Tenga en cuenta la referencia y la fuente de la imagen: "Las matemáticas del aprendizaje profundo"
Las matemáticas del aprendizaje profundo (ituring.com.cn)

Tabla de contenido
4.1 Producto interior vectorial
4.2 Desigualdad de Cauchy-Schwarz
4.3 Representación coordinada del producto interno.
4.4 Generalización de vectores
6. Derivada (función de una sola variable)
6.2 Derivadas de funciones fraccionarias y derivadas de funciones sigmoideas
6.3 Cómo encontrar el valor mínimo
7. Derivadas parciales (funciones multivariables)
7.3 Cómo encontrar el valor mínimo
7.4 Multiplicación de números de Lagrange
8.2 Fórmula derivada de una función compuesta de una sola variable
8.3 Fórmula derivada de funciones compuestas de múltiples variables
9. Fórmula aproximada de función variable.
9.1 Fórmulas aproximadas para funciones de una variable
9.2 Fórmulas aproximadas para funciones multivariables
9.3 Representación vectorial de fórmulas aproximadas
10. Método de descenso de gradiente
10.1 Fórmula básica del método de descenso de gradiente para funciones de dos variables
10.3 Fórmula básica del método de descenso de gradiente para funciones de tres variables
El significado de 10,5 η: tasa de aprendizaje
11. Problemas de optimización y análisis de regresión
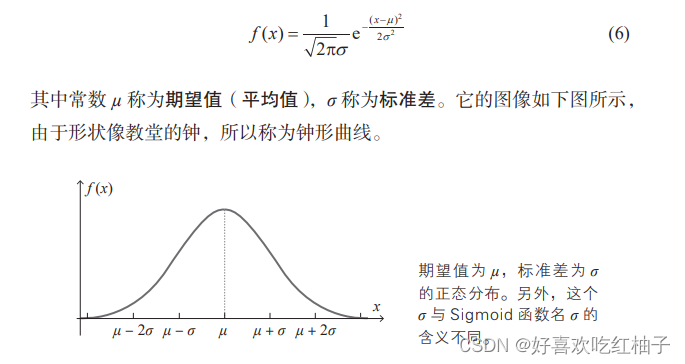
1. Distribución normal
El uso de números aleatorios que siguen una distribución normal al establecer valores iniciales para ponderaciones y sesgos generalmente produce buenos resultados.
2. Relación recursiva
Las computadoras son buenas para calcular relaciones.
Por ejemplo, veamos el cálculo de factorial. El factorial de un número natural n es el producto de números enteros del 1 al n, representado por el símbolo n!.
¡norte! = 1×2×3×…×norte
En la mayoría de los casos, las personas calculan n! según la fórmula anterior, mientras que las computadoras suelen utilizar la siguiente relación de recursividad para calcular.
a1 = 1,an + 1 = (n + 1)an
El método de retropropagación de errores utiliza este método de cálculo en el que las computadoras son buenas para calcular redes neuronales.
3. ∑ símbolo

4. Vectores
4.1 Producto interior vectorial
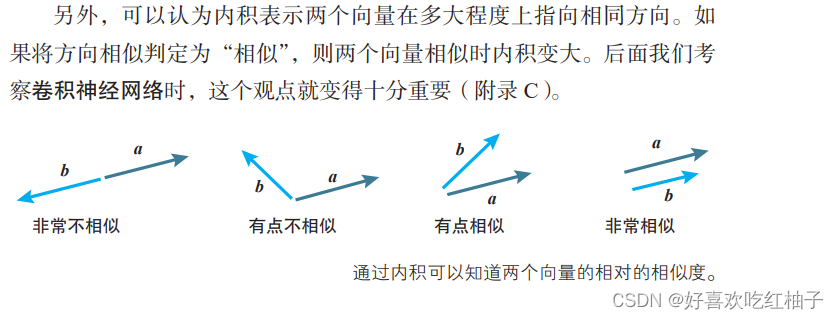
a⋅b = | a | | b |cosθ (θ es el ángulo entre a y b)

4.2 Desigualdad de Cauchy-Schwarz

La propiedad 1 se puede aplicar al método de descenso del gradiente (la dirección opuesta del gradiente desciende más rápido).
4.3 Representación coordinada del producto interno.
Espacio bidimensional:

Espacio tridimensional:

4.4 Generalización de vectores

En el proceso de cálculo de redes neuronales, la perspectiva vectorial es muy beneficiosa.
Cuando la unidad neuronal tiene múltiples entradas x1, x2,…, xn, se pueden organizar en las siguientes entradas ponderadas.


