I. Introducción
Debido a que recientemente hice una pequeña aplicación sobre reconocimiento de imágenes, necesitaba muchas imágenes para crear un conjunto de datos. La descarga de cada una fue demasiado lenta, así que investigué y escribí un pequeño rastreador simple, pensando en registrar estas experiencias cada vez. La estructura de un sitio web es diferente, por lo que es necesario realizar los cambios correspondientes para diferentes sitios web. Leer este artículo puede requerir algunos conocimientos de front-end. He publicado el código total al final.
Aquí usamos un sitio web de ropa como ejemplo (puede usar cualquier sitio web, lo principal es el método y el código) ==》 https://www.black-up.kr/product/detail.html?product_no=32474&cate_no= 96&display_group=1
2. Código
2.1 Solicitudes de tres bibliotecas de herramientas, BeautifulSoup, os
import requests
from bs4 import BeautifulSoup
import os2.2 Obtener y formatear encabezados de solicitud del navegador
Necesitamos preparar un encabezado de solicitud del navegador, que tiene la forma de un diccionario. La esencia de un rastreador es usar el encabezado de solicitud para disfrazarse de navegador y luego acceder a él. El formato del encabezado de solicitud de cada navegador es diferente. pero el contenido es el mismo. Sí, necesitamos cambiar el encabezado de la solicitud a la forma de un diccionario. Aquí escribí un pequeño script para ayudar a formatear el encabezado de la solicitud, pero es posible que solo se limite al navegador de borde que uso. Si Si utilizas un navegador diferente, también puedes probar este script. También puedes formatearlo manualmente, pero es un poco más problemático.
Los pasos para obtener son los siguientes:
1) Abra el navegador e ingrese la URL de destino (yo uso el navegador Edge), presione F12 para ingresar al fondo, haga clic en Red, busque el elemento superior en la lista de nombres, que es el primer elemento y la posición del encabezado es la Rueda de desplazamiento derecha. Desplácese hacia abajo y podrá ver las cuatro palabras del encabezado de la solicitud. Comience a copiar desde Aceptar y cópielo hasta el agente de usuario al final. No necesita nada antes de Aceptar.
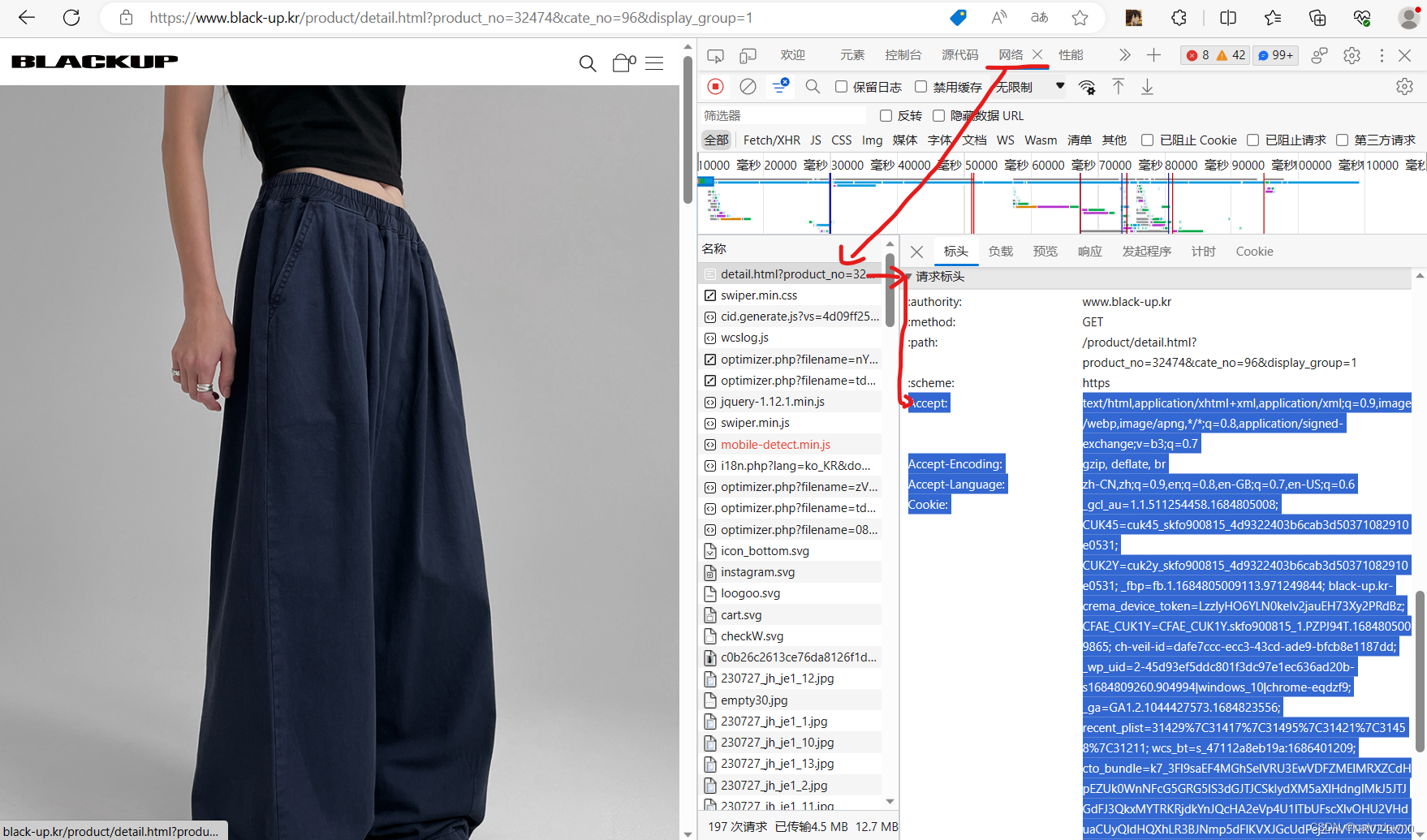
Formatee los encabezados de solicitud copiados
