
1. Descripción
Este artículo es un tutorial sobre cómo crear su propio modelo de difusión desde cero. Siempre me gusta mantener las cosas simples y fáciles, por eso aquí hemos evitado matemáticas complicadas. Este no es un modelo de difusión normal. Más bien lo llamo modelo de difusión rápida. Sólo se utilizarán redes neuronales convolucionales (CNN) para realizar el modelo de difusión. En este artículo no le proporcionaré ningún archivo de modelo/peso/script existente.

Debes entrenar el modelo tú mismo.
(Estamos utilizando el conjunto de datos CIFAR-10 proporcionado por TensorFlow.
Puedes encontrar el código en mi GitHub
https://github.com/Seachaos/Tree.Rocks/blob/main/QuickDiffusionModel/QuickDiffusionModel.ipynb
2. Esta idea
Así es como funciona el modelo de difusión: es como tomar una imagen completamente ruidosa y mejorar gradualmente la calidad de la imagen hasta que se vuelve clara.
(Como se muestra abajo)

Por lo tanto, podemos crear un modelo de aprendizaje profundo que pueda mejorar la calidad de la imagen (desde ruido total hasta imágenes claras).Idea de proceso:
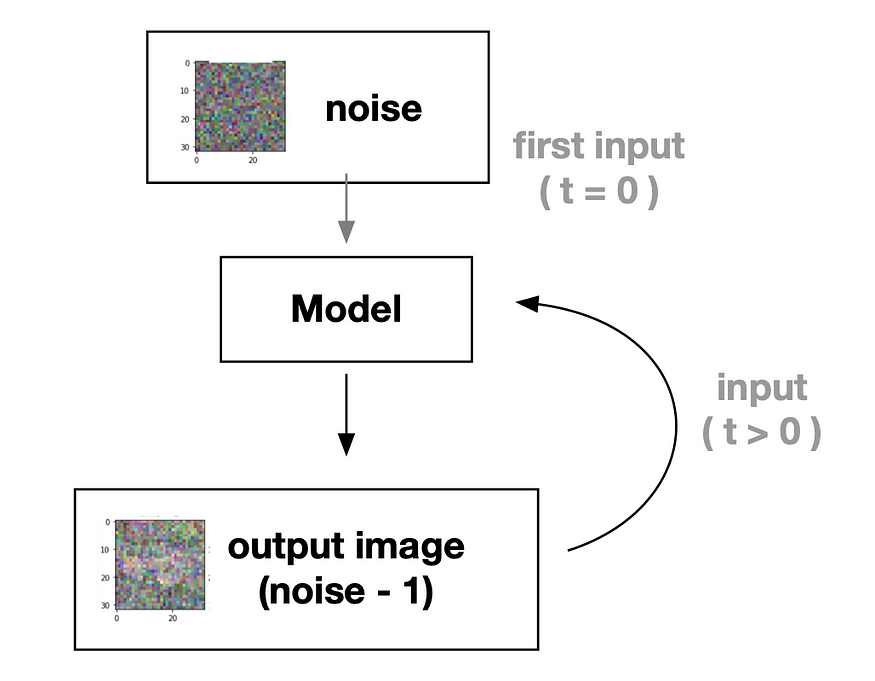
Para una comprensión más clara, consulte este diagrama de flujo adjunto.
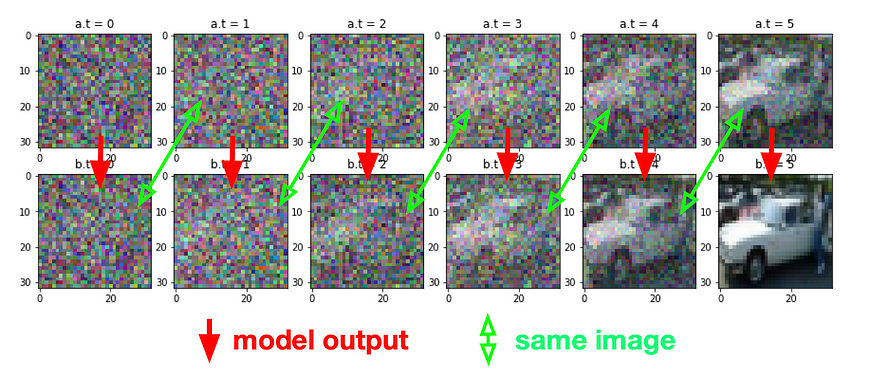
Como se muestra arriba, el modelo intenta generar imágenes con progresivamente menos ruido. Ahora solo necesitamos entrenar un modelo de aprendizaje profundo para aprender a reducir el ruido.
