0. Tonterías al principio
0.1Selección técnica
Seleccione Elasticsearch-7.1.12
0.2 Antecedentes de selección
Dado que la versión de SpringCloud seleccionada tiene una prioridad más alta, después de determinar la versión de SpringCloud
, se determinan la versión de SpringBoot, las versiones de componentes relacionados, la versión de Elasticsearch y la versión de spring-data-elasticsearch.
relación de versión 0.3
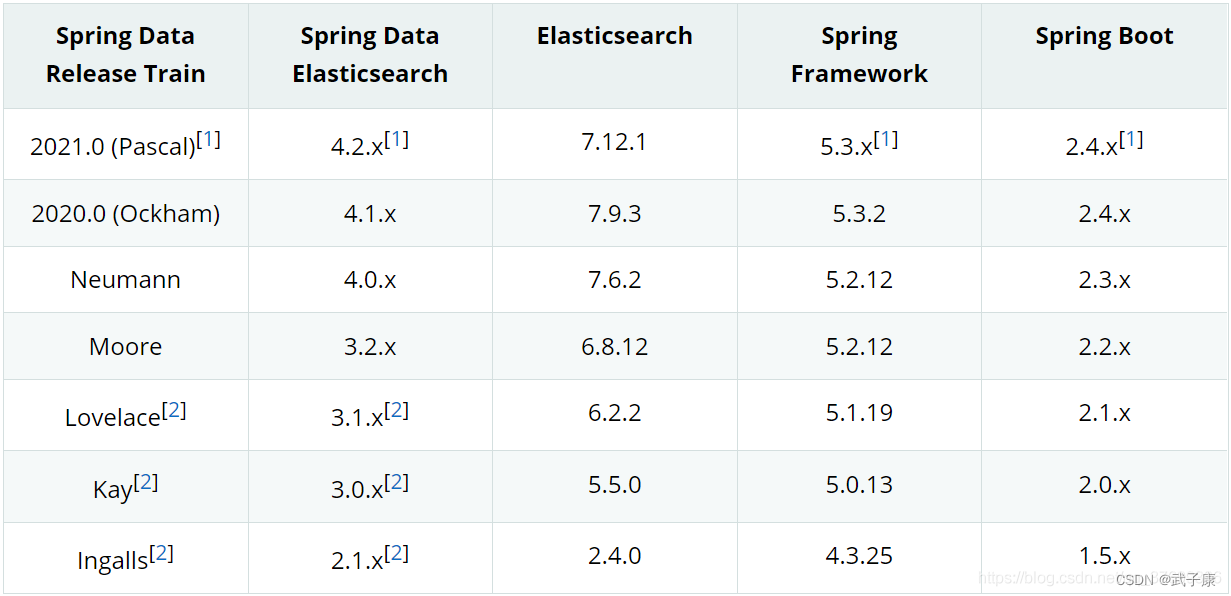
Debido a que el entorno de producción requiere estabilidad, no se utiliza la última versión,
si necesita una nueva versión, puede encontrarla en el siguiente enlace.
- Para la versión Spring, elija Spring oficial
- Versión SpringBoot Seleccione la versión SpringBoot
- Versión de SpringDataElasticsearch seleccione la versión de spring-data-elasticsearch
- Versión de SpringCloud seleccione la versión de SpringCloud
- Paquete maven Paquete maven POM
Para el entorno de aprendizaje actual, Docker se utiliza para construir el entorno para reducir los problemas de instalación y evitar intereses de aprendizaje frustrantes.
0.4 Requisitos previos
- (Tonterías) Una máquina basada en Win, Mac o Linux
- (Obligatorio) Conceptos básicos de Java
- (obligatorio)
- (Obligatorio) Conceptos básicos de SpringBoot
- (obligatorio) shell simple
- (Sugerencia) Cartero Dirección oficial del cartero
- (Recomendación) Conceptos básicos de SpringData
- (Sugerencia) Acceso científico a Internet
1.Instale el software
1.1 Tirar la imagen
docker pull elasticsearch:7.12.1
1.2 Iniciar el contenedor
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xms512m" -e "discovery.type=single-node" -p 9200:9200 elastics
earch:7.12.1
1.3 Acceso entre dominios
Configurar dominio cruzado
docker exec -it elasticsearch /bin/bash
vi config/elasticsearch.yml
El contenido que se está modificando es
cluster.name: "docker-cluster"
network.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
Salga y guarde según las indicaciones.
1.4 Reiniciar el contenedor
docker restart elasticsearch
1.5 Prueba de Acceso
Acceso al navegador
http://127.0.0.1:9200
2. software auxiliar
instalar la cabeza
2.1 Tirar la imagen
docker pull mobz/elasticsearch-head:5
2.2 Iniciar el contenedor
docker run --name elasticsearch-head -d -p 9100:9100 mobz/elasticsearch-head:5
2.3 Prueba de acceso
浏览器访问
http://127.0.0.1:9100
3. Una pequeña prueba de cuchillos.
Intente escribir y leer datos en
Elasticsearch.Abra Postman
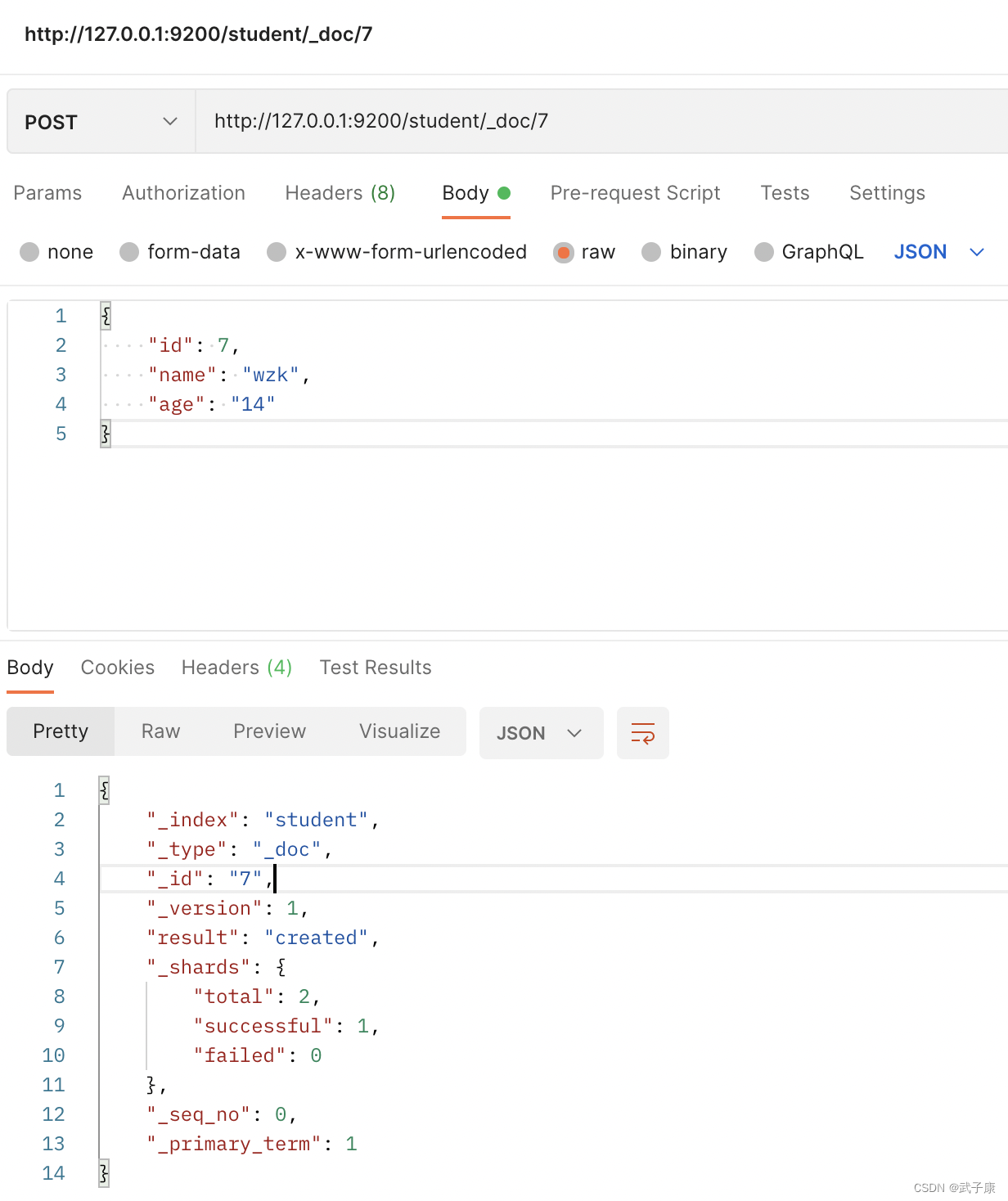
3.1 Escribir datos
Puede cambiar contenido diferente y escribir algunos elementos más para facilitar las condiciones de consulta posteriores.
