En Didi, los datos métricos de la plataforma observable tienen algunos requisitos informáticos en tiempo real, y estos requisitos informáticos en tiempo real se llevan a cabo mediante conjuntos de tareas de Flink. La razón por la que existen múltiples conjuntos de tareas de Flink es porque cada servicio requiere diferentes cálculos de indicadores de acuerdo con sus observaciones comerciales, lo que también corresponde a diferentes topologías de procesamiento de datos . Hacemos todo lo posible para abstraer las mismas necesidades informáticas de los usuarios, pero debido a las limitaciones del modelo de desarrollo de tareas informáticas en tiempo real y el marco informático en tiempo real de Flink, el diseño de estas tareas informáticas de indicadores de observación no es lo suficientemente universal. Al utilizar Flink para el cálculo en tiempo real de indicadores de métricas, mantener múltiples conjuntos de tareas de Flink enfrenta los siguientes problemas:
Las capacidades informáticas generales de métricas que deberían haberse abstraído se han creado repetidamente y son de calidad mixta y no se pueden acumular.
La lógica de procesamiento está codificada aleatoriamente en el código de la tarea de transmisión y es difícil de actualizar y mantener.
El lanzamiento, la expansión y la reducción de Flink requieren tareas de reinicio, lo que provocará retrasos en la salida del indicador, puntos de interrupción y errores.
La plataforma Flink es relativamente cara, representa una gran parte de nuestros costos internos y existe cierta presión de costos.
Para resolver estos problemas, hemos desarrollado un conjunto de motores informáticos en tiempo real: observe-compute (OBC para abreviar), la siguiente es una introducción a la implementación de OBC.
Objetivos de diseño
Al inicio del proyecto, los objetivos de diseño determinados por la OBC fueron los siguientes:
1. Crear un motor de cálculo universal en tiempo real en el campo del cálculo de indicadores de Métricas , este motor tiene las siguientes características:
En línea con los estándares de la industria: uso de PromQL como lenguaje de descripción para tareas de procesamiento de flujo
Gestión y control de tareas flexibles: las estrategias se configuran, las tareas informáticas entran en vigor en tiempo real y el plan de ejecución se puede intervenir manualmente.
Trazabilidad del enlace informático: capaz de lograr la trazabilidad a nivel de política de los resultados del cálculo
Contenedorización nativa de la nube: la implementación de contenedores del motor permite la expansión y contracción dinámicas sin tiempo de inactividad.
2. El producto puede satisfacer todas las necesidades de cálculo de indicadores métricos de la plataforma observable, reemplazar tareas de cálculo repetidas, reducir costos y aumentar la eficiencia, y remodelar los enlaces de recopilación, transmisión y cálculo de observaciones.
