【Descripción del problema】
Tema 6: Problema de matriz numérica
Cada posición es una matriz cuadrada de números con tres filas y tres columnas. Cada posición es un número del 0 al 8 y son diferentes entre sí. Encuentra la forma "más rápida" de pasar de la posición inicial (establecida por ti mismo) a la posición del terminal (configurada por usted mismo). ).
Reglas de movimiento: ¡Solo se puede intercambiar 0 con un número adyacente en las cuatro direcciones arriba, abajo, izquierda y derecha a la vez! Puede que haya una solución, puede que no la haya.
| 0 |
1 |
2 |
|
? |
|
1 |
2 |
3 |
| 3 |
4 |
5 |
|
=》 |
|
4 |
5 |
6 |
| 6 |
7 |
8 |
|
|
|
7 |
8 |
0 |
【análisis de demanda】
1. Funciones básicas
1. El usuario configura él mismo la interfaz inicial y la interfaz de terminación, y los cuadrados de la cuadrícula de nueve cuadrados se pueden mover;
2. Imprima la ruta de movimiento según la interfaz inicial y la interfaz de terminación.
2. Funciones adicionales
1. La función de revertir el movimiento del usuario de la cuadrícula de nueve cuadrados;
2. Se utilizan tres algoritmos, búsqueda A*, primero global y primero en amplitud, para buscar la ruta en movimiento;
3. Se han diseñado cuatro funciones de valoración para la búsqueda A* y los algoritmos globales de primera elección;
4. Determine la cantidad de pasos y el tiempo a seguir cuando se especifican la función de valoración y el algoritmo, almacene los resultados en la base de datos y recíbalos en el front-end.
【Diseño de esquema】
1. Información del sistema
Entorno de hardware de desarrollo
CPU: Intel(R) Core(TM) i7-11800H de 11.ª generación a 2,30 GHz 2,30 GHz
RAM: 16,0 GB
Desarrollar el sistema operativo para el sistema.
Versión: Windows 10 Home Edición China
Entorno de desarrollo de software/herramientas de desarrollo
Intellig IDEA2021.1.1
Código de estudio visual
Constructor X
Cartero、ApiPost7
lenguaje de programación
Java
Puntos técnicos
Tecnología de back-end: Springboot, SpringMVC, knife4j, Mybatis-plus, MySQL, maven, lombok
Tecnología front-end: HTML, CSS, JavaScript, Vue, JQuery, Element-ui, Layui, axios
2. Módulo de funciones
Según las necesidades, las funciones del sistema de resolución de ocho dígitos diseñado incluyen tres categorías: movimiento de cuadrícula de nueve cuadrados, búsqueda de rutas de movimiento y registro de estado. Los detalles se muestran en la Figura 1:
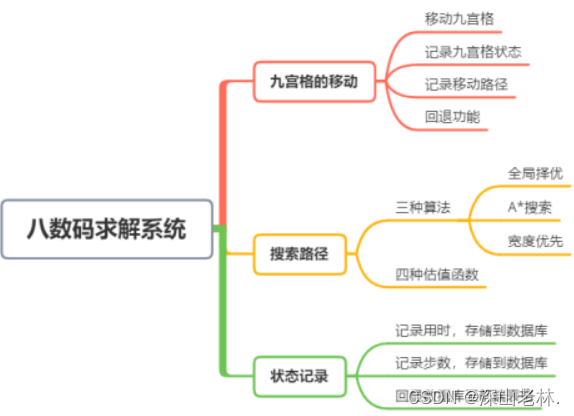
Figura 1 Diagrama de funcionamiento del sistema
3. Estructura del proyecto
(1) Arquitectura MVC de tres niveles
Tabla 1 Tabla de arquitectura MVC
| nivel |
efecto |
Criterios de diseño |
| Capa de modelo (MODELO) |
Encapsule una serie de datos de aplicaciones y defina operaciones, lógica y reglas de cálculo para procesar estos datos. |
Comentarios al controlador llamando a la interfaz. |
| ver capa (VISTA) |
Uno de los propósitos principales del objeto de vista es mostrar datos del objeto del modelo de aplicación y permitir al usuario editar esos datos. |
Envíe solicitudes asincrónicas a través de ajax y proporcione comentarios al controlador |
| Capa controladora (CONTROLLER) |
El controlador es el intermediario entre la capa de vista y varias capas del modelo. |
Operar directamente la capa de modelo y la capa de vista. |
(2) Estructura del paquete
El proyecto utiliza una arquitectura MVC básica de tres niveles, en la que las clases de entidad comunes se almacenan en el paquete común, la información de configuración para el servidor Tomcat se almacena en config, la capa de control está en el paquete del controlador, la interfaz para las operaciones de la base de datos está debajo de la capa del asignador, y el servicio es la capa empresarial, debajo del sistema están las clases de entidad y las clases definidas bajo el paquete vo son objetos de valor, que se utilizan para transferir datos e información. La estructura del directorio del paquete se muestra en la Figura 2.
