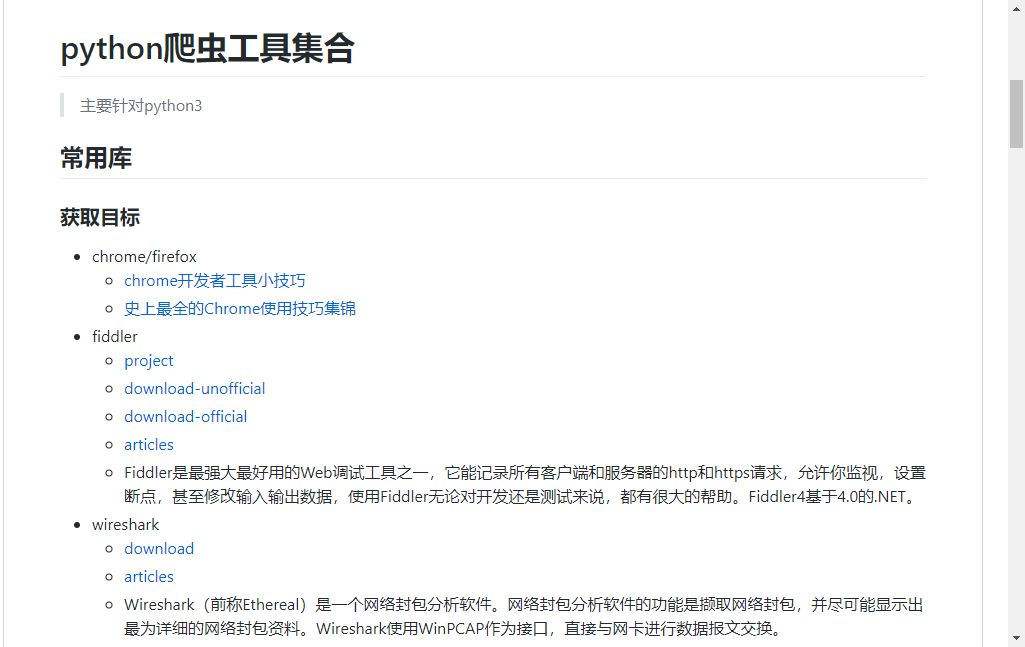
이것은 Python 크롤러용 도구 요약입니다. 여러분이 생각할 수 있는 거의 모든 것을 여기에서 찾을 수 있습니다.
URL: https://lartpang/spyder_tool
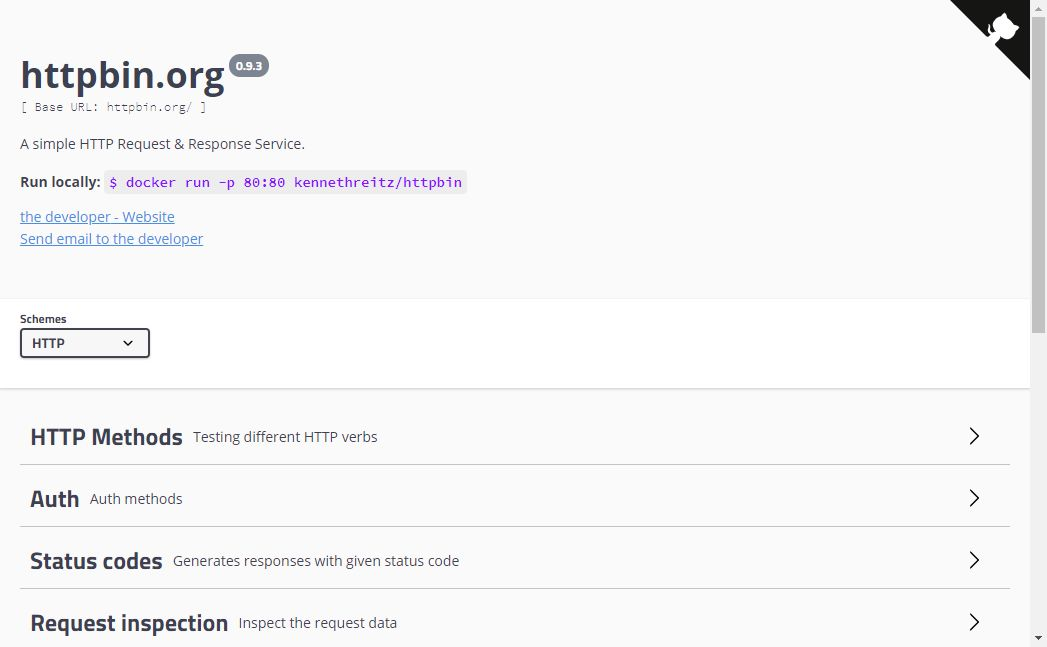
이 웹사이트는 크롤러 테스트(http 및 https)로 사용할 수 있으며, 크롤러 시스템에 대한 일부 정보를 반환하고 온라인 테스트에도 사용할 수 있습니다.