http://127.0.0.1:9200/student/_doc/7
{
"id": 7,
"name": "wzk",
"age": "14"
}
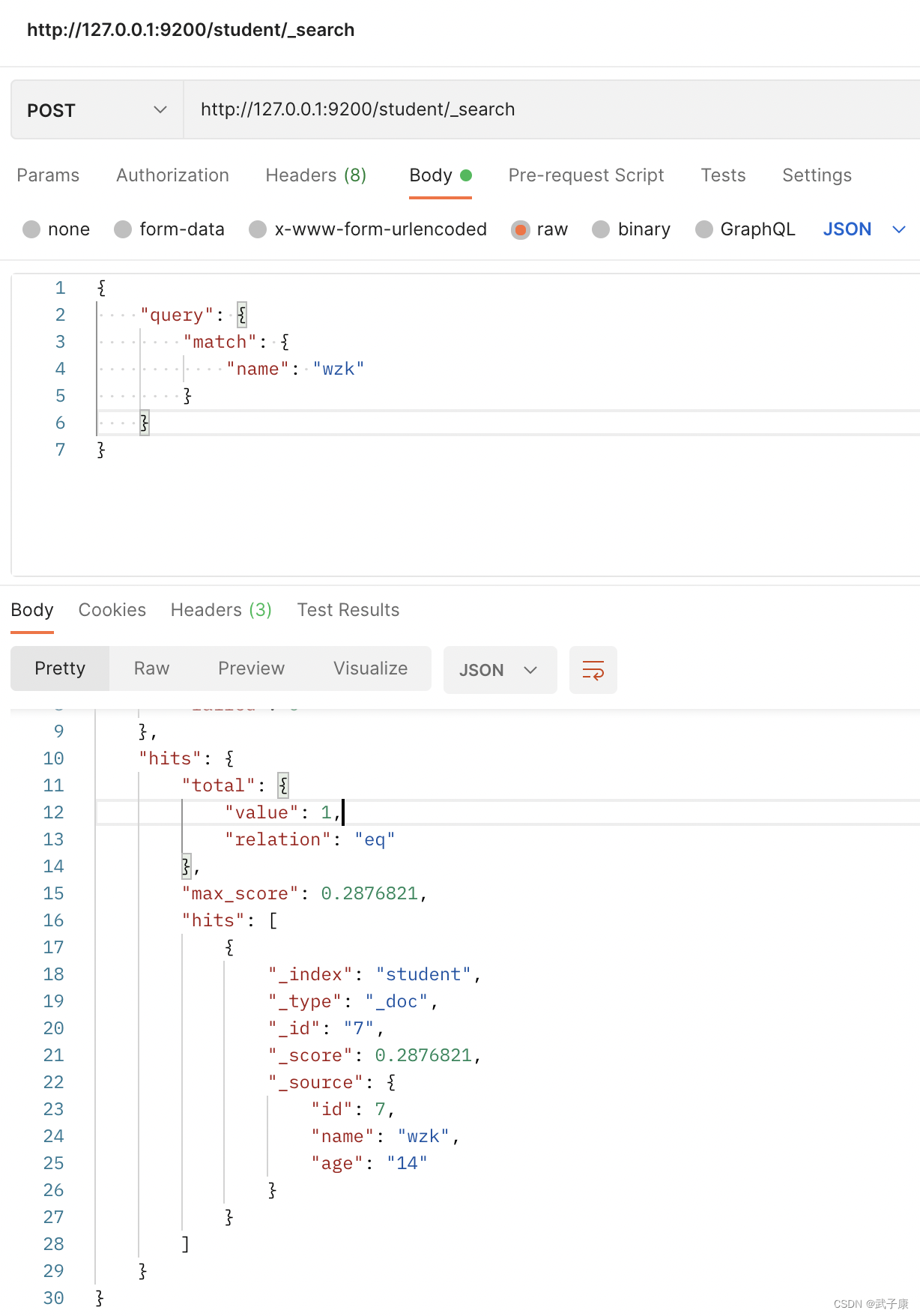
3.2 Lectura de datos
http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"name": "wzk"
}
}
}
4. Zhongxun Baidu
Este capítulo cubre principalmente consultas, diversos métodos de búsqueda, condiciones de búsqueda, clasificación, paginación, etc.