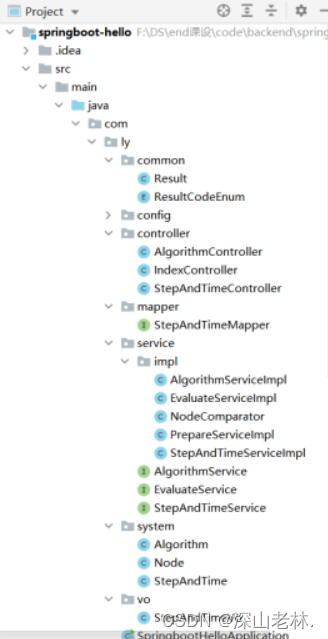
Figura 2 Directorio del paquete del proyecto
4. Estructura de almacenamiento
En el proceso de desarrollo y diseño de JavaEE, similar a la estructura del lenguaje C, el almacenamiento en Java se coloca en una clase de entidad. Por ejemplo, almaceno la información relacionada con los tres algoritmos en el nodo Nodo y el nodo Algoritmo. La estructura de almacenamiento del nodo Nodo se muestra en la Figura 9.
Tabla 2 Estructura de almacenamiento del nodo Nodo
| Nombre del elemento de datos |
Representación del sistema de elementos de datos |
tipo de datos |
Longitud de datos |
Observación |
| Almacenar datos de vértice |
número |
En t[][] |
3*3 |
|
| Pasos de movimiento/profundidad |
profundidad |
En t |
|
|
| ordinal inverso |
número_de_orden_inverso |
En t |
|
|
| Dirección de movimiento del nodo principal |
dirección |
En t |
|
|
| Valor de la función de valoración |
valer |
En t |
|
|
El código de la clase Nodo es el siguiente:
public class Node {
public int[][] num =new int [3][3]; //用于存放节点数据
public int depth; //移动步数/深度
int Reverse_order_number; //逆序数
public int direction;//1 2 3 4 分别为上下左右
public int worth; //启发式函数的值
}La estructura de almacenamiento del algoritmo del nodo se muestra en la Tabla 3:
Tabla 3 Estructura de almacenamiento de algoritmos
| Nombre del elemento de datos |
Representación del sistema de elementos de datos |
tipo de datos |
Longitud de datos |
Observación |
| Estado inicial de num |
núm_Inicial |
En t[][] |
3*3 |
|
| estado final de num |
num_Eventual |
En t[][] |
3*3 |
|
| Tiempo de empezar |
estrellahora |
largo |
|
|
| Longitud máxima de búsqueda |
MAX_SEARCH_DEPTH |
En t |
|
|
El código fuente de la clase Algoritmo es el siguiente:
public class Algorithm {
public static int[][] num_Initial =new int [3][3];
public static int[][] num_Eventual =new int [3][3];
public static long starTime;
public static int MAX_SEARCH_DEPTH=100;
}La clase de almacenamiento de los resultados de la ejecución de la función es StepAndTime y la estructura de almacenamiento es la siguiente:
Tabla 4 Estructura de almacenamiento StepAndTime
| Nombre del elemento de datos |
Representación del sistema de elementos de datos |
tipo de datos |
Longitud de datos |
Observación |
| Clave primaria |
identificación |
Cadena |
|
|
| Nombre del algoritmo |
nombre_algoritmo |
Cadena |
|
|
| Función de valoración |
algoritmo_valor_estimación |
Cadena |
|
|
| tiempo usado |
costo_tiempo |
Cadena |
|
|
| recuento de pasos |
paso |
En t |
|
|
El código de la clase StepAndTime es el siguiente:
public class StepAndTime {
private String id;
private String algorithm_name;
private String algorithm_value_estimate;
private String time_cost;
private int step;
}El nodo StepAndTime aquí se almacena en la base de datos y puede realizar las funciones de agregar, eliminar, modificar y consultar la base de datos. La estructura de la tabla step_and_time se muestra en la Figura 3.

