Código y recursos en papel
enlace de código
Enlace de papel
Modificación de código
Cuando descargamos el código de GitHub, descubrimos que no se podía ejecutar por completo, principalmente porque la versión de pytorch utilizada por el código de GitHub estaba por detrás de la versión 0.4 y la versión instalada en mi computadora era relativamente alta, por lo que habría Habrá algunas advertencias y, en GitHub, las operaciones se realizan directamente en la línea de comandos, lo que no favorece la depuración posterior, por lo que este artículo se modificará para abordar estos problemas.
Modificación de la línea de comando
modificación del tren
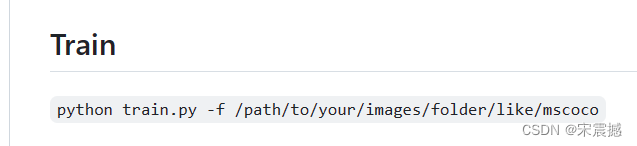
Modifíquelo en tren para:
`parser = argparse.ArgumentParser()
parser.add_argument(
'--batch-size', '-N', type=int, default=32, help='batch size')
parser.add_argument(
'--train', '-f', default=r'C:\Users\scp\Desktop\pytorch-image-comp-rnn000\val2014', type=str, help='folder of training images')
parser.add_argument(
'--max-epochs', '-e', type=int, default=20, help='max epochs')
parser.add_argument('--lr', type=float, default=0.0005, help='learning rate') parser.add_argument('--cuda', '-g', action='store_true', help='enables cuda')
parser.add_argument(
'--iterations', type=int, default=16, help='unroll iterations')
parser.add_argument('--checkpoint', type=int, help='unroll iterations')
args = parser.parse_args()`
modificación del codificador

Modifíquelo en el codificador para:
`parser = argparse.ArgumentParser()
parser.add_argument(
'--model', '-m', type=str, default=r'D:\PycharmProjects\pytorch-image-comp-rnn-master\checkpoint\encoder_epoch_00000016.pth',help='path to model')
parser.add_argument(
'--input', '-i', type=str,default=r'D:\PycharmProjects\pytorch-image-comp-rnn-master\c797b84fc2bdb71e5b6641af1f2b0d4b.jpg', help='input image')
parser.add_argument(
'--output', '-o',type=str,default='ex', help='output codes')
parser.add_argument('--cuda', '-g', action='store_true', help='enables cuda')
parser.add_argument(
'--iterations', type=int, default=16, help='unroll iterations')
args = parser.parse_args()
modificación del decodificador

Modifíquelo en el decodificador para:
`arser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, default=r'D:\PycharmProjects\pytorch-image-comp-rnn-master\checkpoint\decoder_epoch_00000016.pth',help='path to model')
parser.add_argument('--input', type=str,default=r'D:\PycharmProjects\pytorch-image-comp-rnn-master\ex.npz', help='input codes')
parser.add_argument('--output', default=r'D:\PycharmProjects\pytorch-image-comp-rnn-master\test\images', type=str, help='output folder')
parser.add_argument('--cuda', action='store_true', help='enables cuda')
parser.add_argument(
'--iterations', type=int, default=16, help='unroll iterations')
args = parser.parse_args()
Versión compatible con algunas modificaciones de código.
Advertencia de usuario: llamada detectada de lr_scheduler.step()antes optimizer.step(). En PyTorch 1.1.0 y posteriores, debes llamarlos en el orden opuesto: optimizer.step()antes lr_scheduler.step(). De no hacerlo, PyTorch se saltará el primer valor del programa de tasa de aprendizaje. Vea más detalles en https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
advertencias.warn("Llamada detectada lr_scheduler.step()antes optimizer.step()".
