Оглавление
2. Импортируйте связанные библиотеки.
3. Предварительная обработка данных
2. Постройте возрастную последовательность
Способ 1: Обработка последовательностей Series.agg (функция обработки)
Способ 2. Реализуйте группировку с помощью функции pd.cut().
3. Подсчитайте количество людей каждой возрастной группы.
4. Преобразование типов данных
Предисловие
В этой статье анализируются данные пользователей данных авиакомпаний, чтобы получить возраст и возрастное распределение пользователей авиакомпаний.
Сначала выполните предварительную обработку данных о возрасте пользователей авиакомпаний, а затем используйте графики для построения розовой диаграммы возрастного распределения пользователей авиакомпаний.
1. Пьечарты
1. Обобщение
Echarts — это средство визуализации данных с открытым исходным кодом от Baidu. Оно признано многими разработчиками за хорошую интерактивность и изысканный дизайн диаграмм. Python — выразительный язык, очень подходящий для обработки данных. Когда анализ данных сочетается с их визуализацией, появились диаграммы pyecharts .
2. Характеристики
- Простой дизайн API, плавное использование, поддержка цепных вызовов
- Содержит более 30 общих диаграмм — все, что вам нужно.
- Поддерживает основные среды Notebook, Jupyter Notebook и JupyterLab.
- Может быть легко интегрирован в основные веб-фреймворки, такие как Flask, Django и т. д.
- Очень гибкие элементы конфигурации могут легко сочетаться с красивыми диаграммами.
- Подробная документация и примеры помогают разработчикам быстрее приступить к работе над проектами.
- Более 400 файлов карт и собственные карты Baidu обеспечивают надежную поддержку визуализации географических данных.
3. Установка
Найдите приглашение anaconda в Windows и запустите следующий код:
pip установить pyecharts
Или воспользуйтесь загрузкой зеркала Tsinghua (рекомендуется использовать это):
pip install pyecharts -i https://pypi.tuna.tsinghua.edu.cn/simple
4.Официальный сайт
документ
Содержит введение в различные функции и графику в диаграммах, а также анализ параметров кода.
https://pyecharts.org/#/zh-cn/intro
Сообщество
Содержит коды проектов и демонстрации различных графических демонстраций.
https://gallery.pyecharts.org/#/README
2. Импортируйте связанные библиотеки.
-
Первая строка кода
from pyecharts import options as opts— импортировать модуль параметров в библиотеку pyecharts и присвоить ему псевдоним в качестве параметров. Модуль параметров содержит различные элементы конфигурации для рисования, такие как установка размера шрифта метки оси X, необходимость включения плавные изгибы и т. д. -
Вторая строка кода
from pyecharts.charts import Pieимпортирует модуль Pie в библиотеку pyecharts. Модуль Pie обеспечивает функцию рисования круговых диаграмм. -
Третья строка кода
from pyecharts.faker import Fakerимпортирует модуль фейкера в библиотеку pyecharts. Модуль фейкера используется для генерации фейковых данных. Этот модуль может предоставить некоторые тестовые данные, когда данных недостаточно. -
Четвертая строка кода
import pandas as pdимпортирует библиотеку pandas и присваивает ей псевдоним pd. Библиотека pandas — важная библиотека для анализа данных. Она предоставляет различные инструменты обработки и манипулирования данными, такие как DataFrame и т. д. Это может быть для таких операций, как чтение файлов данных или выполнение очистки и обработки данных, требующих использования библиотеки pandas.
