Comencemos Hello Worldcon un ejemplo de:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
Cuando terminamos de escribir el código de hola mundo anterior en el teclado, el archivo guardado en el disco duro hello.goes una secuencia de bytes y cada byte representa un carácter.
Abra el archivo hello.go con vim y, en modo de línea de comando, ingrese el comando:
:%!xxd
Puede ver el contenido del archivo en hexadecimal en vim:

La columna de la izquierda representa el valor de la dirección, la columna del medio representa los caracteres ASCII correspondientes al texto y la columna de la derecha es nuestro código. Luego ejecuta en la terminal man ascii:
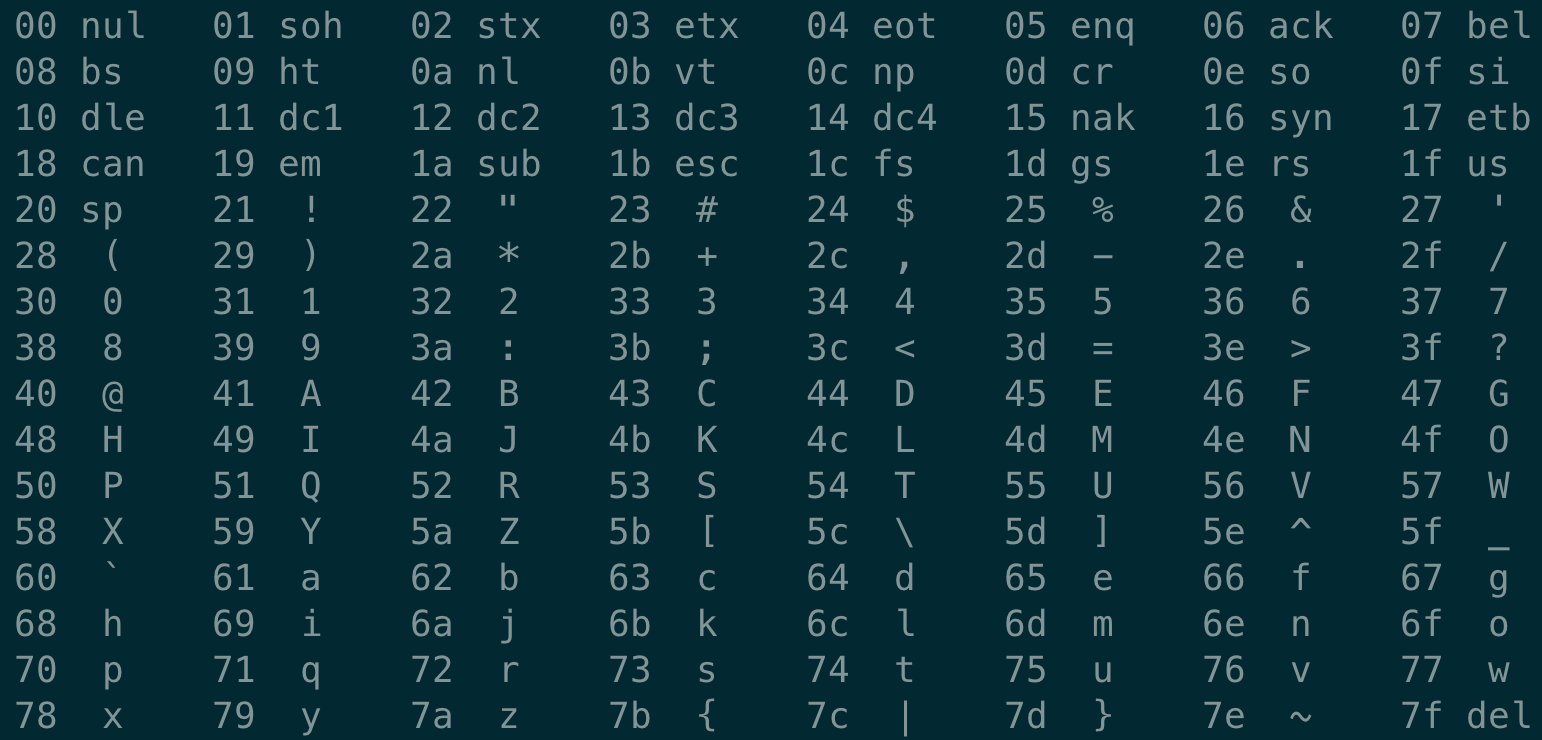
Comparándolo con la tabla de caracteres ASCII, puede encontrar que la columna del medio y la columna más a la derecha están en correspondencia uno a uno. En otras palabras, el archivo hello.go que acaba de escribir está representado por caracteres ASCII, se llama 文本文件y otros archivos se llaman 二进制文件.
