深度学习论文: Un método de segmentación y clasificación de anomalías de cero/pocos disparos para CVPR 2023 VAND Workshop Challenge Tracks 1 y 2: 1er lugar en AD de cero disparos y 4to lugar en AD de pocos disparos Una clasificación de anomalía de cero/pocos disparos
y Método de segmentación para CVPR 2023 VAND Workshop Challenge Tracks 1 y 2: 1.er lugar en Zero-shot AD y 4.° lugar en Few-shot AD
PDF: https://arxiv.org/pdf/2305.17382.pdf
PyTorch代码: https://github. com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1. Información general
Para abordar la amplia diversidad de tipos de productos en la inspección visual industrial, creamos un modelo único que puede adaptarse rápidamente a numerosas categorías y requiere pocas imágenes de referencia normales, o ninguna, lo que proporciona una solución más eficiente para la inspección visual industrial. Se propone una solución al seguimiento de pocas o cero muestras para el desafío VAND de 2023.
1) En la tarea de tiro cero, la solución propuesta agrega una capa lineal adicional al modelo CLIP para mapear características de la imagen en un espacio de incrustación conjunto, lo que permite compararla con características de texto y generar mapas de anomalías.
2) Cuando hay una imagen de referencia disponible (pocas tomas), la solución propuesta utiliza múltiples bancos de memoria para almacenar las características de la imagen de referencia y compararlas con la imagen de consulta en el momento de la prueba.
En este desafío, nuestro método logró el primer lugar en Zero-Shot y tuvo un buen desempeño en la segmentación, con una mejora en la puntuación F1 de 0,0489 sobre el competidor en segundo lugar. En Few-Shot conseguimos el 4º puesto general y el 1º puesto en la clasificación de F1.
Puntos centrales:
- Utilice la integración de mensajes de estado y plantilla para crear mensajes de texto.
- Para localizar áreas anormales, se introduce una capa lineal adicional para asignar las características de la imagen extraídas del codificador de imágenes CLIP al espacio lineal donde se encuentran las características del texto.
- Compare la similitud entre las características de la imagen mapeada y las características del texto para obtener los mapas de anomalías correspondientes.
- En pocos disparos, se retienen las capas lineales adicionales en la etapa de disparo cero y se mantienen sus pesos. Además, se utiliza un codificador de imágenes durante la fase de prueba para extraer características de la imagen de referencia y guardarlas en bancos de memoria para compararlas con las características de la imagen de prueba.
- Para aprovechar al máximo las funciones superficiales y profundas, se utilizan simultáneamente las funciones de diferentes etapas del codificador de imágenes.
2. Metodología
En general, adoptamos el marco general de CLIP para la clasificación de disparo cero y utilizamos una combinación de estados y colecciones de plantillas para crear nuestras indicaciones de texto. Para localizar regiones anormales en imágenes, introducimos capas lineales adicionales que asignan características de la imagen extraídas del codificador de imágenes CLIP al espacio lineal donde residen las características del texto. Luego, realizamos una comparación de similitud entre las características de la imagen mapeada y las características del texto para obtener el mapa de anomalías correspondiente. Para el caso de pocas muestras, conservamos las capas lineales adicionales de la etapa de muestra cero y mantenemos sus pesos. Además, utilizamos un codificador de imágenes para extraer las características de la imagen de referencia y guardarlas en un banco de memoria, que se comparan con las características de la imagen de prueba durante la fase de prueba. Cabe señalar que para utilizar plenamente las funciones superficiales y profundas, utilizamos funciones de diferentes etapas en configuraciones nulas y de pocos disparos.