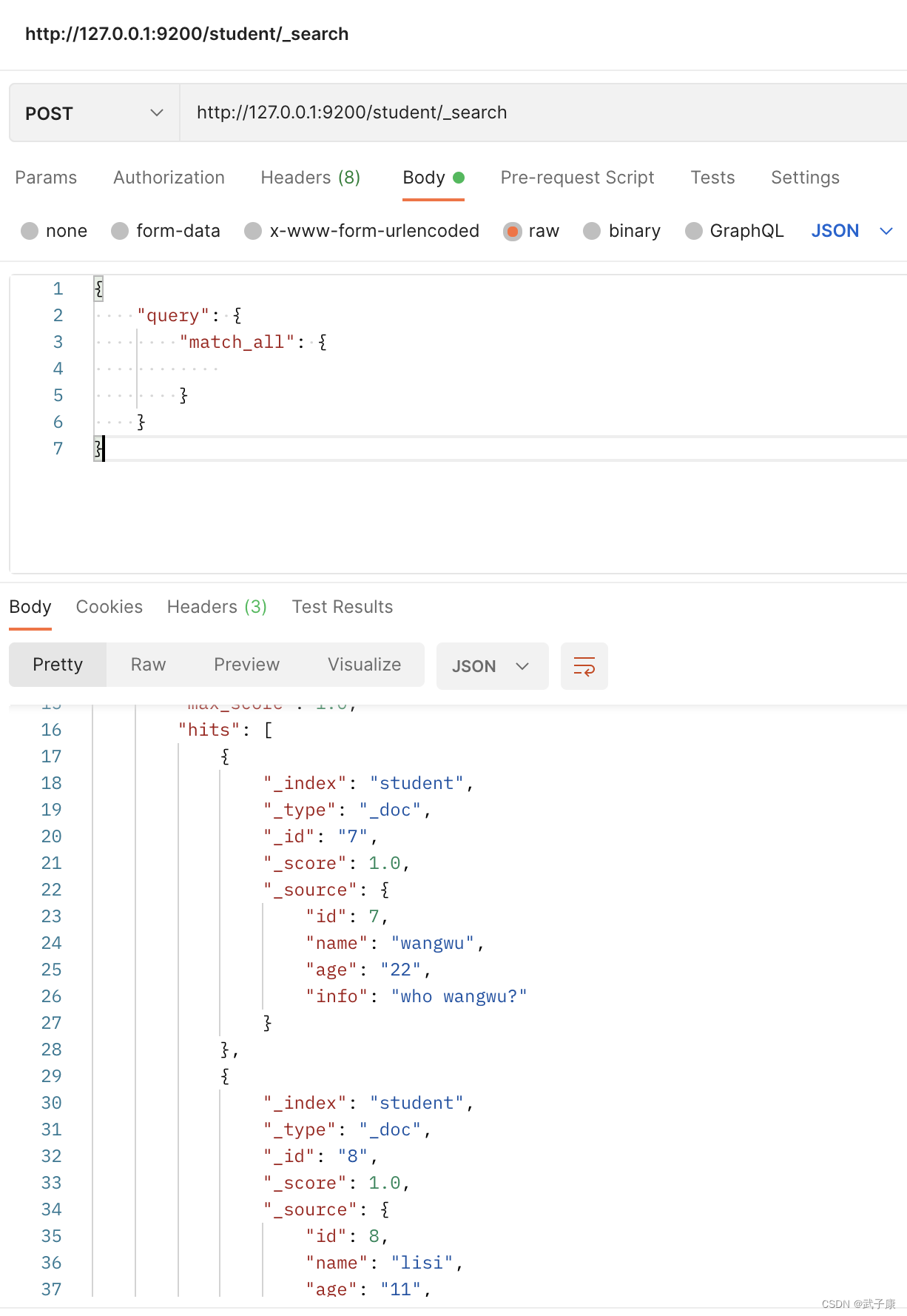
4.1 Consultar todo
http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {
}
}
}
4.2 Búsqueda de texto completo
Buscar después de la segmentación de palabras
http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"info": "oohohohoh"
}
}
}
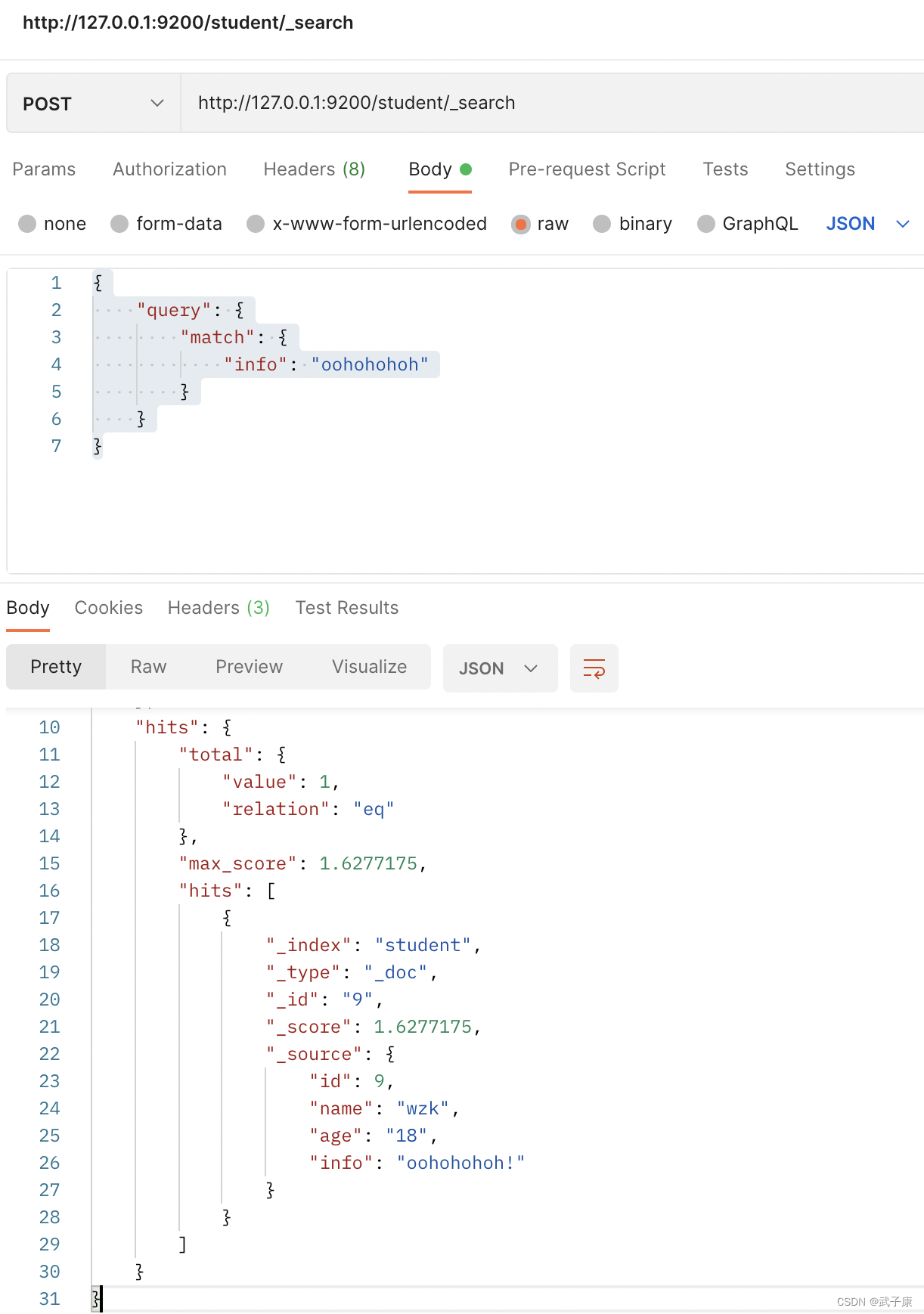
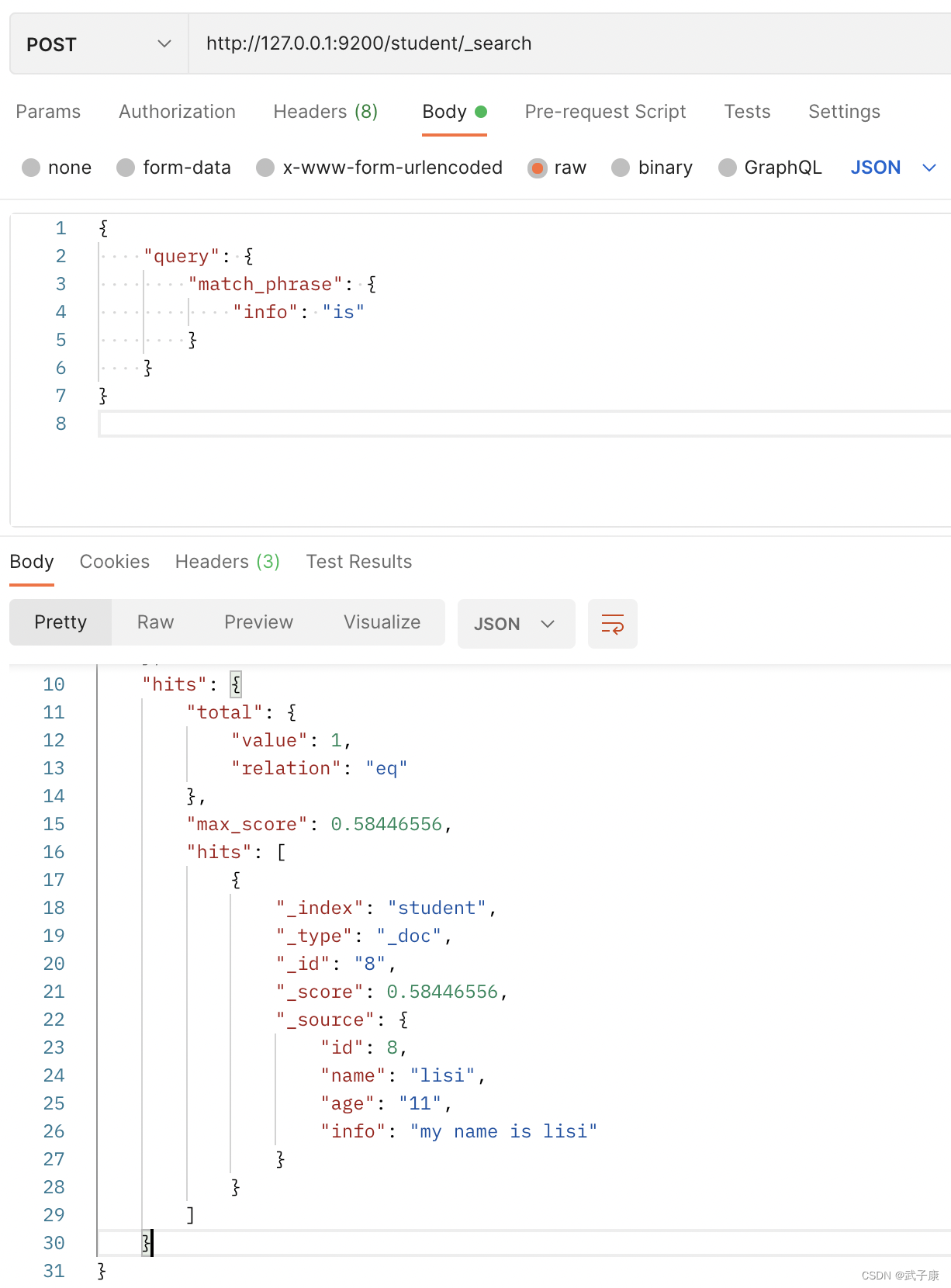
4.3 Búsqueda de frases
Las condiciones de búsqueda no realizan ninguna segmentación de palabras.
http://127.0.0.1:9200/student/_search
{
"query": {
"match_phrase": {
"info": "is"