Por supuesto, si miramos más profundamente, todos los datos en la computadora, como los archivos de disco y los datos en la red, en realidad están compuestos por una cadena de bits, dependiendo de cómo se mire. En diferentes situaciones, la misma secuencia de bytes se puede representar como un número entero, un número de punto flotante, una cadena o una instrucción de máquina.
En cuanto a archivos como hello.go, 8 bits, es decir, un byte se considera una unidad (suponiendo que los caracteres del programa fuente sean todos códigos ASCII) y, en última instancia, se interpreta en el código fuente de Go que los humanos pueden leer.
Los programas Go no se pueden ejecutar directamente. Cada declaración de Go debe convertirse en una serie de instrucciones en lenguaje de máquina de bajo nivel, empaquetarse juntas y almacenarse en forma de un archivo de disco binario, que es un archivo objeto ejecutable.
El proceso de conversión de archivos de origen a archivos de destino ejecutables:
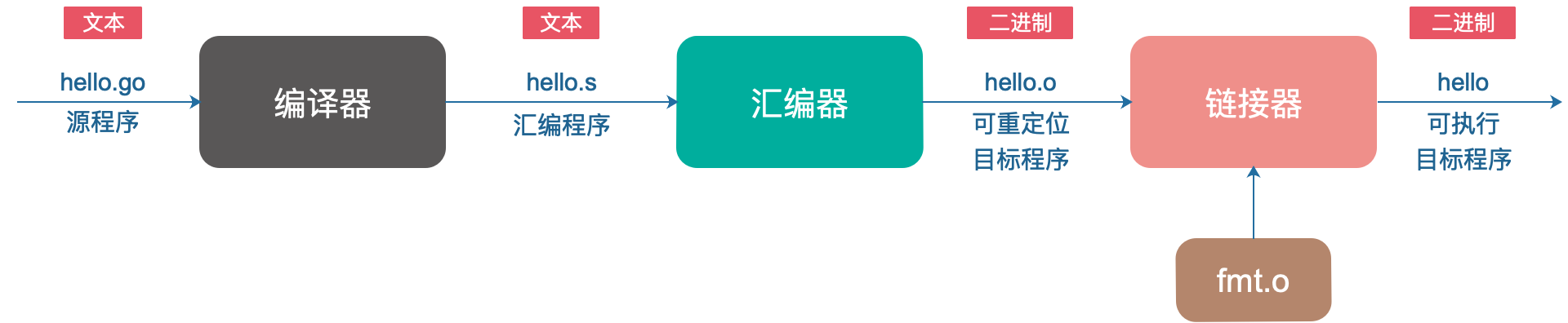
Lo que completa las etapas anteriores es el sistema de compilación Go. Debe conocer el famoso GCC (GNU Compile Collection), el nombre chino es GNU Compiler Suite, que admite C, C ++, Java, Python, Objective-C, Ada, Fortran, Pascal y puede generar código de máquina para muchas máquinas diferentes. .
Los archivos de objetos ejecutables se pueden ejecutar directamente en la máquina. En términos generales, primero se realiza algún trabajo de inicialización; se encuentra la entrada a la función principal y se ejecuta el código escrito por el usuario; una vez completada la ejecución, la función principal sale; luego se realiza algún trabajo de finalización y todo se completa el proceso.
