Каталог статей
- 1. ActionVLAD: изучение пространственно-временной агрегации для классификации действий [код](https://github.com/rohitgirdhar/ActionVLAD/)[](https://github.com/rohitgirdhar/ActionVLAD/)
- 2. Детектор Action Tubelet для пространственно-временной локализации действия [код] (https://github.com/qinzhi-0110/pytorch-act-detector)
- 3. Пространственно-временной вектор локально максимальных объединенных функций для распознавания действий в видео
- 4. Трубчатая сверточная нейронная сеть (T-CNN) для обнаружения действий в видео [код] (https://github.com/kirilllzaitsev/Action_detection/blob/master/action_detection/model.py)
1. ActionVLAD: изучение пространственно-временной агрегации для кода классификации действий.
Резюме и заключение
- Классификация действий, агрегирование локальных сверточных характеристик во всем пространственно-временном диапазоне видео.
- Объединение двухпотоковых сетей и обучаемой агрегации пространственно-временных функций, сквозное
- Объединение и объединение сигналов из разных потоков в пространстве и времени. объединение в пространстве и времени и объединение сигналов из разных потоков.
- (i) Совместное объединение в пространстве и времени важно, но (ii) потоки внешнего вида и движения лучше всего агрегировать в отдельные представления. (i) важно объединять совместно в пространстве и времени, но (ii) потоки внешнего вида и движения лучше всего агрегировать в отдельные представления.
Введение: определение болевых точек и вкладов
Болевые точки:
- Анализируются как 3D-сверточные, так и двухпотоковые сети: каковы подходящие пространственно-временные представления для видеомоделирования? 3D-пространственно-временная свертка , которая потенциально изучает сложные пространственно-временные зависимости , но до сих пор ее трудно масштабировать с точки зрения производительности распознавания ; двухпотоковая архитектура, которая разлагает видео на поток движения и поток внешнего вида и обучает отдельную CNN для каждого потока, и, наконец, плавкий выход. Хотя оба подхода добились быстрого прогресса, двухпотоковые архитектуры обычно превосходят пространственно-временные свертки, поскольку они могут легко использовать новые сверхглубокие архитектуры и модели, предварительно обученные для классификации статических изображений. Однако двухпотоковые архитектуры в значительной степени игнорируют долгосрочную временную структуру видео, по сути изучая классификатор, который работает с одним кадром или короткими блоками из нескольких (до 10) кадров, что потенциально приводит к достижению консенсуса различными оценками классификации. .
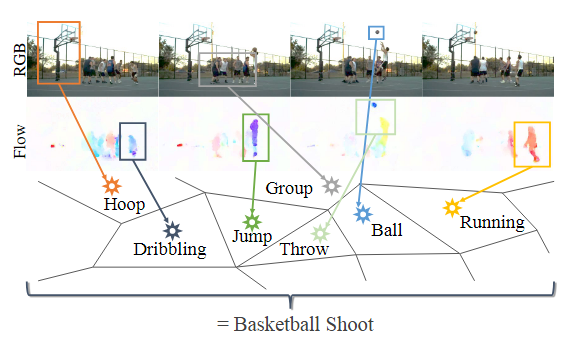
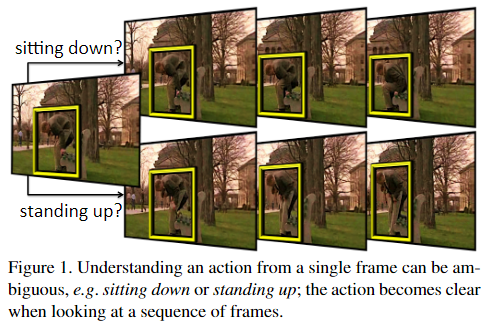
- Независимая классификация и объединение фреймов не могут точно моделировать действия : может ли временное усреднение моделировать сложную пространственно-временную структуру человеческого поведения. Эта проблема усугубляется, когда одно и то же поддействие используется несколькими классами действий. Например, рассмотрим сложное составное действие «баскетбольного броска», показанное на рисунке 1. Учитывая всего лишь несколько последовательных видеокадров, его легко можно спутать с другими действиями, такими как «бег», «ведение», «прыжки» и «броски».
способствовать:
- Слой ActionVLAD CNN, который может помочь в смежных задачах, таких как (пространственно-временная) временная локализация действий человека в длинных видеороликах.
- (1) Мы разрабатываем мощные представления на уровне видео, интегрируя обучаемую пространственно-временную агрегацию с современной двухпоточной сетью. (2) Мы изучаем различные стратегии объединения и комбинирования сигналов из разных потоков в пространстве и времени, предоставляя идеи и экспериментальные доказательства для различных вариантов дизайна.
- Лучше, чем базовый уровень:
Связанных с работой
Обучаемая пространственно-временная агрегация: это
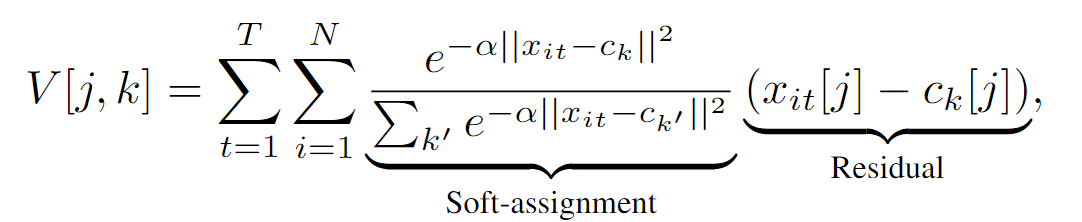
 достигается путем разделения дескрипторного пространства RD на K единиц с использованием словаря из K «слов действия», представленных опорными точками {ck} (рис. 3 ©).
достигается путем разделения дескрипторного пространства RD на K единиц с использованием словаря из K «слов действия», представленных опорными точками {ck} (рис. 3 ©).