5. Matriz
5.1 Matriz de identidad
La matriz identidad, que es una matriz cuadrada con elementos 1 en la diagonal y otros elementos 0, suele representarse por E.
Por ejemplo, la matriz identidad E con 2 filas y 2 columnas y 3 filas y 3 columnas (llamada matriz identidad de segundo orden y matriz identidad de tercer orden) se representan de la siguiente manera, respectivamente.

La matriz identidad es una matriz con las mismas propiedades que 1. El producto de la matriz identidad E y cualquier matriz A satisface la siguiente ley conmutativa.
EA = EA = A
5.2 Producto Hadamard

6. Derivada (función de una sola variable)
6.1 Definición de derivados

6.2 Derivadas de funciones fraccionarias y derivadas de funciones sigmoideas
Derivadas de funciones fraccionarias:

Derivada de la función sigmoidea:

6.3 Cómo encontrar el valor mínimo
Cuando la función f(x) toma el valor mínimo en x = a, f'(a) = 0.
7. Derivadas parciales (funciones multivariables)
7.1 Funciones multivariables
Una función con más de dos variables independientes se llama función multivariable .
f(x1, x2,…, xn) : Una función con n variables independientes x1, x2,…, xn.
Hay miles de variables funcionales en las redes neuronales.
7.2 Derivadas parciales
La derivada con respecto a una variable específica se llama derivada parcial.

7.3 Cómo encontrar el valor mínimo

7.4 Multiplicación de números de Lagrange

8. Regla de la cadena
8.1 Funciones compuestas
Se sabe que la función y = f(u), cuando u se expresa como u = g(x), y en función de x se puede expresar como una estructura anidada de la forma y = f(g(x)) (u y x representan multivariado). En este momento, la función f(g(x)) de la estructura anidada se llama función compuesta de f(u) y g(x) .
La función en la red neuronal también es una función compuesta típica.

8.2 Fórmula derivada de una función compuesta de una sola variable

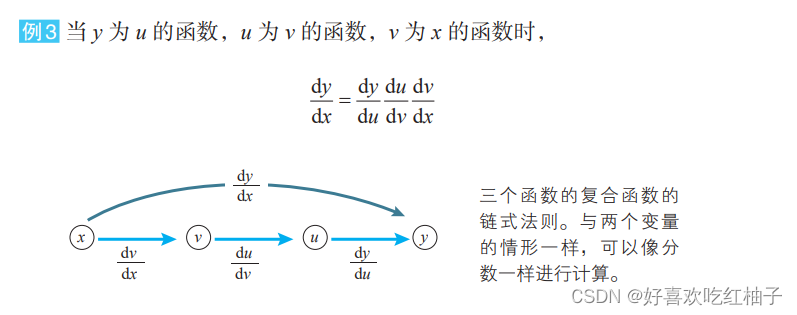
8.3 Fórmula derivada de funciones compuestas de múltiples variables
z = f(u,v), encuentra la derivada parcial de la variable x:
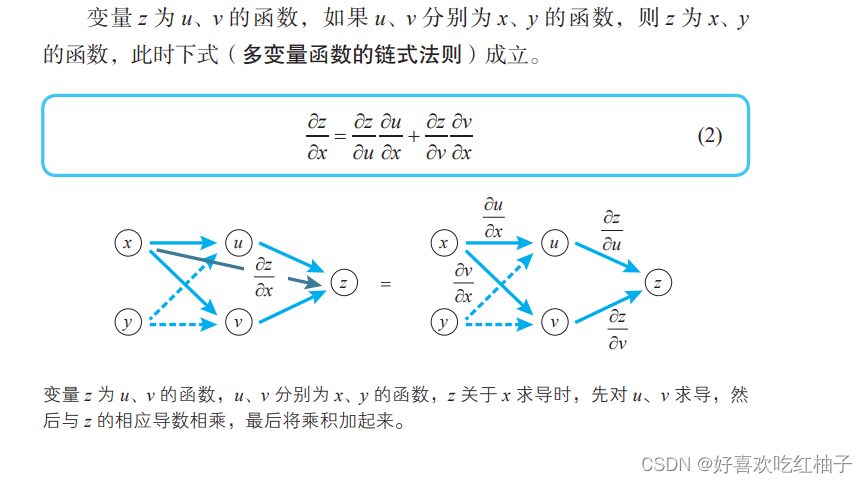
Encuentra la derivada parcial de la variable y:

C = f(u,v,w) , encuentre la derivada parcial de u: (Lo mismo para v y w)

9. Fórmula aproximada de función variable.
El método de descenso de gradiente es un método representativo para determinar redes neuronales. Al aplicar el método de descenso de gradiente, se debe utilizar una fórmula aproximada para una función multivariable.
9.1 Fórmulas aproximadas para funciones de una variable

9.2 Fórmulas aproximadas para funciones multivariables
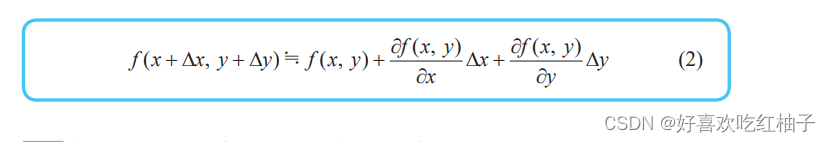
Simplifica la fórmula y usa la letra z para representar el cambio de la función z = f(x, y) cuando xey cambian en Δx y Δy :

La versión simplificada de la fórmula aproximada es la siguiente: de la misma manera, la fórmula aproximada de una función de tres variables también se puede expresar de esta manera.

9.3 Representación vectorial de fórmulas aproximadas
La fórmula aproximada se puede expresar como el producto interno de los siguientes dos vectores ∇ z⋅Δ x.

10. Método de descenso de gradiente
El método de descenso de gradiente es el método más utilizado para encontrar el valor mínimo de una función, es decir, utilizar la dirección del gradiente negativo para determinar la nueva dirección de búsqueda para cada iteración, de modo que cada iteración pueda reducir gradualmente la función objetivo a optimizar. .
10.1 Fórmula básica del método de descenso de gradiente para funciones de dos variables
El proceso de derivación
Cuando x cambia Δx e y cambia Δy, el cambio Δz de la función f (x, y) es:
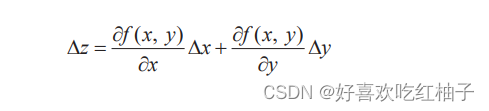
La fórmula anterior se puede expresar como la forma del producto interno de dos vectores a y b.


Se sabe que cuando la dirección de b es opuesta a la de a, el producto interno a·b toma el valor mínimo. Es decir, cuando el vector b satisface b= - ka (k es una constante positiva), el producto interno a·b toma el valor mínimo.
Es decir, cuando las direcciones de los dos vectores a y b son exactamente opuestas, Δz se puede minimizar (es decir, disminuir lo más rápido)

De esto podemos obtener la fórmula básica del método de descenso de gradiente de una función de dos variables.
Al pasar del punto (x, y) al punto (x + Δx, y + Δy), cuando:

La función z = f (x, y) disminuye más rápidamente.
10.2 Degradado
El gradiente es un vector (vector) , lo que significa que la derivada direccional de una determinada función en ese punto alcanza el valor máximo en esa dirección, es decir, la función cambia más rápido en esa dirección (la dirección del gradiente) en ese punto y tiene la mayor tasa de cambio (es el módulo del gradiente).

10.3 Fórmula básica del método de descenso de gradiente para funciones de tres variables
La fórmula básica del método de descenso de gradiente para funciones de dos variables se puede extender fácilmente a situaciones con más de tres variables. Cuando la función f consta de n variables independientes x1, x2,…, xn, la fórmula básica de tres variables se puede generalizar.

10.4 Operador hamiltoniano


El significado de 10,5 η: tasa de aprendizaje
En el mundo de las redes neuronales, eta se llama tasa de aprendizaje . No existe un estándar claro para su método de determinación y el valor apropiado sólo se puede encontrar mediante prueba y error.

11. Problemas de optimización y análisis de regresión
En términos de optimización, la suma de errores se puede denominar "función de error", "función de pérdida", "función de costo", etc. El método de optimización que utiliza la suma de errores al cuadrado se denomina método de mínimos cuadrados .