En el próximo artículo, exploraremos el proceso de 编译suma 运行.
El código fuente del compilador en el código fuente de Go se encuentra src/cmd/compiledebajo de la ruta y el código fuente del vinculador se encuentra src/cmd/linkdebajo de la ruta.
Proceso de compilación
Prefiero usar un IDE (entorno de desarrollo integrado) para escribir código. Goland se usa para el código fuente de Go. A veces simplemente hago clic en el botón "Ejecutar" en la barra de menú del IDE y el programa se ejecutará. En realidad, esto implica el proceso de compilación y vinculación. Generalmente combinamos la compilación y la vinculación como un proceso llamado compilación.
El proceso de compilación consiste en realizar análisis léxico, análisis de sintaxis, análisis semántico y optimización en el archivo fuente y, finalmente, generar un archivo de código ensamblador como .ssufijo del archivo.
Luego, el ensamblador convierte el código ensamblador en instrucciones que la máquina puede ejecutar. Dado que casi todas las declaraciones ensambladas corresponden a instrucciones de máquina, es solo una correspondencia simple uno a uno, que es relativamente simple, sin sintaxis, análisis semántico ni pasos de optimización.
Un compilador es una herramienta que traduce lenguajes de alto nivel a lenguajes de máquina. El proceso de compilación generalmente se divide en seis pasos: escaneo, análisis de sintaxis, análisis semántico, optimización del código fuente, generación de código y optimización del código de destino. La siguiente imagen es de "Autocultivo del programador":
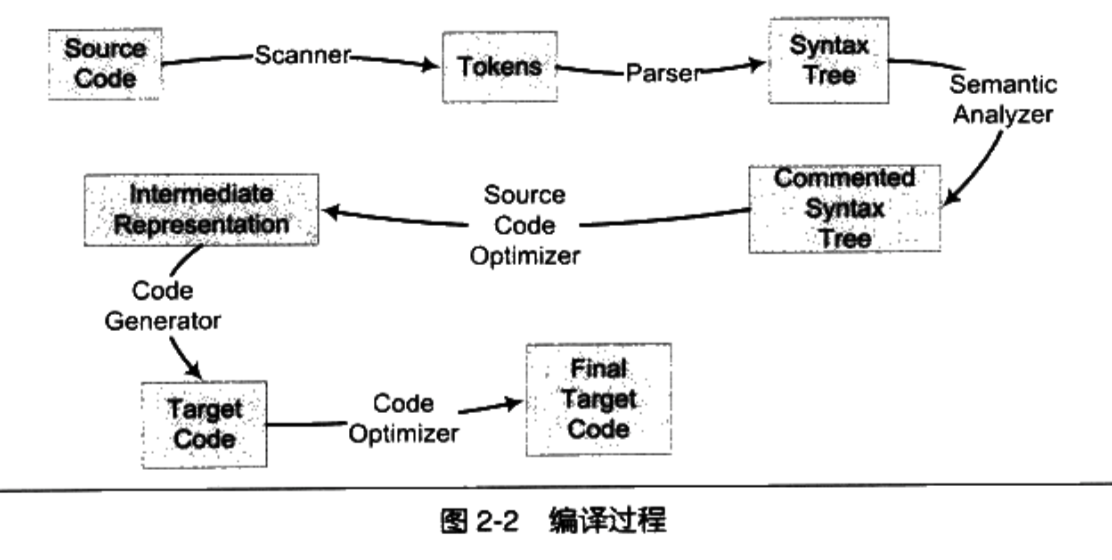
análisis léxico
Por el ejemplo anterior, sabemos que un archivo de programa Go no es más que un montón de bits binarios desde la perspectiva de la máquina. Podemos entenderlo porque Goland codifica este conjunto de bits binarios según el código ASCII (en realidad, UTF-8). Por ejemplo, 8 bits se dividen en un grupo, correspondiente a un carácter, y se pueden encontrar comparando la tabla de códigos ASCII.