El código de formato es el siguiente:
El contenido de la cadena larga headerStr es el encabezado de la solicitud que acaba de copiar. Solo necesita eliminar el contenido en headerStr y reemplazarlo con el encabezado de la solicitud que copió.
Nota: El encabezado de solicitud sin formato en headerStr debe estar en la misma posición que se muestra a continuación. Copie el encabezado. No deje espacios delante de los atributos Aceptar.
import re
def formulate_head():
header_lines_value = ''
headerStr = '''
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding:
gzip, deflate, br
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie:
_gcl_au=1.1.511254458.1684805008; CUK45=cuk45_skfo900815_4d9322403b6cab3d50371082910e0531; CUK2Y=cuk2y_skfo900815_4d9322403b6cab3d50371082910e0531; _fbp=fb.1.1684805009113.971249844; black-up.kr-crema_device_token=LzzlyHO6YLN0keIv2jauEH73Xy2PRdBz; CFAE_CUK1Y=CFAE_CUK1Y.skfo900815_1.PZPJ94T.1684805009865; ch-veil-id=dafe7ccc-ecc3-43cd-ade9-bfcb8e1187dd; _wp_uid=2-45d93ef5ddc801f3dc97e1ec636ad20b-s1684809260.904994|windows_10|chrome-eqdzf9; _ga=GA1.2.1044427573.1684823556; recent_plist=31429%7C31417%7C31495%7C31421%7C31458%7C31211; wcs_bt=s_47112a8eb19a:1686401209; cto_bundle=k7_3Fl9saEF4MGhSelVRU3EwVDFZMElMRXZCdHpEZUk0WnNFcG5GRG5lS3dGJTJCSkIydXM5aXlHdnglMkJ5JTJGdFJ3QkxMYTRKRjdkYnJQcHA2eVp4U1lTbUFscXlvOHU2VHduaCUyQldHQXhLR3BJNmp5dFlKVXJGcUdPejZmVTNRV24xOXlMU3JGdmhKY3BBZnFKSVMwZEIzRCUyRm11SW93JTNEJTNE
Sec-Ch-Ua:
"Not/A)Brand";v="99", "Microsoft Edge";v="115", "Chromium";v="115"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
document
Sec-Fetch-Mode:
navigate
Sec-Fetch-Site:
none
Sec-Fetch-User:
?1
Upgrade-Insecure-Requests:
1
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188
'''
header_lines = headerStr.strip().split('\n')
# print(header_lines)
# exit()
ret = ""
jump = 0
for i in range(jump,len(header_lines)):
if i >= jump:
if header_lines[i].rfind(':') != -1:
ret += '\'' + header_lines[i] + ' ' + header_lines[i+1] + '\'' + ',\n'
jump = i+2
ret = re.sub(": ", "': '", ret)
ret = ret[:-2]
print(ret)
return ret
formulate_head()Ejecute el código anterior. Los resultados son los siguientes. Puede ver que se han formateado en un diccionario. Copie los resultados generados y colóquelos en los parámetros.

