1. Descripción general de UartAssist
1. Introducción a UartAssist
El software asistente de depuración de puerto serie UartAssist es una herramienta de depuración de comunicación de puerto serie bajo la plataforma Windows. Es ampliamente utilizado en monitoreo de datos, recopilación de datos, análisis de datos y otros trabajos en el campo del control industrial. Es una de las herramientas profesionales necesarias para Trabajo de desarrollo y depuración de aplicaciones de puerto serie. Puede ayudar a los diseñadores, desarrolladores y evaluadores de aplicaciones de proyectos de comunicación en serie a verificar el estado de envío y recepción de datos de los productos de software/hardware de aplicaciones de comunicación en serie desarrollados, mejorar la velocidad de desarrollo y simplificar el desarrollo. complejidad Son un poderoso asistente en el desarrollo y depuración de aplicaciones de comunicación en serie.
El asistente de depuración del puerto serie UartAssist es un software ecológico, no requiere instalación, tiene un solo archivo ejecutable, es adecuado para todas las versiones de los sistemas operativos Windows y no requiere compatibilidad con el marco Microsoft dotNet. Se pueden iniciar múltiples asistentes de depuración de puertos serie simultáneamente en una PC (usando diferentes puertos COM).
Escenarios de aplicación típicos: comunicación y depuración conjunta con programas de puerto serie de desarrollo propio o dispositivos de puerto serie a través del asistente de depuración de puerto serie. Admite múltiples puertos serie, monitorea y enumera automáticamente los puertos serie disponibles localmente; configura libremente el número de puerto serie, velocidad en baudios, bit de verificación, bit de datos, bit de parada, etc. (admite velocidad en baudios personalizada no estándar); admite puerto serie DCD, DTR , DSR, RTS y otros controles de detección de bits de estado de pin.
Admite dos modos ASCII/Hex de envío y recepción de datos. Los datos enviados y recibidos se pueden convertir arbitrariamente entre códigos hexadecimales y AsciI; puede enviar automáticamente dígitos de verificación y admite múltiples formatos de verificación; admite envío a intervalos y envío cíclico. Procesamiento por lotes, los datos de entrada se pueden importar desde archivos externos; las instrucciones/secuencias de datos predefinidas se pueden guardar y las instrucciones o datos predefinidos se pueden enviar a través del panel de herramientas en cualquier momento, o se pueden enviar instrucciones por lotes para facilitar la comunicación y la depuración conjunta.
La interfaz del software admite chino/inglés (cambie a través de las opciones del menú) y se adapta al entorno de idioma del sistema operativo de forma predeterminada.
puntos de función:
- Software ecológico, solo un archivo ejecutable, no requiere instalación;
- Admite idiomas duales chino e inglés y selecciona automáticamente el tipo de idioma del sistema según el entorno del sistema operativo;
- Admite varias velocidades de baudios de uso común y se pueden configurar el número de puerto, el bit de paridad, el bit de datos y el bit de parada;
- Admite múltiples métodos de control de flujo de software/hardware;
- Detecta y enumera automáticamente el número del puerto serie local y admite puertos serie virtuales;
- Admite la configuración de parámetros de subpaquete (longitud máxima del paquete, tiempo del subpaquete) para evitar que los datos se peguen durante la recepción.
- Admite el envío de datos de código ASCII/HEX, los datos enviados y recibidos se pueden convertir arbitrariamente entre código hexadecimal y código ASCII, admite el envío y visualización de caracteres chinos;
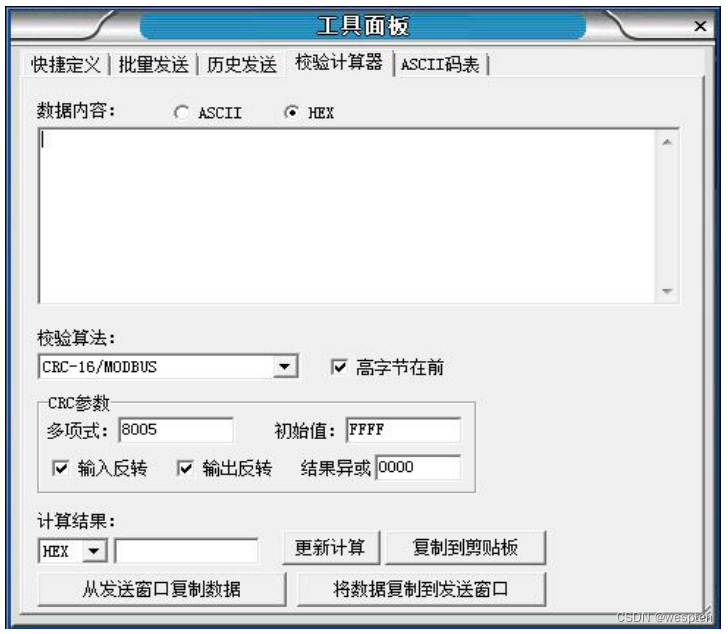
- El dígito de control se puede enviar automáticamente y se admiten varios formatos de verificación, como suma de verificación, LRC, BCC, CRC8, CRC16, CRC32, MD5, etc., entre los cuales el código de verificación CRC se puede personalizar arbitrariamente con parámetros CRC (polinomio CRC, valor inicial, inversión de entrada, inversión de salida, valor XOR de salida);
- El envío de contenido admite caracteres de escape. Por ejemplo, cuando el texto en el cuadro de envío contiene caracteres de escape como \r\n, se analizará automáticamente en el código ASCII correspondiente para el envío.
- Admite el comando AT para agregar automáticamente una opción de retorno de carro y avance de línea. Cuando esta opción está habilitada, el carácter de retorno de carro y avance de línea se completará automáticamente al final de la línea al enviar la especificación AT;
- Los datos se pueden enviar a través del cuadro de entrada o desde una fuente de datos de archivo;
- Admite el guardado automático de los datos recibidos en archivos y el tipo de archivo admite dos formatos: archivo de datos y archivo de registro. El archivo de datos solo guarda el contenido de los datos recibidos, mientras que el archivo de registro guarda la información completa de registro de envío y recepción del asistente de depuración. .
- Modo de recepción de registro de soporte: después de habilitar esta opción, la marca de tiempo y otra información relacionada se mostrarán automáticamente cuando el contenido recibido se muestre en la ventana de recepción.
- Admite envío en cualquier intervalo y de forma cíclica;
- La codificación de texto para recibir y enviar admite ANSI (GBK) y UTF8, y la codificación de recepción y la codificación de envío se pueden configurar de forma independiente sin afectarse entre sí;
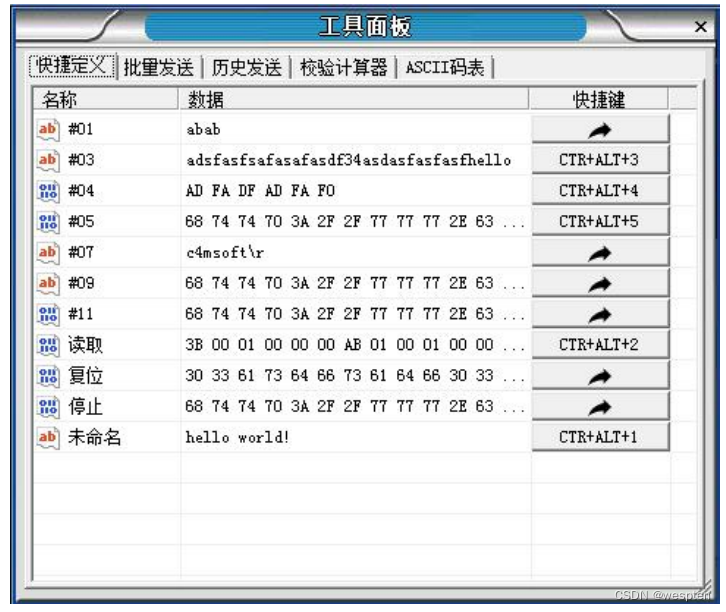
- Admite instrucciones/datos predefinidos, que se pueden enviar presionando teclas o teclas de acceso directo personalizadas. La lista de instrucciones/datos predefinidos se puede guardar, importar y exportar en forma de archivos;
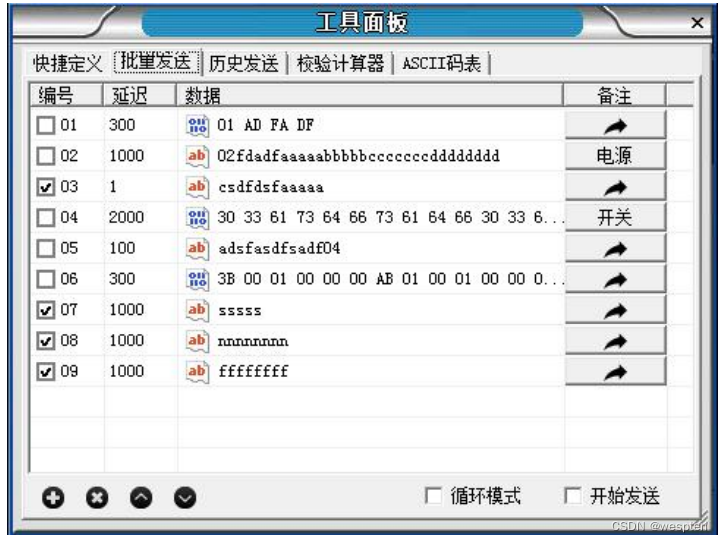
- Admite el envío de instrucciones/secuencias de datos en lotes, se puede configurar el retraso de envío de cada instrucción y las instrucciones se pueden enviar en lotes en secuencia de acuerdo con el orden establecido y el tiempo de retraso. Los datos/instrucciones definidos por lotes se pueden guardar, importar y exportar.
- Guarde automáticamente los registros de envío históricos y los datos históricos se pueden enviar a través de registros históricos;
- Admite la personalización de fuentes y fondos de las ventanas de la interfaz;
- Admite el modo simplificado de la interfaz de trabajo (el panel izquierdo de la interfaz principal se puede plegar);
- El contenido de datos predeterminado del cuadro de envío se puede personalizar;
2. Entorno operativo
El entorno de ejecución del software es la plataforma Windows, que incluye Windows95/WinXP/Vista/Win7/Win8/Win10/WinALL, y es compatible con sistemas operativos de 32/64 bits.
3. Instalación de software
El software verde solo tiene un archivo ejecutable después de la descompresión, que se puede ejecutar directamente. No es necesario instalar (sin depender de) el marco Microsoft .NET Framework.
4. Escenarios de aplicación
El asistente de depuración del puerto serie realiza la depuración conjunta de comunicaciones de dispositivos de puerto serie o aplicaciones de puerto serie mediante operaciones de lectura y escritura en el puerto serie del PC (puerto COM o puerto serie USB). A través de la captura, grabación, análisis de datos del puerto serie y el control de envío de datos/comandos, se puede realizar el análisis y verificación de las capacidades de comunicación y los comportamientos de comunicación de los dispositivos de puerto serie de destino o las aplicaciones de puerto serie. En general, el asistente de depuración del puerto serie tiene principalmente varios escenarios de aplicación.
(1) Configuración de parámetros del terminal del puerto serie (equipo de instrumentos). Para facilitar la configuración de parámetros del dispositivo terminal en la aplicación de ingeniería, la conexión del puerto serie al dispositivo terminal del puerto serie se puede establecer a través del asistente de depuración del puerto serie, y luego la configuración de parámetros del dispositivo serie se puede realizar directamente en el asistente de depuración del puerto serie.
(2) Control de operación de terminales de puerto serie (instrumentos y equipos), captura, registro y análisis de datos de puerto serie. En aplicaciones de ingeniería, en algunos escenarios, es necesario enviar instrucciones al dispositivo en serie para realizar la operación de control del dispositivo, o para capturar y registrar los datos del dispositivo en serie. El asistente de depuración del puerto serie puede enviar periódicamente datos de comando al terminal del puerto serie y guardar automáticamente los datos de los mensajes recibidos y enviados en archivos de disco en forma de registros, para que los usuarios puedan analizar y contar los datos de estado del dispositivo.
(3) Desarrollo y depuración de equipos de control industrial/microcomputadoras de un solo chip. Durante el proceso de desarrollo del puerto serie del sistema integrado/microcomputadora de un solo chip, los datos del puerto serie del dispositivo de microcomputadora de un solo chip se pueden recibir a través del asistente de depuración del puerto serie, o los datos del puerto serie se pueden enviar al dispositivo de microcomputadora de un solo chip Y la capacidad de comunicación del programa de microcomputadora de un solo chip y la precisión de la lógica empresarial se pueden verificar cooperando con el desarrollo del programa de microcomputadora de un solo chip; o utilice el asistente de depuración del puerto serie para realizar una prueba de fatiga de datos en el dispositivo de un solo chip (envío a través de comandos por lotes o cíclicos) y registra el registro de interacción de datos durante el proceso de comunicación, para realizar la verificación de confiabilidad del producto del puerto serie en el proceso de investigación y desarrollo.
5. Interfaz de software
La interfaz funcional principal del asistente de depuración del puerto serie UartAssist se muestra en la siguiente figura, incluida la interfaz principal y varios componentes funcionales de la ventana del panel de herramientas.
Interfaz principal del software:

Composición básica de la interfaz:
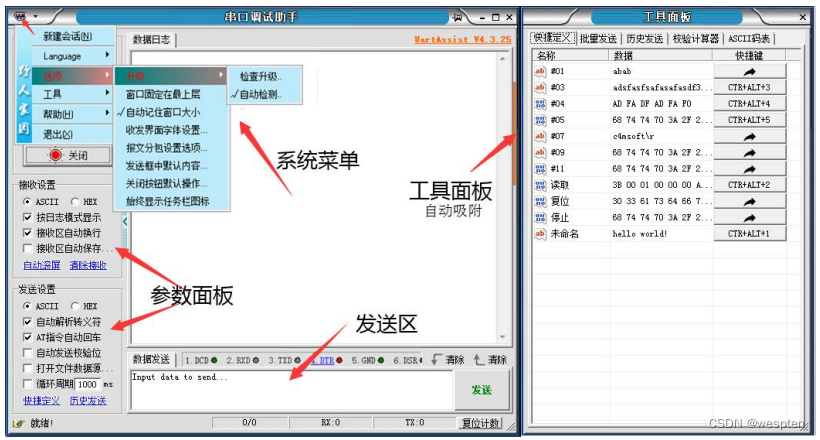
Configuración del tema de la interfaz (fondo/fuente):
Panel de herramientas: definición rápida:
Panel de herramientas/Envío por lotes:
Panel de herramientas/Envío de historial:

Panel de herramientas/Calculadora de inspección:
2. Opciones de configuración de UartAssist
Hay muchos parámetros de configuración y opciones de control del asistente de depuración, incluido el idioma del sistema, codificación de texto, estilo de ventana, formato de datos, verificación de datos, compatibilidad con caracteres de escape, método de control de transmisión de datos, recepción y almacenamiento de datos y grabación de archivos de registro, etc.
Cuando se utiliza el asistente de depuración para la depuración de comunicaciones, combinado con escenarios de aplicaciones reales, el uso de opciones de configuración adecuadas puede mejorar efectivamente la eficiencia de la depuración de comunicaciones e incluso lograr el doble de resultado con la mitad de esfuerzo.
1. Lenguaje y codificación
El software asistente de depuración admite chino e inglés bilingüe y cambia automáticamente según la selección de idioma del sistema de forma predeterminada. El chino se selecciona automáticamente en el entorno chino y el inglés se selecciona automáticamente en otros entornos lingüísticos. También puede especificar directamente el idioma chino/chino a través de la opción de menú [Idioma] del asistente de depuración.