Cuando todos los bits binarios se asignan a caracteres ASCII, podemos ver cadenas significativas. Puede ser una palabra clave, como paquete; puede ser una cadena, como "Hola mundo".
Esto es lo que realmente hace el análisis léxico. La entrada es el archivo del programa Go original. Desde la perspectiva del analizador léxico, es solo un montón de bits binarios. Se desconoce qué son. Después de su análisis, se convierte en tokens significativos. En pocas palabras, el análisis léxico es el proceso en informática de convertir una secuencia de caracteres en una secuencia de tokens.
Echemos un vistazo a la definición dada en Wikipedia:
El análisis léxico es el proceso en informática de convertir una secuencia de caracteres en una secuencia de tokens. El programa o función que realiza el análisis léxico se denomina analizador léxico (lexer para abreviar), también llamado escáner. Los analizadores léxicos generalmente existen en forma de funciones que el analizador de sintaxis puede llamar.
.goEl archivo se ingresa al escáner (Scanner), que utiliza un 有限状态机algoritmo similar al del código fuente para dividir la serie de caracteres del código fuente en una serie de tokens (Token).
Los tokens generalmente se dividen en estas categorías: palabras clave, identificadores, literales (incluidos números y cadenas) y símbolos especiales (como el signo más, el signo igual).
Por ejemplo, para el siguiente código:
slice[i] = i * (2 + 6)
Contiene un total de 16 caracteres no vacíos. Después del escaneo,
| marca | tipo |
|---|---|
| rebanada | identificador |
| [ | corchete izquierdo |
| i | identificador |
| ] | corchete derecho |
| = | Asignación |
| i | identificador |
| * | Signo de multiplicación |
| ( | paréntesis izquierdo |
| 2 | número |
| + | más |
| 6 | número |
| ) | paréntesis derecho |
El ejemplo anterior proviene del "Autocultivo del programador", que explica principalmente el contenido relacionado con la compilación y la vinculación, es muy interesante y se recomienda leerlo.
Idioma Go (la versión Go de este artículo es 1.9.2) Token admitido por la ruta del escáner en el código fuente:
src/cmd/compile/internal/syntax/token.go
Sentirlo:
var tokstrings = [...]string{
// source control
_EOF: "EOF",
// names and literals
_Name: "name",
_Literal: "literal",
// operators and operations
_Operator: "op",
_AssignOp: "op=",
_IncOp: "opop",
_Assign: "=",
_Define: ":=",
_Arrow: "<-",
_Star: "*",
// delimitors
_Lparen: "(",
_Lbrack: "[",
_Lbrace: "{",
_Rparen: ")",
_Rbrack: "]",
_Rbrace: "}",
_Comma: ",",
_Semi: ";",
_Colon: ":",
_Dot: ".",
_DotDotDot: "...",
// keywords
_Break: "break",
_Case: "case",
_Chan: "chan",
_Const: "const",
_Continue: "continue",
_Default: "default",
_Defer: "defer",
_Else: "else",
_Fallthrough: "fallthrough",
_For: "for",
_Func: "func",
_Go: "go",
_Goto: "goto",
_If: "if",
_Import: "import",
_Interface: "interface",
_Map: "map",
_Package: "package",
_Range: "range",
_Return: "return",
_Select: "select",
_Struct: "struct",
_Switch: "switch",
_Type: "type",
_Var: "var",
}
Todavía es relativamente familiar, incluidos nombres y literales, operadores, delimitadores y palabras clave.
