【读论文】RFN-Nest: una red de fusión residual de extremo a extremo para imágenes visibles e infrarrojas
Documento: https://arxiv.org/abs/2103.04286
Código: https://github.com/hli1221/imagefusion-rfn-nest
Si hay alguna infracción, comuníquese con el blogger.
introducir
Palabras clave
- Red de fusión que se puede aprender
- entrenamiento en dos etapas
- Funciones de pérdida novedosas y eficientes
una breve introducción
Un artículo publicado en 2021. El autor del artículo es el autor de DenseFuse con el que estamos familiarizados.
El artículo propone una red de fusión residual basada en una arquitectura residual, llamada RFN. Después de leer DenseNet, sabemos que la estrategia de fusión utilizada en DenseNet está diseñada manualmente. En este artículo, RFN se utiliza como dispositivo de fusión. El RFN aquí se obtiene a través del aprendizaje.
La red mencionada en el documento consta de tres partes, a saber, el codificador, el decodificador y RFN (red de fusión de características). A diferencia de DenseFuse, las características extraídas por el codificador aquí incluyen características de 4 escalas y luego características de cuatro escalas. enviado al RFN para la fusión de características y luego entregado al decodificador para su decodificación y obtener la imagen de fusión que queremos.
Estructura de red
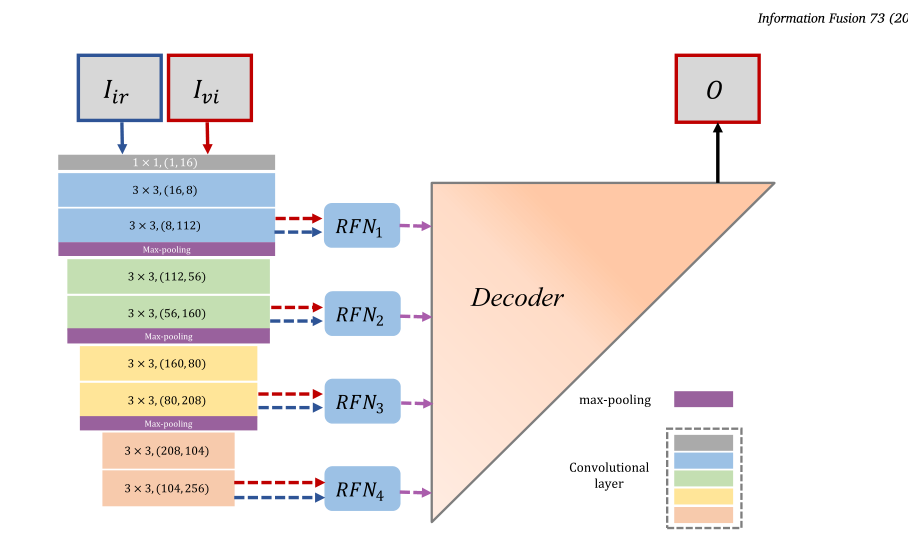
La estructura de red del método mencionado en el artículo se muestra en la figura anterior. Es más complicado que DenseFuse. A continuación, dividiremos la red anterior en tres partes para discutir.
Red convergente RFN
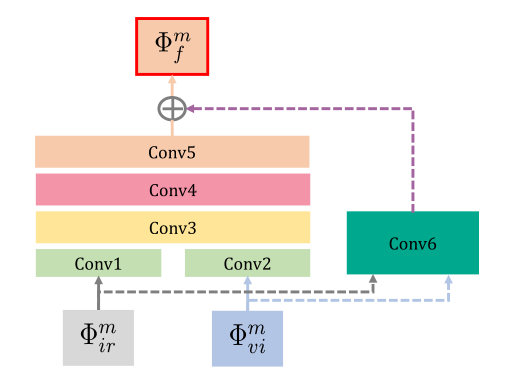
Como se muestra en la figura anterior, es un diagrama estructural de un RFN: la entrada es la característica extraída en múltiples escalas, ir es la característica de la imagen infrarroja y vi es la característica de la imagen visual. Las dos características sirven como entrada de conv1 y conv2 respectivamente, y también sirven como entrada de conv6. Las salidas de conv1 y conv2 están conectadas y sirven como entrada de conv3.
