¿Está justificada la limpieza de datos? Ingeniero fuera de línea ET2 de conversión de grupo de grupo de verificación multidimensional

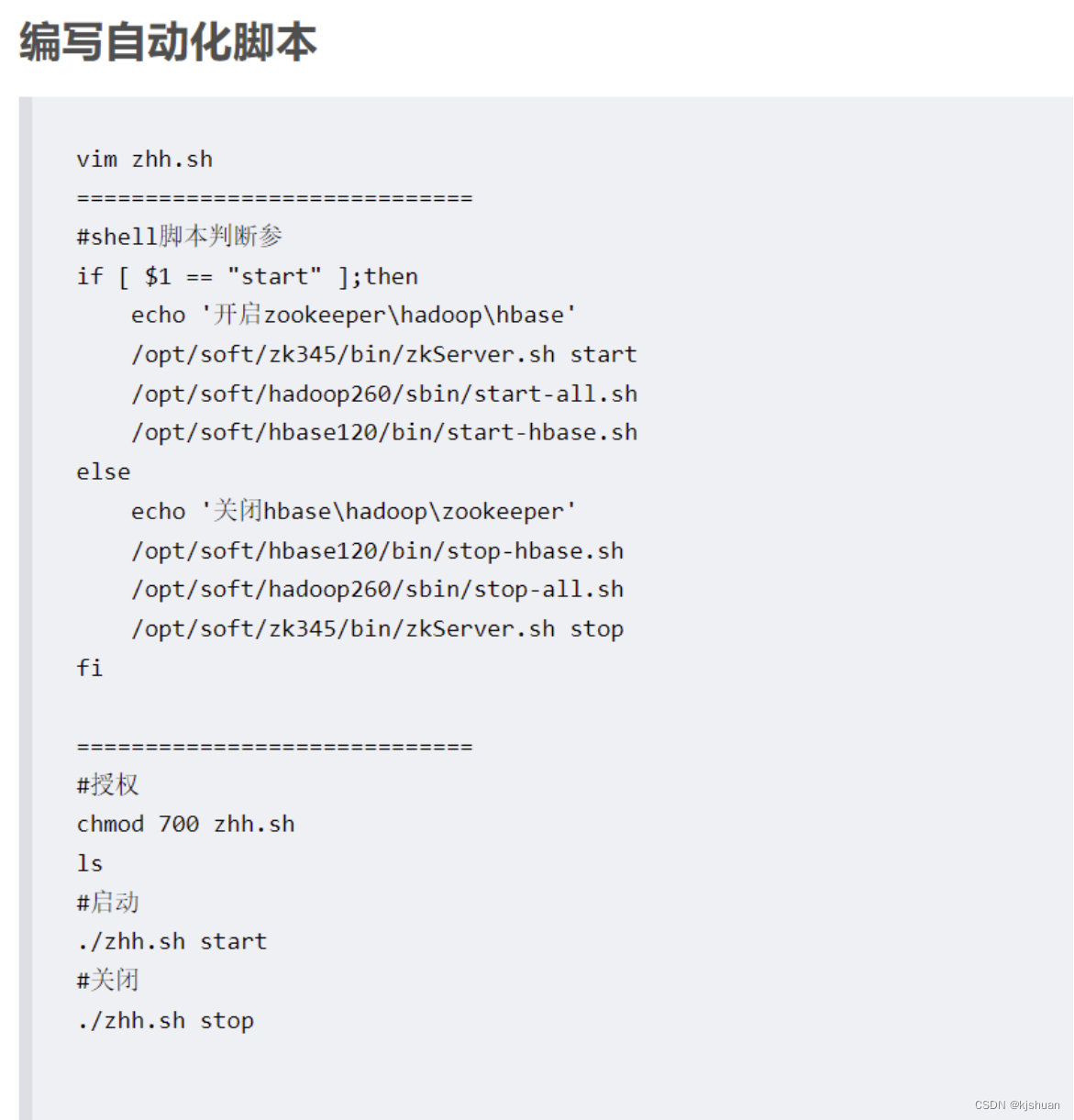
Método 1: utilice RandomAccessFile para descargar el hash del archivo y eliminar duplicados
aplicación de clase pública
{
public static void main( String[] args ) throws Exception {
//Preparar hash
HashMap<String, Integer> map = new HashMap<>();
//Leer archivo
RandomAccessFile raf = new RandomAccessFile("D:\ \bgdata\\bgdata01\\events.csv", "rw");
//Omitir la primera línea
raf.readLine();
//Leer una línea de datos
String line="";
//Bucle para leer datos
while ( (line =raf.readLine())!=null){
//Los datos leídos están separados por comas y la primera
cadena eventid=line.split(",")[0];
//Determina si el mapa contiene id
si (mapa .containsKey(eventid)){
map.put(eventid,map.obtener(eventid)+1);
// De lo contrario, es la primera vez que obtenemos el valor de id y lo configuramos en 1
}else {
map.put(eventid,1);
}
}
//Cerrar el archivo de flujo
raf.close();
//Salir y verificar el tamaño del mapa para ver si hay duplicados
System.out.println(map.size()+" ===== =========");
}
}

Desventajas: los datos del archivo utilizados esta vez fueron 3 millones y la lectura fue muy lenta, tomó alrededor de 30 minutos o (╥﹏╥) o
Se recomienda utilizar el siguiente método.