Simplemente coloque los encabezados formateados en el diccionario.
if __name__ == '__main__':
# 爬虫网址
url = "https://www.black-up.kr/product/detail.html?product_no=32474&cate_no=96&display_group=1"
# 文件命名
pic_name = "download_pic_"
# 保存文件目录
save_dir = "D:\lableimg1.8\csdn\spider_pic"
# 请求头
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cookie': '_gcl_au=1.1.511254458.1684805008; CUK45=cuk45_skfo900815_4d9322403b6cab3d50371082910e0531; CUK2Y=cuk2y_skfo900815_4d9322403b6cab3d50371082910e0531; _fbp=fb.1.1684805009113.971249844; black-up.kr-crema_device_token=LzzlyHO6YLN0keIv2jauEH73Xy2PRdBz; CFAE_CUK1Y=CFAE_CUK1Y.skfo900815_1.PZPJ94T.1684805009865; ch-veil-id=dafe7ccc-ecc3-43cd-ade9-bfcb8e1187dd; _wp_uid=2-45d93ef5ddc801f3dc97e1ec636ad20b-s1684809260.904994|windows_10|chrome-eqdzf9; _ga=GA1.2.1044427573.1684823556; recent_plist=31429%7C31417%7C31495%7C31421%7C31458%7C31211; wcs_bt=s_47112a8eb19a:1686401209; cto_bundle=k7_3Fl9saEF4MGhSelVRU3EwVDFZMElMRXZCdHpEZUk0WnNFcG5GRG5lS3dGJTJCSkIydXM5aXlHdnglMkJ5JTJGdFJ3QkxMYTRKRjdkYnJQcHA2eVp4U1lTbUFscXlvOHU2VHduaCUyQldHQXhLR3BJNmp5dFlKVXJGcUdPejZmVTNRV24xOXlMU3JGdmhKY3BBZnFKSVMwZEIzRCUyRm11SW93JTNEJTNE',
'Sec-Ch-Ua': '"Not/A)Brand";v="99", "Microsoft Edge";v="115", "Chromium";v="115"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188'}
get_content_black(url,pic_name,save_dir,headers)2.3 solicitar acceso
request.get(url,headers) representa la obtención de información del sitio web, url representa la dirección del sitio web y los encabezados representan los encabezados de solicitud anteriores. El Response.status_code devuelto guardará el código de estado. 200 significa que el acceso fue exitoso y los demás son fallas. .
response = requests.get(url, headers=headers)
if response.status_code != 200:
print('访问失败')
return
if response.status_code == 200:
print('访问成功')2.4 Ver el html obtenido
beautifulSoup() convierte la estructura html devuelta por la respuesta al formato lxml para facilitar operaciones posteriores
html = BeautifulSoup(response.content, 'lxml')
print(html) # 查看htmlEl html impreso es el siguiente:
A continuación, puede obtener el contenido en HTML como si manipulara una matriz.

2.5 Obtener la dirección del contenido deseado en html
1) Primero, necesita encontrar la estructura HTML de su ubicación de destino. Por ejemplo, si desea una imagen detallada de este sitio web que vende ropa, el funcionamiento es el siguiente:
O presione F12 para recortar el fondo, haga clic en el botón con la flecha del mouse y luego haga clic en la imagen. En este momento, la estructura html de la imagen se mostrará a la derecha. Se puede ver que estas imágenes detalladas están encapsulados en una clase llamada DetailArea. A continuación, la dirección de la imagen en sí está encapsulada en el atributo src de una etiqueta img, por lo que es suficiente saber esto.

