„ Baichuan Intelligent hat eine neue Generation des Sprachmodells Baichuan2 veröffentlicht. Im Vergleich zur vorherigen ersten Generation wurde die Leistung der neuen Version in verschiedenen Fachbereichen, insbesondere in den Bereichen Mathematik, Naturwissenschaften und Sicherheit, erheblich verbessert. Die Fähigkeiten von Baichuan2 wurden verbessert deutlich verbessert. Die Open-Source-Methode der Veröffentlichung nach außen bietet neue Wahlmöglichkeiten und Möglichkeiten für den Bereich der großen Modelle. “

01
—
Gestern Nachmittag veröffentlichte Baichuan Intelligent eine aufregende Neuigkeit: Das Unternehmen hat die fein abgestimmten Versionen Baichuan2-7B, Baichuan2-13B, Baichuan2-13B-Chat und ihre quantisierten 4-Bit-Versionen offiziell als Open Source bereitgestellt und kann völlig kostenlos kommerziell genutzt werden mit einfachen Schritten. Registrieren Sie sich einfach.
Eine weitere Option bieten inländische Open-Source- und kommerziell erhältliche Großmodelle. Open-Source-Adresse:
https://github.com/baichuan-inc/Baichuan2
Baichuan2 ist ein umfassendes Upgrade der Open-Source-Modellreihe „Baichuan“. Laut der offiziellen Einführung wurden die Fähigkeiten von Baichuan2 in den Bereichen Geisteswissenschaften und Naturwissenschaften im Vergleich zur ersten Generation deutlich verbessert.
Baichuan2-13B-Base hat seine mathematischen Fähigkeiten um 49 %, seine Codierungsfähigkeiten um 46 %, seine Sicherheitsfähigkeiten um 37 %, sein logisches Denken um 25 % und sein semantisches Verständnis um 15 % verbessert.
Die aktuellen Ergebnisse von Baichuan2 zum maßgeblichen Benchmark-Datentestsatz großer Modelle lauten wie folgt (Baichuan2-13B)
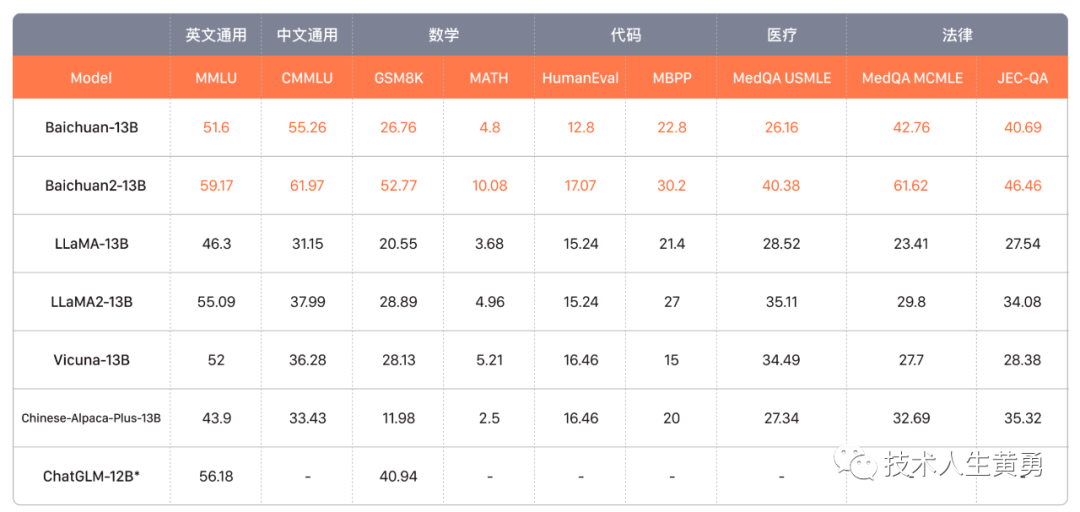
Beschreibung des grundlegenden Bewertungsdatensatzes:
C-Eval ist ein umfassender chinesischer Basismodellbewertungsdatensatz, der 52 Themen und vier Schwierigkeitsstufen abdeckt.
MMLU ist ein englischer Bewertungsdatensatz mit 57 Aufgaben zu den Themen Grundmathematik, amerikanische Geschichte, Informatik, Recht usw. mit Schwierigkeitsgraden vom High-School-Niveau bis zum Expertenniveau. Derzeit ist er der gängige LLM-Bewertungsdatensatz.
