Página de inicio del proyecto: https://lukemelas.github.io/realfusion
Artículo: RealFusion: reconstrucción 360◦ de cualquier objeto a partir de una sola imagen
Directorio de artículos
Resumen
采用一个基于扩散模型的条件图像生成器,并设计一个提示,鼓励它“想出”物体的新视图,从单一图像重建一个完整的360◦模型,使用最近的 DreamFusion 方法,我们将给定的输入视图、条件先验和其他正则化器融合到一个最终的、一致的重建中。重建提供了输入视图的忠实匹配,以及对其外观和三维形状的合理预测,包括物体不可见的一面。
I. Introducción
El desafío es que una sola imagen no contiene suficiente información para una reconstrucción 3D. Pero se puede lograr aprovechando el vasto conocimiento humano del mundo natural y los objetos que contiene para compensar la información que falta en la imagen.
Para resolver el problema, la geometría visual debe combinarse con un potente modelo estadístico del mundo tridimensional . Recientemente, generadores de imágenes 2D como DALL-E [36], Imagen [42] y difusión estable [40] pueden resolver tareas de generación altamente ambiguas mediante difusión, que van desde descripciones de texto, mapeos semánticos, imágenes parcialmente completas o ruido aleatorio. Imágenes 2D. Claramente, estos modelos tienen antecedentes de alta calidad . Si bien las personas tienen acceso a miles de millones de imágenes en 2D, no se puede decir lo mismo de los datos en 3D.
Otra forma de entrenar un modelo de difusión 3D es extraer información 3D de un modelo 2D existente. Un ejemplo reciente es DreamFusion [33], que genera modelos 3D de alta calidad únicamente a partir de descripciones textuales.
En este artículo, utilizamos un campo de radiación neuronal para representar la geometría tridimensional y la apariencia de un objeto . El entrenamiento reconstruye una imagen de entrada determinada minimizando la pérdida de renderizado habitual. Al mismo tiempo, tomamos muestras aleatorias de otras vistas del objeto y utilizamos antecedentes de difusión para restringirlas utilizando una técnica similar a DreamFusion. Esto requiere agregar condiciones suficientemente razonables al modelo de difusión. La idea es configurar un previo a "imaginar" o tomar imágenes, que puedan constituir otras vistas del objeto. Específicamente, las palabras de aviso difusas se crean mejorando aleatoriamente una imagen determinada . Sólo de esta manera los modelos de difusión pueden proporcionar restricciones suficientemente fuertes.
Además de configurar las sugerencias correctamente, también agregamos algunos regularizadores: sombrear la geometría subyacente y eliminar texturas aleatoriamente (también similar a Dream Fusion), suavizar las normales de la superficie y ajustar el modelo de manera gruesa a fina, capturando el object 's Se captura la estructura general y luego solo los detalles finos. En términos de eficiencia, el modelo se basa en Instant NGP [29] para lograr la reconstrucción en cuestión de horas.
No entrenamos un modelo completo de 2D a 3D, ni estamos restringidos a objetos específicos; en cambio, entrenamos previamente un generador 2D de imagen a imagen. Cuantitativa y cualitativamente, supera a los reconstructores de una sola imagen anteriores, incluida la predicción de malla supervisada por estante [58] (con supervisión personalizada específicamente para la reconstrucción 3D).
Las contribuciones son :
(1) RealFusion no requiere suposiciones sobre los tipos de imágenes de objetos ni ningún tipo de supervisión 3D; aprovecha los generadores de imágenes de difusión 2D existentes para nuevas transformaciones de imágenes individuales
(2) Se introduce e implementa eficazmente un nuevo regularizador utilizando InstantNGP
2. Trabajo relacionado
1. Reconstrucción de geometría y apariencia basada en imágenes
El problema de la reconstrucción fotométrica y geométrica se ha revitalizado enormemente con la introducción de los campos de radiación neuronal (NeRF: la coordenada MLP proporciona una representación de dominio tridimensional compacta pero expresable para un modelado eficiente). Neus utiliza funciones de distancia con signo (SDF) para recuperar geometrías más limpias. Estos métodos suponen cientos de vistas por escena para la reconstrucción. donde utilizamos un modelo de difusión para "imaginar" la vista faltante
2. Reconstrucción con pocas vistas
Estrechamente relacionado con nuestro trabajo está NeRF-on-a-Diet [17], que reduce la cantidad de imágenes necesarias para aprender NeRF generando vistas aleatorias y midiendo su "compatibilidad semántica" con las vistas disponibles mediante la incrustación CLIP [35] , pero todavía requieren múltiples vistas de entrada.