модельная основа
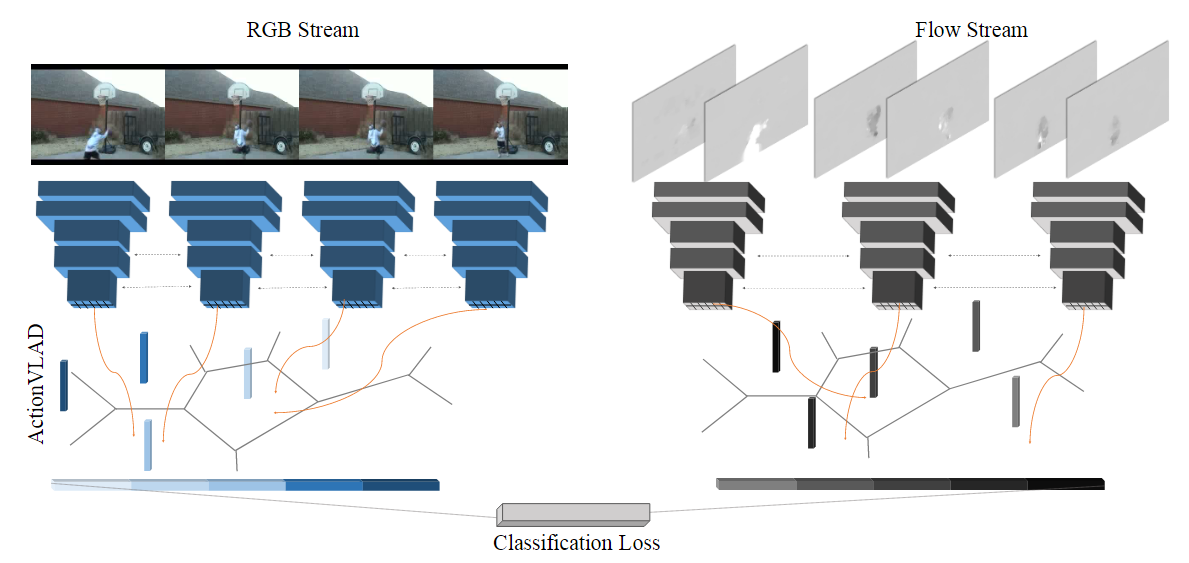
Характеристики извлекаются из выборочных кадров внешнего вида и движения видео с использованием стандартной архитектуры CNN (VGG-16). Затем эти функции объединяются в пространстве и времени с помощью уровня объединения ActionVLAD, который можно обучать сквозным образом с потерей классификации.
Какой слой агрегировать?
Оценка (а) ActionVLAD на разных позициях в сети VGG-16;
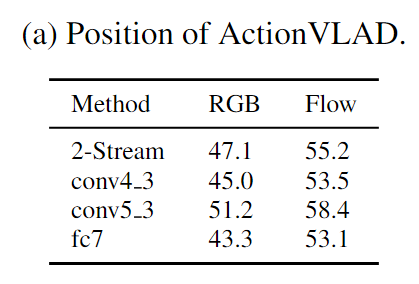
использование двухпоточной сети (предварительно обученной на уровне кадра) в качестве генератора признаков для подачи на наш обучаемый слой объединения ActionVLAD из входных данных разных кадров. Но активации какого слоя мы объединяем?
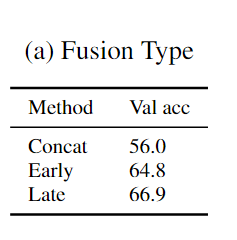
Как объединить потоки Flow и RGB?
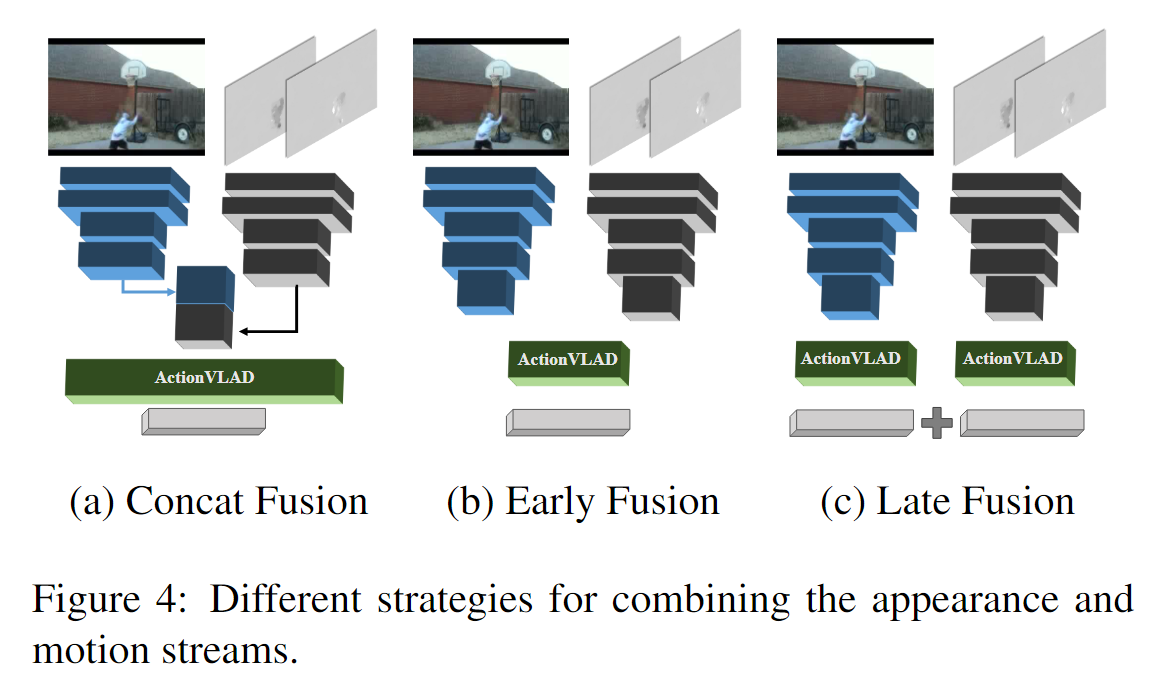
Один слой ActionVLAD поверх объединенных элементов внешнего вида и движения (Concat Fusion).
Единый слой ActionVLAD для всех элементов внешнего вида и движения (Early Fusion).
Поздний фьюжн.
Думая о недостатках
- Отправная точка хороша: классификация одного действия, но может быть несколько различных функций подкатегорий, поэтому найдите способ интегрировать несколько функций подкатегорий в представление всей функции видео. Однако реинтеграция суждений из нескольких подкатегорий, несомненно, увеличивает снижение окончательной точности.
2. Детектор тубусов действия для кода локализации пространственно-временного действия.