El método 2 usa Mapreduce para descargar archivos
2.1Configurar el archivo pom
<dependencia> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <versión>2.6.0</versión> </dependencia> <dependencia> <groupId>org.apache.hadoop </groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId> hadoop-hdfs</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <versión>2.6.0</versión> </dependencia>
2.2 Configurar la clase RcMapper
clase pública RcMapper extiende Mapper<LongWritable,Text,Text, IntWritable> {
IntWritable one= new IntWritable(1);
@Override
mapa vacío protegido (clave LongWritable, valor de texto, contexto de contexto) arroja IOException, InterruptedException {
String eventid=value.toString().split(",")[0];
contexto.write(nuevo texto(eventid),uno);
}
}
2.3 Configurar la clase RcReduce
la clase pública RcReduce extiende Reductor<Texto, IntWritable,Text,IntWritable>{
@Override
protected void reduce(Clave de texto, valores Iterable<IntWritable>, contexto de contexto) lanza IOException, InterruptedException {
int count=0;
for (IntWritable it: valores) {
recuento+=1;
}
contexto.write(clave,nuevo IntWritable(recuento));
}
}
2.4 Configurar la clase RcCountDriver
public class RcCountDriver {
public static void main(String[] args) throws Exception {
//Crear una instancia del objeto de trabajo
Job job = Job.getInstance(new Configuration());
//Obtener el objeto a través de la reflexión
job.setJarByClass(RcCountDriver.class );
//
Reflexión para obtener el objeto RcMapper
//Establece el Text.class correspondiente
job.setMapperClass(RcMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//
Reflexión para obtener el objeto RcReduce
// Establezca el Text.class correspondiente
job.setReducerClass(RcReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//
Obtener el archivo de ruta de destino
FileInputFormat.addInputPath(job,new Path("file:///D:\\bgdata\\bgdata01\\events.csv")); //
Marcar la dirección del archivo de descarga
FileOutputFormat.setOutputPath (trabajo, nueva ruta("file:///d:/calres/cal01"));
