 Fuente: juejin.cn/post/7114669787870920734
Fuente: juejin.cn/post/7114669787870920734
bucle foreach?
HashMap atraviesa la colección y elimina, coloca y agrega los elementos de la colección.
1. Fenómeno
2. Estudie los principios subyacentes en detalle.
Hace algún tiempo, cuando un colega estaba escaneando el código con KW, apareció este artículo:
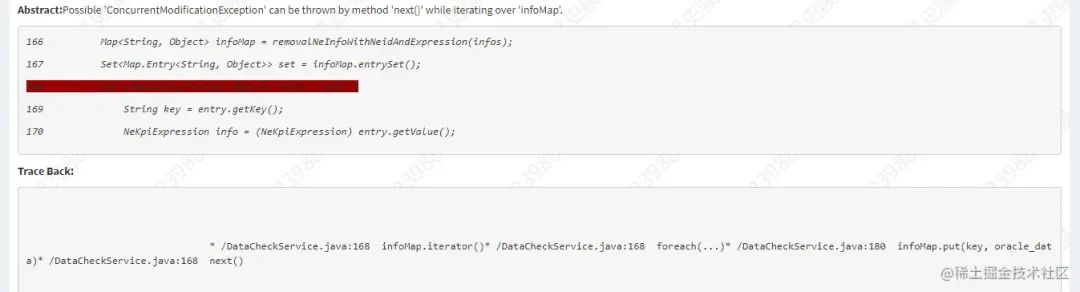
La razón de lo anterior es que cuando se usa foreach para atravesar HashMap, habrá problemas con la operación de asignación de colocación al mismo tiempo y se producirá la excepción ConcurrentModificationException.
Entonces Bangtong echó un vistazo breve y tuvo la impresión de que las clases de colección deben tener cuidado al eliminar o agregar operaciones al mismo tiempo durante el recorrido y, en general, usar iteradores para las operaciones.
Entonces les dije a mis colegas que se debería usar el iterador para operar en los elementos de la colección. Mis compañeros me preguntaron ¿por qué? ¿Esto de repente me confundió? Sí, acabo de recordar que no está permitido usarlo de esta manera, pero parece que nunca he investigado el motivo.
¡Así que hoy decidí estudiar detenidamente esta operación transversal de HashMap para evitar obstáculos!
bucle foreach?
La sintaxis foreach de Java es una nueva característica agregada en JDK 1.5. Se utiliza principalmente como una mejora de la sintaxis for. Entonces, ¿cómo se implementa su implementación subyacente? Miremos más de cerca:
Dentro de la sintaxis foreach, las colecciones se implementan mediante iteradores y las matrices se implementan mediante recorrido de subíndices. Los compiladores de Java 5 y superiores ocultan la implementación interna de iteración y recorrido de subíndices de matriz.
Nota: De lo que estamos hablando aquí es de que el "compilador Java" o el lenguaje Java oculta su implementación, no de que un determinado fragmento de código Java oculta su implementación, es decir, no podemos encontrarlo en ningún fragmento de JDK Java. código La implementación está oculta aquí. La implementación aquí está oculta en el compilador de Java. Mire el código de bytes compilado en un código Java para cada uno y adivine cómo se implementa.
