Directorio de artículos
BERT: Capacitación previa de transformadores bidireccionales profundos para la comprensión del lenguaje
título

Resumen

GPT considera unidireccional (usando la información de contexto de la izquierda para predecir el futuro) , mientras que BERT usa información de la izquierda y la derecha al mismo tiempo, que es bidireccional.
ELMO usa una arquitectura basada en RNN y BERT usa un transformador, por lo que ELMo necesita hacer algunos ajustes en la arquitectura cuando usa algunas tareas posteriores. Sin embargo, BERT es relativamente simple: al igual que GPT, solo necesita cambiar la capa superior. Entiendo
prefacio
En los modelos de lenguaje, la capacitación previa se puede utilizar para mejorar muchas tareas de lenguaje natural.
Las tareas de lenguaje natural incluyen dos categorías.
Tareas a nivel de oración (nivel de oración): se utilizan principalmente para modelar la relación entre oraciones, como el reconocimiento de emociones de oraciones o la relación entre dos oraciones
Tareas a nivel de token (nivel de token): incluidas entidades Reconocimiento de nombres (reconocer si cada palabra es el nombre de una entidad, como el nombre de una persona o el nombre de una calle), estas tareas requieren la salida de algún resultado detallado a nivel de palabra.
Cuando se utilizan modelos previamente entrenados para la representación de características, generalmente existen dos tipos de estrategias:
- Una estrategia se basa en características y su trabajo representativo es ELMo. Para cada tarea posterior, se construye una red neuronal relacionada con esta tarea . Utiliza la arquitectura RNN y luego combina estas representaciones previamente entrenadas (como incrustaciones de palabras, etc.) .) (u otras cosas) como una característica adicional y entrada al modelo. Se espera que estas características tengan una mejor representación, por lo que el entrenamiento del modelo es relativamente fácil. Esta también es la forma más efectiva de usar modelos previamente entrenados en PNL: enfoque de uso común (junte las características aprendidas con la entrada como una buena expresión de características)
- Otra estrategia se basa en el ajuste fino, aquí está el ejemplo de GPT, es decir, cuando el modelo previamente entrenado se coloca en tareas posteriores, no es necesario cambiar demasiado, solo se requieren un pequeño cambio. Los parámetros previamente entrenados de este modelo se ajustarán en los datos posteriores (todos los pesos se ajustarán en función del nuevo conjunto de datos)
Los dos enfoques anteriores utilizan la misma función objetivo durante el entrenamiento previo y ambos utilizan un modelo de lenguaje unidireccional (dadas algunas palabras para predecir cuál es la siguiente palabra, decir una oración y predecir la siguiente oración) ¿Cuál es la palabra? pertenece a un modelo de predicción y se utiliza para predecir el futuro, por lo que es unidireccional )