CMMLU ist ein umfassender chinesischer Bewertungsbenchmark mit 67 Themen, der speziell zur Bewertung des Wissens und der Argumentationsfähigkeiten von Sprachmodellen im chinesischen Kontext verwendet wird.
Gaokao ist ein Datensatz, der chinesische Hochschulaufnahmeprüfungsfragen als Datensatz zur Bewertung der Fähigkeiten großer Sprachmodelle verwendet und zur Bewertung der Sprachfähigkeiten und der logischen Denkfähigkeit des Modells verwendet wird. Baichuan behielt die Single-Choice-Fragen bei und teilte sie nach dem Zufallsprinzip auf.
AGIEval wurde entwickelt, um die allgemeinen Fähigkeiten eines Modells bei kognitiven und problemlösungsbezogenen Aufgaben zu bewerten. Wir haben nur vier der Multiple-Choice-Fragen beibehalten und sie zufällig aufgeteilt.
BBH ist eine Teilmenge der anspruchsvollen Aufgabe Big-Bench. Big-Bench umfasst derzeit 204 Aufgaben. Zu den Aufgabenthemen gehören Linguistik, kindliche Entwicklung, Mathematik, gesundes Denken, Biologie, Physik, soziale Vorurteile, Softwareentwicklung und mehr. BBH ist ein Evaluierungsbenchmark, der gebildet wird, indem aus den 204 Big-Bench-Evaluierungsbenchmark-Aufgaben die Aufgaben herausgenommen werden, bei denen das große Modell schlecht abschneidet.
Die Leistung des Testsatzes ist in Ordnung, aber ich weiß nicht, wie der eigentliche Anwendungsprozess des Nicht-Testsatzes abschneidet.
Verwenden Sie diesen Artikel „ ChatALL: Der erstaunliche KI-Roboter, der die besten Antworten findet!“ „Erleben Sie eine Frage, die an einem großen Modell in getestet wurde“.
„Ein Jäger ging eine Meile nach Süden, eine Meile nach Osten und eine Meile nach Norden, als er wieder an seinem Ausgangspunkt ankam. Er sah einen Bären und schoss ihn. Welche Farbe hatte der Bär? ?“

Nach dem Hinweis auf den Fehler wird das Quadrat dennoch berücksichtigt.

„Es sind 10 Vögel im Baum. Wenn du einen schießt und tötest, wie viele bleiben dann im Baum übrig?“

Diese argumentative Antwort ist völlig richtig und der Faktor der Abschreckung durch den Ton wird ebenfalls berücksichtigt.
02
—
Ausrichten
Im offiziellen technischen Berichtshandbuch (https://baichuan-paper.oss-cn-beijing.aliyuncs.com/Baichuan2-technical-report.pdf) wird erwähnt, dass baichuan2 neben Optimierungen und Verbesserungen im Training auch einen Ausrichtungsprozess einführt. Es umfasst zwei Hauptkomponenten: Supervised Fine-Tuning (SFT) und Human Feedback Reinforcement Learning (RLH F).
In der überwachten Feinabstimmungsphase werden menschliche Kommentatoren eingesetzt, um aus verschiedenen Datenquellen gesammelte Tipps zu kommentieren. Jeder Tipp wird als hilfreich oder unbedenklich markiert und jede Charge, die nicht den Qualitätsstandards entspricht, wird abgelehnt. Unter Verwendung dieses Standards wurden mehr als 100.000 überwachte Feinabstimmungsproben gesammelt und das Grundmodell von Baichuan darauf trainiert.
