(PTP) Mensaje de texto guiado por la posición para el entrenamiento previo del lenguaje visual
Mensaje de texto guiado por la posición del entrenamiento previo del lenguaje visual
Resumen
El preentrenamiento del lenguaje visual (VLP) ha demostrado la capacidad de unificar pares de imágenes y texto, facilitando una variedad de tareas de aprendizaje intermodales. Sin embargo, observamos que los modelos VLP a menudo carecen de capacidades de localización/conexión visual, que son cruciales para muchas tareas posteriores, como el razonamiento visual. En este trabajo, proponemos un nuevo paradigma de indicación de texto guiado por posición (PTP) para mejorar las capacidades de localización visual de modelos intermodales entrenados con VLP . Específicamente, en la etapa VLP, PTP divide la imagen en N × N bloques e identifica los objetos en cada bloque a través del detector de objetos ampliamente utilizado en VLP. Luego reformula la tarea de localización visual como un problema de completar espacios en blanco dado un PTP al alentar al modelo a predecir el objetivo en el bloque dado o redefinir el bloque dado el objetivo, por ejemplo, completar "[P]" en el PTP o "[O]", "Hay una [O] en el bloque [P]". Este mecanismo mejora las capacidades de localización visual de los modelos VLP, ayudándolos así a manejar mejor diversas tareas posteriores. Al introducir PTP en varios marcos VLP de última generación, observamos mejoras significativas y consistentes en arquitecturas representativas de modelos de aprendizaje intermodal y varios puntos de referencia, como la recuperación Flickr30K de la línea base de ViLT (recuperación promedio + 4.8) y subtítulos COCO. de la línea base SOTABLIP (CIDEr+5.3). Además, PTP logra resultados similares a los métodos basados en detectores de objetos y es mucho más rápido en la inferencia porque PTP descarta su detector de objetos en el momento de la inferencia, mientras que este último no puede.
1. Introducción
Los modelos preentrenados de visión y lenguaje (VLP) como CLIP, ALIGN y CoCa han impulsado significativamente el rendimiento de vanguardia en muchas tareas de aprendizaje intermodales, como la respuesta visual a preguntas, el razonamiento y los subtítulos de imágenes. Por lo general, un modelo multimodal general primero se entrena previamente con datos de subtítulos de imágenes a gran escala de manera autosupervisada para ver datos suficientes para mejores capacidades de generalización, y luego se realiza en tareas posteriores. Debido a su notable efecto, este paradigma de modelo VLP ajustado previamente al entrenamiento ha dominado el campo multimodal.
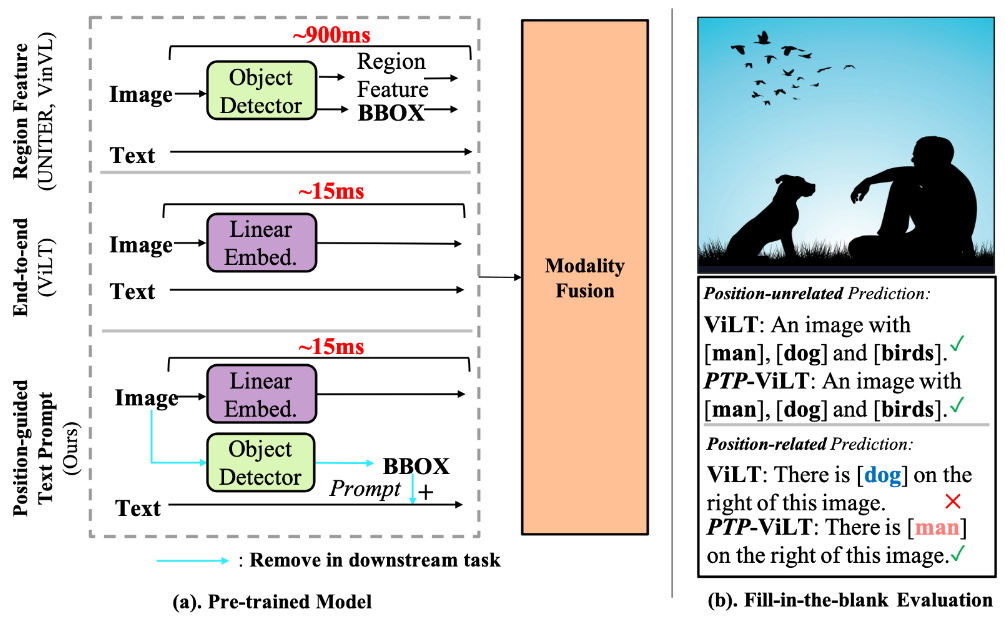
Figura 1. Comparación de tres marcos de aprendizaje de VLP y su desempeño. (a) Comparación de VLP basado en características regionales (RF-VLP), VLP de extremo a extremo (E2E-VLP) y nuestro VLP basado en mensajes de texto guiado por posición (PTP-VLP). Nuestro PTP-VLP solo requiere unos 15 ms de tiempo de inferencia, que es lo mismo que E2E-VLP pero mucho más rápido que RF-VLP. (b) En cuanto al problema de conocimiento de la posición que surge ampliamente en muchas tareas posteriores, RFVLP y PTP-VLP pueden predecir bien los objetos en el caso de entrada de texto e imágenes enmascaradas, mientras que E2E-VLP no puede señalar con precisión los objetos en la imagen. información del objeto.
