1. Introducción al algoritmo de detección de objetivos de aprendizaje profundo
En el segundo artículo, presentamos los algoritmos tradicionales y los métodos de detección de objetivos en la detección de objetivos. En el tercer artículo, comparamos brevemente el algoritmo de detección de objetivos tradicional y el algoritmo de detección de objetivos de aprendizaje profundo. Este artículo registra el contenido de la detección de objetivos de aprendizaje profundo. algoritmo Profundicemos en los principios y efectos de los algoritmos de aprendizaje profundo en la detección de objetivos. El algoritmo de aprendizaje profundo se divide en dos etapas de clasificación en la detección de objetivos:
- Una etapa (series YOLO y SSD): regresa directamente a la posición de destino.
- Dos etapas (serie Faster RCNN): utilice la red RPN para recomendar áreas candidatas, es decir, complete el proceso de detección a través de una red neuronal convolucional completa.
Primero presentamos las dos etapas.
2. Algoritmo de detección de objetivos basado en dos etapas
El algoritmo de detección de objetivos de dos etapas completa principalmente el proceso de detección de objetivos a través de una red neuronal convolucional
completa . Las características utilizadas en la detección de objetivos son características CNN , es decir, se utiliza una red neuronal convolucional CNN para extraer pares de candidatos. Descripción de las características del área objetivo.
El representante más típico del algoritmo de detección de objetivos de dos etapas es la serie de algoritmos propuestos en 2014 desde R-CNN hasta RCNN más rápido.
Se requieren dos pasos en el proceso de capacitación: capacitar a la red RPN y capacitar a la red en el área objetivo. En comparación con los algoritmos tradicionales de detección de objetivos, no es necesario entrenar un clasificador ni realizar una representación de características. Todo el proceso se completa mediante una red neuronal convolucional completa de A a B, y al mismo tiempo se mejora la precisión. Sin embargo, es más lento que el de una etapa.
La descripción anterior se puede resumir en los siguientes puntos:
- Funciones de convolución de CNN
- R. Girshick et al., 2014 propusieron R-CNN para acelerar RCNN
- Detección de objetivos de un extremo a otro (red RPN)
- Alta precisión, velocidad relativamente lenta en comparación con una etapa
3. Proceso básico de dos etapas

Imagen de entrada------Extrae características profundas de la imagen (red neuronal troncal)------La red RPN completa la tarea de la ventana deslizante, es decir, genera áreas candidatas y completa la clasificación de áreas candidatas (fondo y objetivo ) Posicionamiento preliminar de la posición objetivo ------- Para calcular las características CNN sin cálculos repetidos, la operación de mateado se completa a través de roi_pooling ------- la capa fc completamente conectada representa el área candidata -- -- clasificación y regresión Determinación de categoría y refinamiento de posición de objetivos candidatos (obteniendo la verdadera categoría del objeto)
Proceso detallado:
Primero, se ingresa una imagen y luego se extrae la imagen para obtener características profundas. Es decir, una imagen se usa como entrada y pasa a través de una red neuronal convolucional . Generalmente se llama red troncal. Las redes troncales típicas incluyen algunas redes neuronales convolucionales clásicas. Redes como VGG y ResNet., y luego use una red RPN para completar la tarea completada por la ventana deslizante en el algoritmo de detección de objetivos tradicional, es decir, generar áreas candidatas. Mientras se extrae el área del marco candidato, el área del marco candidato se clasifica ( durante el proceso de clasificación, el área del marco candidato se clasifica en dos categorías diferentes: fondo y destino ) . Cuando la red RPN genera áreas candidatas, también realizará una predicción preliminar de la ubicación del objetivo , lo que significa que la red RPN completa tanto la clasificación del área como el refinamiento de la ubicación al mismo tiempo. Después de obtener el área candidata, el área candidata se retrocede y corrige con mayor precisión a través de la capa roi_pooling. Roi_pooling puede entenderse como matting. A continuación, después de obtener las características correspondientes al objetivo candidato en el mapa de características, se utilizará una capa fc para Además, represente las características del área candidata y luego complete la determinación de la categoría del objetivo candidato y el refinamiento de la posición del objetivo candidato mediante clasificación y regresión. La categoría aquí es diferente de la categoría de la red RPN. La categoría real del objeto generalmente se obtiene aquí. La regresión obtiene principalmente la posición de coordenadas específica del objetivo actual, que generalmente se representa como un cuadro rectangular, es decir, cuatro valores (x, y, w, h).