en conclusión

Trabajo relacionado

Esta área se usa a menudo en visión por computadora: el modelo a menudo se entrena en ImageNet y luego se usa en otros lugares, pero no es particularmente ideal en PNL (tal vez, por un lado, porque estas dos tareas son bastante diferentes de otras tareas) (por otro lado). (Por otro lado, puede deberse a que la cantidad de datos aún está lejos de ser suficiente). BERT y su serie de trabajos posteriores han demostrado que el modelo entrenado utilizando una gran cantidad de conjuntos de datos sin etiquetar en PNL es más efectivo que el uso de conjuntos etiquetados. en conjuntos de datos más pequeños funcionan mejor . La misma idea está siendo adoptada lentamente por la visión por computadora. Es decir, los modelos entrenados en una gran cantidad de imágenes sin etiquetar pueden ser mejores que aquellos entrenados en 1 millón de imágenes como ImageNet. ¡El conjunto puede funcionar mejor!
modelo BERT
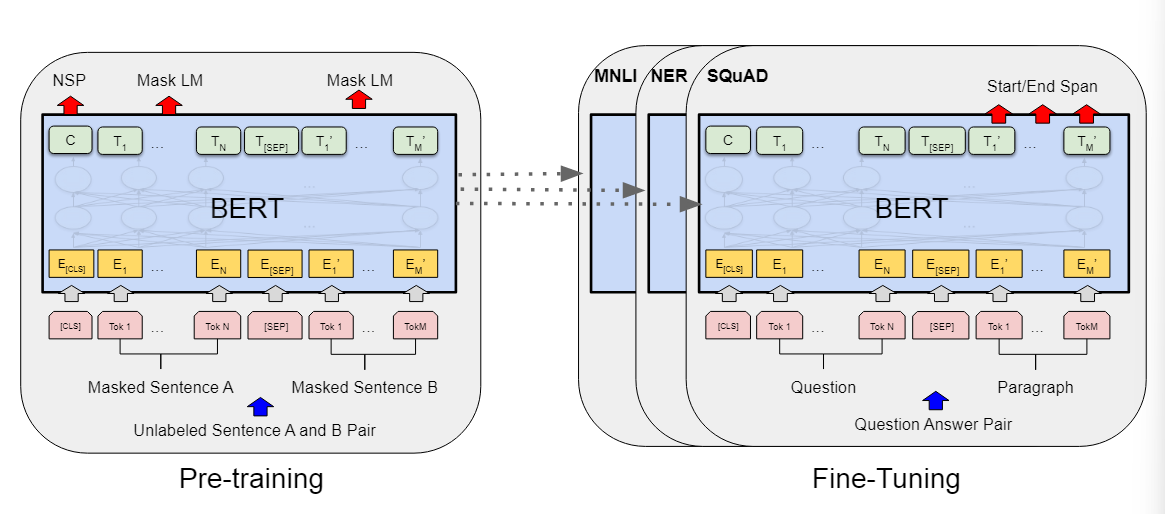
Todos los parámetros se ajustan utilizando datos etiquetados de tareas posteriores. Cada tarea posterior tiene un modelo ajustado independiente, incluso si se inicializan con los mismos parámetros previamente entrenados.
Hay dos pasos en BERT:
- Preentrenamiento: en el preentrenamiento, el modelo se entrena utilizando datos sin etiquetar en diferentes tareas previas al entrenamiento .
- Ajuste fino: durante el ajuste fino, también se utiliza un modelo BERT, pero sus pesos se inicializan con los pesos obtenidos en el entrenamiento previo . Todos los pesos participarán en el entrenamiento durante el ajuste fino, utilizando datos etiquetados.
Durante el entrenamiento previo, la entrada son algunas oraciones sin etiquetar.
Aquí, se entrena un modelo BERT con datos sin etiquetar y se entrenan sus pesos. Para las tareas posteriores, se crea el mismo modelo BERT para cada tarea. modelo, pero el valor de inicialización de su Los pesos provienen de los pesos entrenados en el preentrenamiento anterior, cada tarea tendrá sus propios datos etiquetados, y luego se continuará entrenando BERT, obteniendo así la versión BERT para una determinada tarea.
Arquitectura modelo

¿Qué tres parámetros se ajustan en el modelo?
L: el número de bloques de transformación
H: tamaño oculto
A: el número de cabezas en el multicabezal del mecanismo de autoatención
Digresión:

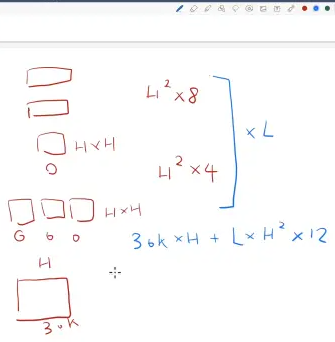
Los tres cuadrados pequeños son Q, K y V.
- Para las matrices de proyección de Q, K y V: la dimensión de cada matriz de proyección es H*64 (suponiendo que la dimensión de cada cabeza sea 64). Como hay cabezales A, el número total de parámetros es 3 (Q, K y V) * A * H * 64
- Matriz de proyección de salida de atención personal: la dimensión de esta matriz también es H * H.
Número de parámetros = 3 * A * H * 64 + H * H = 4 * H * H