En VLP, como se observó en estudios anteriores, la base visual es crucial para muchas tareas. Para modelar la información de ubicación, el modelo VLP tradicional (parte superior de la Figura 1 (a)) adopta un rcnn más rápido pre-entrenado en el genoma visual de clase 1600 para extraer características regionales prominentes y cuadros delimitadores. Luego, estos modelos utilizan tanto cuadros delimitadores como características de objetos como entrada. De esta manera, estos modelos pueden aprender no sólo qué objetos están contenidos en la región saliente, sino también dónde están esos objetos. Sin embargo, cuando se utilizan características regionales como entrada, el modelo se centra en los elementos dentro del cuadro delimitador e ignora los datos contextuales fuera del cuadro delimitador. Lo que es más grave es que en tareas posteriores, estos métodos aún necesitan usar detectores para extraer objetos, lo que brinda a las personas una velocidad de inferencia muy lenta.
Para deshacerse de las características regionales para una mayor eficiencia, una investigación reciente (en la Figura 1(a)) adopta imágenes de píxeles sin procesar como entrada en lugar de características regionales, y entrena el modelo de extremo a extremo con coincidencia de imagen-texto y pérdidas de simulación de lenguaje enmascarado. . A pesar de ser más rápidos, estos modelos no aprenden bien la ubicación de los objetos y las relaciones entre ellos. Como se muestra en la Figura 1 (b), observamos que un modelo ViLT entrenado sabe muy bien cuáles son los objetos en la animación. Pero este modelo no aprende con precisión la ubicación de los objetos. Por ejemplo, predijo incorrectamente "el perro está en el lado derecho de esta imagen". Sin embargo, durante el ajuste fino, las tareas posteriores en realidad requieren información de la posición del objeto para comprender completamente la imagen.
En este trabajo, nuestro objetivo es aliviar el problema de la posición faltante de estos modelos de un extremo a otro mientras mantenemos tiempos de inferencia rápidos para las tareas posteriores. Inspirándonos en métodos recientes de aprendizaje de señales, proponemos un paradigma novedoso y eficaz de indicación de texto guiado por posición (PTP) (parte inferior de la Figura 1 (a)) para el entrenamiento previo de modelos intermodales. La idea clave es que al agregar marcadores de referencia comunes basados en la ubicación en imágenes y texto, la localización visual se puede reformular como un problema de completar espacios en blanco, simplificando al máximo el aprendizaje de la información del objeto. Para establecer la expresión del lenguaje natural en los datos de la imagen, PTP consta de dos partes: (1) Generación de etiquetas de bloque, dividiendo la imagen en N×N bloques e identificando objetos en cada bloque; (2) Generación de texto de indicaciones coloca la consulta texto en una plantilla de consulta de texto basada en la ubicación.
Al introducir información de ubicación en la capacitación previa, nuestro PTP permite que el modelo VLP tenga sólidas capacidades basadas en la visión. Al mismo tiempo, mantenemos tiempos de inferencia rápidos ya que no utilizamos detectores de objetos en tareas posteriores. Los resultados experimentales muestran que nuestro método supera en gran medida a métodos similares, especialmente en el caso de disparo cero. Por ejemplo, nuestro PTP-BLIP logra una recuperación de disparo cero Recall@1 en el conjunto de datos de coco con menos datos de entrenamiento (4 millones frente a 3B) y un modelo más pequeño (2,2 millones frente a 21B) que CoCa. Una precisión absoluta del 3,4% fue logrado. Además de las tareas de disparo cero, demostramos que PTP puede lograr un rendimiento sólido en el razonamiento visual guiado por la ubicación de objetos y otras tareas comunes de VLP, como la respuesta visual a preguntas y los subtítulos de imágenes.
2. Trabajo relacionado
2.1 Modelo de preentrenamiento del lenguaje visual
Los modelos VLP existentes se pueden dividir aproximadamente en tres categorías según su arquitectura: modelos de flujo único, modelos de flujo dual y modelos de codificador fusionado y de flujo dual. Estas tres arquitecturas se presentan a continuación:
- Los modelos de flujo único (como UNITER, ViLT) en la Figura 2 (a) operan con la concatenación de entradas de imágenes y texto. 2) El modelo de dos flujos (por ejemplo, CLIP) en la Figura 2(b) utiliza codificadores transformadores separados pero igualmente costosos para cada modalidad. Los dos modos no están concatenados en la capa de entrada, pero existe una interacción entre el conjunto superficial de vectores de imagen y vectores de texto. 3) Modelos de doble flujo y de fusión (como BLIP) La Figura 2(c) es una combinación de modelos de flujo único y de flujo dual.
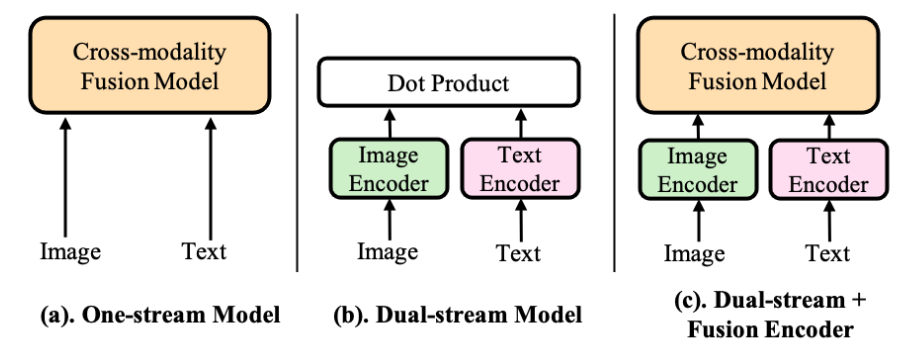
Figura 2. Tres tipos de modelos de visión y lenguaje ampliamente utilizados. La principal diferencia es dónde se produce la fusión de información intermodal. La fusión de corriente única se encuentra en la etapa inicial, la fusión de corriente dual se encuentra en la etapa posterior y el último tipo de fusión se encuentra en la etapa intermedia.
En este trabajo, sin pérdida de generalidad, nos centramos en impulsar los tres modelos VLP debido a su ubicuidad y adaptabilidad a diferentes tareas posteriores.