/
**
*El trabajo se ejecuta a través de job.waitForCompletion(true),
* verdadero significa que el progreso de la ejecución y otra información serán enviar al usuario de manera oportuna,
* Si es falso, simplemente espere a que finalice el trabajo
*/
job.waitForCompletion(true);
}
}
¡Simplemente haga clic para probar! !
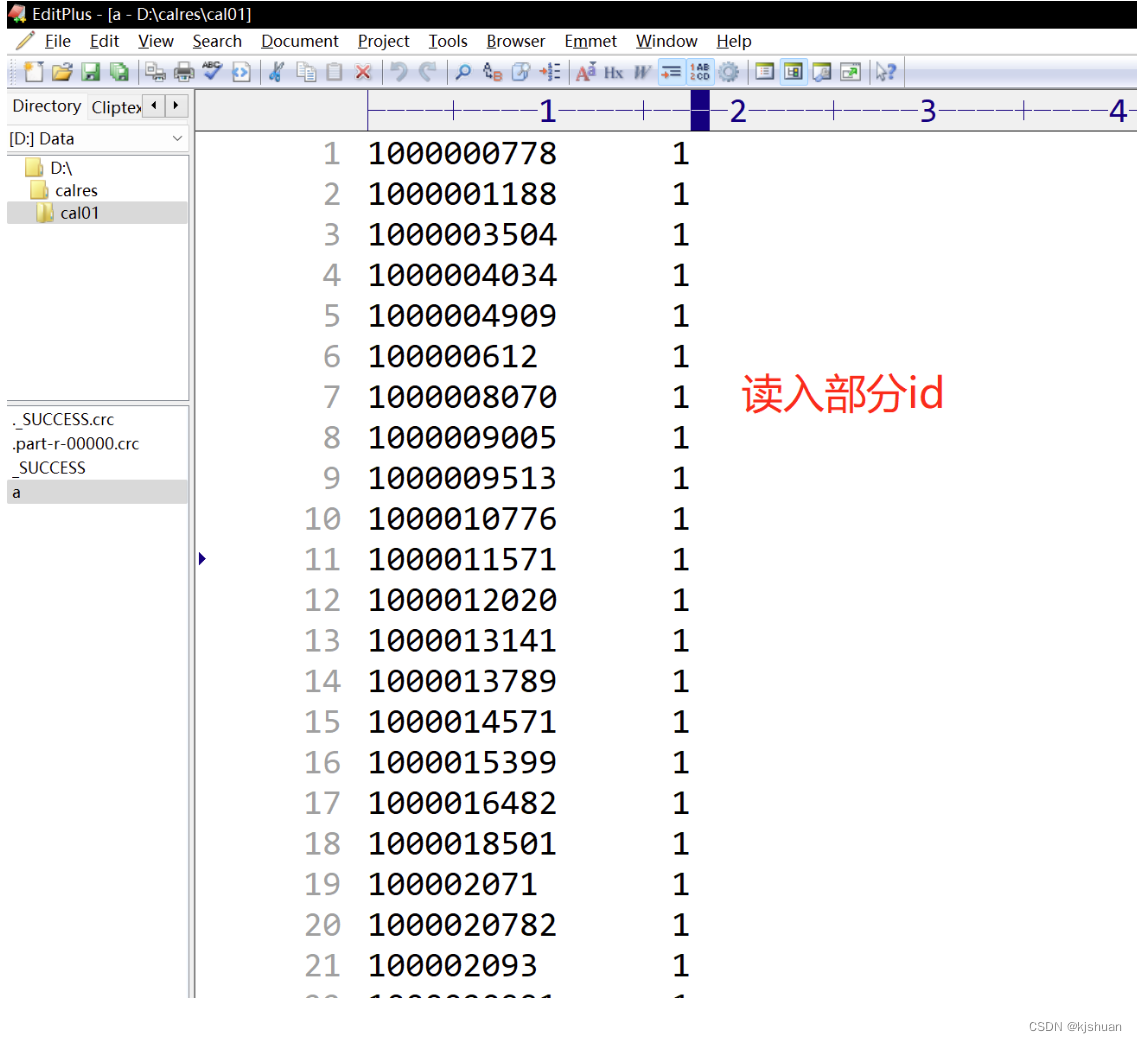
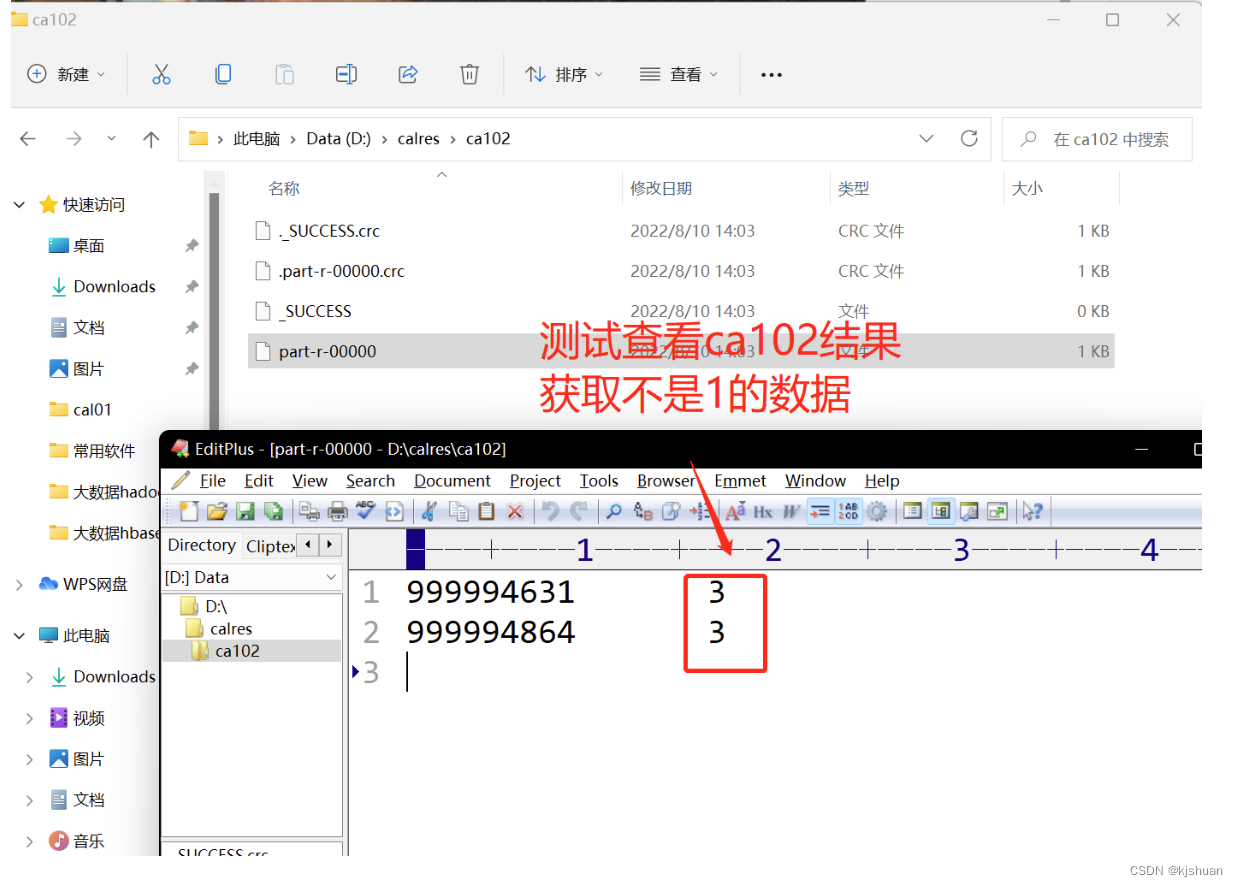
Método 3. Utilice Mapreduce para eliminar duplicados
3.1 Configurar la clase CfMapper
public class CfMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//El valor obtenido está separado por espacios
String[] infos = value . toString().split("\t");
//Operación si el segundo dato no es uno
if (!infos[1].equals("1")){
//Obtener el primer valor, el segundo Quitar espacios a partir de valores distintos de 1
context.write(new Text(infos[0]),new IntWritable(Integer.parseInt(infos[1].trim())));
}
}
}
3.2 Configurar la clase CfCombiner
la clase pública CfCombiner extiende Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Clave de texto, valores Iterable<IntWritable>, contexto de contexto) throws IOException, InterruptedException {
//配置kv键值对
context.write(key ,valores.iterador().siguiente());
}
}
3.3 Configurar la clase CfCountDriver
public class CfCountDriver {
public static void main(String[] args) throws Exception {
//Crear una instancia del objeto de trabajo
Job job = Job.getInstance(new Configuration());
//Obtener el objeto a través de la reflexión
job.setJarByClass(CfCountDriver.class );
//
Reflexión para obtener el objeto CfMapper
//Establece el Text.class correspondiente
job.setMapperClass(CfMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//
Reflexión para obtener el objeto CfCombiner
// Establezca el Text.class correspondiente
// job.setCombinerClass(CfCombiner.class);
job.setReducerClass(CfCombiner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//
Obtener el archivo de ruta de destino
FileInputFormat.addInputPath(job,new Path("file:///d:/calres/cal01/a")); //
