Tipo de experimento: marco de datos de conversión RDD
Requisitos experimentales:
Dados tres conjuntos de datos de estudiantes, es necesario contar toda la información de estos tres conjuntos de datos y finalmente generar los diez mejores estudiantes . El formato del resultado de salida es: clasificación, clase, identificación del estudiante y puntuación.
Pasos:
1. Abra el software de idea y cree el archivo de la siguiente manera: Archivo —> Nuevo —> Proyecto —> Maven —> scala3–> main–> sql. Solo necesita seguir las instrucciones. Nota: (Si su computadora no tiene el complemento Scala instalado antes de realizar este experimento, debe instalar el complemento Scala en idea. Los pasos son: Archivo —> Configuración —> Complementos —> Ingresar a Scala —> Aplicar) .
2. Cree tres conjuntos de datos de estudiantes en el archivo principal recién creado en formato (.txt). Los datos que creé son los siguientes:
3. Agregue la dependencia de Spark SQL: agregue la dependencia de Spark SQL en el archivo pom.xml. El fragmento de código es como sigue
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
</dependency>
Nota: Puede agregar las últimas versiones de spark-sql. Este experimento que hice se realizó antes y la versión de dependencia experimental es la anterior.
archivo de datos:
1. datos del archivo class1.txt:
1,1001,50,2018001
2,1002,60,2018001
3,1003,70,2018001
4,1004,20,2018001
5,1005,80,2018001
6,1006,66,2018001
7,1007,99,2018001
2. datos del archivo class2.txt:
1,2001,55,2018002
2,2002,56,2018002
3,2003,88,2018002
4,2004,60,2018002
5,2005,78,2018002
6,2006,62,2018002
3. Datos del archivo class3.txt:
1,3001,99,2018003
2,3002,84,2018003
3,3003,59,2018003
4,3004,71,2018003
5,3005,69,2018003
6,3006,100,2018003
Después de crear los datos, podemos comenzar el experimento. El código del experimento es el siguiente.
Bloque de código experimental:
import io.netty.handler.codec.smtp.SmtpRequests.data
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{
DataFrame, Row, SparkSession}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions.dense_rank
import org.apache.spark.sql.functions._
case class student(班级:Int,学号:Int,成绩:Int)
object sql {
def main(args:Array[String]):Unit= {
val spark: SparkSession = SparkSession.builder()
.appName("test1")
.master("local[2]")
.getOrCreate()
val sc : SparkContext =spark.sparkContext
sc.setLogLevel("WARN")
val data1:RDD[Array[String]]=
sc.textFile("src/main/class1.txt").map(x=>x.split(","))
val data2:RDD[Array[String]]=
sc.textFile("src/main/class2.txt").map(x=>x.split(","))
val data3:RDD[Array[String]]=
sc.textFile("src/main/class3.txt").map(x => x.split(","))
val data = data1.union(data2).union(data3)
val studentRDD:RDD[student]=
data.map(x => student(x(3).toInt, x(1).toInt, x(2).toInt))
import spark.implicits._
val select=data1.union(data2).union(data3)
val studentDF:DataFrame=studentRDD.toDF("班级","学号","成绩")
//studentDF.sort(studentDF("成绩").desc).show(10)
val windowSpec= Window.partitionBy().orderBy(col("成绩") desc)
val xinliebiao=studentDF.withColumn("排名",row_number()
.over( Window.partitionBy().orderBy(col("成绩") desc)))
.select("排名","班级","学号","成绩")
//.where("rank<=10")
.show(10)
sc.stop()
spark.stop()
}}
Algunas explicaciones importantes del código anteriores:
1. Inicie el experimento e importe el paquete correspondiente y defina la clase de muestra: clase de caso estudiante (clase: Int, número de estudiante: Int, calificación: Int)
2. La función de importar spark.implicits. _ es Admite la conversión de RDD en DataFrame
3. funciones desc en orden descendente, col representa columna, orderBy representa clasificación
4. partición por es agrupar y ordenar solo algunos campos basándose en retener todos los datos.
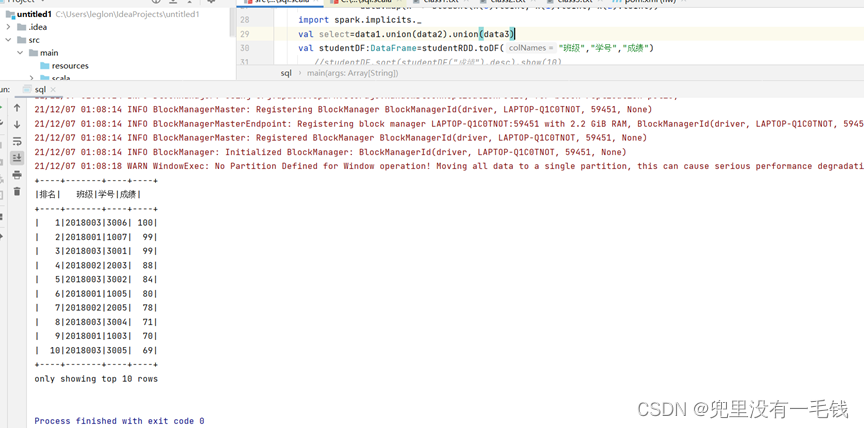
Captura de pantalla de los resultados experimentales:
En la imagen podemos ver las estadísticas y mostrar los diez mejores estudiantes .