2.2 Aprendizaje de sugerencias para visión por computadora
El aprendizaje de sugerencias se diseñó originalmente para probar el conocimiento en modelos de lenguaje previamente entrenados para tareas posteriores específicas. En los últimos años, han surgido investigaciones sobre el ajuste de señales en tareas visuales, como el aprendizaje multimodal y la comprensión de imágenes. Las sugerencias de color avanzadas agregan sugerencias de color a las descripciones de color de imágenes y texto para bases visuales. Lo más relevante para nuestro trabajo es el Aviso multimodal, que propone un ajuste rápido multimodal para los modelos VLPT y logra resultados prometedores en algunas tareas de lenguaje visual.
Sin embargo, estos esfuerzos, al igual que las primeras investigaciones de PNL, se centran en la ingeniería de señales en el ajuste, sin afectar la fase previa al entrenamiento. Por el contrario, el propósito de utilizar diseños de sugerencias en este trabajo es proporcionar al modelo la capacidad de comprender conceptos semánticos a un nivel más fino mientras aún se encuentra en la etapa de preentrenamiento.
2.3 Información de ubicación de aprendizaje en VLP
Se ha demostrado que las capacidades de localización son fundamentales para una variedad de tareas intermodales. Para introducir esta capacidad en los modelos VLP, los modelos ascendente y descendente y sus trabajos posteriores concatenan características regionales y vectores de cuadro delimitador. Sin embargo, la extracción de objetos requiere mucho tiempo en las tareas posteriores de inferencia. Recientemente, algunos trabajos propusieron entrenar modelos VLP con pérdida adicional de localización de objetos o pérdida de alineación de fragmentos, pero estos modelos son difíciles de extender porque están especialmente diseñados para marcos específicos. Por el contrario, nuestro objetivo es proponer un marco general para aprender información sobre la ubicación. Con este fin, proponemos un mensaje de texto simple que se puede insertar fácilmente en los marcos existentes .
3. Mensajes de texto para orientación sobre la ubicación
En esta sección, primero detallamos nuestro paradigma propuesto de indicación de texto guiado por posición (PTP para abreviar). Luego, presentamos cómo combinarlo con el marco actual de preentrenamiento del lenguaje visual (VLP) para mejorar sus capacidades visuales básicas tomando como ejemplos los clásicos y populares VILT, CLIP y BLIP.
3.1 Paradigma PTP
Para mejorar las capacidades de base visual de los modelos intermodales entrenados por VLP, proponemos un mensaje de texto guiado por posición (PTP) novedoso y eficaz para ayudar a los modelos intermodales a percibir objetos y alinearlos con el texto relevante. PTP es diferente de los métodos tradicionales de alineación del lenguaje visual, que concatenan características de destino y cuadros delimitadores como entrada para aprender la alineación entre el texto de destino y el relacionado, lo que allana un enfoque alternativo que disfruta de algunas ventajas, como se muestra en la Sección 3.2 presentada y analizada en Secta. Como se muestra en la Figura 3, PTP tiene dos pasos: 1) Generación de etiquetas de bloque, dividiendo la imagen de entrada en varios bloques e identificando el objetivo en cada bloque al mismo tiempo; 2) Generación de mensajes de texto, según el paso 1) , la tarea de localización visual se reformula como un problema de rellenar espacios en blanco. Con base en estos pasos, se puede insertar fácilmente PTP en el modelo VLP resolviendo el problema de completar espacios en blanco en PTP. Cubriremos estos dos pasos a continuación.
3.1.1 Generación de etiquetas de bloque
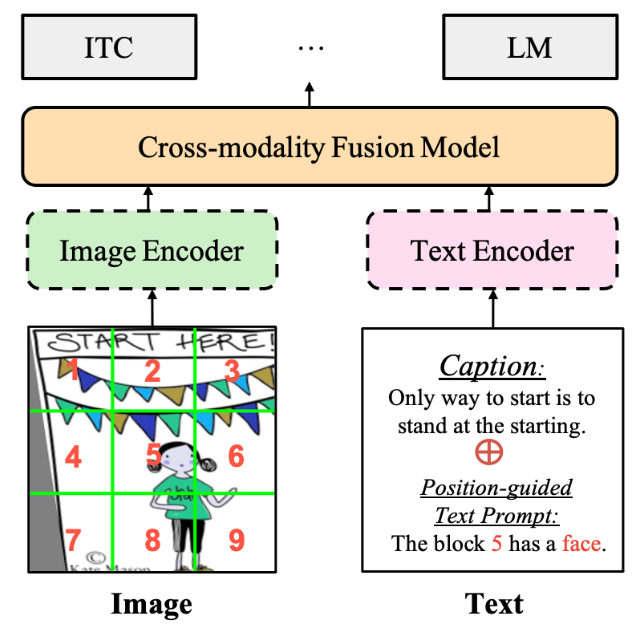
Figura 3. Marco general. Cualquier marco de preentrenamiento (flujo único, flujo dual, flujo dual + codificador fusionado en la Figura 2) y la mayoría de los objetivos se pueden integrar con nuestro PTP. Las líneas discontinuas indican que es posible que el modelo no exista. Eliminamos las sugerencias textuales para las tareas posteriores y evaluamos el modelo como de costumbre.
Como se muestra en la Figura 3, para cada par imagen-texto en la etapa de entrenamiento, dividimos equitativamente la imagen de entrada en N × N bloques. Luego identificamos los objetos en cada bloque de una de dos maneras:
(1) Detector de objetivos . Primero adoptamos el poderoso Faster-rcnn utilizado en VinVL para extraer todos los objetos de cada imagen. Esta versión de Faster-rcnn se basa en ResNeXt152 y está entrenada en el genoma visual de clase 1600. Luego , seleccionamos el objetivo confianza de predicción más alta representada porlaK Para cada bloque, seleccionamos el objetivo cuyo área central está en ese bloque. Finalmente, la etiqueta final de este bloque es la q de estos objetivos seleccionados. En este trabajo, utilizamos un detector de objetos para generar etiquetas de objetos de forma predeterminada.