префикс термина
Якорные кубоиды : Якорные кубоиды похожи на ограничивающие прямоугольники при обнаружении двумерных целей. Оба метода представляют собой метод плотной выборки, используемый для создания блоков-кандидатов. Разница в том, что кубоиды привязки представляют собой трехмерные блоки-кандидаты формы, которые могут обрабатывать движущиеся объекты в видео и использовать информацию о временном измерении, в то время как блоки привязки подходят только для двумерных изображений.
Туплеты : Туплеты в этой статье относятся к пространственно-временному блоку обнаружения, состоящему из последовательностей ограничивающих рамок в нескольких последовательных кадрах. Каждому ограничивающему прямоугольнику соответствует оценка, которая используется для указания наличия определенной категории действия в блоке обнаружения. Его можно понимать как способ обнаружить и определить пространственно-временное положение действия в видео. последовательность ограничивающих рамок с одним показателем достоверности для каждого класса действия

Резюме и заключение
- Предлагаемое действие Детектор трубочек (ACT-детектор) [Действие Детектор трубочек (ACT-детектор)]
- Характеристики каждого кадра складываются во времени для формирования информационных последовательностей временных рядов кадров.
- Он построен на основе SSD и вводит кубоиды привязки , которые выполняют скоринг и регрессию на последовательностях кадров.
Введение: определение болевых точек и вкладов
Болевые точки:
- Категории действий невозможно точно определить только по одному кадру.
способствовать:
- Предлагается детектор Action Tubelet (ACT-детектор), который вводит несколько непрерывных видеокадров, выводит кубоиды привязки, состоящие из нескольких bboxes с прогнозируемым поведением на нескольких кадрах, а затем выполняет регрессию для каждого bbox для получения Tubelet с прогнозируемым поведением . Поскольку ACT-детектор учитывает особенности непрерывности нескольких видеокадров, он может уменьшить неоднозначность прогнозирования поведения, одновременно повышая точность позиционирования.
Связанных с работой
- Обнаружение цели: Faster-RCNN (блок привязки RoI) -> YOLO и SSD. Эта статья распространяет их на якорные кубоиды , тем самым значительно улучшая локализацию действий.
- Локализация действия: (1) Расширение скользящего окна (требуются такие предположения, как: форма куба, пространственный диапазон объектов или поведения, вовлеченного в действие, остается неизменным) (2) Применение блоков-кандидатов (предложений) к видеополю, т.е. Выдвиньте несколько предложений к видео и классифицируйте их.
модельная основа
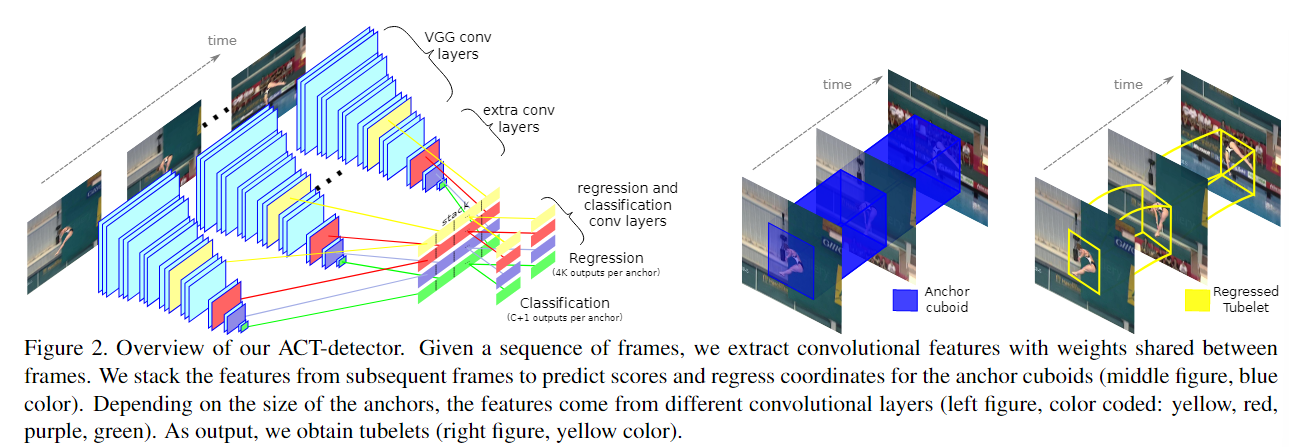

Входные данные: В середине K последовательных кадров
: после сети SSD будет K * объектов разных слоев. K различных объектов складываются вместе, и объекты разных слоев занимают разные строки.
Эти функции будут выводить оценки категорий (класс+1) посредством свертки и координаты регрессии (4*K) посредством другой свертки. Объекты разных слоев будут выводить разные оценки и координаты, а разные слои соответствуют разным привязкам. Таким образом, разные положения изображения и разные слои будут иметь разные привязки. Также в одной и той же позиции будет несколько инициализированных привязок, но кадр K соответствует тот же якорь, который эквивалентен шкалам SSD во временном измерении.
Каждый якорь в конечном итоге будет соответствовать якорному кубоиду , и, наконец, трубка будет выведена после NMS или проигнорирована.Инициализированный
якорный кубоид имеет фиксированное положение по размеру кадра и больше, чем человеческое пространство.Положение каждого кадра после регрессии различен.Состав тубельтесов.
Выходные данные: туплеты: последовательность ограничивающих рамок с одним показателем достоверности для каждого класса действия.
Учитывая последовательность K кадров, детектор ACT вычисляет сверточные характеристики для каждого кадра. Веса этих сверточных функций распределяются по всем входным кадрам.
В частности, при обработке этой последовательности изображений ACTdetector будет использовать операции свертки для извлечения особенностей каждого кадра. Для извлечения признаков между разными кадрами используются одни и те же веса свертки, а это означает, что параметры ядра свертки одинаковы на протяжении всей последовательности. Этот метод совместного использования весов помогает модели лучше понять и уловить корреляцию действий или объектов в разных кадрах, поскольку он использует информацию из всех кадров для извлечения функций, а не обрабатывает каждый кадр независимо. Это помогает повысить точность локализации или обнаружения движения.
Сложите сверточные характеристики каждого кадра из K кадров. (После сети SSD будет K * функций разных слоев. K разных функций складываются вместе, а функции разных слоев занимают разные строки.) Сложенные функции являются входными данными двух сверточных слоев, один для класса действия. оценка и еще одна для регрессии, закрепляющей кубоид.
