Hacia una visión unificada del aprendizaje por transferencia eficiente en parámetros
El ajuste eficiente de parámetros es un método relativamente nuevo en PNL, y el primer trabajo representativo es el adaptador publicado en 2019. A partir de 2021, cada vez más personas están prestando atención a esta dirección y se han propuesto diferentes métodos: el trabajo representativo incluye ajuste de prefijo, ajuste P, ajuste rápido, bitfit, LoRA, etc. Este artículo proporciona una perspectiva unificada para clasificar estos esfuerzos.
El ajuste de grandes modelos de lenguaje previamente entrenados en tareas posteriores se ha convertido en el paradigma de aprendizaje de facto en PNL. Sin embargo, los métodos tradicionales ajustan todos los parámetros de un modelo previamente entrenado, lo que se vuelve prohibitivo a medida que crecen el tamaño del modelo y la cantidad de tareas. Un trabajo reciente propone una familia de métodos de aprendizaje por transferencia eficientes en parámetros que ajustan solo una pequeña cantidad de parámetros (adicionales) para lograr un rendimiento sólido. Aunque eficaces, los factores clave para el éxito y las conexiones entre los distintos enfoques no se conocen bien. En este artículo, desglosamos el diseño de métodos de aprendizaje por transferencia paramétricamente eficientes de última generación y proponemos un marco unificado que establece conexiones entre ellos. Específicamente, los redefinimos como modificaciones a estados ocultos específicos en un modelo previamente entrenado y definimos un conjunto de dimensiones de diseño que varían según los métodos, como la función mediante la cual se calculan las modificaciones y dónde se aplican. A través de un estudio empírico integral de la traducción automática, el resumen de texto, la comprensión del lenguaje y los puntos de referencia de clasificación de texto, aprovechamos una perspectiva unificada para identificar opciones de diseño importantes en enfoques anteriores. Además, nuestro marco unificado es capaz de transferir elementos de diseño entre diferentes métodos y, como resultado, podemos crear instancias de nuevos métodos de ajuste eficiente de parámetros que ajustan menos parámetros que los métodos anteriores y al mismo tiempo son más eficientes, logrando el mismo objetivo que El ajuste de todos los parámetros para las cuatro tareas arrojó resultados comparables.
Introducción
La transferencia de aprendizaje a partir de modelos de lenguaje previamente entrenados (PLM) es ahora un paradigma común en el procesamiento del lenguaje natural, que produce un sólido rendimiento en muchas tareas. La forma más común de adaptar un PLM genérico a tareas posteriores es ajustar todos los parámetros del modelo (ajuste fino completo). Sin embargo, esto da como resultado una copia separada de los parámetros del modelo ajustados para cada tarea, lo que tiene un costo prohibitivo cuando se ofrecen modelos que realizan una gran cantidad de tareas. Este problema es particularmente prominente a medida que la escala de PLM continúa expandiéndose, y ahora la escala de PLM varía de cientos de millones a cientos de miles de millones o incluso billones de parámetros.
Para aliviar este problema, se han propuesto algunas alternativas ligeras que actualizan solo una pequeña cantidad de parámetros adicionales mientras mantienen congelados la mayoría de los parámetros previamente entrenados. Por ejemplo, el ajuste del adaptador inserta pequeños módulos neuronales llamados adaptadores en cada capa de la red previamente entrenada y solo entrena el adaptador durante el ajuste fino.
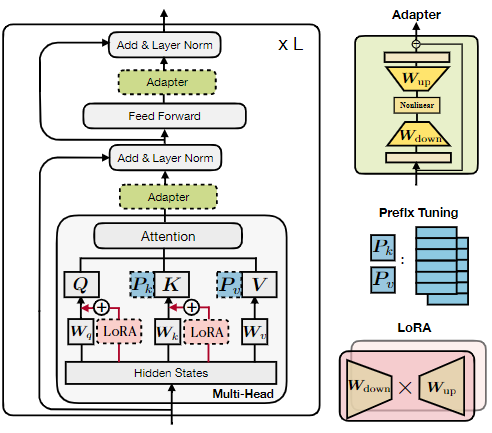
Figura 1: Ilustración de la estructura del transformador y varios métodos de última generación para un ajuste eficiente de los parámetros. Usamos bloques discontinuos para representar los módulos agregados por estos métodos.
