Directorio de artículos
-
- 一、Convolución mixta en profundidad
- 二、Núcleo deformable
- 三、Convolución dinámica
- 四、Convolución subvariedad
- 5. ConvConv.
- 六、Convolución activa
- 七、Convolución separable dilatada en profundidad
- 八、Involución
- 九、Convolución dilatada con espacios que se pueden aprender
- 十、Convolución aumentada por la atención
- 11. PP-OCR
- 12.Unidades de agregación desplazadas
- Trece, convolución dimensional
- 14. Capa de relación local
- 15. Convolución ligera
- 16. hamburguesa
- Decimoséptimo, convolución dinámica basada en intervalos
- 18. Conversión de forma
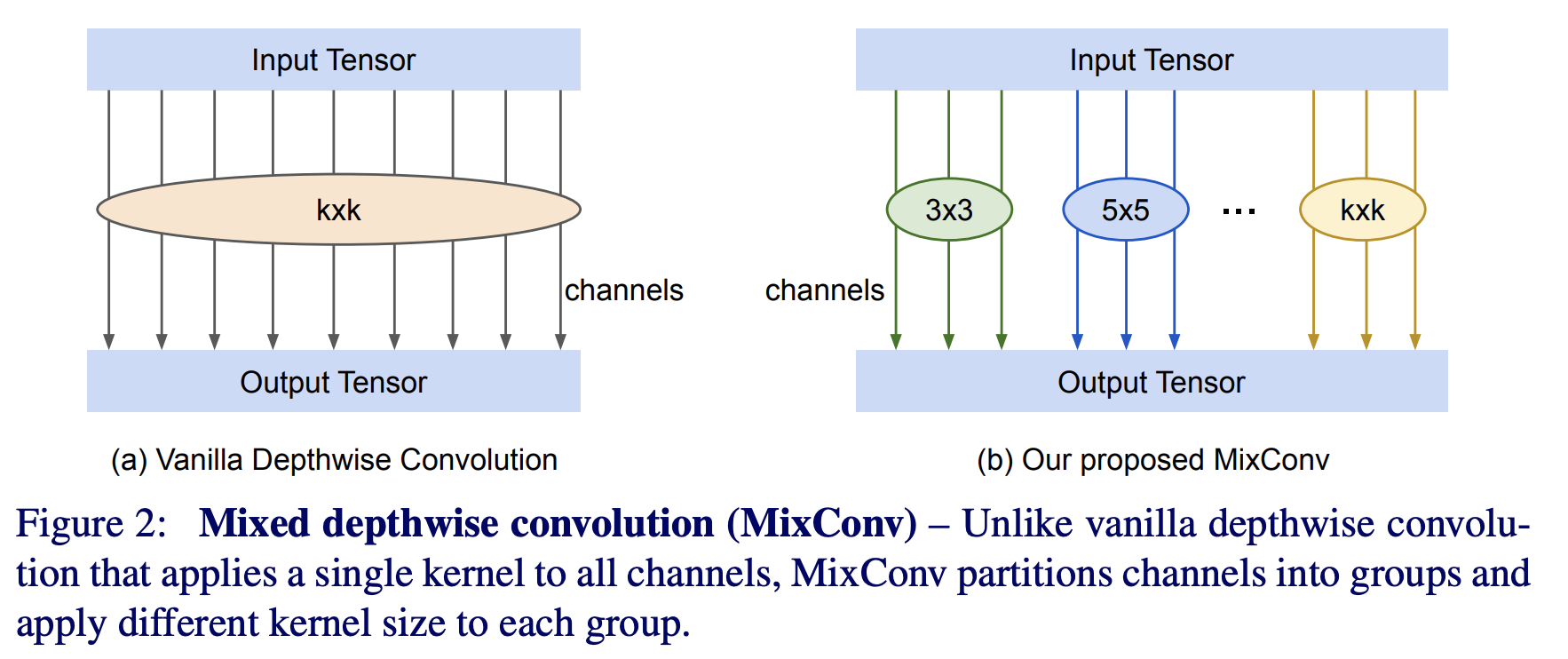
一、Convolución mixta en profundidad
MixConv (o convolución de profundidad mixta) es un tipo de convolución de profundidad que mezcla naturalmente varios tamaños de núcleo en una sola convolución. Se basa en la idea de que las convoluciones profundas aplican un único tamaño de kernel a todos los canales, lo que MixConv supera al combinar las ventajas de múltiples tamaños de kernel. Lo hace dividiendo los canales en grupos y aplicando diferentes tamaños de núcleo a cada grupo.
二、Núcleo deformable
El núcleo deformable es un operador de convolución utilizado para modelar deformaciones. DK aprende desplazamientos de forma libre en las coordenadas del núcleo, deformando el espacio del núcleo original en modalidades de datos específicas en lugar de volver a ensamblar los datos. Esto ajusta directamente el campo receptivo efectivo (ERF) mientras mantiene el campo receptivo sin cambios. Se pueden utilizar como reemplazo directo de núcleos rígidos.