4. Algoritmos comunes de dos etapas
- RCNN
- RCNN rápido
- RCNN más rápido
- Variante RCNN más rápida

5. Componentes centrales de dos etapas
1. Dos componentes centrales de dos etapas
Las dos etapas tienen dos componentes centrales importantes:
- Red CNN (red troncal)
- Red RPN
2. Principios de diseño de la red troncal CNN
- De simple a complejo, y luego de red neuronal convolucional compleja a simple
Estructura de red simple: la más clásica es LeNet (que tiene una capa de entrada, dos capas convolucionales, dos capas de agrupación y tres capas completamente conectadas. Sin embargo, LeNet tiene capacidades de abstracción y expresión de red relativamente pobres en tareas a gran escala. más débil)
Estructura de red compleja: después de LeNet, han surgido estructuras de red complejas como LSNet, Resnet y Vgg, que a menudo se utilizan para aumentar la profundidad de la red, porque cuanto más profunda es la red, más fuerte es la capacidad de expresión no lineal y más Los objetos obtenidos son más abstractos, la expresión es menos sensible a los cambios de imagen, cuanto más fuerte es la robustez y mayor es la capacidad para resolver tareas no lineales, también provocará la desaparición o dispersión del gradiente. El más típico es Resnet, que tiene una profundidad de más de 100 capas, y el más clásico es GoogleNet.
- Red de fusión de características de múltiples escalas
- Red CNN más ligera
Al diseñar, tenga en cuenta el rendimiento y el tamaño del modelo. En este momento, es necesario utilizar redes CNN ligeras, como las clásicas ShuffleNet, MobileNet, etc.
3. Red RPN
Antes de comprender la red RPN, primero comprendamos algunos conceptos relacionados con la recomendación de área (mecanismo de anclaje) .
1. Recomendación regional (mecanismo ancla)
1.1 Introducción del problema
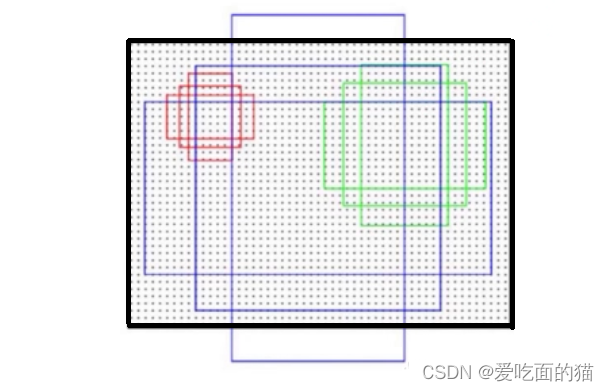
A menudo, el objeto objetivo puede aparecer en cada posición de la imagen y el tamaño del objetivo es incierto. Entonces, ¿hay alguna forma de detectar todos los objetos? La forma más fácil de pensar es interceptar muchos bloques pequeños de diferentes proporciones y tamaños con un píxel como centro . Cada bloque pequeño detecta si el paquete contiene un objeto. Si contiene un objeto, la posición del objeto es la acaba de interceptar La ubicación de la pieza pequeña y al mismo tiempo predecir su categoría. De esta manera, no se perderá ningún objeto con la relación de aspecto y el tamaño del píxel actual; el pequeño bloque recién interceptado es un cuadro de anclaje .
Para detectar objetos en diferentes posiciones en la imagen, utilice el método de ventana deslizante para escanear la imagen de izquierda a derecha y de arriba a abajo, y tome muchos bloques pequeños para la detección en cada punto de píxel, de modo que se puedan garantizar diferentes posiciones. No se pierden objetos de diferentes tamaños. La Fig. 1 es un ejemplo de una verificación de escaneo.

Este método es fácil de entender y realmente efectivo, pero la desventaja también es importante : la cantidad de cálculo es demasiado grande. Si el tamaño del mapa de características de una imagen es 640*640 y se seleccionan 10 fotogramas con diferentes relaciones de aspecto y diferentes tamaños para cada píxel de la imagen para la detección, los fotogramas que deben detectarse serán 640 x 640 x 10 = 4096000 Hay demasiados, como se muestra a continuación. ¿ Cómo mejorarlo ?