Y el camino al escáner es:
src/cmd/compile/internal/syntax/scanner.go
La función más crítica es la siguiente función, que lee continuamente el siguiente carácter (no el siguiente byte, porque el lenguaje Go admite la codificación Unicode, no como el ejemplo de código ASCII que dimos anteriormente, donde un carácter solo tiene un byte), hasta que estos Los personajes pueden constituir una Ficha.
func (s *scanner) next() {
// ……
redo:
// skip white space
c := s.getr()
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
// token start
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
s.ident()
return
}
switch c {
// ……
case '\n':
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
// ……
default:
s.tok = 0
s.error(fmt.Sprintf("invalid character %#U", c))
goto redo
return
assignop:
if c == '=' {
s.tok = _AssignOp
return
}
s.ungetr()
s.tok = _Operator
}
La lógica principal del c := s.getr()obtener el siguiente carácter no analizado a través decódigo esswitch-case
El escáner del analizador léxico en el paquete actual solo proporciona el siguiente método para la capa superior. El proceso de análisis léxico es lento. Se llamará a Next para obtener el último token solo cuando el analizador de la capa superior lo necesite.
análisis de gramática
La secuencia de token generada en el paso anterior debe procesarse más 表达式para nodo 语法树.
Por ejemplo, en el primer ejemplo, slice[i] = i * (2 + 6)el árbol de sintaxis resultante es el siguiente:

La declaración completa se considera una expresión de asignación, el subárbol izquierdo es una expresión de matriz y el subárbol derecho es una expresión de multiplicación; la expresión de matriz consta de 2 expresiones simbólicas; la expresión de multiplicación se compone de una expresión simbólica Consiste en una expresión y una expresión con signo más; la expresión con signo más consta de dos números. Los símbolos y números son las expresiones más pequeñas que ya no se pueden descomponer y normalmente sirven como nodos de hojas de un árbol.
El proceso de análisis de sintaxis puede detectar algunos errores formales, como si falta la mitad de los paréntesis, si a una +expresión le falta un operando, etc.
El análisis gramatical es un proceso que analiza el texto de entrada compuesto por secuencias de Token de acuerdo con una gramática formal específica (Gramática) y determina su estructura gramatical.
Análisis semántico