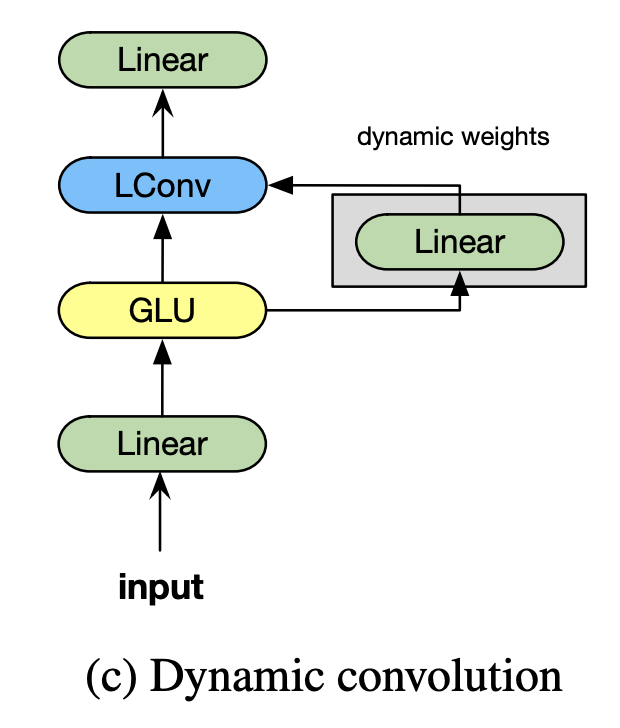
三、Convolución dinámica
DynamicConv es una convolución para modelado secuencial cuyo núcleo cambia con el tiempo como una función aprendida para pasos de tiempo individuales. Está construido sobre LightConv y toma la misma forma, pero usa un kernel dependiente del paso de tiempo:
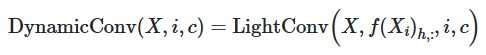
四、Convolución subvariedad

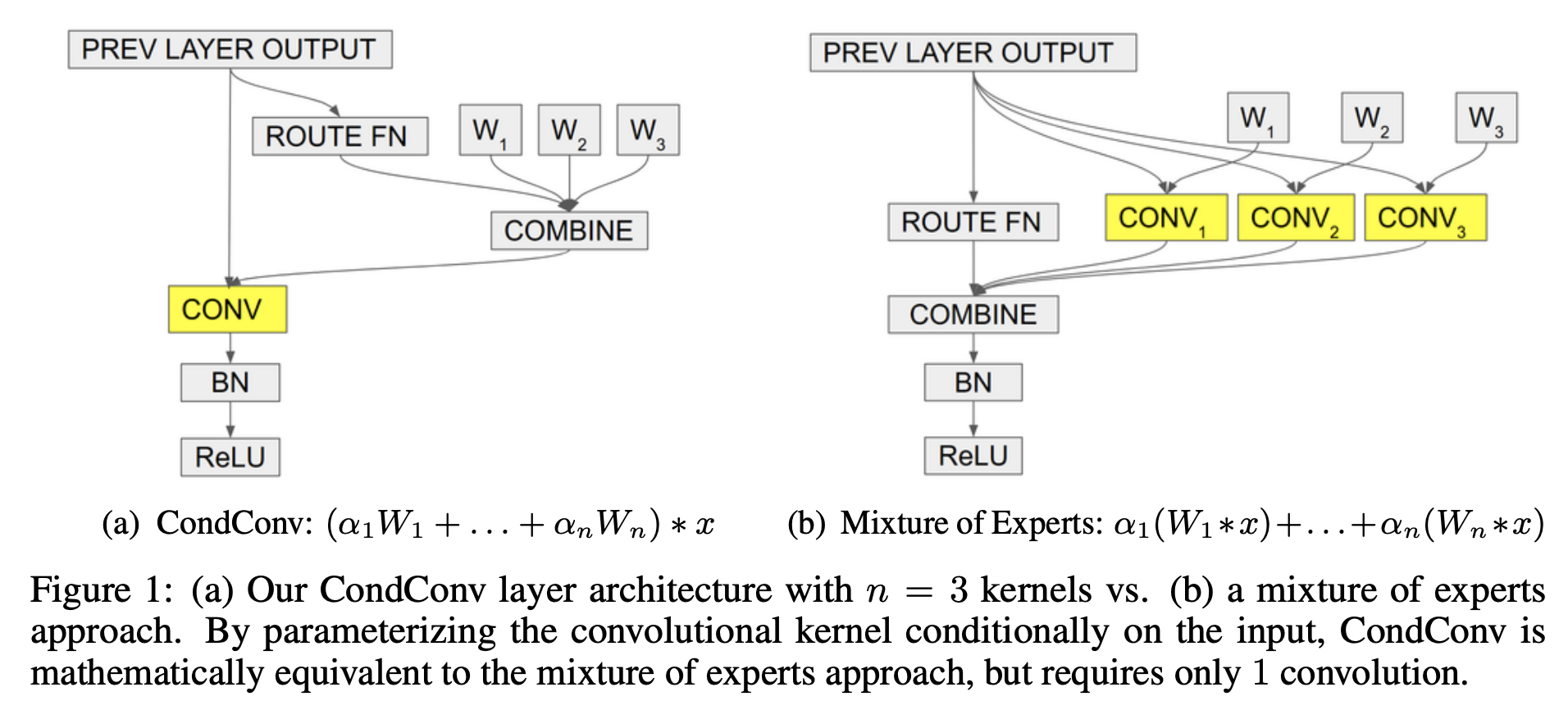
5. ConvConv.
CondConv (o convolución parametrizada condicional) es un tipo de convolución que aprende núcleos de convolución especializados para cada ejemplo.
Para aumentar efectivamente la capacidad de la capa CondConv, los desarrolladores pueden aumentar la cantidad de expertos. Esto es más eficiente desde el punto de vista computacional que aumentar el tamaño del núcleo en sí, ya que el núcleo se aplica a muchas ubicaciones diferentes dentro de la entrada, mientras que los expertos solo se combinan una vez por entrada.