Уровень классификации выводит оценку C+1 для каждого закрепленного кубоида: одну оценку за класс действия плюс оценку фона. Это означает, что классификация трубок основана на последовательности кадров. Регрессия выведет координаты 4×K для каждого закрепленного кубоида (4 для каждого K-кадра). Обратите внимание, что хотя все кубоиды в пакете подвергаются совместной регрессии, они производят разные регрессии для каждого кадра.
(Функции разных слоев будут выводить разные оценки и координаты, а разные слои соответствуют разным привязкам. Следовательно, разные положения изображения и разные слои будут иметь разные привязки . Также в одной и той же позиции будет несколько инициализированных привязок, но K-кадр соответствует к той же привязке, что эквивалентно расширению SSD во временном измерении.)
Рецептивное поле нейрона, используемое для оценки и регрессии, закрепляющего кубоид, больше, чем его пространственная протяженность. Это позволяет нам также делать прогнозы на основе контекста кубоида, то есть понимания действующих лиц, которые могут выходить за пределы кубоида.

Потери при обучении:
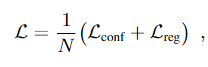 N представляет количество опорных кубоидов, соответствующих истинному значению,
N представляет количество опорных кубоидов, соответствующих истинному значению,
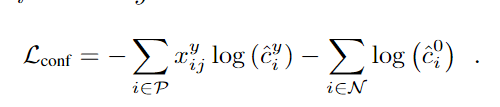 Определите потерю доверия, используя потерю softmax
Определите потерю доверия, используя потерю softmax
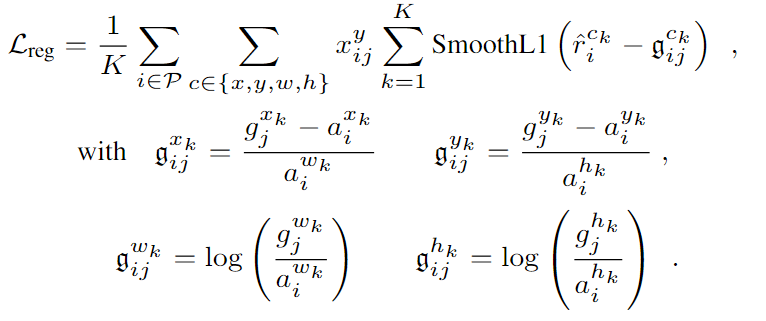
Думая о недостатках
- Ограничения на размер и форму опорных точек или заглушек. Размер и форма опорных точек или заглушек, используемых в методах, часто определяются заранее, что может привести к плохим результатам при работе с множеством действий или объектов разных размеров и форм. . . Если действие или объект в видео не соответствует определенным опорным точкам, это может привести к промахам или ложным обнаружениям.
3. Пространственно-временной вектор локально максимальных объединенных функций для распознавания действий в видео
Локальный максимальный вектор пространственно-временного объединения (ST-VLMPF)
Резюме и заключение
- Пространственно-временной вектор локальных максимальных функций объединения (ST-VLMPF), который представляет собой метод кодирования на основе гипервектора, специально разработанный для локального глубокого кодирования функций . метод кодирования на основе супервекторов, специально разработанный для кодирования локальных глубоких функций.
- Назначение признаков осуществляется на двух уровнях с использованием сходства и пространственно-временной информации. Назначение признаков выполняется на двух уровнях с использованием информации о сходстве и пространственно-временной информации.
Введение: определение болевых точек и вкладов
Болевые точки:
- Одним из недостатков современных стандартных кодировок является отсутствие учета пространственно-временной информации.
- Созданные вручную элементы разрабатываются вручную и часто содержат низкоуровневую информацию, такую как края.
- Учитывая нынешнюю высокую доступность предварительно обученных нейронных сетей, многие исследователи используют их исключительно как инструменты извлечения признаков, поскольку переобучение или тонкая настройка нейронных сетей во многих аспектах сложнее. Следовательно, для решения этой проблемы необходим эффективный метод кодирования глубоких функций.
способствовать:
- Он решает важную проблему понимания видео: как построить видеопредставление, содержащее функции CNN во всем видео.
модельная основа
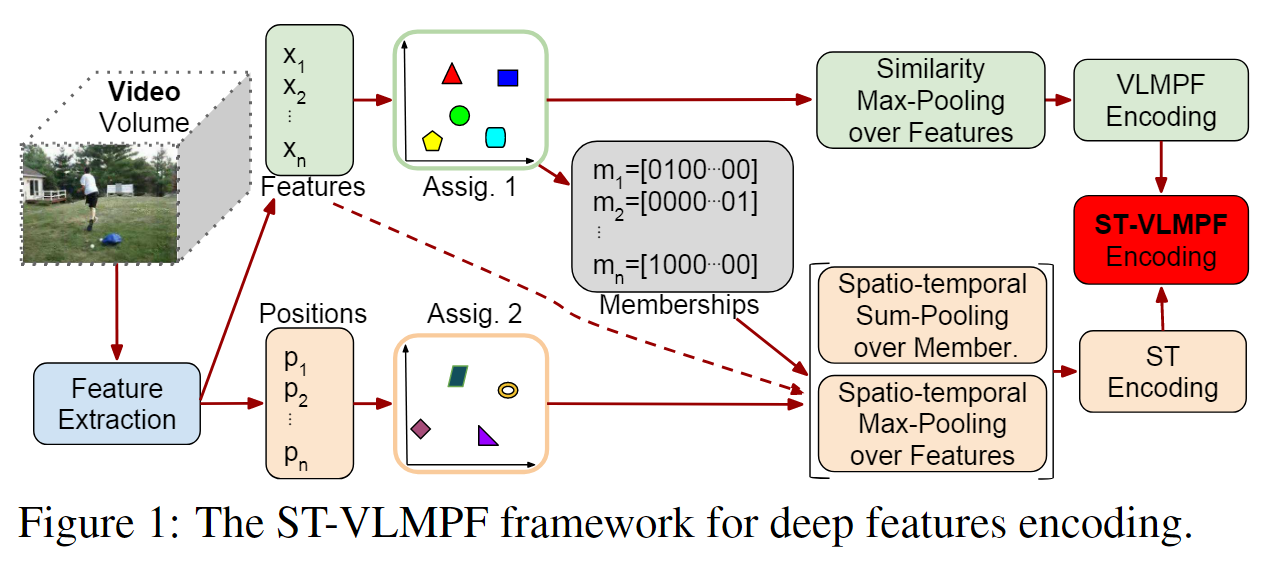
Кодовая книга C изучается с использованием k-средних из большого подмножества случайно выбранных функций, извлеченных из подмножества видео в наборе данных. Результаты представляют собой визуальные слова K1, C={c1,c2,…,ck 1}, которые по сути представляют собой среднее значение каждого кластера функций, изученного с помощью k-Means.