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
import pandas as pd3. Предварительная обработка данных
1.Чтение данных
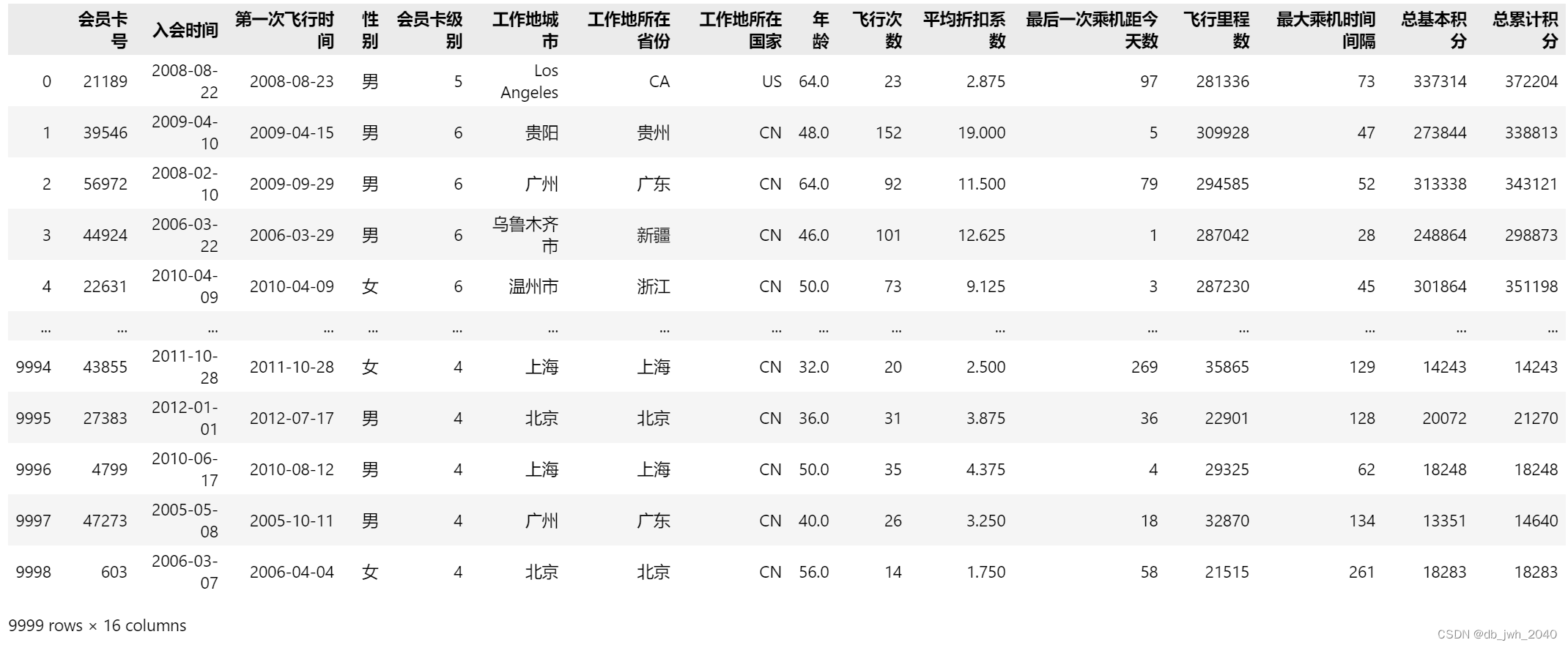
Этот код считывает файл Excel с именем «AirlineData.xlsx» и сохраняет данные в data объекте DataFrame pandas с именем. Этот объект DataFrame можно просматривать и обрабатывать как таблицу Excel. Если вы data добавите его в конце кода при печати объекта print, он выведет все содержимое объекта DataFrame. Если он не добавлен print, Jupyter Notebook по умолчанию отобразит первые пять строк данных объекта DataFrame, а последующие строки будут опущены. Вы можете использовать data.head(n) для просмотра n данных предыдущей строки или использовать data.tail(n) для просмотра данных n последующей строки .
data = pd.read_excel(r'航空公司数据.xlsx')
dataрезультат операции:
2. Постройте возрастную последовательность
Способ 1: Обработка последовательностей Series.agg (функция обработки)
Этот код определяет age_range вызываемую функцию, функция которой заключается в возврате возрастной группы, к которой принадлежит этот возраст, на основе переданного параметра возраста.