(2) modelo CLIP . Debido a la eficiencia y eficacia del modelo CLIP, algunos trabajos recientes también intentan generar una supervisión regional basada en CLIP. Inspirándose en estos trabajos, PTP también puede generar supervisión de objetivos en forma de bloques a través del modelo CLIP (ViT-B). Primero, extraemos las palabras clave/frases M (por defecto 3000) más comunes en todo el corpus de texto. Estas palabras clave/frases se consideran nuestro vocabulario V. Luego, extraemos las características del texto ei, i∈ [1,…, M] de todas estas M incrustaciones de palabras clave/frases a través del codificador de texto CLIP.
Además, extraemos la imagen que incrusta h de cada bloque y calculamos la similitud entre cada característica del texto. La palabra clave/frase con la puntuación de similitud más alta se selecciona como etiqueta de destino final para este bloque en particular. Formalmente, el índice de etiqueta de objeto de cada bloque se calcula como:
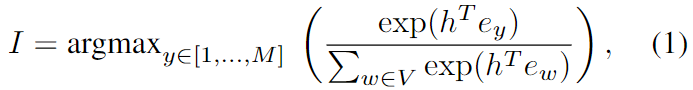
donde h es la característica visual incrustada del bloque seleccionado. Comparado con los detectores de objetos, el modelo CLIP tiene dos ventajas. En primer lugar, en comparación con las categorías de objetos predefinidas, las etiquetas de objetos generadas son más diversas. En segundo lugar, la generación de etiquetas de bloque es mucho más rápida que los detectores de objetos, por ejemplo, 40 veces más rápido que el modelo Faster-RCNN (ResNeXt152). Consulte la Sección 4.3 para comparar.
3.1.2 Generación de mensajes de texto
Para cada par de entrenamiento de imágenes de entrada, las etiquetas y ubicaciones de destino se generaron en la Sección 3.1.1, lo que nos permite diseñar un mensaje de texto simple de la siguiente manera: "El bloque [P] tiene una [O]
"
. ∈{1,…, N 2 } representa el índice del bloque seleccionado, que se utiliza para representar la posición del objeto; O representa la etiqueta de destino generada para el bloque P. Tenga en cuenta que exploramos opciones de diseño más rápidas en la Sección 4.3. Para algunos P, podemos tener múltiples opciones para O, ya que el bloque puede contener múltiples objetos. Para este caso, elegimos aleatoriamente una O cada vez. De esta manera, cada oración en nuestro PTP incorpora la ubicación y el lenguaje de los objetos en el modelo, proporcionando una nueva forma de alinear objetos y texto relacionado.
3.2 Entrenamiento previo de PTP
En este trabajo, incorporamos nuestro PTP al marco VLP convencional, lo que da como resultado PTP-ViLT, PTP-CLIP y PTP-BLIP. Luego de recibir el PTP, tenemos dos opciones para entrenar estos modelos:
Integre en tareas existentes . La forma más sencilla de utilizar indicaciones de texto es cambiar la entrada de texto. Como se muestra en la Figura 3, el texto del mensaje y el título original simplemente se rellenan juntos. Formalmente, el título de entrada x de nuestro método se representa como:

donde w es el texto y q es nuestro mensaje de texto generado. Luego entrenamos el modelo VLP de un extremo a otro utilizando objetivos tradicionales. Adoptamos pérdida de modelado de lenguaje (LM), coincidencia de imagen-texto (ITM) y pérdida de comparación de imagen-texto (ITC) para entrenar nuestro PTP-BLIP; utilizamos ITM y pérdida de modelado de lenguaje enmascarado (MLM) para entrenar nuestro PTP-ViLT; Solo utilizamos la pérdida de ITC para entrenar PTP-CLIP. Debido al buen rendimiento de este método, lo utilizamos como método predeterminado para todos los experimentos.
Como nueva tarea de pretexto . Además, exploramos la predicción de ubicación como una tarea adicional de modelado del lenguaje. Formalmente, si D son los datos previos al entrenamiento, y1, ..., yT son las secuencias de tokens de entrenamiento para el mensaje de texto q que generamos, entonces, en el paso de tiempo t, diseñamos nuestro modelo para predecir una distribución de probabilidad p(t ) = p (*|y1,…, yt-1). Luego tratamos gradualmente de maximizar la probabilidad de ser el marcador correcto. La pérdida de predicción del objetivo se calcula de la siguiente manera:
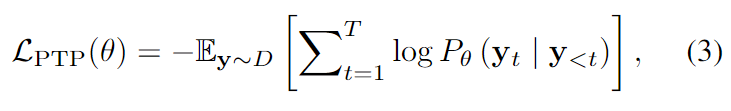
donde θ es el parámetro entrenable del modelo. De esta manera, se le pide al modelo que prediga qué bloque P tiene el objetivo y cuál es el objetivo O en este bloque.
Discusión . Vale la pena señalar que nuestro método no requiere modificación de la red subyacente y se puede aplicar a cualquier modelo VLP sin complicaciones. El modelo está diseñado para aprender información de posición a partir de imágenes de píxeles sin procesar. Tenga en cuenta que solo en la etapa previa al entrenamiento necesitamos la información de ubicación del objetivo; sin embargo, en las tareas posteriores, evaluamos el modelo de manera normal de extremo a extremo sin la información del objetivo para deshacernos del objetivo pesado. extracción de características.
4. Experimentar
En esta sección, evaluamos empíricamente múltiples tareas posteriores de PTP y presentamos un estudio integral.