Escribamos un ejemplo para estudiarlo:
public class HashMapIteratorDemo {
String[] arr = {
"aa",
"bb",
"cc"
};
public void test1() {
for (String str: arr) {}
}
}Convierta el ejemplo anterior en código de bytes y descompílelo (parte de la función principal):
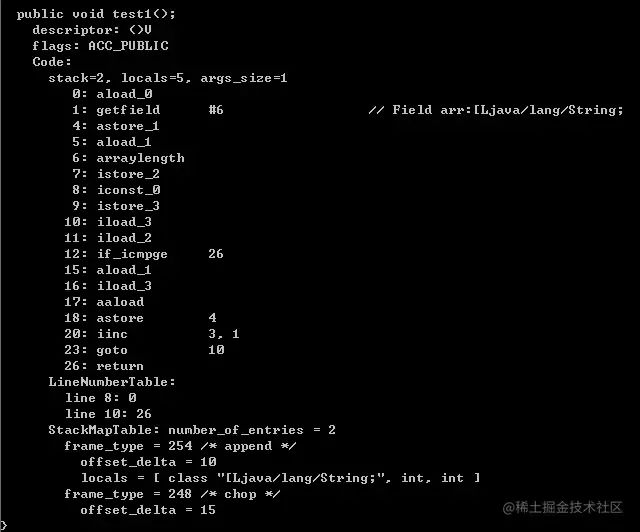
Quizás no sepamos exactamente qué hacen estas instrucciones, pero podemos comparar las instrucciones de código de bytes generadas por el siguiente código:
public class HashMapIteratorDemo2 {
String[] arr = {
"aa",
"bb",
"cc"
};
public void test1() {
for (int i = 0; i < arr.length; i++) {
String str = arr[i];
}
}
}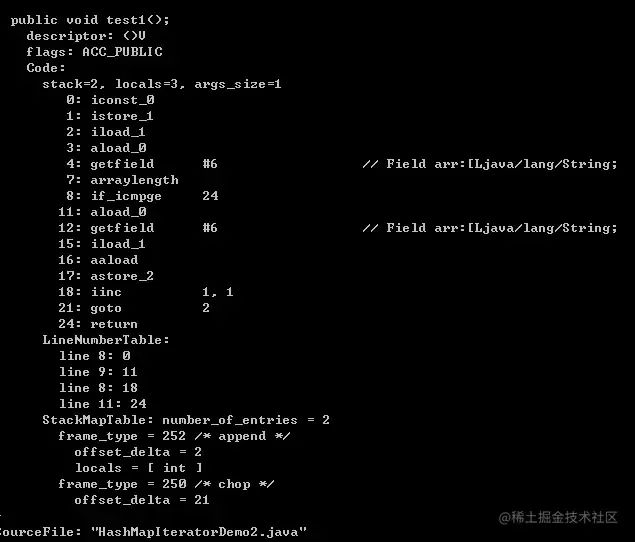
Eche un vistazo a los dos archivos de código de bytes. ¿Le parece que las instrucciones son casi las mismas? Si aún tiene preguntas, veamos la operación foreach en la colección:
Iterar a través de la colección con foreach:
public class HashMapIteratorDemo3 {
List < Integer > list = new ArrayList < > ();
public void test1() {
list.add(1);
list.add(2);
list.add(3);
for (Integer
var: list) {}
}
}Recorre la colección a través de Iterator:
public class HashMapIteratorDemo4 {
List < Integer > list = new ArrayList < > ();
public void test1() {
list.add(1);
list.add(2);
list.add(3);
Iterator < Integer > it = list.iterator();
while (it.hasNext()) {
Integer
var = it.next();
}
}
}Compare los códigos de bytes de los dos métodos de la siguiente manera:
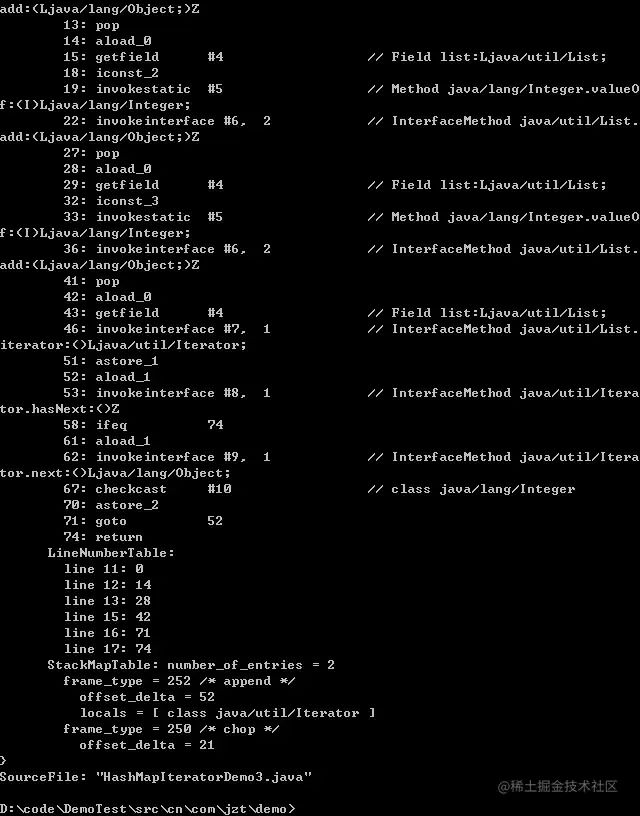
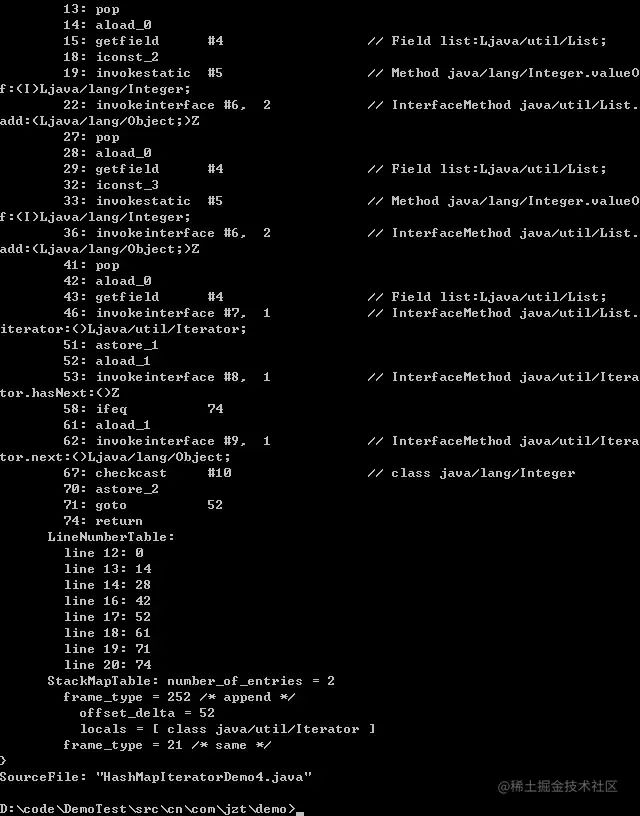
Descubrimos que las operaciones de instrucción de código de bytes de los dos métodos son casi idénticas;
De esto podemos sacar las siguientes conclusiones:
Para las colecciones, dado que todas las colecciones implementan Iterator, el compilador eventualmente convierte la sintaxis foreach en una llamada a Iterator.next();
Para las matrices, se convierte en una referencia circular a cada elemento de la matriz.