Следующая строка кода data['年龄段'] = data['年龄'].agg(age_range) означает передачу столбца «возраст» в DataFrame age_range в функцию и сохранение возвращаемого значения в новом столбце «возраст».
Окончательное data представление выводит обработанные необработанные данные dataс новым столбцом «возрастная группа», используемым для указания, к какой возрастной группе принадлежит каждый человек.
def age_range(age):
if age<20:
return '少年'
elif age<40:
return '青年'
elif age<60:
return '中年'
else:
return '老年'
data['年龄段'] = data['年龄'].agg(age_range)
dataСпособ 2. Реализуйте группировку с помощью функции pd.cut().
Этот код использует функцию библиотеки pandas cut() для разделения столбца «возраст» на 4 группы в соответствии с заданной группировкой.Правила группировки сгруппированы по 0–20, 20–40, 40–60, 60–100 и каждому группа соответствует обозначенному подростку, молодому человеку, среднему возрасту, пожилому человеку. В частности, эта функция группирует серию или массив в указанные интервалы и указывает соответствующую метку или категорию для каждого интервала.
Среди них binsпараметр представляет собой список интервалов группировки, а labelsпараметр — это метка, соответствующая каждому интервалу, data['年龄'] которая относится к операции группировки в столбце «возраст». Наконец, результат присваивается новому столбцу «возрастная группа», то есть data['年龄段']указывающему, к какой возрастной группе принадлежит каждый человек.
data['年龄段'] = pd.cut(data['年龄'],bins=[0,20,40,60,100],labels=['少年','青年','中年','老年'])
data результат операции: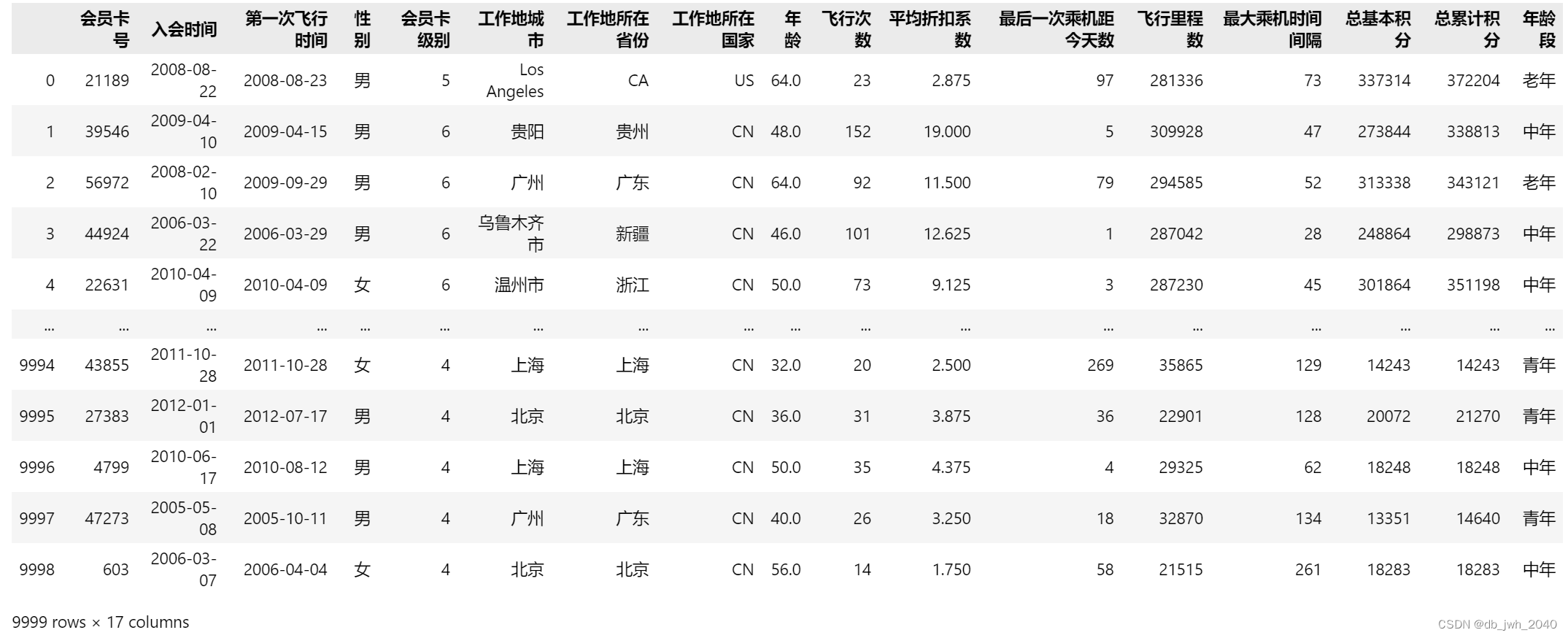
3. Подсчитайте количество людей каждой возрастной группы.
