Kontextuelle Voreingenommenheit zielt darauf ab, kontextuelles Wissen in Spracherkennungssysteme (ASR) zu integrieren, um die Erkennungsgenauigkeit von Wörtern in verwandten Bereichen (allgemein bekannt als „ Hot Words “) zu verbessern. In vielen ASR-Szenarien kann die zu erkennende Sprache Phrasen enthalten, die selten oder nicht in den Trainingsdaten vorkommen, wie etwa einige domänenspezifische Substantive, Namen im Adressbuch des Benutzers usw. Die Genauigkeit der Erkennung dieser Phrasen hat zugenommen eine große Auswirkung auf das Benutzererlebnis. Oder die Auswirkung auf nachgelagerte Aufgaben ist groß, lässt sich aber für das Training von ASR-Systemen auf Allzweckdaten nur schwer vollständig richtig identifizieren. Daher ist die Kontext-Bias-Methode von großem Wert, die darauf abzielt, die Erkennungsgenauigkeit dieser „heißen Wörter“ zu verbessern.
Die Audio and Speech Processing Research Group der NPU (ASLP@NPU) hat kürzlich auf der führenden Sprachforschungskonferenz INTERSPEECH2023 einen Artikel mit dem Titel „Contextualized End-to-End Speech Recognition with Contextual Phrase Prediction Network“ veröffentlicht. In diesem Artikel wird eine Deep-Hot-Word-Verbesserungsmethode vorgeschlagen , die auf einem Netzwerk zur Vorhersage von Hot-Word-Phrasen basiert, das Hot-Word-Codierung verwendet, um Hot-Wörter in der Sprache vorherzusagen, und das Training von Deep-Bias-Modellen durch die Berechnung von Bias-Verlusten unterstützt. Die vorgeschlagene Methode kann auf eine Vielzahl gängiger End-to-End-ASR-Modelle angewendet werden, wodurch die Erkennungsgenauigkeit des Modells für Hot-Word-Daten erheblich verbessert wird.
Der Code dieser Lösung wurde hauptsächlich von Huang Kaixun, dem ersten Autor des Papiers, fertiggestellt. Er ist jetzt Open Source in der WeNet-Community. Einzelheiten finden Sie unter: https://github.com/wenet-e2e/wenet/pull/ 1982
Regelbasierte Hot-Word-Verbesserung
Die zuvor von WeNet implementierte Hot-Word-Lösung ist eine regelbasierte Hot-Word-Verbesserung, d Heiße Wörter haben eine größere Wahrscheinlichkeit und sind präziser. Leicht zu erkennen. Einzelheiten finden Sie unter:
WeNet Hot Word Enhancement 2.0 kommt
WeNet-Update: Unterstützt Hot-Word-Erweiterung
Obwohl diese Lösung unter normalen Umständen über gute Verarbeitungsfähigkeiten verfügen kann, ist der Erkennungseffekt bei seltenen oder im Training unsichtbaren Wörtern sehr gering. Im Wesentlichen handelt es sich bei dieser Methode um eine Hot-Word-Lösung mit flacher Fusion (Schattenfusion oder Postfusion), die während des Trainings nicht gesehen wurde und schwer vorherzusagen ist. Sie erscheint überhaupt nicht in den Dekodierungskandidatenpfaden, daher gibt es keine große Belohnung wird helfen. Die im Folgenden vorgestellten Hotwords des neuronalen Netzwerks sind Deep Fusion (oder Pre-Fusion), die das Problem seltener Wörter sehr effektiv lösen können und auch bessere Ergebnisse bei der Erkennung allgemeiner Hotwords erzielen.
Hot-Word-Verbesserung durch neuronale Netze
Die auf einem neuronalen Netzwerk basierende Hot-Word-Verbesserung führt eine Reihe unabhängiger Bias-Module in das End-to-End-ASR-Modell ein, um Hot-Word-Informationen zu modellieren und zu integrieren, und ordnet den Prozess der Hot-Word-Verbesserung in den Prozess der Inferenz des neuronalen Netzwerkmodells ein. Im Vergleich zu herkömmlichen Hot-Word-Verbesserungsschemata, die auf Decodierungskarten basieren, ist die Hot-Word-Verbesserung mit neuronalen Netzwerken sehr flexibel einsetzbar. Sie kann für kleinere Hot-Word-Listen bessere Ergebnisse erzielen als das Decodierungskarten-Verbesserungsschema und auch bessere Ergebnisse als die Dekodierungskartenverbesserungsschema für Wörter, die noch nie im Trainingssatz erschienen sind. Seltene Wörter haben auch gute Verstärkungseffekte.
