01 Descripción general de los rastreadores web
A continuación, permita que todos tengan una comprensión básica de los rastreadores web desde tres aspectos: el concepto, el uso, el valor y la estructura de los rastreadores web.
1. Rastreadores web y sus aplicaciones
Con el rápido desarrollo de Internet, la World Wide Web se ha convertido en un portador de grandes cantidades de información. Cómo extraer y utilizar eficazmente esta información se ha convertido en un gran desafío, y los rastreadores web surgieron a medida que los tiempos lo exigían. **Un rastreador web (también conocido como araña web o robot web) es un programa o script que rastrea automáticamente información de la World Wide Web de acuerdo con ciertas reglas. **A continuación se muestra el papel de los rastreadores web en Internet a través de la Figura 3-1:

▲Figura 3-1 Rastreador web
Según la estructura del sistema y la tecnología de implementación, los rastreadores web se pueden dividir aproximadamente en los siguientes tipos: ** rastreadores web generales, rastreadores web enfocados, rastreadores web incrementales y rastreadores web profundos. **El sistema de rastreo web real generalmente se implementa mediante una combinación de varias tecnologías de rastreo.
Search Engine , como los motores de búsqueda generales tradicionales Baidu, Yahoo y Google, es un rastreador web grande y complejo y pertenece a la categoría de rastreadores web generales. Sin embargo, los motores de búsqueda universales tienen ciertas limitaciones:
-
Los usuarios de diferentes campos y orígenes a menudo tienen diferentes propósitos y necesidades de búsqueda. Los resultados arrojados por los motores de búsqueda generales incluyen una gran cantidad de páginas web que no interesan a los usuarios.
-
El objetivo de un motor de búsqueda general es maximizar la cobertura de la red, y la contradicción entre los recursos limitados del servidor del motor de búsqueda y los recursos ilimitados de datos de la red se profundizará aún más.
-
Con la riqueza de los formularios de datos en la World Wide Web y el continuo desarrollo de la tecnología de redes, diferentes datos como imágenes, bases de datos, audio y video multimedia aparecen en grandes cantidades. Los motores de búsqueda generales a menudo son incapaces de descubrir y obtener estos datos con Contenido informativo denso y con cierta estructura.
-
La mayoría de los motores de búsqueda generales proporcionan recuperación basada en palabras clave y es difícil admitir consultas basadas en información semántica.
Para resolver los problemas anteriores, surgieron rastreadores enfocados que capturan específicamente recursos web relevantes según lo requieren los tiempos.
**El rastreador enfocado es un programa que descarga páginas web automáticamente y accede selectivamente a páginas web y enlaces relacionados en la World Wide Web según los objetivos de rastreo establecidos para obtener la información requerida. **A diferencia de los rastreadores generales, los rastreadores enfocados no persiguen una gran cobertura, sino que establecen el objetivo de rastrear páginas web relacionadas con el contenido de un tema específico y preparar recursos de datos para consultas de usuarios orientadas a temas.
Después de hablar de rastreadores enfocados, hablemos de rastreadores web incrementales. Los rastreadores web incrementales se refieren a rastreadores que actualizan gradualmente las páginas web descargadas y solo rastrean las páginas web recién generadas o modificadas, lo que puede garantizar hasta cierto punto que las páginas rastreadas sean lo más nuevas posible.
En comparación con los rastreadores web que rastrean y actualizan páginas periódicamente, los rastreadores incrementales solo rastrearán páginas recién generadas o actualizadas cuando sea necesario y no volverán a descargar páginas que no hayan cambiado, lo que puede reducir efectivamente la cantidad de datos descargados y garantizar una actualización oportuna rastreada. Las páginas web reducen el consumo de tiempo y espacio, pero aumentan la complejidad y la dificultad de implementación del algoritmo de rastreo.
Por ejemplo, si desea obtener información de reclutamiento de Ganji.com, no es necesario rastrear los datos rastreados anteriormente. Solo necesita obtener datos de reclutamiento actualizados. En este caso, debe utilizar un rastreador incremental.