3. Reconstrucción de vista única
La recuperación de un campo de radiación completo a partir de una sola imagen normalmente requiere datos de múltiples vistas para el entrenamiento, así como un modelo de aprendizaje específico para una clase de objeto particular. 3D-R2N2 [5], Pix2Vox [55, 55] y LegoFormer [57] aprenden a reconstruir representaciones volumétricas de objetos simples, aprovechando principalmente datos sintéticos (como ShapeNet). Recientemente, CodeNeRF [19] predice un campo de radiación completo que incluye fotometría de objetos reconstruidos.
4. Extraiga el modelo 3D del generador 2D.
CLIP-Mesh y Dream Fields Al utilizar la incrustación CLIP, se puede lograr la generación de texto en 3D. Nuestro modelo está construido sobre DreamFusion (utilizando un modelo de difusión). [Síntesis de vista novedosa con modelos de difusión] propone generar directamente múltiples vistas 2D de un objeto y luego utilizar un modelo similar a nerf para la reconstrucción 3D. El modelo requiere datos de múltiples vistas para el entrenamiento, solo se prueba con datos sintéticos y necesita muestrear explícitamente múltiples vistas para su reconstrucción.
2. Modelo de difusión
El modelo probabilístico de eliminación de ruido por difusión es un tipo de modelo generativo basado en la inversión iterativa del proceso de ruido de Markov. En visión, los primeros trabajos formularon el problema como el aprendizaje de límites inferiores variacionales [14], o lo definieron como la optimización de la discretización de modelos generativos basados en puntuaciones [45, 46] o procesos estocásticos continuos [47]. Las mejoras recientes incluyen el uso de muestreo más rápido y determinista [14, 25, 52], modelos condicionales de clase [7, 46], modelos condicionales de texto [32] y modelado en espacios latentes [41].
3. Método de este artículo.
3.1 Campos de radiación y DreamFusion (conocimientos preliminares)
- Campos de radiación Un campo de radiación (RF) es un par de funciones (
σ(x), c(x)) que asigna un punto 3D x∈R3 a un valor de opacidad σ(x)∈R + y un valor de color c( x) ∈R 3 . I (u)∈R 3 es el color del píxel u, que se representa mediante rayos (consulte el blog [Principio NeRF] para obtener más detalles):
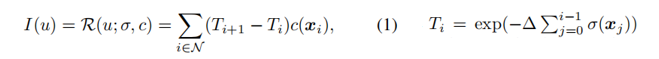
El diagrama de la función de pérdida es el siguiente :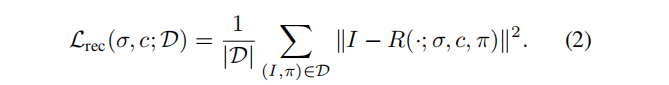
- modelo de difusión
Consulte el blog [Modelo de difusión probabilística de DDPM], la función de pérdida es:
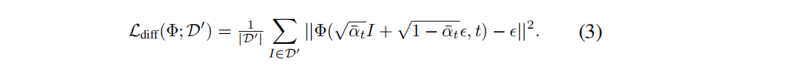
Este modelo se puede ampliar fácilmente para extraer muestras de la distribución p(x|e) bajo la condición del mensaje e . El muestreo condicional de indicaciones se obtiene agregando e como una entrada adicional a la red Φ , y la fuerza del condicionamiento se puede controlar mediante bootstrapping sin clasificador [7].