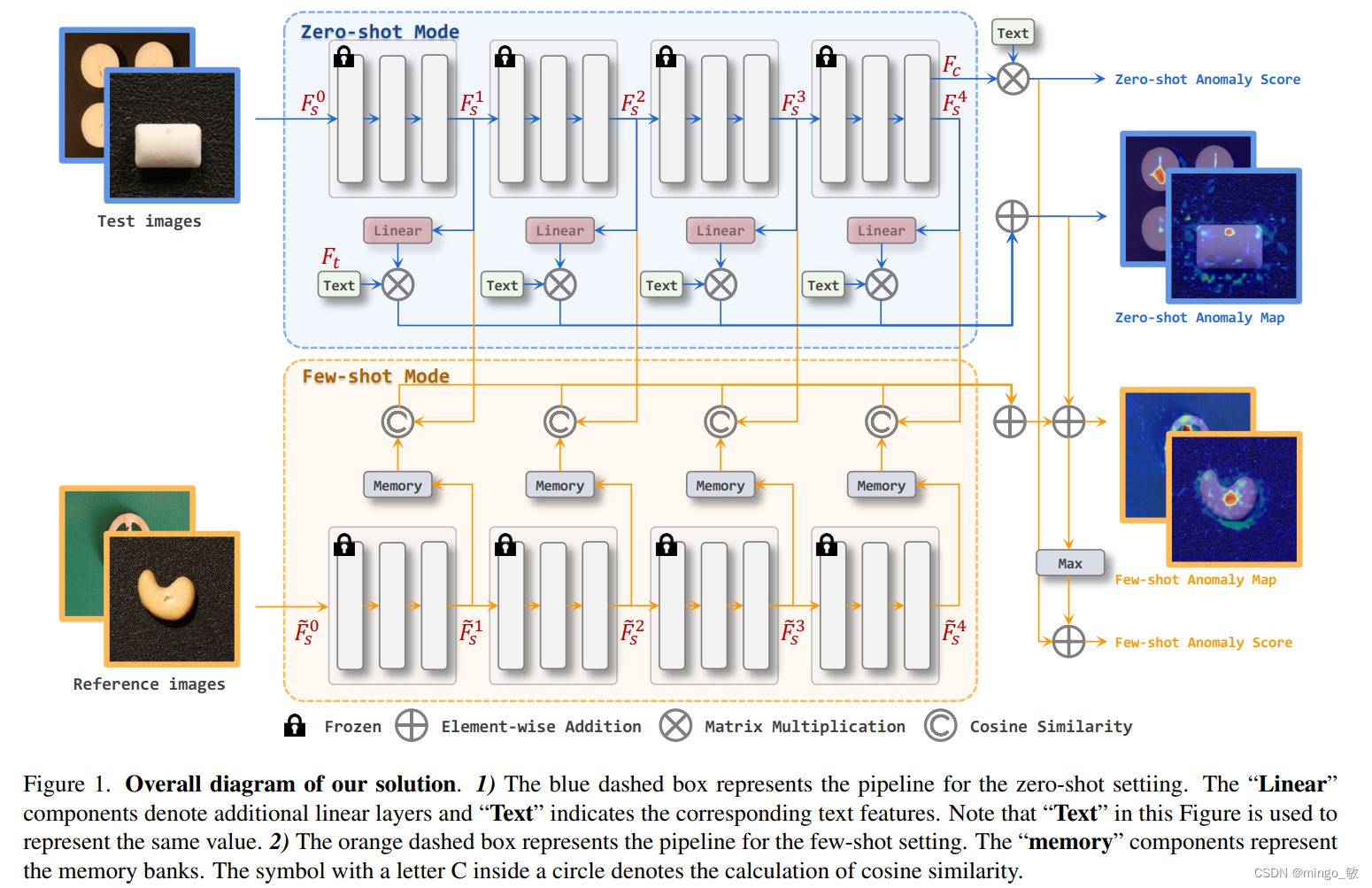
2-1 AD de tiro cero
La clasificación de anomalías
se basa en el marco de clasificación de anomalías de WinCLIP. Proponemos una estrategia de integración de mensajes de texto que mejora significativamente la precisión de la clasificación de anomalías de Baseline sin utilizar estrategias complejas de ventanas de múltiples escalas. Específicamente, la estrategia de integración incluye dos partes: nivel de plantilla y nivel de estado:
1) El mensaje de texto a nivel de estado utiliza texto general para describir objetivos normales o anormales (como impecables, dañados) sin usar "chip around edge" y corner ";
2) mensajes de texto a nivel de plantilla. La solución propuesta examinó 85 plantillas para ImageNet en CLIP y eliminó "una foto del [obj.] extraño" y otros elementos inaplicables. Plantilla para tareas de detección de anomalías.
Estas dos sugerencias de texto se extraerán como características de texto finales mediante el codificador de texto de CLIP: F t ∈ R 2 × C F_{t} \in R^{2 \times C}Ft∈R2 × C. _
def encode_text_with_prompt_ensemble(model, texts, device):
prompt_normal = ['{}', 'flawless {}', 'perfect {}', 'unblemished {}', '{} without flaw', '{} without defect', '{} without damage']
prompt_abnormal = ['damaged {}', 'broken {}', '{} with flaw', '{} with defect', '{} with damage']
prompt_state = [prompt_normal, prompt_abnormal]
prompt_templates = ['a bad photo of a {}.',
'a low resolution photo of the {}.',
'a bad photo of the {}.',
'a cropped photo of the {}.',
'a bright photo of a {}.',
'a dark photo of the {}.',
'a photo of my {}.',
'a photo of the cool {}.',
'a close-up photo of a {}.',
'a black and white photo of the {}.',
'a bright photo of the {}.',
'a cropped photo of a {}.',
'a jpeg corrupted photo of a {}.',
'a blurry photo of the {}.',
'a photo of the {}.',
'a good photo of the {}.',
'a photo of one {}.',
'a close-up photo of the {}.',
'a photo of a {}.',
'a low resolution photo of a {}.',
'a photo of a large {}.',
'a blurry photo of a {}.',
'a jpeg corrupted photo of the {}.',
'a good photo of a {}.',
'a photo of the small {}.',
'a photo of the large {}.',
'a black and white photo of a {}.',
'a dark photo of a {}.',
'a photo of a cool {}.',
'a photo of a small {}.',
'there is a {} in the scene.',
'there is the {} in the scene.',
'this is a {} in the scene.',
'this is the {} in the scene.',
'this is one {} in the scene.']