Todos estos métodos en la Figura 1 muestran un rendimiento comparable al ajuste completo en diferentes conjuntos de tareas, generalmente actualizando menos del 1% de los parámetros del modelo original. Además de guardar parámetros, el ajuste eficiente de los parámetros le permite adaptarse rápidamente a nuevas tareas sin olvidos catastróficos y, a menudo, muestra una excelente solidez en evaluaciones fuera de distribución.
Este artículo tiene como objetivo responder tres preguntas: (1) ¿Cómo se relacionan estos métodos? (2) ¿Tienen estos métodos elementos de diseño comunes que sean críticos para su efectividad? ¿Cuáles son? (3) ¿Se pueden transferir los ingredientes activos de cada método a otros métodos para crear variantes más efectivas?
Descripción general de los métodos anteriores para un ajuste eficiente de los parámetros
Los tres métodos principales congelan los parámetros de PLM y solo ajustan los nuevos parámetros.
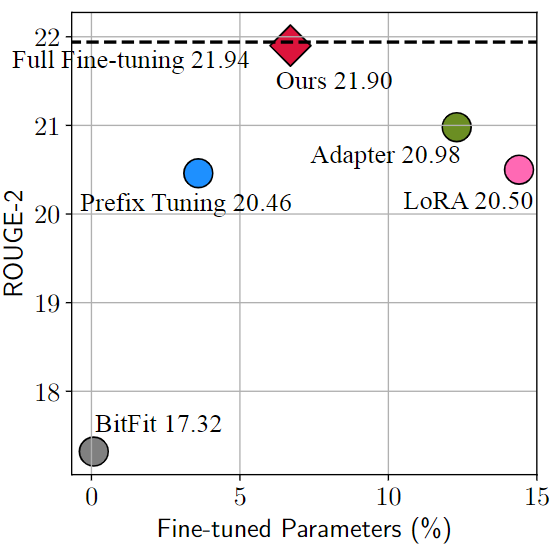
Figura 2: Rendimiento de diferentes métodos en la tarea de resumen XSum. El número de parámetros de ajuste fino es relativo a los parámetros de ajuste para un ajuste fino completo.
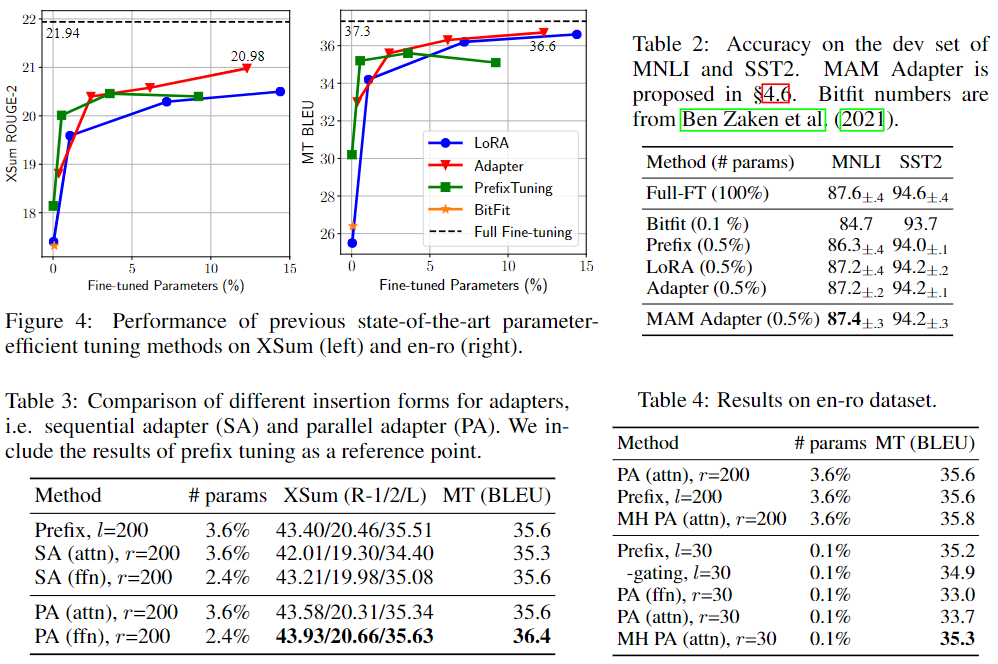
La figura anterior muestra el efecto de varios métodos de aprendizaje por transferencia eficientes en parámetros en la tarea de resumen de texto en inglés en el conjunto de datos Xsum. El porcentaje en el eje horizontal de la figura se refiere a la proporción de los parámetros ajustados por estos métodos con respecto a los parámetros ajustados mediante un ajuste fino completo; el eje vertical ROUGE-2 es el índice de evaluación de la tarea (cuanto mayor, mejor), Entonces, en esta figura, la posición superior izquierda es el enfoque ideal. En la figura, encontramos que Adapter[1], Prefix Tuning[2] y LoRA[3] son métodos con mejor rendimiento.
