Hace setenta años, el profesor del MIT, Robert Fano, planteó a los estudiantes una pregunta de opción múltiple en su clase de teoría de la información:
(1) Realizar el examen final tradicional
(2) Resolver un problema difícil
El rompecabezas consiste en encontrar la forma más eficaz de codificar letras, números y otros símbolos utilizando dígitos binarios.
Esto parece un rompecabezas flexible, pero de hecho, este método también se puede utilizar para comprimir información para facilitar su almacenamiento y transmisión a través de redes informáticas.
Por supuesto, el profesor Fano ocultó el hecho de que él mismo, e incluso Shannon, el famoso fundador de la teoría de la información, estaban luchando con este problema.
Hoffman, un estudiante de posgrado de 25 años al que no le gustaba hacer exámenes, decidió resolver el problema.
El "engañado" Hoffman emprendió un camino sin retorno.
1
Hofmann comenzó a trabajar en este problema, considerando un mensaje formado por letras, números y signos de puntuación. La forma más sencilla de codificarlo es asignar a cada carácter un número binario único de la misma longitud, por ejemplo:
A -> 01000001
B -> 01000010
C -> 01000010
Este método es muy fácil de analizar, pero muy ineficaz porque algunos caracteres se utilizan con más frecuencia y otros con menos frecuencia.
Un mejor enfoque es el código Morse, en el que la frecuente letra E se representa solo con un punto, mientras que la J, menos común, requiere un punto-rayón-rayón-rayón más largo y laborioso para expresarse.

Aunque la codificación Morse tiene longitudes largas y cortas, sigue siendo ineficiente, lo que es aún más molesto es que al enviar información es necesario agregar pausas adicionales entre cada carácter, de lo contrario será imposible distinguir dos mensajes como este:
Punto-rayón-punto-punto-rayón ("trillado")
punto-rayón-punto-punto-rayón ("verdadero")
De hecho, el profesor Fano ha solucionado parcialmente este problema: utilizando códigos sin prefijos.
Por ejemplo, si la letra S aparece con mucha frecuencia en un mensaje en particular, entonces se le puede asignar el código extremadamente corto 01.
El punto es que no se codificarán otras letras del mensaje que comiencen con 01, y 010, 011 y 0101 están prohibidos.
Dado que el prefijo de cada letra es completamente diferente, el mensaje codificado se puede leer de izquierda a derecha sin ninguna ambigüedad.
Por ejemplo:
S -> 01
A -> 000
M -> 001
L -> 1
Entonces 0100000111 se puede traducir como PEQUEÑO sin ambigüedad.
Entonces, ¿cómo encontrar un algoritmo que pueda asignar los códigos más cortos a los caracteres más utilizados, reservar los códigos más largos para los caracteres poco utilizados y garantizar que cada carácter tenga un prefijo diferente?
El profesor Fano propuso un método aproximado para construir un árbol binario de arriba a abajo según la frecuencia de aparición de los caracteres en el mensaje, y luego asignar códigos.
El algoritmo específico no se describirá aquí, los estudiantes interesados pueden consultar la información relevante.
Dado que el método del profesor Fano sólo produce aproximaciones, debe haber una mejor estrategia de compresión, así que desafió a los estudiantes.
2
Hoffman estudió diligentemente durante meses y desarrolló varios métodos, pero ninguno resultó eficaz.
Hoffman estaba desesperado: el profesor lo engañó, ¡así que debería prepararse para el examen final!
Justo cuando tiraba sus notas a la basura, un relámpago pasó por su mente y apareció la solución.
"¡Este fue definitivamente el momento más singular de mi vida!"
La idea de Huffman es muy simple y elegante: específicamente, construye un árbol binario de abajo hacia arriba de acuerdo con la frecuencia de aparición de los caracteres.
Un ejemplo lo aclarará.
Suponiendo que hay un mensaje ESCUELA, primero calcule la frecuencia de cada carácter.
O: 4 veces
S/C/H/L/R/M: 1 vez
Huffman primero toma los dos caracteres con la frecuencia más baja, como R y M, para formar un árbol binario, en el que la frecuencia del nodo padre es la suma de los dos nodos hoja, que es 2.
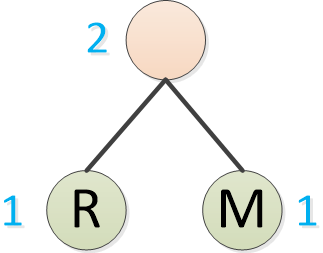
Ahora, el carácter más frecuente es O, que aparece 4 veces. La frecuencia del nodo principal de R/M es 2 y la frecuencia de otros caracteres sigue siendo 1.