2) Código buscando estructura
Primero busque toda la información de la etiqueta en el nombre de la clase DetailArea a través de .find_all
content = html.find_all('div', class_="detailArea")
print(content)El resultado de la impresión es el siguiente:
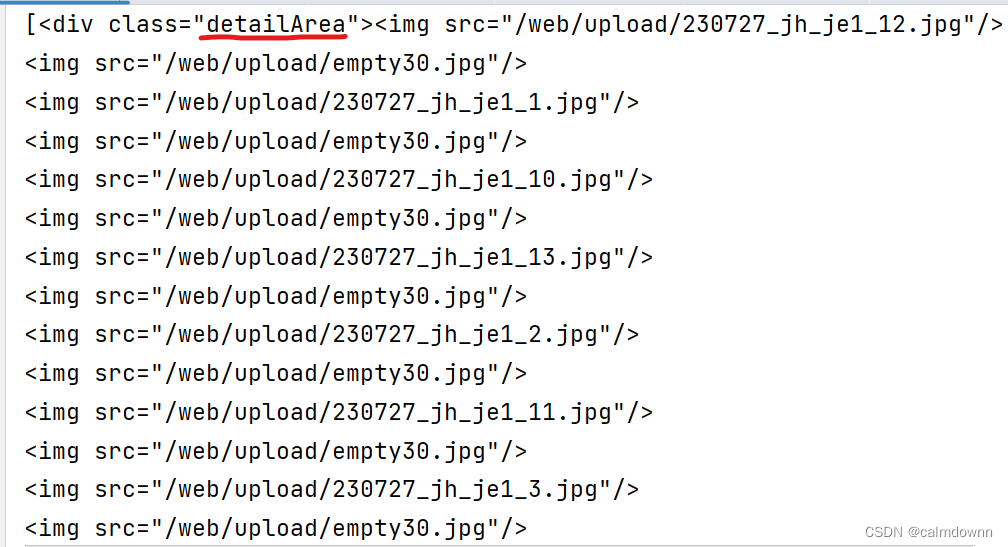
Descubrimos que existe la etiqueta img que queremos y que también es una imagen detallada. Puede compararla usted mismo. El siguiente paso es muy claro. Utilice find_all para extraer todas las etiquetas img. Aquí se utiliza el contenido [0] porque se devolvió en el paso anterior. De hecho, es un formato de lista (tenga en cuenta los corchetes en la imagen de arriba), y esta lista tiene solo un elemento (porque solo se encuentra un nombre de clase de área de detalle. Si hay varios div clases de DetailArea, habrá múltiples elementos. Use comas en la lista (separados), aunque es muy largo, aún debe obtener el primer elemento al llamar, por lo que aparece contenido [0].
pics = content[0].find_all('img') # 第一个子集
print(pics)El resultado de la impresión es el siguiente:
Puede ver que debido a que hay varias etiquetas img en la clase DetailArea, los retornos también están en forma de lista, por lo que el siguiente paso es realizar un bucle for en esta lista para extraer todos los valores src.
Utilice un bucle for para extraer el valor después de cada signo igual de src, luego empalme el encabezado de la URL y luego coloque la información de la URL empalmada en una nueva lista. En este momento, se almacenan todas las direcciones de enlace de las imágenes. en la nueva lista. Entendido.
# 循环获得子集里img的键值对
for i in pics:
pic_url = 'https://www.black-up.kr/' + i['src']
pic_urls.append(pic_url)Los resultados de la impresión de la lista son los siguientes:

El último paso es descargar y guardar la imagen, el código es el siguiente:
request.get (url, encabezados) Este método se utiliza para descargar el contenido de la URL. El parámetro URL representa la URL y los encabezados son los encabezados de solicitud que siempre se usan. Debido a que cada sitio web de imágenes es diferente, debe juzgar si el código de estado es 200 significa si el acceso fue exitoso. El acceso exitoso significa que la descarga de la imagen fue exitosa. Luego, configure el nombre del archivo y junte la ruta de guardado y el nombre del archivo, y finalmente guárdelo localmente.