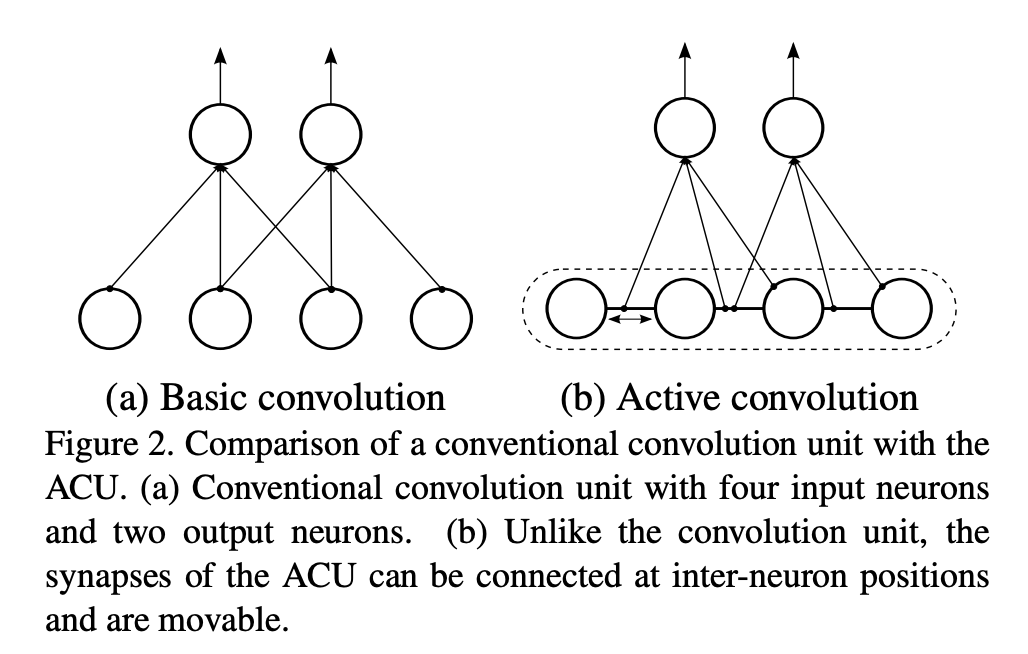
六、Convolución activa
La convolución activa es un tipo de convolución que no tiene una forma de campo receptivo fija y puede utilizar formas de campo receptivo más diversas para la convolución. Su forma se puede aprender mediante retropropagación durante el entrenamiento. Puede verse como una generalización de la convolución; puede definir no solo todas las convoluciones regulares, sino también las convoluciones con coordenadas de píxeles fraccionarias. Podemos cambiar libremente la forma de la convolución, lo que proporciona mayor libertad para formar estructuras CNN. En segundo lugar, la forma de la convolución se aprende durante el entrenamiento y no requiere ajuste manual.
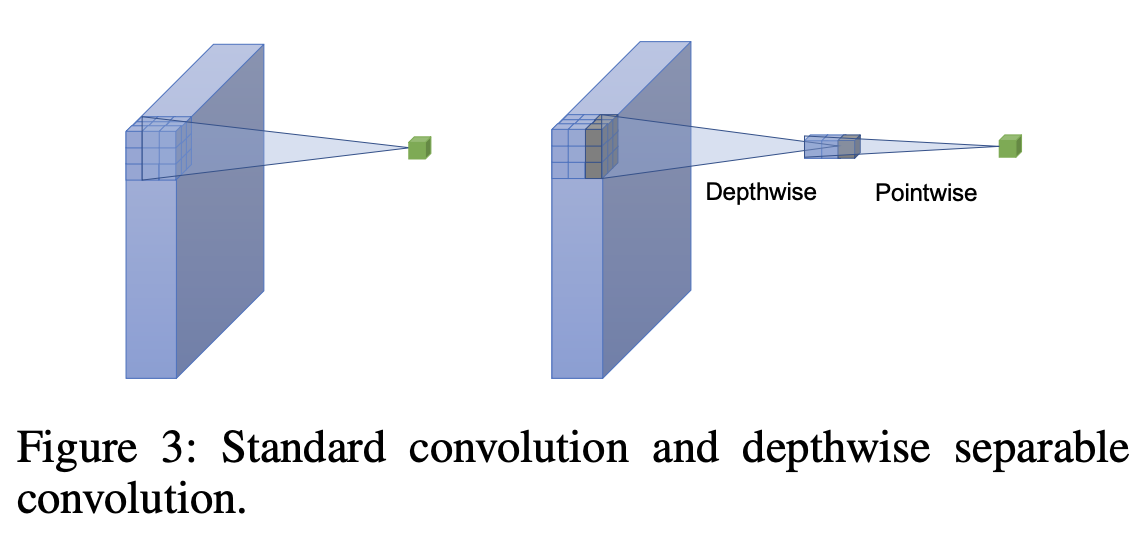
七、Convolución separable dilatada en profundidad
Las convoluciones separables dilatadas en profundidad son un tipo de convolución que combina la separabilidad en profundidad con el uso de convoluciones dilatadas.