Actualmente, a excepción de la función de calcular la trazabilidad del enlace, se han implementado todas las demás funciones del motor. OBC ha estado funcionando de manera estable en línea durante más de varios meses. Varios conjuntos de tareas informáticas de Flink en el núcleo de la plataforma observable se han migrado a OBC. Se espera que las tareas migradas ahorren un costo acumulativo de 1 millón de yuanes para el observable. plataforma para finales de año.
Arquitectura del motor
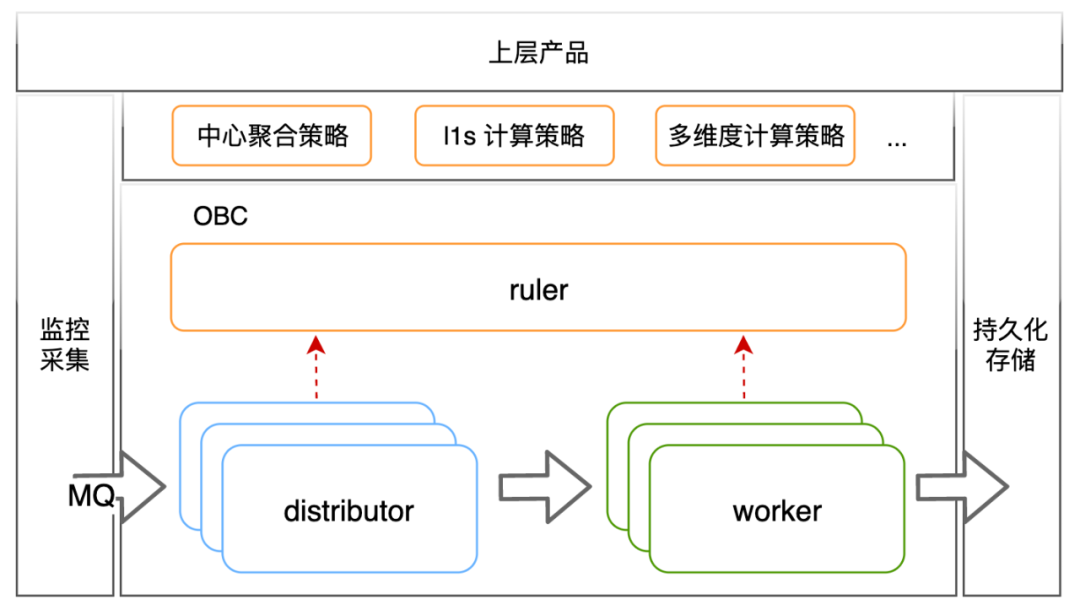
La arquitectura del motor se muestra en la figura anterior y se divide en tres componentes: obc-ruler es el componente de control del motor, que proporciona capacidades de registro y descubrimiento de servicios para otros componentes del motor. También es responsable del acceso a datos externos. estrategias informáticas y el control de planes de ejecución. obc-distributor ingiere indicadores de métricas de la cola de mensajes de métricas, coincide con la estrategia de cálculo y reenvía los datos a obc-worker de acuerdo con el plan de ejecución de la estrategia. obc-worker es el componente del motor que realmente es responsable de los cálculos. Es responsable de completar los cálculos de los indicadores de acuerdo con el plan de ejecución y entregar los resultados de los cálculos al almacenamiento persistente externo.
discusión sobre usabilidad
Antes de presentar en detalle la lógica central de cada componente, primero presentemos nuestras ideas y compromisos sobre la usabilidad, así como algunos conceptos introducidos para lograr los objetivos de usabilidad. Esta parte de la discusión ayudará a comprender la lógica central de cada componente.
pensamiento de usabilidad
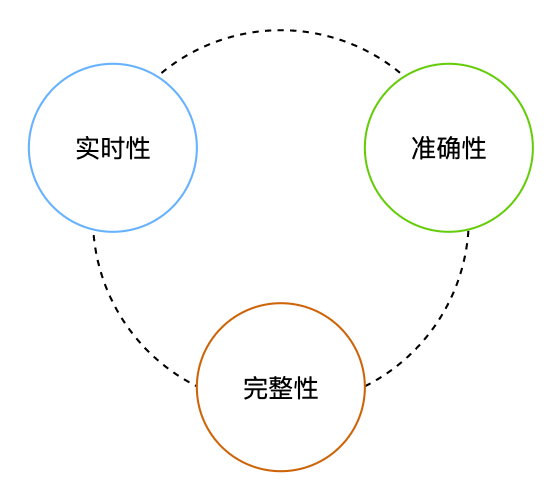
Los requisitos de disponibilidad de datos en escenarios informáticos en tiempo real se pueden dividir en requisitos de tiempo real y requisitos de precisión , que requieren datos de baja latencia y alta precisión. La precisión se puede describir como buenos datos y sin pérdidas. El requisito de que los datos sean buenos es lo que yo llamo requisito de precisión, y el requisito de que los datos no se pierdan es lo que llamo requisito de integridad.
Para los datos de observación empresarial, desde la perspectiva de los resultados finales, también es adecuado discutir la disponibilidad desde las tres perspectivas anteriores:
Tiempo real: no debería haber grandes retrasos en la caída de datos al almacenamiento
Precisión: los datos almacenados deben reflejar con precisión el estado del sistema.
Integridad: a los datos ingresados en el almacenamiento no les pueden faltar puntos ni puntos de interrupción.
El proceso simple de procesamiento de datos de observación se puede simplificar como: recopilación => almacenamiento. Lo que se recopila en dicho proceso es lo que se recopila y no es necesario discutir la exactitud de los datos. Entre los dos requisitos de tiempo real e integridad, para reducir la complejidad de la implementación y la sobrecarga operativa del sistema, el enfoque general es garantizar el tiempo real y sacrificar la integridad.
