CrossKD: Destilación de conocimientos entre cabezales para la detección de objetos densos, arXiv2306
Documento: https://arxiv.org/abs/2306.11369
Código: https://github.com/jbwang1997/CrossKD
Resumen
La destilación de conocimientos (KD) se ha validado como una técnica eficaz de compresión de modelos para aprender detectores de objetos comprimidos. La mayoría de los métodos KD de última generación existentes para la detección de objetos se basan en simulaciones de características, que generalmente se consideran mejores que las simulaciones predictivas. Este artículo encuentra que la inconsistencia en los objetivos de optimización entre las señales GT y los objetivos de destilación es una razón clave para la ineficiencia de las simulaciones de predicción.
Para aliviar este problema, el artículo propone un mecanismo de destilación CrossKD simple y efectivo, que transfiere las características intermedias del cabezal de detección del modelo de estudiante al cabezal de detección del modelo de maestro y obliga a que la predicción de la cruceta sea consistente con la predicción de el modelo docente. A través de este método de destilación, el cabezal de detección del modelo de estudiante puede evitar recibir señales de supervisión conflictivas de las anotaciones GT y las predicciones del modelo del maestro, mejorando así en gran medida el rendimiento de detección del modelo de estudiante.
En el conjunto de datos MS COCO, aplicando solo la pérdida de destilación de predicción, el CrossKD del autor mejora la precisión promedio del modelo GFL ResNet-50 de 40,2 a 43,7, superando todos los métodos de destilación de conocimiento existentes en el campo de la detección de objetos.
Introducción
conocimiento de fondo
Los métodos de destilación de conocimientos existentes se pueden dividir a grandes rasgos en dos categorías según el lugar de destilación:
- predicción imitando predicción imitando (destilación predictiva)
- Imitación de características (destilación de características)
Se entiende que la destilación se lleva a cabo desde dos niveles: el nivel de resultado de predicción y el nivel de característica intermedia.

- La simulación de predicción (ver Figura 1(a)), señala que la distribución suave de los resultados de predicción de los profesores es más beneficiosa para el aprendizaje de los estudiantes, en lugar de la distribución de Dirac de los valores GT. Las simulaciones predictivas tienen como objetivo minimizar la diferencia en las predicciones entre el modelo de profesor y el modelo de estudiante.

Entre ellos, representan los resultados de predicción del modelo de estudiante y del modelo de maestro respectivamente, mientras que el criterio de selección de región
cambia con el esquema y
se usa para medir la diferencia entre predicciones, como la divergencia KL para clasificación, L1 y LD para regresión.
Dado que las predicciones tienen un significado físico claro, la destilación predictiva puede proporcionar a los estudiantes conocimientos específicos de la tarea. Sin embargo, el bajo rendimiento de la destilación predictiva en comparación con los métodos de destilación característica limita su aplicación.
- La imitación de características (ver Figura 1 (b)) considera que las características intermedias contienen más información que la predicción del maestro. La imitación de características tiene como objetivo mejorar la coherencia del modelo profesor-alumno en términos de características latentes.

Entre ellos, representan las características intermedias del modelo de estudiante y del modelo de maestro respectivamente, generalmente características de salida de FPN.
Se utiliza para medir la distancia entre entidades, como MSE, PCC (coeficiente de correlación de Pearson).
Representa el principio de selección de región, que genera un peso para cada posición r en toda la región de la imagen R. Para evitar que el ruido de gran amplitud interfiera con la convergencia del modelo, diferentes métodos pueden utilizar diferentes principios de selección de regiones
para seleccionar regiones efectivas para la destilación y equilibrar el peso de las muestras de primer plano y de fondo.
Finalmente, la pérdida se normalizará mediante la acumulación |S| sobre todas las características intermedias .
La destilación de características se ha convertido en la corriente principal de los métodos de destilación de conocimientos para la detección de objetivos debido a su excelente rendimiento. Sin embargo, esto puede obligar al modelo de estudiante a extraer ruido innecesario del modelo de maestro, lo que puede afectar negativamente los resultados finales.
Punto de partida
La destilación predictiva juega un papel crucial en la destilación de modelos de detección de objetos. Sin embargo, desde hace tiempo se ha observado que la destilación predictiva es menos eficiente que la destilación característica. La destilación localizada (LD) mejora la destilación predictiva mediante la transferencia de conocimientos de localización. LD demuestra que la destilación predictiva tiene la capacidad de transferir conocimientos específicos de tareas, lo que permite que los modelos de los estudiantes se beneficien de una perspectiva diferente a la destilación de características.