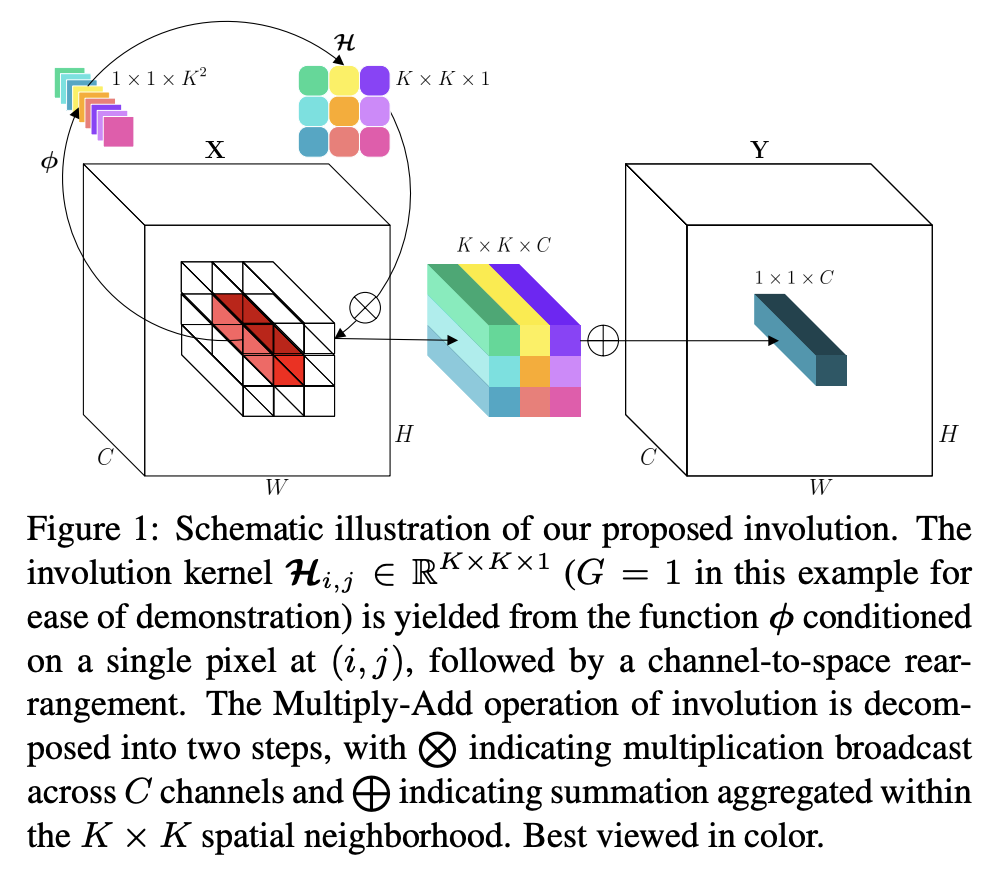
八、Involución
La convolución es una operación atómica de redes neuronales profundas, que invierte el principio de diseño de la convolución. Los núcleos de convolución son espacialmente distintos pero compartidos entre canales. Si el núcleo de involución se parametriza como una matriz de tamaño fijo (como un núcleo de convolución) y se actualiza mediante el algoritmo de retropropagación, el núcleo de involución aprendido no será transferible entre imágenes de entrada con resoluciones variables.
Los autores creen que la involución tiene dos beneficios sobre la convolución: (i) la involución puede resumir el contexto en una disposición espacial más amplia, superando así la dificultad de modelar interacciones de largo alcance; (ii) la involución puede asignar de forma adaptativa diferentes ponderaciones posicionales, priorizando así las más Elementos visuales informativos en el dominio espacial.
九、Convolución dilatada con espacios que se pueden aprender
La convolución dilatada con espaciado aprendible (DCLS) es un tipo de convolución que permite aprender el espaciado entre elementos distintos de cero del núcleo durante el entrenamiento. Esto hace posible aumentar el campo receptivo de la convolución sin aumentar la cantidad de parámetros, lo que puede mejorar el rendimiento de la red en tareas que requieren dependencias de largo alcance.
La convolución dilatada es un tipo de convolución que permite al núcleo omitir ciertas características de entrada. Esto se hace insertando ceros entre elementos distintos de cero del kernel. El efecto de esto es aumentar el campo receptivo de la convolución sin aumentar el número de parámetros.
DCLS lleva esta idea un paso más allá al permitir que el espacio entre elementos distintos de cero del núcleo se aprenda durante el entrenamiento. Esto significa que la red puede aprender a omitir diferentes funciones de entrada según la tarea en cuestión. Esto es particularmente útil para tareas que requieren dependencias remotas, como la segmentación de imágenes y la detección de objetos.
Se ha demostrado que DCLS es eficaz para una variedad de tareas, incluida la clasificación de imágenes, la detección de objetos y la segmentación semántica. Se trata de una nueva tecnología prometedora que tiene el potencial de mejorar el rendimiento de las redes neuronales convolucionales en una variedad de tareas.
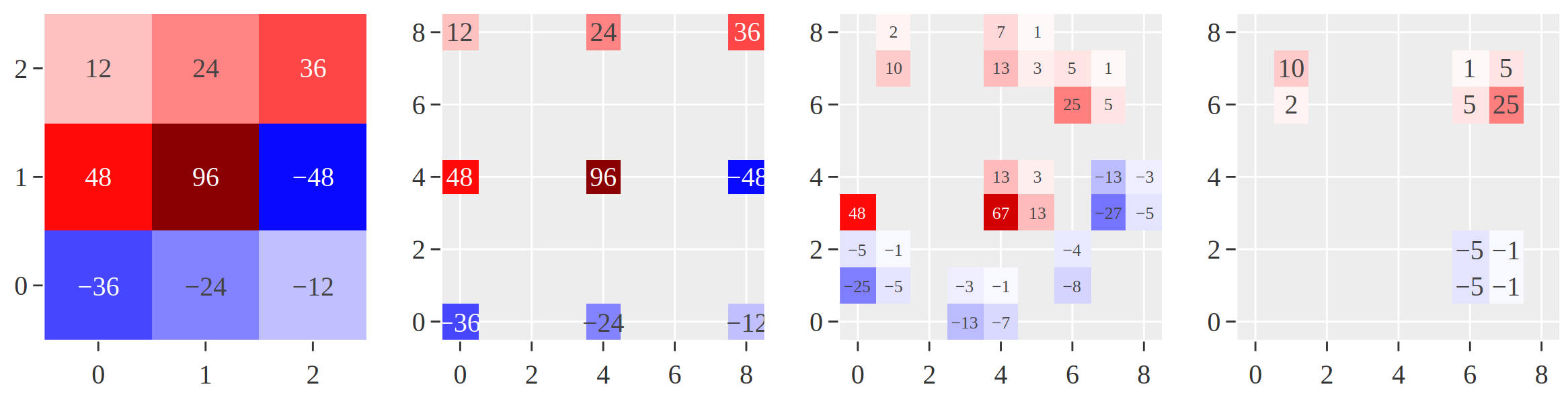