Marcar la dirección del archivo de descarga
FileOutputFormat .setOutputPath(job,new Path("file:///d:/calres/ca102/"));
/**
*El trabajo se ejecuta a través de job.waitForCompletion(true),
* true significa que el progreso de la ejecución y otros la información se enviará a tiempo Para el usuario,
* si es falso, simplemente espere a que finalice el trabajo
*/
job.waitForCompletion(true);
}
}
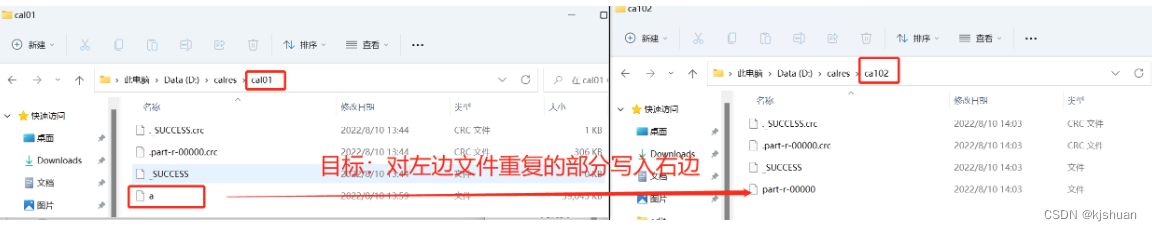
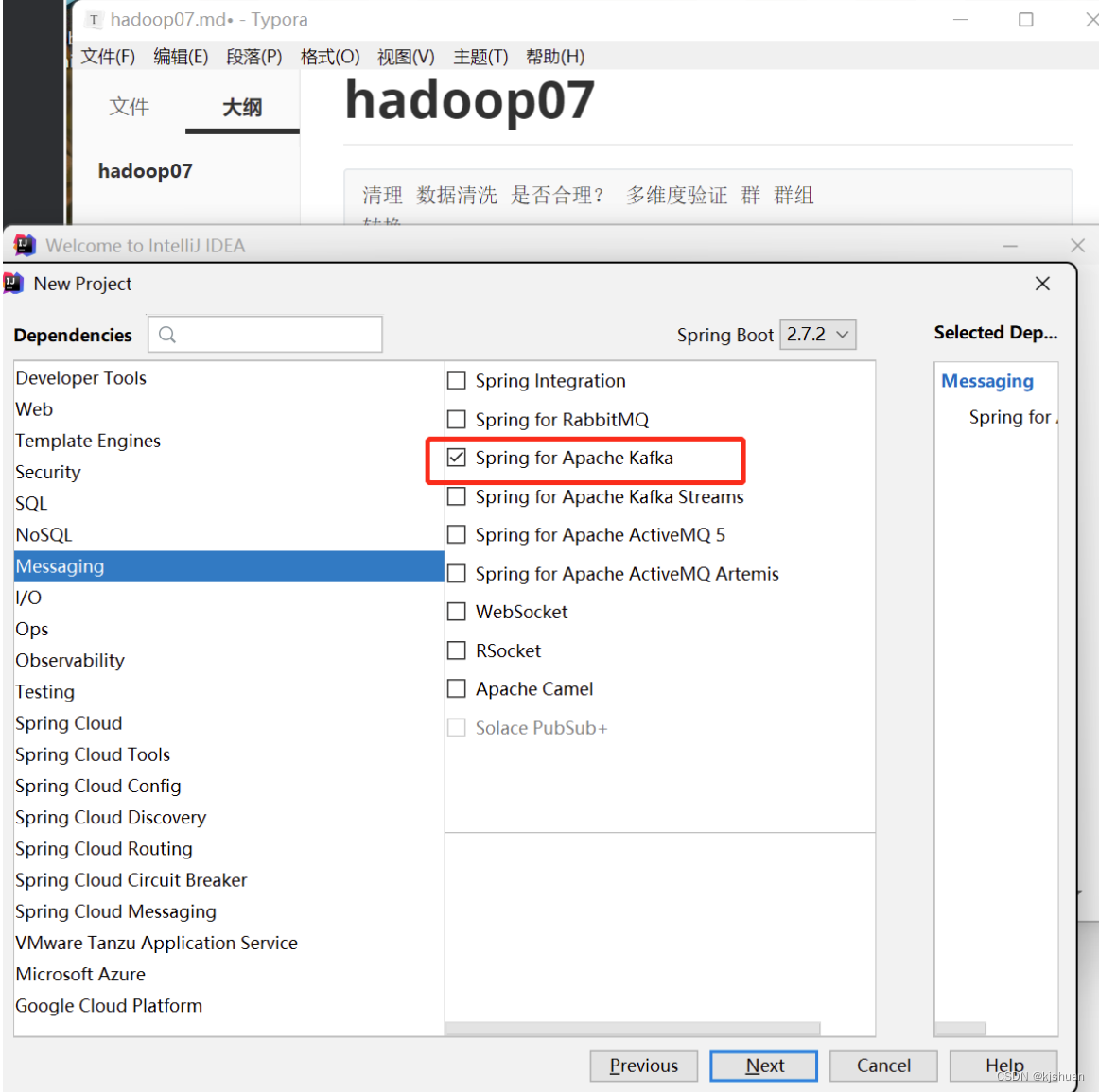
Configuración ideal para la implementación del código Kafka (optimización: modo puente)
1 Importar archivo kafka pom
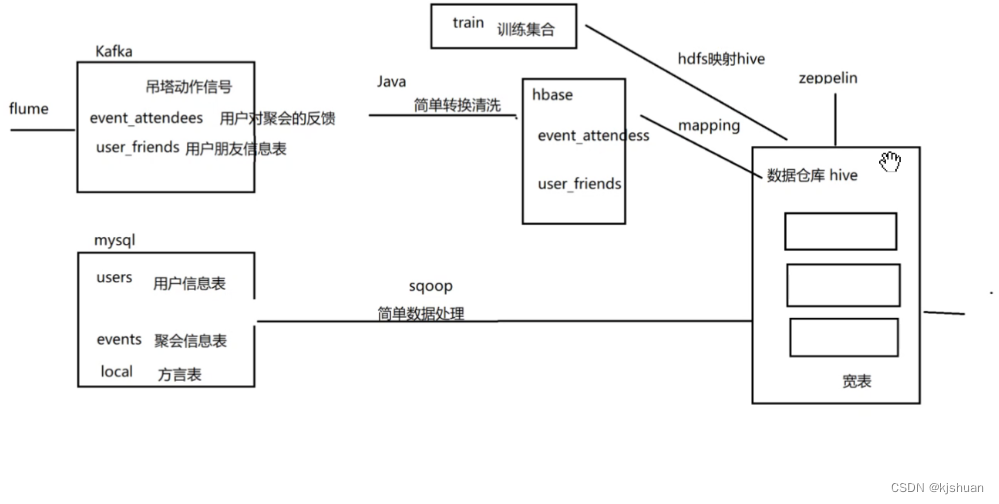
canal extrae datos de la base de datos en tiempo real
2Configurar yml
Envíe manualmente el monitor de serialización de datos leídos desde el principio
servidor: puerto: 8999 primavera: aplicación: nombre: interés del usuario kafka: servidores bootstrap: 192.168.64.210:9092 #acks=0: Independientemente del éxito o el fracaso, envíe solo una vez. No se requiere confirmación #acks=1: es decir, solo necesita confirmar que el líder ha recibido el mensaje #acks=all o -1: ISR + Leader seguramente recibirá al consumidor: #Si se debe confirmar automáticamente la compensación enable-auto-commit: false #Earliest: Sin registro de envío, el consumo comienza desde el principio #latest: Sin registro de envío, el consumo comienza desde el siguiente mensaje más reciente auto-offset-reset: más antiguo #Método de codificación y decodificación de claves deserializador de claves: org.apache.kafka.common.serialization.StringDeserializer #método de codificación y decodificación de valores value-deserializer: org.apache.kafka.common.serialization.StringDeserializer #Configurar el oyente oyente: #Cuando el valor de enable.auto.commit se establece en falso, el valor tendrá efecto ; cuando sea verdadero, no tendrá efecto. # manual_immediate: debe llamar manualmente a Acknowledgment.acknowledge() para enviar un reconocimiento -modo: manual_inmediato
3. Configurar la plantilla del modo puente