Los autores observan que la destilación predictiva debe abordar el conflicto entre los objetivos de GT y los objetivos de destilación , que se ha ignorado en trabajos anteriores. Cuando se entrena mediante simulación predictiva, las predicciones del modelo de estudiante se ven obligadas a minimizar simultáneamente la diferencia entre los dos, lo que a su vez afecta el rendimiento del modelo de estudiante. Sin embargo, el objetivo de destilación predicho por el modelo del profesor suele ser significativamente diferente del objetivo GT asignado al modelo del estudiante.
Como se muestra en la Figura 2, el modelo de maestro produce probabilidades de clase inexactas en el área del círculo verde, lo que entra en conflicto con el objetivo de GT. Por lo tanto, durante el proceso de destilación, el modelo de estudiante sufre un proceso de aprendizaje contradictorio, que los autores creen que es la razón principal que impide que la destilación predictiva alcance un mayor rendimiento.
contribuir
Por lo tanto, el artículo propone un método novedoso de destilación de conocimientos para cabezales de detección cruzada, llamado CrossKD, para aliviar el problema del conflicto de objetivos. Como se muestra en la Figura 1 (c), las características intermedias del cabezal de detección del modelo de estudiante se ingresan en el cabezal de detección del modelo de maestro para obtener la predicción del cabezal de detección cruzada. Luego, se realiza una operación de destilación de conocimientos entre las predicciones del nuevo cabezal de detección cruzada y las predicciones originales del modelo docente.
CrossKD tiene dos ventajas principales:
- La pérdida por destilación de conocimientos no afectará la actualización del peso del modelo de estudiante Head, evitando el conflicto entre la pérdida de detección original y la pérdida por destilación de conocimientos.
- Dado que las predicciones de la cruceta y las predicciones del modelo del maestro se generan compartiendo parte del cabezal de detección del modelo del maestro, las predicciones de la cruceta son relativamente consistentes con las predicciones del modelo del maestro. Esto mitiga las diferencias entre pares profesor-alumno y mejora la estabilidad del entrenamiento de la destilación predictiva.
Estas dos ventajas permiten a nuestro CrossKD extraer conocimiento de manera eficiente de las predicciones del modelo docente y lograr un mejor rendimiento que los métodos de destilación de características de última generación anteriores.
Método CrossKD
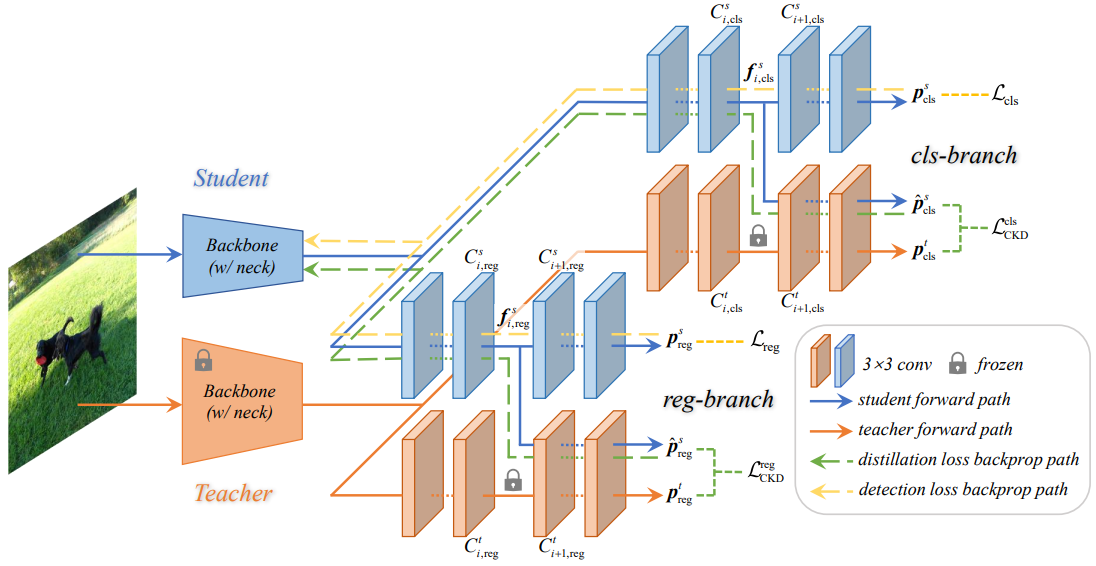