- Сначала из видео извлекаются местные особенности. В видео используются извлеченные локальные признаки X={x1, x2,..., xn}εRn×d, где d — размерность признака, а n — общее количество локальных признаков видео. Вместе с локальными объектами мы сохраняем их позиции P = {p1, p2,…, pn}εRn×3.
- Предлагаемый нами метод кодирования выполняет два жестких назначения с использованием полученной кодовой книги: первое основано на сходстве признаков , а второе — на их расположении. Для первого назначения каждому локальному видеообъекту xj(j=1, …, n) присваивается ближайшее визуальное слово из кодовой книги C. Затем по группам признаков, присвоенным кластерам ci (i=1, …, n). …, k1)
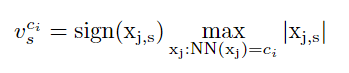
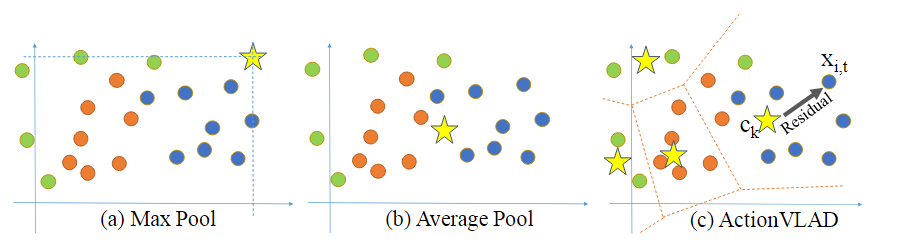
NN(xj) представляет центроид ближайшего соседа кодовой книги C абсолютного значения признака. По сути, уравнение 2 позволяет получить максимальное абсолютное значение, сохраняя при этом начальный знак возвращаемого конечного результата. На рисунке 1 мы называем это сходство максимальным пулом функций, поскольку объекты группируются на основе их сходства, а затем для каждой результирующей группы выполняется максимальный пул. Конкатенированное представление всех векторов [vc1, vc2,…, vck1] представляет собой кодировку VLMPF (локальный максимальный вектор объединения в пул), а окончательный размер вектора равен (k1×d). - После первого назначения мы также сохраняем принадлежность каждого объекта к центроиду с целью сохранения соответствующей информации о кластеризации на основе сходства. После первого назначения мы также сохраняем принадлежность каждого объекта к центроиду с целью сохранения соответствующей информации о кластеризации на основе сходства. Для каждого признака мы используем вектор m для представления информации о членстве, например, m=[0100…00] для сопоставления информации о признаке членства со вторым визуальным словом кодовой книги C.
- Мы выполняем второе задание на основе местоположения объектов. Нижняя часть рисунка 1 показывает этот путь. Каждая позиция pj признака в P назначается ближайшему центроиду в кодовой книге PC.
- Объекты группируются на основе пространственно-временной информации, а затем рассчитывается максимальное абсолютное значение с сохранением исходного знака объекта. Мы также объединяем информацию о членстве в отношении сходства признаков, полученную в результате первого задания в уравнении 3, с целью инкапсулировать сходство принадлежности пространственно-временных группировок признаков с пространственно-временной информацией. Мы объединяем все эти векторы [vpc1, vpc2,…, vpck2] для создания кодировки ST (пространство-время), получая таким образом размер вектора (k2×d + k2×k1). Наконец, мы объединяем кодировки ST и VLMPF, чтобы создать окончательное представление ST-VLMPF, которое используется в качестве входных данных для классификатора. Следовательно, окончательный размер вектора, представленного ST-VLMPF, равен (k1×d) + (k2×d + k2×k1).
Извлечение локальных глубоких признаков
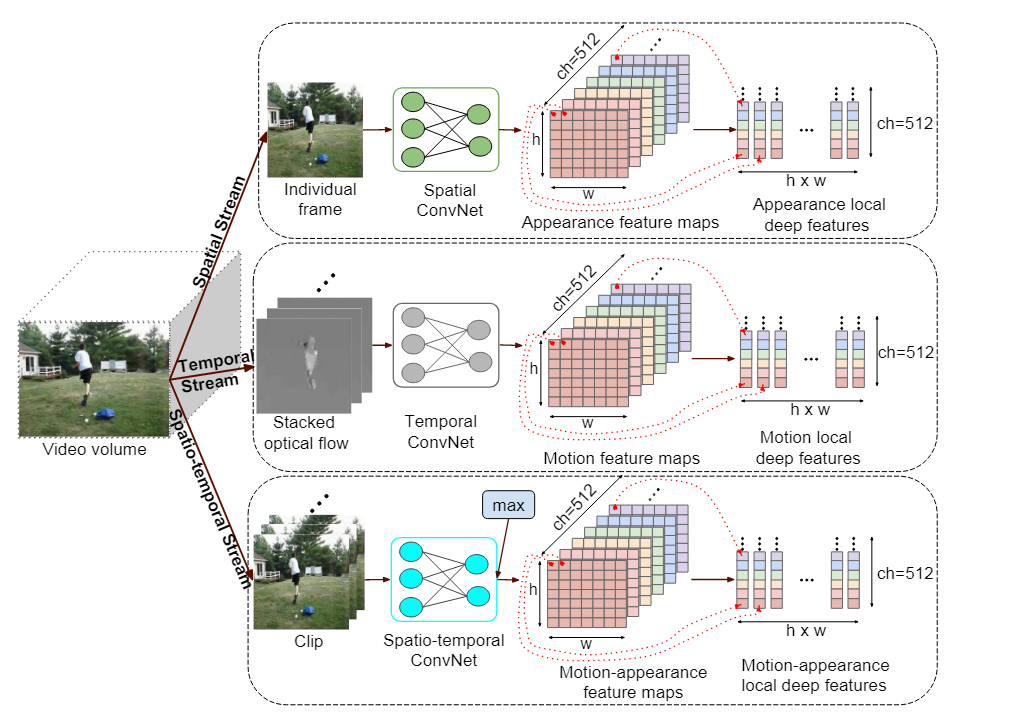
используется для захвата пространственного потока внешнего вида, временного потока для захвата движения и пространственно-временного потока для захвата информации о внешнем виде и движении.