Finalmente, hablemos de los rastreadores de la web profunda. Las páginas web se pueden dividir en páginas web superficiales y páginas web profundas según sus métodos de existencia. Las páginas web de superficie se refieren a páginas que pueden ser indexadas por motores de búsqueda tradicionales y se componen principalmente de páginas web estáticas a las que se puede acceder mediante hipervínculos. La web profunda son aquellas páginas web donde la mayor parte del contenido no se puede obtener a través de enlaces estáticos, está oculto detrás de formularios de búsqueda y solo pueden obtenerlo los usuarios que envían algunas palabras clave.
Por ejemplo, páginas a las que los usuarios sólo pueden acceder después de iniciar sesión o registrarse. Puedes imaginar un escenario como este: rastrear datos de Tieba o foros requiere que los usuarios inicien sesión y tengan permiso para obtener datos completos.
2. Estructura del rastreador web
A continuación se utiliza una estructura general de rastreador web para ilustrar el flujo de trabajo básico de un rastreador web, como se muestra en la Figura 3-4.

▲Figura 3-4 Estructura del rastreador web
El flujo de trabajo básico de un rastreador web es el siguiente:
-
Comience seleccionando un subconjunto de URL de torrents cuidadosamente seleccionadas.
-
Coloque estas URL en la cola de URL para rastrearlas.
-
Lea la URL de la cola que se va a rastrear desde la cola de URL que se va a rastrear, analice el DNS, obtenga la IP del host, descargue la página web correspondiente a la URL y guárdela en la biblioteca de páginas web descargadas. Además, estas URL se colocan en la cola de URL rastreadas.
-
Analice las URL en la cola de URL rastreadas, analice otras URL de los datos de la página web descargada, compárelas con las URL rastreadas para eliminar duplicados y, finalmente, coloque las URL deduplicadas en la cola de URL que se rastrearán para ingresar al siguiente ciclo.
02 Implementación Python de solicitud HTTP
A través de la estructura del rastreador web anterior, podemos ver que leer URL y descargar páginas web son funciones esenciales y clave de cada rastreador, lo que requiere lidiar con solicitudes HTTP. A continuación, explicaremos las tres formas de implementar solicitudes HTTP en Python: urllib2/urllib, httplib/urllib y Requests.
1. Implementación de urllib2/urllib
urllib2 y urllib son dos módulos integrados en Python. Para implementar la función HTTP, el método de implementación es utilizar urllib2 como módulo principal y urllib como complemento.
1.1 Primero implemente un modelo completo de solicitud y respuesta
urllib2 proporciona una función básica urlopen para obtener datos realizando una solicitud a una URL específica. La forma más simple es:
import urllib2
response=urllib2.urlopen('http://www.zhihu.com')
html=response.read()
print html
De hecho, la respuesta a la solicitud anterior a http://www.zhihu.com se puede dividir en dos pasos, uno es la solicitud y el otro es la respuesta, el formulario es el siguiente:
import urllib2
# 请求
request=urllib2.Request('http://www.zhihu.com')
# 响应
response = urllib2.urlopen(request)
html=response.read()
print html
Los dos formularios anteriores son solicitudes GET. A continuación, demostraremos la solicitud POST. De hecho, son similares, excepto que se agregan los datos de la solicitud. En este caso, se usa urllib. Los ejemplos son los siguientes:
import urllib
import urllib2
url = 'http://www.xxxxxx.com/login'
postdata = {
'username' : 'qiye',
'password' : 'qiye_pass'}
# info 需要被编码为urllib2能理解的格式,这里用到的是urllib
data = urllib.urlencode(postdata)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
html = response.read()
Pero a veces sucede esto: incluso si los datos de la solicitud POST son correctos, el servidor le niega el acceso. ¿Por qué sucede esto? El problema radica en la información del encabezado de la solicitud. El servidor comprobará el encabezado de la solicitud para determinar si se accede a él desde el navegador. Este también es un método común para los anti-rastreadores.