La codificación de datos del asistente de depuración admite dos codificaciones: ANSI (GBK)/UTF-8. El método predeterminado es la codificación ANSI (GBK). Si la ventana de recepción muestra datos confusos, es posible que los datos recibidos sean texto codificado en UTF-8. Si se muestran en el modo ANSI (GBK) predeterminado, serán confusos. La solución es hacer clic derecho en la ventana de recepción. ventana y seleccione, elija cambiar la codificación a UTF-8, como se muestra en la figura anterior.
Tenga en cuenta que después de cambiar la codificación, los datos confusos recibidos no se actualizarán ni mostrarán. Solo los datos recién recibidos se pueden mostrar de acuerdo con la nueva configuración de codificación.
Al enviar datos, también interviene la elección del método de codificación del texto. El método de codificación de la ventana de envío y el método de codificación de la ventana de recepción son independientes entre sí. De la misma manera que la configuración de codificación de la ventana de recepción, haga clic derecho en la ventana de envío y, en el menú emergente contextual, puede seleccionar el método de codificación para enviar datos como ANSI (GBK) o UTF-8. .
Para letras o caracteres en inglés, no es necesario distinguir si se trata de codificación ANSI (GBK) o codificación UTF-8, porque las dos codificaciones son iguales y ambas son códigos ASCII de un byte; pero para caracteres chinos y otros caracteres múltiples. Texto codificado en bytes o Los símbolos son diferentes. Por ejemplo, la codificación ANSI (GBK) de un carácter chino ocupa 2 bytes, mientras que la codificación UTF-8 de un carácter chino ocupa 3 bytes. El asistente de depuración puede codificar y mostrar los datos enviados y recibidos en consecuencia según el método de codificación establecido.
Por ejemplo, al ingresar el carácter chino "Hola" en la ventana de envío y luego hacer clic en el botón [Enviar], si se usa el código ANSI (GBK) para enviar, los datos hexadecimales realmente enviados son "C4 E3 BA C3", mientras que UTF-8 Al codificar y enviar, los datos hexadecimales realmente enviados son "E4 BD A0 E5 A5 BD". El asistente de depuración enviará datos correctos de acuerdo con la codificación actualmente configurada.
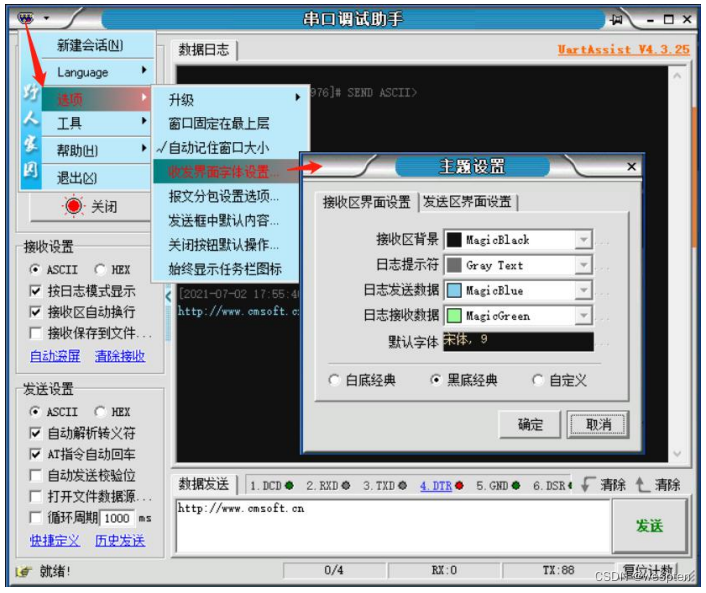
2. Estilo del tema de la ventana
Para garantizar que la interfaz del software esté más en línea con los hábitos visuales personales, el asistente de depuración proporciona una función de personalización del tema de la interfaz. Contenido de personalización del tema de la interfaz, incluido el estilo, tamaño, color y fondo de fuente. Además, los colores de fuente de las indicaciones de registro, los datos recibidos y los datos enviados se pueden configurar de forma independiente.
Como se muestra en la figura siguiente, abra la ventana de configuración del tema de la interfaz de usuario a través de las opciones del menú.
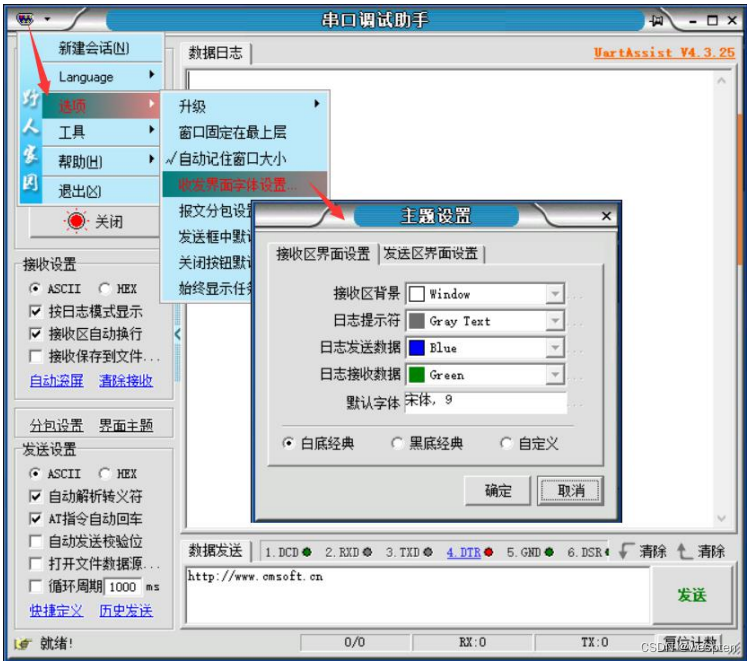
Puede personalizar los temas de la interfaz de la ventana de recepción y de envío respectivamente, o elegir utilizar el estilo de tema preestablecido.
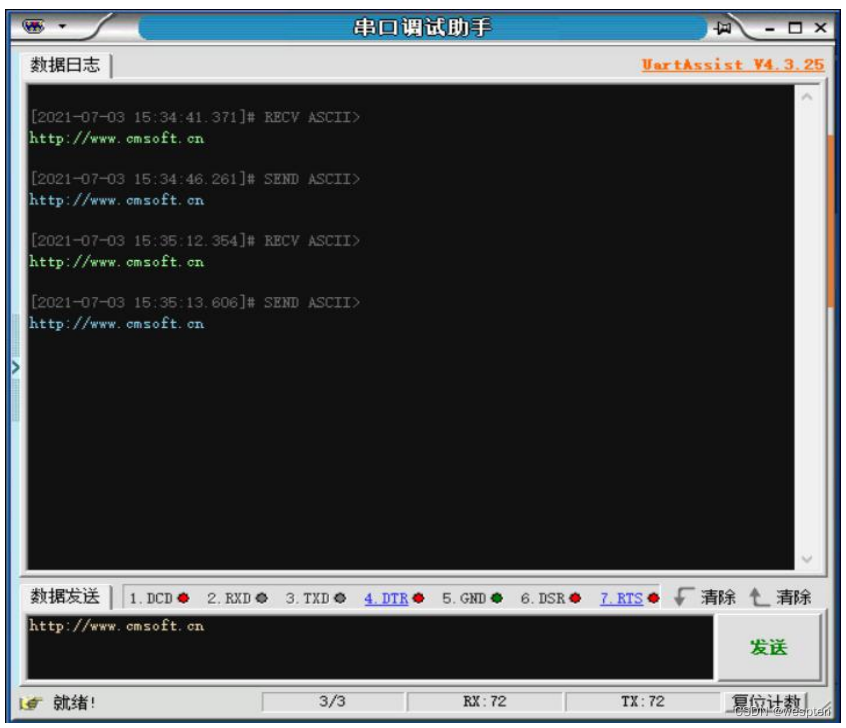
El asistente de depuración proporciona dos estilos de tema preestablecidos: clásico con fondo blanco (tema predeterminado) y clásico con fondo negro. También puedes elegir un método personalizado y configurar el fondo y las fuentes de la interfaz según tus preferencias personales. La siguiente imagen muestra el efecto de seleccionar el tema clásico de fondo negro. El panel de control izquierdo se puede plegar para que la pantalla sea más concisa.
Las ventanas de recepción/recepción son los modos temáticos "Clásico de fondo negro" y "Clásico de fondo blanco" respectivamente:

Las ventanas de recepción/envío son ambas "clásicas con fondo negro":
3. Opciones de configuración de recepción de datos
1. Formato de recepción de datos
En el panel de parámetros de recepción en el lado izquierdo del asistente de depuración, puede configurar el formato de visualización de los datos recibidos en código ASCII o código HEX, lo cual es conveniente para que los usuarios analicen y vean los datos recibidos de diferentes maneras.
Si los datos recibidos son caracteres imprimibles (texto), puede verlos directamente en modo ASCII o ver su codificación hexadecimal en modo HEX; pero si los datos recibidos contienen caracteres no imprimibles, entonces verlos en modo ASCII y los datos recibidos Aparecerá una ventana con datos confusos que no pueden reflejar de manera efectiva el contenido real de los datos recibidos. En este caso, puede seleccionar el modo HEX para imprimir el contenido de los datos recibidos de manera veraz y efectiva.
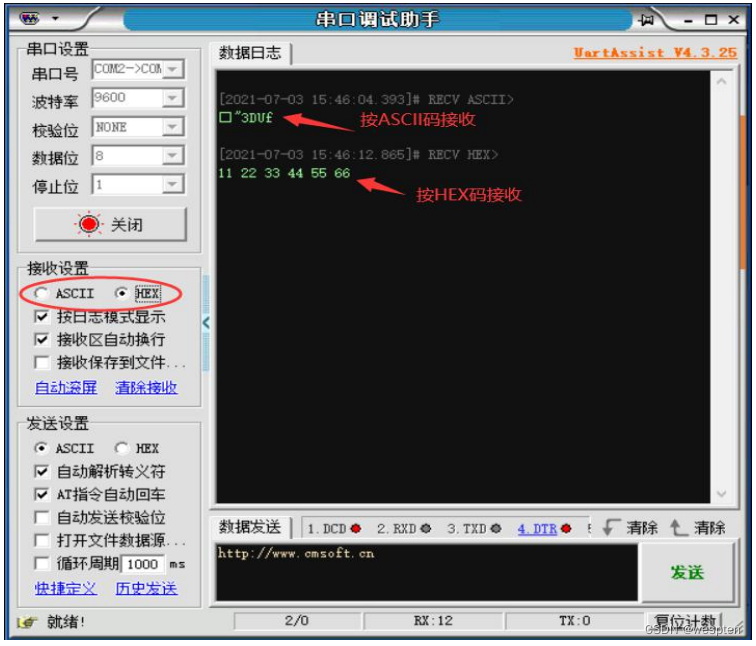
Como se muestra en la figura anterior, un dato que contiene caracteres no imprimibles se recibe según el código ASCII y el código HEX respectivamente. Cuando se recibe según el código ASCII, contiene caracteres confusos, pero cuando se recibe según el código HEX, es muy fácil distinguir el contenido recibido real.
Cuando utilice el asistente de depuración, debe cambiar el formato de visualización de datos de acuerdo con los requisitos reales de la escena.
2. Formato de visualización del registro
La ventana de recepción de datos se muestra en modo de registro de forma predeterminada. Además de mostrar el contenido de los datos recibidos, también muestra la marca de tiempo de los datos recibidos, el formato de los datos (código ASCII/código HEX), la dirección IP de la fuente de datos y el número de puerto. Además, la ventana de recepción también muestra la información del registro de datos enviado. Como se muestra abajo:
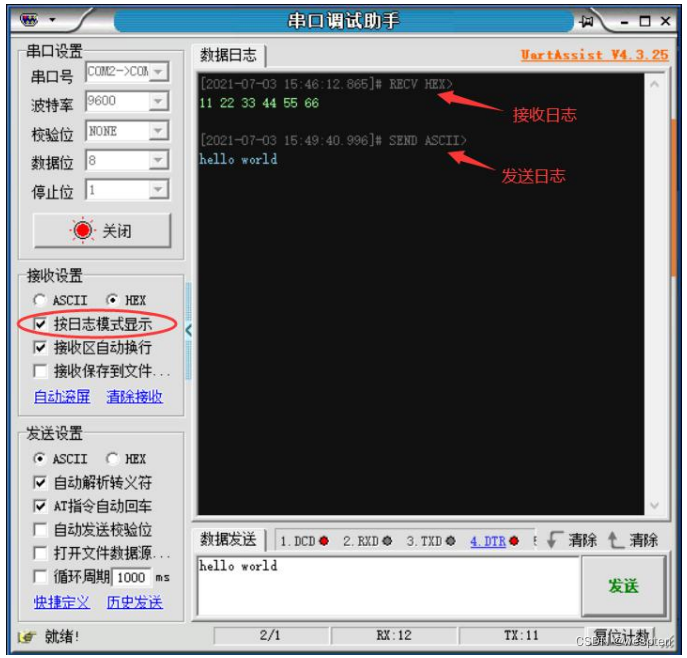
Si está en las opciones de configuración de recepción, cancele la opción [Mostrar en modo de registro]. Luego, la ventana de recepción solo mostrará el contenido de los datos recibidos y no mostrará información adicional, como la marca de tiempo del registro de recepción, y no se mostrará el registro de datos de envío.
3. Reciba ajuste de línea automático
La opción [Ajuste de línea automático del área de recepción] determina si cada nuevo registro de datos se ajustará automáticamente o se agregará al final de los datos recibidos anteriormente. Esta opción no tiene ningún efecto obvio en el modo de registro, porque cada registro recibido en el modo de registro se verá obligado a ajustarse.
El ajuste automático de líneas implica una cuestión conceptual: cómo distinguir el comienzo de un registro de datos. En otras palabras, cuando se recibe un flujo de datos continuo, cómo cortar varios paquetes conectados de extremo a extremo y transmitidos en secuencia, es decir, para solucionar el problema de la adherencia. Dado que la transmisión de datos por puerto serie es similar a la transmisión de datos en tiempo real, solo puede garantizar que los datos salientes o los paquetes de instrucciones se transmitan de manera ordenada y no proporciona a la capa de aplicación un identificador inicial para la segmentación de paquetes.
Incluso si el transmisor del puerto serie empaqueta y envía los datos a la vez, los datos que llegan al extremo receptor llegarán uno tras otro como agua corriente, especialmente cuando el intervalo de envío de múltiples mensajes es muy pequeño y la aplicación del puerto serie se debe a la potencia de cálculo. O cuando el problema de eficiencia del algoritmo no puede recuperar datos de la cola de recepción del hardware del puerto serie a tiempo, la aplicación no puede juzgar correctamente el intervalo de tiempo entre los paquetes de datos originales y, por lo tanto, no puede separar eficazmente múltiples mensajes que se transmiten densamente. Para el asistente de depuración del puerto serie, es relativamente simple y tosco lidiar con el problema del bloqueo de los paquetes de datos: si la brecha excede los 50 ms, se cortará automáticamente y se tratará como un registro de datos.
4. Recibir y guardar en el archivo.
Los datos recibidos por el asistente de depuración se pueden guardar automáticamente en un archivo. En la configuración de recepción, haga clic en la opción [Recibir y guardar en archivo] y aparecerá el cuadro de diálogo que se muestra a continuación. Seleccione la ruta del archivo para recibir y guardar.

Como se muestra en la figura, al seleccionar la ruta de almacenamiento del archivo de destino, preste atención a configurar el tipo de almacenamiento del archivo. Las opciones disponibles son [Archivo de registro] (tipo predeterminado) y [Archivo de datos].