}
}
}
4.4 Búsqueda de rango
Búsqueda de rango en campos de tipo numérico
- gt: mayor que mayor que
- gte: mayor o igual mayor o igual
- lt: menos que menos que
- lte: menor o igual menor o igual
http://127.0.0.1:9200/student/_search
{
"query": {
"range": {
"id": {
"gt": 6,
"lte": 9
}
}
}
}

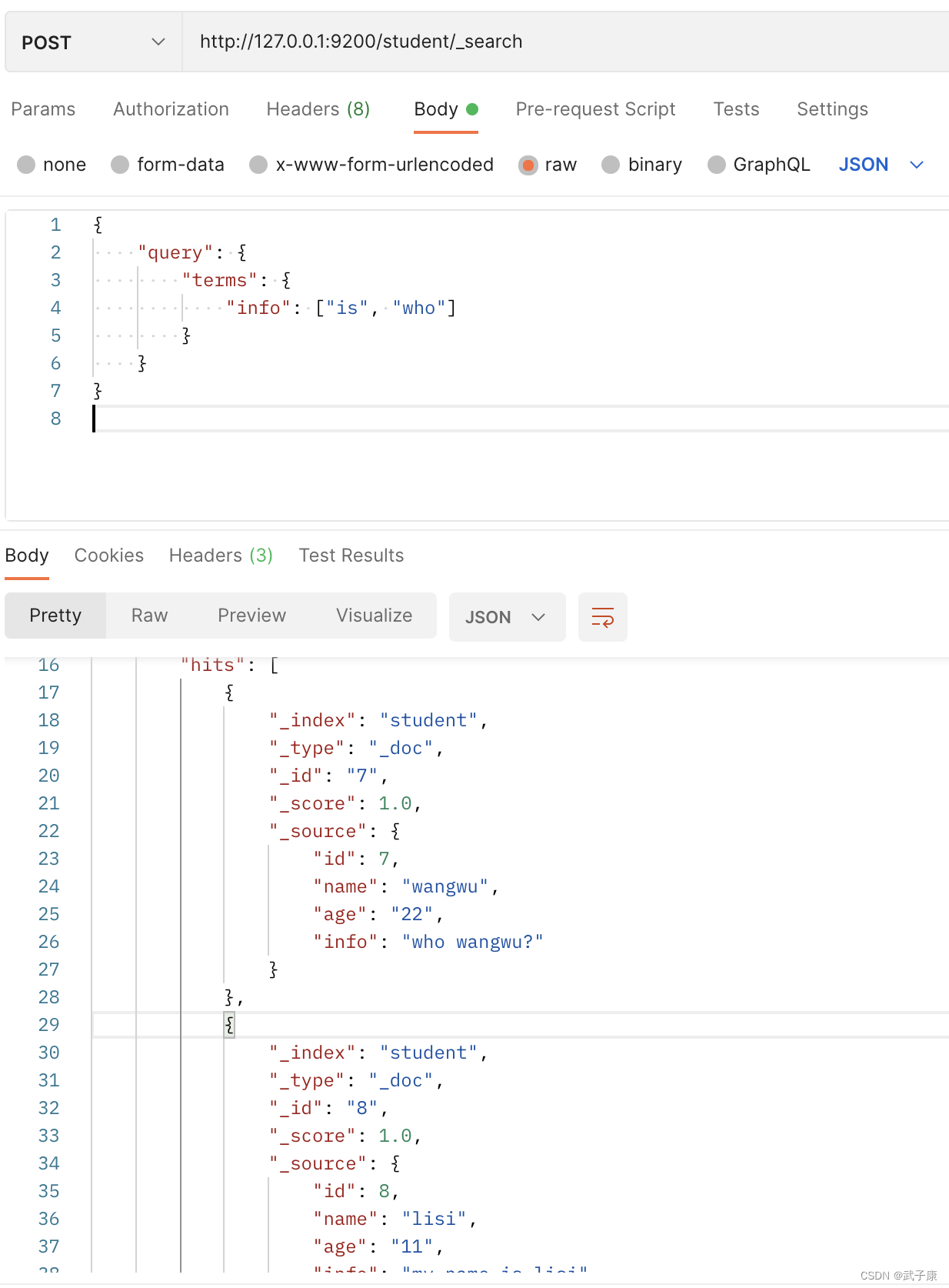
4.5 Búsqueda de frases
Las condiciones de búsqueda de palabras/frases no realizan ningún análisis de segmentación de palabras y coinciden exactamente en el índice invertido correspondiente al campo de búsqueda.