Figura 3 Almacenamiento de base de datos
【diseño detallado】
1. Movimiento de la Rejilla de los Nueve Palacios
(1) Mover la cuadrícula de nueve cuadrados
Se colocan dos cuadrículas de nueve cuadrados en la interfaz de usuario, cada cuadrícula de nueve cuadrados contiene ocho números del 1 al 8. La primera cuadrícula de nueve cuadrados representa el estado inicial y la segunda cuadrícula de nueve cuadrados representa el estado objetivo. El usuario hace clic en el bloque vacío, es decir, la cuadrícula de nueve cuadrados se divide. Cuando hay un bloque que no sea 8 bloques con números, el bloque se intercambiará con un bloque vacío. La lógica de intercambio se muestra en la Figura 4.
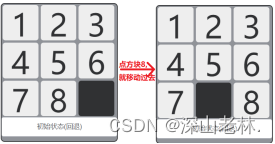
Figura 4 El efecto de movimiento al hacer clic en el cuadrado.
(2) Registre el estado del Jiugongge y el estado del movimiento.
Utilice una matriz ti2 para registrar el estado del Jiugongge, utilice la concatenación de cadenas para registrar el estado del movimiento del Jiugongge (para revertir) e imprima el contenido en la consola.

Figura 5 Registro del estado de la cuadrícula de nueve cuadrados
(3) Función de reversión
Haga clic en el botón Atrás a continuación para regresar al estado anterior de la cuadrícula de nueve cuadrados.
2. Ruta de búsqueda
(1) Algoritmo de optimización global
La búsqueda preferencial global es una búsqueda heurística, que utiliza información heurística en problemas conocidos para guiar la resolución de problemas, en lugar de fuerza bruta y búsqueda ciega exhaustiva.
Información heurística : es decir, información de control que puede usarse para guiar el proceso de búsqueda y es relevante para resolver problemas específicos.
Función heurística : Un modelo matemático utilizado para describir información heurística, llamado función heurística. Según las características del problema y la perspectiva del problema, se pueden definir múltiples funciones heurísticas para el mismo problema.
El proceso de ejecución del algoritmo de optimización global consiste en colocar primero el nodo inicial S0 en la tabla OPEN y calcular la función heurística f (S0) en función de la profundidad del nodo actual y la medición de la diferencia entre el nodo actual y el nodo de destino. Si la tabla OPEN está vacía, entonces el problema no se resuelve, simplemente salga del programa. Si la tabla OPEN aún no está vacía, coloque el primer nodo n de la tabla OPNE en la tabla CLOSED y verifique si el nodo es el nodo de destino. Si es así, entonces está bien Obtenga la solución al problema directamente y salga del programa. Si no se ha encontrado el nodo de destino, el nodo n no se puede expandir. Vaya al paso 2. Si el nodo n se puede expandir , expanda el nodo y use la función de valoración f (n) para calcular cada uno El valor estimado del nodo y configure un puntero al nodo principal para cada nodo secundario, coloque estos nodos secundarios en la tabla ABIERTA y luego ordene todos los nodos en la tabla OPEN de acuerdo con el tamaño de la función de valoración f(n), y luego vaya al Paso 2. El proceso de ejecución del algoritmo óptimo global se muestra en la Tabla 5.
Tabla 5 Proceso de ejecución del algoritmo de optimización global
| paso |
Proceso de algoritmo de optimización global. |
| Paso 1 |
Coloque el nodo inicial SO en la tabla OPEN, f(S0) |
| Paso 2 |
Si la tabla OPEN está vacía, no hay solución al problema y se sale |
| Paso 3 |
Tome el primer nodo de la tabla ABIERTA (registrado como nodo n) y colóquelo en la tabla CERRADA |
| Etapa 4 |
Compruebe si el nodo n es el nodo objetivo. Si es así, busque la solución al problema y salga. |
| Paso 5 |
Si el nodo n no se puede expandir, vaya al Paso 2. |
| Paso6 |
Expanda el nodo n, use la función heurística f (x) para calcular el valor estimado de cada nodo secundario y configure un puntero al nodo principal para cada nodo secundario, envíe estos nodos secundarios a la tabla OPEN y luego calcule todos los nodos en la tabla OPEN Ordene por valor estimado de pequeño a grande, luego vaya al Paso 2 |
(2) Algoritmo de búsqueda A*
El algoritmo de búsqueda A * tiene cambios muy pequeños en comparación con el algoritmo de optimización global y solo agrega algunas funciones. Las definiciones y diferencias de la optimización global, el algoritmo A y el algoritmo A * se muestran en la Tabla 6:
Tabla 6 Definición de algoritmo A y algoritmo A*
| definición |
Proceso de algoritmo de optimización global. |
| Definición 1 |
En el proceso GRAPHSEARCH, si la tabla OPEN se reorganiza según f(x)=g(x)+h(x), el proceso se denomina algoritmo A. |
| Definición 2 |
En el algoritmo A, si h(x)<=h*(x) se cumple para todo x, entonces h(x) se denomina límite inferior de h*(x), lo que representa algún tipo de estimación conservadora. |
| Definición 3 |
El algoritmo A que utiliza el límite inferior h*(x) de h(x) como función heurística se denomina algoritmo A*. |
A*算法是在A算法的基础上,每生成一个新节点,即查找closed表,如果closed表中有相同排列的结点,那么则比较他们的权重(f(n)),如果新节点的权重更小,则替代原结点,即,刷新原结点的深度,这样就很有可能找到更短、更快的到达目标结点的路径。A*算法执行的流程图如图 6所示
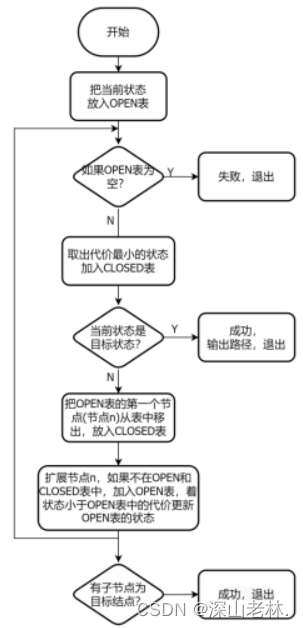
图 6 A*算法执行流程图
(三)宽度优先算法
宽度优先算法是一种盲目搜索算法,即,蛮力法;需要一个Open表,把起始节点放入Open表中,如果Open表为空,则无解并退出,否则,继续把第一个节点n从Open表中移除,并放入CLOSED扩展节点表中。这里要考察节点n是不是目标节点,如果是的话,就代表求出答案了,则可以退出,如果节点n往下不可以接着扩展了,那么转到第二步,继续从OPEN表中选节点,放入CLOSED表考察。如果节点n可扩展,则把所有n的子节点放入OPEN表的尾部,配置父节点指针,继续转Step2开始下一轮判断。算法流程如表 7所示。
表 7 宽度优先算法流程表
| 步骤 |
宽度优先算法流程 |
| Step1 |
把起始节点放到OPEN表中 |