In den letzten Jahren haben sich Methoden zur Hot-Word-Verbesserung neuronaler Netze rasant weiterentwickelt. Im Jahr 2018 schlug Google erstmals das CLAS-Modell vor [2], das Hot-Word-Informationen über ein vollständiges neuronales Netzwerk in das LAS-Modell integriert. Die Modellstruktur von CLAS ist in der folgenden Abbildung dargestellt. Die beiden enthaltenen Bias-Module sind:
-
Hot-Word-Encoder (Bias-Encoder): Codieren Sie Hot-Word-Informationen über RNN und codieren Sie Hot-Words ungleicher Länge in Hot-Word-Einbettungen derselben Dimension.
-
Hot-Word-Bias-Schicht (Aufmerksamkeit): Enthält eine Multi-Head-Aufmerksamkeitsschicht, verwendet die Audio-Codierung als Abfrage, die Hot-Word-Codierung als Schlüssel und Wert, fragt Hot-Words ab, die sich auf das aktuelle Audio beziehen, und extrahiert die Hot-Word-bewusste Codierung.
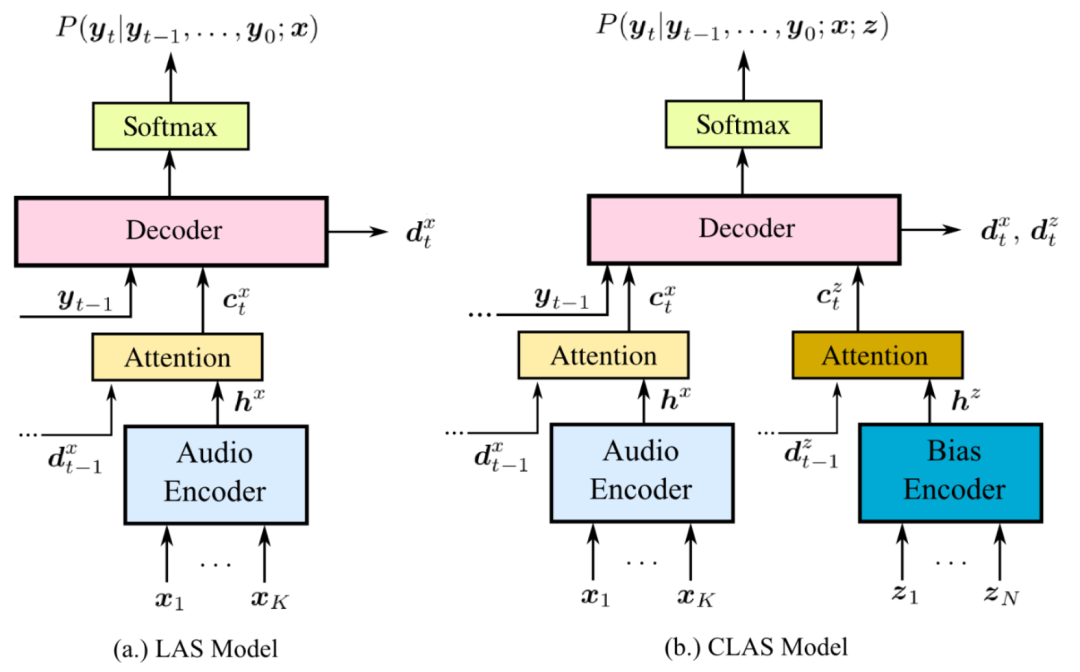
Die anschließende Forschung zur Hot-Word-Verbesserung neuronaler Netze folgte im Wesentlichen CLAS und war in zwei Schritte unterteilt: Kodierung von Hot-Words, Abfrage audiobezogener Hot-Words und Integration von Informationen. Für andere ASR-Modelle wurden Hot-Word-Enhancement-Modelle für neuronale Netzwerke vorgeschlagen, die für RNNT-Modelle [3] und CIF-Modelle [4] geeignet sind. Es wurden auch viele Varianten von Methoden zur Verbesserung neuronaler Netzwerke erstellt, z. B. TCPGen [5] und NAM [6]. ] Warten.