Para esta tarea necesitamos dos entradas del modelo:
- Imagen de entrada: es necesario procesar la imagen con ruido
- marca de tiempo: le dice al modelo cuál es el estado del ruido para que pueda aprender más fácilmente
3. Implementar un modelo de difusión rápida
Primero, importemos lo que necesitamos:
import numpy as np
from tqdm.auto import trange, tqdm
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers Y prepare nuestro conjunto de datos. En este tutorial usaremos una gran colección de imágenes de automóviles (CIFAR-10) como ejemplo para mantener las cosas lo más simples y rápidas posible.
(Sin embargo, si tiene suficientes muestras, puede elegir la imagen que desee.
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
X_train = X_train[y_train.squeeze() == 1]
X_train = (X_train / 127.5) - 1.0A continuación, definamos las variables.
IMG_SIZE = 32 # input image size, CIFAR-10 is 32x32
BATCH_SIZE = 128 # for training batch size
timesteps = 16 # how many steps for a noisy image into clear
time_bar = 1 - np.linspace(0, 1.0, timesteps + 1) # linspace for timestepsAquí configuramos el "paso de tiempo", lo que significa que nuestro modelo aprenderá a generar imágenes desde ruidosas (nivel 0) hasta claras (nivel 16) a través del proceso de entrenamiento.
Veamos una imagen para tener una idea más clara.
plt.plot(time_bar, label='Noise')
plt.plot(1 - time_bar, label='Clarity')
plt.legend()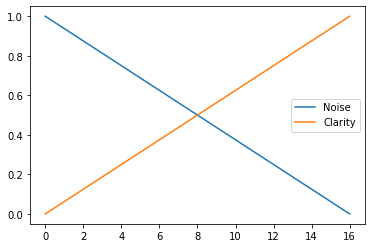
Como puede ver, desde el paso 0 al 16, el ruido disminuye y la claridad aumenta gradualmente. Esto es lo que queremos que nuestro modelo aprenda.
y preparar algunas funciones para obtener una vista previa de los datos
def cvtImg(img):
img = img - img.min()
img = (img / img.max())
return img.astype(np.float32)
def show_examples(x):
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i+1)
img = cvtImg(x[i])
plt.imshow(img)
plt.axis('off')
show_examples(X_train)
CIFAR-10 Automotriz
3.1 Preparación para la formación
Aquí necesitamos preparar el código para las imágenes de entrenamiento.
La idea es obtener dos imágenes (A y B) de puntos aleatorios en el tiempo, donde A es la imagen ruidosa y B es la imagen más clara.
Nuestro modelo aprenderá a convertir A en B (de ruidoso a más claro) en función de ese momento específico.
(otra vez como esta imagen)
Entonces aquí tenemos la función forward_noise .
def forward_noise(x, t):
a = time_bar[t] # base on t
b = time_bar[t + 1] # image for t + 1
noise = np.random.normal(size=x.shape) # noise mask
a = a.reshape((-1, 1, 1, 1))
b = b.reshape((-1, 1, 1, 1))
img_a = x * (1 - a) + noise * a
img_b = x * (1 - b) + noise * b
return img_a, img_b
def generate_ts(num):
return np.random.randint(0, timesteps, size=num)
# t = np.full((25,), timesteps - 1) # if you want see clarity
# t = np.full((25,), 0) # if you want see noisy
t = generate_ts(25) # random for training data
a, b = forward_noise(X_train[:25], t)
show_examples(a)Si quieres entender cómo funciona, te recomiendo ejecutar el código que comenté. (t=...)

3.2 Construyendo bloques CNN
Usaremos U-Net como nuestro modelo, los detalles se explican en el código a continuación.