Adaptadores : el método del adaptador inserta pequeños módulos (adaptadores) entre las capas del transformador. La capa adaptadora generalmente usa el mapeo descendente de W down ∈ R d×r para mapear la entrada h a un espacio de baja dimensión especificado por la dimensión del cuello de botella r, y luego usa la función de activación no lineal f (·) y usa W up ∈ R r × El mapeo ascendente de d . Estos adaptadores están rodeados por una conexión residual, dando como resultado la forma final de 
colocar dos adaptadores secuencialmente dentro de una capa del transformador, uno después de la atención de múltiples cabezales y otro después de la subcapa FFN. Pfeiffer propuso una variante de adaptador más eficiente que se inserta solo después de la subcapa FFN "Agregar y especificación de capa".
Ajuste de prefijo : inspirado en el éxito del método de solicitud de texto, el ajuste de prefijo preestablece l vectores de prefijo ajustables con precisión en las teclas y valores de atención de múltiples cabezales en cada capa. Específicamente, dos conjuntos de vectores de prefijo Pk, Pv∈Rl×d están conectados con la clave original K y el valor V. Luego, realice atención de múltiples cabezas en el nuevo valor de clave de prefijo. El cálculo de la cabeza i en la Fórmula 2 se convierte en:
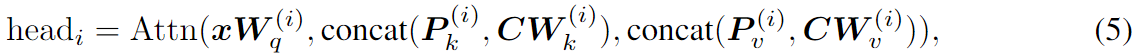
Pk y Pv se dividen en Nh vectores de cabeza respectivamente, P (i) k, P (i) v∈Rl×d/Nh representa el i-ésimo vector de cabeza. El ajuste rápido simplifica el ajuste fino de prefijos y solo preprocesa las incrustaciones de palabras de entrada de la primera capa.
LoRA : LoRA inyecta matrices de bajo nivel entrenables en la capa del transformador para aproximar las actualizaciones de peso. Para una matriz de peso previamente entrenada W∈Rd×k, LoRA utiliza la descomposición de rango bajo W+ΔW=W+WdownWup para representar su actualización, donde Wdown∈Rd×r y Wup∈Rr×k son parámetros ajustables. LoRA aplica esta actualización a las matrices de mapeo de valores y consultas (Wq, Wv) en la subcapa de atención de múltiples cabezales, como se muestra en la Figura 1. Para una entrada específica x de proyección lineal en atención de múltiples cabezales, LoRA modifica la salida de proyección h como:

donde s≥1 es un hiperparámetro escalar ajustable.