Einführung in das CPPN-Papier
Frühere Forschungen zur Hot-Word-Verstärkung mit neuronalen Netzen untersuchten hauptsächlich das Erreichen oder Verbessern der Wirkung der Hot-Word-Verstärkung bei ASR-Modellen wie RNNT, es fehlte jedoch eine wirksame Methode zur Hot-Word-Verstärkung mit reinen neuronalen Netzwerken beim AED-Modell. Daher besteht unsere anfängliche Motivation darin, ein wirksames Hot-Word-Enhancement-Schema für neuronale Netze im AED-Modell zu finden. Da wir das WeNet-Framework für Experimente verwenden und auf den Merkmalen der Aufmerksamkeits-Rescore-Dekodierung basierend auf CTC posterior basieren, hoffen wir, dies zu können Führen Sie ein neuronales Netzwerk im Encoder-Teil durch. Verbesserung von Internet-Hotwords.
In der Anfangsphase des Experiments haben wir versucht, dem Encoder des AED-Modells für das Training ein grundlegendes Hot-Word-Verbesserungsmodul einschließlich eines Hot-Word-Encoders und einer Hot-Word-Bias-Schicht hinzuzufügen, aber das Modell hat die Fähigkeit zur Hot-Word-Verbesserung nicht gelernt Wörter überhaupt. Argumentation Das Hinzufügen von Informationen zu wichtigen Wörtern während des Prozesses hat fast keine Auswirkungen auf die Ergebnisse. Unsere Analyse legt nahe, dass dies wahrscheinlich auf die Tatsache zurückzuführen ist, dass es beim AED-Modell für das Hot-Word-Enhancement-Modul schwieriger ist, den Zusammenhang zwischen Hot-Word-Codierung und Audio-Codierung zu lernen. Wenn Sie sich beim Training nur auf die Verlustfunktion von ASR verlassen und die Aufgabe zur Hot-Word-Verbesserung nicht explizit überwachen, tendiert das Modell dazu, die Ausgabe des Hot-Word-Verbesserungsmoduls direkt aufzugeben. Daher hat sich der Schwerpunkt unserer Forschung auf die Suche nach einem effektiven überwachten Verlust für die Aufgabe der Verbesserung von Schlagwörtern verlagert.
Die intuitivste Idee besteht darin, das Hot-Word-Verbesserungsmodul die im Satz enthaltenen Hot-Words direkt vorhersagen zu lassen, aber die Eingabe- und Ausgabelänge des Hot-Word-Moduls entspricht der Länge der Audiokodierung, wodurch eine Lücke zwischen der Kodierungslänge entsteht und die Länge der im Satz enthaltenen Hot-Word-Phrasen. Nichtübereinstimmung. Unsere Experimente ergaben, dass der CTC-Verlust dieses Problem gut lösen kann. Da der Encoder selbst bei der Implementierung des WeNet AED-Modells auch auf den CTC-Verlust für das Hilfstraining angewiesen ist, kann die gleiche Verwendung des CTC-Verlusts bei der Vorhersage von Hot-Word-Aufgaben das Hot-Word erzeugen Erweiterungsmodul passt besser zur Ausgabe des Encoders. Auf dieser Grundlage haben wir eine Spracherkennungslösung für heiße Wörter vorgeschlagen, die auf dem Contextual Phrase Prediction Network (CPPN) basiert. Die Struktur des Hot-Word-Enhancement-Modells ist in der folgenden Abbildung dargestellt.