Una vez completado el análisis gramatical, no sabemos cuál es el significado específico de la declaración. Si los dos subárboles del número anterior *son dos punteros, esto es ilegal, pero el análisis sintáctico no puede detectarlo, esto es lo que hace el análisis semántico.
Lo que se puede verificar en el momento de la compilación es la semántica estática, que se puede considerar en la etapa de "código", incluida la coincidencia de tipos de variables, la conversión, etc. Por ejemplo, al asignar un valor de punto flotante a una variable de puntero, si hay una discrepancia de tipo obvia, se informará un error de compilación. En cuanto a los errores que sólo ocurren durante el tiempo de ejecución: si accidentalmente agrega un 0, el análisis semántico no puede detectarlo.
Una vez completada la fase de análisis semántico, cada nodo se marcará con un tipo:
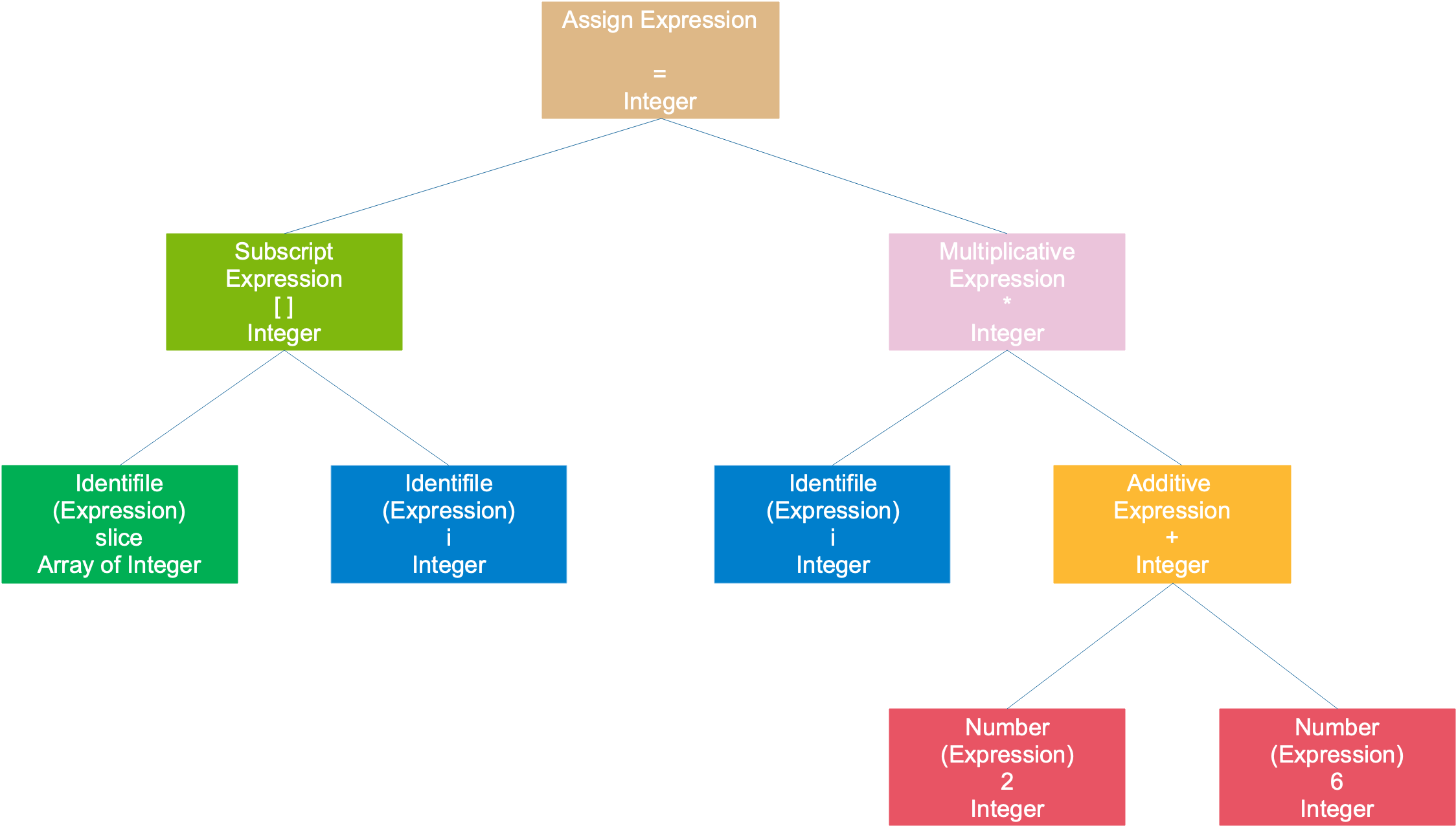
En esta fase, el compilador de Go verifica los tipos de constantes, tipos, declaraciones de funciones y declaraciones de asignación de variables, y luego verifica los tipos de claves en el hash. Las funciones que implementan la verificación de tipos suelen ser declaraciones gigantes de cambio/caso de varios miles de líneas.
La verificación de tipos es la segunda etapa de la compilación del lenguaje Go. Después del análisis léxico y sintáctico, obtenemos el árbol de sintaxis abstracta correspondiente a cada archivo. La verificación de tipos posterior atravesará los nodos en el árbol de sintaxis abstracta y realizará la verificación de tipos en cada nodo. Verifique para encontrar errores gramaticales.
El árbol de sintaxis abstracta también se puede reescribir durante este proceso, lo que no solo elimina parte del código que no se ejecutará para optimizar la compilación y mejorar la eficiencia de la ejecución, sino que también modifica los tipos de operación de los nodos correspondientes a palabras clave como make y new.
Por ejemplo, la palabra clave make, más utilizada, se puede utilizar para crear varios tipos, como sectores, mapas, canales, etc. En este paso, para la palabra clave make, es decir, el nodo OMAKE, primero se verificará su tipo de parámetro y, según el tipo, se ingresará la rama correspondiente. Si el tipo de parámetro es segmento, ingresará a la rama de caso TSLICE y verificará si len y cap cumplen con los requisitos, como len <= cap. Finalmente, el tipo de nodo se cambiará de OMAKE a OMAKESLICE.
Generación de código intermedio.
