Original | Text von BFT Robot

„PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding“ ist eine Forschungsarbeit auf dem Gebiet des Verständnisses von 3D-Punktwolkendaten. Ziel ist es, eine unbeaufsichtigte Vortrainingsmethode vorzuschlagen, um das Verständnis von 3D-Punktwolkendaten zu verbessern.
01
Hintergrund
Bei 3D-Punktwolkendaten handelt es sich um Daten, die von Sensoren wie Lidar- oder Kamera-Arrays erfasst werden und zur Darstellung von Objekten und Umgebungen im dreidimensionalen Raum verwendet werden. Diese Daten finden vielfältige Anwendungsmöglichkeiten in Bereichen wie autonomes Fahren, Roboternavigation, Building Information Modeling (BIM), Virtual Reality und Augmented Reality. Allerdings ist die Verarbeitung und das Verständnis von 3D-Punktwolkendaten eine komplexe Aufgabe. 3D-Punktwolkendaten sind von Sensoren gesammelte Daten zur Darstellung der dreidimensionalen Umgebung und werden häufig in Anwendungen wie autonomem Fahren, Roboternavigation und virtueller Realität verwendet. Allerdings ist die Verarbeitung und das Verständnis von 3D-Punktwolkendaten eine Herausforderung, da diese Daten normalerweise spärlich und ungeordnet sind und nur über begrenzte Anmerkungsdaten verfügen. PointContrast ist eine unbeaufsichtigte Vortrainingsmethode, die die Leistung fortgeschrittener Szenenverständnisaufgaben erheblich verbessern kann. Durch das Vortraining unter Verwendung einer einheitlichen Architektur, Quelldatensätzen und Kontrastverlusten erzielt PointContrast beeindruckende Segmentierungs- und Erkennungsergebnisse für eine Vielzahl von realen und synthetischen Datensätzen im Innen- und Außenbereich.
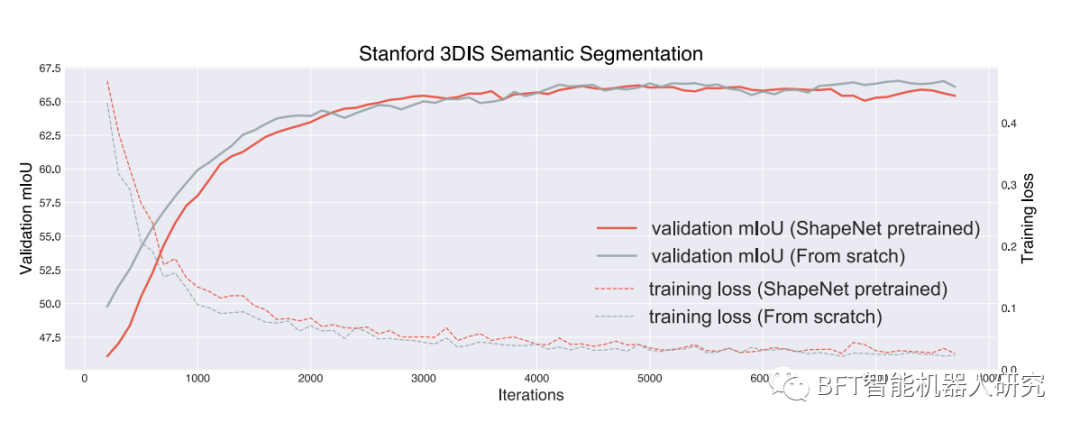
Abbildung 1 Feinabstimmung mit vorab trainierten ShapeNet-Gewichten
02
Arbeitsinhalt
Zu den Neuerungen und Arbeitsinhalten der Arbeit „PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding“ gehören folgende Aspekte:
1. Unbeaufsichtigte Vortrainingsmethode: In diesem Artikel wird eine unbeaufsichtigte Vortrainingsmethode für das Verständnis von 3D-Punktwolkendaten vorgestellt. Diese Methode basiert auf der Idee von Autoencodern und lernt nützliche Merkmalsdarstellungen durch Vorabtraining an großen, unbeschrifteten Punktwolkendaten. Dies ist eine innovative Arbeit, da die meisten 3D-Punktwolkenaufgaben normalerweise auf beschrifteten Daten basieren und PointContrast eine Alternative zum unbeaufsichtigten Lernen bietet und so den Anwendungsbereich erweitert.
2. Kontrastverlustfunktion: Das Papier führt eine Kontrastverlustfunktion ein, um die Leistung des Encoders während des Vortrainingsprozesses zu messen. Diese Verlustfunktion trägt dazu bei, dass der Encoder ähnliche Punktwolkendaten ähnlichen Feature-Darstellungen zuordnet und so die semantischen Informationen der Features verbessert. Die Nutzung dieses Kontrastverlustes ist eine der wichtigen Neuerungen dieser Methode.