Los escenarios en los que los datos de observación participan en cálculos en tiempo real serán más complejos que los escenarios ordinarios y es necesario analizar más a fondo la precisión de los datos. Nuestro flujo de datos interno desde observe-agent (final de colección) => mq => obc-distributor => obc-worker => almacenamiento persistente, bajo la premisa de que el retraso en la distribución de datos en la misma ventana de cálculo que llega a obc-worker satisface la Supuesto, se debe garantizar al menos la semántica de al menos una vez desde el final de la recopilación hasta obc-worker, y se debe implementar la lógica de deduplicación de datos y la integridad de la ventana de cálculo en obc-worker para garantizar resultados precisos. Para nosotros, tanto el costo de diseño e implementación como el costo de recursos informáticos adicionales para garantizar la precisión son ligeramente mayores. Y cuando usamos Flink para calcular los indicadores de métricas, no podemos garantizar que los datos de salida finales sean precisos. Por lo tanto, OBC también ha hecho algunos compromisos necesarios en el diseño de la solución. Con la premisa de garantizar la salida en tiempo real de la Resultados del cálculo, hacemos todo lo posible para garantizar los resultados del cálculo . Solo romperá puntos (integridad) y no cometerá errores (precisión), pero no promete que los datos producidos serán precisos.
diseño de usabilidad
Primero, presentamos un concepto llamado tiempo de corte. El significado de corte es cambio. Este concepto está tomado de m3aggregator. En OBC, el tiempo de corte se establecerá en un momento posterior al momento en que la configuración cambia como el tiempo efectivo real de la configuración, de modo que obc-distributor y obc-worker tengan múltiples oportunidades para sincronizarse con la misma configuración antes del cambio. la configuración realmente surte efecto. El concepto de tiempo de corte se introduce aquí inicialmente porque cuando obc-distributor reenvía datos a obc-worker, seleccionará a qué instancia de trabajador se debe reenviar en el anillo hash formado por obc-worker. , Cuando el trabajador cambia el hash constituido, surgirá un problema: si el cambio entra en vigor inmediatamente, entonces obc-distribuidor percibe que el proceso de cambio de hash es secuencial y el anillo de hash del trabajador que entra en vigor en el grupo de distribuidores será inconsistente durante un corto período de tiempo. La configuración se configurará mediante transición. Retrasar el tiempo efectivo real puede darle al distribuidor más tiempo para detectar los cambios de configuración. El diseño de usabilidad más específico se divide en los siguientes puntos:
1. Obc-worker falla, se desvía y se reinicia, provocando como máximo tres puntos de interrupción en algunas curvas, sin ningún punto de error.
Existe un mecanismo de sincronización de latidos entre el trabajador y el gobernante, que se sincroniza cada 3 segundos.
El distribuidor sincroniza el hash trabajador de la regla con una frecuencia de timbre de 3 segundos.
La regla completa la lógica de actualización de la versión del anillo hash según el estado del trabajador. Una transición es una versión y la versión histórica se conserva por hasta 10 minutos.
Juicio del gobernante sobre la muerte del trabajador: el latido del corazón no se ha actualizado durante 8 segundos, o el gobernante llama activamente a la interfaz para cerrar sesión.
Tiempo de retardo de propagación del anillo hash: 8 s

2. La deriva y el reinicio del distribuidor obc no causarán puntos de interrupción en la curva ni puntos incorrectos.
obc está implementado en nuestra plataforma en la nube interna. Nuestra plataforma en la nube interna tiene algunas capacidades de soporte para un reinicio elegante: la deriva y el reinicio del contenedor enviarán una señal SIGTERM al proceso comercial. El distribuidor escuchará esta señal y hará dos cosas después de recibirla:
Deja de consumir de MQ
Los puntos de datos de métricas, los puntos de datos en el caché que aún no se han enviado al trabajador, se enviarán lo antes posible.
3. Los pánicos del distribuidor de Obc y el nodo físico donde está ubicado pueden causar puntos de interrupción y errores.
En este caso, el distribuidor no tiene posibilidad de hacer frente a las consecuencias: parte de los datos que se han almacenado en caché en la memoria y aún no han sido enviados al trabajador se pierden, lo que provocará errores en los resultados del cálculo.
¿Cuál es el impacto sobre los usuarios de esta situación? Nuestro antiguo enlace de cálculo de métricas observe-agent (final de colección) => mq => router => kafka => flink. El módulo de enrutador en el enlace realiza parte del trabajo similar al distribuidor. También tiene el mismo problema y ha estado ejecutándose. durante tantos años Parece que la percepción del usuario no es obvia
4. El requisito de precisión del resultado del indicador es que no habrá puntos de interrupción ni errores al actualizar las estrategias dentro de los 60 segundos o menos.
Después de que la actualización de la política entre en vigor en el clúster, se producirán errores a corto plazo si la política no está sincronizada. Para resolver este problema, también se introduce en la política el concepto de tiempo de corte. El tiempo de corte está alineado con 60 segundos. .