웹사이트: httpbin.org
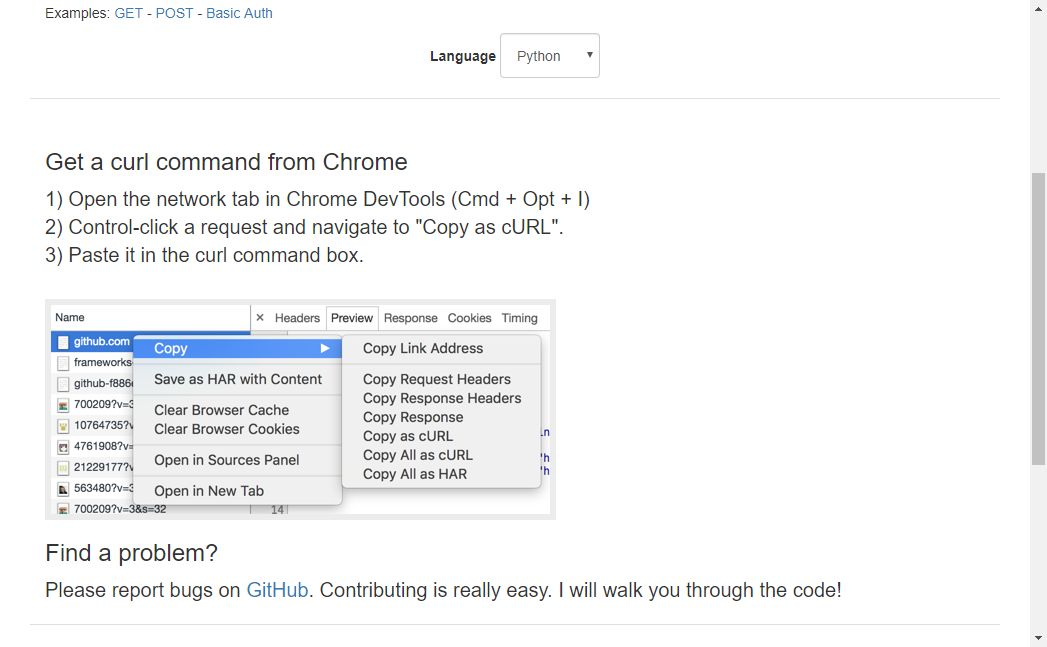
이 웹사이트는 컬 명령을 Python 요청으로 빠르게 변환할 수 있으며(다른 언어도 사용 가능), 컬 명령은 브라우저 개발자 도구를 통해 빠르게 얻을 수 있습니다.