De hecho, hay dos puntos obvios que se pueden mejorar en los problemas anteriores:
- En primer lugar, 4.096.000 cuadros de escaneo se superponen demasiado.
- En primer lugar, muchos de estos fotogramas son fondos y no contienen objetos, por lo que no hay necesidad de detección.
Por lo tanto, es particularmente importante intentar garantizar que toda la imagen esté cubierta, omitir los fotogramas que se superpongan demasiado, evitar los fotogramas de fondo y encontrar fotogramas candidatos de alta calidad que puedan contener objetos de destino para la detección . la cantidad de cálculo y mejorar la velocidad de detección .
Los cuadros de anclaje son una serie de cuadros candidatos que determinamos antes de la detección. De forma predeterminada, todos los objetos que aparecen en la imagen estarán cubiertos por los cuadros de anclaje que configuramos. La calidad de la selección de la caja de anclaje está directamente relacionada con dos aspectos:
- Una es si puede cubrir bien el panorama completo.
- Una es si puede enmarcar todos los objetos que puedan aparecer en la imagen.
Por lo tanto, la configuración del cuadro de anclaje es muy importante, no solo en relación con la precisión, sino también con la velocidad (la velocidad es solo para el método de escaneo mencionado anteriormente).
1.2 Solución: establecer cajas de anclaje
Utilice los cuadros de anclaje establecidos para reducir la cantidad de cálculo y mejorar la velocidad de detección. ¿Cómo configurar cajas de anclaje? Esto lo logramos siguiendo estos pasos:
- Determinación de la relación de aspecto.
- Determinación de escala
- Determinación del número de cajas de anclaje.
Por ejemplo: si desea realizar una detección de objetos en un conjunto de datos, la resolución de imagen del conjunto de datos es 256 x 256 y el tamaño de la mayoría de los objetos de destino en el conjunto de datos es 40 x 40 u 80 x 40 .
Determinación de la relación de aspecto.
Debido a que el tamaño de los objetos objetivo en la gran mayoría del conjunto de datos es 40*40 u 80*40, esto significa que la relación alto-ancho del borde verdadero de la mayoría de los objetos en el conjunto de datos es 1:1 y 2:1 . Con base en esta información, se puede determinar la información de relación de aspecto del cuadro de anclaje. Al diseñar cuadros de anclaje para este conjunto de datos , la relación de aspecto debe incluir al menos 1:1 y 2:1 . Por conveniencia, aquí solo tomamos 1:1 y 2:1 como ejemplos.
Determinación de escala
La escala es la relación entre la altura o el ancho de un objeto y la altura o el ancho de la imagen . Por ejemplo, si el ancho de la imagen es 256 px y el ancho del objeto en la imagen es 40 px, entonces la escala del objeto es 40/256 = 0,15625, lo que significa que el objeto ocupa el 15,62% del ancho de la imagen. .
Para seleccionar un conjunto de escalas que representen mejor los objetivos en el conjunto de datos, debemos usar el valor de escala máximo y el valor del objeto objetivo en el conjunto de datos como límites superior e inferior. Por ejemplo, los valores mínimo y máximo de la escala de los objetos en el conjunto de datos son 0,15625 y 0,3125 respectivamente, si planeamos establecer tres escalas dentro de este rango, podemos elegir {0,15625, 0,234375, 0,3125}.
Determinación del número de cajas de anclaje.
Nuestras escalas son {0.15625, 0.234375, 0.3125}, las relaciones de aspecto son {1:1, 2:1}, luego el número de un conjunto de cuadros de anclaje en cada punto de anclaje es 3x2 = 6. Como se muestra en la figura siguiente, hay tres tamaños {0,15625, 0,234375, 0,3125} y cada tamaño tiene dos relaciones de aspecto {1:1, 2:1}.

Según el método anterior, el punto de anclaje se refiere a cada píxel de la imagen de 256 x 256. Según la detección de objetivos de la red neuronal basada en anclaje, el punto de anclaje es cada punto en el mapa de características de salida final de la red.
1.3 ¿Cómo se utiliza Anchor en la detección de objetivos?