3.1 Clase de interfaz en modo puente
interfaz pública FillHbaseData<T> extiende FillData<Put,T> {
List<Put> fillData(List<T> lis);
}
/
**
* Convertir formatos de datos según diferentes datos de usuario y modelos de clase de entidad entrantes Interfaz
* @param < T>
*/
interfaz pública StringToEntity<T> {
Lista<T> cambio(línea de cadena);
}
3.2 Clase de implementación del modo puente
# EventAttendessFillDataImpl类 public class EventAttendessFillDataImpl implements FillHbaseData<EventAttendees> { @Override public List<Put> fillData(List<EventAttendees> lst) { List<Put> puts = new ArrayList<>(); lst.stream().forEach(ea->{ Put put = new Put((ea.getEventid() + ea.getUserid() + ea.getAnswer()).getBytes()); put.addColumn("base" .getBytes(),"eventid".getBytes(),ea.getAnswer().getBytes()); put.addColumn("base".getBytes(),"userid".getBytes(),ea.getAnswer(). getBytes()); put.addColumn("base".getBytes(),"answer".getBytes(),ea.getAnswer(). getBytes()); pone.add(poner); }); devolución pone; } } # EventFillDataImpl类 public class EventFillDataImpl implements FillHbaseData<Events> { @Override public List<Put> fillData(List<Events> lis) { List<Put> puts = new ArrayList<>(); lis.stream().forEach( evento -> { Put put = new Put(event.getEventid().getBytes()); put.addColumn("base".getBytes(),"userid".getBytes(),event .getUserid().getBytes()); put.addColumn("base".getBytes(),"starttime".getBytes(),event.getStarttime().getBytes()); put.addColumn("base". put.addColumn("base".getBytes(),"zip".getBytes(),event.getZip().getBytes()); put.addColumn("base".getBytes(),"estado".getBytes(),event.getState().getBytes()); put.addColumn("base".getBytes(),"país".getBytes(),event.getCountry().getBytes()); put.addColumn("base".getBytes(),"lat".getBytes(),event.getLat().getBytes()); put.addColumn("base".getBytes(),"lng".getBytes(),event.getLng().getBytes()); pone. getBytes()); }); devolver nulo; } } # EventAttendeesChangeImpl类 public class EventAttendeesChangeImpl implements StringToEntity<EventAttendees> { / ** * Los datos