Flask 기반의 전염병 데이터 관리 및 시각화 시스템
1. 프로젝트 소개
이 프로젝트는 Python + Echarts + Flask + Layui + MySQL을 기반으로 하는 새로운 크라운 전염병 실시간 모니터링 시스템입니다. 관련된 주요 기술에는 원클릭 팬더 가져오기, 관련 데이터 저장 기능에 MySQL 사용, Python을 사용하여 MySQL 데이터베이스와 상호 작용, Flask를 사용하여 웹 프로젝트 구축, Echarts를 기반으로 데이터 시각화 디스플레이 맵 만들기, Layui를 배경 데이터 관리 시각화 프레임워크 pycharm을 개발 플랫폼으로 사용합니다.
2. 프로젝트 기능
① 전국 신형 크라운 폐렴 전염병의 전반적인 상황에 대한 통계 및 표시,
② Echart를 사용하여 전국 신형 크라운 폐렴 전염병 지도를 만들고 각 지역의 확인된 사례 수를 표시하고,
③ Layui 프레임워크를 사용하여 배경을 만듭니다. 데이터 관리 시스템 및 관리자 로그인 기능 생성
④ 전국 신형 크라운 폐렴 누적 유행자 수 추이
⑤ 전국 신형 크라운 폐렴 유행자 수 추세를 그래프로 표시
차트 후베이성 이외의 도시에서 확인된 사례 수 표시 ⑦
관리자는 한 번의 클릭으로 데이터를 가져올 수 있습니다.
3. 프로젝트 기능

4. 업데이트 지침
국가 전염병 정책 자유화로 인해 현재 모든 웹사이트의 전염병 데이터 유지 관리가 중단되었으며 대부분의 전염병 데이터 채널이 폐쇄되었습니다. 따라서 크롤러를 통해 데이터를 얻는 방법은 더 이상 가능하지 않지만 프로젝트에는 학습 및 참조용으로만 사용되는 이전 크롤러 코드가 여전히 남아 있습니다.
동시에 지원 보고서도 버전과 다르며 보고서는 참고용일 뿐입니다.
업데이트 :
- 새 데이터를 추가하고 일부 데이터를 원클릭으로 가져오면 프로젝트를 빠르게 가져올 수 있습니다.
- 전염병 데이터 인터페이스 중단으로 인한 페이지 오류 알림 수정
- 전체 코드 디렉터리 구조 최적화
5. 프로젝트 시연
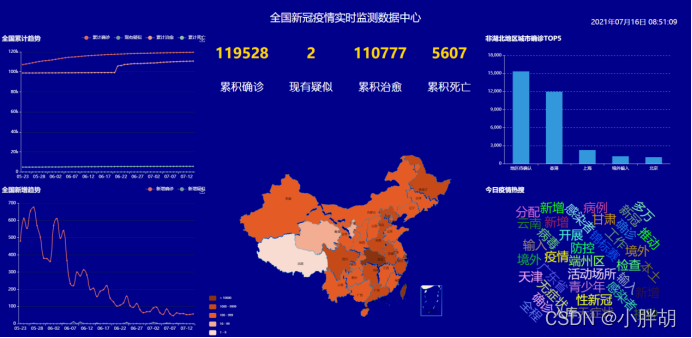
시스템 프런트엔드 데이터 표시 페이지
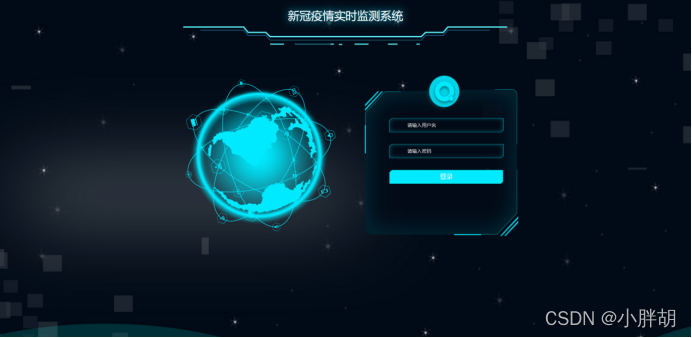
시스템 백그라운드 로그인 인터페이스
시스템 백엔드 홈 페이지(크롤러 시작 및 데이터 대시보드로 이동 포함)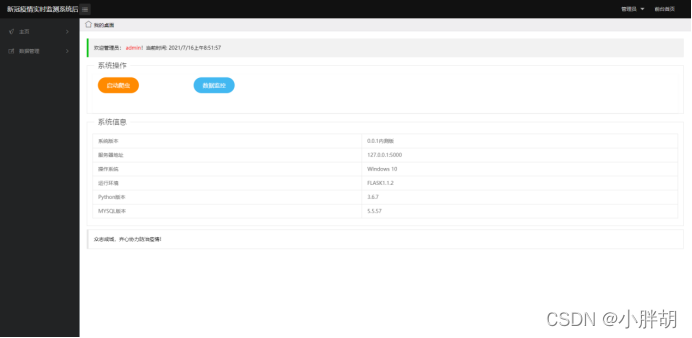
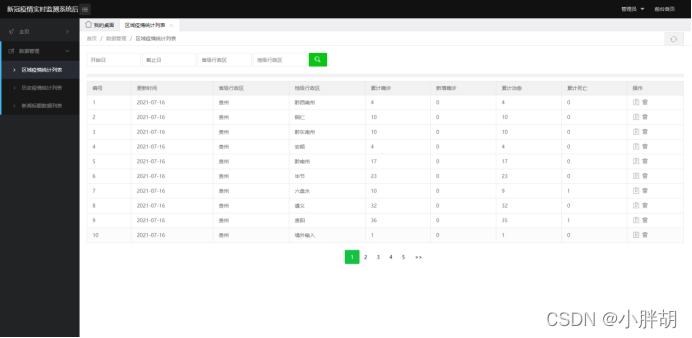
지역별 전염병 통계 목록(삭제, 수정, 조회, 페이징 기능 포함)
지역 전염병 통계 수정 페이지
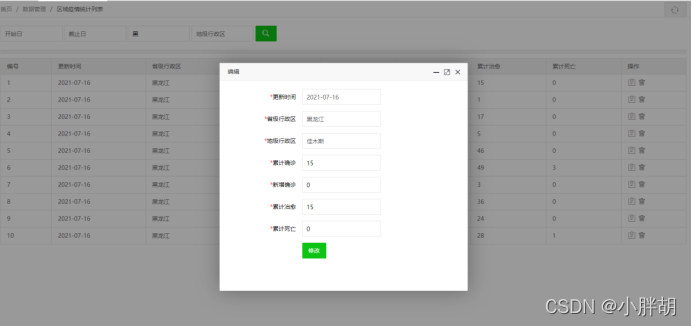
과거 전염병 통계 목록(삭제, 수정, 조회, 페이징 기능 포함)
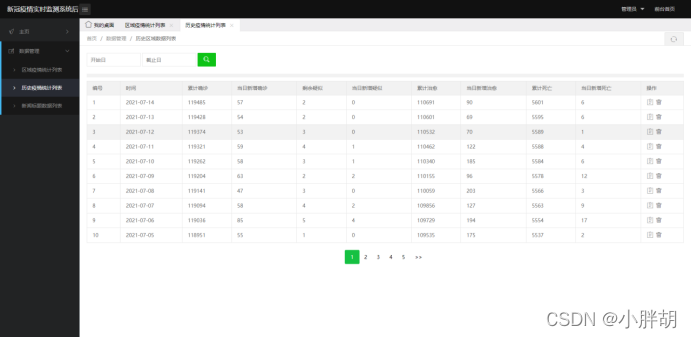
과거 전염병 통계 가져오기