Introducción a cada componente.
regla-obc
El módulo de regla tiene dos funciones principales, registro/descubrimiento de servicios y gestión de políticas, como se muestra en la siguiente figura:
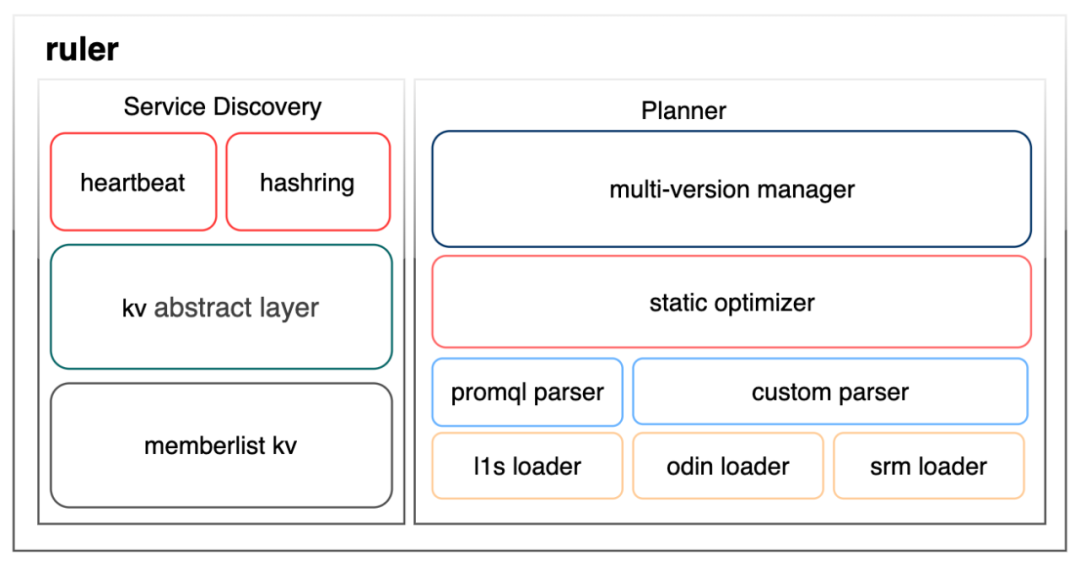
La construcción de capacidades de registro/descubrimiento de servicios se divide en tres capas. La capa abstracta kv y las capas kv de lista de miembros utilizan la biblioteca tripartita grafana/dskit. Esta biblioteca admite varios kv como cónsul y etcd bajo la capa abstracta kv. Finalmente, Elegimos usar memberlist kv para construir el kv de consistencia final basado en la capacidad de sincronización de datos proporcionada por el protocolo gossip. La razón es que esperamos que el observable en sí reduzca las dependencias externas tanto como sea posible para evitar depender de componentes externos para proporcionar capacidades de observación, y estos componentes externos dependen de nuestras capacidades de observación para garantizar su estabilidad, lo cual es un problema de dependencia circular. La explicación directa del latido y el hash de la capa superior son las dos claves registradas en la tienda kv y su lógica de fusión de conflictos de apoyo. La clave de latido almacena información como la dirección del trabajador, la hora de registro, la hora del último latido, los tokens hash asignados al trabajador, etc., mientras que la clave de hash almacena los anillos hash del trabajador de múltiples versiones de transición.
El módulo de gestión de políticas está dividido en cuatro capas. La capa más baja son varios cargadores, que son responsables de cargar configuraciones desde fuentes de políticas externas. En la figura se enumeran los cargadores de políticas informáticas de varios de nuestros productos más principales. Para las tareas informáticas existentes, para migrar OBC, personalizaremos un analizador para convertir estrategias informáticas. Para las tareas informáticas nuevas, necesitaremos el uso unificado de PromQL para describir sus requisitos informáticos y utilizar el análisis del analizador PromQL. El plan de ejecución producido por el analizador es un árbol y el optimizador realizará algunas optimizaciones en el plan de ejecución. De hecho, actualmente es solo una simple combinación de algunos operadores. El administrador de versiones múltiples realiza la programación general de las actualizaciones de políticas y prohíbe las políticas anormales.
distribuidor-obc
La función principal del módulo distribuidor es correlacionar estrategias de cálculo y reenvío de puntos de datos de métricas.