- DreamFusion y SDS (muestreo por destilación fraccionada)
Dado un modelo de difusión bidimensional p (I | e) y una palabra rápida e, DreamFusion usa RF (σ, c) para extraer la representación tridimensional del concepto correspondiente del modelo. Muestra aleatoriamente un parámetro de cámara π, usa RF para representar la vista correspondiente I π y evalúa su similitud con la vista renderizada en función de la vista generada por el modelo p (I π |e) y actualiza RF para aumentar el modelo. vista renderizada Autenticidad.
DreamFusion utiliza una red de eliminación de ruido como evaluador congelado y toma pasos de gradiente:
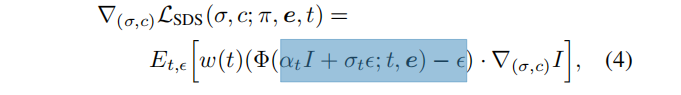
donde I = R(·; σ, c, π), es la imagen renderizada desde una perspectiva dada π, y punta e. Este proceso se llama muestreo por destilación fraccionada (SDS) . La ecuación (4) difiere de simplemente optimizar el objetivo del modelo de difusión estándar porque no incluye el término jacobiano de Φ . En la práctica, eliminar este término mejora la calidad de construcción y reduce los requisitos computacionales y de memoria.
Este último aspecto de DreamFusion es esencial para entender nuestra contribución en la siguiente sección: para obtener buenas formas 3D, es necesario utilizar pesos muy altos de la guía sin clasificador [7] (digamos 100), que son más pequeños que El muestreo de imágenes es mucho mayor. Como resultado, la diversidad generada es a menudo limitada; sólo generan los objetos más probables para una pista determinada, lo cual es incompatible con nuestro objetivo de reconstruir cualquier objeto determinado.