Esta advertencia ocurre en el tren porque, como dice el error, "lr_scheduler.step()" se llama antes que "optimizer.step()", como se muestra en el siguiente código de error:
for epoch in range(last_epoch + 1, args.max_epochs + 1):
scheduler.step()
for batch, data in enumerate(train_loader):
batch_t0 = time.time()
## init lstm state
encoder_h_1 = (Variable(torch.zeros(data.size(0), 256, 8, 8).cuda()),
Variable(torch.zeros(data.size(0), 256, 8, 8).cuda()))
encoder_h_2 = (Variable(torch.zeros(data.size(0), 512, 4, 4).cuda()),
Variable(torch.zeros(data.size(0), 512, 4, 4).cuda()))
encoder_h_3 = (Variable(torch.zeros(data.size(0), 512, 2, 2).cuda()),
Variable(torch.zeros(data.size(0), 512, 2, 2).cuda()))
decoder_h_1 = (Variable(torch.zeros(data.size(0), 512, 2, 2).cuda()),
Variable(torch.zeros(data.size(0), 512, 2, 2).cuda()))
decoder_h_2 = (Variable(torch.zeros(data.size(0), 512, 4, 4).cuda()),
Variable(torch.zeros(data.size(0), 512, 4, 4).cuda()))
decoder_h_3 = (Variable(torch.zeros(data.size(0), 256, 8, 8).cuda()),
Variable(torch.zeros(data.size(0), 256, 8, 8).cuda()))
decoder_h_4 = (Variable(torch.zeros(data.size(0), 128, 16, 16).cuda()),
Variable(torch.zeros(data.size(0), 128, 16, 16).cuda()))
patches = Variable(data.cuda())
solver.zero_grad()
losses = []
res = patches - 0.5
bp_t0 = time.time()
for _ in range(args.iterations):
encoded, encoder_h_1, encoder_h_2, encoder_h_3 = encoder(
res, encoder_h_1, encoder_h_2, encoder_h_3)
codes = binarizer(encoded)
output, decoder_h_1, decoder_h_2, decoder_h_3, decoder_h_4 = decoder(
codes, decoder_h_1, decoder_h_2, decoder_h_3, decoder_h_4)
res = res - output
losses.append(res.abs().mean())
bp_t1 = time.time()
loss = sum(losses) / args.iterations
loss.backward()
solver.step()
batch_t1 = time.time()
print(
'[TRAIN] Epoch[{}]({}/{}); Loss: {:.6f}; Backpropagation: {:.4f} sec; Batch: {:.4f} sec'.
format(epoch, batch + 1,
len(train_loader), loss.data, bp_t1 - bp_t0, batch_t1 -
batch_t0))
print(('{:.4f} ' * args.iterations +
'\n').format(* [l.data for l in losses]))
index = (epoch - 1) * len(train_loader) + batch
## save checkpoint every 500 training steps
if index % 500 == 0:
save(0, False)
save(epoch)
cambie a:
for epoch in range(last_epoch + 1, args.max_epochs + 1):
for batch, data in enumerate(train_loader):
batch_t0 = time.time()
## init lstm state
encoder_h_1 = (Variable(torch.zeros(data.size(0), 256, 8, 8).cuda()),
Variable(torch.zeros(data.size(0), 256, 8, 8).cuda()))
encoder_h_2 = (Variable(torch.zeros(data.size(0), 512, 4, 4).cuda()),
Variable(torch.zeros(data.size(0), 512, 4, 4).cuda()))
encoder_h_3 = (Variable(torch.zeros(data.size(0), 512, 2, 2).cuda()),
Variable(torch.zeros(data.size(0), 512, 2, 2).cuda()))
decoder_h_1 = (Variable(torch.zeros(data.size(0), 512, 2, 2).cuda()),
Variable(torch.zeros(data.size(0), 512, 2, 2).cuda()))
decoder_h_2 = (Variable(torch.zeros(data.size(0), 512, 4, 4).cuda()),
Variable(torch.zeros(data.size(0), 512, 4, 4).cuda()))
decoder_h_3 = (Variable(torch.zeros(data.size(0), 256, 8, 8).cuda()),
Variable(torch.zeros(data.size(0), 256, 8, 8).cuda()))
decoder_h_4 = (Variable(torch.zeros(data.size(0), 128, 16, 16).cuda()),
Variable(torch.zeros(data.size(0), 128, 16, 16).cuda()))
patches = Variable(data.cuda())
solver.zero_grad()
losses = []
res = patches - 0.5
bp_t0 = time.time()
for _ in range(args.iterations):
encoded, encoder_h_1, encoder_h_2, encoder_h_3 = encoder(
res, encoder_h_1, encoder_h_2, encoder_h_3)
codes = binarizer(encoded)
output, decoder_h_1, decoder_h_2, decoder_h_3, decoder_h_4 = decoder(
codes, decoder_h_1, decoder_h_2, decoder_h_3, decoder_h_4)
res = res - output
losses.append(res.abs().mean())
bp_t1 = time.time()
loss = sum(losses) / args.iterations
loss.backward()
solver.step()
batch_t1 = time.time()
print(
'[TRAIN] Epoch[{}]({}/{}); Loss: {:.6f}; Backpropagation: {:.4f} sec; Batch: {:.4f} sec'.
format(epoch, batch + 1,
len(train_loader), loss.data, bp_t1 - bp_t0, batch_t1 -
batch_t0))
print(('{:.4f} ' * args.iterations +
'\n').format(* [l.data for l in losses]))
index = (epoch - 1) * len(train_loader) + batch
## save checkpoint every 500 training steps
if index % 500 == 0:
save(0, False)
scheduler.step()
save(epoch)
Por lo tanto, lr_scheduler.step() debe colocarse después de que se complete el entrenamiento de cada época.