Sabemos que el proceso de compilación generalmente se puede dividir en front-end y back-end: el front-end genera código intermedio que es independiente de la plataforma y el back-end genera diferentes códigos de máquina para diferentes plataformas.
El análisis léxico anterior, el análisis de sintaxis, el análisis semántico, etc. pertenecen al front-end del compilador, y las etapas posteriores pertenecen al back-end del compilador.
Hay muchos enlaces de optimización en el proceso de compilación, y este enlace se refiere a la optimización a nivel de código fuente. Convierte árboles de sintaxis en códigos intermedios, que son representaciones secuenciales de árboles de sintaxis.
El código intermedio generalmente es independiente de la máquina de destino y del entorno de ejecución y tiene varias formas comunes: código de tres direcciones y código P. Por ejemplo, el más básico 三地址码es este:
x = y op z
Significa que después de que la variable y y la variable z realizan la operación operativa, se asignan a x. op puede ser una operación matemática como suma, resta, multiplicación y división.
El ejemplo que dimos anteriormente se puede escribir de la siguiente forma:
t1 = 2 + 6
t2 = i * t1
slice[i] = t2
Aquí 2 + 6 se puede calcular directamente, de modo que la variable temporal t1 se "optimiza" y la variable t1 se puede reutilizar, por lo que t2 también se puede "optimizar". Después de la optimización:
t1 = i * 8
slice[i] = t1
La representación de código intermedio del lenguaje Go es SSA (Static Single-Assignment, asignación única estática), se llama asignación única porque cada nombre se asigna solo una vez en SSA. .
En esta etapa, las variables correspondientes utilizadas para generar código intermedio se configurarán de acuerdo con la arquitectura de la CPU, como el tamaño de los punteros y registros utilizados por el compilador, la lista de registros disponibles, etc. Las dos partes, la generación de código intermedio y la generación de código de máquina, comparten la misma configuración.
Antes de generar código intermedio, se reemplazan algunos elementos de los nodos en el árbol de sintaxis abstracta. Aquí hay una imagen de un blog relacionado con los principios de compilación de la "Programación orientada a la fe":