ingresan como eventid si tal vez invitado no * ex:123,112233,34343,234234,45454,112233,23232,234234,3434343,34343 * Convertir los datos formato Para 123 112233 sí, 123 34343 sí, 123 234234 tal vez... * @param line * @return */ @Override public List<EventAttendees> change(String line) { String[] infos = line.split(" ," , -1); List<EventAttendees> eas = new ArrayList<>(); //Primero cuenta todas las personas que respondieron que sí if (infos[1].trim().equals("")&&infos[1]! = nulo){ Arrays.asList(información[1].dividir(" ")).stream().forEach( yes->{ EventAttendees ea = EventAttendees.builder() .eventid(infos[0]).userid(yes).answer("yes") .build(); eas.add(ea); }); } //先计算所有回答maybe的人 if (infos[2].trim().equals("")&&infos[2]!=null){ Arrays.asList(infos[2].split(" ")) .stream().forEach( tal vez->{ EventAttendees ea = EventAttendees.builder() .eventid(infos[0]).userid(tal vez).answer("tal vez") .build(); eas.add(ea); }); } //Primero calcula todas las personas que respondieron invitadas if (infos[3].trim().equals("")&&infos[3]!=null){ Arrays.asList( infos [3].split(" ")).stream().forEach( invitado->{ EventAttendees ea = EventAttendees.builder() .eventid(infos[0]).userid(invitado).answer("invitado") . build(); eas.add(ea); }); } //Primero calcula todas las personas que respondieron que no if (infos[4].trim().equals("")&&infos[4]!=null) { Arrays.asList(infos[4].split(" ")).stream().forEach( no->{ EventAttendees ea = EventAttendees.builder() .eventid(infos[0]).userid(no).answer( "no") .build(); eas.add(ea); }); } devolver fácil; } } # EventsChangeImpl类 public class EventsChangeImpl implements StringToEntity<Events> { @Override public List<Events> cambio(String line) { String[] infos = line.split(",", -1); Lista<Eventos> eventos=new ArrayList<>(); Eventos evento = Events.builder().eventid(infos[0]).userid(infos[1]).starttime(infos[2]) .city(infos[3]).state(infos[4]). zip (información[5]).country(información[6]) .lat(información[7]).lng(información[8]).build(); eventos.add(evento); devolver