Otros : Otros métodos eficientes de ajuste de parámetros incluyen BitFit, que solo ajusta los vectores de sesgo en el modelo previamente entrenado, y la poda de diferencias, que puede aprender un vector de actualización de parámetros disperso.
marco unificado

Figura 3: Ilustración gráfica de los métodos existentes y variantes propuestas. "Módulo PLM" indica una subcapa de PLM que está congelada (como Atención o FFN). "PA escalado" significa adaptador paralelo escalado. Para ahorrar espacio, no incluimos aquí adaptadores paralelos de cabezales múltiples.
Inspirándonos en la conexión entre el ajuste de prefijos y los adaptadores, proponemos un marco general que tiene como objetivo unificar varios métodos de ajuste fino eficientes en parámetros de última generación. Específicamente, los resumimos en aprender un vector de modificación Δh, que se aplica a varias representaciones ocultas.
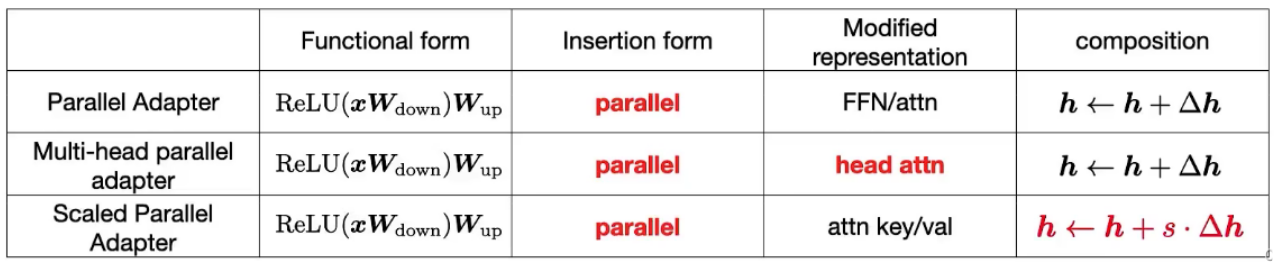
La forma funcional se refiere a la función específica para calcular Δh. Detallamos las formas funcionales de adaptador, ajuste de prefijo y LoRA en las Ecuaciones 4, 6 y 10, respectivamente. La forma funcional de todos estos métodos es similar a la arquitectura projdown→nonlinear→projup, mientras que "no lineal" degenera en funciones propias en LoRA.
Representación modificada indica qué representación oculta se modificó directamente.
El formulario de inserción se refiere a cómo se inserta el módulo agregado en la red. Como se mencionó en la sección anterior, como se muestra en la Figura 3, los adaptadores tradicionalmente se insertan de manera secuencial en una posición donde tanto la entrada como la salida son h. El ajuste de prefijo y LoRA, aunque no se describieron originalmente como tales, resultaron ser equivalentes a la inserción paralela, donde x es la entrada.
La función de composición se refiere a cómo se compone el vector modificado Δh con la expresión oculta original h para formar una nueva expresión oculta. Por ejemplo, el adaptador realiza una síntesis aditiva simple, el ajuste de prefijo utiliza una síntesis aditiva cerrada y LoRA escala Δh mediante un factor constante y lo agrega a la representación oculta original, como se muestra en la Ecuación 6.
Observamos que muchos otros métodos que no se muestran en la Tabla 1 también encajan en este marco. Por ejemplo, la sintonización rápida modifica la atención de la cabeza en la primera capa de una manera similar a la sintonización de prefijo y se pueden representar varias variantes de adaptadores de una manera similar a los adaptadores. Es importante destacar que este marco unificado nos permite estudiar métodos de ajuste preciso de parámetros a lo largo de estas dimensiones de diseño, identificar opciones de diseño clave y potencialmente transferir elementos de diseño entre diferentes métodos, como se muestra en las siguientes secciones.