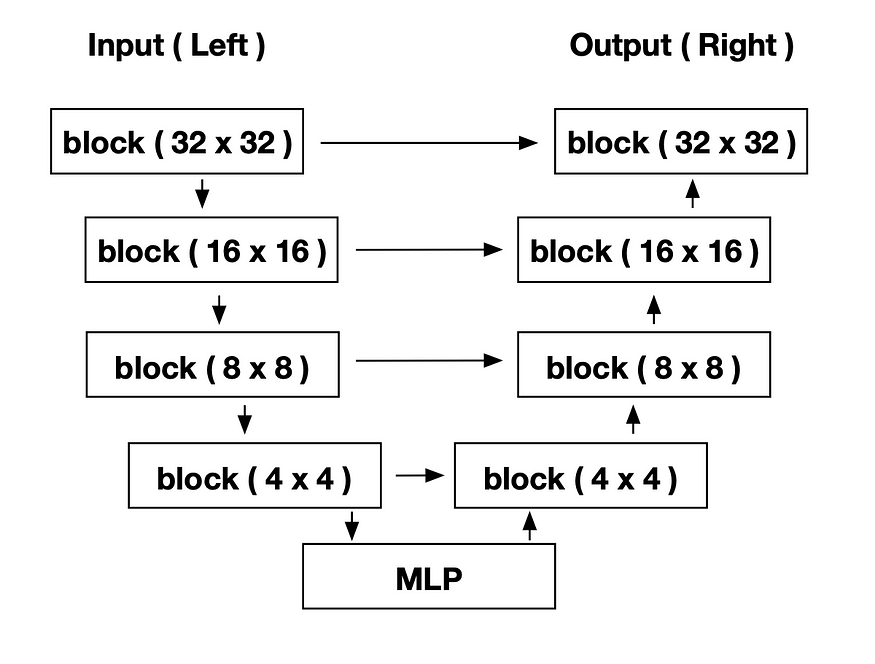
Arquitectura del modelo, los detalles se explicarán en el siguiente código: antes de construir el modelo, primero debemos definir los bloques.
Aquí está el código para el bloque make:
def block(x_img, x_ts):
x_parameter = layers.Conv2D(128, kernel_size=3, padding='same')(x_img)
x_parameter = layers.Activation('relu')(x_parameter)
time_parameter = layers.Dense(128)(x_ts)
time_parameter = layers.Activation('relu')(time_parameter)
time_parameter = layers.Reshape((1, 1, 128))(time_parameter)
x_parameter = x_parameter * time_parameter
# -----
x_out = layers.Conv2D(128, kernel_size=3, padding='same')(x_img)
x_out = x_out + x_parameter
x_out = layers.LayerNormalization()(x_out)
x_out = layers.Activation('relu')(x_out)
return x_out Cada bloque contiene dos redes convolucionales con parámetros temporales, lo que permite a la red determinar su paso de tiempo actual y generar la información correspondiente.
Puede ver el diagrama de flujo de bloques:
(x_img es la imagen de entrada, es la imagen de ruido, x_ts es la entrada para el paso de tiempo)
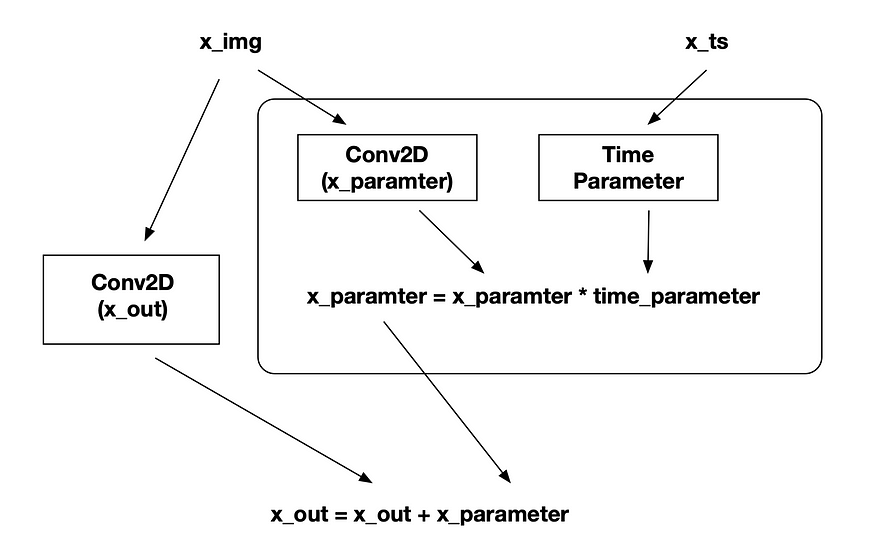
Construyendo el modelo Ahora podemos construir nuestro modelo.