| Step2 |
如果OPEN是个空表,则没有解失败退出;否则继续 |
| Step3 |
把第一个节点 (节点n) 从OPEN表移出,并把它放入CLOSED扩展节点表中 |
| Step4 |
考察节点n是否为目标节点。如果是,则求得了问题的解,退出 |
| Step5 |
如果节点n不可扩展,则转Step2 |
| Step6 |
把n的所有子节点放到OPEN表的尾部,并为其配置指向父节点的指针然后转第Step2步 |
算法流程图如图 7所示
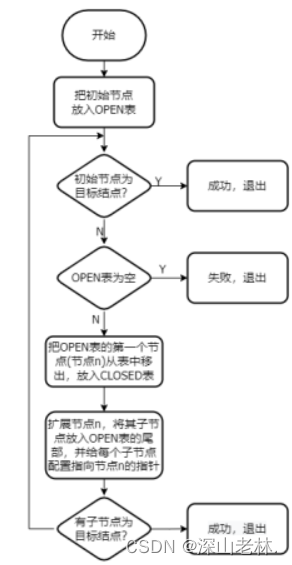
图 7 宽度优先算法流程图
(四)四种估值函数
对于全局择优和A*搜索这两种算法,为了求取最优解,可以设置不同的估值函数,测试看不同的效果。这里选择了四种估值函数,估值函数的解释如图 8所示。
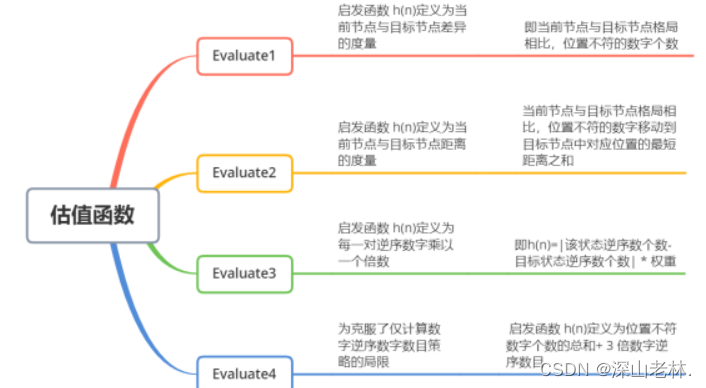
图 8 四种估值函数
这里的Evaluate1和Evaluate2的启发函数定义为当前结点与目标结点差异的度量,这里的“差异”,可以是当前节点与目标节点相比,位置不符的数字个数,也可以是当前节点和目标节点格局相比,位置不符的数字移动到目标节点中对应位置的最短距离之和。
Evaluate3定义为每一对逆序数字乘以一个倍数,即该状态下 逆序数个数与目标状态逆序数个数的绝对值乘以权重。
Evaluate4是为了克服仅在计算数字逆序数字量策略的局限,启发函数定义为位置不符数字个数的总和+3倍逆序数字序列。
三、状态记录
前端使用了el-table表格,对八数码路径查找执行时的用时、步数等进行了数据的持久化存储,并利用axios调用后端接口,实现了数据的回显。在前端显示的表格中,部分数据如图 9所示。
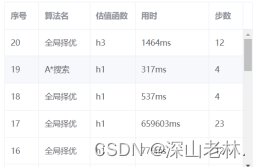
图 9 数据记录表的部分数据
【编码实现】
由于主要功能的实现是通过估值函数类&&算法类实现的,所以在这里,仅对四种估值函数和三种算法做介绍。
一、估值函数
(一)估值函数1
启发函数 h(n)定义为当前节点与目标节点差异的度量:即当前节点与目标节点格局相比,位置不符的数字个数。其中,估值函数Evaluate1的代码如下:
public int Evaluate1(int a[][],int[][] num_Finish) {
int n = 0;
for (int i = 0; i < 3; ++i) {
for (int j = 0; j < 3; ++j) {
if (a[i][j] != num_Finish[i][j])
++n;//找两个状态有多少个格子位置错了
}
}
return n;
}(二)估值函数2
启发函数 h(n)定义为当前节点与目标节点距离的度量:当前节点与目标节点格局相比,位置不符的数字移动到目标节点中对应位置的最短距离之和。其中估值函数Evaluate2如下:
public int Evaluate2(int a[][],int[][] num_Finish) {
int h = 0;// 代价
//找到这个数在初始状态和目标状态的位置在哪
for (int i = 0; i < 9; ++i) {
int m, n;
for (m = 0; m < 9; ++m)
//二维数组遍历找0-8中的数字i,找到就往下
if (a[m / 3][m % 3] == i) break;
for (n = 0; n < 9; ++n)
if (num_Finish[n / 3][n % 3] == i)//找到就往下
break;
//行序差+列序差
h += Math.abs((m / 3) - (n / 3)) + Math.abs((m % 3) - (n % 3));
}
return h;
}
(三)估值函数3
启发函数 h(n)定义为每一对逆序数字乘以一个倍数,即h(n)=|该状态逆序数个数-目标状态逆序数个数| * 权重
public int Evaluate3(int a[][],int[][] num_Finish) {
int weight=Math.abs(ReverseNumber(a)-ReverseNumber(num_Finish));
return weight*Math.abs(ReverseNumber(a)-ReverseNumber(num_Finish));
}
(四)估值函数4
为克服了仅计算数字逆序数字数目策略的局限 启发函数 h(n)定义为位置不符数字个数的总和+ 3 倍数字逆序数目。
public int Evaluate4(int a[][],int[][] num_Finish) {
return Evaluate1(a,num_Finish) + 3 * Math.abs(ReverseNumber(a) - ReverseNumber(num_Finish));
}
二、搜索算法
(一)全局择先算法
全局择优算法的执行流程是先把初始节点S0放入OPEN表中,根据当前结点的深度和当前结点和目标结点差异的度量,计算出启发函数f(S0),如果OPEN表为空,那么问题没有解,直接退出程序,如果OPEN表还不为空,那就把OPNE表的第一个节点n放入CLOSED表,考察该节点是否是目标结点,如果是的,那就可以直接得出问题解,从而退出程序,如果还没找到目标节点,则节点n不可以扩展,转到Step2,如果节点n可以扩展,则扩展该节点,用估值函数f(n)计算每个节点的估价值,并给每个子结点配置指向父结点的指针,把这些子节点都放入OPEN表中,然后对OPEN表中的所有节点按照估值函数f(n)的大小进行排序,再转到Step2去,全局择优算法的执行流程如表 5所示。其中,全局择先函数如下:
public int[][][] GlobalSearch2(long info[],int nEvaluate,int[][] num_Begin,int[][] num_Finish) {
starTime = System.nanoTime();
Vector<Node> OPEN=new Vector<Node>();
Vector<Node> CLOSED=new Vector<Node>();
// 添加根节点