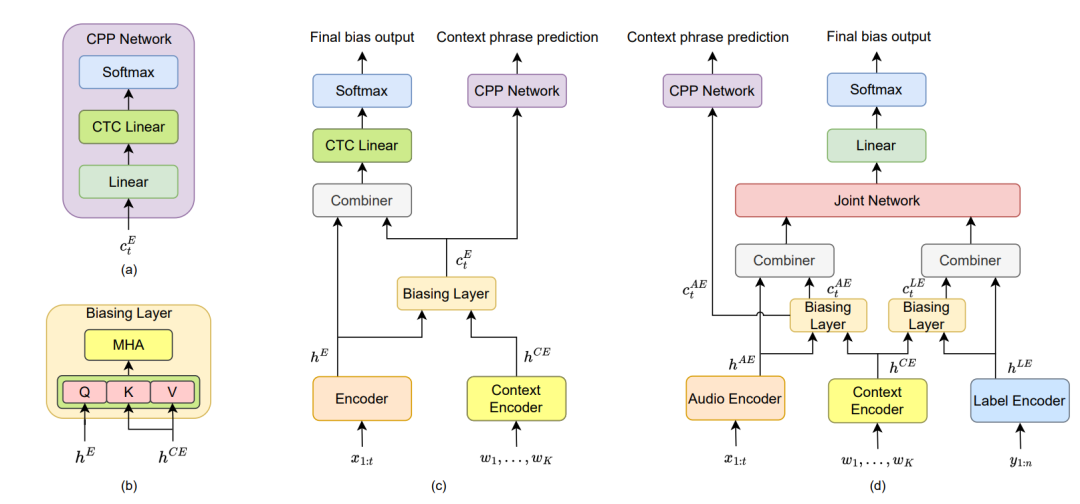
Abbildung (c) ist die Hot-Word-Enhancement-Modellstruktur, die wir basierend auf dem AED-Modell implementiert haben. Da nur der Encoder-Teil des Modells geändert wurde, wird die Struktur des Decoder-Teils nicht gezeichnet. Dieses Hot-Word-Enhancement-Schema eignet sich auch für Modelle, die nur das CTC-Modell eines Encoders enthalten. Im AED-Hot-Word-Enhancement-Modell umfassen die Module im Zusammenhang mit der Hot-Word-Enhancement:
-
Hot-Word-Encoder (Kontext-Encoder): Wir verwenden BLSTM als Hot-Word-Encoder, um Hot-Word-Phrasen zu kodieren.
-
Hot-Word-Bias-Schicht (Biasing-Schicht): Fragen Sie, wie in Abbildung (b) gezeigt, die Hot-Words ab, die sich auf das aktuelle Audio beziehen, und extrahieren Sie die Hot-Word-Wahrnehmungskodierung.
-
Combiner: Verbindet Audiocodierung und Hot-Word-Aware-Codierung und integriert Informationen über eine lineare Ebene.
-
Hot Word Phrase Prediction Network (CPP-Netzwerk): Wie in Abbildung (a) dargestellt, enthält es zwei lineare Schichten, von denen die zweite lineare Schicht Parameter mit der linearen CTC-Schicht des Encoders teilt. Das Netzwerk zur Vorhersage von Hot-Word-Phrasen verwendet Hot-Word-bewusste Codierung als Eingabe, um in Sätzen enthaltene Hot-Word-Phrasen vorherzusagen, und wird mithilfe der CTC-Verlustüberwachung trainiert. Wenn die Satzbezeichnung beispielsweise „Ich möchte an die NPU gehen, um Spracherkennung zu studieren“ lautet und „NPU“ und „Spracherkennung“ heiße Wörter sind, lautet die Bezeichnung des Netzwerks zur Vorhersage heißer Wortphrasen „NPU-Spracherkennung“.
Abbildung (d) ist die Struktur des Hot-Word-Enhancement-Modells basierend auf dem RNNT-Modell. Wir haben ein Hot-Word-Phrase-Vorhersagenetzwerk basierend auf dem Hot-Word-Enhancement-Schema CATT [7] hinzugefügt. Im Vergleich zum AED-Modell ist der Tag-Encoder ( Label Encoder) Außerdem wurde eine Hot-Word-Bias-Ebene hinzugefügt.
Das auf neuronalen Netzen basierende Hot-Word-Verbesserungsschema hat auch das Problem, dass es empfindlich auf die Größe der Hot-Word-Phrasenliste reagiert. Da das Modell auf den Aufmerksamkeitsmechanismus angewiesen ist, um Hot-Word-Phrasen zu finden, die mit dem Audio verknüpft sind, wenn die Hot-Word-Liste gegeben ist Wenn es zu groß ist, geht die Aufmerksamkeit verloren. Es wird stärker gestreut, was den Effekt der Hot-Word-Verstärkung beeinträchtigt. Daher haben wir einen zweistufigen Hot-Word-Phrasen-Screening-Algorithmus eingeführt [8]: Zuerst wird die Ausgabe des Encoderteils des Modells berechnet, ohne das Hot-Word-Enhancement-Modul zu berechnen, und der CTC-Posterior wird zur Berechnung des Posterior- und Konfidenzintervalls verwendet (PSC) bzw. SOC (Sequence Order Confidence), um die Hot-Wörter herauszufiltern, die am wahrscheinlichsten im Audio vorkommen, und dann eine kleinere Hot-Word-Liste zu erstellen und eine Hot-Word-Verbesserung mit neuronalen Netzwerken durchzuführen.