Этот код использует метод библиотеки pandas groupby() для группировки столбца «возрастная группа», а затем подсчитывает количество каждой возрастной группы. by='年龄段' Указывает группировку по столбцу «возраст» и возвращает количество столбцов «возраст» в каждой группе.
Следующим шагом ['年龄'].count() является выполнение операции подсчета в сгруппированном столбце «возраст» и подсчет количества значений в столбце «возраст» в каждой возрастной группе. Наконец, сохраните результат в result переменной и выведите результат.
result = data.groupby(by='年龄段')['年龄'].count()
resultрезультат операции:

4. Преобразование типов данных
Этот код создает list список с именем и result преобразует значение счетчика, соответствующее каждой возрастной группе, в элементы списка, проходя по объекту. В частности, понимание списка в коде [x,int(y)] for x,y in zip(result.index, result.values)] перебирает result индексы и значения объектов, упаковывая соответствующие им возрастные группы и значения счетчика в кортеж, где x представляет возрастную группу и yпредставляет значение счетчика.
При упаковке кортежей в список int() преобразуйте тип значения счетчика в целочисленный тип, чтобы избежать ошибок при последующей обработке. В конечном итоге каждый элемент в этом списке представляет собой список, в котором первый элемент — это возрастная группа, а второй элемент — значение счетчика для этой возрастной группы.
list = [[x,int(y)] for x,y in zip(result.index, result.values)]
list результат операции: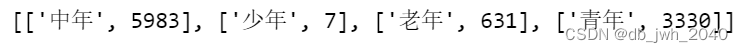
4. Рисование
роза диаграмма
Судя по круговой диаграмме, радиус каждой круговой диаграммы представляет размер данных области.
код карты розы
Этот код использует библиотеку pyecharts для рисования розовой диаграммы. Источником данных является ранее обработанная возрастная группа и соответствующий ей список значений количества list.
Сначала задайте ширину и высоту области рисования Pie() с помощью метода . InitOpts()Затем add() добавьте серию, используя метод Ages, и укажите data_pair аргумент в качестве ранее выведенного списка list . radius Параметры определяют внутренний и внешний диаметр розовой диаграммы. Здесь он установлен от «20%» до «40%», то есть между 20-м и 40-м процентилями центра, что указывает на то, что полая кольцеобразная роза схема нарисована..
Затем используйте LabelOpts() метод для форматирования метки, включая переименование имени данных в «Возраст» и установку формата содержимого метки «{a}: {b}\nЧисло: {c}\nПропорция: {d} %» означает вывод возрастная группа и соответствующее ей значение и пропорция на этикетке.