OPEN.add(new Node(num_Begin, 0, evaluateService.ReverseNumber(num_Begin), 0, null, evaluateService.Evaluate(num_Begin, 0, nEvaluate,num_Finish)));
while(!OPEN.isEmpty()) {
// 计算可达性,限制搜索深度
if (!isAvailable(OPEN.get(0).num,num_Finish) || OPEN.get(0).depth > MAX_SEARCH_DEPTH) {
return null;
}
CLOSED.add(OPEN.get(0));
OPEN.remove(0);
if(isEqual(CLOSED.lastElement().num,num_Finish)) {
return Route2(CLOSED.lastElement(),info);
}
else {
Node father=CLOSED.lastElement();
int i = 0, j = 0;
// 找到空格
for (int k = 0; k < 9; ++k) {
if (father.num[k / 3][k % 3] == 0) {
i = k / 3;
j = k % 3;
break;
}
}
int dir=father.direction,dep=father.depth;
int a[][]=new int[3][3];
//1 上
if (i != 0&& dir!=2) {
for (int m = 0; m < 3; ++m) {
for (int n = 0; n < 3; ++n) {
a[m][n]=father.num[m][n];
}
}
a[i][j]=a[i-1][j];
a[i-1][j]=0;
OPEN.add(new Node(a, dep + 1, evaluateService.ReverseNumber(a), 1, father,evaluateService.Evaluate(a, dep + 1, nEvaluate,num_Finish)));
}
//参照“1 上”,执行下、左、右三个方向的扩展
}
return null;
}
(二)A*搜索算法
A*搜索算法相对于全局择优算法改动非常小,只增加了个别函数,因此在此处省略。
(三)宽度优先算法
宽度优先算法是一种盲目搜索算法,即,蛮力法;需要一个Open表,把起始节点放入Open表中,如果Open表为空,则无解并退出,否则,继续把第一个节点n从Open表中移除,并放入CLOSED扩展节点表中。这里要考察节点n是不是目标节点,如果是的话,就代表求出答案了,则可以退出,如果节点n往下不可以接着扩展了,那么转到第二步,继续从OPEN表中选节点,放入CLOSED表考察。如果节点n可扩展,则把所有n的子节点放入OPEN表的尾部,配置父节点指针,继续转Step2开始下一轮判断。算法流程如表 7所示。WideSearch2函数如下所示:
public int[][][] WideSearch2(long info[],int[][] num_Begin,int[][] num_Finish) {
int[][][] result = {};
starTime = System.nanoTime();
Vector<Node> OPEN = new Vector<Node>();//声明不定长数组
Vector<Node> CLOSED = new Vector<Node>();
// 把初始节点送入OPEN表
OPEN.add(new Node(num_Begin, 0, evaluateService.ReverseNumber(num_Begin), 0, null, 0));
//初始节点是否是目标节点?
if(isEqual(OPEN.get(0).num,num_Finish)){
String s = "-----第1步-----\n";
for (int k = 0; k < 3; ++k) {
for (int j = 0; j < 3; ++j) {
s += CLOSED.lastElement().num[k][j] + " ";
//最后一个元素的节点数据
result[0][k][j] = CLOSED.lastElement().num[k][j];
}
s += "\n";
}
s += "-----结束-----\\n";
info[0] = 0; // 移动步数
info[1] = System.nanoTime() - starTime;
return result;
}
while (!OPEN.isEmpty()) {
// 计算可达性,限制搜索深度
if (!isAvailable(OPEN.get(0).num,num_Finish) || OPEN.get(0).depth > MAX_SEARCH_DEPTH) {
return null;
}
CLOSED.add(OPEN.get(0));
OPEN.remove(0);
int i = 0, j = 0;
// 找到空格
for (int k = 0; k < 9; ++k) {
if (CLOSED.lastElement().num[k / 3][k % 3] == 0) {
i = k / 3;
j = k % 3;
break;
}
}
int dir = CLOSED.lastElement().direction, dep = CLOSED.lastElement().depth;
int a[][] = new int[3][3];
// 1 上
if (i != 0 && dir != 2) {
for (int m = 0; m < 3; ++m) {
for (int n = 0; n < 3; ++n) {
a[m][n] = CLOSED.lastElement().num[m][n];
}
}
a[i][j] = a[i - 1][j];
a[i - 1][j] = 0;
Node temp = new Node(a, dep + 1, evaluateService.ReverseNumber(a), 1, CLOSED.lastElement(), 0);
// 子节点是否是目标节点?