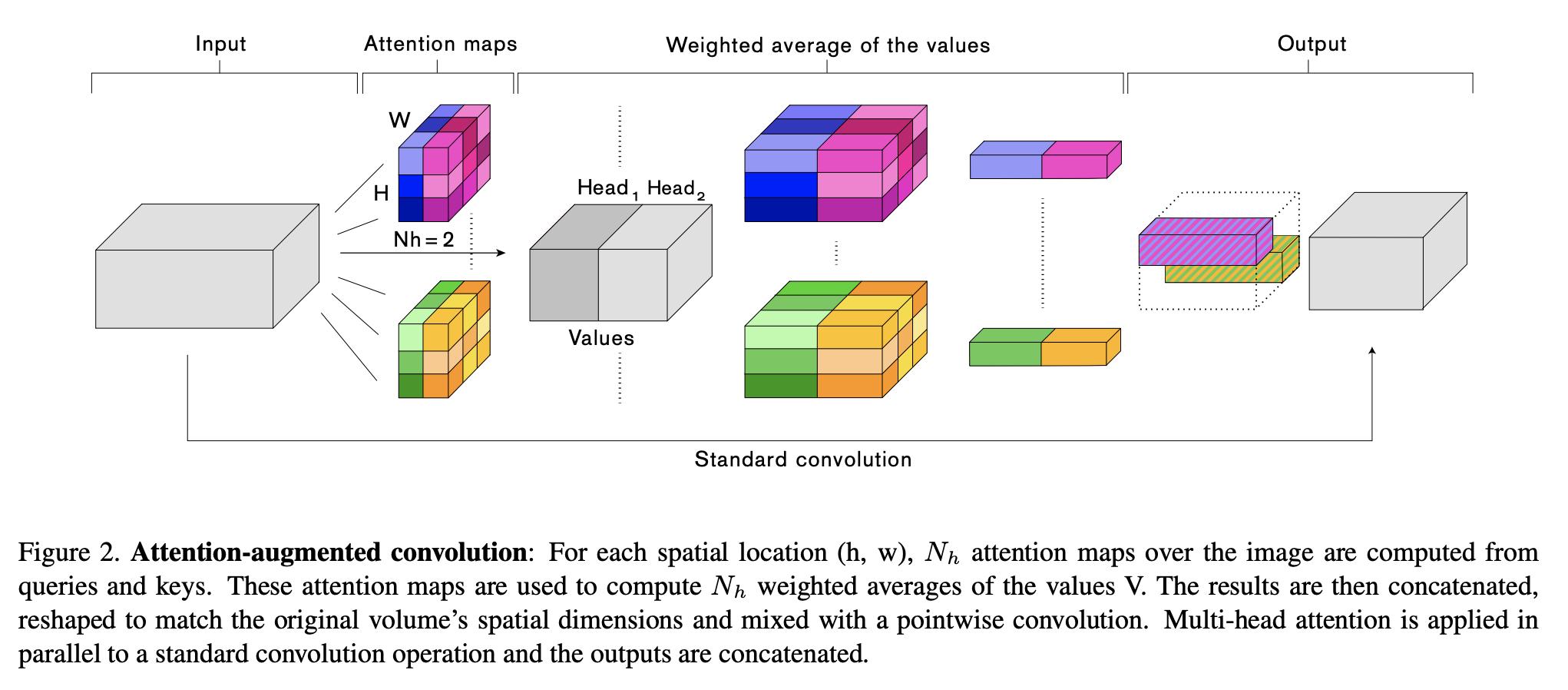
十、Convolución aumentada por la atención
La convolución mejorada por atención es una convolución con un mecanismo de autoatención relativa bidimensional que puede reemplazar la convolución como una primitiva informática independiente para la clasificación de imágenes. Al igual que Transformers, utiliza atención de producto escalable y atención de múltiples cabezales.

De manera similar a las convoluciones, las convoluciones con atención aumentada son 1) equivalentes a la traducción y 2) pueden operar fácilmente con entradas de diferentes dimensiones espaciales.
11. PP-OCR
PP-OCR es un sistema OCR que consta de tres partes: detección de texto, detección de corrección de cuadros y reconocimiento de texto. El propósito de la detección de texto es localizar áreas de texto en imágenes. En PP-OCR, la binarización diferenciable (DB) se utiliza como detector de texto basado en una red de segmentación simple. Integra extracción de características y modelado de secuencias. Emplea pérdida de clasificación temporal conexionista (CTC) para evitar inconsistencias entre predicciones y etiquetas.

12.Unidades de agregación desplazadas
Las unidades de agregación permutadas reemplazan las capas convolucionales clásicas en ConvNet con ubicaciones de unidades que se pueden aprender. Esto introduce una estructura explícita de composición jerárquica y aporta varios beneficios:
Logre campos receptivos totalmente sintonizables y aprendibles a través de unidades de filtro ajustables espacialmente.
Reduzca los parámetros de cobertura espacial para una inferencia eficiente.
Desacople los parámetros del tamaño del campo receptivo.
Trece, convolución dimensional


14. Capa de relación local
La capa de relación local es un extractor de características de imagen y una alternativa al operador de convolución. Intuitivamente, la agregación en convolución es básicamente un proceso de coincidencia de patrones que aplica filtros fijos, lo cual resulta ineficiente cuando se modelan elementos visuales con diferentes distribuciones espaciales. La capa de relación local determina de forma adaptativa el peso de agregación de acuerdo con la relación de composición de los pares de píxeles locales. Se argumenta que a través de este enfoque relacional, se pueden combinar elementos visuales en entidades de nivel superior de una manera más eficiente, facilitando así el razonamiento semántico.