1.2 Procesamiento de encabezados de solicitud
Vuelva a escribir el ejemplo anterior, agregue información del encabezado de la solicitud y configure el campo User-Agent y la información del campo Referer en el encabezado de la solicitud.
import urllib
import urllib2
url = 'http://www.xxxxxx.com/login'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
referer='http://www.xxxxxx.com/'
postdata = {
'username' : 'qiye',
'password' : 'qiye_pass'}
# 将user_agent,referer写入头信息
headers={
'User-Agent':user_agent,'Referer':referer}
data = urllib.urlencode(postdata)
req = urllib2.Request(url, data,headers)
response = urllib2.urlopen(req)
html = response.read()
También puede escribirlo así, usar add_header para agregar información del encabezado de la solicitud y modificarlo de la siguiente manera:
import urllib
import urllib2
url = 'http://www.xxxxxx.com/login'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
referer='http://www.xxxxxx.com/'
postdata = {
'username' : 'qiye',
'password' : 'qiye_pass'}
data = urllib.urlencode(postdata)
req = urllib2.Request(url)
# 将user_agent,referer写入头信息
req.add_header('User-Agent',user_agent)
req.add_header('Referer',referer)
req.add_data(data)
response = urllib2.urlopen(req)
html = response.read()
Preste especial atención a algunos encabezados, el servidor verificará estos encabezados, por ejemplo:
-
Agente de usuario : algunos servidores o proxy utilizarán este valor para determinar si la solicitud la realiza el navegador.
-
Tipo de contenido : cuando se utiliza la interfaz REST, el servidor verificará este valor para determinar cómo se debe analizar el contenido del cuerpo HTTP. Cuando se utilizan servicios RESTful o SOAP proporcionados por el servidor, una configuración de tipo de contenido incorrecta hará que el servidor niegue el servicio. Los valores comunes son: aplicación/xml (usado al llamar a XML RPC, como RESTful/SOAP), aplicación/json (usado al llamar a JSON RPC), aplicación/x-www-form-urlencoded (el navegador envía un formulario web cuando se usa).
-
Referer : El servidor a veces comprueba el anti-hotlinking.
1.3 Procesamiento de cookies
urllib2 también maneja automáticamente las cookies, utilizando la función CookieJar para administrar las cookies. Si necesita obtener el valor de un elemento de cookie, puede hacer esto:
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
response = opener.open('http://www.zhihu.com')
for item in cookie:
print item.name+':'+item.value
Pero a veces nos encontramos con esta situación. No queremos que urllib2 lo maneje automáticamente. Queremos agregar el contenido de la cookie nosotros mismos. Podemos hacerlo configurando el dominio de la cookie en el encabezado de la solicitud:
import urllib2
opener = urllib2.build_opener()
opener.addheaders.append( ( 'Cookie', 'email=' + "[email protected]" ) )
req = urllib2.Request( "http://www.zhihu.com/" )
response = opener.open(req)
print response.headers
retdata = response.read()
1.4 Configuración del tiempo de espera
En versiones anteriores a Python 2.6, la API de urllib2 no expone la configuración de Tiempo de espera. Para establecer el valor de Tiempo de espera, solo puede cambiar el valor de Tiempo de espera global del Socket. Los ejemplos son los siguientes:
import urllib2
import socket
socket.setdefaulttimeout(10) # 10 秒钟后超时
urllib2.socket.setdefaulttimeout(10) # 另一种方式
En Python 2.6 y versiones más recientes, la función urlopen proporciona la configuración de tiempo de espera. El ejemplo es el siguiente:
import urllib2
request=urllib2.Request('http://www.zhihu.com')
response = urllib2.urlopen(request,timeout=2)
html=response.read()
print html
1.5 Obtener código de respuesta HTTP
Para 200 OK, puede obtener el código de retorno HTTP utilizando el método getcode() del objeto de respuesta devuelto por urlopen. Pero para otros códigos de retorno, urlopen generará una excepción. En este momento es necesario verificar el atributo de código del objeto de excepción, el ejemplo es el siguiente:
import urllib2
try:
response = urllib2.urlopen('http://www.google.com')
print response
except urllib2.HTTPError as e:
if hasattr(e, 'code'):
print 'Error code:',e.code
1.6 Redirección
De forma predeterminada, urllib2 redirigirá automáticamente los códigos de retorno HTTP 3XX. Para detectar si se ha producido una acción de redireccionamiento, simplemente verifique si la URL de la Respuesta y la URL de la Solicitud son consistentes, el ejemplo es el siguiente:
import urllib2
response = urllib2.urlopen('http://www.zhihu.cn')