if (isEqual(temp.num,num_Finish)) {
return Route2(temp, info);
}
OPEN.add(temp);
}
//参照“1 上”,执行下、左、右三个方向的扩展
}
return null;
}【实验结果与分析】
一、执行逻辑
| 介绍 |
运行截图 |
|
初始化界面由九宫格的初始状态和目标状态、估值函数选择区、算法选择区、路径打印区、结果记录表组成。 |
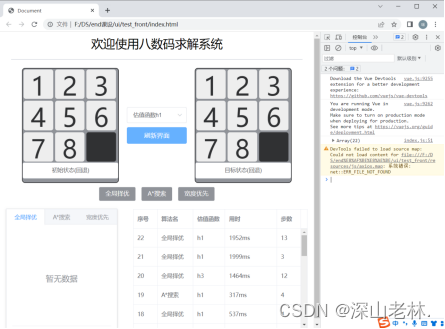
|
|
打乱九宫格后,点击“全局择先”按钮,跳出confirm框,询问是否确定进行路径查找。 |
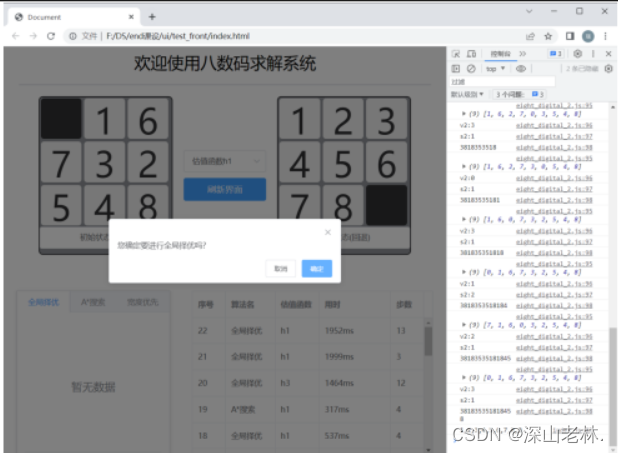
|
|
选择确定后,打印出初始状态到目标状态需要走的步数,显示在标签页内嵌的表格中。 |
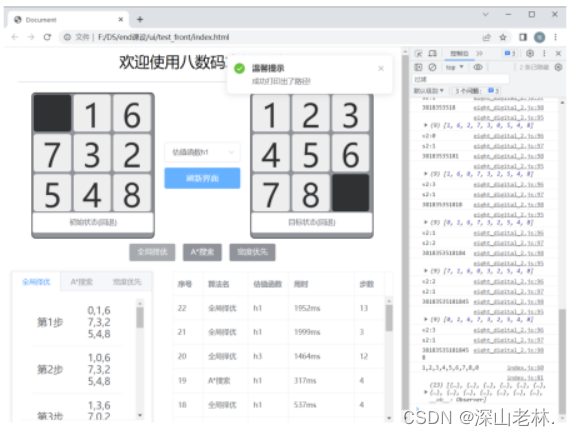
|
|
刷新界面后数据会从数据库回显到表格中,三种算法、四种估值函数均可用 |
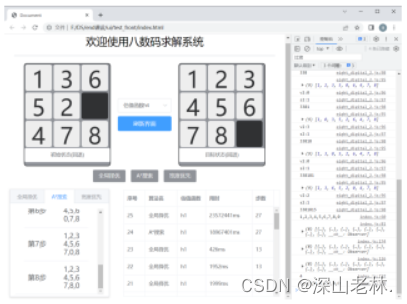
|
二、结果测试
| 信息 |
测试截图 |
| --测试用例1
全局择先 h1 10步 132ms |
|
| --测试用例2
全局择先 h2 10步 166ms |
|
| --测试用例3
A*搜索 h3 10步 319ms |
|
| --测试用例4
宽度优先 10步 655ms |
|




三、结果分析
从上面的对比结果来看可以得到以下的结果分析:
- 选取不同的估值函数,有时还是会得到相同的路径结果;
- A*搜素和全局择先的运行速度比较接近;
- 在初始状态和目标状态相同的情况下,宽度优先的效率低于两种启发式搜索算法,即全局择先和A*算法。
【总结】
现在是凌晨3点20,课设报告终于收尾了,回想这几天的课设制作,也确实是感想颇深。
我是上周四开始写课设的,第一天,当然是储备基础知识,像典型的A*算法,还有全局择先,宽度优先这些,都认真学了一遍。当然还构思了一下课设的思路,因为不限语言,不限技术,脑子里一大堆天马行空的想实现的东西,一开始设计是想对比三种算法的优劣+用深度学习的方法训练一下它去玩这个华容道,看看到底是跑出个什么东西,或者就是想做一个联网的平台,可以让用户自行在网站pk拼图速度,或是打乱让用户还原,比较看和三种算法相比,谁的还原步数少。还想了一个点子就是用户自行上传图片––>裁剪成九宫格的样子––>玩自定义拼图,但都碍于时间有限,就没做了。
当然,由于我目前为止主要学过的也是全栈开发,所以,在这次的课设中,最终呈现的效果,就是一个前后端交互的网页端系统了。
周五,写课设的第二天,想着把后端架子先搭好,结果一下是pom出问题,找半天发现是maven仓库路径写错了,一下又是springboot报错,找半天,然后对着重新敲一遍就又可以运行了,气得我肝疼。好不容易加载出Spring标标了,结果又因为tomcat配的是2.9.5以上版本,配高了它有些东西不认识,又得重新写配置,总而言之就是突然发现,从头搭一个Springboot项目,对经验不丰富的人确实挺困难的呐。
然后下午的时候,开始写逻辑,数据库如果做了实时回显的话,倒也不会显得我那张记录存储表那么没用,还是遇到了很玄学的问题,局部刷新不了+数据回显它只读第一次的,后面无法修改数据+reload整个界面又把我的路径给刷没了,所以最后这个问题就没解决了,后期有时间的话还是做成分页,elementui里倒是有个el-pagenation,今天试了绑定不了数据就没做了,下次有时间再试试。
总之,后端遇到的困难主要是搭框架,还有就是写算法逻辑的问题,估值函数还挺好写的,三个算法对着流程图敲就完了,但一开始设计的时候,图方便,设计的字符串输出,结果就是,前端写完之后,改的我肝疼。
分别测试了三种接口写法,一种是String直接打印结果的,非常丑,而且,不好裁。第二种是返回的三维数组,相当于是吧每种状态都存在了数组中,而每种状态本身就是个二维数组,但因为用了是数组,数组就肯定定长,定长没排满,结果就是一堆0,太心累了,找了一堆办法没裁好,最后想着,要不要就还是用Node存储Service层返回的结果,结果因为设计的问题,它递归了,嵌套了十几二十层,才能找到最里面的节点,前端拿到的json文件,一看,我是真束手无策。最后求助大佬,大佬用三维数组的那个接口,给我裁好了,但我还是追求界面美观,于是又花了一个多小时,把路径结果从直线存成了3x3的了。