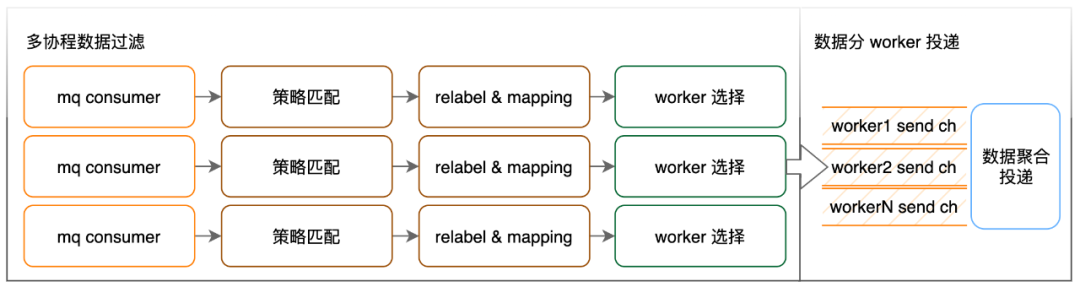
El trabajo realizado aquí en la coincidencia de estrategias es filtrar los puntos de datos de acuerdo con la etiqueta especificada y etiquetar los puntos de datos filtrados con el ID de la estrategia correspondiente. Uno de nuestros grupos informáticos OBC en línea más grandes tiene un volumen de entrada de casi 1000 W/s y el número de políticas informáticas efectivas es de 1,2 W. La cantidad de datos es realmente demasiado grande, por lo que para mejorar la eficiencia de la detección, tenemos impuso algunas restricciones a las políticas efectivas: La evaluación de políticas debe contener dos etiquetas, __name__ y __ns__, y estas dos etiquetas no pueden utilizar coincidencias regulares. __name__ es el nombre del indicador y __ns__ significa espacio de nombres, que representa el clúster de servicios al que se informa el indicador. Nos basamos en estas dos etiquetas para crear un índice de dos niveles para mejorar la eficiencia de la coincidencia de políticas.
La acción de volver a etiquetar es agregar/eliminar/modificar las etiquetas de los puntos de datos de acuerdo con los requisitos de la política. En términos de sintaxis de configuración, para unificar la descripción, procesamos estas reglas en funciones PromQL y limitamos los parámetros vectoriales de estas funciones a solo un selector u otra función de reetiquetado. La acción de mapeo es similar a la unión de tablas de dimensiones en otras transmisiones informáticas: es el producto de un compromiso para acceder a tareas informáticas existentes y no se presentará en detalle.
El proceso de selección de trabajadores:
Tiempo de alineación del punto de datos event_time: align_time = event_time - event_time % de resolución, donde la resolución es la precisión del indicador de salida esperado dado en la estrategia
Selección de anillo hash de trabajador: use align_time para encontrar el último anillo hash de trabajador en la lista de anillos hash cuya transición no sea mayor que align_time.
Selección de instancia de trabajador: use planid + align_time + el valor de una serie de etiquetas especificadas como clave para calcular el valor hash y use el valor hash para encontrar la instancia de trabajador en el anillo hash de trabajador. La regla genera la serie especificada de etiquetas después de analizar la estrategia y, generalmente, están vacías para las estrategias que requieren el procesamiento de una pequeña cantidad de datos.
trabajador-obc
La función principal del trabajador es el cálculo de indicadores de métricas.
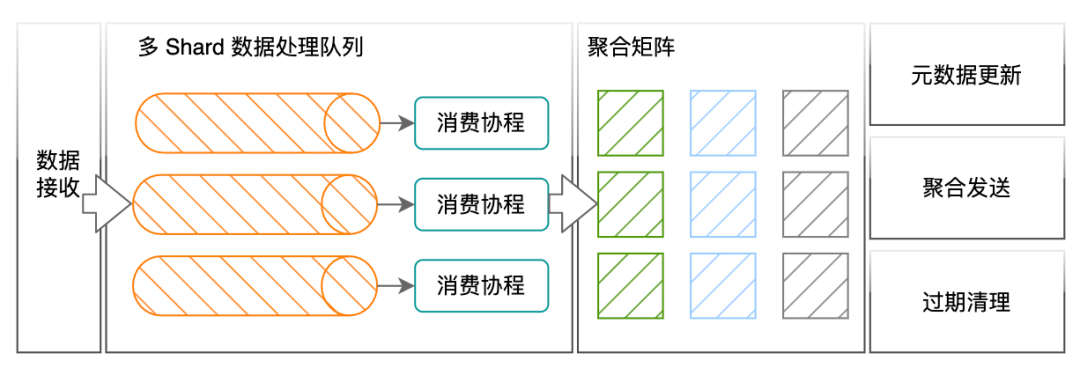
El distribuidor garantiza que los puntos de métricas de la misma política, la misma dimensión de agregación y la misma ventana de cálculo se reenviarán al mismo trabajador. Los puntos de datos de métricas recibidos por el trabajador contendrán la información de identificación de la política, y el trabajador la utilizará para buscar y calcular el contenido de la política. La unidad de operación lógica más pequeña para calcular estrategias es la Acción. Las funciones, operaciones binarias y operaciones de agregación en PromQL se traducen en Acciones. En la matriz de agregación del trabajador, debajo de cada Acción hay una serie de ventanas de tiempo alineadas de acuerdo con la resolución. Dentro de la ventana de tiempo, un conjunto de datos que deben calcularse juntos se escribe en la misma unidad informática. La unidad informática es en el trabajador La unidad informática física más pequeña. Los datos agregados a la misma unidad informática no se almacenan en caché, sino que se utilizan para cálculos en tiempo real a menos que sea necesario.