isRedirected = response.geturl() == 'http://www.zhihu.cn'
Si no desea redirigir automáticamente, puede personalizar la clase HTTPRedirectHandler.El ejemplo es el siguiente:
import urllib2
class RedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(self, req, fp, code, msg, headers):
pass
def http_error_302(self, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(self, req, fp, code,
msg, headers)
result.status = code
result.newurl = result.geturl()
return result
opener = urllib2.build_opener(RedirectHandler)
opener.open('http://www.zhihu.cn')
1.7 Configuración de proxy
En el desarrollo de rastreadores, los agentes son indispensables. De forma predeterminada, urllib2 utilizará la variable de entorno http_proxy para configurar el proxy HTTP. Sin embargo, generalmente no usamos este método, sino que usamos ProxyHandler para configurar dinámicamente el proxy en el programa. El código de muestra es el siguiente:
import urllib2
proxy = urllib2.ProxyHandler({
'http': '127.0.0.1:8087'})
opener = urllib2.build_opener([proxy,])
urllib2.install_opener(opener)
response = urllib2.urlopen('http://www.zhihu.com/')
print response.read()
Un detalle a tener en cuenta aquí es que el uso de urllib2.install_opener() establecerá el abridor global de urllib2, y todos los accesos HTTP posteriores utilizarán este proxy. Esto será muy conveniente de usar, pero no puede proporcionar un control más detallado. Por ejemplo, si desea utilizar dos configuraciones de Proxy diferentes en el programa, este escenario es muy común en los rastreadores. Un mejor enfoque es no usar install_opener para cambiar la configuración global, sino llamar directamente al método open del abridor en lugar del método global urlopen, la modificación es la siguiente:
import urllib2
proxy = urllib2.ProxyHandler({
'http': '127.0.0.1:8087'})
opener = urllib2.build_opener(proxy,)
response = opener.open("http://www.zhihu.com/")
print response.read()
2. Implementación de httplib/urllib
El módulo httplib es un módulo básico de bajo nivel. Puede ver cada paso para establecer una solicitud HTTP, pero implementa relativamente pocas funciones y rara vez se usa en circunstancias normales. Básicamente, no se utiliza en el desarrollo del rastreador de Python, por lo que solo estoy aquí para popularizar el conocimiento. A continuación se presentan objetos y funciones de uso común:
-
Crear objeto HTTPConnection:
clase httplib.HTTPConnection(host[, puerto[, estricto[, tiempo de espera[, dirección_fuente]]]])。
-
Enviar petición:
HTTPConnection.request(método, url[, cuerpo[, encabezados]])。
-
Obtener una respuesta:
HTTPConnection.getresponse()。
-
Leer información de respuesta:
HTTPResponse.read([amt])。
-
Obtenga la información del encabezado especificado:
HTTPResponse.getheader(nombre[, predeterminado])。
-
Obtenga una lista de tuplas de encabezado de respuesta (encabezado, valor):
HTTPResponse.getheaders()。
-
Obtenga el descriptor del archivo de socket subyacente:
HTTPResponse.fileno()。
-
Obtener contenido del encabezado:
HTTPResponse.msg。
-
Obtenga la versión http del encabezado:
HTTPResponse.versión。
-
Obtener código de estado de devolución:
HTTPResponse.status。
-
Obtenga instrucciones de devolución:
HTTPResponse.razón。
A continuación, demostraremos el envío de solicitudes GET y POST. El primero es un ejemplo de solicitud GET, como se muestra a continuación:
import httplib
conn =None
try:
conn = httplib.HTTPConnection("www.zhihu.com")
conn.request("GET", "/")
response = conn.getresponse()
print response.status, response.reason
print '-' * 40
headers = response.getheaders()
for h in headers:
print h
print '-' * 40
print response.msg
except Exception,e:
print e
finally:
if conn:
conn.close()
Un ejemplo de una solicitud POST es el siguiente:
import httplib, urllib
conn = None
try:
params = urllib.urlencode({
'name': 'qiye', 'age': 22})
headers = {
"Content-type": "application/x-www-form-urlencoded"
, "Accept": "text/plain"}
conn = httplib.HTTPConnection("www.zhihu.com", 80, timeout=3)
conn.request("POST", "/login", params, headers)
response = conn.getresponse()
print response.getheaders() # 获取头信息
print response.status
print response.read()
except Exception, e:
print e
finally:
if conn:
conn.close()
3. Solicitudes más fáciles de usar
Recomiendo encarecidamente la forma en que Requests implementa las solicitudes HTTP en Python y también es el método más utilizado en el desarrollo del rastreador de Python. Requests es muy sencillo de implementar solicitudes HTTP y la operación es más fácil de usar.