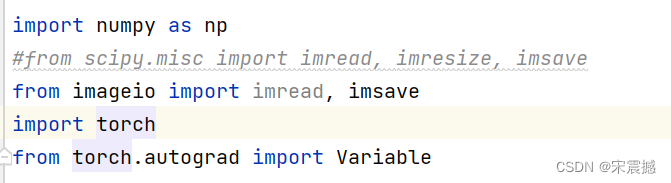
Como se mencionó anteriormente, debido a razones de versión, desde scipy.misc import imread, imresize, imsave
deben reemplazarse con from imageio import imread, imsave y otras partes también se modifican.

Esta advertencia aparecerá en la parte anterior del código:
UserWarning: volatile fue eliminado y ahora no tiene ningún efecto. Úselo con torch.no_grad(): en lugar.self.priors = Variable(self.priorbox.forward(), volatile=True )
Esto se debe a que el error indica que lo volátil ya no es útil. La razón es que con la iteración de versiones, ya no es necesario. Para usar con torch.no_grad(): Entonces la modificación

es la siguiente: lo mismo es
válido para otras partes. La referencia es la siguiente: descripción del enlace
Errores en otras partes:
advertencias.warn("nn.function.tanh está en desuso. Usar torch.tanh en su lugar.") Esto también es antes de la modificación debido a motivos de versión
:
ingate = F.sigmoid(ingate)
forgetgate = F.sigmoid(forgetgate)
cellgate = F.tanh(cellgate)
outgate = F.sigmoid(outgate)
Después de la modificación:
ingate = torch.sigmoid(ingate)
forgetgate = torch.sigmoid(forgetgate)
cellgate = torch.tanh(cellgate)
outgate = torch.sigmoid(outgate)
Lo mismo ocurre con otras partes.
Interpretación del artículo
Método de compresión de imágenes basado en red neuronal recurrente.
RNN apareció en la década de 1980. RNN no se usó ampliamente al principio debido a dificultades de implementación. Más tarde, con el avance de la estructura de RNN y la mejora del rendimiento de la GPU, RNN se hizo popular gradualmente. Actualmente, RNN ha logrado muchos logros en el campo de reconocimiento de voz, traducción automática, etc. Resultados. En comparación con CNN, RNN tiene las mismas características de intercambio de parámetros que CNN. La diferencia es que el intercambio de parámetros de CNN es espacial, mientras que RNN es temporal, es decir, basado en secuencia, lo que hace que RNN tenga la capacidad de comprender la información de secuencia anterior. Además de la "memoria", el método de entrenamiento consiste en calcular iterativamente hacia adelante mediante el descenso de gradiente. Estos dos métodos pueden, en primer lugar, mejorar el grado de compresión de datos y, en segundo lugar, controlar la velocidad de bits de la imagen mediante métodos iterativos, los cuales pueden mejorar el rendimiento de compresión de la imagen.
Por lo tanto, la compresión de imágenes usando RNN ha logrado resultados relativamente buenos tanto en la compresión de imágenes de resolución completa como en el control de la relación de compresión a través de la velocidad del código, pero vale la pena señalar que cuando se usa RNN, la mayoría de ellos necesitan introducir LSTM [1] o GRU[2] ] para resolver el problema de dependencia a largo plazo, por lo que el entrenamiento del modelo será más complicado.
Principios de RNN y LSTM
El método de compresión de imágenes utilizado en este artículo.
Toderici et al.[3] utilizaron LSTM convolucional por primera vez para implementar la compresión de imágenes de aprendizaje de extremo a extremo con velocidad de bits variable. Se puede decir que este método es un método representativo del uso de RNN para la compresión de imágenes. Verifica cualquier Imagen de entrada. Bajo la condición de una calidad de imagen dada, podemos obtener un efecto de calidad de imagen reconstruida mejor que la tasa de compresión óptima actual, pero este efecto se limita a imágenes de tamaño 32 × 32, lo que ilustra las deficiencias de este método en la captura de dependencias de imágenes. ., para poder solucionar este problema. Toderici y otros [4] diseñan un codificador residual basado en bloques y un codificador de entropía que no solo son capaces de capturar dependencias a largo plazo entre parches en imágenes y combinan dos métodos posibles para mejorar la tasa de compresión para una calidad determinada, y logra compresión de imágenes de resolución completa. Este método utiliza el método de entrenamiento de descenso de gradiente RNN para proponer un método de compresión de imágenes con pérdida basado en resolución completa.