El llamado archivo de registro significa que el archivo de destino no solo almacena el contenido de los datos recibidos, sino que también almacena la marca de tiempo de los datos recibidos y la IP de la fuente de datos y otra información relacionada, y también contiene la información de registro de envío del asistente de depuración. ; mientras que el archivo de datos significa que el archivo de destino solo almacena los datos recibidos. El contenido de los datos no contiene otra información adicional ni contiene información de registro de datos de envío. En aplicaciones reales, si se utiliza para fines de registro, elija el tipo de archivo de registro. Si es únicamente para guardar los datos originales recibidos, elija el tipo de archivo de datos.
5. Recibir desplazamiento automático
Los datos recibidos por el asistente de depuración del puerto serie se mostrarán en la ventana de recepción. Los datos recién recibidos se agregarán automáticamente al final de los datos recibidos anteriormente y la ventana de recepción se actualizará en tiempo real. Si el contenido de los datos recibidos excede la altura de la ventana, automáticamente El desplazamiento de línea garantiza que los últimos datos recibidos estén siempre visibles en la ventana de recepción. Esto causará un problema. Si se muestra un flujo de datos continuo durante la recepción de alta velocidad, la ventana de recepción continuará desplazándose y pasando páginas, lo que provocará que el usuario no pueda ver los datos de manera efectiva porque la página pasará automáticamente antes de que puede verlo claramente.
Reciba la opción [Desplazamiento automático] en la configuración para cambiar la función de desplazamiento automático. La configuración predeterminada después de iniciar el software es habilitar el desplazamiento automático. Haga clic en esta opción para activar o desactivar el desplazamiento automático. Una vez que se desactiva el desplazamiento automático, aunque los datos recién recibidos aún se agregarán automáticamente al final de los datos en la ventana de recepción, la ventana de recepción no se desplazará automáticamente. Al controlar la barra de desplazamiento de la ventana de recepción con el mouse, el El usuario puede ver libremente los datos en la ventana de recepción y nunca más será interrumpido por la función de desplazamiento automático.
4. Opciones de configuración de envío de datos
Las opciones de configuración de envío de datos incluyen modo de envío de datos (ASCII/HEX), compatibilidad con caracteres de escape, retorno de carro automático para comandos AT, envío automático de dígitos de control, configuración de fuente de datos de archivos, configuración de envío de bucle, etc.
1. Tipo de envío de datos
El asistente de depuración puede enviar dos tipos de datos: cadenas de texto ASCII y datos codificados en hexadecimal HEX. En correspondencia con el panel de parámetros de envío en el lado izquierdo de la interfaz del software, puede seleccionar el tipo de codificación de envío de datos: código ASCII o código HEX. Cualquier dato se puede enviar como texto codificado en formato hexadecimal, pero no se puede enviar ningún dato como una cadena de código ASCII. Si los datos enviados contienen caracteres no imprimibles, se distorsionarán cuando se conviertan a código ASCII y los datos se perderán al enviarlos.
Por lo tanto, los datos que contienen caracteres no imprimibles solo se pueden enviar en codificación hexadecimal; cómo elegir el tipo de envío de datos para datos que no contienen caracteres no imprimibles depende de la conveniencia del escenario de aplicación específico.
2. Soporte de personajes de escape
El asistente de depuración del puerto serie admite la inserción de caracteres de escape en el texto ASCII enviado. Siempre que la opción [Analizar caracteres de escape automáticamente] en la configuración de envío esté marcada, al enviar texto ASCII que contenga caracteres de escape, los caracteres de escape se analizarán automáticamente en los datos de código ASCII correspondientes para su envío, lo que hace que sea conveniente para los usuarios enviar mensajes no escritos. caracteres imprimibles en forma de texto. . Los caracteres de escape comienzan con una barra invertida.
Por ejemplo, el carácter de escape para el retorno de carro es \r o \x0d, el carácter de escape para el avance de línea es \n o \x0a, y así sucesivamente. Cualquier carácter de código ASCII (incluidos los caracteres imprimibles y no imprimibles) se puede representar con \x seguido de dos dígitos de datos codificados en hexadecimal.

La imagen de arriba es un ejemplo de envío de texto que contiene caracteres de escape: ingrese hola\r\n en el cuadro de envío y luego haga clic en el botón enviar para enviar la cadena hola, retorno de carro y avance de línea. Tenga en cuenta que los caracteres de escape solo se admiten en el modo de envío de código ASCII y que la opción [Analizar caracteres de escape automáticamente] está marcada.
3. Los comandos AT ingresan automáticamente
Para facilitar el envío de comandos AT, siempre que la opción [retorno de carro automático del comando AT] esté marcada, al enviar un comando de texto que comience con AT, el software asistente de depuración verificará automáticamente si termina con un retorno de carro y carácter de avance de línea. Si no hay un retorno de carro explícito y un carácter de fin de nueva línea, entonces el comando AT enviado completará automáticamente el final con un carácter de retorno de carro y avance de línea. De esta manera, cuando los usuarios envían comandos AT, no tienen que agregar retornos de carro y avances de línea cada vez, lo que puede mejorar efectivamente la eficiencia de la depuración de la comunicación.
4. Enviar automáticamente el dígito de control
Cuando se utiliza el asistente de depuración para la depuración de comunicaciones, en algunos escenarios es necesario enviar datos de comando con dígitos de control. Por ejemplo, al depurar el protocolo de comunicación Modbus, se debe agregar un dígito de verificación CRC16 al final del comando. Esto requiere calcular el código de verificación por adelantado antes de preparar las instrucciones de depuración. Si hay muchas instrucciones y es necesario modificarlas en cualquier momento, será más problemático.
Para solucionar este problema, el asistente de depuración ofrece la opción de enviar automáticamente dígitos de control. Siempre que marque esta opción y seleccione el algoritmo de verificación correspondiente, los datos del dígito de control seleccionado se enviarán automáticamente al final de los datos al enviar datos.
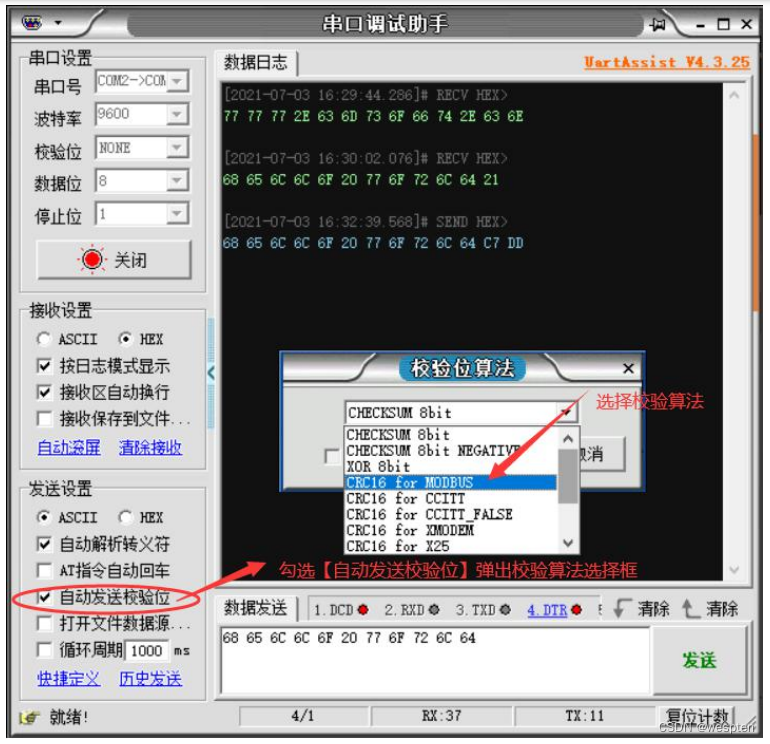
Ejemplo como se muestra. Seleccione CRC-16/MODBUS como dígito de control y luego envíe el comando de datos hexadecimales: 011000000002040000. Al final del comando real, se agregarán automáticamente 2 bytes de datos del dígito de control CRC16, lo que elimina la necesidad de que el usuario calcule y agreguen el dígito de control por sí solos. Problemas al verificar.
5. Enviar datos de archivos
Cuando el asistente de depuración envía datos, existen dos métodos de entrada de datos: el método convencional es introducir datos a través del cuadro de entrada de envío; cuando la cantidad de datos es relativamente grande, los datos que se enviarán se pueden guardar como un archivo y luego los datos se envían a través de la fuente de datos del archivo.
Método de operación específico: en la configuración de envío del panel de control en el lado izquierdo del asistente de depuración, haga clic en [Abrir fuente de datos de archivo]; luego seleccione el archivo de destino que se enviará en el cuadro de diálogo emergente de selección de archivos, es decir, cargue la fuente de datos del archivo; finalmente, haga clic en Haga clic en el botón [Enviar] para comenzar a enviar datos desde la fuente de datos del archivo.
6. Configuración de envío cíclico
En el panel de configuración de envío, establezca el período de tiempo para el envío cíclico en milisegundos y marque la opción [Envío cíclico], luego haga clic en el botón [Enviar] El asistente de depuración enviará cíclicamente la fuente de datos de entrada de acuerdo con el período de tiempo establecido. . Una vez que se inicia el proceso de envío del bucle, el botón [Enviar] cambiará automáticamente al botón [Detener]. Para finalizar la operación de envío del bucle, simplemente haga clic en el botón [Detener].
7. Ingrese la clave para enviar la configuración.
El envío de datos del asistente de depuración se activa haciendo clic en el botón [Enviar] con el mouse, o también se puede enviar presionando las teclas del teclado. De forma predeterminada, el envío de datos se puede realizar presionando solo la tecla Enter o la combinación de teclas CTRL+Enter. Si desea ingresar un retorno de carro y un avance de línea en el cuadro de entrada de envío, presionar la tecla Enter directamente solo puede activar el envío de datos, pero no puede ingresar un retorno de carro y un avance de línea. , debe usar la combinación de teclas Shift+Enter para insertar un retorno de carro y un carácter de avance de línea.
Enviar configuración de teclas de método abreviado:
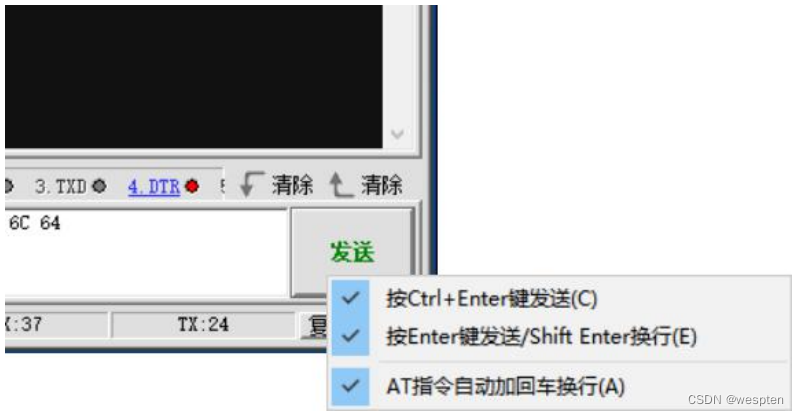
Si desea cambiar la configuración predeterminada de la tecla Intro, puede hacer clic derecho en el botón [Enviar] y verificar la configuración en el menú emergente contextual, como se muestra en la figura anterior, y las opciones específicas son descrito abajo.
- [Presione Ctrl+Enter para enviar]: Después de marcar esta opción, la combinación de teclas Ctrl+Enter realiza la operación de envío; de lo contrario, la combinación de teclas no realiza ninguna operación;
- [Presione la tecla Enter para enviar/Shift Enter salto de línea]: Después de marcar esta opción, presione la tecla Enter sola (no combine Shift o Ctrl) para ejecutar la operación de envío, y la combinación de teclas Shift+Enter se usa para ingresar un retorno de carro y avance de línea en el cuadro de entrada de envío; si esta opción no está marcada, cuando se presiona la tecla Enter sola, el retorno de carro y el avance de línea se ingresarán sin activar la operación de envío, y la combinación de teclas Shift+Enter no es válida;
5. Configuración del contenido predeterminado del cuadro de envío
Configuración de contenido predeterminada del cuadro de envío:
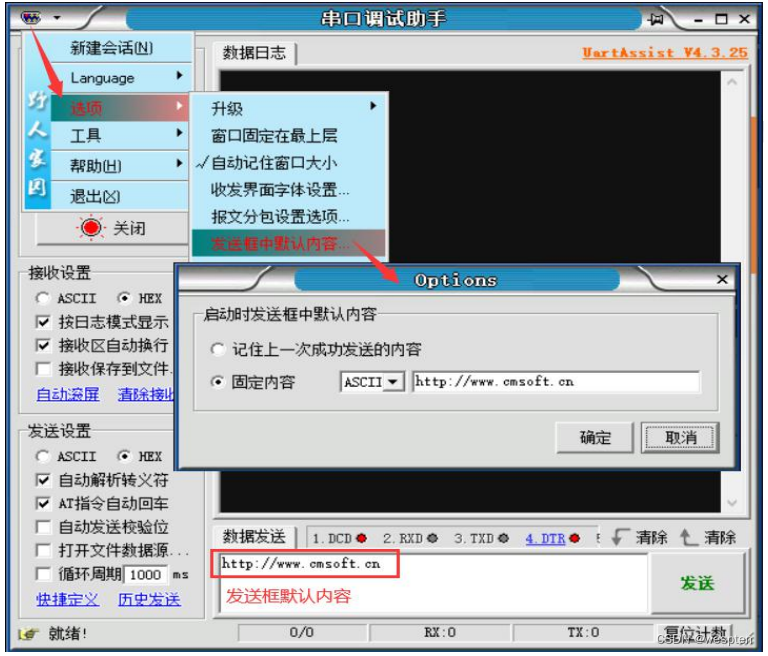
Una vez iniciado el software del asistente de depuración, el contenido de visualización predeterminado en el cuadro de entrada de envío se puede personalizar, puede ser contenido de datos fijos (o vacíos) o puede recordar el último dato enviado cuando se cerró la última vez. Método de configuración específico: busque la opción [Contenido predeterminado en el cuadro de envío] en el menú del asistente de depuración y haga clic para que aparezca la ventana de configuración, como se muestra en la figura anterior.
Puede elegir [Recordar el último contenido enviado correctamente] o [Reparar contenido]. Para contenido fijo, puede elegir texto ASCII o datos hexadecimales HEX. Después de modificar la configuración, haga clic en el botón Aceptar y entrará en vigor la próxima vez que inicie el software asistente de depuración.
6. Otros parámetros y opciones de control.
1. Crea una nueva sesión
Durante el proceso de depuración de comunicaciones, según el escenario de la aplicación real, es posible que sea necesario ejecutar varios programas asistentes de depuración en cualquier momento. Para evitar problemas de que los usuarios encuentren/ejecuten software en la computadora, el software asistente de depuración proporciona la función [Nueva sesión]. Esta opción de control se encuentra en el primer elemento del menú del sistema y se utiliza para iniciar otra instancia de software. del asistente de depuración, es decir, ejecute otro software asistente de depuración.
Cada vez que haga clic en la opción [Nueva sesión], se iniciará un proceso de ventana del asistente de depuración. Siempre que la memoria de la PC sea lo suficientemente grande, se puede iniciar cualquier número de ventanas del asistente de depuración al mismo tiempo.
2. Recuerda automáticamente el tamaño de la ventana
Después de habilitar la opción de menú [Recordar automáticamente el tamaño de la ventana], el software asistente de depuración guardará y recordará automáticamente el tamaño de la ventana actual cada vez que se cierre. Cuando el software se inicie nuevamente, restaurará automáticamente el tamaño de la ventana del software cuando estuvo cerrado por última vez.