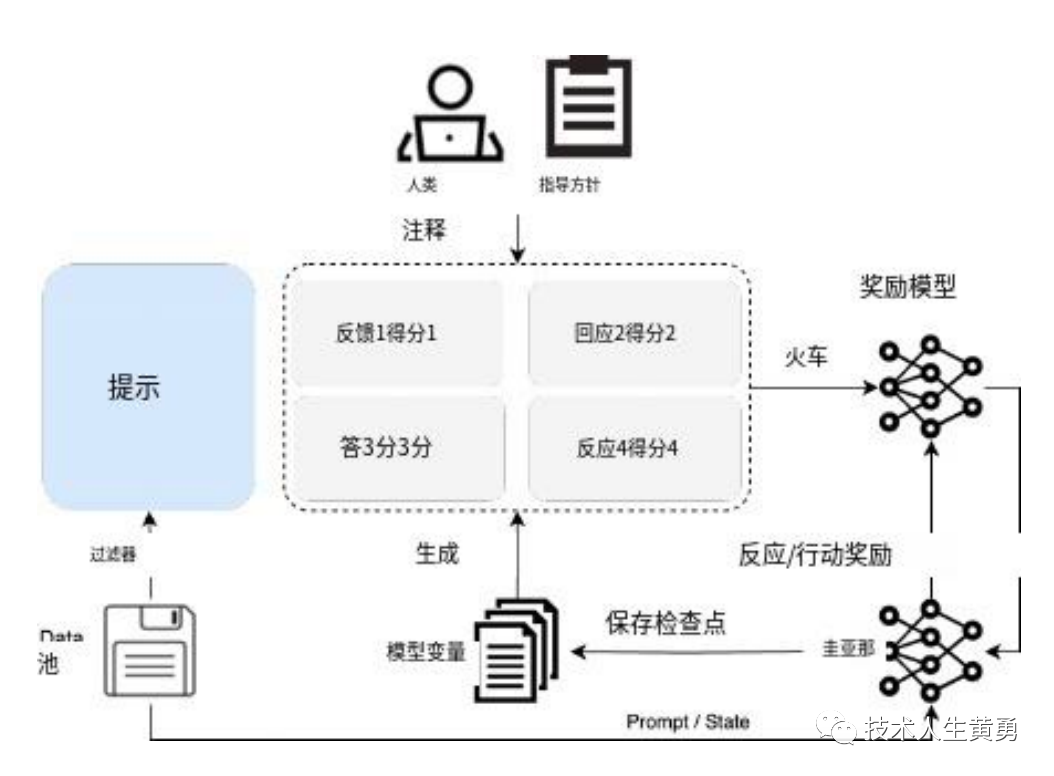
In diesem Artikel: Ist künstliche Intelligenz sicher? OpenAI „richtet“ große Modelle auf Menschen aus und stellt so sicher, dass ChatGPT intelligenter als Menschen ist und gleichzeitig menschlichen Absichten folgt. „Ausrichtung“ ist ein wichtiger Teil des aktuellen Trainings für große Modelle. Es kann große Modelle intelligenter machen und gleichzeitig angemessene Sicherheit gewährleisten .
In der Ausrichtungsphase baute Baichuan einen Red-Team-Prozess auf, der aus 6 Angriffstypen und über 100 granularen Sicherheitswertkategorien bestand, und ein 10-köpfiges Expertenteam mit Erfahrung in der traditionellen Internetsicherheit initialisierte Eingabeaufforderungen zur Sicherheitsausrichtung. Relevante Snippets werden aus dem Datensatz vor dem Training abgerufen, um Antworten zu erstellen, was zu etwa 1 KB annotierten Daten für die Initialisierung führt.
Das Experten-Annotationsteam leitete ein 50-köpfiges ausgelagertes Annotationsteam an, um eine Rot-Blau-Konfrontation mit dem initialisierten Ausrichtungsmodell durchzuführen und dabei 200.000 Angriffstipps zu generieren.
Die maximale Nutzung der Angriffsdaten wird durch den Einsatz eines speziellen, mehrwertigen, überwachten Sampling-Ansatzes erreicht, um Antworten mit unterschiedlichen Sicherheitsstufen zu generieren.
Interessierte Freunde können das offizielle technische Berichtshandbuch von Baichuan lesen, das weitere technische Implementierungsdetails enthält.
03
—
Baichuan stellte außerdem vor, wie Benchmark-Tests in mehreren derzeit gefragten Anwendungsbereichen durchgeführt werden: Recht, medizinische Versorgung, Mathematik, Codierung und mehrsprachige Übersetzung.
Rechtsbereich: Es wird der JEC-QA-Datensatz verwendet. Der JEC-QA-Datensatz stammt aus der chinesischen nationalen gerichtlichen Prüfung.
Medizinische Domäne: Verwenden Sie medizinbezogene Disziplinen, MedQA und MedMCQA in gemeinsamen Domänendatensätzen (C-Eval, MMLU, CMMLU).
Der MedQA-Datensatz stammt aus medizinischen Untersuchungen in den USA und China. Zwei Teilmengen von USMLE und MCMLE im MedQA-Datensatz wurden getestet und fünf Kandidatenversionen wurden übernommen.
Der MedMCQA-Datensatz stammt aus der Aufnahmeprüfung des Indian Medical College. Es wurden nur die Multiple-Choice-Fragen getestet.