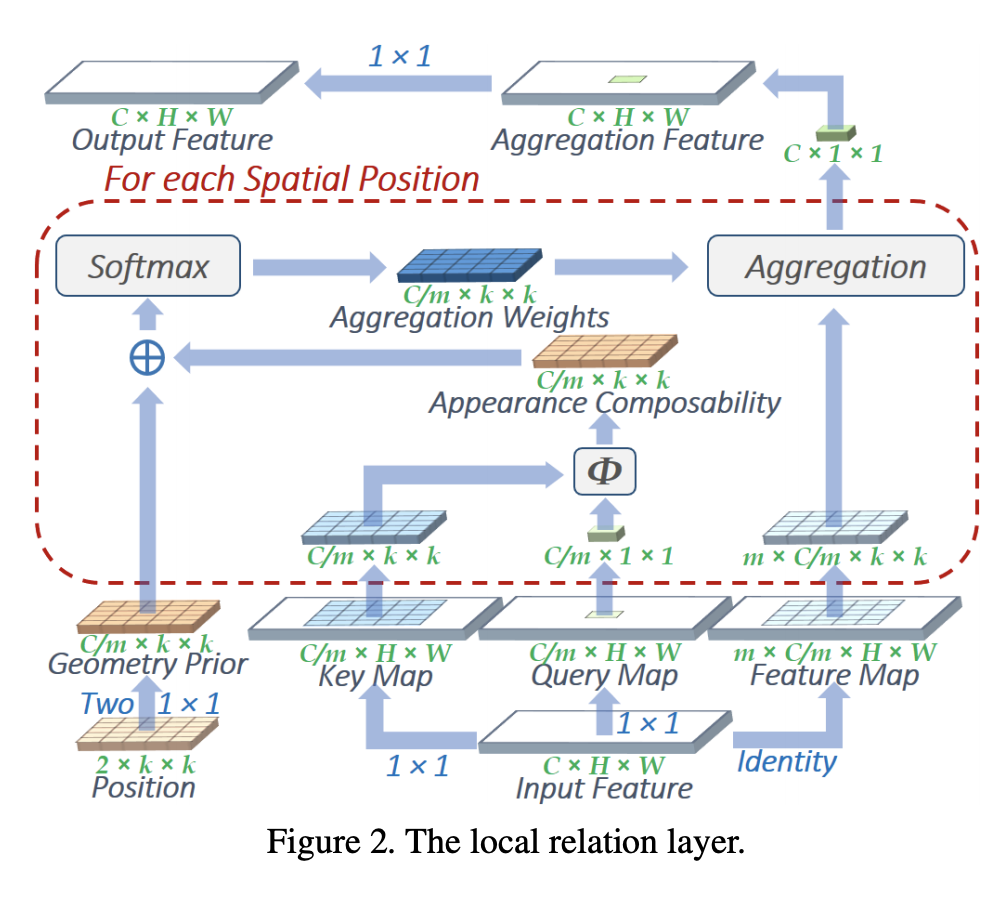
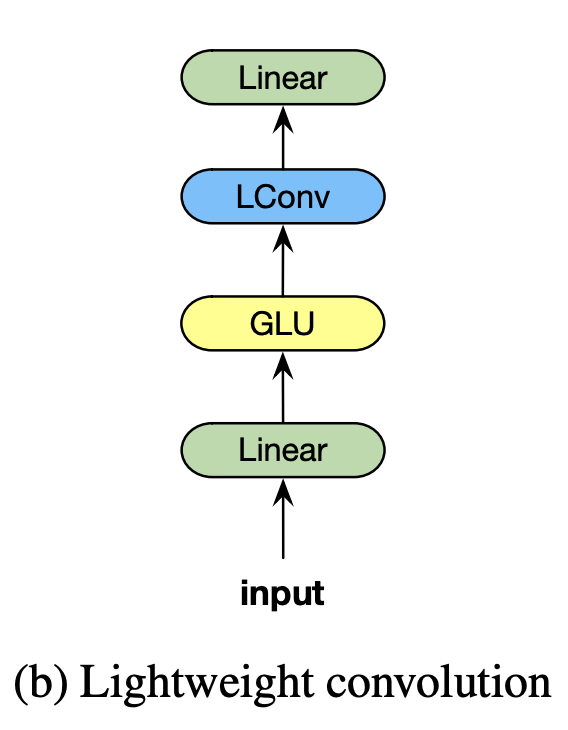
15. Convolución ligera
LightConv es una convolución profunda para modelado secuencial que comparte algunos canales de salida y utiliza softmax para normalizar los pesos en la dimensión temporal. En comparación con la autoatención, LightConv tiene una ventana de contexto fija, que determina la importancia de los elementos contextuales a través de un conjunto de pesos que no cambian con los pasos de tiempo. LightConv calcula la siguiente secuencia y el primer elemento en el canal de salida:
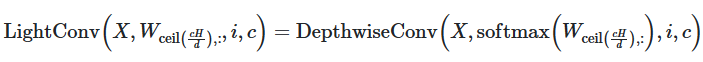
16. hamburguesa
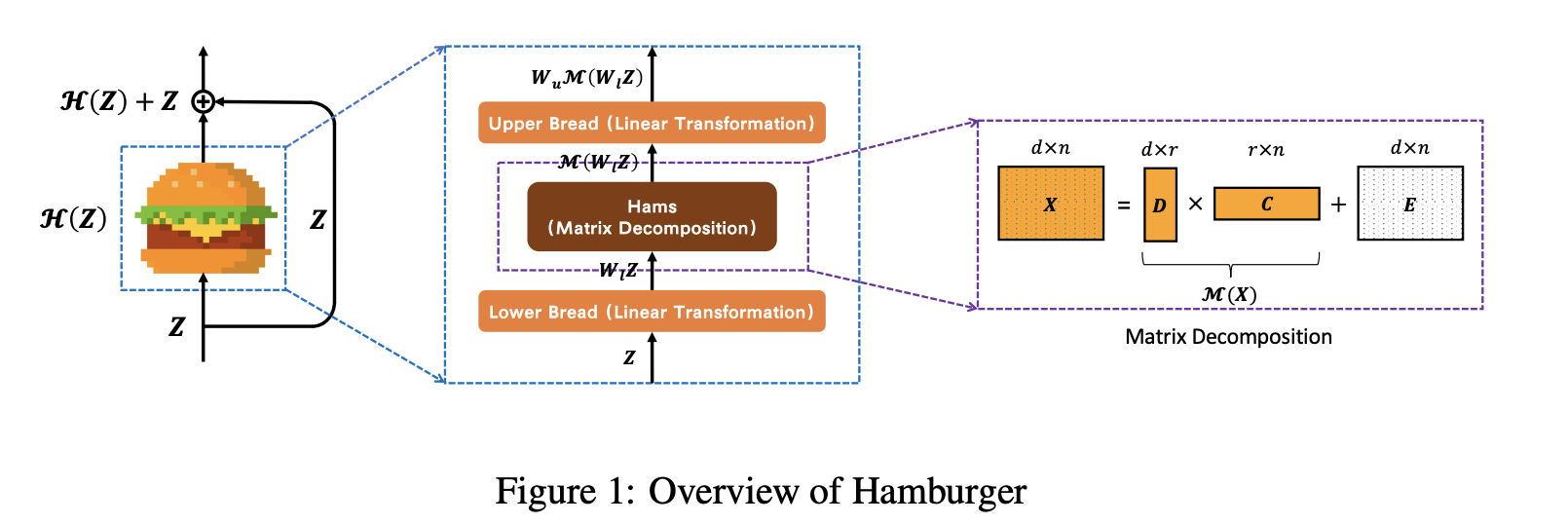
Hamburger es un módulo de contexto global que emplea factorización matricial para descomponer la representación aprendida en submatrices, recuperando así un