4.1 Configuración experimental
Primero describimos las condiciones experimentales previas al entrenamiento, incluido el conjunto de datos, la configuración del entrenamiento, los procedimientos de evaluación y los modelos de referencia utilizados en nuestro estudio.
conjunto de datos . Al igual que estudios anteriores, primero utilizamos una configuración 4M que consta de cuatro conjuntos de datos populares de preentrenamiento (COCO, VG, SBU y CC3M). Tras un trabajo reciente, también exploramos la configuración de 14M, que incluye el conjunto de datos CC12M adicional (en realidad, solo hay imágenes de 10M disponibles) además del conjunto de datos de 4M. Para obtener más detalles sobre el conjunto de datos, remitimos al lector al material complementario.
Configuraciones de entrenamiento . Nuestro modelo está implementado en PyTorch y preentrenado en 8 GPU NVIDIA A100. Para los hiperparámetros de optimización y entrenamiento, seguimos la implementación original desde los trabajos básicos para una comparación justa. Para mejorar la imagen, exploramos RandAugment y utilizamos todas las estrategias originales excepto la inversión de color, ya que la información del color es importante. Aumentamos los cuadros delimitadores de la misma manera que las imágenes para implementar transformaciones afines como la rotación. Durante el entrenamiento previo, tomamos muestras aleatorias de imágenes con una resolución de 224 × 224 y aumentamos la resolución de la imagen a 384 × 384 para realizar ajustes.
línea de base . Evaluamos tres variantes del marco de preentrenamiento, incluido ViLT de flujo único, CLIP de codificador dual y BLIP de codificador fusionado, para evaluar su rendimiento superior. Para hacer una comparación justa, adoptamos ViTB/16 como codificador visual base y utilizamos el mismo conjunto de datos.
4.2 Principales resultados
En esta sección, integramos nuestro PTP en las redes existentes y lo comparamos con los métodos VLP existentes en una amplia gama de tareas posteriores de visuallingüística. Luego presentamos cada tarea y afinamos la estrategia. Se pueden encontrar más detalles en el material complementario.
4.2.1 Recuperación de imagen y texto
Evaluamos la recuperación de imagen a texto (TR) y la recuperación de texto a imagen (IR) de PTP en los puntos de referencia COCO y Flickr30K. Para PTP-BLIP, luego de la implementación original, adoptamos una estrategia de reordenamiento adicional.
Primero informamos los resultados de recuperación de disparo cero para las configuraciones de imagen-texto y texto-imagen en la Tabla 1. 1. Descubrimos que PTP mejora significativamente la línea de base en todas las métricas. Por ejemplo, para la línea de base de ViLT, PTP genera una mejora absoluta del 13,8 % (del 41,3 % al 55,1 %), superando a Recall@1 para la recuperación de imagen a texto en MSCOCO. Además, basado en el poderoso BLIP, nuestro PTP-BLIP incluso supera al CoCa en la mayoría de las tasas de recuperación de MSCOCO con muchos menos datos.
Tabla 1. Resultados de la recuperación de texto e imagen de toma cero en conjuntos de datos de Flickr30K y MSCOCO. Eliminamos métodos que se entrenan en corpus más grandes o utilizan modelos más grandes. †Denota un modelo implementado por nosotros mismos y entrenado en el mismo conjunto de datos, ya que el conjunto de datos original no es accesible o no fue entrenado en estos fragmentos. Avg es el promedio de todas las recuperaciones de imagen a texto y de todas las recuperaciones de texto a imagen.
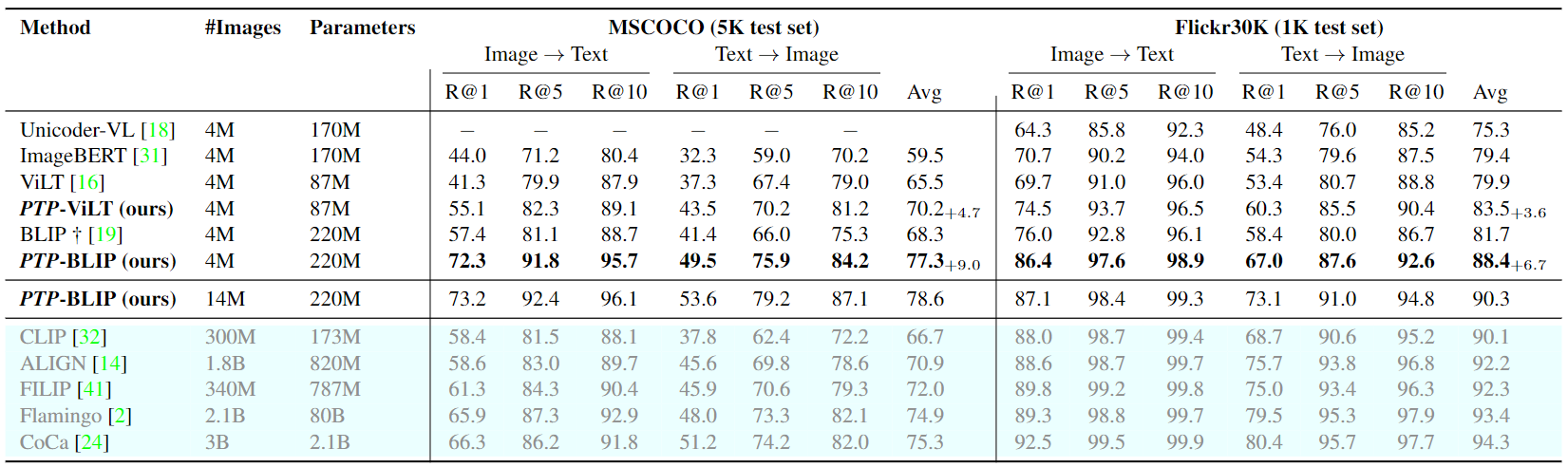
En la Tabla 2.2 se muestra una comparación resumida de las configuraciones de ajuste entre diferentes modelos, de la cual podemos ver: (1) PTP supera las líneas de base BLIP y ViLT por un amplio margen en ambos conjuntos de datos. Por ejemplo, PTP-ViLT logra una impresionante mejora del 5,3% en R@1 del TR de MSCOCO. (2) Tomando el potente BLIP como base, PTPBLIP logra un rendimiento de última generación a la misma escala. Tenga en cuenta que el costo de capacitación es el mismo que el de la línea base BLIP porque entrenamos PTP con la misma configuración que la línea base y no aumentamos el token de texto de entrada máximo. Bajo un marco similar, podemos incluso cerrar la brecha entre la configuración 4M y ALBEF (datos 14M).