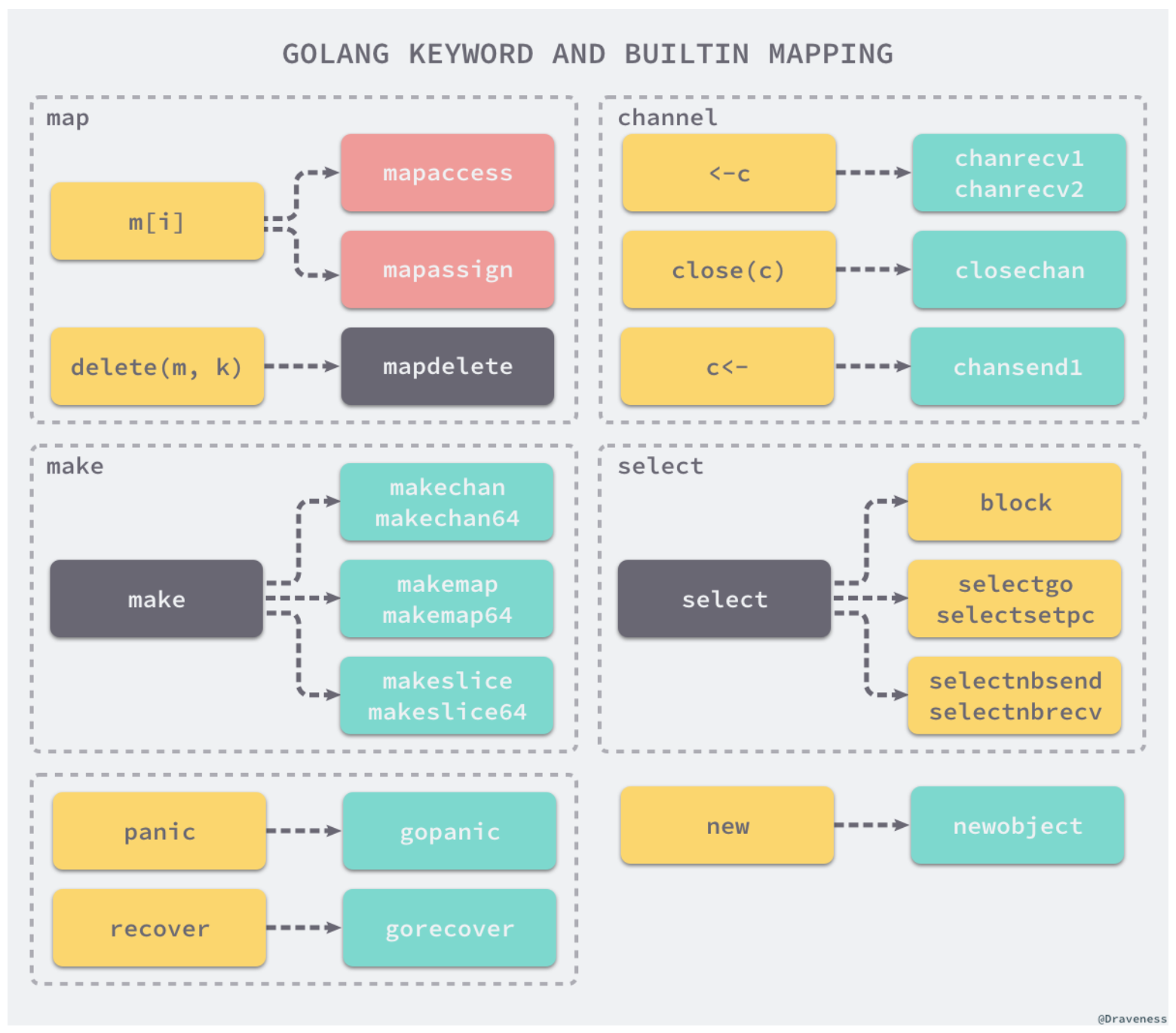
Por ejemplo, la operación de mapa m [i] se convertirá aquí en mapacess o mapassign.
El programa principal del lenguaje Go llamará funciones en el tiempo de ejecución cuando se ejecute, en otras palabras, las funciones de las palabras clave y las funciones integradas en realidad las completan el compilador del lenguaje y el tiempo de ejecución.
El proceso de generación de código intermedio es en realidad el proceso de conversión del árbol de sintaxis abstracta AST al código intermedio SSA. Durante este período, las palabras clave en el árbol de sintaxis se actualizarán una vez y el árbol de sintaxis actualizado se someterá a múltiples rondas de procesamiento para transformar el SSA final, código intermedio.
Generación y optimización de código de destino.
Diferentes máquinas tienen diferentes longitudes de palabras, registros, etc., lo que significa que el código de máquina que se ejecuta en diferentes máquinas es diferente. El propósito del paso final es generar código que pueda ejecutarse en diferentes arquitecturas de CPU.
Para exprimir cada gota de aceite y agua de la máquina, el optimizador de código de destino optimizará algunas instrucciones, como usar instrucciones de cambio en lugar de instrucciones de multiplicación.
Realmente no tengo la capacidad de profundizar en esta área, pero afortunadamente no necesito profundizar. Para los ingenieros de desarrollo de software en la capa de aplicaciones, es suficiente entenderlo.
proceso de enlace
El proceso de compilación se realiza para un solo archivo, y los archivos inevitablemente hacen referencia a variables globales o funciones definidas en otros módulos, las direcciones de estas variables o funciones solo se pueden determinar en esta etapa.
El proceso de vinculación consiste en vincular los archivos objeto generados por el compilador en archivos ejecutables. El archivo final se divide en varios segmentos, como segmentos de datos, segmentos de código, segmentos BSS, etc., y se cargará en la memoria durante el tiempo de ejecución. Cada segmento tiene diferentes atributos de lectura, escritura y ejecución, lo que protege el funcionamiento seguro del programa.