eventos; } } # UserFriendsChangeImpl类 /** * 将将123123, 123435 435455 345345 => 123123, 123435 123123,435455 123123, 345345 * / public class UserFriendsChangeImpl implementa StringToEntity<User Amigos> { @Override lista pública<UserFriends> cambio(Cadena línea) { String[] infos = line.split(","); Lista<UserFriends> ufs = new ArrayList<>(); Arrays.asList((infos[1]).split(" ")).stream().forEach( fid->{ UserFriends uf = UserFriends.builder().userid(infos[0]).friendid(fid). construir(); ufs.add(uf); } ); devolver ufs; } }
3.3 Clase abstracta en modo puente
/** * #3.3.1 AbstractDataChanage抽象类 * 桥梁模式中的抽象角色 */ clase abstracta pública AbstractDataChanage<E,T> implementa DataChanage<T> { protected FillData<E,T> fillData; protected StringToEntity<T> stringToEntity; public AbstractDataChanage(FillData<E, T> fillData, StringToEntity<T> stringToEntity) { this.fillData = fillData; this.stringToEntity = stringToEntity; } @Override lista abstracta pública<T> cambio(línea de cadena); relleno vacío abstracto público /** * #3.3.2 Interfaz DataChanage * Interfaz de conversión de datos Los datos Kafka se convierten a formatos de datos comunes * (si hay varias bases de datos de Redis Hbase Oracle, se debe escribir una interfaz de llenado) * @param <T> * / interfaz pública List<T> cambio(String line); } # 3.3.3 Clase DataChangeFillHbaseDatabase clase pública DataChangeFillHbaseDatabase<T> extiende AbstractDataChanage<Put,T> { public DataChangeFillHbaseDatabase( FillData<Put,T> fillData, StringToEntity<T > stringToEntity) { super(fillData,stringToEntity); } @Override public List<T> change(String line){ return stringToEntity.change(line); } @Override public void fill(ConsumerRecord<String,String> record){ //Leer el ConsumerRecord obtenido por kafka y convertirlo en un string List< Put> puts = fillData.fillData(change(record.value())); //Completa la colección en la base de datos hbase correspondiente } } # 3.3.4 Interfaz FillData public interface FillData<T,E> { List< T> fillData(Lista<E> lst); }
3.4 Modo puente