3. La ventana se fija en la parte superior.
La opción de menú [Ventana fija en la parte superior] es en realidad la función de la parte superior de la ventana, que puede evitar que otras ventanas de software bloqueen el asistente de depuración del puerto serie. También hay una entrada de acceso directo para esta opción de menú. Es un botón con un icono estilo chincheta en el lado derecho de la columna de título de la ventana principal del asistente de depuración. Haga clic en él para cambiar directamente la ventana al modo superior.
4. Mostrar siempre los iconos de la barra de tareas
Una vez iniciado el software del asistente de depuración, el icono del software se mostrará en la barra de tareas del sistema operativo y en el área de la bandeja de la barra de tareas. Cuando se minimiza el Asistente de depuración, el ícono en la barra de tareas se ocultará automáticamente de manera predeterminada y solo se mostrará el ícono en el área de la bandeja de la barra de tareas. Si el área de la bandeja del sistema operativo del usuario está configurada en modo plegado, es posible que el icono del asistente de depuración esté oculto y no se pueda encontrar de forma intuitiva.
En este caso, desea que el ícono del software en la barra de tareas no esté oculto cuando el asistente de depuración esté minimizado. El elemento de menú [Mostrar siempre el icono de la barra de tareas] se utiliza para implementar esta función. Después de marcar esta opción, el icono del software del asistente de depuración siempre se mostrará en la barra de la barra de tareas del sistema operativo para facilitar a los usuarios localizar la ventana de trabajo.
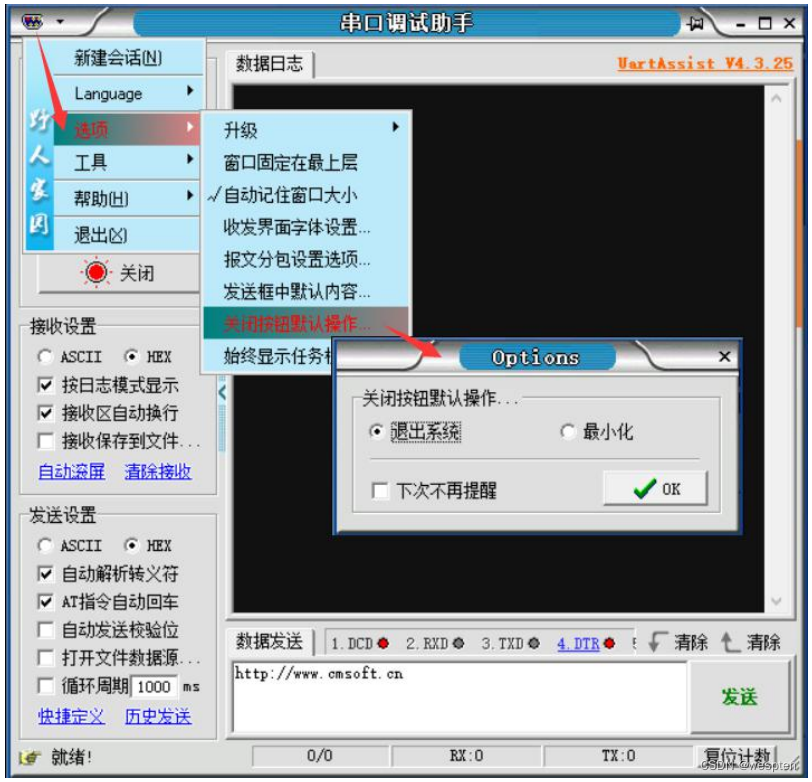
5. Acción predeterminada del botón Cerrar
Haga clic en el botón Cerrar en la interfaz principal del asistente de depuración. A través de esta opción se puede configurar si cerrar el software o minimizar la ventana, como se muestra en la siguiente figura.
3. Operaciones básicas de UartAssist
Métodos de operación básicos, incluida la configuración del puerto serie, conexiones, recepción y envío de datos del puerto serie, etc.
1. Configuración de parámetros del puerto serie
Los parámetros de comunicación en serie se refieren a parámetros como velocidad en baudios, bits de datos, bits de paridad y bits de parada. Al conectarse y comunicarse entre dispositivos de puerto serie, ambas partes comunicantes deben aceptar utilizar exactamente los mismos parámetros de comunicación para establecer una comunicación efectiva. En otras palabras, para que dos puertos serie se comuniquen, estos parámetros deben coincidir. Solo cuando ambas partes en comunicación están en el mismo canal se puede garantizar una comunicación de datos efectiva.
Interfaz de configuración de parámetros del puerto serie:

(1) Velocidad en baudios. Este es un parámetro que mide la velocidad a la que se transmiten los símbolos. Representa el número de símbolos transmitidos por segundo. Por ejemplo, 300 baudios significa enviar 300 símbolos por segundo. Cuando nos referimos al período del reloj, nos referimos a la velocidad en baudios; por ejemplo, si el protocolo requiere una velocidad de 4800 baudios, entonces el reloj es de 4800 Hz. Esto significa que la frecuencia de muestreo de la comunicación serie en la línea de datos es de 4800 Hz. Las velocidades de baudios comunes para las líneas telefónicas son 14400, 28800 y 36600. Las velocidades en baudios pueden ser mucho mayores que estos valores, pero la velocidad en baudios es inversamente proporcional a la distancia. A menudo se utilizan velocidades de transmisión altas para la comunicación entre instrumentos que están colocados muy cerca unos de otros, un ejemplo típico es la comunicación de dispositivos GPIB.
(2) Bits de datos. Esta es una medida de los bits de datos reales en la comunicación. Cuando una computadora envía un paquete, los datos reales no son de 8 bits; los valores estándar son de 5, 7 y 8 bits. La forma de configurar esto depende de la información que desee enviar. Por ejemplo, el código ASCII estándar es 0~127 (7 bits). El código ASCII extendido es 0~255 (8 bits). Si los datos están en texto simple (ASCII estándar), se utilizan 7 bits de datos por paquete. Cada paquete hace referencia a un byte, incluidos bits de inicio/parada, bits de datos y bits de paridad. Dado que los bits de datos reales dependen del protocolo de comunicación elegido, el término "paquete" se refiere a cualquier situación de comunicación.
(3) Bit de parada. Se utiliza para representar el último bit de un solo paquete. Los valores típicos son 1, 1,5 y 2 bits. Dado que los datos se cronometran en la línea de transmisión y cada dispositivo tiene su propio reloj, es posible que se produzca una pequeña desincronización entre los dos dispositivos durante la comunicación. Por lo tanto, el bit de parada no sólo indica el final de la transferencia, sino que también brinda al ordenador la oportunidad de corregir la sincronización del reloj. Cuantos más bits haya disponibles para los bits de parada, mayor será la tolerancia para diferentes sincronizaciones de reloj, pero al mismo tiempo más lenta será la velocidad de transferencia de datos.
(4) Bit de paridad. Un método sencillo de detección de errores en la comunicación serie. Hay cuatro modos de detección de errores: par, impar, alto y bajo. Por supuesto, también es posible no tener dígito de control. Para paridad par e impar, el puerto serie establecerá el bit de paridad (un bit después del bit de datos), utilizando un valor para garantizar que los datos transmitidos tengan bits lógicos altos pares o impares. Por ejemplo, si los datos son 011, entonces para paridad par, el bit de paridad es 0, lo que garantiza que el número de bits lógicamente altos sea par. Si es una paridad impar, el bit de paridad es 1, por lo que hay 3 bits lógicos altos. Los bits alto y bajo no son realmente datos de verificación, simplemente están configurados en lógica alta o lógica baja para verificación.
Esto permite que el dispositivo receptor conozca el estado de un bit, dándole la oportunidad de determinar si el ruido está interfiriendo con la comunicación o si los datos transmitidos y recibidos no están sincronizados.
2. Abra la conexión del puerto serie.
Antes de establecer la comunicación en serie, primero debe confirmar si el dispositivo de comunicación en serie de destino se ha conectado eléctricamente al puerto serie de la computadora local (puerto COM o puerto serie USB) y necesita saber el número de puerto serie de la computadora al que está conectado el dispositivo. . Si la conexión es un puerto COM, dado que los puertos COM de la computadora tienen números fijos, el número de serie será el número del puerto COM al que está conectado el dispositivo; si el dispositivo de comunicación de destino está conectado a un adaptador de puerto USB a serie (Dongle), entonces el número de serie será No es fijo, pero podemos confirmar el número de serie conectado al dispositivo de destino conectando y desconectando el adaptador del puerto serie USB y luego observando el aumento o disminución en los números de serie disponibles enumerados. en la lista desplegable de números de serie del asistente de depuración.
Después de conocer el número de puerto serie del dispositivo de comunicación de destino conectado a la computadora local, puede utilizar el asistente de depuración del puerto serie para establecer una conexión de comunicación con el dispositivo de comunicación de destino. El método de operación es muy simple: en los parámetros de configuración del puerto serie del asistente de depuración del puerto serie, seleccione el número de puerto serie consistente con el dispositivo de destino y configure otros parámetros de comunicación (velocidad en baudios, bits de datos, bits de paridad y bits de parada) para el dispositivo El final es consistente y finalmente haga clic en el botón [Abrir]. Si la operación es exitosa, la luz indicadora del botón cambia de negro a rojo, lo que indica que el puerto serie se abrió exitosamente y se estableció la comunicación con el puerto serie.
3. Recepción de datos del puerto serie
Después de que el asistente de depuración del puerto serie abre el puerto serie, puede recibir datos enviados desde el puerto serie sin ninguna operación adicional (de acuerdo con la configuración predeterminada). Los datos recibidos se mostrarán en la ventana de recepción de acuerdo con el modo establecido en la ventana de recepción. ajustes. Como se muestra abajo:

Para facilitar la observación y el análisis de los datos recibidos, puede realizar algunas modificaciones y ajustes al modo de recepción en la configuración de recepción. El más utilizado es establecer el tipo de datos (ASCII/HEX), es decir, si los datos recibidos se muestran como una cadena de código ASCII o una cadena hexadecimal. Si los datos recibidos son contenido de texto, seleccione el modo ASCII; si los datos recibidos son datos binarios o contienen caracteres que no se pueden imprimir, seleccione el modo HEX, es decir, convierta los datos recibidos en una cadena hexadecimal que se mostrará más adelante.
Además, existe una opción común en la configuración de recepción llamada "Mostrar en modo de registro". Si esta opción no está marcada, la ventana de recepción solo mostrará los datos recibidos, no los datos enviados, y los datos recibidos no se mostrarán sin una marca de tiempo; si esta opción está marcada, entonces, independientemente de si se reciben o envían Los datos se muestran en la ventana y cada registro de datos tiene una marca de tiempo.
4. Envío de datos por puerto serie
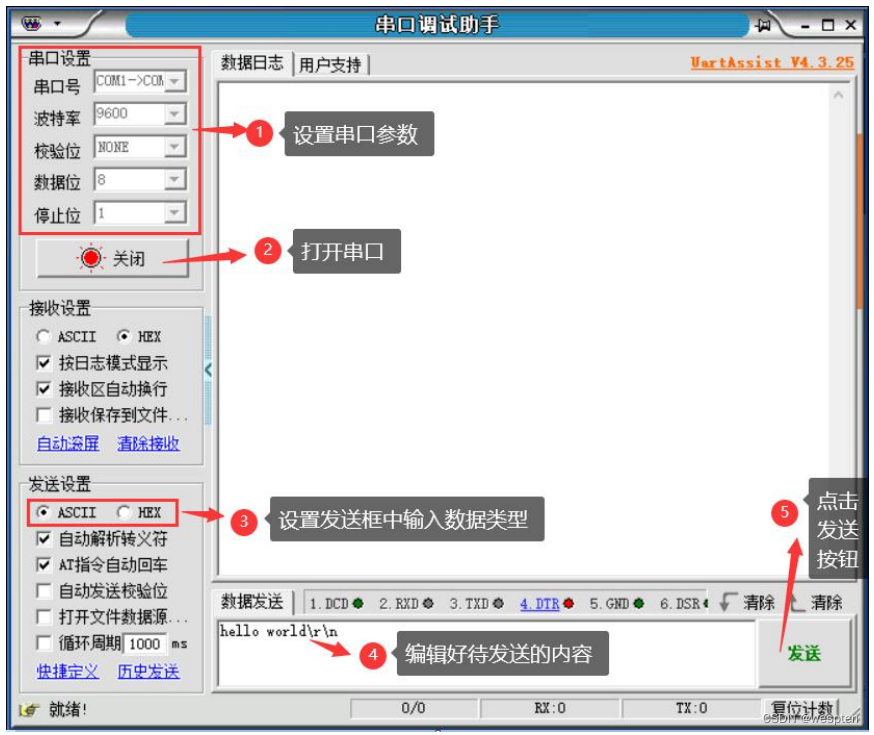
El asistente de depuración del puerto serie envía datos al puerto serie de destino, que se divide en 5 pasos:
- Configuración de parámetros del puerto serie;
- Abra la conexión del puerto serie;
- Establezca el tipo de datos que se enviará (cadena de código ASCII/cadena hexadecimal HEX);
- Editar el contenido a enviar;
- Haga clic en el botón enviar;
5. Enviar caracteres de escape
Al enviar datos como una cadena de código ASCII, los usuarios pueden insertar caracteres no imprimibles en la cadena mediante el uso de caracteres de escape. El ejemplo más simple, para enviar un comando AT con retorno de carro y avance de línea al final, simplemente ingrese AT\r\n en el cuadro de envío y luego haga clic en el botón enviar directamente.
Actualmente, el asistente de depuración admite los siguientes caracteres de escape estándar del lenguaje C:
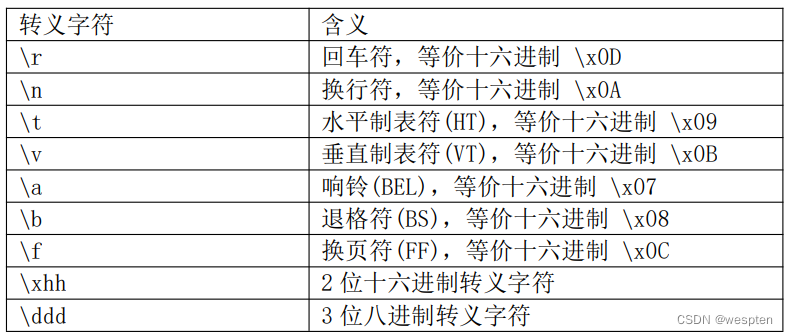
Como extensión, el asistente de depuración admite matrices hexadecimales con escape, por ejemplo: \xA0\x12\xF1\xAB\xCD\x51\xF3 es equivalente a \x[A0 12 F1 AB CD 51 F3]. Varios bytes hexadecimales contenidos entre corchetes [] pueden estar separados por varios espacios o sin espacios.
Nota: Cuando utilice caracteres de escape, debe marcar la opción [Analizar caracteres de escape automáticamente] en la configuración de envío en el lado izquierdo de la interfaz principal; de lo contrario, el asistente de depuración no realizará ningún análisis de los caracteres de escape.
6. Enviar script de comando
A través de la expansión de caracteres de escape, el asistente de depuración comenzó a admitir el envío de scripts de comandos después de la versión V5.0.2, lo que permite a los usuarios agregar varias lógicas de procesamiento empresarial a los datos de comando enviados, incrustar códigos de script que contienen funciones y expresiones de cálculo, y calcular y generar dinámicamente el final. Contenido de datos utilizado para enviar. Para fines de depuración, los usuarios también pueden llamar a la función printf en el comando enviado para depurar la impresión, y los resultados de la salida de la depuración se mostrarán en la ventana de registro.