En la red, los cuadros de anclaje se utilizan para codificar la posición del objeto de destino . La detección de objetivos generalmente no detecta directamente las coordenadas absolutas del marco del objeto, pero detecta su desplazamiento en relación con un marco de anclaje, como el desplazamiento del marco verde de valor verdadero al marco azul en la figura siguiente. Todos los objetos del conjunto de datos se codificarán como desplazamientos de los cuadros de anclaje. Por ejemplo, en la imagen presentada en la pregunta 1.1, hay muchos cuadros de anclaje. Una imagen puede contener múltiples objetos y muchos cuadros de anclaje. Entonces, ¿cómo usar cuadros de anclaje para codificar el valor verdadero?

Pasos para codificar cuadros delimitadores de valor real con cuadros de anclaje
- a. Para cada cuadro de anclaje, calcule qué cuadro delimitador de valor verdadero tiene la intersección más grande sobre la puntuación de unión.
- B. Si la relación de intersección es> 50%, el cuadro delimitador actual es responsable de detectar el objeto correspondiente al cuadro delimitador de valor verdadero actual y encontrar el desplazamiento del cuadro delimitador de valor verdadero al cuadro de anclaje.
- C. Si la relación de intersección está entre 40% y 50%, no se puede determinar si el ancla contiene el objeto y es un cuadro borroso.
- d. Si la relación de intersección es <40%, se considera que el marco de anclaje es todo fondo y el anclaje se clasifica como clase de fondo.
- Además del cuadro de anclaje del objeto asignado, para el cuadro de anclaje y el cuadro vago que solo contienen el fondo, se asigna 0 al desplazamiento y se asigna el fondo a la clasificación.
Después de la codificación, el objetivo de regresión de la red de detección de objetos se convierte en el desplazamiento codificado de regresión . La entrada de la red es una imagen y la salida es la clasificación y el desplazamiento de cada cuadro de anclaje. Cada píxel en el mapa de características finalmente generado por la red tiene un conjunto de cuadros de anclaje (si el número de un conjunto de cuadros de anclaje es 6, la relación de aspecto es 2: 1 y 1: 1, y la escala es 0.15625, 0.234375, 0,3125, como se muestra en la figura), suponiendo que la resolución del mapa de características de salida final de la red es 7*7, entonces el número total de cuadros de anclaje en la red de regresión es 7x7x6=296. El valor verdadero recibido por la red es la información de clasificación de si los 296 cuadros de anclaje son fondos (si contienen objetos, se separan en categorías de objetos) y el desplazamiento de cada anclaje al cuadro delimitador del objeto de destino (el desplazamiento entre el desenfoque (cuadro y el cuadro de fondo). La cantidad de desplazamiento es 0), y la salida de la red es la información de compensación y clasificación de 296 cuadros.
Para una red entrenada, en su salida, el cuadro de anclaje que solo contiene el fondo se clasifica como fondo y el desplazamiento es 0; el cuadro de anclaje que contiene el objeto se clasifica como categoría de objeto y el desplazamiento es la diferencia entre el cuadro de anclaje y el borde real del objeto.desplazamiento entre
¿Por qué devolver compensaciones en lugar de coordenadas absolutas?
Una de las propiedades de las redes neuronales es la invariancia de desplazamiento. Por ejemplo, para una fotografía que contiene un árbol, independientemente de si el árbol está en la esquina superior izquierda o en la esquina inferior derecha de la imagen, la clasificación generada por la red es un árbol y el resultado de la clasificación no cambiará debido a los cambios. en la posición del árbol en la foto. Por lo tanto, para un árbol, no importa cuál sea su posición en la imagen, la red de regresión tiende a generar las mismas coordenadas de posición para él. Se puede ver que la invariancia de desplazamiento entra en conflicto con los cambios de coordenadas de posición que necesitamos, lo cual obviamente no es aceptable. . Si recurrimos al desplazamiento de regresión , no importa dónde esté el árbol en la imagen, su desplazamiento hasta el cuadro de anclaje donde se encuentra es básicamente el mismo, lo que es más adecuado para la regresión de redes neuronales.
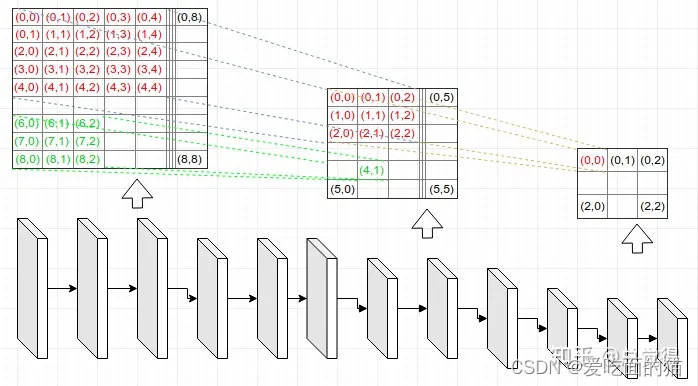
¿Cuál es la relación entre el mapa de características de salida y el cuadro de anclaje?