def make_model():
x = x_input = layers.Input(shape=(IMG_SIZE, IMG_SIZE, 3), name='x_input')
x_ts = x_ts_input = layers.Input(shape=(1,), name='x_ts_input')
x_ts = layers.Dense(192)(x_ts)
x_ts = layers.LayerNormalization()(x_ts)
x_ts = layers.Activation('relu')(x_ts)
# ----- left ( down ) -----
x = x32 = block(x, x_ts)
x = layers.MaxPool2D(2)(x)
x = x16 = block(x, x_ts)
x = layers.MaxPool2D(2)(x)
x = x8 = block(x, x_ts)
x = layers.MaxPool2D(2)(x)
x = x4 = block(x, x_ts)
# ----- MLP -----
x = layers.Flatten()(x)
x = layers.Concatenate()([x, x_ts])
x = layers.Dense(128)(x)
x = layers.LayerNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.Dense(4 * 4 * 32)(x)
x = layers.LayerNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.Reshape((4, 4, 32))(x)
# ----- right ( up ) -----
x = layers.Concatenate()([x, x4])
x = block(x, x_ts)
x = layers.UpSampling2D(2)(x)
x = layers.Concatenate()([x, x8])
x = block(x, x_ts)
x = layers.UpSampling2D(2)(x)
x = layers.Concatenate()([x, x16])
x = block(x, x_ts)
x = layers.UpSampling2D(2)(x)
x = layers.Concatenate()([x, x32])
x = block(x, x_ts)
# ----- output -----
x = layers.Conv2D(3, kernel_size=1, padding='same')(x)
model = tf.keras.models.Model([x_input, x_ts_input], x)
return model
model = make_model()
# model.summary()Esta es una U-Net. Para las partes izquierda, derecha y MLP, consulte la figura anterior (arquitectura del modelo).
No olvides compilar el modelo.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0008)
loss_func = tf.keras.losses.MeanAbsoluteError()
model.compile(loss=loss_func, optimizer=optimizer)Usamos Adam como optimizador y MeanAbsoluteError (MAE) como función de pérdida.
Resultados de la predicción: ahora podemos probar nuestra primera predicción. Los pasos de predicción son los siguientes:
- Crea imágenes ruidosas
- entrada a nuestro modelo en pasos de tiempo
- Sigue haciendo esto hasta el final del paso de tiempo.
Entonces esta es la función:
def predict(x_idx=None):
x = np.random.normal(size=(32, IMG_SIZE, IMG_SIZE, 3))
for i in trange(timesteps):
t = i
x = model.predict([x, np.full((32), t)], verbose=0)
show_examples(x)
predict()
Imagen de salida del modelo no entrenado Arriba está la salida de nuestro modelo no entrenado y, como puede ver, no hace nada útil. Esta función también nos ayuda a visualizar cada paso:
def predict_step():
xs = []
x = np.random.normal(size=(8, IMG_SIZE, IMG_SIZE, 3))
for i in trange(timesteps):
t = i
x = model.predict([x, np.full((8), t)], verbose=0)
if i % 2 == 0:
xs.append(x[0])
plt.figure(figsize=(20, 2))
for i in range(len(xs)):
plt.subplot(1, len(xs), i+1)
plt.imshow(cvtImg(xs[i]))
plt.title(f'{i}')
plt.axis('off')
predict_step()
4. Modelo de formación
Esta función de entrenamiento es muy sencilla.
def train_one(x_img):
x_ts = generate_ts(len(x_img))
x_a, x_b = forward_noise(x_img, x_ts)
loss = model.train_on_batch([x_a, x_ts], x_b)
return lossSolo necesitamos proporcionar x_ts y x_img (x_a) para que nuestro modelo pueda aprender a generar x_b.
y convertirlo en una función de época
def train(R=50):
bar = trange(R)
total = 100
for i in bar:
for j in range(total):
x_img = X_train[np.random.randint(len(X_train), size=BATCH_SIZE)]
loss = train_one(x_img)
pg = (j / total) * 100
if j % 5 == 0:
bar.set_description(f'loss: {loss:.5f}, p: {pg:.2f}%')Finalmente, ejecútelo varias veces y reduzca gradualmente la tasa de aprendizaje.
for _ in range(10):
train()
# reduce learning rate for next training
model.optimizer.learning_rate = max(0.000001, model.optimizer.learning_rate * 0.9)
# show result
predict()
predict_step()
plt.show()Puedes obtener una imagen de salida como esta.

5. Conclusión
Este tutorial está diseñado para ser simple y permitirle experimentar. Puede probar sus propios parámetros (como cambiar el tamaño de la imagen, el filtro CNN, el paso de tiempo o MLP, etc.) y entrenar con más épocas para obtener mejores resultados. Caos del mar