http://127.0.0.1:9200/student/_search
{
"query": {
"terms": {
"info": ["is", "who"]
}
}
}
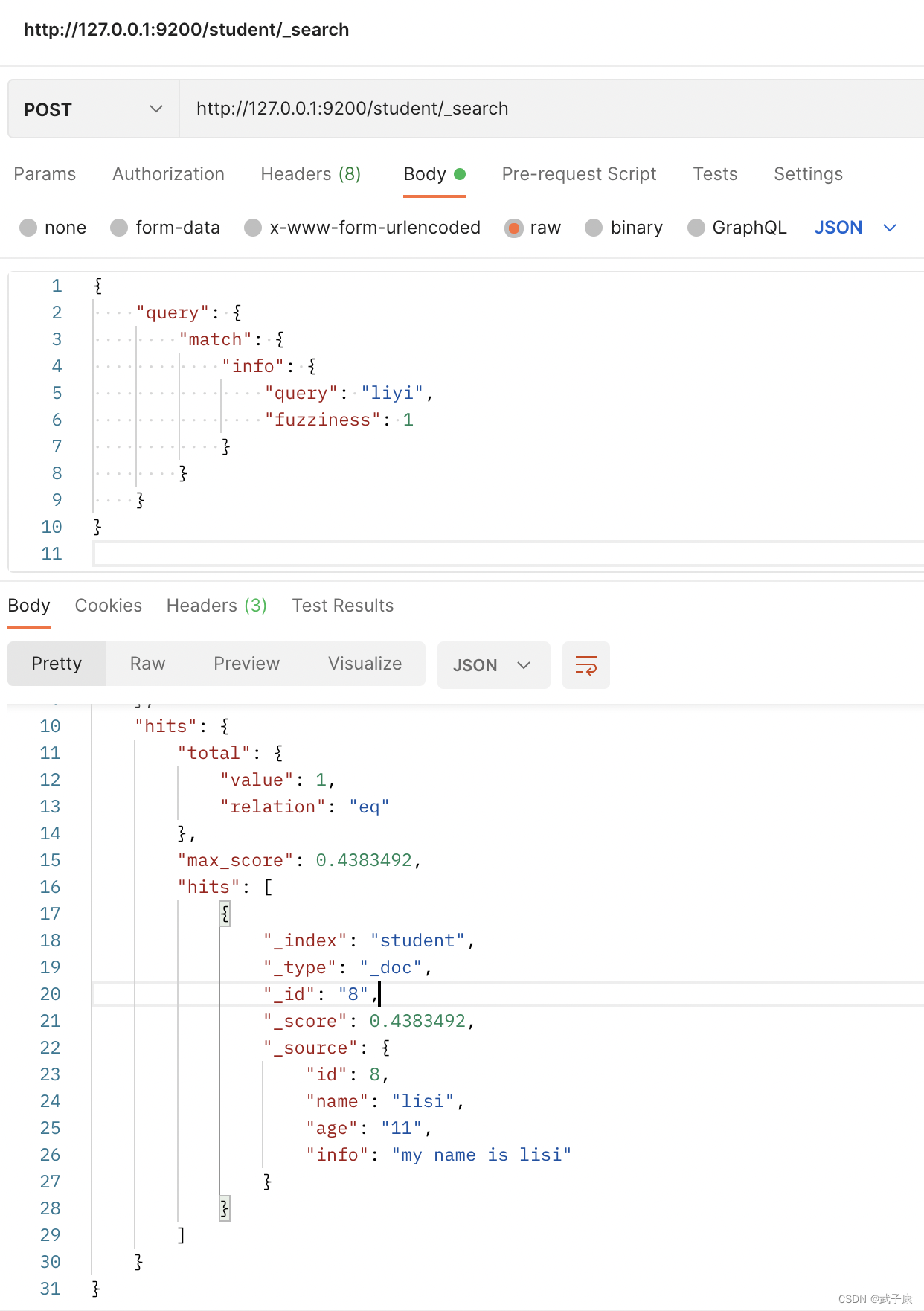
4.6 Búsqueda difusa
Pueden ocurrir errores durante la búsqueda. Elasticsearch corregirá automáticamente los errores de coincidencia aproximada.
- consulta: criterios de búsqueda
- borrosidad: el número máximo de caracteres de error no puede exceder 2
http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"info": {
"query": "liyi",
"fuzziness": 1
}
}
}
}
4.7 Búsqueda compuesta
Combine múltiples condiciones para buscar resultados coincidentes
- debe condiciones que deben cumplirse
- debe satisfacer cualquiera de las múltiples condiciones
- must_not condiciones que no deben cumplirse
http://127.0.0.1:9200/student/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"info": "my"
}
},
{