Weitere Einzelheiten zum Plan finden Sie im Tweet:
Modellimplementierung
-
Die Implementierung der meisten Hot-Word-Erweiterungsmodule befindet sich in Transformer/context_module.py. Wir deklarieren den Hot-Word-Encoder, die Hot-Word-Bias-Schicht, den Combiner, das Hot-Word-Phrasen-Vorhersagenetzwerk und den CTC der Erweiterungsaufgabe in der ContextModule-Klasse. Verlust. Im Vergleich zur Implementierung im Artikel ersetzen wir hier den Combiner durch eine einfachere Form, die über eine lineare Schicht direkt zur Audiokodierung beiträgt. Dadurch kann das ASR-Modell stärker vom Hot-Word-Modul entkoppelt werden, und dies wurde getestet grundsätzlich kein Unterschied in der Wirkung. Außerdem legen wir ein zusätzliches Gewicht zur Verbesserung von Hot-Words fest, um den Grad der Hot-Word-Verstärkung zu steuern. Die Hot-Word-Aware-Codierung wird zunächst mit diesem Gewicht multipliziert und dann zur Audio-Codierung hinzugefügt.
class ContextModule(torch.nn.Module):
"""Context module, Using context information for deep contextual bias
During the training process, the original parameters of the ASR model
are frozen, and only the parameters of context module are trained.
Args:
vocab_size (int): vocabulary size
embedding_size (int): number of ASR encoder projection units
encoder_layers (int): number of context encoder layers
attention_heads (int): number of heads in the biasing layer
"""
def __init__(
self,
vocab_size: int,
embedding_size: int,
encoder_layers: int = 2,
attention_heads: int = 4,
dropout_rate: float = 0.0,
):
super().__init__()
self.embedding_size = embedding_size
self.encoder_layers = encoder_layers
self.vocab_size = vocab_size
self.attention_heads = attention_heads
self.dropout_rate = dropout_rate
# 热词编码器
self.context_extractor = BLSTM(self.vocab_size, self.embedding_size,
self.encoder_layers)
self.context_encoder = nn.Sequential(
nn.Linear(self.embedding_size * 4, self.embedding_size),
nn.LayerNorm(self.embedding_size)
)
# 热词偏置层
self.biasing_layer = MultiHeadedAttention(
n_head=self.attention_heads,
n_feat=self.embedding_size,s
dropout_rate=self.dropout_rate
)
# 组合器
self.combiner = nn.Linear(self.embedding_size, self.embedding_size)
self.norm_aft_combiner = nn.LayerNorm(self.embedding_size)
# 热词短语预测网络
self.context_decoder = nn.Sequential(
nn.Linear(self.embedding_size, self.embedding_size),
nn.LayerNorm(self.embedding_size),
nn.ReLU(inplace=True),
)
self.context_decoder_ctc_linear = nn.Linear(self.embedding_size,
self.vocab_size)
# 热词 CTC 损失
self.bias_loss = torch.nn.CTCLoss(reduction="sum", zero_infinity=True)-
Wir haben den Code für den Hot-Word-Phrasen-Screening-Teil in /utils/context_graph.py implementiert. Diese Datei war ursprünglich für die Implementierung der Hot-Word-Verbesserung basierend auf dem Decodierungsdiagramm verantwortlich. Sie enthält Informationen über die Hot-Word-Liste, die bei der Decodierung verwendet wird Hier geeignet. Führen Sie ein Hot-Word-Phrasen-Screening durch und übergeben Sie die Hot-Word-Liste in Tensorform an das Hot-Word-Erweiterungsmodul.