2.RealFusion (énfasis)
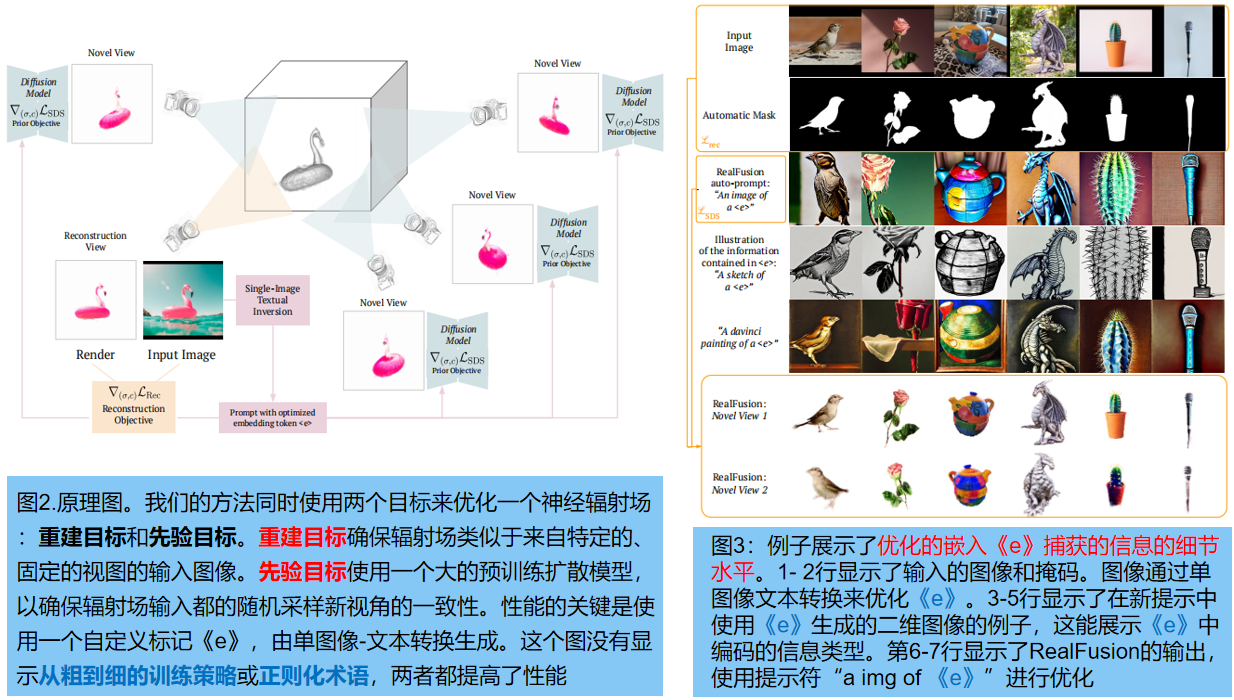
Objetivo: utilizar el anterior en el modelo de difusión Φ para reconstruir un modelo tridimensional del objeto en una sola imagen I 0 . Esto se logra optimizando un campo de radiación logrando dos objetivos simultáneamente:
- Un objetivo de reconstrucción de ángulo fijo: ecuación (2)
- Ecuación objetivo previa basada en SDS (4) para nuevas vistas muestreadas aleatoriamente en cada iteración
1. Conversión de una sola imagen a texto como alternativa a la vista múltiple
Utilice inversión textual de una sola imagen en lugar de vistas múltiples. Dado que las nuevas imágenes no se pueden muestrear directamente de la distribución: p(I|I0 ) , se sintetiza un mensaje de texto e (Io) específicamente para la imagen de entrada I0 , como una aproximación de la vista múltiple p (I| I0 ) ** .
Esto se logra aumentando aleatoriamente la imagen de entrada g (I 0 ) , g∈G , como una vista pseudosustituta. Usamos estos potenciadores como un miniconjunto de datos D'={g(I 0 )} g∈G y optimizamos la ecuación (3) con respecto a la pérdida de difusión L diff (Φ(·; e ( Io) )), mientras congelamos incrustaciones de texto y parámetros del modelo «e» .
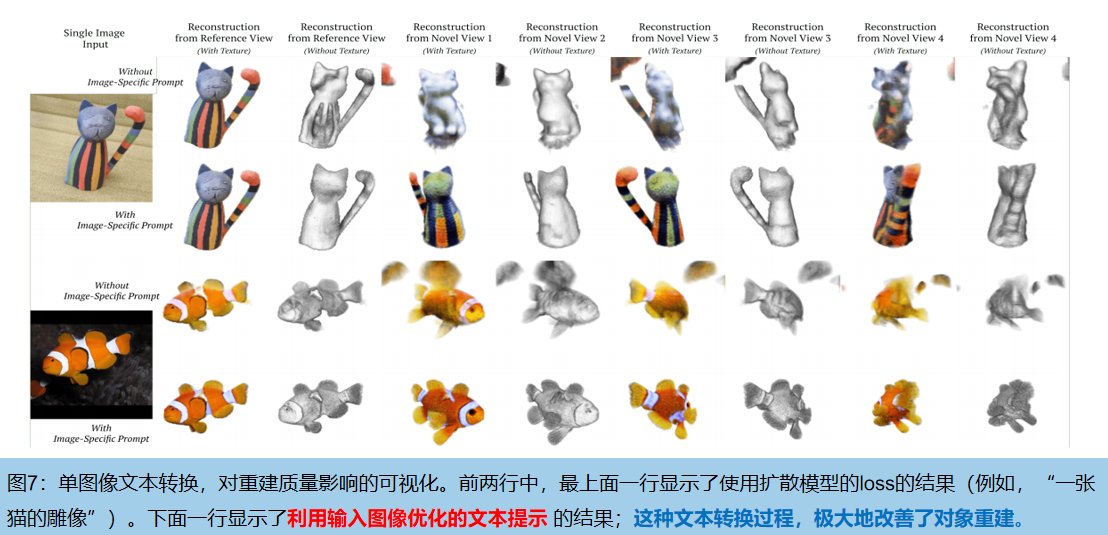
En la práctica, el mensaje se deriva automáticamente de la plantilla “una imagen de una «e»”, donde «e» = g (I 0 ) es un nuevo token introducido en el vocabulario del codificador de texto del modelo de difusión. El proceso de optimización refleja y generaliza el método de conversión de texto propuesto recientemente [10: Una imagen vale más que una palabra].