"match_phrase": {
"info": "name"
}
}
],
"should": [
{
"match_phrase": {
"info": "name"
}
}
],
"must_not": [
{
"match_phrase": {
"info": "wzk"
}
}
]
}
}
}
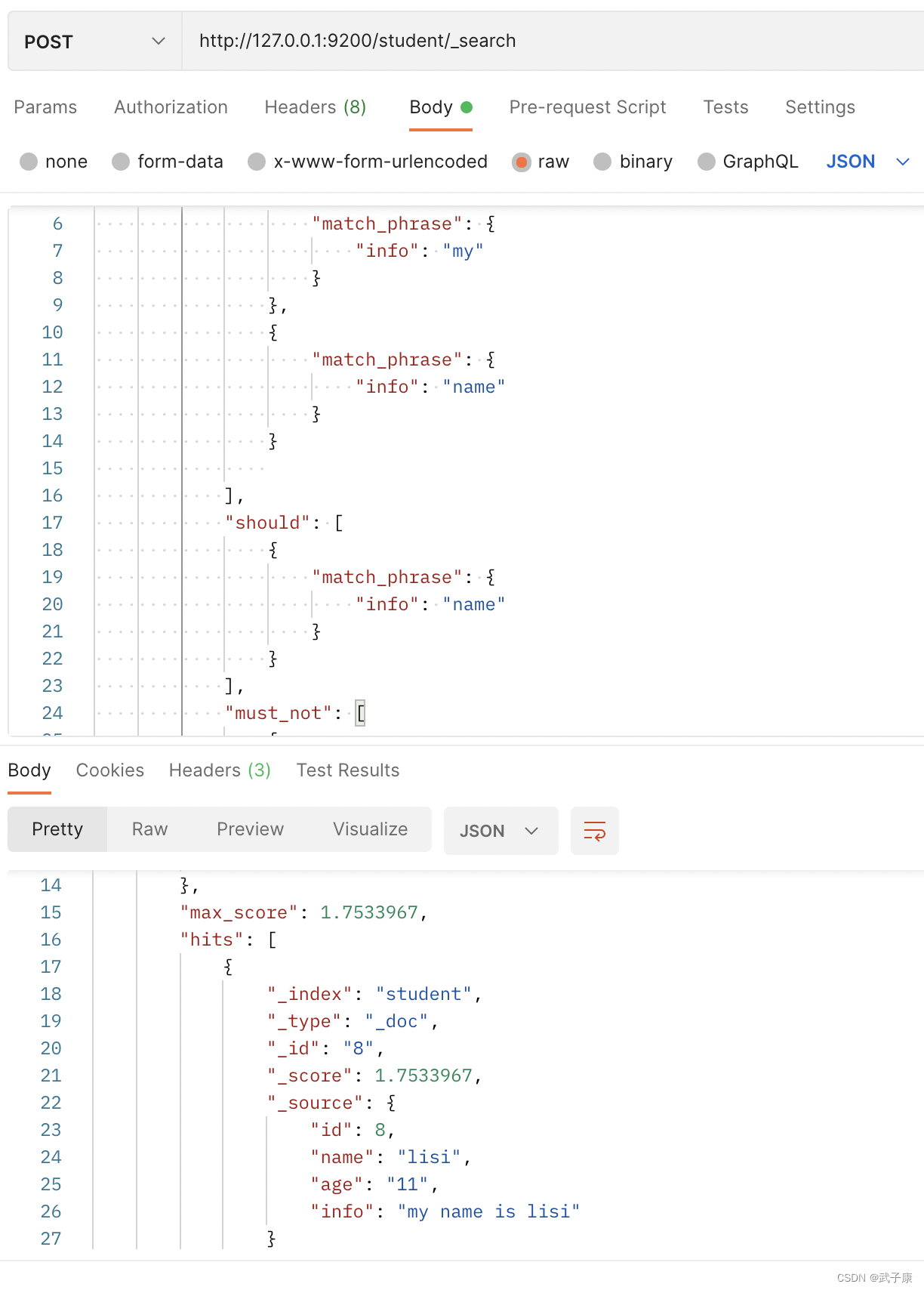
4.8 Clasificación de resultados
Ordenar los resultados de la consulta.
Dado que Elasticsearch realiza la segmentación de palabras en datos de campos de tipo de texto,
no es razonable ordenar el tipo de texto sin importar qué palabra se utilice. Por lo tanto, no se permite ordenar el tipo de texto de forma predeterminada.
Si desea utilizar resultados de cadena para ordenar,
puede utilizar el campo de tipo de palabra clave como base de clasificación porque el campo de palabra clave no realiza el procesamiento de segmentación de palabras.
http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"id": {
"order": "desc"
}
}
]