class ContextGraph:
def get_context_list_tensor(self, context_list: List[List[int]]):
"""Add 0 as no-bias in the context list and obtain the tensor
form of the context list
"""
def two_stage_filtering(self,
context_list: List[List[int]],
ctc_posterior: torch.Tensor,
filter_window_size: int = 64):
"""Calculate PSC and SOC for context phrase filtering,
refer to: https://arxiv.org/abs/2301.06735
"""-
Der Code für Hot-Word-Sampling während des Trainings befindet sich in den Methoden context_sampling und context_label_generate von /dataset/processor.py. Während des Trainings wählen wir aus jeder Äußerung zufällig mehrere Phrasen zufälliger Länge als heiße Wörter der Äußerung aus. Die aus jedem Stapel extrahierten heißen Wortphrasen sowie einige Interferenzphrasen (heiße Wörter aus dem vorherigen Stapel) werden zusammen verwendet. Eine Liste heißer Wörter, aus denen der Satz besteht.
def context_sampling(data,
symbol_table,
len_min,
len_max,
utt_num_context,
batch_num_context,
):
"""Perform context sampling by randomly selecting context phrases from the
utterance to obtain a context list for the entire batch
Args:
data: Iterable[List[{key, feat, label}]]
Returns:
Iterable[List[{key, feat, label, context_list}]]
"""
def context_label_generate(label, context_list):
""" Generate context labels corresponding to the utterances based on
the context list
"""Experimentelle Ergebnisse
Wir testen mit dem Librispeech-Test einen anderen Testsatz und verwenden dabei die in [9] angegebene Hot-Word-Liste, die über diesen Link abgerufen werden kann: https://github.com/facebookresearch/fbai-speech/tree/main/is21_deep_bias
Wir haben für Experimente das vorab trainierte Open-Source-AED-Modell Librispeech von WeNet verwendet, die Parameter des ursprünglichen ASR-Modells eingefroren, nur das Hot-Word-Enhancement-Modul für 30 Epochen trainiert und als Ergebnis den über 3 Epochen gemittelten Modellwert genommen. Während des Trainings müssen Sie die Streaming-Trainingsoption use_dynamic_chunk deaktivieren. Wenn Sie diese Option aktivieren, wird der Hot-Word-Enhancement-Effekt schlechter. Das durch Testen von Nicht-Streaming-Training erhaltene Modell weist im Wesentlichen eine konsistente Leistung bei der Verbesserung von Hotwords für Nicht-Streaming und Streaming-Dekodierung auf. Das trainierte Hot-Word-Enhancement-Modell kann unter folgendem Link heruntergeladen werden: https://huggingface.co/kxhuang/Wenet_Librispeech_deep_biasing/tree/main
Zusätzlich zur Wortfehlerrate (WER) verwenden wir U-WER und B-WER, um die Wortfehlerrate des Nicht-Hot-Word-Teils bzw. des Hot-Word-Teils zu bewerten. Die experimentellen Ergebnisse sind wie folgt.
Nicht-Streaming-Begründung:
| Methode | Listengröße | Diagrammpunktzahl | Biasing-Score | WIR SIND | U-WER | B-WER |
|---|---|---|---|---|---|---|
| Grundlinie | / | / | / | 8,77 | 5.58 | 36,84 |
| Kontextdiagramm | 3838 | 3,0 | / | 7,75 | 5,83 | 24.62 |
| CPPN | 3838 | / | 1.5 | 7,93 | 5,92 | 25.64 |
| Kontextdiagramm + CPPN | 3838 | 2,0 | 1,0 | 7.66 | 6.08 | 21.48 |
| Kontextdiagramm | 100 | 3,0 | / | 7.32 | 5.45 | 23.70 |
| CPPN | 100 | / | 2,0 | 7.08 | 5.33 | 22.41 |
| Kontextdiagramm + CPPN | 100 | 2.5 | 1.5 | 6.55 | 5.33 | 17.27 |
Das Kontextdiagramm in der Tabelle stellt die Hot-Word-Verbesserungsmethode dar, die auf dem Dekodierungsdiagramm in WeNet basiert. Die kartenbasierte Dekodierungsmethode funktioniert besser, wenn eine größere Hot-Word-Liste (3838) verwendet wird, während der Verbesserungseffekt von CPPN besser ist, wenn eine kleinere Hot-Word-Liste (100) verwendet wird. Unabhängig von der Größe der Hot-Word-Liste können durch die gleichzeitige Verwendung beider Methoden mit angemessenen Verbesserungsgewichten und -werten bessere Ergebnisse erzielt werden als mit einer einzelnen Methode.