Esto puede ser difícil de entender, déjame darte un ejemplo, tomando la regla de cálculo suma por (llamante, llamador) (rpc_counter), el filtrado del indicador original rpc_counter se completa en el distribuidor, y la acción de suma por (calante , destinatario) se procesa como una acción. El tipo de acción es una operación de agregación. El tipo de agregación es suma. Las dimensiones de la salida de datos después de la agregación son la persona que llama y la persona que llama. Al procesar puntos de datos, el trabajador comparará los datos con el mismo valor de las dos etiquetas de la persona que llama y la persona que llama. Los puntos se envían a la misma unidad de agregación. Cada vez que la unidad de agregación recibe un punto, realizará una acción como suma += punto.valor.
Un problema al que los trabajadores deben prestar atención cuando procesan operaciones binarias y operaciones de agregación es la configuración del tiempo de apertura de la ventana. ¿Cuánto tiempo espera una ventana hasta que lleguen todos los datos que necesita? Este valor afecta directamente el tiempo real y la precisión de salida del indicador. Hemos establecido la siguiente política predeterminada basada en la distribución del retraso de nuestras propias métricas en la transmisión del enlace:
Si el valor del paso del indicador original es menor o igual a 10, el tiempo de apertura de la ventana se establece en 25 segundos.
Si el valor del paso del indicador original es mayor que 10, el tiempo de apertura de la ventana se establece en 2*paso + 5. Si el tiempo de apertura de la ventana es mayor que 120 s, el tiempo de apertura de la ventana se establece en 120
Esta parte presenta la implementación de cada componente de manera relativamente breve. Solo presenta el proceso central. Muchas de las compensaciones y optimizaciones que hemos realizado en términos de rendimiento y funciones se presentarán por separado cuando tengamos la oportunidad.
Contenido complementario
Para facilitar la comprensión de todos, aquí se agrega contenido adicional.
Ejemplo de estrategia de cálculo
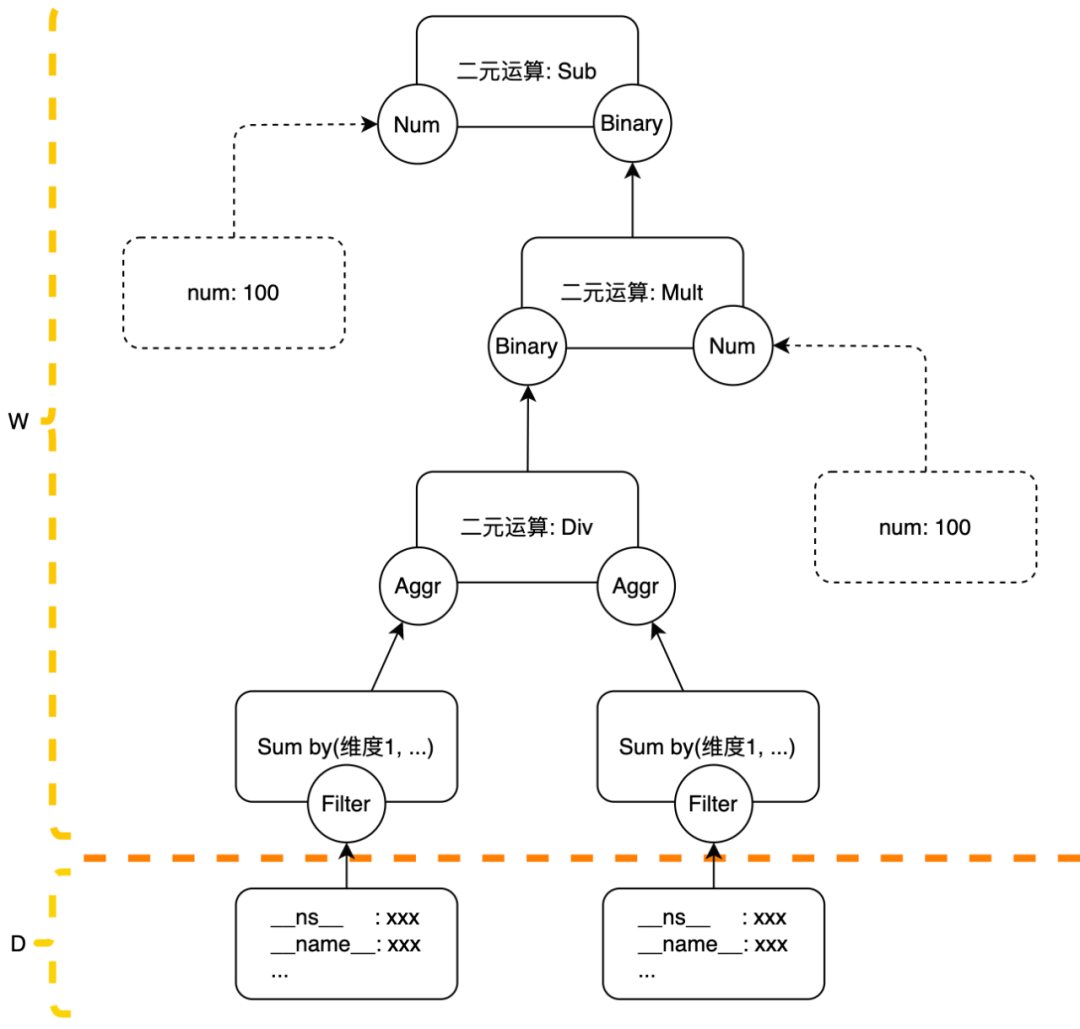