4. Трубчатая сверточная нейронная сеть (T-CNN) для обнаружения действий в видеокоде .
Резюме и заключение
- предложить сквозную глубокую сеть под названием Tube Convolutional Neural Network (T-CNN) для обнаружения действий в видео. Он использует трехмерные сверточные сети для извлечения эффективных пространственно-временных характеристик и выполнения локализации и распознавания действий в единой среде. Грубые блоки предложений тщательно выбираются на основе трехмерных сверточных кубов признаков и связываются для распознавания и локализации действий.
Введение: определение болевых точек и вкладов
Болевые точки:
- Предыдущие методы обнаружения видеодействий на основе сверточной нейронной сети (CNN) обычно содержали два основных этапа: генерацию предложения действия на уровне кадра и межкадровую ассоциацию предложений. Кроме того, большинство этих методов используют двухпотоковую структуру CNN для раздельной обработки пространственных и временных характеристик.
способствовать:
- Предлагается метод обнаружения видеодействий, основанный на сквозном глубоком обучении. Он работает непосредственно с исходным видео, использует единую 3D-сеть для захвата пространственно-временной информации и выполняет локализацию и распознавание действий на основе сверточных 3D-функций. Это первая работа, использующая 3D ConvNet для обнаружения действий.
- Представлена сеть предложений труб, которая использует объединение пропусков во временной области для сохранения временной информации о позиционировании действий в трехмерном объеме.
- В T-CNN предлагается новый уровень объединения — уровень объединения Tube-of-Interesr (ToI) . Уровень объединения ToI представляет собой трехмерное обобщение слоя объединения областей интереса (RoI) R-CNN. Это эффективно решает проблему переменных пространственных и временных размеров предложений по конвейеру.
Связанных с работой
- R-CNN: для обнаружения целей на изображениях Region-CNN (R-CNN) предложения регионов извлекаются с использованием выборочного поиска . Затем регион-кандидат преобразуется до фиксированного размера и вводится в ConvNet для извлечения функций CNN. Наконец, модель SVM обучается классификации объектов.
- Быстрый R-CNN. По сравнению с многоэтапным конвейером R-CNN , Fast R-CNN добавляет в сеть классификатор объектов и одновременно обучает классификатор объектов и регрессор ограничивающего прямоугольника. Введен слой объединения областей интересов (RoI) для извлечения векторов признаков фиксированной длины из ограничивающих рамок разных размеров.
- Быстрее R-CNN. Он вводит RPN (сеть региональных предложений) для генерации предложений вместо выборочного поиска . RPN разделяет все функции свертки изображений с сетью обнаружения, поэтому генерация предложений практически бесплатна. Более быстрый R-CNN обеспечивает современную производительность обнаружения объектов, сохраняя при этом эффективность во время тестирования. Руководствуясь его высокой производительностью, в этой статье мы исследуем возможность обобщения более быстрого R-CNN из областей 2D-изображений в объемы 3D-видео для обнаружения действий.
модельная основа
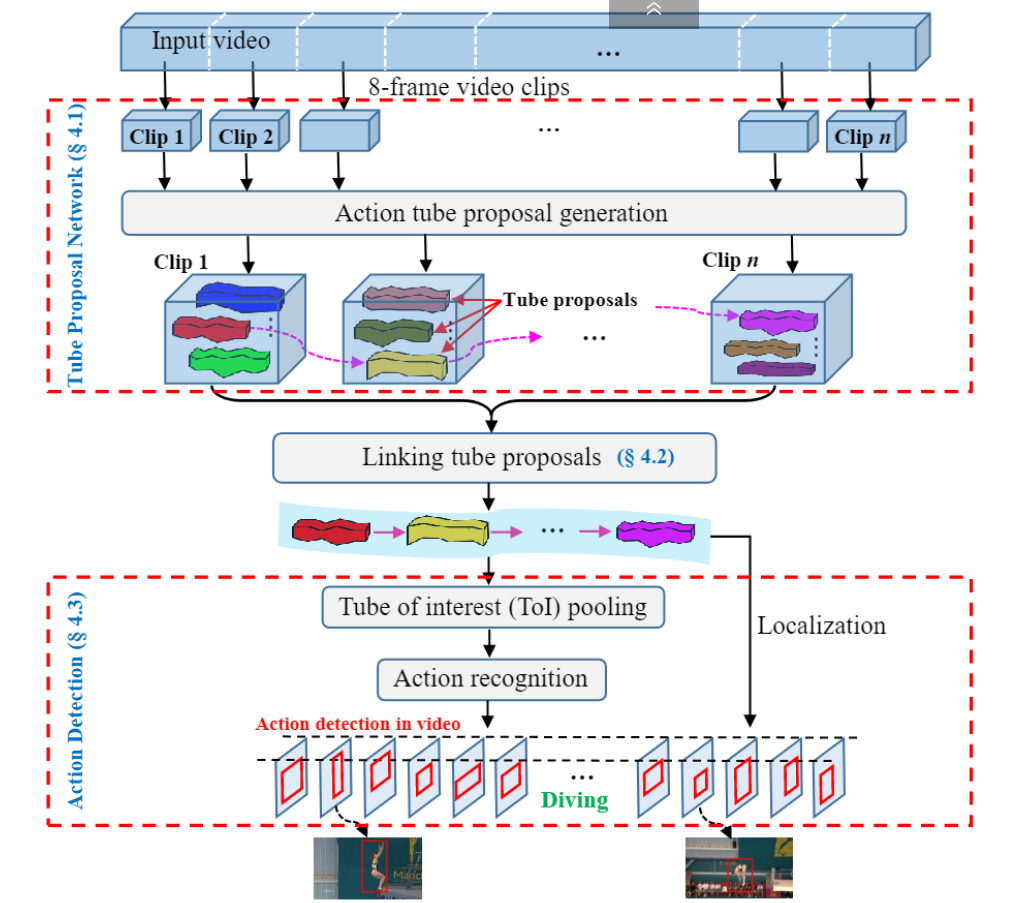
- Входное видео сначала делится на клипы одинаковой длины .