Transferir elementos de diseño.
Aquí, y en la Figura 3, describimos solo algunos métodos nuevos que se pueden obtener transfiriendo elementos de diseño entre diferentes métodos a través de nuestra vista unificada anterior: (1) Los adaptadores paralelos se obtienen cambiando el prefijo. La inserción paralela de sintonización se transfiere a la variante del adaptador. Curiosamente, si bien propusimos el adaptador paralelo debido a su similitud con la sintonización de prefijos, un trabajo concurrente propuso de forma independiente esta variante y la estudió empíricamente; (2) El adaptador paralelo de cabezales múltiples es el Un paso adicional en el que el adaptador es más similar a la sintonización de prefijos: aplique Parallel Adapteris para modificar la salida de atención del parche como ajuste de prefijo. (3) El adaptador paralelo escalado es una variante que transfiere la composición y la forma de inserción de LoRA al adaptador, como se muestra en la Figura 3e.
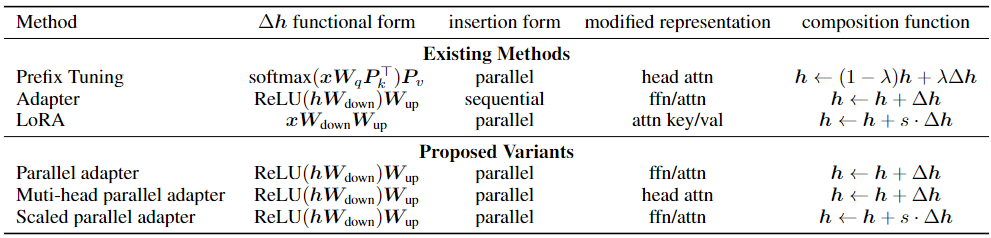
Tabla 1: Métodos efectivos de ajuste fino para parámetros desglosados a lo largo de dimensiones de diseño definidas. Aquí, en aras de la claridad, escribimos directamente la función no lineal del adaptador como el ReLU de uso común. La parte inferior de la tabla ejemplifica nuevas variantes al transferir opciones de diseño de métodos existentes.
experimento
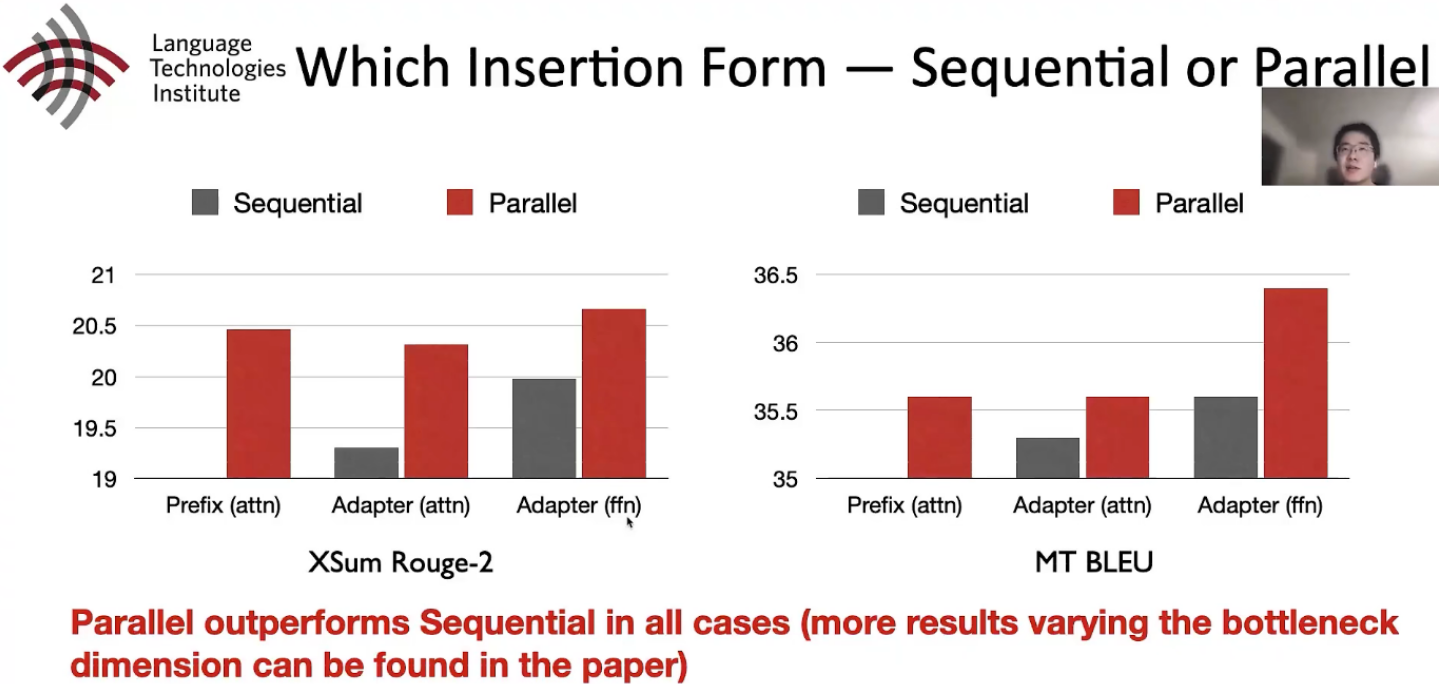