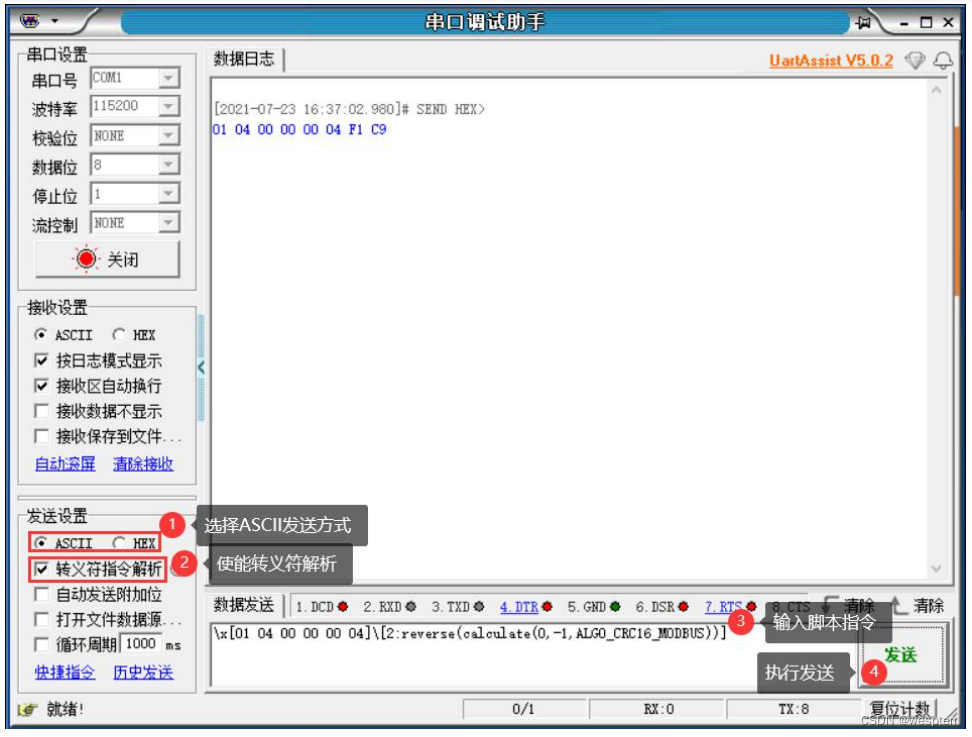
En el siguiente ejemplo, se envía un comando Modbus a través del asistente de depuración. Ingrese el siguiente contenido en la ventana de envío del asistente de depuración:
\x[01 04 00 00 00 04]\[2:reverse(calculate(0,-1,ALGO_CRC16_MODBUS))]Este comando significa enviar un conjunto de datos hexadecimales de 6 bytes 01 04 00 00 00 04, seguido de un código de verificación CRC16 de 2 bytes, que se calcula dinámicamente mediante el siguiente código:
\[2:reverse(calculate(0,-1,ALGO_CRC16_MODBUS))]Entre ellos, \[] se denomina carácter de patrón y se utiliza como contenedor para el código de script incrustado. La expresión anterior se divide en dos partes mediante dos puntos. El 2 antes de los dos puntos significa que el valor calculado final solo ocupa 2 bytes. La expresión después de los dos puntos se utiliza para calcular el código de verificación. El cálculo en la expresión es una función incorporada en el sistema, que se utiliza para calcular el algoritmo de verificación. El primer parámetro de la función de cálculo indica el número de bytes de los datos enviados actualmente para comenzar a calcular el código de verificación; el segundo parámetro indica la longitud de los datos de verificación. , esta longitud puede ser un número negativo. Por ejemplo, cuando es -1, significa que la longitud de los datos es hasta el byte de datos antes de la posición de llamada de la función de cálculo actual. -2 significa que los datos de verificación. la longitud de los datos se avanza 2 bytes desde la posición actual, y así sucesivamente; el tercer parámetro de la función de cálculo indica el algoritmo utilizado. ALGO_CRC16_MODBUS es una constante incorporada en el sistema, que indica el algoritmo de verificación MODBUS_CRC16.
La función inversa se utiliza para invertir el orden de los bytes de los datos de destino (intercambio y reorganización de bytes altos y bajos). El propósito de llamar a la inversa aquí es porque el código de verificación CRC de 16 bits calculado por la función de cálculo está en el orden de bytes de la red (BigEndian), pero el código de verificación CRC en el protocolo ModbusRTU requiere el uso del orden de bytes LittleEndian, por lo que el orden de bytes aquí se invierte el procesamiento de transferencia.
Envíe un script de comando que contenga una expresión de función:
Al enviar código de script, debe marcar las dos opciones modo [ASCII] y [análisis del comando de carácter de escape] en la configuración de envío. Esto se debe a que solo se permite ingresar el código de secuencia de comandos si se selecciona [ASCII]. De lo contrario, si se selecciona el modo HEX, solo se pueden ingresar números hexadecimales; y se debe marcar la opción [Análisis de comando de caracteres de escape] antes de que el asistente de depuración pueda Análisis de expresiones de script importadas mediante barras invertidas.
El carácter de patrón \[] debe usarse para incrustar código de script en las instrucciones. Hay dos métodos de incrustación específicos: expresiones de operación y bloques de código BLOCK.
1. Expresiones operativas
La expresión de operación aquí se refiere específicamente a la expresión de cálculo basada en reglas gramaticales de lenguaje similar a C con un valor de retorno. Su forma general es:
\[n:expression#remark]Esta es una notación de tres secciones: la Sección 1 es la longitud de los datos de salida, la Sección 2 es la expresión de cálculo y la Sección 3 es el texto de la anotación (nota). Tanto el primer como el tercer párrafo se pueden omitir y la forma más simple es \[expresión].
Si la longitud de salida establecida (n) es mayor que la longitud del valor calculado final de la expresión de cálculo real (expresión), se complementará con 0 y la salida. De lo contrario, si la longitud de salida establecida es menor que la longitud de la resultado calculado final, los bytes sobrantes de orden superior se truncarán más tarde. Si se omite el valor de longitud del primer segmento, se genera la longitud inherente del resultado del cálculo de la expresión.
El campo de anotación es un campo opcional, que comienza con un signo #, que indica texto anotativo y también se puede citar como un nombre de anotación.
Por ejemplo, el campo de expresión de una sola línea contenido en el contenido enviado en el ejemplo de la sección anterior es el siguiente:
\[2:reverse(calculate(0,-1,ALGO_CRC16_MODBUS))]Si se omite aún más la longitud de salida, se simplifica a:
\[reverse(calculate(0,-1,ALGO_CRC16_MODBUS))]Aunque se llaman múltiples funciones y múltiples parámetros, solo hay una declaración (una expresión) y un valor de retorno.
2. Segmento de código BLOQUE
BLOQUE Un campo de código a nivel de bloque tiene el formato \[{ script }].
El código a nivel de bloque puede contener cualquier cantidad de declaraciones y el resultado final del cálculo se genera mediante la función echo o echob, o se devuelve mediante la declaración de retorno. Por ejemplo, el campo de expresión única en el ejemplo anterior se puede reescribir como el siguiente segmento de código a nivel de bloque:
\[{
short crc16=calculate(0,-1,ALGO_CRC16_MODBUS);
crc16=reverse(crc16);
return crc16; //或者 echo(crc16);
}]4. Escritura de código de script
Los datos de comando o la plantilla de comando de la herramienta de depuración del puerto serie se pueden incrustar en código script con sintaxis de lenguaje similar a C, lo que facilita a los usuarios escribir comandos o plantillas de manera flexible y realizar potentes funciones avanzadas de envío de comandos o respuesta automática.
1. Operador
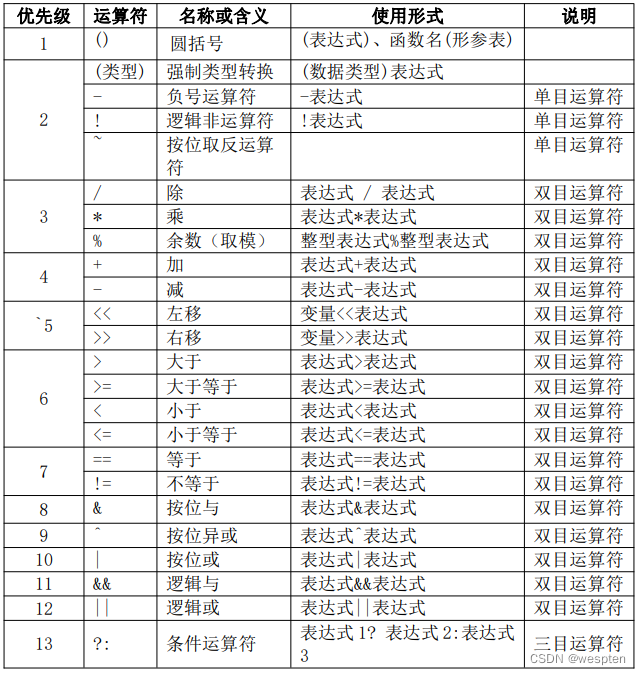
El motor de reglas de respuesta automática admite varias operaciones lógicas y operadores de bits. Hay un total de 34 operadores y 10 tipos de operaciones: operadores aritméticos (+, -, *, /, %), operadores relacionales (>, >=, ==, !=, >, <<, ==, != , <, <=), operadores lógicos (!, ||, &&), operadores condicionales, (?:) operadores de puntero (&, *), operadores de asignación (=), operadores de coma (, ), operador de búsqueda de bytes (sizeof ), operador de conversión de tipo coercitivo ((nombre de tipo)), otros (subíndice [], componente, función); según la cantidad de objetos involucrados en la operación, los operadores se pueden dividir en operadores binarios individuales (como!), binario operadores (como +, -) y operadores ternarios (como ?:).
Los operadores reales utilizados comúnmente en las plantillas de instrucciones se muestran en la siguiente tabla:
2. Expresiones operativas
La llamada expresión de operación es una expresión de cálculo basada en reglas gramaticales de lenguaje similar a C con un valor de retorno. Por ejemplo:
\[2: 2*(getuchar(0)+getuchar(1))]
\[(getuchar(#len)+1): 2*(getuchar(0)+getuchar(1))]Durante el proceso automático de coincidencia y respuesta de comandos, la expresión de la operación será reemplazada dinámicamente por el valor calculado final en tiempo real.
Por lo tanto, la expresión de operación debe estar compuesta por una declaración de script con un valor de retorno en forma y no se permite implementarla en varias declaraciones. Si una declaración no se puede implementar, solo se puede lograr a través de un segmento de código BLOQUE que contiene varias declaraciones de script que se presentan en la siguiente sección. El valor de retorno del bloque de código BLOCK se pasa a través de la declaración de retorno o la función echo/echob.
3. bloque de código BLOQUEAR
La plantilla de instrucciones de la regla de respuesta automática puede utilizar la sintaxis BLOQUE que contiene varias declaraciones. Varias declaraciones de un BLOQUE están entre llaves {} y separadas por punto y coma. Finalmente, el valor final de la expresión BLOQUE se devuelve a través de la declaración de retorno o la función de eco.
La diferencia es que return terminará la declaración después del BLOQUE actual después de devolver el valor, y echo continuará ejecutando la declaración después del BLOQUE después de devolver el valor. Si echo se ejecuta varias veces en un BLOQUE, los datos devueltos cada vez se agregarán a los datos devueltos anteriormente. Si no se ejecuta ningún eco o retorno, significa que no hay datos de retorno; si hay tanto un valor de eco como un valor de retorno, el valor de eco se ignorará y solo se tomará el valor de retorno.
Por ejemplo, el siguiente ejemplo de BLOQUE:
\[{
int num=getuchar(#num);
if(num>0){
echo(0xF2F1);
echo("\xF3\xF4%x",num);
}
else return 0;
}]Descripción del código: si la expresión if(num>0) es verdadera, llame a echo dos veces, los dos datos se superponen y finalmente devuelve el flujo de datos hexadecimal F1 F2 F3 F4 num; si la expresión if(num>0) no es verdadera , luego devuelve el valor 0.
Como extensión, el código de script en la regla de respuesta admite números inmediatos hexadecimales que comienzan con 0x. Por ejemplo, 0xF2F1 en el código anterior es un número inmediato hexadecimal.
4. Tipo de datos variables
El código de secuencia de comandos integrado del motor de reglas de respuesta automática solo puede utilizar los tipos de datos básicos que se muestran en la siguiente tabla y no admite estructuras de variables definidas por el usuario. Los tipos de datos básicos admitidos actualmente son los siguientes:

Restricciones de uso: solo se admiten matrices unidimensionales y punteros unidimensionales. Las matrices multidimensionales y los punteros multidimensionales no se admiten por el momento; los tipos de datos de 64 bits no se admiten por el momento.
5. Definición y alcance de las variables
El lenguaje de programación para reglas de respuesta automática admite el uso de variables. Según los tipos de variables fuertes y débiles, se pueden dividir en variables de tipo fuerte y variables de tipo débil; según el alcance de la variable, se pueden dividir en variables locales y variables globales.
1. Variables fuertemente tipadas y variables débilmente tipificadas
(1) Variables fuertemente tipadas. Las variables fuertemente tipadas son similares al método estándar de definición de variables del lenguaje C y deben definirse antes de su uso. El tipo de datos de una variable fuertemente tipada se especifica cuando se define la variable y no se permite la modificación dinámica del tipo de variable. Al definir una variable fuertemente tipada, debe especificar el tipo de datos y el nombre de la variable, y permitir la inicialización y asignación cuando se define la variable. como:
\[{
int x,y; //定义两个强类型的整形变量
int z=100; //定义一个初值为 100 的强类型整形变量
char *str1="abc";//定义一个 null-teminated 字符串
string str2="abc\x00\x01\x02";//定义一个标准字符串,允许包含0。
}](2) Variables débilmente tipificadas. Las variables de tipo débil no necesitan declararse ni definirse, ni necesitan especificar el tipo de datos de la variable, y pueden usarse directamente. Al asignar un valor a una variable de tipo débil, si el nombre de la variable no existe, la variable se creará automáticamente. El tipo de datos de una variable de tipo débil siempre es igual al tipo de datos del último valor asignado. En otras palabras, el tipo de datos de una variable de tipo débil se puede modificar dinámicamente. Las variables de tipo débil deben usarse mediante la indexación de matrices mediante la palabra reservada global, y el subíndice de la matriz es el nombre de la variable en forma de cadena. Por ejemplo:
\[ {
global["x"]=100; //给弱类型全局变量 x 赋值整形数 100。
global["x"]="abcdefg"; //给弱类型全局变量 x 赋值字符串。
}]2. Variables locales y variables globales
Si las variables en las reglas de respuesta automática se definen en un tipo seguro, solo se pueden usar como variables locales y solo son válidas en la sección \[] actual de la plantilla de comando actual. Las variables locales con el mismo nombre en múltiples \[] no se afectan entre sí.
Si necesita utilizar variables globales, debe utilizar variables de tipo débil en el formato global ["nombre"]. El alcance de las variables de tipo débil cubre todas las plantillas de instrucciones y permanece residente en la memoria durante toda la operación del asistente de depuración.
Una vez que se inicializa una variable global de tipo débil y se le asigna un valor, se puede omitir la palabra clave global y se puede acceder a ella directamente a través del nombre de la variable, tal como se opera con una variable de tipo fuerte. Solo cuando es necesario modificar el tipo de datos de la variable, se debe asignar un valor a la variable mediante la palabra clave global.
6. Conversión de tipo variable
Al igual que las reglas de sintaxis estándar de C/C++, cuando los tipos de operandos son diferentes, a menudo es necesario convertirlos al tipo requerido, proceso que se denomina conversión de tipo forzada.
1. Forma de conversión de tipo forzada
Las conversiones variables vienen en dos tipos: conversiones explícitas y conversiones implícitas. Las dos formas se describen brevemente a continuación.