text_features = []
for i in range(len(prompt_state)):
prompted_state = [state.format(texts[0]) for state in prompt_state[i]]
prompted_sentence = []
for s in prompted_state: # [prompt_normal, prompt_abnormal]
for template in prompt_templates:
prompted_sentence.append(template.format(s))
prompted_sentence = tokenize(prompted_sentence).to(device)
class_embeddings = model.encode_text(prompted_sentence)
class_embeddings /= class_embeddings.norm(dim=-1, keepdim=True)
class_embedding = class_embeddings.mean(dim=0)
class_embedding /= class_embedding.norm()
text_features.append(class_embedding)
text_features = torch.stack(text_features, dim=1).to(device).t()
return text_features
Las características de imagen correspondientes a través del codificador de imágenes son: F c ∈ R 1 × C F_{c} \in R^{1 \times C}Fc∈R1 × C .
Implementación integrada a nivel de estado y nivel de plantilla, utilizando el codificador de texto CLIP para extraer características de texto y promediar características normales y anormales respectivamente. Finalmente, los valores promedio de las características normales y anormales se comparan con las características de la imagen, y la probabilidad de categoría anormal se obtiene después de softmax como la puntuación de clasificación
s = softmax ( F c F t T ) s = softmax(F_{c} F_ {t}^ {T})s=so f t ma x ( FcFtt)
Finalmente seleccionessLa segunda dimensión de s como resultado del problema de clasificación de detección de anomalías.
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
results['pr_sp'].append(text_probs[0][1].cpu().item())
La segmentación de anomalías
es análoga a los métodos de clasificación de anomalías a nivel de imagen para la segmentación de anomalías. Una idea natural es medir la similitud entre diferentes niveles de características extraídas por Backbone y características de texto. Sin embargo, el modelo CLIP está diseñado en base a un esquema de clasificación, es decir, a excepción de las características de imagen abstractas utilizadas para la clasificación, otras características de la imagen no se asignan a un espacio de imagen/texto unificado. Por lo tanto, proponemos una solución simple pero efectiva para resolver este problema: use capas lineales adicionales para mapear características de la imagen en diferentes niveles en el espacio de incrustación de la unión imagen / texto, es decir, la capa lineal mapea patch_tokens y luego los suma en función de cada uno. patch_token.Las características del texto se utilizan para el cálculo de similitud y obtener el mapa de anomalías. , vea el proceso azul del Mapa de anomalías de disparo cero en la imagen de arriba. Específicamente, las características en diferentes niveles se integran conjuntamente en la transformación del espacio de características a través de una capa lineal, y las características transformadas se comparan con las características del texto para obtener mapas de anomalías en diferentes niveles. Finalmente, los gráficos de anomalías en diferentes niveles simplemente se suman para obtener el resultado final.
patch_tokens = linearlayer(patch_tokens)
anomaly_maps = []
for layer in range(len(patch_tokens)):
patch_tokens[layer] /= patch_tokens[layer].norm(dim=-1, keepdim=True)
anomaly_map = (100.0 * patch_tokens[layer] @ text_features.T)
B, L, C = anomaly_map.shape
H = int(np.sqrt(L))
anomaly_map = F.interpolate(anomaly_map.permute(0, 2, 1).view(B, 2, H, H),
size=img_size, mode='bilinear', align_corners=True)
anomaly_map = torch.softmax(anomaly_map, dim=1)[:, 1, :, :]
anomaly_maps.append(anomaly_map.cpu().numpy())
anomaly_map = np.sum(anomaly_maps, axis=0)
El entrenamiento de Linear Layer (los parámetros de la parte CLIP están congelados) utiliza pérdida focal y pérdida de dados.
2-2 AD de pocos tiros
Clasificación de anomalías
Para la configuración de pocas tomas, la predicción de anomalías de la imagen proviene de dos partes. La primera parte es la misma que la configuración de disparo cero. La segunda parte sigue el enfoque convencional utilizado en muchos métodos AD, considerando el valor máximo del mapa de anomalías. El esquema propuesto agrega estas dos partes como puntuación de anomalía final.
La tarea de segmentación de pocas tomas de segmentación de anomalías utiliza el banco de memoria, como se muestra en el fondo amarillo de la Figura 1.
Para decirlo sin rodeos, se calcula la similitud del coseno entre la muestra de consulta y la muestra de soporte en el banco de memoria, y luego se obtiene el mapa de anomalías mediante remodelación y, finalmente, el mapa de anomalías obtenido mediante disparo cero se agrega al mapa de anomalías para Obtenga la predicción de segmentación final.
Además, en la tarea de pocos disparos, no es necesario ajustar la capa lineal mencionada anteriormente, pero los pesos entrenados en la tarea de cero disparos se utilizan directamente.
3 experimentos

En pocas palabras, en imágenes más simples, el disparo cero y el disparo reducido tienen efectos similares, pero cuando se enfrentan a tareas difíciles, el disparo reducido mejorará.