- Затем клип вводится в сеть предложений трубок (TPN) и получается набор предложений трубок .
- Затем предложения по трубкам для каждого видеоклипа связываются на основе их оценки действия и перекрытия между соседними предложениями , чтобы сформировать полное предложение по трубкам для пространственно-временной локализации действия в видео.
- Наконец, к предложениям каналов действий ссылки применяется объединение трубок интересов (ToI) для создания вектора признаков фиксированной длины для прогнозирования меток действий.
Объединение интересов в трубке
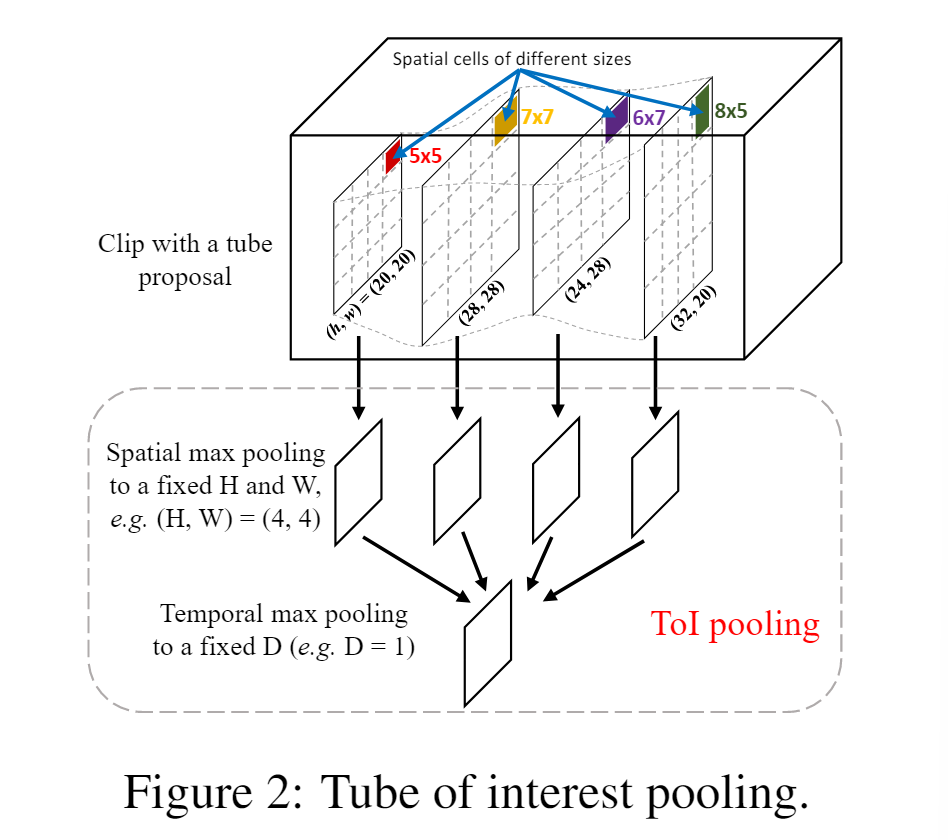
- Пространственное максимальное объединение: сначала разделите карту объектов h × w на ячейки H × W, где каждая ячейка соответствует единице размера примерно h/H × w/W. В каждой ячейке применяется максимальное объединение для выбора максимального значения.
- Объединение временного максимума. Во-вторых, карты пространственных объединений d делятся на D интервалы во времени. Как и на первом этапе, карты смежных объектов d/D группируются вместе для выполнения стандартного группирования временных максимальных значений. Следовательно, фиксированный выходной размер слоя объединения ToI составляет D × H × W. На рис. 2 показана схема объединения ToI.
- Как показано на рисунке выше, свертка красной области делит карту объектов 20*20 на 4 ячейки.
Max Pooling делит входное изображение на несколько прямоугольных областей и выводит максимальное значение для каждой подобласти.
Сеть предложений по трубам
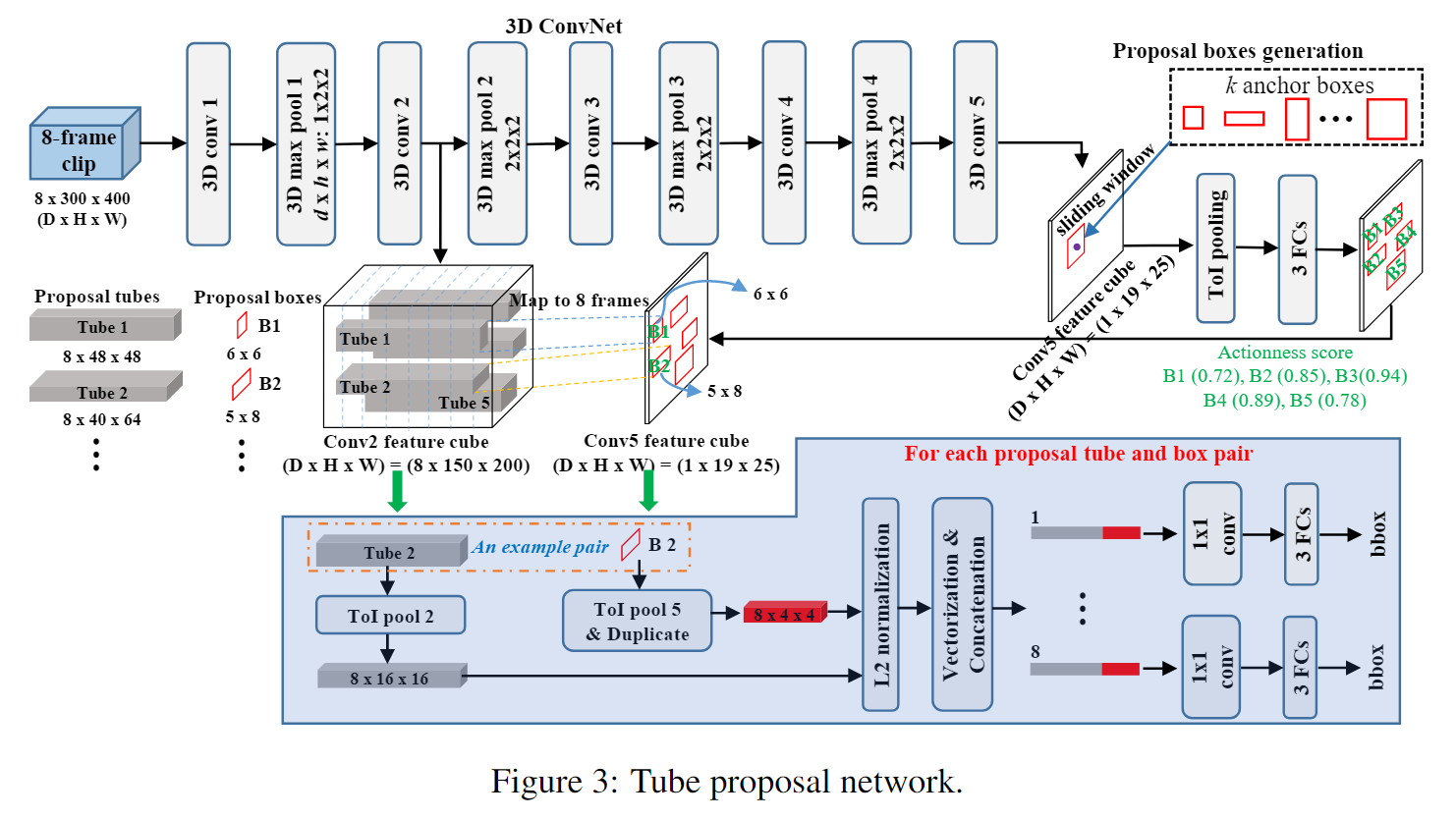
Объединение предложений по трубкам
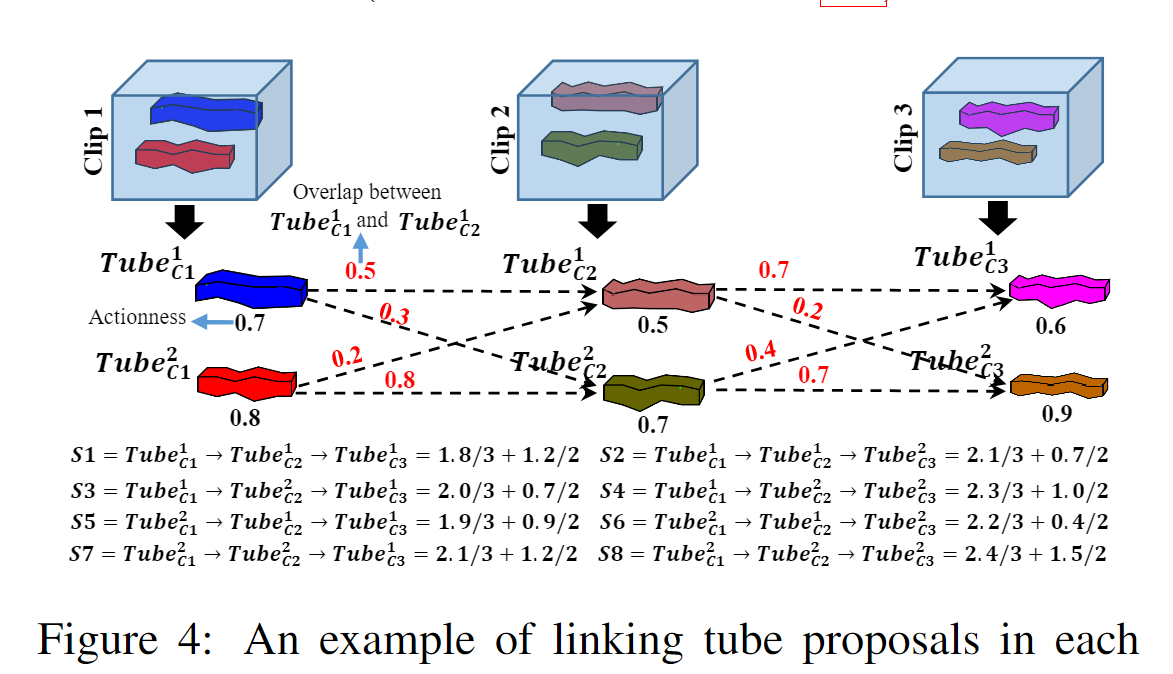