¿No debería colocarse el cuadro de anclaje en el mapa de entrada? ¿Por qué se dice que cada punto en el mapa de características de salida tiene un conjunto de cuadros de anclaje?
Como se muestra en la figura, cualquier punto en el mapa de características de salida (el pequeño mapa de características de 3 x 3 en el extremo derecho) se puede asignar a la imagen de entrada (el significado del campo receptivo), es decir, de acuerdo con Al reducir la escala y la red, cualquier punto en el mapa de características de salida se puede encontrar proporcionalmente en su posición correspondiente en la imagen de entrada. Por ejemplo, la posición correspondiente del punto (0, 0) en el mapa de características de salida en la imagen de entrada es (2, 2), y la dimensión de la característica de salida de la red es 3 3 84 (= 3 3 6 14), luego el mapa de características de salida Los valores correspondientes a los 84 canales en el punto (0, 0) son los desplazamientos y valores de clasificación de los 6 cuadros de anclaje en la posición (2, 2) de la imagen de entrada. 3 3 84 = 3 3 6 6 en 14 son los 6 cuadros de anclaje, 4 en 14 es el desplazamiento de (x, y, w, h) y 10 en 14 es el número de categorías.
A través de una relación de mapeo tan implícita, todos los cuadros de anclaje se colocan en la imagen de entrada.
1.3 La esencia de Anchor
La esencia de Anchor es lo opuesto a la idea de SPP (agrupación de pirámides espaciales). El propio SPP cambia el tamaño de entradas de diferentes tamaños a salidas del mismo tamaño, por lo que lo contrario de SPP es invertir la salida del mismo tamaño para obtener entradas de diferentes tamaños.
Recomendación de región: llamado mecanismo de anclaje, es decir, n * c * w * h, donde n representa el número de muestras, c representa el número de canales, w y h representan la altura y el ancho de la imagen, y cada punto en w * El área h se utiliza como
candidata. El punto central del área se utiliza para extraer el área candidata, y cada uno de esos puntos se denomina ancla.
Cuando se extrae un área candidata con un determinado punto como punto central del área candidata, generalmente se extrae de acuerdo con una determinada proporción. Por ejemplo, cada punto central en fastRCN extrae 9 regiones candidatas. Por lo tanto, 1 región w*h requiere que se extraigan regiones candidatas w*h*9.
Para estas áreas candidatas y valores verdaderos (GT), utilice los valores verdaderos para examinar estas áreas posteriores y obtener muestras positivas y negativas después de la detección. Las muestras positivas son las áreas que contienen los objetivos candidatos
y si son incluido generalmente se determina a través del juicio IOU, es decir, el juicio del área de cobertura de la superposición entre el valor verdadero y el área candidata.
Si el área de superposición entre el valor verdadero y el área posterior excede el 70%, es una muestra positiva. Si es inferior al 30%, es muestra negativa.
Los 0,7 y 0,3 aquí son súper parámetros y usted mismo puede configurarlos.