Aquí la salida de conv6 y la salida de conv5 se procesan antes de usarse como características generadas por la red de fusión. Aquí puede ver que la salida de conv6 se usa como entrada del resultado final. Es un poco similar. ¿Es ¿Muy similar a ResNet? Parece entender que el residuo está ahí.
La salida final se utiliza como entrada del decodificador, y hablaremos de ello a su vez.
Codificador
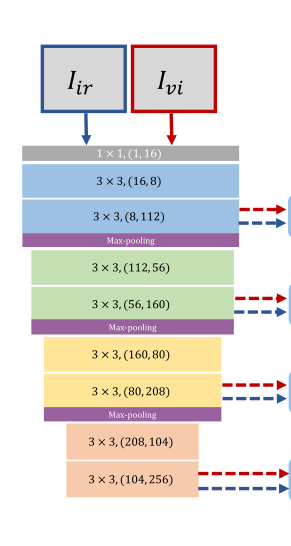
La estructura del decodificador se muestra en la figura anterior: la estructura de la red del decodificador se puede dividir en cuatro bloques, cada bloque consta de dos capas, seguidas de una agrupación máxima.
La entrada de la red es una imagen visual y una imagen infrarroja. Hay ocho flechas en el lado derecho de la figura. Cada flecha representa una salida, que representa las características extraídas de la imagen infrarroja o las características extraídas de la imagen visual. Aquí puede combinarlo con el RFN anterior. Las entradas vi e ir en RFN son las características extraídas. Como se muestra abajo
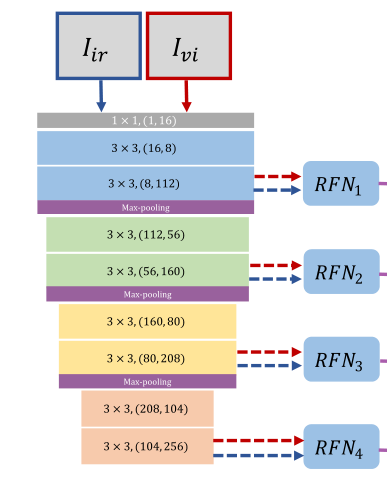
Ahora asociamos aproximadamente el decodificador con la red de fusión.
Entonces, ¿por qué hay ocho resultados? Esta es la extracción de características de múltiples escalas mencionada en el documento.
Después de la convolución y la agrupación máxima, el tamaño de la imagen ha cambiado y el tamaño de la imagen inferior es más pequeño. Las imágenes de gran tamaño se utilizan para extraer características detalladas y las imágenes de tamaño pequeño se utilizan para extraer características generales. Se dividen en 4 escalas para extraer características. Estas características se ingresan en RFN, y las características fusionadas se obtienen y se ingresan a el decodificador para reconstruir la imagen.
descifrador
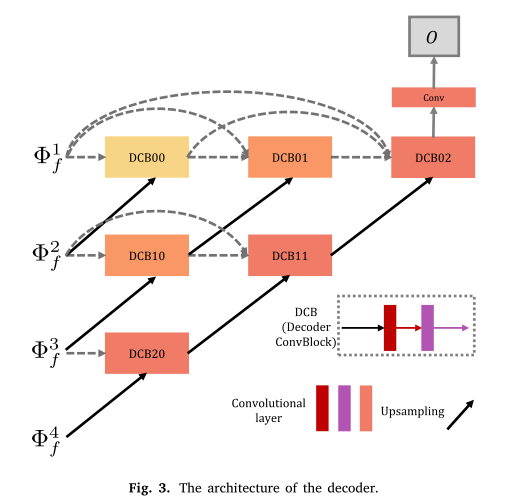
La estructura del decodificador se muestra en la figura anterior.