(1) Conversión de tipo de conversión explícita
Una conversión explícita es simple y toma la forma:
TYPE b = (TYPE) a;Entre ellos, TYPE es un descriptor de tipo, como int, float, etc. Después de ser operado por el operador de conversión de tipo obligatorio, se devuelve un valor con tipo TYPE. Este tipo de operación de conversión obligatoria no cambia el operando en sí y el operando en sí no cambia después de la operación, por ejemplo:
int n=0xab65;
char a=(char)n;El resultado de la conversión de tipo forzada anterior es eliminar el byte superior del valor entero 0xab65, asignar el contenido del byte inferior como un valor de carácter a la variable a y el valor de n permanece sin cambios después del tipo. conversión.
(2) Conversión de tipo de coerción implícita
Las conversiones de tipos implícitas ocurren en expresiones de asignación y expresiones de llamada de función que devuelven un valor. En una expresión de asignación, si los tipos de operandos en los lados izquierdo y derecho del operador de asignación son diferentes, el operando en el lado derecho del operador de asignación se fuerza al valor de tipo en el lado izquierdo del operador de asignación y luego se asigna a la variable en el lado izquierdo del operador de asignación. Cuando se llama a una función, si el tipo de expresión que sigue al retorno es diferente del tipo de valor de retorno de la función, el valor de la expresión que sigue al retorno se forzará al tipo de valor de retorno de la función al devolver el valor, y luego el valor será devuelto, como por ejemplo:
int n;
double d=3.88;
n=d;//执行本句后,n 的值为 3,而 d 的值仍是 3.882. Usos típicos de la conversión de tipos forzada en reglas de respuesta automática
En la sección de datos de respuesta del patrón en la plantilla de respuesta del comando, si la longitud de los datos no se especifica explícitamente, la longitud predeterminada es la longitud inherente de su tipo de datos.
Por ejemplo, hay un segmento de datos enteros con una longitud predeterminada de 4 bytes. Si es necesario, tome sólo 2 bytes. Puede especificar explícitamente la longitud de los datos como 2 o forzar la conversión de tipo a tipo corto. Por ejemplo, las dos plantillas de respuesta de comando siguientes son equivalentes:
\[2:getshort(0)*100] //#直接指定数据长度 2
\[(short)(getU16(0)*100)] //#强制类型转成 2 字节的short 数据类型Nota: Para el valor de retorno de la expresión de cálculo numérico, si no se realiza ninguna conversión de tipo forzada, el tipo de datos predeterminado es int de 32 bits o tipo flotante, con una longitud de 4 bytes.
7. Reglas gramaticales de capitalización.
El código de script integrado del asistente de depuración no distingue entre mayúsculas y minúsculas. Sin embargo, para evitar confusiones, se recomienda que siempre cumpla con las normas de escritura de código que "distinguen entre mayúsculas y minúsculas" y trate de asegurarse de que las mayúsculas y minúsculas de los nombres de funciones, nombres de variables y nombres de constantes se escriban de forma coherente.
8. Definición y referencia de anotación de campo.
Tanto los comandos de script como las plantillas de comandos (incluidas las plantillas de coincidencia de comandos y las plantillas de respuesta de comandos) pueden contener varios segmentos de patrón, y la forma general de cada segmento de patrón se puede resumir como:
\[exp_len:exp_value#comment]Entre ellos, exp_len es la longitud de los datos del campo, exp_value es el contenido de los datos del campo y #comment es el comentario del campo.
La forma de anotación comienza con un signo # seguido del texto de la anotación. El campo de anotación tiene dos funciones:
- Sirve como anotación para explicar el campo de destino.
- Asigne un nombre al campo. Otras secciones del esquema de la misma plantilla de directiva pueden hacer referencia a los datos del campo nombrado a través de nombres de anotaciones. Solo se puede acceder a las anotaciones de referencia a través de las siguientes funciones del sistema para leer segmentos de datos de instrucciones: get, getchar, getuchar, getshort, getushort, getint, getuint. Además, ninguna otra función admite la llamada de anotaciones como parámetros.
A continuación se muestra un ejemplo sencillo para ilustrar:
- Plantilla de coincidencia de comandos: REQ\[2 #command];
- Plantilla de respuesta de comando: ACK\[2:gets(#command,2)];
En la plantilla de coincidencia de comandos de este ejemplo, \[2 #command] es una coincidencia aproximada de longitud fija de 2 bytes de datos de comando; mientras que en la plantilla de respuesta, estos dos bytes deben copiarse como parte del marco de datos de respuesta. En la sección de respuesta del patrón correspondiente a la plantilla de respuesta, el bloque de datos correspondiente al nombre de la anotación se puede leer a través de la función get (#comment, len). Omitir el segundo parámetro de get significa leer todo el campo de destino.
En este ejemplo, la plantilla de respuesta necesita copiar los datos de todo el segmento de comando en la instrucción de solicitud, por lo que se puede omitir el segundo parámetro que representa la longitud de la función get.
De esta manera, esta plantilla de respuestas se puede simplificar a:
- Plantilla de respuesta de comando → Simplificado: ACK\[2:gets(#command)];
Si la longitud de datos requerida del segmento de respuesta del patrón es consistente con la longitud del bloque de datos devuelto por get, se puede omitir el parámetro de longitud del segmento de respuesta del patrón, como se muestra a continuación:
- Plantilla de respuesta de comando → Simplificado nuevamente: ACK\[gets(#command)];
9. Explicación detallada de las funciones integradas del sistema.
La expresión de operación de la regla de respuesta automática puede llamar a la función integrada del sistema del motor de reglas (los nombres de las funciones no distinguen entre mayúsculas y minúsculas). Las funciones actualmente admitidas son las siguientes.
(1) printf: salida formateada a la consola
Prototipo de función:
void printf(const char format, 可选参数...);Descripción de la función: Enviar información de impresión de depuración al dispositivo de salida estándar (ventana de registro/recepción) en el formato especificado.
(2) sprintf - cadena de formato
Prototipo de función:
int sprintf(char *buffer, char *format [,argument,...]);Descripción de la función: escribe datos formateados en un búfer de cadena. Si tiene éxito, devuelve el número total de caracteres escritos, excluyendo el carácter nulo añadido al final de la cadena. Si falla, se devuelve un número negativo.
(3) strtoint - cadena a entero
Prototipo de función:
int strtoint(const char *nptr);Alias de función:
atoiDescripción de la función: la función strtoint escanea la cadena nptr del parámetro, omite los espacios en blanco anteriores (como espacios, tabulaciones), etc., y escanea hasta el siguiente carácter no numérico o el final de la entrada. Si nptr no se puede convertir a un número entero, se devolverá 0.
(4) inttostr - convierte un número entero en una cadena
Prototipo de función:
string inttostr(int n);Descripción de la función: convierte el número entero n en un tipo de cadena y lo devuelve.
(5) strcpy - copia de cadena
Prototipo de función:
char *strcpy(char* dest, const char *src);Descripción de la función: copie la cadena terminada en nulo apuntada por src al espacio de direcciones apuntado por destino y devuelva el puntero a destino.
(6) strcat - concatenación de cadenas
Prototipo de función:
char *strcat(char *dest,const char *src1, const char *src2,…);Descripción de la función: Copie y empalme varias cadenas de origen terminadas en NULL (src1, src2,...) al final de la cadena a la que apunta dest (elimine "\0" al final de dest original). Asegúrese de que el espacio de cadena al que apunta destino sea lo suficientemente largo para acomodar la cadena fuente copiada. Finalmente devuelve un puntero al destino.
(7) strcmp - comparación de cadenas (distingue entre mayúsculas y minúsculas)
Prototipo de función:
int strcmp(const char *s1,const char *s2);Descripción de la función: Compare dos cadenas carácter por carácter de izquierda a derecha (compare según el valor ASCII) hasta que aparezcan caracteres diferentes (distingue entre mayúsculas y minúsculas) o hasta que se encuentre '\0'. Cuando s1s2, devuelve un número positivo.
(8) estricto: comparación de cadenas (no distingue entre mayúsculas y minúsculas)
Prototipo de función:
int stricmp(const char *s1,const char *s2);Descripción de la función: Compare dos cadenas carácter por carácter de izquierda a derecha (compare según el valor ASCII) hasta que aparezcan caracteres diferentes (no distingue entre mayúsculas y minúsculas) o hasta que se encuentre '\0'. Cuando s1s2, devuelve un número positivo.
(9) strncpy: copia de cadena de longitud limitada
Prototipo de función:
char *strncpy(char* dest, const char *src, int n);Descripción de la función: copie la cadena terminada en nulo apuntada por src al espacio de direcciones apuntado por destino y devuelva el puntero a destino. Si la longitud real de la cadena de origen es mayor que el parámetro n, se copian como máximo n bytes.
(10) strncmp: comparación de cadenas de longitud limitada (distingue entre mayúsculas y minúsculas)
Prototipo de función:
int strncmp(const char *s1,const char *s2,int n);Descripción de la función: compare dos cadenas carácter por carácter de izquierda a derecha (compare según el valor ASCII) hasta que aparezcan caracteres diferentes (distingue entre mayúsculas y minúsculas), se encuentre '\0' o el número de caracteres comparados exceda n. Cuando s1s2, devuelve un número positivo.
(11) strnicmp - comparación de cadenas de longitud limitada (no distingue entre mayúsculas y minúsculas)
Prototipo de función:
int strnicmp(const char *s1,const char *s2,int n);Descripción de la función: compare dos cadenas carácter por carácter de izquierda a derecha (compare según el valor ASCII) hasta que aparezcan caracteres diferentes (no distingue entre mayúsculas y minúsculas), encuentre '\0' o el número de caracteres comparados exceda n. Cuando s1s2, devuelve un número positivo.
(12) memcpy - copia de datos de la memoria
Prototipo de función:
void *memcpy(void *dest, void *src, int n);Descripción de la función: Copie n bytes del área de almacenamiento src al área de almacenamiento destino. Devuelve un puntero al área de almacenamiento de destino.
(13) memcmp-comparación de datos de memoria
Prototipo de función:
int memcmp(const void *data1, const void *data2, int n);Descripción de la función: compare los primeros n bytes de los datos del área de almacenamiento1 y los datos del área de almacenamiento2. Si el valor de retorno == 0, significa que datos1 es igual a datos2; si el valor de retorno < 0, significa que datos1 es menor que datos2; si el valor de retorno> 0, significa que datos2 es menor que datos1.
(14) cadena: método de construcción de cadena estándar
Prototipo de función 1:
string string(int len);Función: construye y devuelve una cadena vacía con una longitud de espacio reservado de len.
Prototipo de función 2:
string string(void *str, int len);Función: construye una cadena vacía con una longitud de len e inicialízala con los datos señalados por str.
Prototipo de función 3:
string string(string1,string2, …);Función: conecte varias cadenas de tipo cadena o char * de principio a fin para construir una nueva cadena y devolverla.
(15) unix_timestamp: obtiene la marca de tiempo Unix de 32 bits
Prototipo de función:
unsigned int unix_timestamp(void);Parámetros de entrada: Ninguno.
Valor de retorno: devuelve un entero sin signo de 32 bits.
Descripción de la función: Genera una marca de tiempo Unix de 32 bits, es decir, la cantidad de segundos desde 1970-1-1 00:00:00 hasta la hora actual.
(16) genAutoID: genera ID de serie de incremento automático de 32 bits
Prototipo de función:
unsigned int genAutoID(void);Parámetros de entrada: Ninguno.
Valor de retorno: devuelve un entero sin signo de 32 bits. Descripción de la función: el valor inicial es 1. Cada vez que se llama, el valor de retorno aumenta automáticamente en 1.
(17)aleatorio: genera números aleatorios/selecciona aleatoriamente datos de conjuntos
Prototipo de función 1:
int random (int maximum);Descripción de la función: Genera un número aleatorio de 32 bits cuyo valor absoluto es menor que el máximo del parámetro de entrada. Si no se especifica ningún límite superior (se omite el parámetro máximo), se genera aleatoriamente un número aleatorio de 32 bits.
Prototipo de función 2:
var random (var1,var2,…);Parámetros de entrada: dos o más datos de cualquier tipo
Valor de retorno: devuelve aleatoriamente uno de la lista de parámetros de entrada.
Descripción de la función: seleccione aleatoriamente los datos de la colección, es decir, seleccione aleatoriamente un dato entre varios datos y devuélvalo.
Por ejemplo: aleatorio (100,0x255,123.456, 'x', "abcdefg"), para realizar un retorno aleatorio de datos de la lista de parámetros de entrada, los tipos de datos de los parámetros de entrada se pueden mezclar libremente y el tipo de valor de retorno es el tipo de datos real de los parámetros seleccionados aleatoriamente.
(18)reverse invierte el orden de los bytes de los datos
Prototipo de función:
var reverse(data, maxLen);Parámetro de entrada: los datos del parámetro son los datos de origen que se van a revertir, que pueden ser un tipo de datos básico como un entero (entero corto o entero largo) o punto flotante, o una matriz de bytes, cadena o tipo de puntero de datos; el parámetro opcional maxLen se utiliza Especifica la longitud máxima de la conversión de datos. Si se omite este parámetro, la longitud de conversión será la longitud predeterminada de los datos de origen. Por ejemplo, la longitud predeterminada de los datos de tipo int es 4 bytes, y la longitud predeterminada de los datos cortos El tipo es de 2 bytes. Para las cadenas, la longitud de la cadena en sí se obtendrá automáticamente, etc.
Descripción de la función: invierta el orden de bytes de los datos de origen y devuelva los datos reorganizados en orden inverso. Si el tipo de datos de origen es un tipo de datos básico como un entero (entero corto o largo) o punto flotante, el orden de bytes de los datos de origen no se modificará, pero se devolverán los datos invertidos; si el tipo de datos de origen es una cadena, matriz o Si el tipo de puntero es un tipo de puntero, los datos de origen también se invertirán en el orden de las palabras y se devolverá la referencia de datos invertida.
(19) obtiene: copia el segmento de datos de los datos de la instrucción actual
Prototipo de función:
var gets(offset|#comment,len);Parámetro de entrada: desplazamiento|#comentario es la dirección de desplazamiento o el nombre de la anotación de campo. Si copia datos a través de una dirección de compensación, debe dejar claro que la dirección de compensación es relativa a los datos de instrucción correspondientes a la plantilla actual; si copia datos a través de un nombre de anotación de campo, el sistema primero buscará el campo de anotación. correspondiente al marco de instrucción de origen. Si no existe, busque el campo de anotación correspondiente al marco de comando de respuesta, y el nombre de la anotación de destino al que se hace referencia debe definirse antes de llamar a la función get en la plantilla actual.
Descripción de la función: copie un bloque de datos con una longitud especificada de len desde la ubicación especificada (dirección de desplazamiento del marco de comando actual o el segmento de datos de comando correspondiente al nombre de anotación del campo de plantilla); el parámetro de longitud len se puede omitir. Si se copia la dirección de desplazamiento se utiliza, si se omite el parámetro de longitud, los datos se copiarán hasta el final del marco de comando; si se utiliza una anotación de nombre de campo, si se omite el parámetro de longitud, los datos de todo el campo correspondiente al nombre de la anotación ser copiado.
Por ejemplo, la siguiente regla de respuesta:
Plantilla de coincidencia de instrucciones:
ABCD\[2#command]Plantilla de respuesta de comando:
ACK_[4:gets(0)]_\[2:gets(#command)]Supongamos que el motor de reglas de respuesta automática recibe los datos de cadena ABCDFF, luego la coincidencia del comando es exitosa y el contenido que coincide con la coincidencia aproximada de longitud fija \[2#command] es FF. Según la plantilla de respuesta del comando, los datos de respuesta generados son: ACK_ABCD_FF.