3. Transferlernen und Feinabstimmung: Der Artikel betont die Transferlern- und Feinabstimmungsfähigkeiten des vorab trainierten Modells für verschiedene 3D-Punktwolkenaufgaben. Durch die Übertragung erlernter Merkmalsdarstellungen auf bestimmte Aufgaben kann die Leistung erheblich verbessert werden, ohne dass große Mengen an beschrifteten Daten erforderlich sind.
4. Breites Anwendungsspektrum: Zu den vielfältigen Anwendungsfeldern dieser Methode gehören autonomes Fahren, Roboternavigation, Virtual Reality, Augmented Reality usw. Dies macht die Methode für ein breites Spektrum praktischer Anwendungen vielversprechend und dürfte die damit verbundenen Aufgaben in diesen Bereichen verbessern.
In diesem Artikel wird auf innovative Weise eine unbeaufsichtigte Vortrainingsmethode vorgeschlagen, mit der die Merkmalsdarstellung von 3D-Punktwolkendaten verbessert und dadurch die Leistung und Effektivität von Aufgaben in verschiedenen Anwendungsbereichen verbessert werden kann. Die kontrastiven Verlust- und Transferlernideen dieser Methode eröffnen neue Forschungsrichtungen im Bereich des Verständnisses von 3D-Punktwolkendaten.
03
Einführung in den Algorithmus
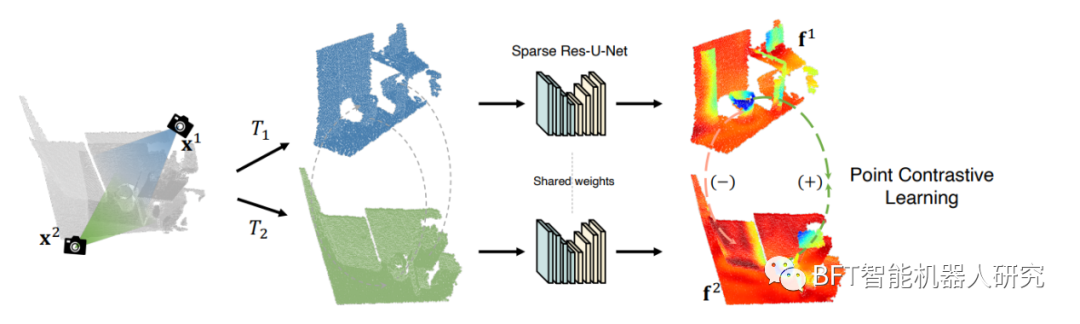
Abbildung 2 3D-Vorschulungsaufgaben
Der Algorithmus im Artikel ist eine Methode für unbeaufsichtigtes Vortraining, die darauf abzielt, die Merkmalsdarstellung von 3D-Punktwolkendaten zu verbessern. Im Folgenden sind die Hauptschritte des Algorithmus aufgeführt:
1. Datenvorverarbeitung: Zunächst werden die ursprünglichen dreidimensionalen Punktwolkendaten vorverarbeitet, um sie auf eine feste Anzahl von Punkten zu normalisieren oder in eine feste Anzahl von Stichprobenpunktwolken abzutasten. Dadurch wird sichergestellt, dass die Eingabepunktwolke für die Kodierung und Dekodierung die gleichen Abmessungen aufweist.
2. Encoder: Der Encoder ist Teil des neuronalen Netzwerkmodells. Er akzeptiert Punktwolkendaten als Eingabe und codiert sie in einen niedrigdimensionalen Merkmalsvektor. Dieser Merkmalsvektor ist eine abstrakte Darstellung der Punktwolkendaten und sollte wichtige Informationen der Punktwolke erfassen. Die Ausgabe des Encoders ist ein Merkmalsvektor.
3. Decoder: Der Decoder ist ebenfalls Teil des neuronalen Netzwerkmodells. Er akzeptiert den vom Encoder generierten Merkmalsvektor als Eingabe und versucht, ihn in einer Punktwolke mit derselben Struktur wie die ursprünglichen Punktwolkendaten wiederherzustellen. Die Ausgabe des Decoders sind rekonstruierte Punktwolkendaten.
5. Kontrastverlust: Der Kontrastverlust ist der Kernbestandteil dieser Methode. Sein Ziel besteht darin, sicherzustellen, dass ähnliche Punktwolkendaten ähnliche Darstellungen im Merkmalsraum haben, während unterschiedliche Punktwolkendaten deutlich unterschiedliche Darstellungen im Merkmalsraum haben. Insbesondere misst der Kontrastverlust die Ähnlichkeit zwischen zwei Proben, sodass der Abstand der Merkmalsdarstellung zwischen ähnlichen Proben geringer und der Abstand zwischen unterschiedlichen Proben weiter entfernt ist.