Наконец, используйте set_colors() метод для установки цветовой схемы розовой диаграммы, используйте set_global_opts() метод для установки глобальных параметров диаграммы, включая настройку основного заголовка title, стиля легенды legend_optsи положения значка, а затем вызовите render_notebook() метод для визуализации диаграммы и отображения. это в Jupyter Notebook.
c = (
Pie(init_opts=opts.InitOpts(width="600px", height="400px")) # 设置背景的大小
.add(
series_name = "年龄段", # 必须项
data_pair = list,
radius=["20%", "40%"], # 设置环的大小
# center=["20%", "50%"], # 设置饼图的位置
rosetype="radius", # 设置玫瑰图类型
label_opts=opts.LabelOpts(formatter="{a}:{b}\n个数:{c}\n占比:{d}%"), # 设置标签内容格式
)
.set_colors(["blue", "green", "yellow", "red"]) # 颜色设置
.set_global_opts(title_opts=opts.TitleOpts(title="Pie-玫瑰图示例"),
legend_opts=opts.LegendOpts(pos_top="10%", pos_left="25%"), # 设置图示的位置
)
)
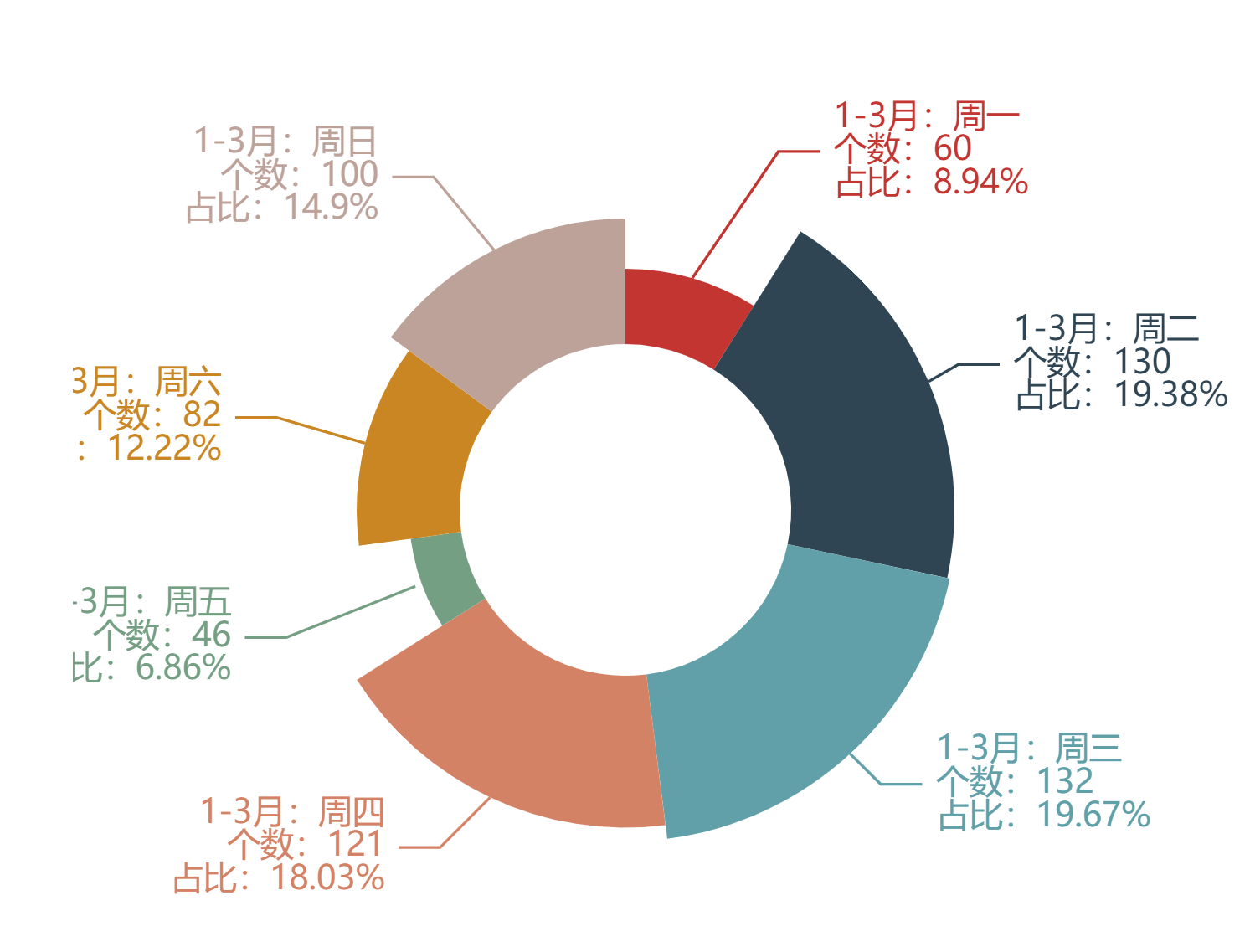
c.render_notebook()результат операции:
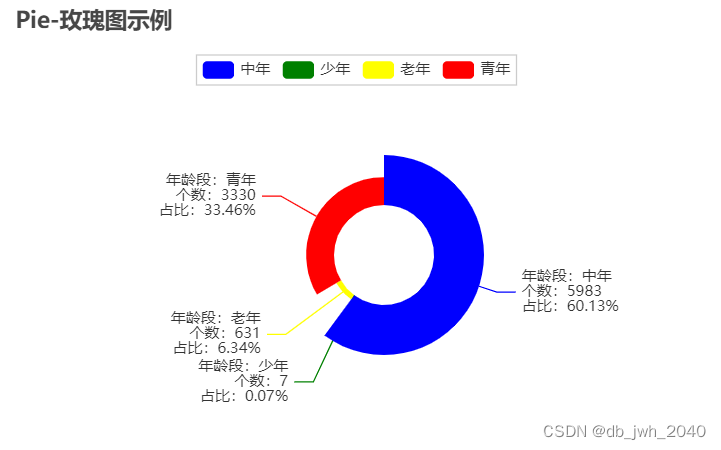
Из розы-диаграммы видно, что люди среднего возраста составляют до 60% пользователей авиакомпаний, а подростки составляют менее одного процента пользователей авиакомпаний.
5. Полный код
# 导入必要的库
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
import pandas as pd
# 读取文件数据
data = pd.read_excel(r'航空公司数据.xlsx')