HashMap atraviesa la colección y elimina, coloca y agrega los elementos de la colección.
1. Fenómeno
Según el análisis anterior, sabemos que la capa inferior de HashMap implementa el iterador, por lo que en teoría también podemos usar iteradores para atravesar, lo cual es cierto, por ejemplo, de la siguiente manera:
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map < Integer, String > map = new HashMap < > ();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for (Map.Entry < Integer, String > entry: map.entrySet()) {
int k = entry.getKey();
String v = entry.getValue();
System.out.println(k + " = " + v);
}
}
}Producción:

Bien, no hay ningún problema con el recorrido, pero ¿qué pasa con la operación de eliminar, colocar y agregar elementos de la colección?
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map < Integer, String > map = new HashMap < > ();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for (Map.Entry < Integer, String > entry: map.entrySet()) {
int k = entry.getKey();
if (k == 1) {
map.put(1, "AA");
}
String v = entry.getValue();
System.out.println(k + " = " + v);
}
}
}Resultados de:

No hay ningún problema con la ejecución y la operación de venta es exitosa.
¡pero! ¡pero! ¡pero! ¡Aquí viene el problema! ! !
Sabemos que HashMap es una clase de colección insegura para subprocesos. Si usa foreach para atravesar, agregar y eliminar operaciones provocará una excepción java.util.ConcurrentModificationException. La operación de venta puede generar esta excepción. (Por qué se dice que es posible, lo explicaremos más adelante)
¿Por qué se lanza esta excepción?
Primero echemos un vistazo a la explicación de las operaciones de HasMap en la documentación de la API de Java.

La traducción aproximada significa: este método devuelve una vista de colección de las claves contenidas en este mapa.