La destilación directa de las predicciones de los profesores adolece del problema del conflicto de objetivos, que impide que los métodos de destilación predictiva logren un buen rendimiento. Para aliviar este problema, esta sección propone un nuevo método de destilación de conocimientos entre cabezales (CrossKD). El marco general se muestra en la Figura 3. De manera similar a los métodos de destilación de predicción existentes, CrossKD destila directamente el resultado de la predicción. La diferencia es que CrossKD pasa las características intermedias del estudiante al cabezal de detección del profesor y genera predicciones cruzadas para la destilación.
Destilación del conocimiento entre cabezas
Tomando detectores densos (como RetinaNet) como ejemplo, cada cabezal de detección generalmente se compone de múltiples capas convolucionales, expresadas como . Para simplificar, supongamos que cada cabezal de detección tiene n convoluciones, por ejemplo, el cabezal de detección de RetinaNet tiene 5 convoluciones, 4 capas ocultas + 1 capa de predicción. Tomando las características
que representan
la salida,
se encuentra
la entrada y la predicción p se genera a través de la convolución final
. Por lo tanto, para una determinada pareja profesor-alumno, las predicciones se expresan respectivamente como
.
Además, CrossKD introduce adicionalmente las características intermedias del modelo de estudiante en la capa convolucional del cabezal de detección del modelo de profesor
para generar predicciones cruzadas
. En este momento, no se calcula
la pérdida por destilación entre ellos , pero
se calcula la pérdida por destilación KD entre ellos. Los objetivos de optimización de CrossKD se describen a continuación:

Entre ellos, S(·) y |S| representan el principio de selección de región y el factor de normalización respectivamente. Para evitar diseñar S(·) complejo, los autores siguen la operación predeterminada de entrenar detectores densos. En la rama de clasificación, S(·) es una función constante con un valor de 1. En la rama de regresión, S(·) es un indicador que genera 1 en el área de primer plano y 0 en el área de fondo. Dependiendo de las diferentes tareas de cada rama (por ejemplo, clasificación o regresión), se utilizan diferentes tipos para transferir de manera efectiva el conocimiento específico de la tarea a los estudiantes.
Con CrossKD, la pérdida por detección y la pérdida por destilación actuarán de forma independiente en diferentes ramas. Como se muestra en la Figura 3: el gradiente de pérdida de detección se propaga a través de toda la cabeza del estudiante, mientras que el gradiente de pérdida por destilación se propaga a las características latentes del estudiante a través de la capa de profesor congelada, aumentando así heurísticamente la coherencia entre el profesor y el alumno. En comparación con el ajuste directo de las predicciones entre pares profesor-estudiante, CrossKD permite que una parte de las cabezas de detección del estudiante se correlacione solo con la pérdida de detección, optimizando así mejor el objetivo GT.
optimizar el objetivo
La pérdida total de formación se puede expresar como la suma ponderada de la pérdida por detección y la pérdida por destilación de la siguiente manera:

donde, y
representan las pérdidas de detección, que se calculan entre el valor predicho del estudiante
y
el valor objetivo verdadero correspondiente
.
La pérdida adicional de CrossKD se expresa como
la suma
, que se calcula entre el valor previsto de la cruceta
y el valor previsto
del maestro .
En términos de implementación específica, el autor utiliza diferentes funciones de distancia para diferentes ramas de tareas .
- En la rama de clasificación, el puntaje de clasificación previsto por el modelo del maestro se considera una etiqueta suave, y la pérdida focal de calidad (QFL) se usa directamente para restringir la distancia entre el modelo del estudiante y los resultados de predicción del modelo del maestro;
- Rama de regresión, para el cabezal de regresión que hace una regresión directa al cuadro delimitador desde Anchor (RetinaNet, ATSS) o punto (FCOS), GIoU se usa directamente como cabezal de regresión; para el cabezal de regresión que predice un vector para representar la distribución de las posiciones del
cuadro (GFL), contiene el límite de proporción La distribución de Dirac representada por el cuadro tiene información más rica, destila efectivamente la información de posición y utiliza la divergencia KL para la transferencia de conocimiento.
experimento
experimento de ablación
Posiciones para aplicar CrossKD

- CrossKD puede mejorar el rendimiento del modelo en todas las posiciones de destilación;
- El mejor rendimiento de 38,7 mAP se logró en la tercera posición, que es 0,9 mAP más alto que el esquema de simulación de predicción LD existente.
CrossKD vs imitación de funciones

- PKD puede alcanzar 38,0 mAP cuando actúa sobre la función FPN, pero el rendimiento del modelo cae significativamente cuando actúa sobre el cabezal de detección;
- CrossKD logró 38,7 mAP, que es 0,7 mAP más alto que la solución PKD.

Los gradientes generados por PKD tienen un impacto grande y amplio en el mapa de características completo, mientras que los gradientes generados por CrossKD solo se centran en regiones con información semántica potencial .
CrossKD vs Prediction Mimicking

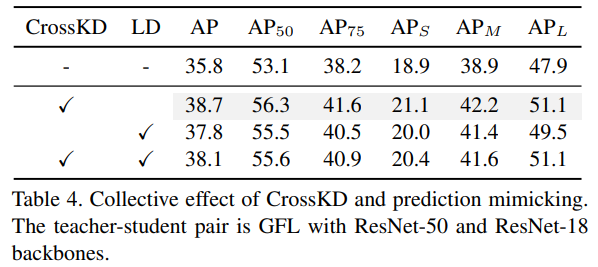
- Se pueden lograr mejoras de rendimiento estables reemplazando LD con CrossKD;
- Por el contrario, el rendimiento de la combinación CrossKD+LD cayó, del 38,7 de CrossKD al 38,1.

CrossKD y HEAD

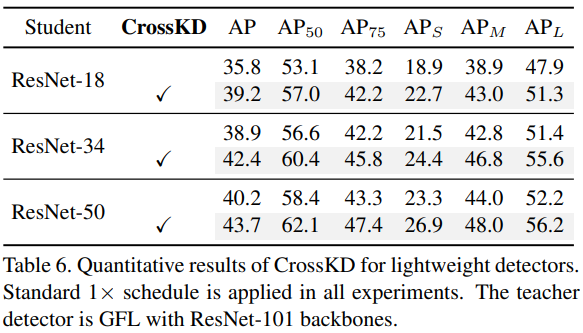
CrossKD para detectores ligeros
Experimento comparativo
Comparación con los métodos SOTA KD

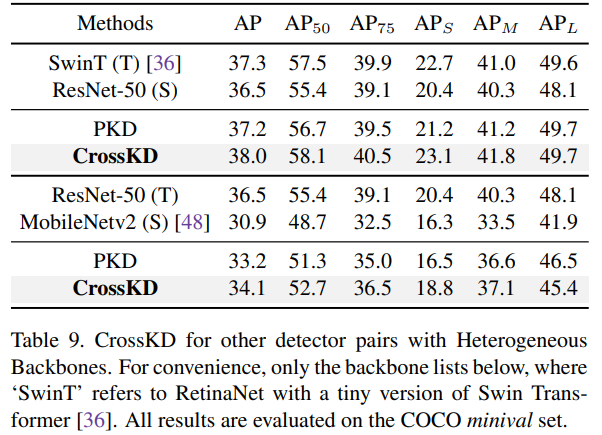
CrossKD en diferentes detectores


apéndice
Diferentes variaciones de CrossKD

Rendimiento de diferentes variantes.

Impacto de la pérdida por destilación de la rama de clasificación