La red RPN procesa la salida del mapa de características de la red troncal (una de VGG, ResNet, etc.) y genera múltiples áreas sugeridas que pueden contener objetivos. Consta de dos ramas de convolución: una rama localiza la posición aproximada del objetivo en la imagen mediante regresión de coordenadas y la otra rama encuentra el área de primer plano que contiene el objetivo mediante procesamiento de clasificación binaria. La estructura de red de RPN se muestra en la figura:
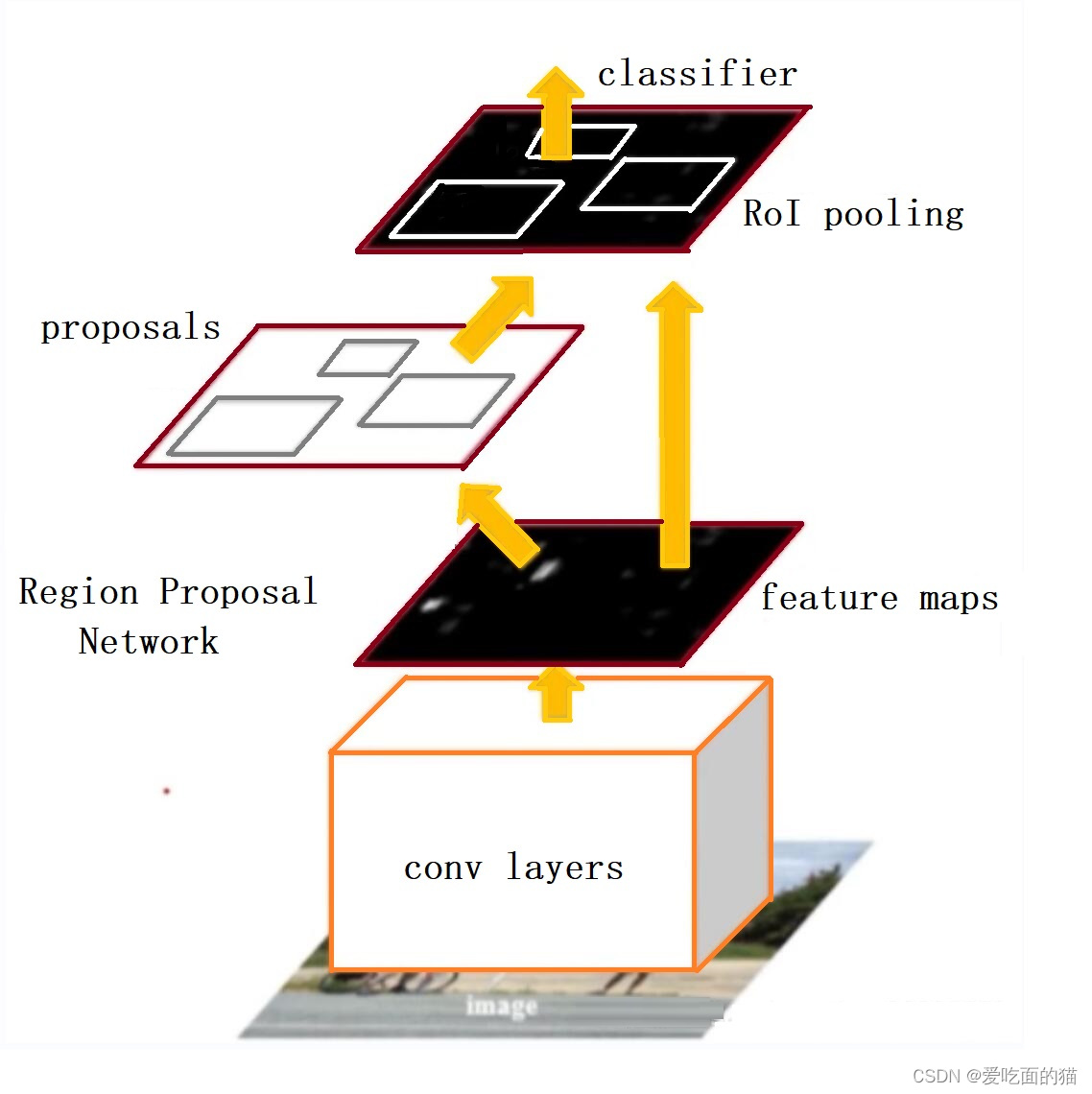
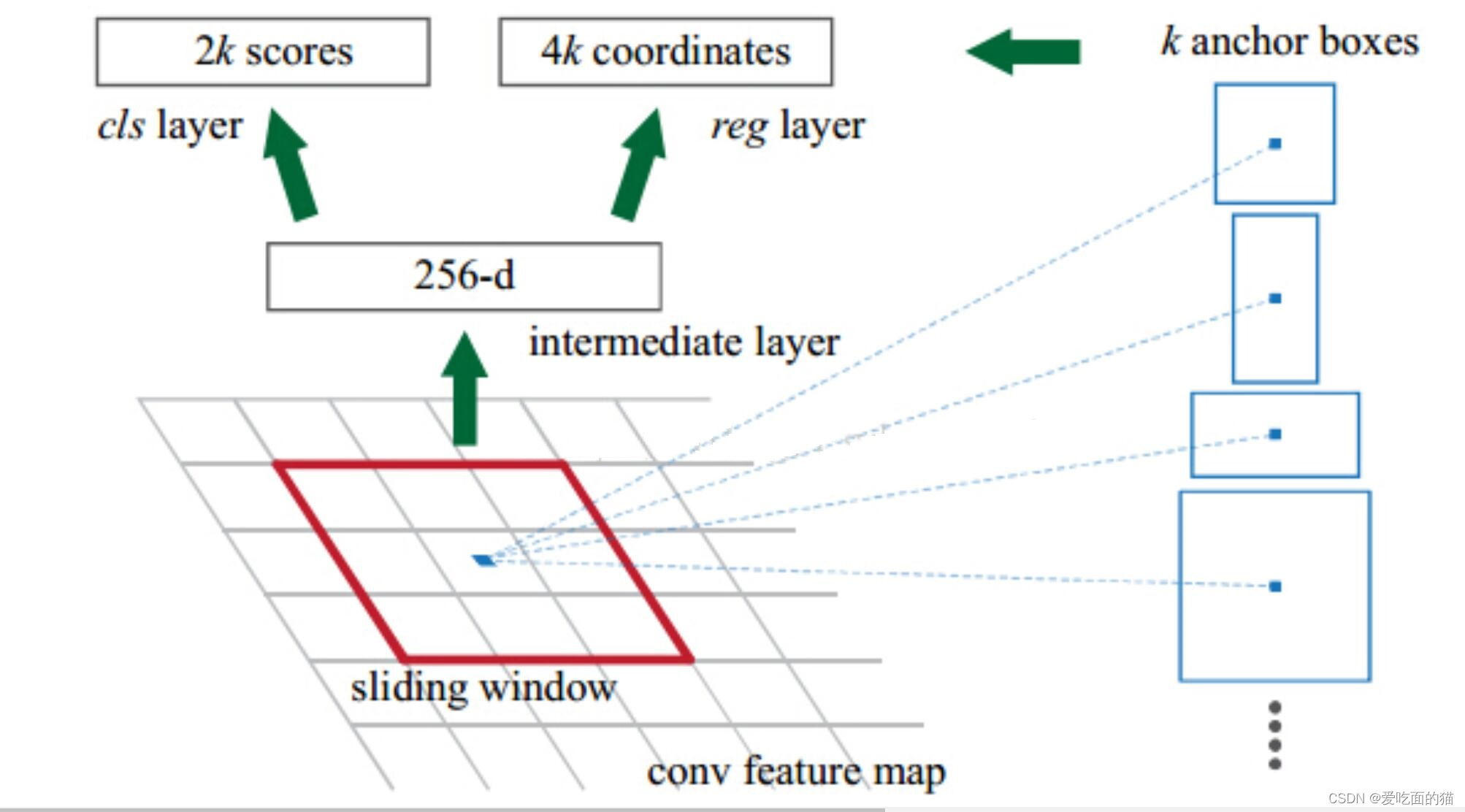
El mapa de características de entrada de RPN son los mapas de características extraídos por la red troncal en la Figura 1, también llamados mapas de características compartidos, cuya escala es H (alto) × W (ancho) × C (número de canales). Con base en este parámetro de característica, a través de una ventana corrediza de 3×3 y deslizándose sobre esta área de H×W, se pueden obtener ventanas de H×W de 3×3. El punto central de cada ventana de 3×3 corresponde al punto central de un área objetivo en la imagen original.
Luego realice dos operaciones de conexión completa en cada vector de características. Una rama obtiene 2 puntuaciones (confianza del primer plano y del fondo) y la otra rama obtiene 4 coordenadas (la información del marco de coordenadas del objetivo). Las 4 coordenadas se refieren al desplazamiento original. de coordenadas del gráfico. Dado que se debe realizar la misma operación completamente conectada en cada vector, equivale a realizar dos convoluciones 1 × 1 en todo el mapa de características, lo que da como resultado un mapa de características de 2 × H × W y un tamaño de 4 × H × W. Finalmente, se combina con los Anchors predefinidos para completar la operación de posprocesamiento y obtener el marco candidato.
En general, los clientes de RPN se pueden resumir en los siguientes puntos:
- Recomendación regional (mecanismo de anclaje)
- Agrupación de retorno de la inversión
- Clasificación y regresión