La estrategia interna de OBC se expresa en forma de árbol: los nodos de hoja del árbol deben ser las condiciones de filtrado o constantes de las métricas, y los nodos de hoja no pueden ser constantes (dicha estrategia no tiene sentido para las basadas en eventos). motores de computación) El filtrado de Métricas La condición se llama Filtro en la política, el Filtro se ejecuta en el distribuidor y el resto de Acciones se ejecutan en el trabajador. Si la política no se establece específicamente, las métricas que coincidan con la política en la misma ventana se enviarán al mismo trabajador. El procesamiento de acciones posteriores se completará en este trabajador. Los datos de diferentes ventanas se pueden enviar a diferentes trabajadores. El motivo de La cuestión es que el equilibrio de carga entre los trabajadores no se puede lograr simplemente dispersándolos en la dimensión política.
Hay un punto especial a tener en cuenta aquí: si la cantidad de datos en una sola ventana de una determinada política es demasiado grande para que la maneje un solo trabajador, realizaremos algunas configuraciones manualmente para distribuir la política a varios trabajadores de acuerdo con algún cálculo agregado. dimensiones. Si no se puede dividir o si un solo trabajador aún no puede manejarlo después de dividirlo, optaremos por prohibirlo. Por supuesto, debido a que restringimos los datos filtrados en la política de cálculo para que tengan la etiqueta __ns__ y solo podemos usar los datos de métricas del mismo servicio para el cálculo, hasta ahora no nos hemos encontrado con una situación que requiera una política de prohibición. Para situaciones en las que un solo trabajador no puede manejarlo, también puede optar por implementar capacidades informáticas en cascada entre trabajadores y procesar tareas de datos grandes de manera combinada. Si hay una demanda posterior, esta capacidad se puede expandir rápidamente en la arquitectura actual.
Soporte para PromQL
OBC espera utilizar PromQL como método de acceso de usuarios para estrategias informáticas, lo que puede reducir la comprensión de las estrategias por parte de los usuarios y los costos de acceso. A la fecha de redacción de este artículo, nuestro nivel de finalización del soporte de sintaxis y funciones de PromQL no es alto. La razón principal de esto es que hay muchas operaciones y acceso estratégico a las existencias de operadores que no se utilizarán. La demanda nos impulsa a implementar gradualmente ellos bajo demanda En la implementación, también hay algunas sintaxis PromQL que no son adecuadas para la implementación en cálculos en tiempo real, como el modificador de compensación, el modificador @ y la subconsulta.