Tabla 2. Resultados de ajuste para la recuperación de imagen a texto y la recuperación de texto a imagen en COCO y Flickr30K. Tenga en cuenta que UNITER, OSCAR y VinVL utilizan cuadros delimitadores y funciones de destino. BeIT-3 utiliza un corpus de texto adicional de 160 GB.
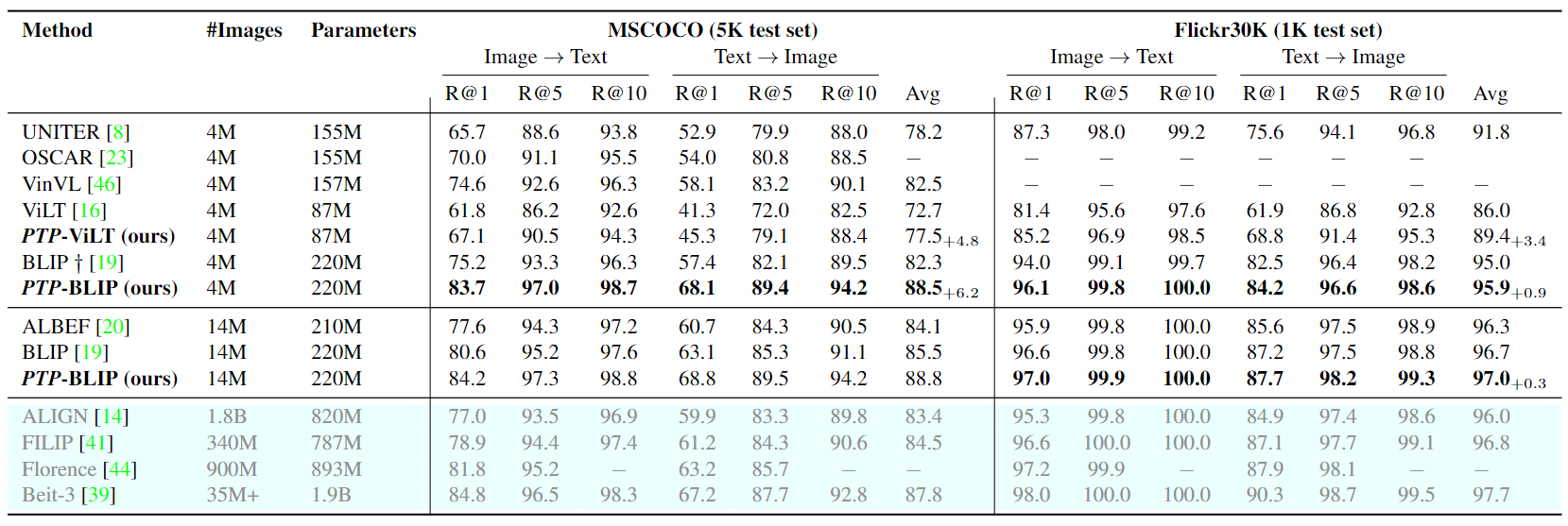
De los resultados anteriores, señalamos que UNITER, OSCAR, VinV e ImageBERT usan fastr-cnn como nosotros. Sin embargo, los resultados de nuestro PTP son mucho mejores que estos trabajos relacionados. Además, solo utilizamos el detector de objetos en la etapa de preentrenamiento. Esto demuestra que los detectores de objetos no son el secreto del éxito y que cómo utilizar la información de posición es crucial para los modelos VLP.
4.3 Ablación y opciones de diseño
En esta sección, primero evaluamos nuestro método en la tarea de recuperación en el entorno 4M en comparación con tres líneas de base bien conocidas. Luego entrenamos un modelo BLIP en CC3M como base y realizamos varias ablaciones.