Entre ellos, \[4:gets(0)] significa copiar 4 bytes de datos a partir de la dirección de desplazamiento 0 del mensaje de datos recibido actualmente (ABCDFF): ABCD; \[2:gets(#command)] significa comenzar desde dirección de desplazamiento 0 del mensaje de datos recibido actualmente (ABCDFF); Copie 2 bytes de datos en la dirección de desplazamiento correspondiente a la anotación #comando del mensaje de datos recibido actualmente (ABCDFF): FF.
(20) getchar: copia un número con signo de byte de los datos de la instrucción actual
Prototipo de función:
char getchar(offset|#comment);Alias de función: getS8
Parámetros de entrada: dirección de desplazamiento del marco de instrucción o nombre de anotación del campo de plantilla (consulte la descripción del parámetro de la función get más arriba).
Descripción de la función: copie 1 byte de datos firmados desde la ubicación especificada (dirección de desplazamiento del marco de comando actual o el segmento de datos de comando correspondiente al nombre de anotación del campo de plantilla).
(21) getuchar: copia un número de byte sin signo de los datos de la instrucción actual
Prototipo de función:
unsigned char getuchar(offset|#comment);Alias de función: getU8, getByte
Parámetros de entrada: dirección de desplazamiento del marco de instrucción o nombre de anotación del campo de plantilla (consulte la descripción del parámetro de la función get más arriba).
Descripción de la función: copie 1 byte de datos sin firmar desde la ubicación especificada (dirección de desplazamiento del marco de comando actual o el segmento de datos de comando correspondiente al nombre de anotación del campo de plantilla).
(22) getshort: copia un entero con signo de 2 bytes de los datos de la instrucción actual
Prototipo de función:
short getshort(offset|#comment,isBigEndian);Alias de función: getS16
Parámetros de entrada: offset|#comment es la dirección de desplazamiento o el nombre de la anotación del campo; isBigEndian es un parámetro opcional, una variable de datos booleana, que indica si el orden de bytes de los datos de lectura especificados es el primero o el último byte alto. Si es verdadero, significa que el byte alto es el primero; de lo contrario, el byte bajo es el primero. Si se omite el parámetro isBigEndian, significa que se toma la configuración de orden de bytes global (la casilla de verificación "Orden de bytes de red" en la parte inferior derecha del panel de la ventana de configuración de respuesta automática se usa para establecer el orden de bytes predeterminado global. Marcarla significa que el orden global de bytes es BigEndian (de lo contrario, LittleEndian).
Descripción de la función: copie un entero con signo de 2 bytes desde la ubicación especificada (dirección de desplazamiento del marco de comando actual o el segmento de datos del comando correspondiente al nombre de anotación del campo de plantilla).
(23) getushort: copia un entero sin signo de 2 bytes de los datos de la instrucción actual
Prototipo de función:
unsigned short getushort(offset|#comment, isBigEndian);Alias de función: getU16
Parámetros de entrada: offset|#comment es la dirección de desplazamiento o el nombre de la anotación del campo; isBigEndian es un parámetro opcional, una variable de datos booleana, que indica si el orden de bytes de los datos de lectura especificados es el primero o el último byte alto. Si es verdadero, significa que el byte alto es el primero; de lo contrario, el byte bajo es el primero. Si se omite el parámetro isBigEndian, se toma la configuración del orden de bytes global.
Descripción de la función: copie un entero sin signo de 2 bytes desde la ubicación especificada (dirección de desplazamiento del marco de comando actual o el segmento de datos del comando correspondiente al nombre de anotación del campo de plantilla).
(24) getint: copia un entero con signo de 4 bytes de los datos de la instrucción actual
Prototipo de función:
short getint(offset|#comment, isBigEndian);Alias de función: getS32
Parámetros de entrada: offset|#comment es la dirección de desplazamiento o el nombre de la anotación del campo; isBigEndian es un parámetro opcional, una variable de datos booleana, que indica si el orden de bytes de los datos de lectura especificados es el primero o el último byte alto. Si es verdadero, significa que el byte alto es el primero; de lo contrario, el byte bajo es el primero. Si se omite el parámetro isBigEndian, se toma la configuración del orden de bytes global.
Descripción de la función: copie un entero con signo de 4 bytes desde la ubicación especificada (dirección de desplazamiento del marco de comando actual o el segmento de datos del comando correspondiente al nombre de anotación del campo de plantilla).
(25) getuint: copia un entero sin signo de 4 bytes de los datos de la instrucción actual
Prototipo de función:
unsigned short getuint(offset|#comment, isBigEndian);Alias de función: getU32
Parámetros de entrada: offset|#comment es la dirección de desplazamiento o el nombre de la anotación del campo; isBigEndian es un parámetro opcional, una variable de datos booleana, que indica si el orden de bytes de los datos de lectura especificados es el primero o el último byte alto. Si es verdadero, significa que el byte alto es el primero; de lo contrario, el byte bajo es el primero. Si se omite el parámetro isBigEndian, se toma la configuración del orden de bytes global.
Descripción de la función: copie un entero sin signo de 4 bytes desde la ubicación especificada (dirección de desplazamiento del marco de comando actual o el segmento de datos del comando correspondiente al nombre de anotación del campo de plantilla).
(26) calcular - calcular el dígito de control
Prototipo de función:
var calculate(offset, len, algorithm);Parámetros de entrada: el parámetro offset es la dirección de desplazamiento de los datos a verificar; len es la longitud de los datos a verificar. Si len es -1, significa que la longitud de los datos es hasta el byte de datos anterior en el posición actual de llamada a la función de cálculo. Si len es -2, entonces Indica que la longitud de los datos se adelanta 2 bytes desde la posición actual, y así sucesivamente; el algoritmo del parámetro es el algoritmo seleccionado.
Descripción de la función: Calcular el valor de verificación de datos. El tipo de datos del valor de retorno de la función depende del algoritmo de verificación específico. Si el valor de verificación es de un solo byte, el tipo de datos devuelto es un carácter sin signo; si el valor de verificación es de doble byte, el tipo de datos del valor devuelto es corto sin signo; si el valor de verificación es de cuatro bytes, entonces el valor de retorno El tipo de datos es int sin signo.
La lista de algoritmos actualmente admitidos por calcular (el algoritmo de parámetro puede tomar un valor constante) es la siguiente:
- ALGO_ACC //Suma acumulativa de 1 byte
- ALGO_LRC //Suma acumulada de 1 byte y luego negativa
- ALGO_XOR //comprobación XOR de 1 byte
- ALGO_CRC16_MODBUS //comprobación MODUBUS CRC16 de 2 bytes
- ALGO_CRC8
- ALGO_CRC8_ITU
- ALGO_CRC8_ROHC
- ALGO_CRC8_MAXIM
- ALGO_CRC8_WCDMA
- ALGO_CRC8_CDMA2000
- ALGO_CRC16_CCITT
- ALGO_CRC16_CCITT_FALSE
- ALGO_CRC16_XMODEM
- ALGO_CRC16_X25
- ALGO_CRC16_IBM
- ALGO_CRC16_USB
- ALGO_CRC16_MAXIM
- ALGO_CRC16_DNP
- ALGO_CRC32
- ALGO_CRC32_BZIP2
- ALGO_CRC32_MPEG2
- ALGO_CRC32_POSIX
- ALGO_CRC32_JAMCRC
(27) eco: implementa el valor de retorno de transmisión del bloque de código BLOQUE
Prototipo de función:
int echo (const char *format,…);Descripción de la función: los datos de texto de salida formateados se utilizan como el valor de retorno final del bloque de código BLOCK, y la función de eco en sí devolverá la longitud de los datos de texto generados.
Por ejemplo:
\[{ echo("hello\r\n"); echo("ok\r\n") }]
\[{ echo("ERR=%d",errno); }]
\[{ echo (gets(#Annotation)); }]Nota: El segundo parámetro de eco se puede omitir. Cuando solo hay un parámetro, no se realiza ningún formateo y los datos señalados por el primer parámetro se generan directamente. Un bloque de código BLOCK en forma de \[{…}] puede realizar el valor de retorno de todo el BLOQUE a través de la declaración de retorno o la función de eco. La diferencia es que la declaración de retorno saldrá del BLOQUE actual inmediatamente después de la ejecución, y el código posterior del BLOQUE actual no se ejecutará; la declaración de eco no saldrá del BLOQUE. Si hay múltiples datos de salida de funciones de eco en el futuro, Estos datos se transmitirán y unirán en Together como el valor de retorno del BLOQUE actual.
(28) echob: implementa el valor de retorno de transmisión del bloque de código BLOCK
Prototipo de función:
void echob (data,length);Parámetros de entrada: datos es el contenido de los datos de salida (puede ser un número entero, una cadena, una matriz o un puntero de datos, etc.); longitud es la longitud del byte que limita los datos de salida.
Descripción de la función: genera datos binarios como valor de retorno del bloque de código BLOCK. La salida de múltiples funciones echo o echob en el mismo BLOQUE se agregará y fusionará secuencialmente en forma de transmisión de datos.
Por ejemplo:
\[{ echob(gets(0),100)); }]
\[{ echob(gets(#Annotation)); }]
\[{ char str[3]="\x01\x02\x03"; echob(str,3); }]Tenga en cuenta que el segundo parámetro de echob se puede omitir. Cuando solo hay un parámetro, las dos funciones echo y echob son equivalentes y se generan de acuerdo con la longitud inherente de los datos de entrada.
(29) retraso – operación retrasada
Prototipo de función:
void delay(ms);Parámetros de entrada: ms es el número de milisegundos de retraso.
Descripción de la función: esta función se utiliza principalmente para que las plantillas de respuesta implementen respuestas retrasadas. Por ejemplo, la siguiente plantilla de respuesta:
\[{delay(1000); echob(gets(0),100));}]
\[{delay(500);}]OK\r\nAl insertar la función de retraso en el encabezado de la plantilla de respuesta, se logra una salida (envío) retrasada de los datos de respuesta.
5. Uso avanzado de UartAssist
La ventana del panel de herramientas proporciona opciones de operación avanzadas para la depuración de comunicaciones, incluidos comandos de acceso directo, envío por lotes, respuesta automática, envío histórico, calculadora de verificación, etc.
1. Definición rápida
Cuando el asistente de depuración del puerto serie se comunica con el dispositivo de destino o el servicio de aplicación del puerto serie, generalmente necesita enviar algunas instrucciones o datos interactivos de acuerdo con el protocolo de aplicación real. Cuando hay muchas instrucciones, definitivamente será problemático e ineficiente ingresar estos datos de instrucciones en el sitio. Para resolver este problema, el asistente de depuración del puerto serie proporciona una función de predefinición de comando, es decir, [definición de acceso directo] en el panel de herramientas (la última versión ha pasado a llamarse comando de acceso directo).
Esta función admite la predefinición de comandos en forma de cadenas de código hexadecimal o ASCII. Puede definir el nombre del comando y el contenido de datos correspondiente, y puede definir la tecla de acceso rápido de envío (tecla de acceso directo). Las instrucciones predefinidas se pueden exportar y guardar directamente como archivos, o importar desde archivos externos en cualquier momento. De forma predeterminada, las instrucciones predefinidas se guardan automáticamente en el directorio de la aplicación actual en forma de archivo de configuración y se cargan automáticamente cuando se inicia el software.
Como se muestra abajo:
Como se muestra en la figura anterior, cada comando predefinido contiene tres partes: nombre, datos y teclas de acceso directo. El nombre del comando es equivalente al comentario del comando, que describe los datos del comando; cada comando puede tener una tecla de acceso directo separada y los datos del comando correspondiente se pueden enviar directamente presionando la tecla de acceso directo en el teclado. Para cada comando, independientemente de si se define una tecla de acceso directo, los datos del comando seleccionado se pueden enviar directamente haciendo clic en el botón en la barra de acceso directo o presionando la tecla Intro.
Cree una nueva directiva predefinida:
Las instrucciones predefinidas se pueden agregar, eliminar, modificar, ordenar, importar y exportar a través del menú contextual. Tome como ejemplo la creación de un comando predefinido, haga clic derecho en el espacio en blanco de la ventana [Definición rápida], aparecerá el menú contextual y seleccione el elemento del menú [Nuevo] para crear un nuevo comando predefinido.
Al crear una nueva instrucción, seleccione un valor de cadena o un valor hexadecimal de acuerdo con el escenario de la aplicación real y luego complete la entrada del nombre de la instrucción y el contenido de los datos en la ventana de definición de acceso directo.
Editar directivas predefinidas:

Si desea editar las instrucciones predefinidas que se han ingresado, puede hacer clic derecho directamente en la instrucción de destino y luego seleccionar editar la instrucción de destino en el menú emergente contextual, incluida la modificación del contenido de los datos, el tipo de datos ( ASCII/HEX), configuración de teclas de acceso directo y cambio de nombre, eliminación y otras operaciones.
Por ejemplo, la imagen de arriba es para editar el contenido de datos de una instrucción. Después de editar, haga clic en el botón [Aceptar] para cerrar la ventana de edición. El contenido editado y modificado se guardará automáticamente cuando se cierre el software.
Utilice un editor hexadecimal específico para modificar las instrucciones:
Como se muestra en la figura anterior, después de seleccionar la instrucción de destino, puede seleccionar [Modificar datos hexadecimales] a través del menú contextual y usar un editor hexadecimal especial para editar la instrucción de datos comparando códigos hexadecimales y ASCII.
2. Enviar en lotes
La función de envío por lotes se utiliza para controlar múltiples instrucciones de datos predefinidas que se enviarán en un orden determinado y en diferentes intervalos de retraso. La función [Envío por lotes] se encuentra en la ventana del panel de herramientas, similar a la función [Definición rápida], y primero requiere editar e ingresar instrucciones predefinidas. Además de definir los datos del comando y los comentarios de texto, cada comando también define un tiempo de retraso, es decir, cuánto tiempo se debe retrasar el envío del comando actual después de enviar el comando anterior.
Envío por lotes ~ Lista de instrucciones:
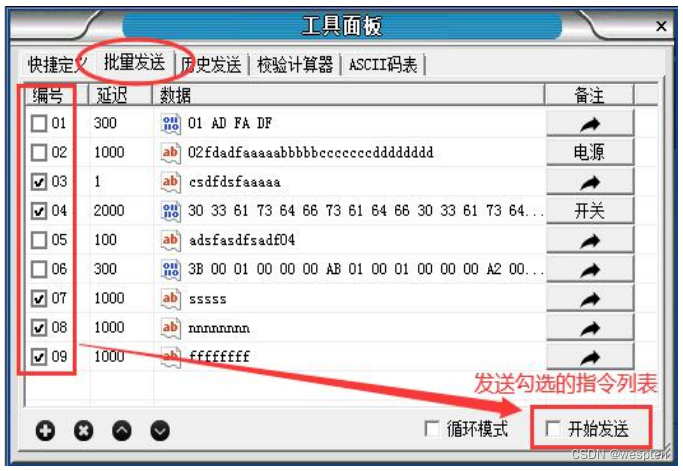
Como se muestra en la figura anterior, en la ventana de envío por lotes, cada instrucción predefinida incluye cuatro partes: número, tiempo de retraso, datos y comentarios. El orden de los números de instrucción determina el orden de las instrucciones enviadas en lotes, y solo las instrucciones con la casilla de verificación anterior marcada se enviarán en lotes; el retraso se refiere al retraso antes del envío, es decir, el retraso en el envío entre la instrucción actual y la anterior. instrucción enviada. El tiempo, en milisegundos; el comentario del comando es en realidad similar al nombre del comando en [Definición de acceso directo], que se utiliza para comentar el comando. Haga clic en el botón en la columna de comentarios para enviar directamente los datos del comando correspondiente.