}
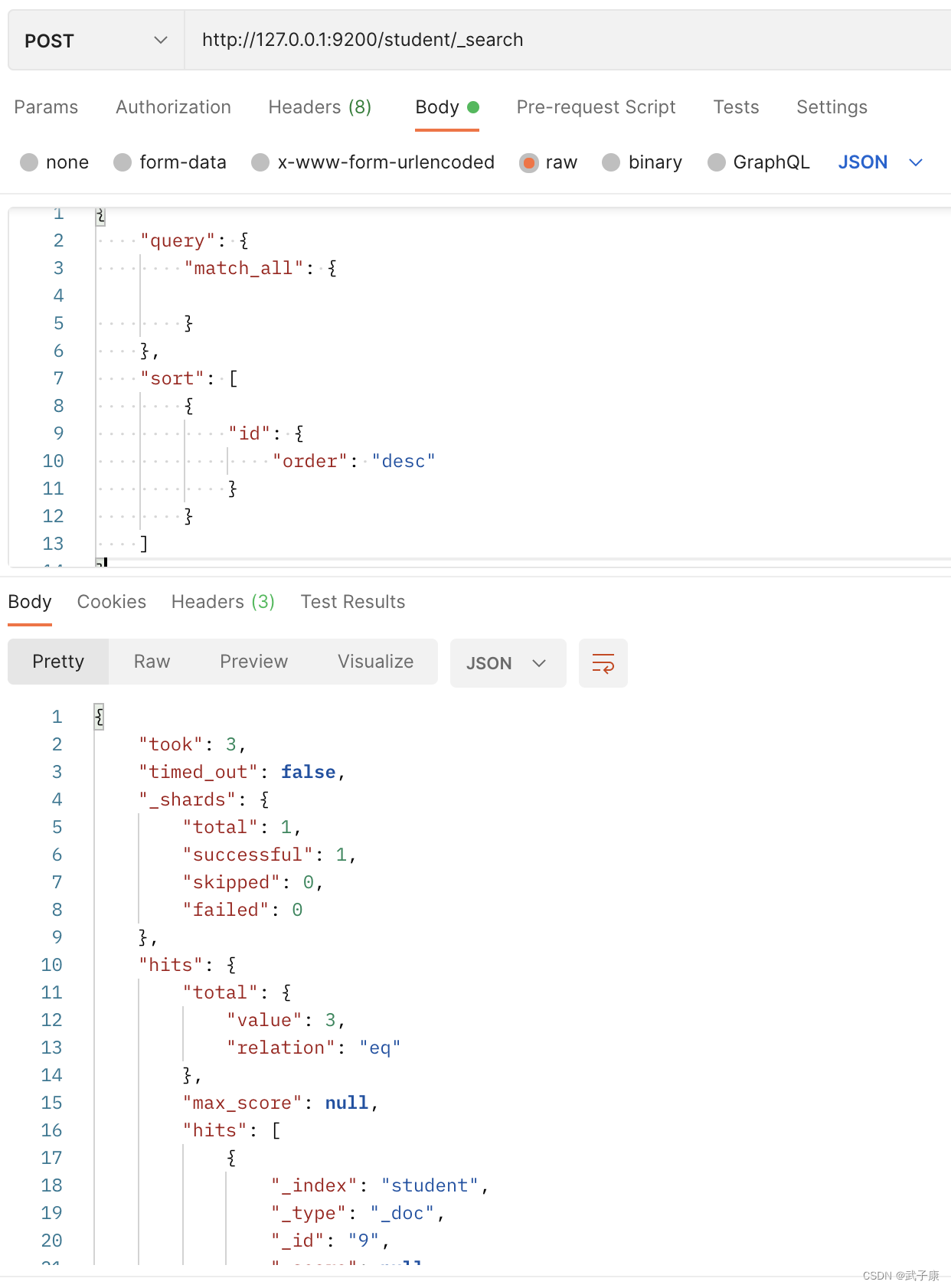
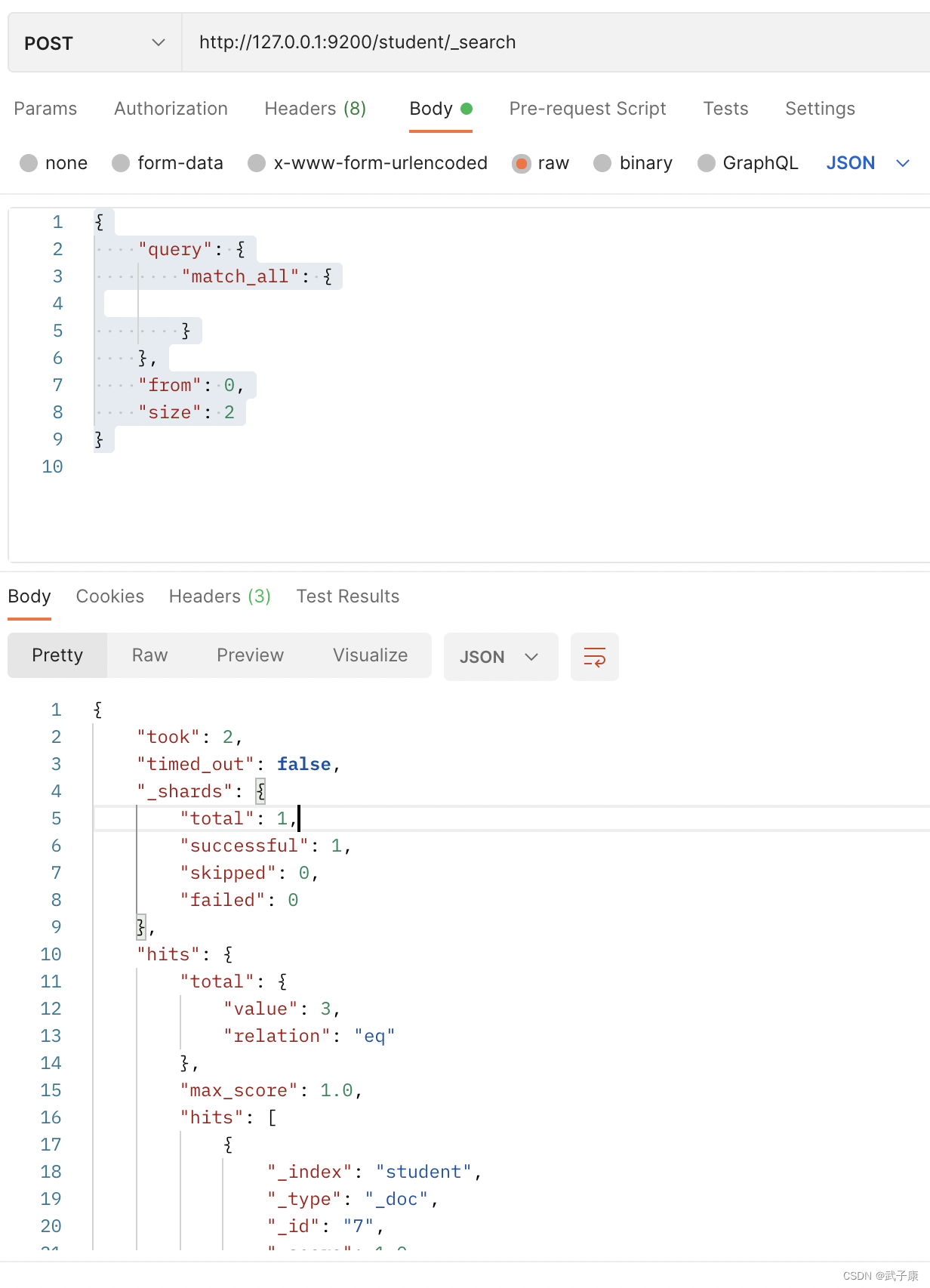
4.9 Consulta de paginación
En el uso real en línea, puede haber muchos resultados coincidentes,
por lo que los resultados deben paginarse para mejorar la eficiencia.
http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {
}
},
"from": 0,
"size": 2
}
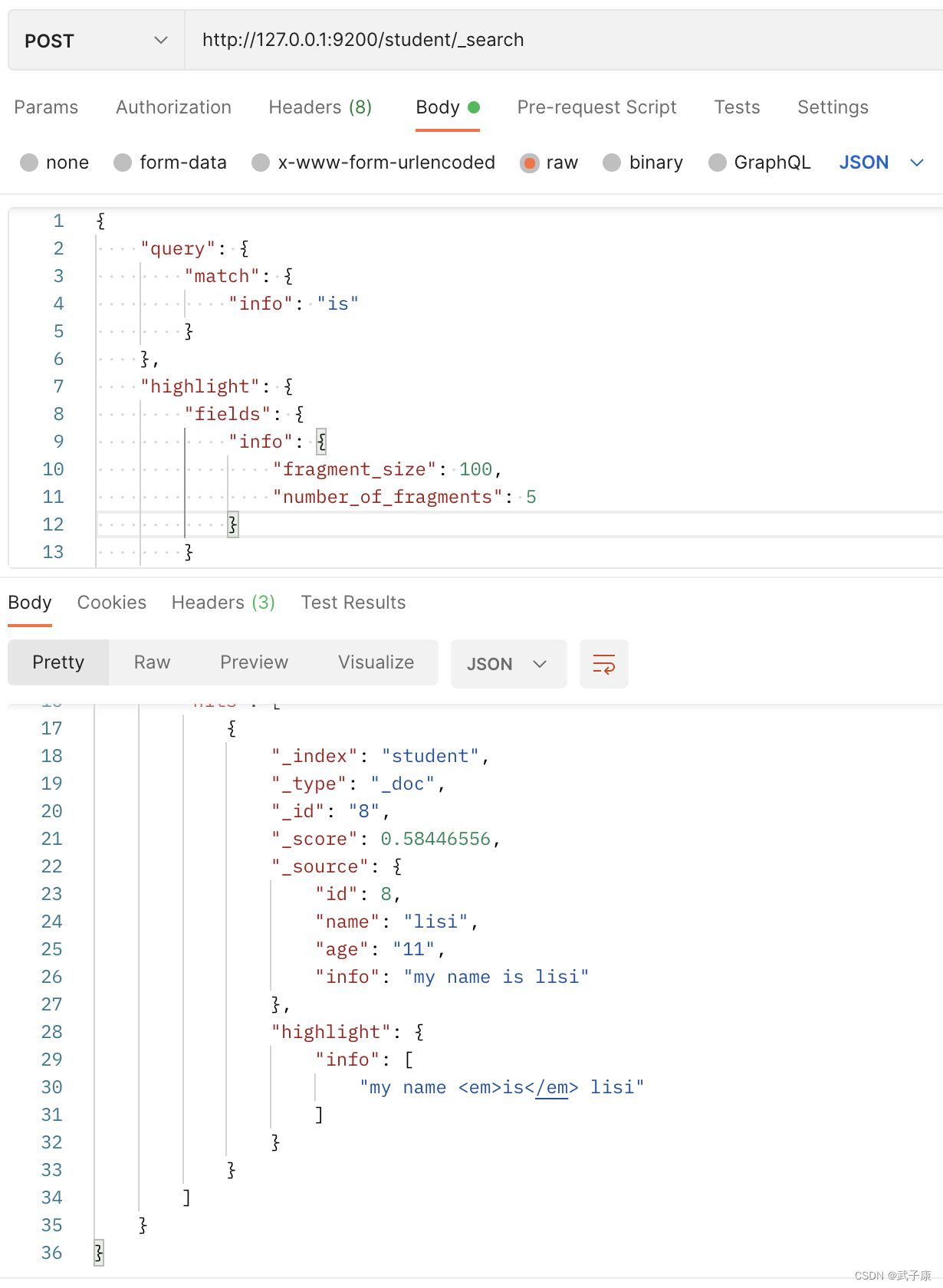
4.10 Consulta resaltada
http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"info": "is"
}
},
"highlight": {
"fields": {
"info": {
"fragment_size": 100,
"number_of_fragments": 5
}
}
}
}
5. El cinturón se vuelve más ancho.
La solución utilizada para construir un proyecto usando Elasticsearch en el proyecto SpringBoot
es que es relativamente fácil comenzar con SpringData (para mí, puede que no sea suficiente para el aprendizaje gratuito).