En el artículo anterior, presentamos que el distribuidor garantiza que los datos de la misma ventana de cálculo de la misma estrategia de cálculo se envíen al mismo trabajador. Quizás se pregunte aquí, ¿qué pasa con el vector de rango? ¿Cómo calcular Irate cuando dos puntos en la ventana antes y después de operaciones como Irate (http_request_total[10s]) se reenvían a diferentes trabajadores? Si tiene esas dudas, debo felicitarme por hacerle leer atentamente y comprender lo que escribí antes.
Los vectores de rango, incluido el selector de vectores de rango y la función de vector de rango, no son compatibles con la versión actual de OBC. La razón por la que no son compatibles es porque no podemos usarlos por el momento. Puede pensar que todos nuestros datos internos son calibre. tipos en Prometheus. Para solicitudes El llamado indicador de contador de nuestro lado en realidad cuenta el volumen de solicitudes en cada ciclo de 10. Los datos entre ciclos no se acumularán, al igual que nuestros datos de contador se han incrementado (http_request_total) antes de ser informados. [ 10s]) dicha operación. Por supuesto, definitivamente consideraremos implementar soporte de sintaxis relacionada con vectores de rango en el futuro, pero también impondremos algunas restricciones de sintaxis.
Latencia de solicitud de granularidad de clúster precisa
Didi Observable Platform no tenía el concepto de histograma como tipo de datos antes de admitir la recopilación de Prometheus Exporter y la recuperación de datos PromQL. Con respecto al retraso de la solicitud de servicio, utilizaremos el algoritmo t-digest en el extremo de la recopilación para aproximar la distribución del retraso de la interfaz de cada instancia de servicio e informar los datos de retraso de los valores cuantiles 99, 95, 90 y 50 de forma predeterminada. Debido a la falta de información original, es imposible proporcionar a los usuarios un cálculo relativamente preciso del valor cuantil de retraso de la interfaz de granularidad del clúster. En su lugar, solo pueden utilizar el valor promedio o máximo del indicador del valor cuantil de retraso de granularidad de una sola máquina.
También resolvimos este problema en OBC. El método específico es que OBC coopera con el extremo de la colección. Cuando el extremo de la colección informa el indicador del valor del cuantil de retraso, también informa la información del depósito de la distribución de retraso de la interfaz en conjunto. La información agrupada no cae en el almacenamiento persistente y solo se ingiere en OBC a pedido. OBC extiende las operaciones relevantes a un operador de agregación PromQL. El nombre de este operador es percentil. Su acción es fusionar la información agrupada de una sola máquina para obtener una nueva distribución de retraso, produciendo los cuantiles de esta distribución bajo demanda.
Resumen y perspectivas
Hasta ahora, OBC ha estado funcionando de manera estable en línea durante más de varios meses. Varias tareas informáticas de métricas centrales de la plataforma observable se han migrado a OBC y se han logrado importantes beneficios de costos.
Con respecto a las ideas de iteración posterior del proyecto, aquí hay una introducción a uno de los puntos centrales: esperamos incluir el final de la colección en este conjunto de motores informáticos para lograr la integración de la recopilación y el cálculo: para las necesidades informáticas del usuario, podemos movernos como lo más adelante posible, el final de la adquisición se completa y el precálculo se puede realizar al final de la adquisición y el precálculo se puede realizar al final de la adquisición tanto como sea posible.
Después del cálculo realizado por el motor de cálculo, hemos producido más datos de observación, incluidos datos originales y nuevos resultados de cálculo. ¿Dónde terminan almacenados estos datos? Si elegir almacenamiento en filas o columnas, si usar soluciones existentes o autoinvestigación y cómo resolver problemas de datos masivos. El próximo artículo contará la historia del almacenamiento de datos de observación en Didi.
Charla nocturna nativa de la nube
¿Cómo soporta las necesidades de cálculo de indicadores observables en el entorno de producción? Bienvenido a dejar un mensaje en el área de comentarios. Si necesita comunicarse más con nosotros, también puede enviar un mensaje privado directamente al backend.
El autor seleccionará uno de los mensajes más significativos y le enviará una maleta personalizada Didi, deseándole un viaje sin preocupaciones el 1 de octubre. La lotería se sorteará el 26 de septiembre a las 21:00 horas.