Luego, el tercer día, el sábado, comencé a escribir la parte delantera. La interfaz no es nada difícil. Jiugongge es un Huarongdao 4x4. Eliminé el sitio web y entendí la lógica de 4x4 y lo cambié a 3x3. Es realmente agotador cambiar esto. La lógica de 4x4 es n%4. n÷4, ¿entonces 3x3 significa cambiar 4 por 3? No, la cuadrícula de nueve cuadrados 4x4 se puede mover en cuatro direcciones. Si la cambias directamente, definitivamente habrá un problema. La lógica es que debes poder entenderlo aproximadamente. Estaba principalmente atascado en la función de reversión. Lo que escribió fue n*3-v o algo así. Pensé, ¿3? Esto no está bien. El resultado es que esto se usa para registrar la dirección del movimiento y el número de pasos. Hay 8 formas de moverse en el cuadrado de 3x3, por lo que es 0-8, y moviendo dos cuadrados y moviendo un cuadrado, hay son modificaciones al plc. Es una relación de duplicación, por lo que aún existen requisitos para el pedido desde interruptor hasta corte. Pero fui yo quien finalmente lo escribió.
En resumen, el resultado final del diseño del curso es bastante bueno, el único inconveniente es que la base de datos aún no logró eco en tiempo real al final, la base de datos carecía de registros del estado inicial y del estado de terminación durante el diseño, y el La función del rompecabezas personalizado no fue escrita. También existe la función de restaurar automáticamente el lienzo o alterar la cuadrícula de nueve cuadrados. En realidad es necesaria, pero no ha sido escrita. Además, al diseñar clases de entidad, olvidé proteger las variables. Es muy inseguro hacerlas públicas.
Pero siento que lo que escribí todavía está bien. Este debería ser mi desafío para mí nuevamente. Un proyecto Springboot en 3 días es un paso más hacia ser un ingeniero completo. Además, a través del diseño de este curso, también aprendí algoritmos como la búsqueda codiciosa y heurística, que creo que traerán beneficios para mis estudios futuros.
Finalmente, se completa el diseño del curso. ¡Gracias al maestro por su ardua enseñanza este semestre!