La biblioteca de solicitudes es un módulo de terceros y requiere instalación adicional. Requests es una biblioteca de código abierto, el código fuente se encuentra en:
GitHub: https://github.com/kennethreitz/requests
Espero que todos apoyen al autor.
Para utilizar la biblioteca de solicitudes, primero debe instalarla. Generalmente existen dos métodos de instalación:
-
Utilice pip para instalar. El comando de instalación es: pip install request, pero puede que no sea la última versión.
-
Vaya directamente a GitHub para descargar el código fuente de Requests, el enlace de descarga es:
https://github.com/kennethreitz/requests/releases
Descomprima el paquete comprimido del código fuente, luego ingrese a la carpeta descomprimida y ejecute el archivo setup.py.
¿Cómo verificar si el módulo Solicitudes se instaló correctamente? Ingrese las solicitudes de importación en el shell de Python. Si no se informa ningún error, la instalación se realizó correctamente. Como se muestra en la Figura 3-5.
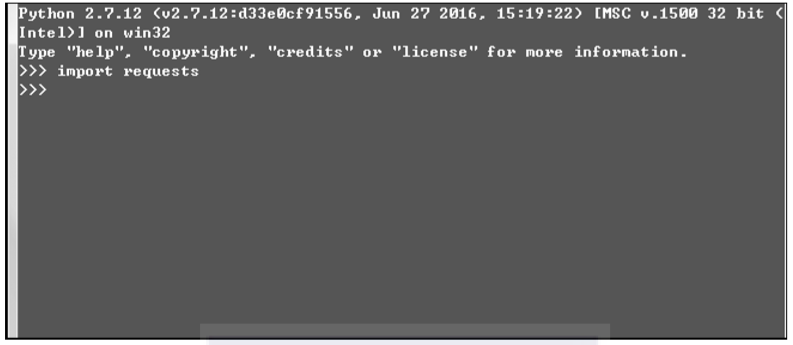
▲Figura 3-5 Instalación de Verificar solicitudes
3.1 Primero, implementar un modelo completo de solicitud y respuesta
Tomando la solicitud GET como ejemplo, la forma más simple es la siguiente:
import requests
r = requests.get('http://www.baidu.com')
print r.content
Como puede ver, la cantidad de código es menor que la implementación de urllib2. A continuación, demostremos la solicitud POST, que también es muy corta y más al estilo Python. Los ejemplos son los siguientes:
import requests
postdata={
'key':'value'}
r = requests.post('http://www.xxxxxx.com/login',data=postdata)
print r.content
También se pueden implementar otros métodos de solicitud en HTTP utilizando Solicitudes. Los ejemplos son los siguientes:
r = requests.put('http://www.xxxxxx.com/put', data = {
'key':'value'})
r = requests.delete('http://www.xxxxxx.com/delete')
r = requests.head('http://www.xxxxxx.com/get')
r = requests.options('http://www.xxxxxx.com/get')
A continuación, expliquemos un método un poco más complicado, seguramente habrás visto URL como esta:
http://zzk.cnblogs.com/s/blogpost?Keywords=blog:qiyeboy&pageindex=1
Significa que la URL va seguida de "?" y hay parámetros después de "?". Entonces, ¿cómo enviar dicha solicitud GET? Algunas personas definitivamente dirán que puede ingresar la URL completa directamente, pero Requests también proporciona otros métodos, los ejemplos son los siguientes:
import requests
payload = {
'Keywords': 'blog:qiyeboy','pageindex':1}
r = requests.get('http://zzk.cnblogs.com/s/blogpost', params=payload)
print r.url
Al imprimir los resultados, vemos que la URL final pasa a ser:
http://zzk.cnblogs.com/s/blogpost?Keywords=blog:qiyeboy&pageindex=1
3.2 Respuesta y codificación
Comencemos con el código, el ejemplo es el siguiente:
import requests
r = requests.get('http://www.baidu.com')
print 'content-->'+r.content
print 'text-->'+r.text
print 'encoding-->'+r.encoding
r.encoding='utf-8'
print 'new text-->'+r.text
Entre ellos, r.content devuelve el formato de bytes, r.text devuelve el formato de texto y r.encoding devuelve el formato de codificación de la página web adivinado según el encabezado HTTP.