Marque la opción [Iniciar envío] en la esquina inferior derecha de la ventana de envío por lotes, y el asistente de depuración enviará las instrucciones marcadas en la lista de instrucciones en secuencia, y el tiempo de espera establecido se ejecutará antes de enviar cada instrucción. Una vez enviadas todas las instrucciones, el envío se detendrá automáticamente y la casilla de verificación [Iniciar envío] se cancelará automáticamente. Si se marca la opción [Modo de ciclo], el envío por lotes continuará una y otra vez hasta que se desmarque manualmente la opción [Modo de ciclo] o [Iniciar envío].
A través del menú contextual, puede agregar, eliminar, modificar, ordenar, importar y exportar instrucciones enviadas en lotes. Tomando la nueva instrucción por lotes como ejemplo, haga clic derecho en el espacio en blanco de la ventana [Envío por lotes] para que aparezca el menú contextual, seleccione el elemento de menú [Nuevo] y luego seleccione un valor de cadena o un valor hexadecimal según al escenario de la aplicación real, y finalmente en la ventana emergente La ventana de edición completa la entrada del contenido de la instrucción, como se muestra en la siguiente figura.
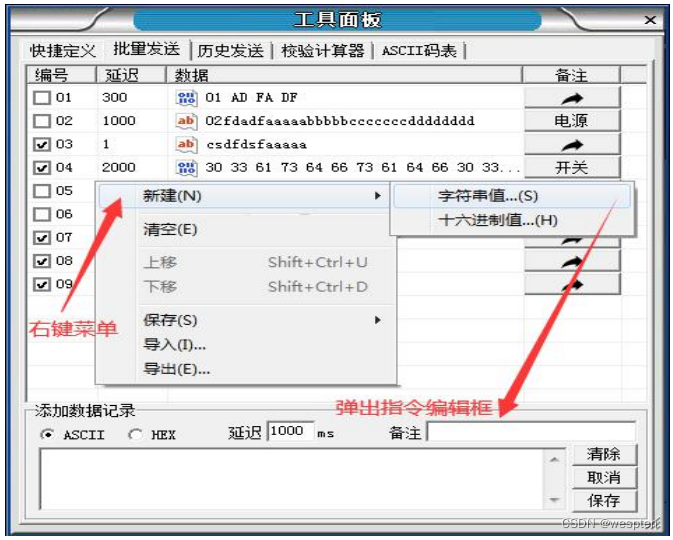
Después de editar el contenido, haga clic en el botón Guardar. Si desea editar esta instrucción nuevamente, puede hacer doble clic directamente en la instrucción de destino en la lista de instrucciones, o hacer clic con el botón derecho en la instrucción de destino y luego hacer clic en el elemento del menú [Modificar]. en el menú emergente contextual, que aparecerá La ventana de edición de la instrucción de destino.
3. Respuesta automática
La función de respuesta automática se utiliza para hacer coincidir e identificar las instrucciones de datos recibidas por el asistente de depuración en tiempo real y enviar automáticamente las instrucciones de respuesta correspondientes de acuerdo con las reglas predefinidas por el usuario.
Los usuarios solo necesitan diseñar las reglas de respuesta con anticipación y luego el motor de reglas integrado en el asistente de depuración coincidirá automáticamente con las reglas de comando para los datos recibidos y enviará los datos de respuesta. Si necesita admitir respuestas automáticas a varias instrucciones al mismo tiempo, simplemente cree varias reglas de respuesta automática en consecuencia.
4. Envío de historial
La ventana de envío histórico en el panel de herramientas registra datos de comandos históricos enviados por los usuarios. Los usuarios pueden abrir la ventana de envío histórico para verla en cualquier momento, como se muestra en la siguiente figura.
Registros históricos de envío:
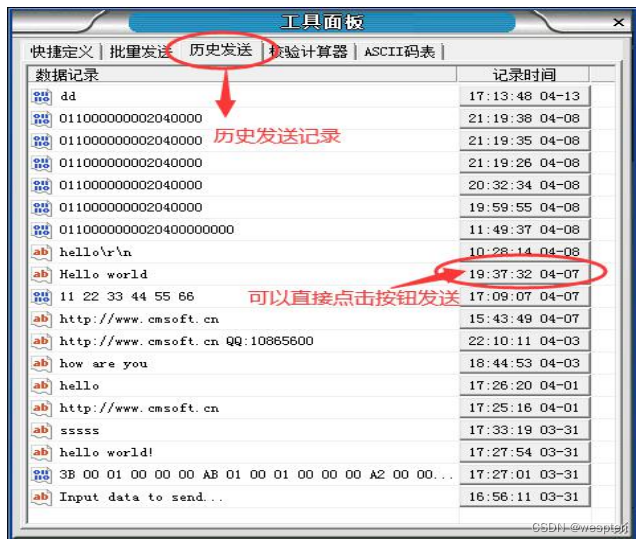
Cada registro de envío histórico se divide en dos partes: contenido de datos y tiempo de grabación. El tiempo de grabación es el momento en que se enviaron los datos por primera vez. Este tiempo se muestra en forma de botón. Haga clic en el botón para reenviar directamente el comando. Sin embargo, el comando resent no agregará nuevos registros de envío a la ventana de envío histórico a menos que se eliminen los registros históricos existentes. De hecho, la ventana de envío histórico solo guarda los datos enviados a través del botón de envío en la ventana principal, y los datos enviados mediante la definición de acceso directo, el envío por lotes y el envío histórico no se guardarán en el registro de envío histórico.
5. Calculadora
El asistente de depuración del puerto serie admite la adición automática de un código de verificación al enviar datos, o puede calcular el código de verificación de los datos a través de la calculadora de verificación proporcionada por el asistente de depuración y luego agregarlo manualmente a los datos enviados.
Calculadora de dígitos de control:
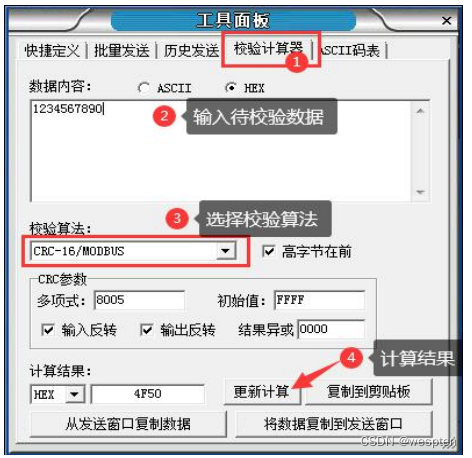
La calculadora de dígitos de control se abre desde el panel de herramientas como se muestra arriba.
El tipo de datos para la verificación puede ser código ASCII o código HEX, pero el tipo de datos debe ser consistente con el contenido real de los datos de entrada; los principales algoritmos de verificación disponibles son los siguientes:
- CHECKSUM-8: código de verificación de suma acumulativa de 8 bits (1 byte). El código de verificación es la suma de todos los bytes de los datos de verificación;
- CHECKSUM-8N/LRC: Verificación de redundancia longitudinal (LRC, verificación de redundancia longitudinal), el valor de verificación es el número negativo de la suma de todos los bytes de los datos de verificación;
- XOR-8/BCC: Carácter de verificación de bloque (BCC, carácter de verificación de bloque), el valor de verificación es el valor XOR de todos los bytes de los datos de verificación;
- CRC-8: verificación CRC de 8 bits, polinomio x 8 + x 2 + x + 1 (0x07), valor inicial 0x00, los datos de entrada no se invierten, los datos de salida no se invierten y el resultado de salida es el valor XOR 0x00;
- CRC-16/MODBUS: código de verificación CRC de 16 bits adecuado para Modbus, polinomio x 16 + x 15 + x 2 + 1 (0x8005), valor inicial 0xFFFF, inversión de datos de entrada, inversión de datos de salida, valor XOR de resultado de salida 0x0000;
- CRC-16/CCITT: Polinomio x 16+x 12+x 5+1 (0x1021), valor inicial 0x0000, los datos de entrada se invierten, los datos de salida se invierten, el resultado se aplica XOR con 0x0000;
- CRC-16/CCITT-FALSE: Polinomio x 16+x 12+x 5+1 (0x1021), valor inicial 0xFFFF, los datos de entrada no se invierten, los datos de salida no se invierten, el resultado es XOR con 0x0000;
- CRC-16/XMODEM: Polinomio x 16+x 12+x 5+1 (0x1021), valor inicial 0x0000, los datos de entrada no se invierten, los datos de salida no se invierten, el resultado es XOR con 0x0000;
- CRC-16/X25: Polinomio x 16+x 12+x 5+1 (0x1021), valor inicial 0xFFFF, los datos de entrada se invierten, los datos de salida se invierten, el resultado se aplica XOR con 0xFFFF;
- CRC-16/IBM: Polinomio x 16+x 15+x 2+1 (0x8005), valor inicial 0x0000, los datos de entrada se invierten, los datos de salida se invierten, el resultado se aplica XOR con 0x0000;
- CRC-16/MAXIM: Polinomio x 16+x 15+x 2+1 (0x8005), valor inicial 0x0000, los datos de entrada se invierten, los datos de salida se invierten, el resultado se aplica XOR con 0xFFFF;
- CRC-16/USB: Polinomio x 16+x 15+x 2+1 (0x8005), valor inicial 0xFFFF, los datos de entrada se invierten, los datos de salida se invierten, el resultado se aplica XOR con 0xFFFF;
- CRC-32: Polinomio x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 + x7 +x5 + x4 + x2 + x + 1 (0x04C11DB7), valor inicial 0xFFFFFFFF, los datos de entrada se invierten, los datos de salida se Transferencia invertida, el resultado se aplica XOR con 0xFFFFFFFF;
- CRC-32/BZIP2: Polinomio x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 +x7 + x5 + x4 + x2 + x + 1 (0x04C11DB7), valor inicial 0xFFFFFFFF, los datos de entrada no se invierten, Los datos de salida no se invierten y el resultado se aplica XOR con 0xFFFFFFFF;
- CRC-32/MPEG-2: Polinomio x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8+ x7 + x5 + x4 + x2 + x + 1 (0x04C11DB7), valor inicial 0xFFFFFFFF, los datos de entrada no se invierten , los datos de salida no se invierten y el resultado se aplica XOR con 0x00000000;
- MD5: código de verificación MD5 de 16 bytes;
- BYTES HEXAGONALES FIJOS: Código de verificación de datos fijo, el código de verificación es una constante arbitraria de varios bytes;
El algoritmo de verificación CRC admite tres algoritmos de verificación de ancho: CRC8, CRC16 y CRC32, y puede personalizar los parámetros de verificación, como polinomio, valor inicial, inversión de datos de entrada, inversión de datos de salida y valor XOR del resultado de salida. Modificando los parámetros de CRC, se puede implementar cualquier algoritmo de verificación de CRC.
6. Tabla de comparación de códigos ASCII
ASCII (Código estándar americano para el intercambio de información) es un sistema de codificación informático basado en el alfabeto latino que se utiliza principalmente para mostrar el inglés moderno y otros idiomas de Europa occidental. Hasta ahora se han definido un total de 128 caracteres, incluidos 33 caracteres de control (caracteres que tienen ciertas funciones especiales pero que no se pueden mostrar, es decir, caracteres no imprimibles) y 95 caracteres visualizables (caracteres imprimibles).
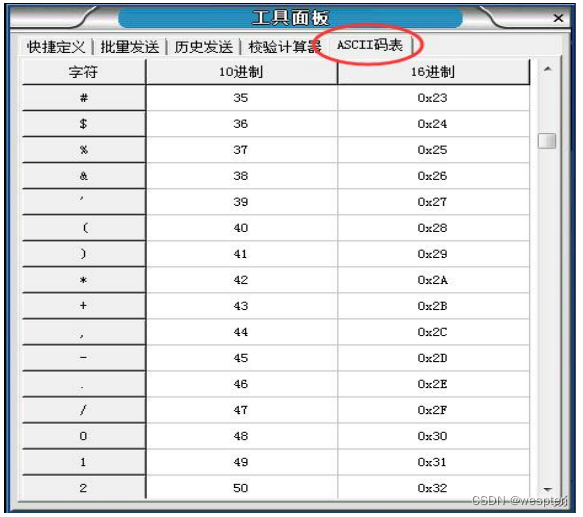
El asistente de depuración proporciona una tabla de comparación ASCII, como se muestra en la figura anterior. Puede ayudar a los usuarios a analizar y procesar datos de caracteres en datos enviados y recibidos durante la depuración de la comunicación. Por ejemplo, después de recibir datos hexadecimales, si necesita convertirlos manualmente en una cadena de código ASCII, puede usar la tabla de códigos ASCII para encontrar los caracteres de destino uno por uno según el valor hexadecimal; para otro ejemplo, al enviar un ASCII cadena que contiene caracteres no imprimibles, puede utilizar el carácter de escape, es decir, barra invertida más letra minúscula x más dos dígitos de datos hexadecimales, y el valor hexadecimal correspondiente al carácter no imprimible se puede encontrar a través de la tabla de códigos ASCII.
7. Parámetros de inicio de la línea de comando
El asistente de depuración se puede iniciar mediante parámetros de línea de comando y opciones de parámetros dadas, y también puede enviar datos del puerto serie directamente a través de la línea de comando. El método para configurar los parámetros de la línea de comando es el siguiente:
uartassist.exe [-p 串口名] [-b 波特率] [-c 校验位] [-w 数据位] [-s 停止位] [-x][-d 数据内容]Descripción de parámetros:
- Nombre del puerto serie: como COM1, COM2, COM3...
- Velocidad de baudios: Complete la velocidad de baudios real utilizada, como 9600, 19200, 115200...
- Dígito de control: tome NINGUNO, IMPAR, PAR, MARCA, ESPACIO
- Bits de datos: tome 5, 6, 7, 8
- Bit de parada: toma 1, 1,5, 2
- Contenido de los datos: Al parámetro -d le sigue el contenido de los datos a enviar, los cuales deben ir entre comillas dobles, si se agrega el parámetro -x significa envío en formato HEX, en caso contrario se enviará en formato ASCII.
Ejemplo 1:
uartassit.exe -p COM6 -b 115200Inicie el asistente de depuración del puerto serie en la línea de comando, abra el puerto serie COM6, configure la velocidad en baudios en 115200 y use los valores predeterminados para otros parámetros no configurados. Tenga en cuenta que al iniciar el asistente de depuración del puerto serie a través de la línea de comando, si se especifica un número de puerto serie, automáticamente intentará abrir el puerto serie de destino.
Ejemplo 2:
uartassit.exe -p COM6 -b 115200 -c NONE -w 8 -s 1 -d "hello" -qLa línea de comando inicia el asistente de depuración para enviar datos de cadena y el software del asistente de depuración se cierra automáticamente después de la ejecución. El parámetro -q indica salir del proceso del asistente de depuración después de la ejecución.
Nota: Al enviar datos a través de los parámetros de la línea de comando del asistente de depuración del puerto serie, dado que solo se pueden transportar parámetros de cadena de texto, los datos binarios no se pueden enviar directamente, pero los datos binarios se pueden enviar mediante caracteres de escape. Por ejemplo, envíe un comando AT con un retorno de carro y un avance de línea al final, correspondiente a los datos -d "AT\r\n"
- Equivalente a -d "AT\x0D\x0A"
- Equivalente a -d "\x41\x54\x0D\x0A"
- Equivalente a -d "\x[41 54 0D 0A]"
- Equivalente a -d "\x[41540D0A]"
- Equivalente a -x -d "41540D0A"
- Equivalente a -x -d "41 54 0D 0A"
Tenga en cuenta que después de usar el parámetro -x, el parámetro -d puede ir seguido directamente de datos hexadecimales sin caracteres de escape.
Comando de ejecución real:
uartassit.exe -p COM6 -b 115200 -q -d "AT\r\n"Equivalente a:
uartassit.exe -p COM6 -b 115200 -q -x -d "41540D0A"Enlace: Baidu Netdisk, ingrese el código de extracción
Código de extracción: dm7u