4.3.1 Cambios de arquitectura
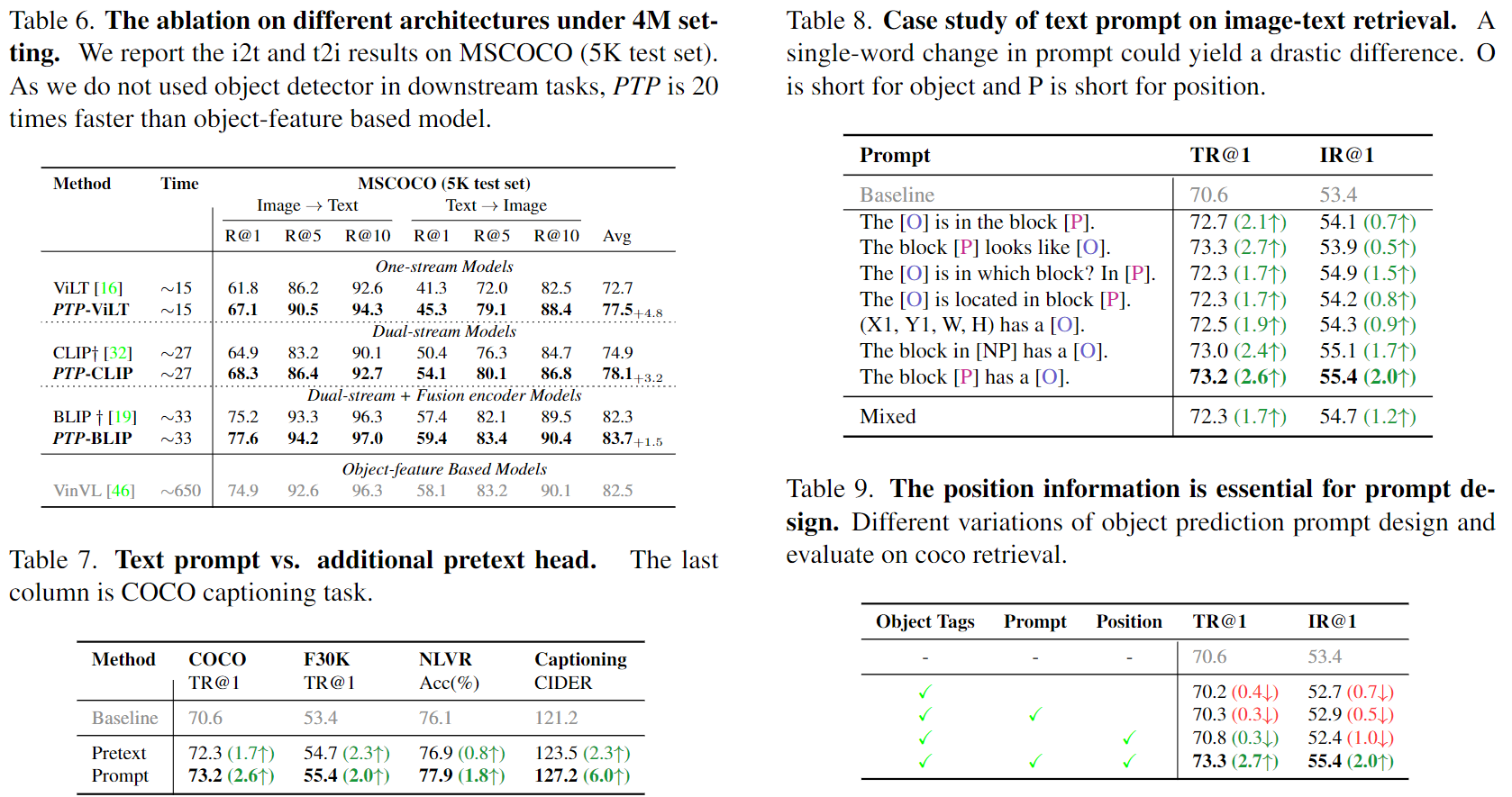
Realizamos experimentos con tres líneas de base diferentes: ViLT, CLIP y BLIP para explorar el impacto de PTP. La Tabla 6 informa el rendimiento del equipo de prueba COCO 5K. Al comparar los resultados de estos experimentos de referencia, encontramos que PTP mejora significativamente el rendimiento de i2t y t2i. Esto demuestra que PTP tiene buena versatilidad.
Además, comparamos los tiempos de ejecución. Dado que no utilizamos detectores de objetos ni señales en tareas posteriores, el costo computacional sigue siendo consistente con el modelo de referencia, pero es 20 veces más rápido que el VinVL basado en características de objetos.
4.3.2 Indicaciones de texto frente a tareas de pretexto adicionales
Estudiamos el efecto de utilizar PTP como una nueva tarea de Pretexto. De esta forma, la tarea Pretexto no afecta a otros objetivos de preentrenamiento como ITM e ITC, pero sí aumenta el coste computacional. Por el contrario, el diseño del mensaje simplemente modifica la entrada de texto, por lo que tendrá un impacto en todos los objetivos previos a la capacitación.
Informamos este resultado en la Tabla 7. Observamos que los diseños de Pretexto y Prompt mejoran la línea base en las cuatro tareas. Sin embargo, Hint es mucho mejor que Pretext, especialmente para los subtítulos de SIDRA de COCO (127,2 frente a 123,5). En este trabajo, utilizamos sugerencias por defecto debido a su eficiencia.
4.3.3 Otros tipos de mensajes de texto
Presentamos los resultados en la Tabla 8. Observamos que las ubicaciones precisas no producen mejores resultados que los bloques, y la razón puede ser que las ubicaciones precisas son difíciles de aprender.
Además, descubrimos que el uso de ID de bloque (por ejemplo, 0) o sustantivos (por ejemplo, arriba a la izquierda) aún daba resultados similares. Al final, descubrimos que la versión híbrida no produjo los mejores resultados.
4.3.4 La importancia de la posición en las indicaciones de texto
En este experimento, estudiamos la eficacia de obtener información de nuestro PTP en diferentes granularidades, como sin Posicional. Solo usamos [P] y [O] al eliminar mensajes. Enumeramos los resultados en la Tabla 9. Observamos: 1. Curiosamente, cada componente es crucial. Sin ningún componente, el rendimiento posterior se deteriorará gradualmente. Aunque OSCAR descubrió que el uso de etiquetas de objetos como entrada complementaria mejoraba los resultados cuando se usaban características regionales como entrada, hemos demostrado que las etiquetas de objetos son ineficaces cuando se utilizan imágenes de píxeles sin procesar. Esto ilustra la necesidad de establecer una señal factible para comprender la coherencia entre las etiquetas de los objetos y las regiones de la imagen.
4.3.5 Número de bloques
Exploramos si una información de ubicación más precisa contribuye a nuestro PTP. En la Figura 4, cambiamos el número de bloques de 1 × 1 (eliminando información de posición en PTP) a 4 × 4 e informamos el rendimiento relativo según los modelos BLIP y ViLT. Se puede observar que cuando el número de bloques supera 1, se mejoran los resultados de ambas redes troncales. Sin embargo, una vez que haya 16 bloques, el rendimiento de todas las actividades posteriores disminuirá relativamente. La razón puede ser que el cuadro delimitador previsto se desvía de la posición del objeto real, lo que da como resultado una cuadrícula que es demasiado pequeña y puede que no contenga el objeto seleccionado. Por lo tanto, recomendamos utilizar bloques de 3×3 ya que te permite disfrutar de la precisión.
