Szenenbeschreibung
Nehmen Sie als Beispiel ein Szenario:
Dokument A: Downstream-Untertabelle (geringe Datenmenge)
Dokument B: Downstream-Haupttabelle (geringe Datenmenge)
Dokument C: Midstream-Untertabelle (geringe Datenmenge)
Dokument D: Midstream-Haupttabelle (geringe Datenmenge)
Dokument E: Upstream Untertabelle (kleiner Datenumfang)
Dokument F: Upstream-Haupttabelle (größerer Datenumfang als andere Tabellen)
Anforderung: Streichen Sie ein bestimmtes Feld von Dokument F auf ein bestimmtes Feld von Dokument A. Von A bis F können sie alle in Form eines ID-Verbindungsindex verknüpft werden. Aber die Verbindungsreihenfolge von A nach F muss von A nach F sein. Zum Beispiel:
Der Zusammenhang dieser Tabellen lässt sich anhand des folgenden Beispiels demonstrieren:
a join b on a.id = b.id
b join c on b.id = c.mainId
c join d on c.id = d.tableId
d join e on d.id = e.tid
e join f on e.tid = f.code
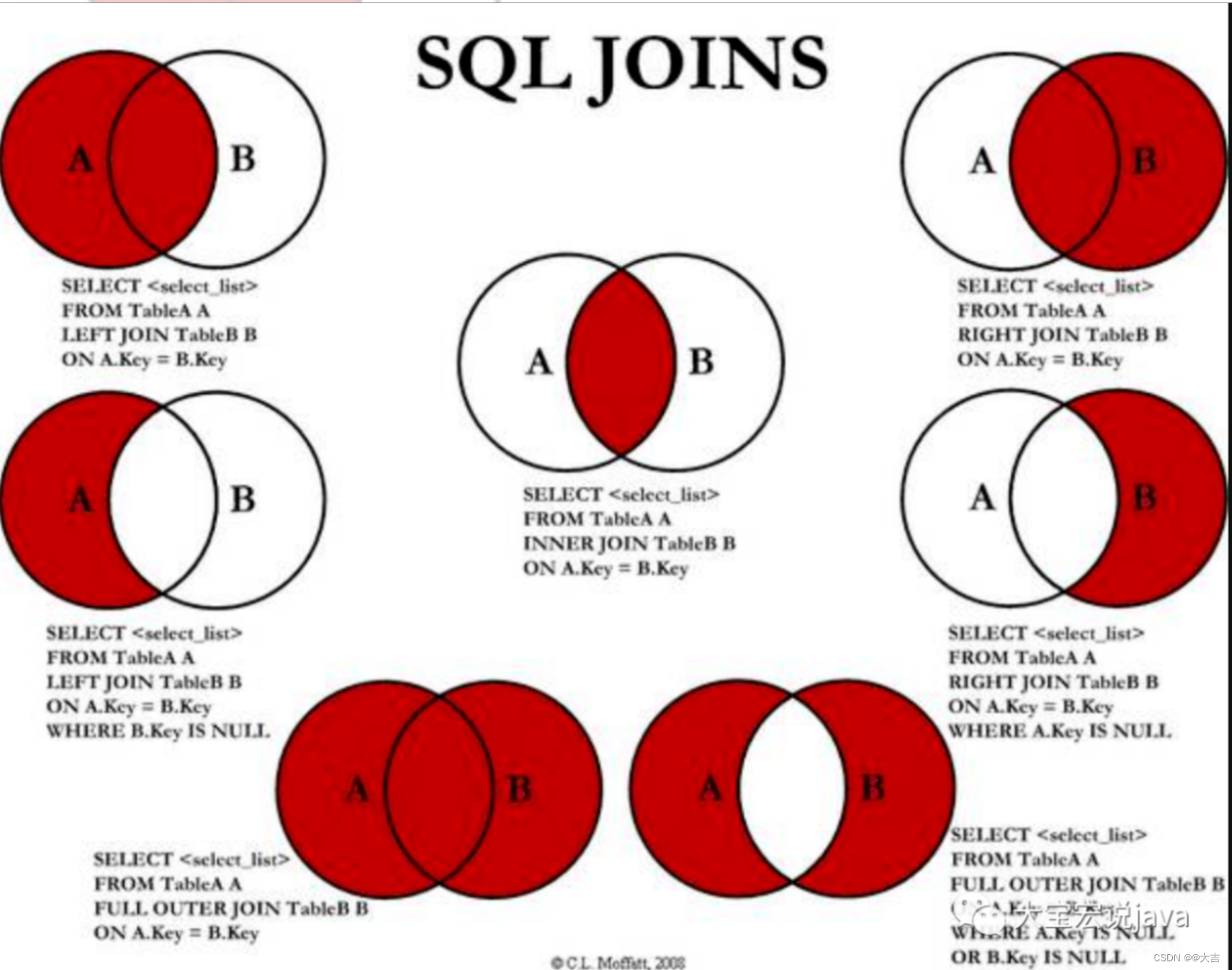
Der Unterschied zwischen Inner Join und Left Join
Wenn wir die Update-Anweisung schreiben, möchten wir unbedingt Join verwenden, um die Tabellen zu verbinden. Aber ist es besser, Inner Join oder Left Join zu verwenden?