El texto incrustado "e" contiene el conocimiento de la imagen original: si se utiliza el mensaje de texto general "imagen de un pez" para reconstruir la imagen del pez, se utilizan las pérdidas de las fórmulas (3) y (4). Sin embargo, esto a menudo da como resultado una entrada que se parece al pez de entrada desde un ángulo, pero que parece un pez diferente y más general desde atrás. Por el contrario, utilizando el mensaje "una imagen de una e" , la reconstrucción se parece al pez ingresado desde todos los ángulos . La figura 7 muestra un ejemplo exacto.
2. Entrenamiento de grueso a fino
Modelo de RF: InstantNGP es un modelo basado en cuadrícula que almacena características en los vértices de una cuadrícula de características de resolución múltiple {G i } L i=1 y tiene una alta eficiencia computacional y velocidad de entrenamiento. Sin embargo, el proceso de optimización produce ocasionalmente pequeñas irregularidades en la superficie del objeto . Descubrimos que el entrenamiento de grueso a fino ayuda a aliviar estos problemas: en la primera mitad del entrenamiento, solo optimizamos la cuadrícula de características de baja resolución {G i } L/2 i=1 , y luego en la segunda mitad de entrenamiento Parcialmente, optimizamos todas las cuadrículas de funciones {G i } L i=1 . Al utilizar esta estrategia, obtenemos los beneficios de una capacitación eficiente y resultados de alta calidad.
3. Regularización de vectores normales
Debido a la observación de que nuestro modelo de RF produce ocasionalmente superficies ruidosas con bajos niveles de artefactos. Por lo tanto, se introduce un nuevo término de regularización para fomentar que la geometría de nuestra RF tenga normales suaves . Tenga en cuenta que esta regularización se realiza en 2D en lugar de 3D.
En cada iteración, además de calcular los valores RGB y de opacidad, también calculamos la normal en cada punto a lo largo del rayo y la agregamos mediante la ecuación de viaje del rayo para obtener la normal N∈R H×W× 3 .
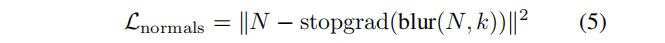
donde stopgrlad es una operación de parada de gradiente y desenfoque(·, k) es un desenfoque gaussiano con tamaño de núcleo k (usamos k = 9). Aunque regularizar normales es más común en tres dimensiones, operar en dos dimensiones reduce la varianza del término de regularización, lo que produce mejores resultados.
4. pérdida de máscara
Además de la imagen de entrada, el modelo también utiliza la máscara del objeto que se desea reconstruir. En la práctica, utilizamos un modelo de matizado de imágenes disponible en el mercado para obtener la máscara de la imagen. La forma de fusionar máscaras es agregar un término de pérdida L2 simple a la diferencia entre puntos de vista de referencia fijos R(σ, π 0 ) ∈R H×W :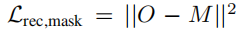
El objetivo de optimización final incluye cuatro ítems , la fila superior corresponde al objetivo a priori y la fila inferior corresponde al objetivo de reconstrucción:
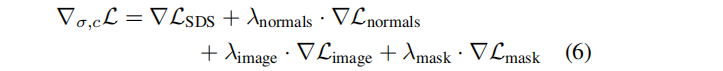
4. Experimentar
1. Configuración
El modelo de difusión se entrena a priori en el conjunto de datos LAION [43] utilizando pares texto-imagen. El modelo Instant NGP se entrena de manera gruesa a fina utilizando un modelo con 16 niveles de resolución, dimensión de característica 2 y resolución máxima 2048.
La cámara utilizada para la reconstrucción se coloca en una esfera de radio 1,8, observando el origen en un ángulo de 15 grados sobre el plano. Cada vez que se optimiza el renderizado, se calculan la pérdida de reconstrucción L rec y L rec , máscara. λ imagen = 5,0, λ máscara = 0,5, λ normal = 0,5 .