Las colecciones están respaldadas por mapas, y si el mapa se modifica mientras se itera sobre la colección (que no sea mediante las propias operaciones de eliminación del iterador), el resultado de la iteración no está definido. Las colecciones admiten la eliminación de elementos mediante las operaciones Iterator.remove, set.remove, removeAll, retener y borrar para eliminar las asignaciones correspondientes del mapa. En pocas palabras, al atravesar una colección a través de map.entrySet (), no puede realizar operaciones como eliminar y agregar en la colección en sí, y necesita usar un iterador para las operaciones.
Para la operación de colocación, si la operación de reemplazo modifica el primer elemento como en el ejemplo anterior, no se generará ninguna excepción, pero si la operación de colocación se usa para agregar elementos, definitivamente se generará una excepción. Modifiquemos el ejemplo anterior:
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map < Integer, String > map = new HashMap < > ();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for (Map.Entry < Integer, String > entry: map.entrySet()) {
int k = entry.getKey();
if (k == 1) {
map.put(4, "AA");
}
String v = entry.getValue();
System.out.println(k + " = " + v);
}
}
}Se produjo una excepción durante la ejecución:

Esto verifica que la operación de venta mencionada anteriormente puede generar una excepción java.util.ConcurrentModificationException.
Pero tengo preguntas: ¿Dijimos anteriormente que el bucle foreach atraviesa iteradores? ¿Por qué no es posible venir aquí?
En realidad, esto es muy simple. La razón es que la capa inferior de nuestra operación transversal de hecho se realiza a través de iteradores, pero nuestra operación de eliminación y otras operaciones se realizan operando directamente el mapa, como en el ejemplo anterior: map.put(4, " AA"); // Las operaciones reales aquí se realizan directamente en la colección, en lugar de a través de iteradores. Por lo tanto, todavía habrá problemas de excepción ConcurrentModificationException.
2. Estudie los principios subyacentes en detalle.
Echemos un vistazo al código fuente de HashMap. A través del código fuente, encontramos que este método se utilizará al atravesar la colección usando Iterator:
final Node < K, V > nextNode() {
Node < K, V > [] t;
Node < K, V > e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}Aquí modCount representa cuántas veces se han modificado los elementos en el mapa (este valor aumentará automáticamente al eliminar o agregar nuevos elementos), y expectedModCount representa el número esperado de modificaciones.Estos dos valores son iguales cuando el iterador es construido. Si los dos valores no están sincronizados durante el proceso transversal, se generará una excepción ConcurrentModificationException.
Ahora veamos la operación de eliminación de colección:
(1) La implementación de eliminación del propio HashMap:
public V remove(Object key) {
Node < K, V > e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}(2) Eliminar la implementación de HashMap.KeySet
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}(3) Eliminar la implementación de HashMap.EntrySet
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry << ? , ? > e = (Map.Entry << ? , ? > ) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}(4) Implementación del método de eliminación de HashMap.HashIterator
public final void remove() {
Node < K, V > p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount; //--这里将expectedModCount 与modCount进行同步
}Todos los cuatro métodos anteriores implementan la operación de eliminación de claves llamando al método HashMap.removeNode. Siempre que se elimine la clave en el método removeNode, modCount realizará una operación de incremento automático. En este momento, modCount será inconsistente con el esperadoModCount;
final Node < K, V > removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node < K, V > [] tab;
Node < K, V > p;
int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
...
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode < K, V > ) node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount; //----这里对modCount进行了自增,可能会导致后面与expectedModCount不一致
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}Entre las tres implementaciones de eliminación anteriores, solo el método de eliminación del tercer iterador sincroniza el valor esperadoModCount después de llamar al método removeNode. El valor de esperadoModCount es el mismo que modCount, por lo que al atravesar el siguiente elemento y llamar al método nextNode, el método iterador no lanzará una excepción.
Cuando llegas aquí, ¿sientes que de repente lo entiendes?
Por lo tanto, si necesita realizar operaciones de elementos al atravesar una colección, debe utilizar un iterador, de la siguiente manera:
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map < Integer, String > map = new HashMap < > ();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
Iterator < Map.Entry < Integer, String >> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry < Integer, String > entry = it.next();
int key = entry.getKey();
if (key == 1) {
it.remove();
}
}
}
}