Lo más interesante aquí es cada línea. Si la miras línea por línea, encontrarás que es un poco como DenseNet. Las características de fusión extraídas por la escala 3 y las características de fusión extraídas por la escala 4 son procesadas juntas por DCB20 para obtener el resultado, y luego el resultado se procesa junto con el resultado de otro procesamiento de características, y esto continúa hasta el resultado final, un fusionado. se genera la imagen.
Al ver esto, es posible que se sienta un poco confundido. ¿No se trata de una reducción de resolución después de la convolución? No hay aumento de resolución en todo el artículo. ¿Cómo podemos restaurar la imagen al mismo tamaño que la imagen original?
No es obvio que la flecha negra aquí esté sobremuestreo. Aquí está la explicación de cómo regresar.
Ahora sólo nos falta ensamblar las tres partes anteriores para obtener la estructura final.
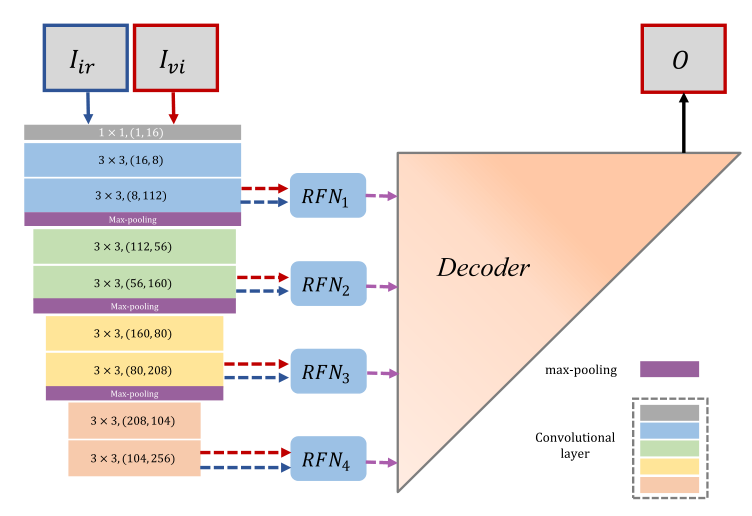
tren
Aquí se utiliza un método de entrenamiento en dos etapas.
Entrenar una red de codificador automático
Primero, extraiga el RFN y entrene el codificador y el decodificador. La estructura de red entrenada se muestra en la siguiente figura.
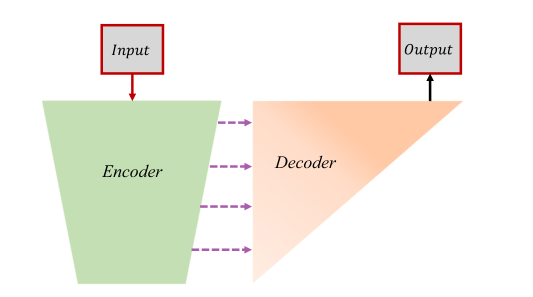
El propósito de entrenar la red anterior es hacer que el codificador tenga una mejor capacidad para extraer características y que el decodificador tenga una mejor capacidad de decodificación, es decir, la capacidad de generar imágenes.
Tenga en cuenta que la entrada y la salida aquí son imágenes únicas.
función de pérdida
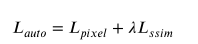
Lpixel representa la pérdida de píxeles, Lssim representa la pérdida estructural.
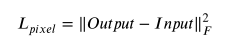
La fórmula de F aquí es la siguiente: Lpixel es hacer una diferencia entre salida y entrada y optimizar continuamente la red en función de la diferencia, de modo que la imagen generada se vuelva cada vez más similar a la imagen original.
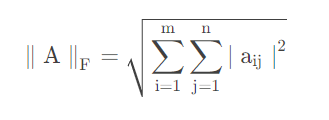
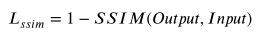
SSIM calcula la similitud estructural entre Salida y Entrada. Para obtener contenido de cálculo específico, consulte la fórmula SSIM: Principio de cálculo de similitud estructural, evaluación de la calidad de imagen basada en SSIM
Entrenamiento RFN
El entrenamiento de RFN se realiza después de que se completa el entrenamiento del codificador y el decodificador. En este momento, nuestro propósito es entrenar el RFN después de que el codificador y el decodificador estén reparados para lograr el mejor efecto.