Bei einer Hot-Word-Liste (3838) funktioniert die kartenbasierte Dekodierungsmethode besser, während bei einer kleineren Hot-Word-Liste (100) der Verbesserungseffekt von CPPN besser ist. Unabhängig von der Größe der Hot-Word-Liste können durch die gleichzeitige Verwendung beider Methoden mit angemessenen Verbesserungsgewichten und -werten bessere Ergebnisse erzielt werden als mit einer einzelnen Methode.
Das kleine Experiment mit der Hot-Wort-Liste zeigte auch einen Rückgang der WER der Nicht-Hot-Wort-Teile. Dies liegt daran, dass das Modell nach der Hot-Word-Verbesserung einen Pfad auswählen kann, der die richtigen Hot-Wörter enthält und in den Nicht-Hot-Worten genauer ist Wortteile bei der Strahlsuche.
Streaming-Argumentation (Kapitel 16):
| Methode | Listengröße | Diagrammpunktzahl | Biasing-Score | WIR SIND | U-WER | B-WER |
|---|---|---|---|---|---|---|
| Grundlinie | / | / | / | 10.47 | 7.07 | 40.30 |
| Kontextdiagramm | 100 | 3,0 | / | 9.06 | 6,99 | 27.21 |
| CPPN | 100 | / | 2,0 | 8,86 | 6,87 | 26.28 |
| Kontextdiagramm + CPPN | 100 | 2.5 | 1.5 | 8.17 | 6,85 | 19.72 |
In den Ergebnissen des Streaming-Argumentation führt die Verwendung von CPPN auch zu einer signifikanten Verbesserung des B-WER, was im Wesentlichen mit dem Hot-Word-Enhancement-Effekt des nicht fließenden Reasonings übereinstimmt.
Verweise
[1] Kaixun Huang, Ao Zhang, Zhanheng Yang, Pengcheng Guo, Bingshen Mu, Tianyi Xu, Lei Xie: Kontextualisierte End-to-End-Spracherkennung mit Contextual Phrase Prediction Network. INTERSPEECH 2023
[2] Golan Pundak, Tara N. Sainath, Rohit Prabhavalkar, Anjuli Kannan, Ding Zhao: Deep Context: End-to-End kontextuelle Spracherkennung. SLT 2018
[3] Mahaveer Jain, Gil Keren, Jay Mahadeokar, Geoffrey Zweig, Florian Metze, Yatharth Saraf: Kontextuelles RNN-T für Open Domain ASR. INTERSPEECH 2020
[4] Minglun Han, Linhao Dong, Shiyu Zhou, Bo Xu: Cif-basierte kollaborative Dekodierung für eine durchgängige kontextuelle Spracherkennung. ICASSP 2021
[5] Guangzhi Sun, Chao Zhang, Philip C. Woodland: Baumbeschränkter Zeigergenerator für die kontextbezogene End-to-End-Spracherkennung. ASRU 2021
[6] Tsendsuren Munkhdalai, Khe Chai Sim, Angad Chandorkar, Fan Gao, Mason Chua, Trevor Strohman, Françoise Beaufays: Schnelle kontextuelle Anpassung mit neuronalem assoziativem Gedächtnis für die personalisierte Spracherkennung auf dem Gerät. ICASSP 2022
[7] Feng-Ju Chang, Jing Liu, Martin Radfar, Athanasius Mouchtaris, Maurizio Omologo, Aria Rastrow, Siegfried Kunzmann:
Kontextbewusster Transformatorwandler für die Spracherkennung. ASRU 2021 [8] Zhanheng Yang, Sining Sun, Xiong Wang, Yike Zhang, Long Ma, Lei Xie: Zweistufige kontextbezogene Wortfilterung für Kontextverzerrung in Unified Streaming und Non-Streaming Transducer. INTERSPEECH 2023
[9] Duc Le, Mahaveer Jain, Gil Keren, Suyoun Kim, Yangyang Shi, Jay Mahadeokar, Julian Chan, Yuan Shangguan, Christian Fuegen, Ozlem Kalinli, Yatharth Saraf, Michael L. Seltzer: Kontextualisierte Streaming-End-to-End-Spracherkennung mit Trie-basiertem Deep Biasing und Shallow Fusion. INTERSPEECH 2021