Mathematik: Unter Verwendung des OpenCompass-Bewertungsframeworks wurden 4-Schuss-Tests mit den GSM8K- und MATH-Datensätzen durchgeführt.
GSM8K ist ein von OpenAI veröffentlichter Datensatz, der aus 8,5K qualitativ hochwertigen Textaufgaben für Grundschulmathematik in verschiedenen Sprachen besteht. Es erfordert die Auswahl der sinnvollsten Lösung auf der Grundlage eines bestimmten Szenarios und zweier möglicher Lösungen.
Der MATH-Datensatz enthält 12.500 mathematische Probleme (7.500 davon gehören zum Trainingssatz und 5.000 zum Testsatz), die aus Mathematikwettbewerben wie AMC 10, AMC 12 und AIME gesammelt wurden.
Codedomäne : Es werden HumanEval- und MBPP-Datensätze verwendet. Mit OpenCompass wurde ein 0-Schuss-Test für HumanEval und ein 3-Schuss-Test für den MBPP-Datensatz durchgeführt.
Zu den Programmieraufgaben in HumanEval gehören das Verständnis der Modellsprache, Argumentation, Algorithmen und einfache Mathematik, um die funktionale Korrektheit des Modells zu bewerten und die Problemlösungsfähigkeiten des Modells zu messen.
MBPP umfasst einen Datensatz mit 974 Python-Kurzfunktionen, Textbeschreibungen von Programmen und Testfällen zur Überprüfung der funktionalen Korrektheit.
Mehrsprachige Übersetzung : Der Flores-101-Datensatz wurde verwendet, um die mehrsprachigen Fähigkeiten des Modells zu bewerten. Flores-101 deckt 101 Sprachen aus der ganzen Welt ab. Die Daten stammen aus verschiedenen Quellen, darunter Nachrichten, Reiseführer und Bücher.
Als Testsprachen wurden die offiziellen Sprachen der Vereinten Nationen (Arabisch, Chinesisch, Englisch, Französisch, Russisch und Spanisch) sowie Deutsch und Japanisch ausgewählt. OpenCompass wurde verwendet, um 8-Schuss-Tests für sieben Teilaufgaben in Flores-101 durchzuführen, darunter Chinesisch-Englisch, Chinesisch-Französisch, Chinesisch-Spanisch, Chinesisch-Arabisch, Chinesisch-Russisch, Chinesisch-Japanisch und Chinesisch-Deutsch.
Es ist ersichtlich, dass die inländischen Anwendungsszenarien des Baichuan-Großmodells relativ zielgerichtet sind.
Heutzutage haben sich alle nachfolgenden großen Modellhersteller für Open Source für die kommerzielle Nutzung entschieden. Früher gab es ChatGLM vom Tsinghua-Team, im Ausland Meta's Llama und später Baichuan.
Vorteile dieser Vorgehensweise:
Erweitern Sie Ihren Einfluss auf die große Modellbahn . Später entwickelte große Modelle haben keinen Einflussvorteil, und nach Open Source und kommerzieller Nutzung kann das Produkt weithin bekannt sein.
Bauen Sie Markenvertrauen auf . Das große Modell ist ein neues Geschäft und die Benutzer haben nicht viel Wissen über seine Funktionen, Sicherheit, Benutzerfreundlichkeit usw. Open Source ermöglicht es Benutzern, eine Reihe von Arbeiten zu verstehen, die bei der Erstellung, Schulung, Feinabstimmung, Ausrichtung und Bewertung durchgeführt wurden, um so ein umfassendes Verständnis davon zu erlangen.
Sammeln Sie schnell Kundenfeedback und beschleunigen Sie die Modellentwicklung und -iteration . Nach Open Source können mehr Benutzer an der Nutzung des Modells teilnehmen und ein immer umfassenderes Benutzerfeedback erhalten. Und wird in nachfolgenden Iterationen der Versionsentwicklung verwendet, um die Anwendung gezielter und universeller zu gestalten.
Verweise
https://www.baichuan-ai.com/
https://github.com/baichuan-inc/Baichuan2
https://baichuan-paper.oss-cn-beijing.aliyuncs.com/Baichuan2-technical-report.pdf
Leseempfehlungen
8.23 Anmerkungen zu Chinas großem Vorbild „Top Group Chat“
Nehmen Sie die Zukunft an und erlernen Sie KI-Fähigkeiten! Folgen Sie mir und erhalten Sie kostenlose KI-Lernressourcen.