subespacio de señal limpio de bajo rango. La idea clave es que si formulamos un sesgo inductivo como el contexto global como una función objetivo, entonces un algoritmo de optimización que minimice la función objetivo puede construir un gráfico computacional, la arquitectura que necesitamos en la red.
Decimoséptimo, convolución dinámica basada en intervalos
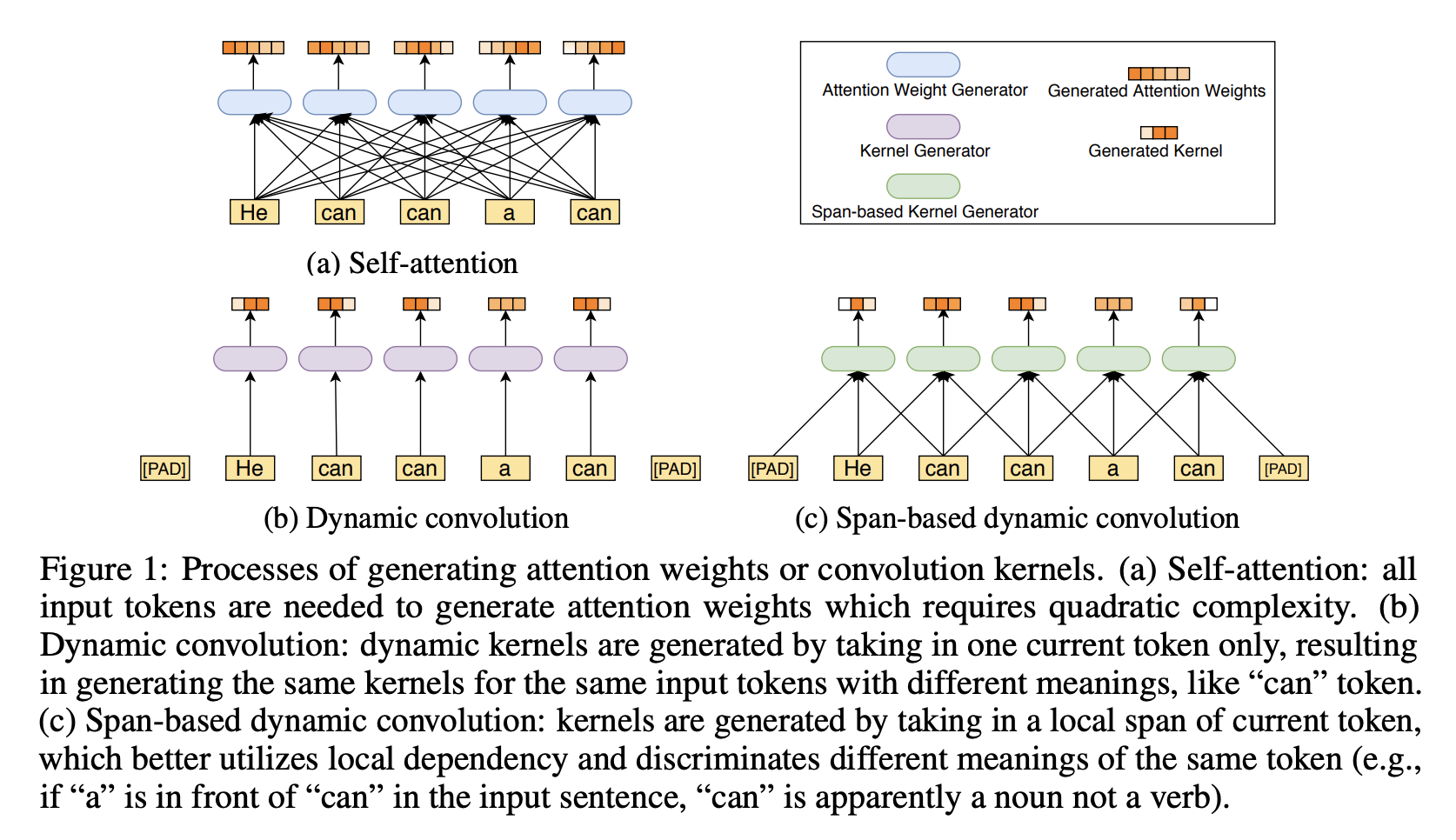
La convolución dinámica basada en pasos es un tipo de convolución utilizada en la arquitectura ConvBERT para capturar dependencias locales entre marcadores. El kernel se genera obteniendo el alcance local del token actual, que explota mejor las dependencias locales y distingue diferentes significados del mismo token (por ejemplo, si "a" va antes de "can" en la oración de entrada, entonces "can" es obviamente sustantivo más que verbo).