Para ilustrar: digamos que tenemos un texto que contiene la palabra "infelicidad". Utilizando métodos tradicionales de segmentación de palabras, se dividirá en una sola palabra, "infelicidad". Sin embargo, si utilizamos el algoritmo de WordPiece, es posible que divida la palabra en dos subpalabras: "un" y "happiness". Esto se debe a que "des" y "felicidad" son partes comunes: "des" generalmente significa negación y "felicidad" significa felicidad. Este método de segmentación capta mejor el significado del texto.
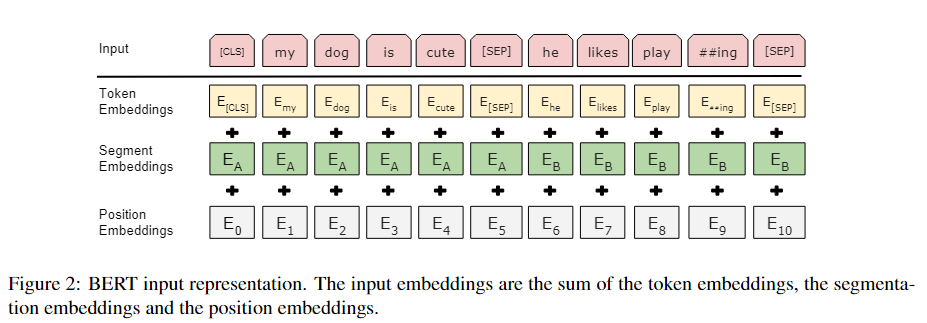
Para cada elemento de palabra que ingresa a la representación vectorial de BERT, es la incrustación del elemento de palabra en sí más la incrustación de la oración en la que se encuentra más la incrustación de la posición, como se muestra en la siguiente figura. La figura anterior demuestra la práctica de incrustación de BERT capa
., Es decir, una secuencia de vectores se obtiene a partir de una secuencia de elementos de palabras. Esta secuencia de vectores ingresará al bloque transformador.
Cada cuadrado en la figura anterior es un elemento de palabras.
- Incrustación de tokens: esta es una capa de incrustación normal que genera su vector correspondiente para cada elemento de palabra.
- incrustación de segmento: indica si es la primera oración o la segunda oración
- incrustación de posición: El tamaño de la entrada es la longitud máxima de la secuencia, su entrada es la información de posición de cada elemento de palabra en la secuencia (comenzando desde cero), obteniendo así el vector de posición correspondiente.
Al final, es la incrustación de cada elemento de palabra en sí más la incrustación en qué oración más la posición en el medio de la oración incrustada
en el transformador. La información de posición es una matriz construida manualmente, pero en BERT, no importa qué oración pertenece, o una posición específica, su representación vectorial correspondiente se obtiene mediante el aprendizaje
Pre-entrenamiento
LM enmascarado

Tenga en cuenta que el propósito de las estrategias de enmascaramiento es reducir la falta de coincidencia entre el preentrenamiento y el ajuste fino, ya que el símbolo [MASK] nunca aparece durante la etapa de ajuste fino.
-fase de sintonización.
El objetivo principal de la estrategia de enmascaramiento es crear una señal de entrenamiento más consistente entre el pre-entrenamiento y el ajuste para mejorar el rendimiento de generalización del modelo. Esto se debe a que existe una cierta discrepancia en la distribución de datos entre el pre-entrenamiento y el ajuste fino. Si no se adopta una estrategia de enmascaramiento, el modelo puede funcionar mal en la fase de ajuste fino porque el conocimiento que aprendió en la fase previa al entrenamiento no puede ser transferido directamente a la tarea de ajuste fino.
Predicción de la siguiente oración (NSP)


Utilice BERT para realizar ajustes