2. Resultados cuantitativos
Comparación de métodos: método de reconstrucción de objetos 3D arbitrarios Predicción de malla supervisada por estantería [58] (proporciona 50 modelos previamente entrenados para 50 categorías diferentes en OpenImages [23]). Evaluamos 7 categorías en el conjunto de datos CO3D [39] con las correspondientes categorías de imágenes abiertas. Se seleccionaron aleatoriamente tres imágenes por clase y se ejecutaron RealFusion y Shelf-Supervised simultáneamente para obtener reconstrucciones.
Probamos la calidad 3D reconstruida en la Figura 5. Shelf-Supervised predice la malla directamente. Usamos cubos de marcha para extraer la malla del campo de radiación previsto . CO3D es capaz de reconstruir nubes de puntos dispersas de objetos a partir de geometrías de múltiples vistas. Para la evaluación, tomamos muestras de puntos de la malla reconstruida y los alineamos de manera óptima con la nube de puntos GroundTruth utilizando ICP (Punto más cercano iterativo) mediante la estimación de un factor de escala. Finalmente, se utiliza una puntuación F con un umbral de 0,05 para medir la distancia entre la nube de puntos real predicha y la nube de puntos real del terreno. Las representaciones son visualmente cercanas a las vistas reales, por lo que también evaluamos la similitud de incrustación CLIP . Los resultados se muestran en la Tabla 1:
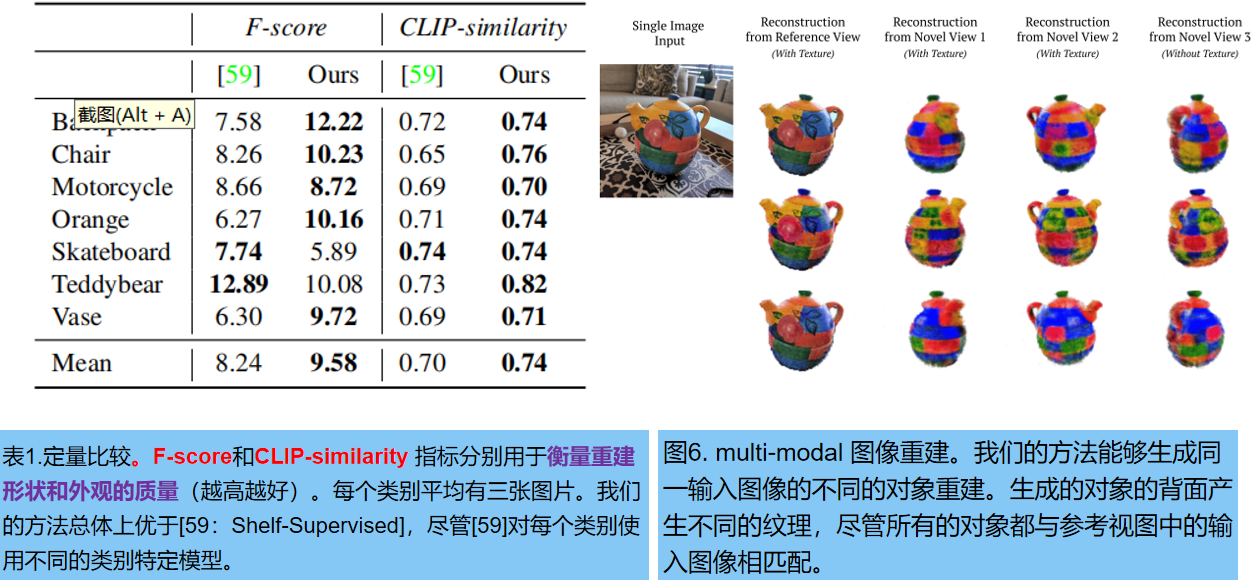
3. Resultados cualitativos
La Figura 4 muestra los resultados cualitativos de múltiples vistas: múltiples reconstrucciones 3D utilizando una sola imagen. La Figura 6 explora la capacidad de muestrear el espacio de posibles soluciones comenzando desde la misma imagen de entrada y repitiendo la reconstrucción varias veces. Casi no hay diferencia en la reconstrucción de la parte frontal del objeto, pero hay una gran diferencia en la parte posterior.