La estructura durante el entrenamiento es la estructura completa que mencionamos anteriormente, y el mapa no se mapeará aquí.
función de pérdida
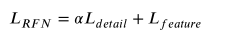
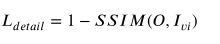
Según tengo entendido, Ldetail aquí es para garantizar que la imagen tenga más detalles e información estructural en la imagen visual, pero la imagen visual a menudo no puede mostrar completamente la estructura completa del objetivo, lo que requiere que la extraigamos de la imagen infrarroja. La información que queremos.

Por ejemplo, en las dos imágenes de arriba podemos ver algunos detalles de la ropa del cuerpo de la persona, pero no podemos encontrar completamente el contorno del cuerpo, por lo que es necesario fusionar ambas para generar una imagen con información más completa. Esto introduce la siguiente función de pérdida, que es el segundo término de la función de pérdida total.
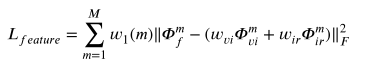
Aquí M es el número de escalas múltiples, w es un parámetro, w1 es un parámetro utilizado para ajustar el peso de la información de las características de diferentes escalas, wvi y wir son parámetros utilizados para ajustar el peso de la información de las características de la imagen visual y de la imagen infrarroja, respectivamente. . En Lfeature, principalmente queremos conservar las características infrarrojas, por lo que wvi suele ser más pequeño que wir.
Echemos un vistazo a la función de pérdida. Intuitivamente, la función de pérdida espera que la suma de las características fusionadas y las características visuales ponderadas y las características infrarrojas sea lo más consistente posible. ¿A qué se debe esto?
Permítanme hablar sobre mi propio entendimiento: aquí debemos revisar el entrenamiento del codificador automático, donde eliminamos la estructura RFN, lo que significa que las características extraídas se utilizan directamente como entrada del decodificador para reconstruir la imagen, y cuando RFN es agregado, la imagen reconstruida toma las características de fusión como entrada. En este momento, si las características de fusión son similares a las características infrarrojas, ¿significa que la imagen generada por el decodificador debe ser lo más similar posible a la imagen infrarroja, lo que logra Nuestro objetivo El objetivo es retener la información de la imagen infrarroja tanto como sea posible.
Entonces, ¿wvi puede tomar 0? ¿Es mejor cuando wvi es igual a 0?
No, porque Ldetail y Lfeature entran en conflicto cuando Wvi es 0, lo que hará que la red no converja. Entonces, ¿por qué hay un conflicto? Cuando Wvi es 0, es decir, esperamos que las características fusionadas sean lo más similares posible a las características infrarrojas, de modo que la imagen generada por el decodificador sea similar a la imagen infrarroja. similar a la función de pérdida Ldetai anterior que espera generar una imagen Detalles conflictivos en múltiples imágenes visibles.
experimento
Después de muchos experimentos, finalmente se determinó que wir=6,0, wvi=3,0, a=700
Al mismo tiempo, también confirmó la superioridad del entrenamiento de dos etapas en comparación con el entrenamiento de una etapa y la necesidad de la red nido. El contenido experimental específico se puede leer en el texto original, por lo que no entraré en detalles aquí.
Resumen personal
En comparación con DenseFuse, tanto el codificador, como el decodificador y la estrategia de fusión son mucho más complejos.
- El codificador ya no utiliza la extracción de características de una sola escala, sino que utiliza la extracción de características de múltiples escalas.
- El decodificador ya no es una simple acumulación de CNN multicapa, sino que utiliza una estructura de conexión anidada para procesar características de múltiples escalas para generar una imagen fusionada.
- La estrategia de fusión ya no utiliza un diseño manual simple, sino que utiliza redes neuronales para fusionar información de características.
- En términos de función de pérdida, se propone una nueva función de pérdida para garantizar que RFN tenga un buen efecto de fusión de características.
referencia
[1] RFN-Nest: una red de fusión residual de extremo a extremo para imágenes visibles e infrarrojas