Resumen fábrica a, fábrica abc, 3 productos, fábrica b, fábrica abc, 3 productos
4. Escribe clases de entidad.
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class EventAttendees {
cadena privada eventid;
ID de usuario de cadena privada;
respuesta de cadena privada;
}
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class Eventos {
cadena privada eventid;
ID de usuario de cadena privada;
hora de inicio de cadena privada;
ciudad privada de cuerdas;
estado de cadena privada;
zip de cadena privada;
país de cadena privada;
cadena privada lat;
longitud de cadena privada;
}
@Datos
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class UserFriends {
cadena privada ID de usuario;
ID de amigo de cadena privada;
}
5.Escribir clase de configuración
@Configuration
clase pública HbaseConfig { @Bean
public org.apache.hadoop.conf.Configuration hbaseConfiguration(){
org.apache.hadoop.conf.Configuration cfg= HBaseConfiguration.create();
cfg.set(HConstants.ZOOKEEPER_QUORUM,"192.168.64.210:2181");
return cfg;
}
@Bean
@Scope("prototipo")
Conexión pública getConnection() {
Conexión conexión=null;
intente {
conexión = ConnectionFactory.createConnection(hbaseConfiguration());
} captura (IOException e) {
e.printStackTrace();
}
conexión de retorno;
} @Bean
proveedor público<Conexión> hbaseConSupplier(){
return ()->{
return getConnection();
};
}
}
5.1 Resolver la duplicación de datos hbase
hbase subyacente kv k es la clave de fila y la clave de fila es nombre de usuario + amigo 5.2 ¿La cantidad de datos es demasiado grande? Más de 30w, docenas de g, 3000w de datos, aproximadamente varios g, subbase de datos, tabla, partición vertical 10g función hbase función de prepartición partición oracle rango de partición hash partición lista de particiones
5.2 Clases de servicio de redacción
#5.2.1 /** * Acepte el conjunto de datos List<Put> convertido para completar la base de datos Hbase */ @Component public class HbaseWriter { @Resource private Connection hbaseConnection; public void write(List<Put> puts,String tableName ){ try { Table table = hbaseConnection.getTable(TableName.valueOf(tableName)); table.put(puts); } catch (IOException e) { e.printStackTrace(); } } } # 5.2.2 @Component clase pública KafkaReader { @KafkaListener (groupId = "cm", temas = {"events_raw"}) public void readEventToHbase(ConsumerRecord<String ,String > record, Acknowledgement ack){ AbstractDataChanage<Put,Events> eventsHandler = new DataChangeFillHbaseDatabase<Events>( new EventFillDataImpl(), new EventsChangeImpl() ); eventsHandler.fill(registro); reconocimiento.reconocimiento(); } @KafkaListener(groupId = "cm",topics = {"event_attendees_raw"}) public void readEventToHbase1(ConsumerRecord<String ,String > record, Acknowledgement ack){ AbstractDataChanage<Put, nuevo EventAttendeesChangeImpl() ) ; eventsHandler.fill(registro); reconocimiento.reconocimiento(); } @KafkaListener(groupId = "cm",topics = {"user_friends_raw"}) public void readEventToHbase2(ConsumerRecord<String ,String > record, Acknowledgement ack){ AbstractDataChanage<Put, UserFriends> eventsHandler = new DataChangeFillHbaseDatabase<UserFriends>( new UserFriendsFillDataImpl (), nuevo UserFriendsChangeImpl() ) ; eventsHandler.fill(registro); reconocimiento.reconocimiento(); } }
6 Crear grupo de columnas en la base de datos hbase
# Calcule automáticamente la división en función del número requerido de regiones y el algoritmo de división
cree 'userfriends','base',{ NUMREGIONS => 3, SPLITALGO =>'HexStringSplit' }
============ ==
================================================== == ====== Descripción de NUMREGIONS :
el tamaño predeterminado del archivo
Hbase de hbase
Los datos de origen
son Hive: número recomendado de particiones ≈ tamaño HDFS/10G * 10 * 1.2
HexStringSplit
, UniformSplit, DecimalStringSplit Descripción:
UniformSplit
(ocupación de espacio pequeño, prefijo de clave de fila completamente aleatorio •••••••): un agregado que divide uniformemente el espacio de posibles claves. Esto se recomienda cuando las claves son bytes aleatorios aproximadamente consistentes (como hashes). Las filas son valores de bytes sin formato en el rango 00 => FF, rellenados a la derecha con 0 para mantener el mismo orden de memcmp(). Este es un algoritmo natural para un entorno de bytes[] y ahorra espacio, pero no es necesariamente el más simple en términos de legibilidad.
HexStringSplit (ocupa mucho espacio, la clave de fila es una cadena hexadecimal como prefijo •••••••): HexStringSplit es un RegionSplitter.SplitAlgorithm típico para seleccionar el límite de la región. El formato de los límites de la región HexStringSplit es una representación ASCII de una suma de comprobación MD5 o cualquier otro valor hexadecimal distribuido uniformemente. La fila es un valor largo codificado en hexadecimal en el rango "00000000" => "FFFFFFFF", rellenado a la izquierda con 0 para que permanezca lexicográficamente en el mismo orden que el binario. Debido a que este algoritmo de división utiliza cadenas hexadecimales como claves, es fácil de leer y escribir en el shell, pero ocupa más espacio y puede no ser intuitivo.
DecimalStringSplit: filakey es una cadena decimal como prefijo
======================================= === ==============================
crear
'eventAttendees','base'
cat
events.csv.COMPLETED | head -2
cd
/opt/data/attendes
cat event_attendees_raw |head -2
crea
'eventos' 'base'
6.1 comando de inicio de hbase
#hbaseStart start-hbase.sh o inicia el script. ! ! ! El script es el siguiente #Dirección del navegador http://192.168.64.210: 60010 /master-status