¡Se supone que ya tiene la base de SpringBoot!
Ahora eliminaré el desorden rápidamente y comenzaré un proyecto ( el padre es 2.2.2.RELEASE )
5.1 Construir el proyecto
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.2.RELEASE</version>
</parent>
<dependencies>
<!-- spring-boot-web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
<scope>provided</scope>
</dependency>
</dependencies>
5.2 Configuración básica
Cree un nuevo directorio de configuración en el proyecto
y cree una nueva clase de configuración (no olvide @Configuration )
@Configuration
public class ElasticSearchConfig extends AbstractElasticsearchConfiguration {
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration clientConfiguration = ClientConfiguration
.builder()
.connectedTo("127.0.0.1:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
5.3 Clase de entidad
- @Document(indexName = “estudiante”) El nombre del índice es estudiante, si no existe se creará automáticamente.
- @Id es el índice
- @Field(tipo = FieldType.Text, tienda = verdadero) campo
La estructura y los campos de los objetos que almacena en elasticsearch pueden corresponderse entre sí. Cree
una nueva carpeta de modelo
y cree un nuevo objeto de Estudiante.
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "student")
public class Student {
@Id
private Integer id;
@Field(type = FieldType.Text, store = true)
private String name;
@Field(type = FieldType.Text, store = true)
private String info;
@Field(type = FieldType.Text, store = true)
private String age;
@Field(type = FieldType.Text, store = true)
private String links;
}
5.4 Crear interfaz
ElasticsearchRepository es una clase básica que tiene muchos métodos listos para usar después de la herencia.
<Student, Integer> es el nombre del índice de Student. Integer es el campo @Id.
Cree una nueva carpeta dao.
Cree una nueva clase StudentRepository.
public interface StudentRepository extends ElasticsearchRepository<Student, Integer> {
}
5.5 Nuevos datos
Para evitar problemas, la lógica se coloca directamente en el Controlador y
StudentRepository se inyecta en
SpringData para ayudar a proporcionar muchos métodos listos para usar.
@Autowired
private StudentRepository studentRepository;
@GetMapping("/addStudent")
public String addStudent() {
String name = UUID.randomUUID().toString();
name = name.replace("-", " ");
Student student = Student
.builder()
.name(name)
.links("this is a link to " + name)
.build();
studentRepository.save(student);
return "ok";
}
5.6 Consultar datos
Inyectar StudentRepository en
@Autowired
private StudentRepository studentRepository;
@GetMapping("/getStudent")
public List<Student> getStudent() {
Iterable<Student> dataList = studentRepository.findAll();
List<Student> resultList = new ArrayList<>();
for (Student student : dataList) {
resultList.add(student);
}
return resultList;
}
5.7 Consultar un solo elemento
Inyectar StudentRepository en
@Autowired
private StudentRepository studentRepository;
@GetMapping("/getStudentById")
public Student getStudentById() {
Optional<Student> stuData = studentRepository.findById(11);
return stuData.orElseGet(Student::new);
}
5.8 Modificar datos
Inyectar StudentRepository en
@Autowired
private StudentRepository studentRepository;
@GetMapping("/updStudent")
public String updStudent() {
String name = UUID.randomUUID().toString();
name = name.replace("-", " ");
Student student = Student
.builder()
.id(1)
.name(name)
.links("this is a link to " + name)
.build();
studentRepository.save(student);
return "ok";
}
5.9 Eliminación de datos
Inyectar StudentRepository en
@Autowired
private StudentRepository studentRepository;
@GetMapping("/delStudent")
public String delStudent() {
studentRepository.deleteById(1);
return "ok";
}
6. Luces tenues
En el Capítulo 5, descubrimos que aunque SpringData nos proporciona muchos métodos (a través de herencia),
no es lo suficientemente gratuito y no se puede utilizar cuando las condiciones de consulta son complejas,
por lo que el funcionario también proporciona las soluciones correspondientes.
6.1 Métodos personalizados
Primero, adjunte un


ejemplo de correspondencia oficial y utilícelo de acuerdo con las reglas anteriores.
// 根据名字查询
List<Student> findByName(String name);
// 根据名字模糊查询
List<Student> findByNameLike(String name);
6.2 paginación condicional
Pageable pageable = PageRequest.of(0, 2); puede realizar consultas de paginación
@Autowired
private StudentRepository studentRepository;
@GetMapping("/getPage")
public List<Student> getPage() {
Pageable pageable = PageRequest.of(0, 2);
Page<Student> page = studentRepository.findAll(pageable);
List<Student> dataList = page.getContent();
long number = page.getTotalElements();
int total = page.getTotalPages();
out.println("number: " + number);
out.println("total: "+ total);
return dataList;
}
6.3 Paginación personalizada
La paginación paginable se usa en 6.2.
También podemos usar el método en 6.1 para paginación.
Agregar métodos a StudentRepository
// 注意 Pageable page
// 这样逻辑大约变成了(方便理解 用SQL表达一下):
// select * from student where name=#{name} limit #{page.page, page.size}
Page<Student> findByNameLike(String name, Pageable page);
@Autowired
private StudentRepository studentRepository;
@GetMapping("/findByNamePage")
public List<Student> findByNamePage() {
Pageable pageable = PageRequest.of(0, 1);
// 传参 将 条件、分页 一起传入
Page<Student> data = studentRepository.findByNameLike("2", pageable);
System.out.println(data.getTotalElements());
System.out.println(data.getTotalPages());
return data.getContent();
}
6.4 Clasificación de consultas
Ordenar durante la consulta
Ordenar sort = Sort.by(Sort.Direction.DESC, “id”);
@Autowired
private StudentRepository studentRepository;
@GetMapping("/findByNameOrder")
public List<Student> findByNameOrder() {
// 排序顺序、排序字段
Sort sort = Sort.by(Sort.Direction.DESC, "id");
Iterable<Student> dataList = studentRepository.findAll(sort);
List<Student> resultList = new ArrayList<>();
for (Student student : dataList) {
resultList.add(student);
}
return resultList;
}
6.5 Ordenar paginación
Se ha agregado Ordenar a Pageable para que pueda paginarse y ordenarse.
@Autowired
private StudentRepository studentRepository;
@GetMapping("/findByNamePageOrder")
public List<Student> findByNamePageOrder() {
Sort sort = Sort.by(Sort.Direction.ASC, "id");
// 传参 start、limit、sort规则
// 即可实现 分页 + 排序
Pageable pageable = PageRequest.of(0,2, sort);
Page<Student> page = studentRepository.findAll(pageable);
return page.getContent();
}