Figura 4. Relación entre el número de bloques y la mejora relativa de la precisión. Exploramos dos líneas de base y demostramos mejoras en cuatro tareas diferentes.
4.3.6 ¿Son necesarios detectores de objetos?
En este trabajo, parte de la información del cuadro delimitador prevista proviene de Faster-rcnn. Para verificar la expresividad de los objetos, también consideramos dos cambios: 1. Similitud pura de fragmentos. Esta elección de diseño se debió principalmente a consideraciones de eficiencia; el uso de detectores de objetos requiere mucho tiempo y, a veces, no está disponible. Además del potente detector de objetos basado en ResNext152, también utilizamos una red Faster-rcnn más pequeña que aprovecha ResNet101 como columna vertebral.
Los resultados se muestran en la Tabla 10. También informamos el tiempo total de extracción de funciones en 8 GPU NVIDIA V100. Como puede verse en la tabla, encontramos que el uso de detectores más potentes conduce a mejores resultados, pero al mismo tiempo conlleva un enorme coste computacional. Además, observamos que los resultados de la incrustación de CLIP son muy cercanos a los de Faster-rcnn (ResNeXt152). Además, solo se necesita alrededor del 2,3% del tiempo de la versión Faster-rcnn (ResNeXt152) para extraer pseudoetiquetas para cada cuadrícula. Concluimos que el modelo CLIP recortado es una buena opción para detectores de objetos en PTP.
Tabla 10. Diferentes métodos para obtener pseudoetiquetas de malla y sus correspondientes tiempos de ejecución. Informamos los resultados de la recuperación de imagen a texto en el conjunto de datos COCO como referencia.
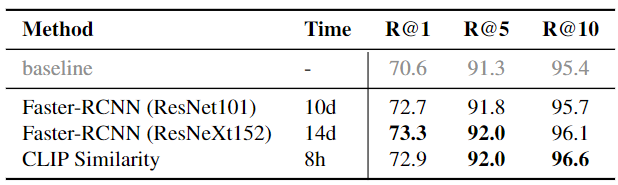
4.4 Visualización
Para explorar si el modelo entrenado con el marco PTP realmente puede aprender información de ubicación, diseñamos un experimento de evaluación para completar espacios en blanco en esta sección. Siguiendo a ViLT, bloqueamos algunas palabras clave y le pedimos al modelo que prediga las palabras bloqueadas y muestre sus mapas de calor correspondientes. Diseñamos dos pistas de texto, una para predecir la ubicación dada el sustantivo y otra para predecir el sustantivo faltante dada la ubicación. Mostramos los tres resultados de predicción principales; se pueden encontrar más visualizaciones en el suplemento.
Los resultados se muestran en la Figura 5. Por un lado, encontramos que PTP-ViLT puede realizar predicciones de objetivos correctas en función de la información de posición del parche y su concepto visual. Por otro lado, cuando solo se enmascara la información posicional, somos testigos de valores de probabilidad predichos altos para el bloque correcto. Por ejemplo, en la parte inferior de la Figura 5, nuestro modelo encontró correctamente todos los parches que parecían "personas". Con base en estos experimentos y la Figura 1, llegamos a la conclusión de que PTP puede ayudar al modelo VLP básico a aprender bien información de ubicación basada en señales de texto simples.
Figura 5. Evaluación de la tarea de rellenar espacios en blanco. Le pedimos al modelo que prediga qué objetos están contenidos en un bloque determinado y que prediga qué bloques contienen objetos específicos.
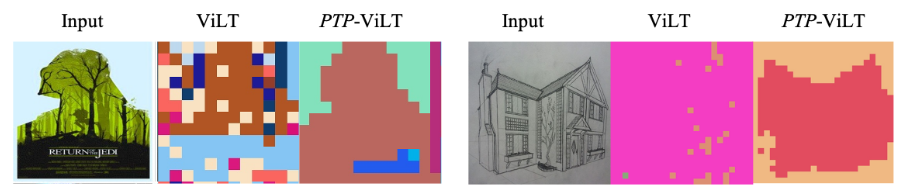
Además, utilizamos el algoritmo KMeans para agrupar las características a nivel de marcador de ViLT y PTP-ViLT. Intuitivamente, las etiquetas con semántica similar deben agruparse. Mostramos los resultados visualizados en la Figura 6. En comparación con la línea de base de ViLT, descubrimos que nuestro método puede agrupar parches similares con mayor precisión. Esto muestra que nuestro PTP aprende información semántica con bastante precisión.
Figura 6. Visualización de la agrupación de tokens. Entrenamos ViLT y PTPViLT utilizando el modelo ViT-B/32 en el conjunto de entrenamiento CC3M. Mostramos los resultados de la agrupación de tokens utilizando el algoritmo KMeans en el conjunto de pruebas CC3M. PTP-ViLT muestra agrupación alternativa
5. Limitaciones y conclusiones
Primero intentamos construir un modelo VLP de una manera simple aprovechando la información de ubicación de los detectores de objetos/modelos de entrenamiento existentes. Proporcionamos una práctica exitosa de configuración de avisos intermodales para ayudar a la ingeniería rápida. A través de experimentos rigurosos, demostramos que PTP se puede utilizar como un canal general para mejorar el aprendizaje de la información de posición sin mucho costo computacional adicional. Sin embargo, en este momento, PTP no tiene en cuenta cómo manejar etiquetas de objetos incorrectas. Además, este trabajo no exploró completamente señales más complejas. Investigaciones futuras también examinarán el desempeño de PTP en otras tareas de lenguaje visual.