Huffman continúa encontrando la frecuencia más baja para formar un árbol binario, como H, L
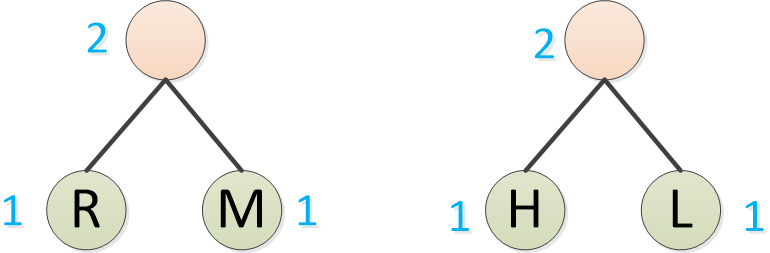
Continúe buscando el que tiene la frecuencia más baja para formar un árbol binario, como S, C
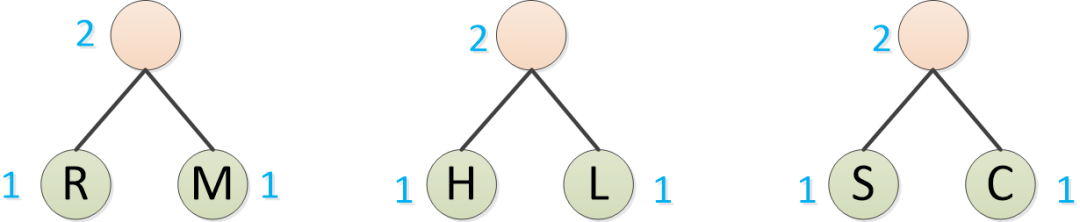
La tabla de frecuencias actual se ve así:
O: 4 veces
R/M: 2 veces
AL/L: 2 veces
S/C: 2 veces
Huffman todavía toma la frecuencia más baja, como H/L y S/C, para formar un árbol binario.
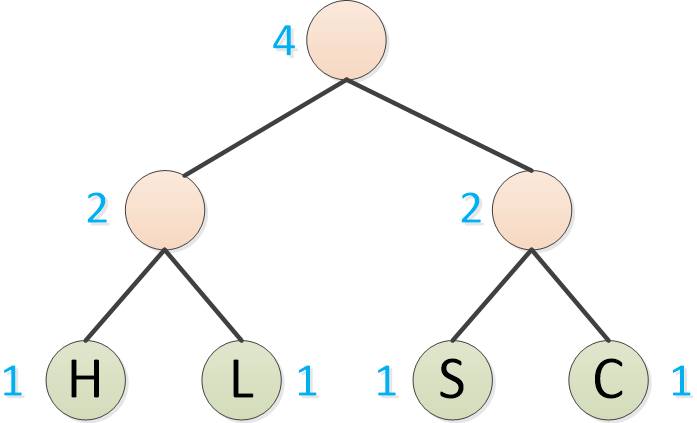
La tabla de frecuencias queda así:
O: 4 veces
R/M: 2 veces
H/L/S/C: 4 veces
Luego tome las dos frecuencias más bajas para formar un árbol binario. Tenga en cuenta que el de baja frecuencia se convierte en el subárbol izquierdo y el de alta frecuencia se convierte en el subárbol derecho.
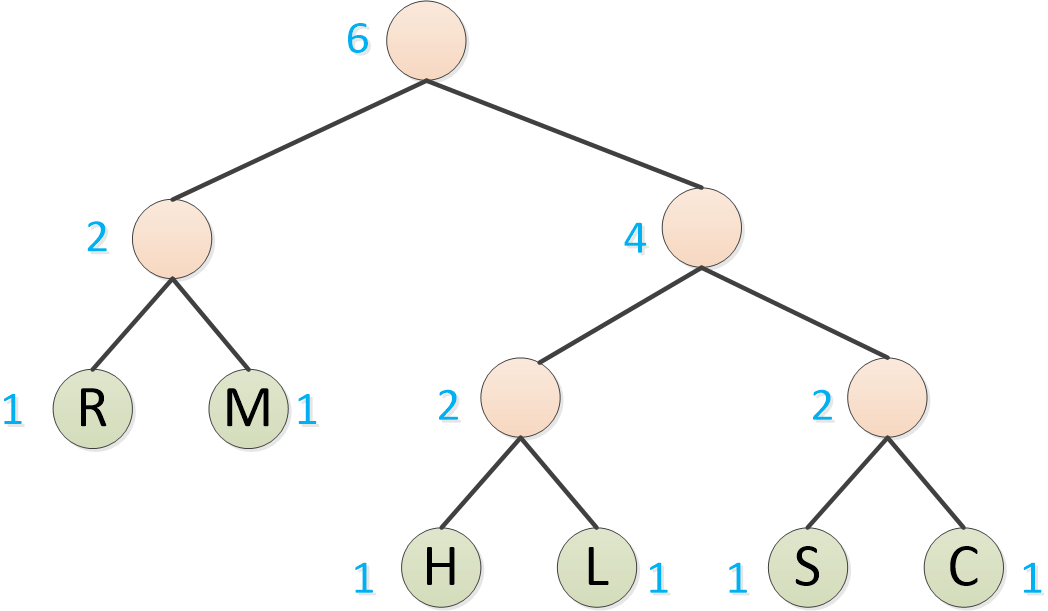
Finalmente, las O restantes también se forman en un árbol binario.