En el resultado de salida: el contenido después de "texto–>" está confuso en la consola, y el contenido después de "codificación–>" es ISO-8859-1 (el formato de codificación real es UTF-8), debido a las solicitudes de conjetura An El error de codificación resultó en texto confuso en el texto analizado. Requests proporciona una solución. Puede configurar el formato de codificación usted mismo. Después de configurar r.encoding='utf-8' en UTF-8, el contenido de "nuevo texto–>" no será confuso.
Sin embargo, este método manual es un poco torpe, aquí hay un método más simple: chardet, que es un excelente módulo de detección de codificación de cadenas/archivos. El método de instalación es el siguiente:
pip install chardet
Una vez completada la instalación, utilice chardet.detect() para devolver el diccionario, donde la confianza es la precisión de la detección y la codificación es la forma de codificación. Los ejemplos son los siguientes:
import requests
r = requests.get('http://www.baidu.com')
print chardet.detect(r.content)
r.encoding = chardet.detect(r.content)['encoding']
print r.text
Asigne directamente la codificación detectada por chardet a r.encoding para implementar la decodificación, y la salida de r.text no será confusa.
Además del método anterior para obtener todas las respuestas directamente, también existe un modo de transmisión, el ejemplo es el siguiente:
import requests
r = requests.get('http://www.baidu.com',stream=True)
print r.raw.read(10)
Establezca el indicador stream=True para leer la respuesta como un flujo de bytes, y la función r.raw.read especifica el número de bytes a leer.
3.3 Procesamiento de encabezados de solicitud
El procesamiento de encabezados por Solicitudes es muy similar a urllib2: simplemente agregue el parámetro de encabezados en la función de obtención de Solicitudes. Los ejemplos son los siguientes:
import requests
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers={
'User-Agent':user_agent}
r = requests.get('http://www.baidu.com',headers=headers)
print r.content
3.4 Procesamiento de código de respuesta y encabezados de respuesta
Para obtener el código de respuesta, use el campo status_code en Solicitudes y para obtener el encabezado de respuesta, use el campo de encabezados en Solicitudes. Los ejemplos son los siguientes:
import requests
r = requests.get('http://www.baidu.com')
if r.status_code == requests.codes.ok:
print r.status_code# 响应码
print r.headers# 响应头
print r.headers.get('content-type')# 推荐使用这种获取方式,获取其中的某个字段
print r.headers['content-type']# 不推荐使用这种获取方式
else:
r.raise_for_status()
En el programa anterior, r.headers contiene toda la información del encabezado de respuesta. Puede obtener uno de los campos a través de la función get, o puede obtener el valor del diccionario a través de la referencia del diccionario, pero no se recomienda, porque si no existe tal campo en el campo, segundo El primer método generará una excepción y el primer método devolverá Ninguno.
r.raise_for_status() se utiliza para generar activamente una excepción. Cuando el código de respuesta es 4XX o 5XX, la función rise_for_status() arrojará una excepción. Cuando el código de respuesta es 200, la función rise_for_status() devuelve Ninguno.