Каждое предложение видеоролика из разных клипов можно связать в последовательность предложений видеоролика (т. е. предложение видеоролика) для обнаружения действия. Однако не все комбинации предложений видеоролика могут правильно передать все действие. Например, клип Предложение видеоролика в клипе может содержать движение, в то время как предложение видеоролика в следующем клипе может захватывать только фон. Интуитивно понятно, что контент в выбранном предложении видеоролика должен захватывать движение, а предложения видеороликов, соединенные в любых двух последовательных клипах, должны иметь большее перекрытие по времени. Следовательно, два При связывании предложений по трубкам учитываются критерии: эффективность и оценка перекрытия. Каждому предложению видео затем присваивается оценка, определенная следующим образом: где
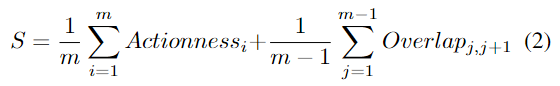
Actionness_i представляет оценку действия предложения по трубке из i-го клипа, Overlap_j,_j+1 измеряет перекрытие между два предложения из ссылок j-го и (j + 1)-го клипа соответственно, а m — общее количество видеоклипов. Как показано на рисунке 3, каждое из предложений ограничительной рамки из трубки функций conv5 связано с Оценка действия. Оценка действия наследуется соответствующим предложением трубки. Перекрытие
между двумя предложениями трубки основано на последнем кадре j-го предложения трубки и (j+1)-го предложения трубки. Оно рассчитывается на основе IoU (пересечение через объединение) первого кадра. Первый член S вычисляет средний балл действия всех предложений по трубкам в предложении видео, а второй член вычисляет среднее перекрытие между предложениями по трубкам в каждых двух последовательных видеоклипах. Таким образом, мы гарантируем, что связанные предложения по трубкам могут инкапсулировать операции, оставаясь при этом согласованными во времени. На рисунке 4 показан пример соединения предложений по трубкам и расчета оценок. Мы выбираем последовательность нескольких связанных предложений с наивысшими оценками в видео.