Trainingsprozess: Während des Trainingsprozesses werden die Parameter des Encoders und Decoders optimiert, indem der Kontrastverlust minimiert wird. Auf diese Weise wird der Encoder darauf trainiert, Punktwolkendaten in aussagekräftige Merkmalsdarstellungen zu codieren, und der Decoder wird darauf trainiert, die ursprünglichen Punktwolkendaten so weit wie möglich wiederherzustellen.
Feinabstimmung und Transferlernen: Nach Abschluss des Trainings kann der Encoderteil als vorab trainierter Feature-Extraktor verwendet werden, und Feinabstimmung oder Transferlernen können für bestimmte 3D-Punktwolkenaufgaben durchgeführt werden. Dadurch können vorab trainierte Merkmalsdarstellungen zur Lösung verschiedener Punktwolkenaufgaben wie Zielerkennung, semantische Segmentierung, Objekterkennung usw. verwendet werden.
Zusammenfassend lässt sich sagen, dass dieser Algorithmus durch unbeaufsichtigtes Vortraining nützliche Merkmalsdarstellungen für 3D-Punktwolkendaten lernt, wobei der Kontrastverlust eine Schlüsselrolle spielt, um sicherzustellen, dass die vom Encoder generierten Merkmale die Ähnlichkeiten und Unterschiede der Punktwolkendaten effektiv kodieren. Es wird erwartet, dass diese Vortrainingsmethode die Leistung von Aufgaben im Bereich des Verständnisses von 3D-Punktwolkendaten verbessert.
04
Experimentelle Diskussion
Im experimentellen Teil dieses Artikels werden hauptsächlich die experimentellen Ergebnisse von PointContrast für mehrere reale und synthetische Datensätze im Innen- und Außenbereich vorgestellt, einschließlich Segmentierungs- und Erkennungsaufgaben. Das Folgende ist eine kurze Einführung in den experimentellen Teil:
1. Datensatz: Das Experiment verwendete mehrere öffentliche Datensätze, darunter S3DIS, ScanNet, Semantic3D, KITTI und ModelNet40 usw. Diese Datensätze decken verschiedene Szenarien und Aufgaben ab, sodass die Leistung von PointContrast in verschiedenen Situationen bewertet werden kann.
2. Experimentelle Einstellungen: Das Experiment verwendete zwei Bewertungsindikatoren, nämlich die durchschnittliche Präzision (mAP) und das durchschnittliche Schnittpunkt-zu-Union-Verhältnis (mIoU). Für Segmentierungsaufgaben wird PointNet++ als Basismethode verwendet; für Erkennungsaufgaben wird VoteNet als Basismethode verwendet.
3. Experimentelle Ergebnisse: Experimentelle Ergebnisse zeigen, dass PointContrast bei mehreren Datensätzen beeindruckende Ergebnisse erzielt und die besten vorhandenen Methoden übertrifft. Im S3DIS-Datensatz beispielsweise übertrifft der mIoU-Wert von PointContrast mit 65,5 % die beste vorhandene Methode (63,7 %). Im ScanNet-Datensatz beträgt der mAP-Wert von PointContrast 68,3 % und übertrifft damit die beste vorhandene Methode (65,5 %).
Zusammenfassend zeigen die experimentellen Ergebnisse, dass PointContrast ein wirksames unbeaufsichtigtes Pre-Training-Framework ist, das die Leistung von 3D-Punktwolken-Verständnisaufgaben erheblich verbessern kann.
05
abschließend
In diesem Artikel wird PointContrast vorgeschlagen, ein unbeaufsichtigtes Pre-Training-Framework für 3D-Punktwolken, das die Leistung fortgeschrittener Szenenverständnisaufgaben verbessern kann. Durch den Einsatz von Techniken wie lokal-globalen Kontrastverlustfunktionen und zufälliger Punktstichprobe kann PointContrast bessere Punktwolkendarstellungen erlernen und beeindruckende Ergebnisse bei mehreren Datensätzen erzielen.
Der in diesem Artikel vorgeschlagene PointContrast-Algorithmus bietet eine neue unbeaufsichtigte Vortrainingsmethode für Aufgaben zum Verständnis von 3D-Punktwolken und weist einen hohen praktischen Wert und Anwendungsaussichten auf.
Autor | Azukii
Satz | Xiaohe
Rezension | Orange
Wenn Sie Fragen zum Inhalt dieses Artikels haben, kontaktieren Sie uns bitte und wir werden umgehend antworten. Wenn Sie weitere aktuelle Informationen erhalten möchten, denken Sie daran, ~ zu liken und zu folgen