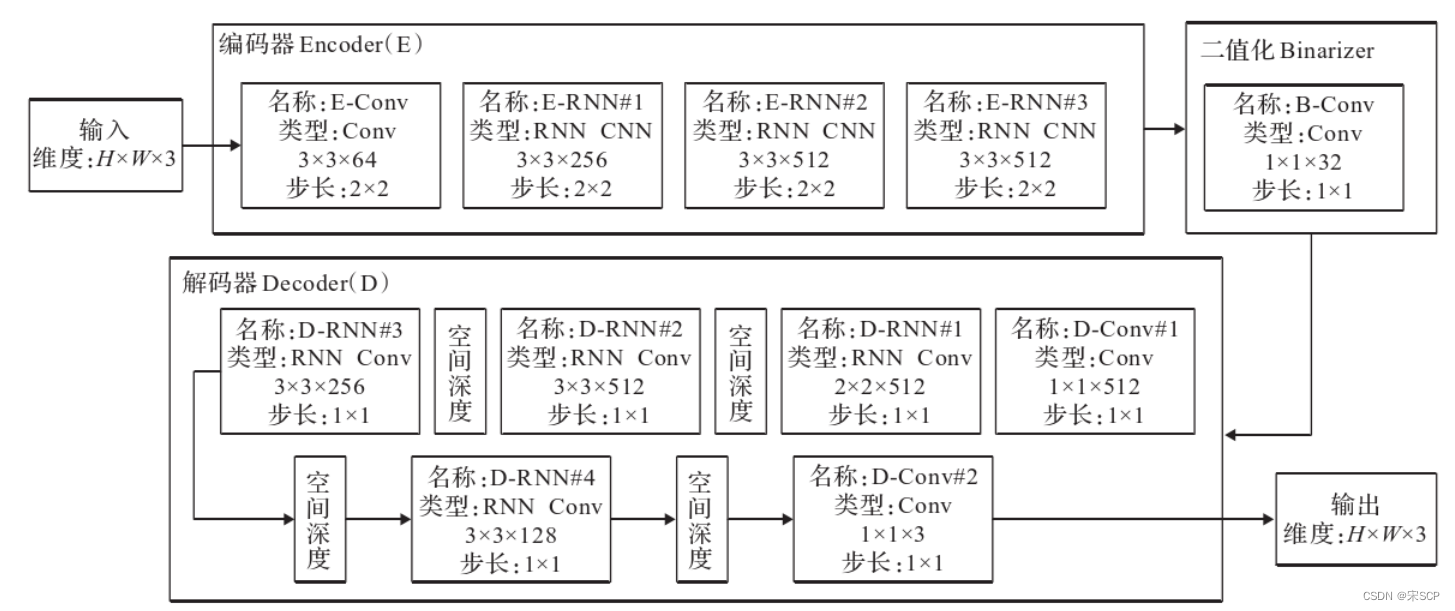
Su estructura se muestra en la figura. Este método incluye tres partes principales, a saber: codificación del codificador, binarización del binarizador y decodificación del decodificador. La imagen de entrada primero se codifica y luego se convierte en un código binario que puede almacenarse o transmitirse al decodificador.
La parte de codificación consta de una CNN y tres RNN, y la red decodificadora del codificador crea una estimación de la imagen de entrada original en función del código binario recibido.
La parte de binarización de Binarizer se realiza principalmente a través de un RNN.
La parte de decodificación del decodificador utiliza una estructura de red cíclica de convolución para iterar la señal y restaurar la imagen original. Durante el proceso de iteración, los pesos se comparten y cada iteración producirá un número binario de bits. Al mismo tiempo, en cada iteración La red extrae nueva información del residual actual y la combina con el contexto almacenado en el estado oculto de la capa recurrente para lograr la reconstrucción de imágenes a través de esta información. El éxito de este método en el uso de RNN es obvio para todos, lo que hace que más personas presten atención a la compresión de imágenes.
Marco de compresión de imágenes RNN utilizado por Toderici:
referencias
[1] Hochreiter S, Schmidhuber J. Memoria larga y a corto plazo [J].
Computación neuronal, 1997, 9 (8).
[2] Chung J, Gulcehre C, Cho KH, et al. Evaluación empírica
de redes neuronales recurrentes cerradas en modelado de secuencias [J]. arXiv: 1412.3555, 2014.
[3] Toderici G, O'Malley SM, Hwang SJ, et al.
Compresión de imágenes de velocidad variable con redes neuronales recurrentes [J]. arXiv: 1511.06085, 2015.
[4] Toderici G, Vincent D, Johnston N, et al.
Compresión de imágenes de resolución completa con redes neuronales recurrentes [C] // Actas de la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones, 2017: 5306-5314.