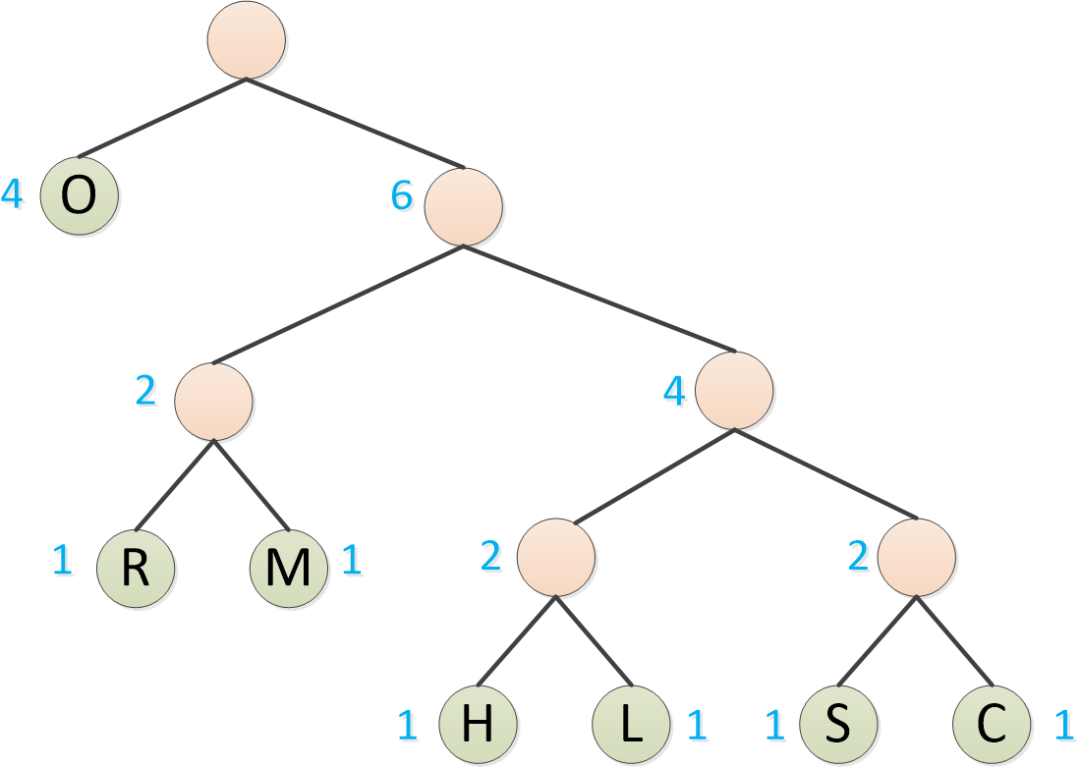
Luego, para la rama del subárbol izquierdo, marque 0, y para la rama del subárbol derecho, marque 1
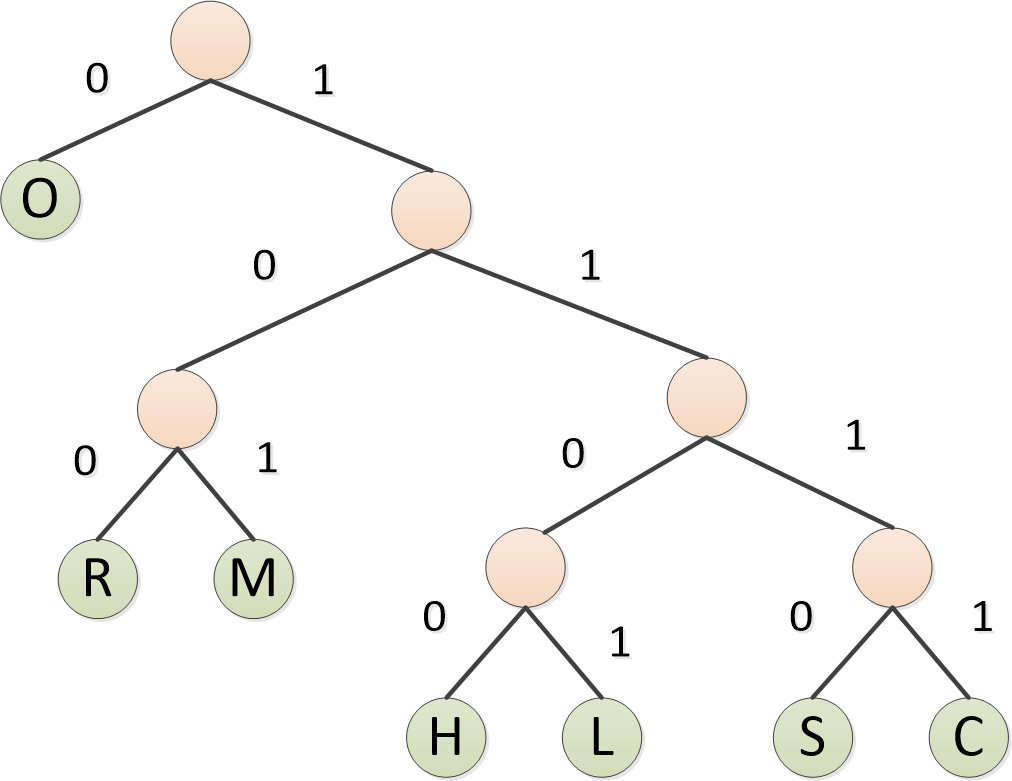
Finalmente, se forma la codificación de cada carácter.
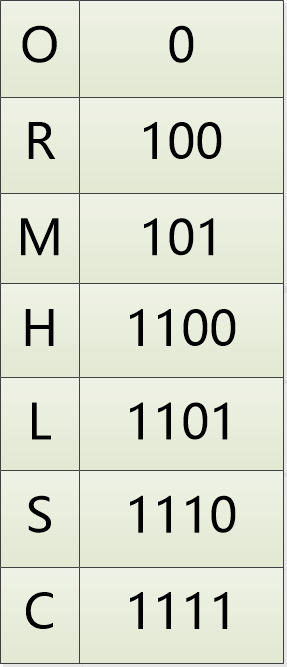
Para SCHOOLROOM, la codificación es: 11101111110000110110000101.
(Nota: al seleccionar nodos con la misma frecuencia, el orden puede ser diferente y la forma del árbol binario puede ser diferente, por lo que la codificación de Huffman no es única).
El algoritmo de Huffman se denomina "codificación óptima" y logra dos objetivos:
(1) Cualquier codificación de caracteres no es un prefijo para otras codificaciones de caracteres.
(2) La longitud total de la codificación de la información es mínima.
Hofmann superó el algoritmo de su maestro y luego dijo:
"Si hubiera sabido que el profesor Fano y Shannon, el fundador de la teoría de la información, habían luchado con este problema, nunca habría intentado resolverlo, y mucho menos resolverlo a los 25 años".

Ni siquiera el gran Shannon había pensado en un algoritmo: fue un milagro que un estudiante lo descubriera accidentalmente.
El algoritmo de Huffman se utiliza ampliamente en la compresión de datos, la compresión de archivos, la codificación de gráficos y otros campos, y es un algoritmo muy básico en la industria de TI.
3