num = 0
for each_img_url in pic_urls:
response = requests.get(each_img_url, headers=headers)
# print(response.status_code)
# exit()
if response.status_code == 200:
# 获取文件名
file_name = pic_name + str(num) + '.jpg'
num = num + 1
# 拼接保存图片的完整路径
save_path = os.path.join(save_dir, file_name)
# 保存图片到本地
with open(save_path, 'wb') as file:
file.write(response.content)
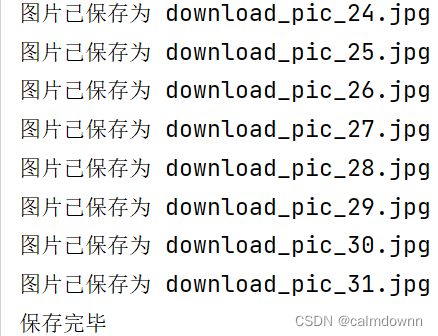
print(f'图片已保存为 {file_name}')
# print(f'图片已保存为 {file_name}')
else:
print('无法下载图片')
print(f'保存完毕')
La captura de pantalla en ejecución es la siguiente:

3. Resumen
Eso se acabó. Hablemos de algo adicional. Si desea obtener información específica, como una imagen específica, puede observar la diferencia entre la estructura html de esta imagen y otras imágenes, y luego usar algunas condiciones if para dar Simplemente sepárelo. Es un proceso en el que la práctica hace la perfección. Cuando utilice el código, no olvide utilizar sus propios encabezados y formatearlos. Eso es todo lo que tengo que decir. He puesto todos los códigos a continuación. Si todavía ¿No entiendes o tienes alguna pregunta? Si tienes dificultades también puedes contactarme por correo electrónico y podemos avanzar juntos [email protected]
import requests
from bs4 import BeautifulSoup
import os
def get_content_black(url, pic_name, save_dir, headers):
pic_urls = []
response = requests.get(url, headers=headers)
if response.status_code != 200:
print('访问失败')
return
if response.status_code == 200:
print('访问成功')
# print(response) # 查看是否请求成功
print("**开始获取图片**")
html = BeautifulSoup(response.content, 'lxml')
# print(html) # 查看html
content = html.find_all('div', class_="detailArea") # class为detail的子集
# print(content)
first_single = html.find_all('div', class_="keyImg") # 首页第一个照片
# print(first_single)
first_single_a = first_single[0].find_all('a') # 获取a标签
first_single_a_i = first_single_a[0].find_all('img') # 进入img标签
first_single_src = first_single_a_i[0]['src'] # 取键值对
first_single_src = 'https:' + first_single_src
# first_single_src = first_single_src.replace("//", "", 1) # 删除字符串开头的//
pic_urls.append(first_single_src) # 添加到数组中
# print(first_single_src)
pics = content[0].find_all('img') # 第一个子集
# print(pics)
# 循环获得子集里img的键值对
for i in pics:
pic_url = 'https://www.black-up.kr/' + i['src']
pic_urls.append(pic_url)
# print(pic_url)
# print(pic_urls)
if len(pic_urls) == 0:
print(f'图片获取失败')
return
print(f'图片获取成功')
# 下面是下载图片
num = 0
for each_img_url in pic_urls:
response = requests.get(each_img_url, headers=headers)
# print(response.status_code)
# exit()
if response.status_code == 200:
# 获取文件名
file_name = pic_name + str(num) + '.jpg'
num = num + 1
# 拼接保存图片的完整路径
save_path = os.path.join(save_dir, file_name)
# 保存图片到本地
with open(save_path, 'wb') as file:
file.write(response.content)
print(f'图片已保存为 {file_name}')
else:
print('无法下载图片')
print(f'保存完毕')
return pic_urls
if __name__ == '__main__':
# 爬虫网址
url = "https://www.black-up.kr/product/detail.html?product_no=32474&cate_no=96&display_group=1"
# 文件命名
pic_name = "download_pic_"
# 保存文件目录
save_dir = "D:\lableimg1.8\csdn\spider_pic"
# 请求头
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cookie': '_gcl_au=1.1.511254458.1684805008; CUK45=cuk45_skfo900815_4d9322403b6cab3d50371082910e0531; CUK2Y=cuk2y_skfo900815_4d9322403b6cab3d50371082910e0531; _fbp=fb.1.1684805009113.971249844; black-up.kr-crema_device_token=LzzlyHO6YLN0keIv2jauEH73Xy2PRdBz; CFAE_CUK1Y=CFAE_CUK1Y.skfo900815_1.PZPJ94T.1684805009865; ch-veil-id=dafe7ccc-ecc3-43cd-ade9-bfcb8e1187dd; _wp_uid=2-45d93ef5ddc801f3dc97e1ec636ad20b-s1684809260.904994|windows_10|chrome-eqdzf9; _ga=GA1.2.1044427573.1684823556; recent_plist=31429%7C31417%7C31495%7C31421%7C31458%7C31211; wcs_bt=s_47112a8eb19a:1686401209; cto_bundle=k7_3Fl9saEF4MGhSelVRU3EwVDFZMElMRXZCdHpEZUk0WnNFcG5GRG5lS3dGJTJCSkIydXM5aXlHdnglMkJ5JTJGdFJ3QkxMYTRKRjdkYnJQcHA2eVp4U1lTbUFscXlvOHU2VHduaCUyQldHQXhLR3BJNmp5dFlKVXJGcUdPejZmVTNRV24xOXlMU3JGdmhKY3BBZnFKSVMwZEIzRCUyRm11SW93JTNEJTNE',
'Sec-Ch-Ua': '"Not/A)Brand";v="99", "Microsoft Edge";v="115", "Chromium";v="115"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188'}
get_content_black(url,pic_name,save_dir,headers)