-
Left Join:
select a.*,b.* from a left join b on a.id = b.idDiese beiden Tabellen sind verbunden. Gemäß der nachfolgenden On-Bedingung werden alle Datenspalten in Tabelle A angezeigt, wenn b.id in Tabelle b nicht mit a.id = b.id übereinstimmt. Dann enthält Tabelle b diese Art von Daten nicht, sodass b.* in SQL mit Null gefüllt wird -
innerer Join:
select a.*,b.* from a inner join b on a.id = b.idDiese beiden Tabellen sind verbunden. Gemäß den folgenden Bedingungen : Wenn b.id in Tabelle b nicht mit a.id = b.id übereinstimmt, dann stimmen einige Datenspalten in Tabelle a (nicht mit a.id = überein). B. ID-Bedingung) wird nicht angezeigt.
Gemäß der obigen Definition wird in SELECT-Anweisungen häufig ein Left-Join verwendet; dies soll verhindern, dass Tabelle A weniger übereinstimmende Datensätze enthält, und um die gesamte Tabelle A anzuzeigen, wird ein Left-Join verwendet.
Wie nachfolgend dargestellt:
Das Verständnis kleiner Ergebnismengen aus der Indexperspektive führt zu großen Ergebnismengen
Unabhängig vom Left-Join oder Inner-Join ist es wichtig zu beachten, dass die kleine Ergebnismenge die große Ergebnismenge steuert. Wenn Tabelle a sich Tabelle b anschließt,
Schauen wir uns die SQL aus dem vorherigen Beispiel an:
select a.*,b.* from a left join b on a.id = b.id
Nehmen Sie an, dass die Größe von Tabelle a 1 Million Elemente und die Größe von Tabelle b 100 Elemente beträgt. Wenn ich mich auf diese Weise verbinde, steuert die große Tabelle die kleine Tabelle; schauen Sie sich einfach die Anzahl der Suchanfragen an:
Wenn Sie die folgende Bedingung verwenden, um zwei Tabellen zu verbinden, müssen Sie zuerst den B+-Baumindex zum Abgleichen verwenden; nehmen Sie die 1-Millionen-Größenordnung von Tabelle a, vergleichen Sie sie einzeln -> B+-Baum -> entsprechen Sie den Datensätzen von Tabelle b . Unter der Annahme, dass die Suche im B+-Baum nach 100 Einträgen in Tabelle b zwei Suchvorgänge erfordert, beträgt die endgültige Anzahl der Suchvorgänge: 1 Million * 2 Mal
Wenn eine kleine Tabelle eine große Tabelle steuert:
select a.*,b.* from b left join a on a.id = b.id
Dann nehmen wir die 100 Datensätze von Tabelle b und vergleichen sie einzeln -> B+-Baum -> entsprechen den Datensätzen von Tabelle a. Unter der Annahme, dass der B+-Baum für die Suche nach 1 Million Einträgen in Tabelle a 3 Suchvorgänge erfordert, beträgt die endgültige Anzahl der Suchvorgänge: 100 * 3 Mal
Aus Sicht des Indexabgleichs wurde die Effizienz kleiner Ergebnismengen bei der Steuerung großer Ergebnismengen überhaupt nicht optimiert. Wir müssen bewusst die kleine Uhr links und die große Uhr rechts platzieren
Wenn Sie jedoch Inner Join verwenden, führt MySQL eine interne Optimierung durch und platziert automatisch die kleine Tabelle vorne und die große Tabelle hinten. Mit anderen Worten: Egal wie Sie es schreiben, die Effizienz wird gleich sein. Allerdings kann der Left Join nicht automatisch optimiert werden, daher müssen Sie darauf achten!
Die Update-Anweisung verwendet häufig einen Inner-Join anstelle eines Left-Joins.
Zum Beispiel das folgende SQL:
(Aufgabenziel: Aktualisieren Sie ein Tabellenfeld mit f Tabellenfeld)
update a
inner join b on a.id = b.id
inner join c on b.id = c.mainId
inner join d on c.id = d.tableId
inner join e on d.id = e.tid
inner join f on e.tid = f.code
set a.Demand_orgid = f.req_org_id
where xxx = xxx;
Für die Aktualisierung muss grundsätzlich Inner Join verwendet werden.
Wenn Sie sich die obige SQL-Anweisung ansehen, gehen Sie davon aus, dass Sie für alle Assoziationen den Left-Join verwenden , da Sie am Ende das Feld von a aktualisieren. Nehmen Sie an, dass sich Tabelle a im Prozess des Left-Joins befindet, da ein bestimmter Punkt nicht mit Tabelle f übereinstimmen kann Verwenden Sie Tabelle f. Wenn bei der Feldaktualisierung der Felder in Tabelle a ein Link nicht übereinstimmt, werden alle Felder in Tabelle f mit Null gefüllt. Wenn Tabelle a am Ende nicht mit den Daten in Tabelle f übereinstimmen kann, wird sie auf null aktualisiert!
Wenn Sie jedoch Inner Join verwenden, um die Felder von Tabelle a mit den Feldern von Tabelle f zu aktualisieren, werden alle Daten in Tabelle a, die nicht mit Tabelle f übereinstimmen können, nicht angezeigt, sobald ein Link nicht übereinstimmen kann wird nicht angezeigt. erneuern.
Wenn Sie darüber nachdenken, können Sie nicht einmal die Datenspalten zuordnen. Was aktualisieren Sie sonst noch? Aktualisieren Sie null? Aus den oben genannten Gründen erfüllt Inner Join tatsächlich die Anforderungen
Außerdem! Der linke Join muss die Größenbeziehung dieser Tabellen berücksichtigen, welche größer und welche kleiner ist. Der kleine Ergebnissatz steuert den großen Ergebnissatz. Bei Inner Join besteht jedoch überhaupt keine Notwendigkeit, dieses Problem zu berücksichtigen, da Inner Join MySQL eine interne Optimierung durchführt, um die kleine Tabelle automatisch vorne und die große Tabelle hinten zu platzieren.