Ahora que la historia ha terminado, compartamos algunas ideas:
(1) Este algoritmo se inventó hace 70 años. Estados Unidos está muy por delante en el campo de las computadoras, tanto en la teoría como en la práctica. Cuando se crea un campo por primera vez, hay oro por todas partes y, cuando madura, sólo puede ocuparse de las esquinas.
(2) El algoritmo de Huffman es simple y hermoso. Justo ahora, mi estudiante de quinto grado de primaria leyó este artículo y le hice una pregunta. Pudo dibujar rápidamente el árbol binario y obtener el código final.
Sin embargo, al igual que el descubrimiento de América por Colón, la mayoría de la gente realmente no puede pensar en ello, y mucho menos usar las matemáticas para expresarlo y demostrarlo.
(3) Huffman no solicitó una patente para su invención y todavía hay mucho debate sobre si el algoritmo puede patentarse. Sin embargo, otros han ganado millones utilizando el software desarrollado por el algoritmo de Huffman. La principal recompensa de Hofmann fue la exención del examen final de teoría de la información.
Knuth, autor de "El arte de la programación informática", dijo: En los campos de la informática y la comunicación de datos, la codificación de Huffman es una de las ideas básicas que la gente siempre ha utilizado.
¡Esta puede ser la recompensa más alta!
El texto completo ha terminado. Si te gusta, haz clic en Me gusta en la esquina inferior derecha y léelo.