Específicamente, utilizando la convolución clásica, compartiremos parámetros fijos para todos los tokens de entrada. Por lo tanto, es preferible la convolución dinámica debido a su mayor flexibilidad para capturar las dependencias locales de diferentes marcadores. La convolución dinámica utiliza un generador de kernel para generar diferentes kernels para diferentes tokens de entrada. Sin embargo, esta convolución dinámica no puede distinguir el mismo token en diferentes contextos y generar el mismo núcleo (por ejemplo, las tres "latas" en la figura (b)).
Por lo tanto, las convoluciones dinámicas basadas en intervalos se desarrollan para producir núcleos convolucionales más adaptables al recibir intervalos de entrada en lugar de solo tokens individuales, lo que permite la diferenciación de núcleos generados para el mismo token en diferentes contextos. Por ejemplo, como se muestra en la Figura (c), la convolución dinámica basada en intervalos genera diferentes núcleos para diferentes tokens "can".
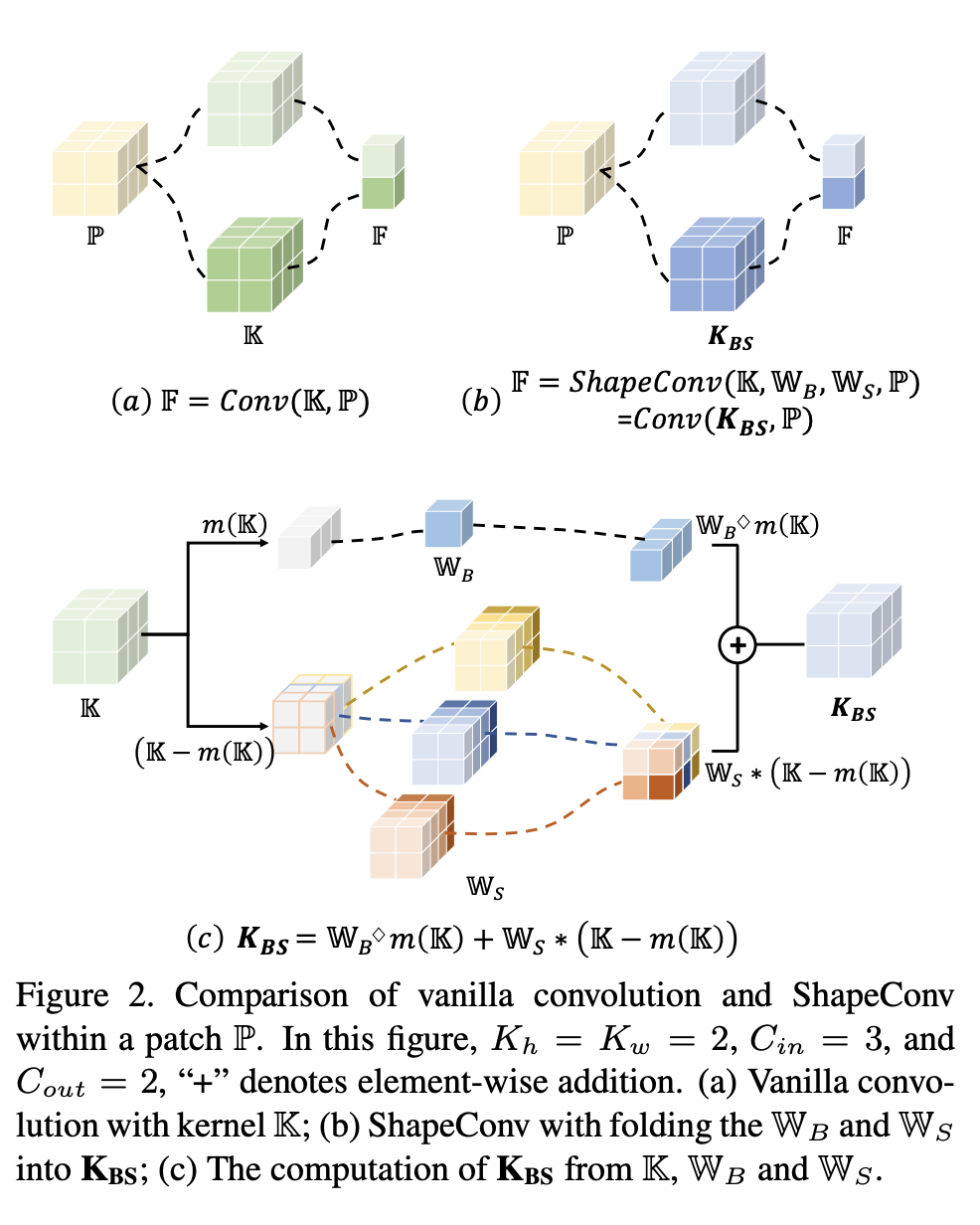
18. Conversión de forma
ShapeConv, la capa convolucional con reconocimiento de forma, es una capa convolucional que se utiliza para procesar características de profundidad en la segmentación semántica RGB-D en interiores. Las características profundas primero se descomponen en componentes de forma y componentes fundamentales, luego se introducen dos pesos que se pueden aprender para ajustarlos de forma independiente y, finalmente, se aplica convolución a la combinación reponderada de estos dos componentes.