Secuencial o Paralelo
El adaptador paralelo (PA) supera al adaptador en serie (SA) en todos los casos
Atención o FFN
Para la representación modificada, el autor comparó los efectos de agregar atención y agregar feed forward y descubrió que, en términos generales, agregar feed forward tiene un mejor efecto.
Resultados: Como se muestra en la Figura 5, cualquier método con modificación de FFN supera a todos los métodos con modificación de atención en todos los casos (los marcadores rojos son generalmente más altos que todos los marcadores azules, la única excepción es ffn-PA, con parámetros del 2,4%), a menudo con menos parámetros. Cuando se aplica el mismo método a FFN, siempre mejora con respecto a su contraparte de atención. Estos resultados muestran que la modificación de FFN puede utilizar parámetros aumentados de manera más efectiva que la atención, independientemente de la forma funcional o las funciones constituyentes. Nuestra hipótesis es que esto se debe a que FFN aprende patrones de texto específicos de tareas, mientras que la atención aprende interacciones por pares y no requiere mucha capacidad para adaptarse a nuevas tareas.
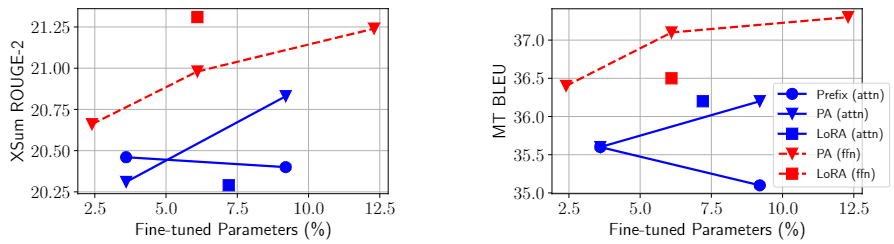
Figura 5: Resultados de XSum (izquierda) y en-ro (derecha). PA significa Adaptador paralelo. Los marcadores azul y rojo se aplican a las modificaciones de las subcapas atención y FFN respectivamente.