# 构造年龄段序列
# 方法1:序列的加工 Series.agg(加工函数)
# def age_range(age):
# if age<20:
# return '少年'
# elif age<40:
# return '青年'
# elif age<60:
# return '中年'
# else:
# return '老年'
# data['年龄段'] = data['年龄'].agg(age_range)
# 方法2:通过pd.cut()函数实现分箱
data['年龄段'] = pd.cut(data['年龄'],bins=[0,20,40,60,100],labels=['少年','青年','中年','老年'])
# 统计各年龄段人数
result = data.groupby(by='年龄段')['年龄'].count()
# 数据类型改造
list = [[x,int(y)] for x,y in zip(result.index, result.values)]
# 画图
c = (
Pie(init_opts=opts.InitOpts(width="600px", height="400px")) # 设置背景的大小
.add(
series_name = "年龄段", # 必须项
data_pair = list,
radius=["20%", "40%"], # 设置环的大小
# center=["20%", "50%"], # 设置饼图的位置
rosetype="radius", # 设置玫瑰图类型
label_opts=opts.LabelOpts(formatter="{a}:{b}\n个数:{c}\n占比:{d}%"), # 设置标签内容格式
)
.set_colors(["blue", "green", "yellow", "red"]) # 颜色设置
.set_global_opts(title_opts=opts.TitleOpts(title="Pie-玫瑰图示例"),
legend_opts=opts.LegendOpts(pos_top="10%", pos_left="25%"), # 设置图示的位置
)
)
c.render_notebook()Подведем итог
Выше я расскажу сегодня. В этой статье лишь кратко представлен метод реализации использования Pyecharts для реализации розовой диаграммы возрастного распределения пользователей авиакомпаний. Pyecharts предоставляет большое количество уникальных диаграмм и очень гибких элементов конфигурации, которые можно легко изменить. сопоставляются для создания красивой диаграммы.