웹사이트: https://curl.trillworks.com
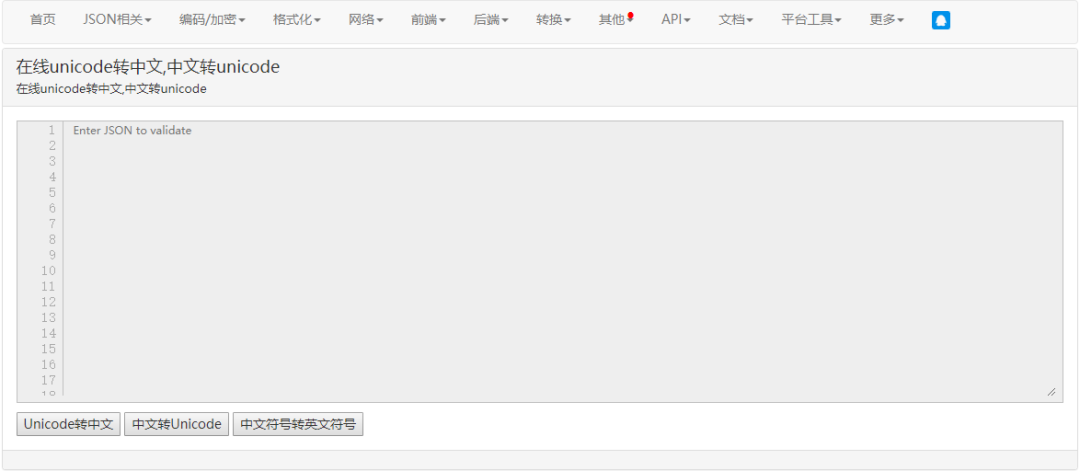
웹페이지에 중국어가 보이는 경우가 있는데, 웹페이지의 소스코드를 보면 유니코드 문자로 표시되는 경우가 있는데, 이런 경우에는 온라인에서 유니코드 문자를 중국어로 변환해 주어야 합니다.
URL: https://unicode_chinese/
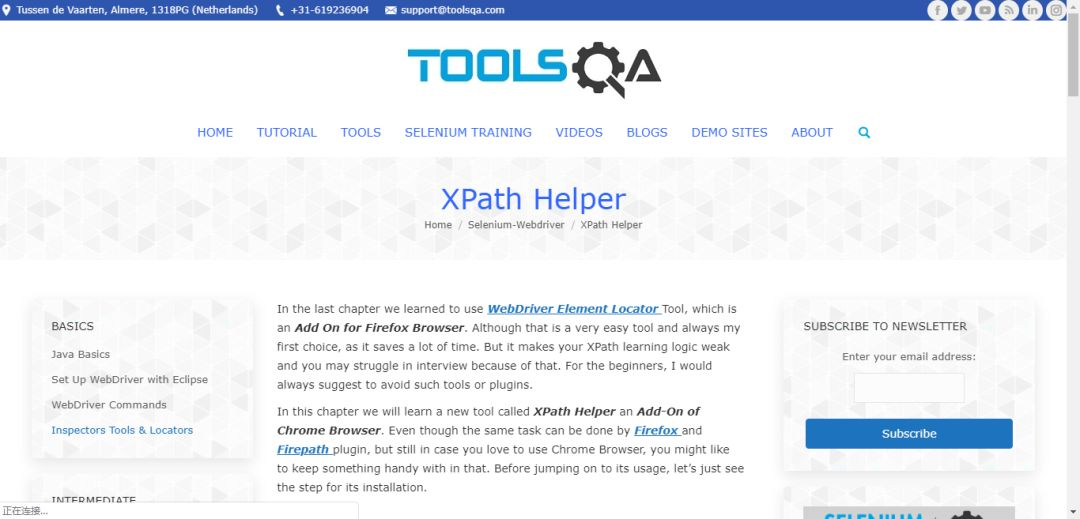
이 도구는 xpath 분석 및 디버깅을 지원하는 데 사용되는 크롬 확장입니다.
링크: https://xpath-helper/
마침내:
[크롤러를 배우고 싶은 분들을 위해 파이썬 학습자료를 많이 모아서 CSDN 공식에 올려두었습니다. 필요한 친구들은 아래 QR코드를 스캔하여 얻으실 수 있습니다.]
1. 연구개요
2. 개발 도구

3. 파이썬 기본 자료
4. 실제 데이터