3.5 Procesamiento de cookies
Si la respuesta contiene el valor de Cookie, puedes obtener el valor del campo Cookie de la siguiente manera, el ejemplo es el siguiente:
import requests
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers={
'User-Agent':user_agent}
r = requests.get('http://www.baidu.com',headers=headers)
# 遍历出所有的cookie字段的值
for cookie in r.cookies.keys():
print cookie+':'+r.cookies.get(cookie)
Si desea personalizar el valor de la cookie a enviar, puede utilizar el siguiente método, el ejemplo es el siguiente:
import requests
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers={
'User-Agent':user_agent}
cookies = dict(name='qiye',age='10')
r = requests.get('http://www.baidu.com',headers=headers,cookies=cookies)
print r.text
También existe una forma más avanzada que puede manejar automáticamente las cookies. A veces no necesitamos preocuparnos por el valor de la cookie. Solo queremos que el programa proporcione automáticamente el valor de la cookie cada vez que visitamos, como un navegador. Requests proporciona un concepto de sesión, que es particularmente conveniente cuando se accede continuamente a páginas web y se manejan saltos de inicio de sesión, sin prestar atención a detalles específicos. Ejemplos de uso son los siguientes:
import Requests
oginUrl = 'http://www.xxxxxxx.com/login'
s = requests.Session()
#首先访问登录界面,作为游客,服务器会先分配一个cookie
r = s.get(loginUrl,allow_redirects=True)
datas={'name':'qiye','passwd':'qiye'}
#向登录链接发送post请求,验证成功,游客权限转为会员权限
r = s.post(loginUrl, data=datas,allow_redirects= True)
print r.text
El programa anterior es en realidad un problema encontrado en el desarrollo formal de Python. Si no accede a la página de inicio de sesión en el primer paso, pero envía directamente una solicitud de publicación al enlace de inicio de sesión, el sistema lo tratará como un usuario ilegal porque accede al interfaz de inicio de sesión. Se asignará una cookie al enviar una solicitud de publicación. Esta cookie debe introducirse al enviar una solicitud de publicación. Este método de utilizar la función de sesión para procesar cookies será muy común en el futuro.
3.6 Redireccionamiento e información histórica
Para manejar las redirecciones, sólo necesita configurar el campo enable_redirects, por ejemplo:
r=requests.get('http://www.baidu.com',allow_redirects=True)
Establezca enable_redirects en True para permitir la redirección; en False para deshabilitar la redirección. Si se permite la redirección, puede ver información histórica a través del campo r.history, es decir, toda la información de salto de solicitud antes del acceso exitoso. Los ejemplos son los siguientes:
import requests
r = requests.get('http://github.com')
print r.url
print r.status_code
print r.history
El resultado de la impresión es el siguiente:
https://github.com/
200
(<Response [301]>,)
El efecto que muestra el código de muestra anterior es que al acceder a la URL de GitHub, todas las solicitudes HTTP se redirigirán a HTTPS.
3.7 Configuración del tiempo de espera
La opción de tiempo de espera se configura a través del parámetro tiempo de espera, el ejemplo es el siguiente:
requests.get('http://github.com', timeout=2)
3.8 Configuración de proxy
Al utilizar un proxy, puede configurar una única solicitud para cualquier método de solicitud configurando el parámetro proxies:
import requests
proxies = {
"http": "http://0.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
El proxy también se puede configurar a través de las variables de entorno HTTP_PROXY y HTTPS_PROXY?, pero no se usa comúnmente en el desarrollo de rastreadores. Su proxy debe utilizar autenticación básica HTTP, que se puede realizar utilizando la sintaxis http://usuario:contraseña@host/:
proxies = {
"http": "http://user:[email protected]:3128/",
}
03 Resumen
Este artículo explica principalmente la estructura y aplicación de los rastreadores web, así como varios métodos para implementar solicitudes HTTP en Python. Espero que en este artículo se concentre en absorber y digerir el flujo de trabajo del rastreador web y la forma en que Requests implementa las solicitudes HTTP.
por fin:
[Para aquellos que quieran aprender sobre rastreadores, he recopilado muchos materiales de aprendizaje de Python y los he subido al sitio oficial de CSDN. Los amigos que lo necesiten pueden escanear el código QR a continuación para obtenerlos]
1. Esquema del estudio

2. Herramientas de desarrollo

3. Materiales básicos de Python

4. Datos prácticos