Combinando los resultados de la Figura 5 y la Tabla 4, llegamos a la conclusión de que la atención del cabezal de modificación muestra los mejores resultados cuando el presupuesto de parámetros es muy pequeño, mientras que FFN puede utilizar mejor las modificaciones en capacidades mayores. Esto sugiere que puede ser eficaz asignar un mayor presupuesto de parámetros a las modificaciones de FFN, en lugar de tratar la atención y la FFN por igual.
Función de composición
El diseño de LoRA es relativamente bueno, simple y efectivo, mientras que la interpolación lineal del ajuste de prefijo es relativamente complicada.
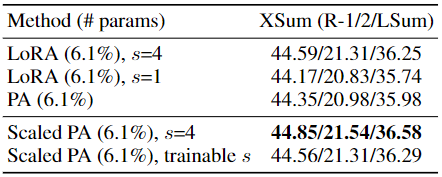
Tabla 5: Resultados de XSum cuando se utilizan diferentes funciones de combinación. La notación modificada es FFN. (Escalado) El tamaño del cuello de botella de PA es r = 512 y el tamaño del cuello de botella de LoRA es r = 102.
Integración efectiva mediante la transferencia de elementos de diseño beneficiosos.
Primero destacamos tres hallazgos de las secciones anteriores: (1) Los adaptadores paralelos proporcionales son la mejor variante de FFN modificado; (2) FFN puede utilizar mejor las modificaciones en capacidades mayores; (3) Cabeceras modificadas La atención parcial, como el ajuste de prefijos, puede lograr fuertes rendimiento con sólo el 0,1% de los parámetros. Inspirándonos en ellos, hibridamos el diseño ventajoso detrás de estos hallazgos: específicamente, utilizamos ajuste de prefijo con una dimensión de cuello de botella pequeña (l=30) en la subcapa de atención y asignamos más presupuesto de parámetros, usando un adaptador paralelo escalado (r=512) modifica FFN representación. Dado que el ajuste fino de prefijos puede verse como una forma de adaptador en nuestro marco unificado, llamamos a esta variante Adaptador Mix-And-Match (Adaptador MAM). En la Tabla 6, comparamos el adaptador MAM con varios métodos de ajuste fino eficientes en parámetros. Para completar, también enumeramos en la Tabla 6 los resultados de otras versiones combinadas: usando adaptadores paralelos en la capa de atención y la capa FFN, y combinando el ajuste previo (attn) con LoRA (ffn); todas estas versiones combinadas son comparables con sus respectivos prototipos. han sido mejorados. Sin embargo, el adaptador MAM logra el mejor rendimiento en ambas tareas y solo necesita actualizar el 6,7% de los parámetros previamente entrenados para lograr nuestro efecto completamente ajustado. En la Tabla 2, también presentamos los resultados del adaptador MAM en MNLI y SST2, donde el adaptador MAM solo agrega el 0,5% de los parámetros previos al entrenamiento y logra resultados comparables a los del ajuste fino completo.
en conclusión
Nuestro trabajo propone un método de ajuste eficiente para modelos previamente entrenados, especialmente modelos de lenguaje. Los modelos de lenguaje previamente entrenados tienen una variedad de aplicaciones activas, como las descritas en nuestro artículo para resúmenes, traducción o comprensión del lenguaje. En términos de impacto ambiental, los métodos propuestos en este documento agregan una pequeña cantidad de parámetros y componentes adicionales a los modelos existentes, por lo que tienen un impacto negativo nominal en los tiempos de entrenamiento e inferencia; por ejemplo, en nuestros cuatro puntos de referencia, el Adaptador MAM final. requiere entre el 100% y el 150% del tiempo de entrenamiento porque el ajuste eficiente de los parámetros generalmente requiere más épocas para converger; el tiempo de inferencia es aproximadamente el mismo que el de un modelo completamente ajustado. Por otro lado, dado que el enfoque propuesto en este documento puede evitar la necesidad de un ajuste completo, esto también puede reducir significativamente el costo del modelo de servicio (en términos de memoria/servidores implementados).