가져오기 템플릿

과거 전염병 통계 수정 페이지
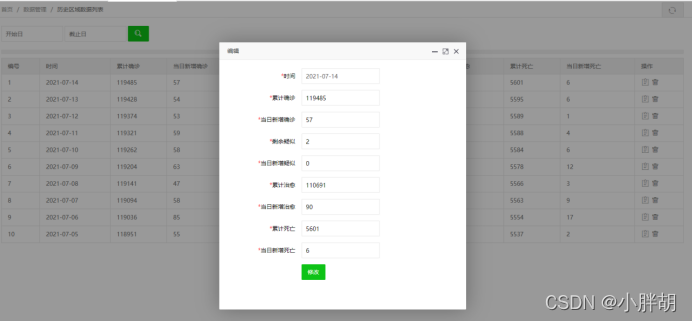
뉴스제목 통계목록(삭제, 수정, 조회, 페이징 기능 포함)
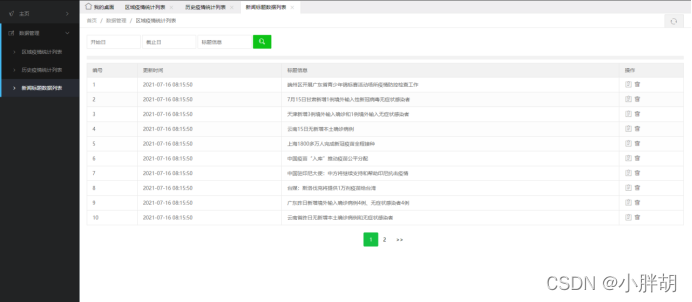
뉴스 제목 수정 페이지
6. 프로젝트 소스 코드
파충류 소스 코드
import time
import datetime
from selenium.webdriver.common.by import By
import pymysql
import json
import traceback
import requests
from selenium.webdriver import Firefox, FirefoxOptions
from bs4 import BeautifulSoup
import re
def get_conn():
# 建立数据库连接
conn = pymysql.connect(host="127.0.0.1", user="root", password="123456", db="cov", charset="utf8")
# 创建游标
cursor = conn.cursor()
return conn, cursor
def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
##################爬虫独立模块######################
# 功能说明:
# ①爬取并插入各个地区历史疫情数据
# ②爬取并插入全国历史疫情统计数据
# ③爬取并插入百度新闻标题最新数据
# 文件说明:
# ①可独立运行呈现结果
# ②调用online方法运行
####################################################
def get_tx_history_data():
url2 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_other"
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'
}
r2 = requests.get(url2, headers)
res2 = json.loads(r2.text)
try:
data_all2 = json.loads(res2["data"])
except:
return [], []
history = {
}
for i in data_all2["chinaDayList"]:
ds = i["y"] + "." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {
"confirm": confirm, "suspect": suspect, "heal": heal, "dead": dead}
for i in data_all2["chinaDayAddList"]:
ds = i["y"] + "." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
if ds in history:
history[ds].update({
"confirm_add": confirm, "suspect_add": suspect, "heal_add": heal, "dead_add": dead})
return history
def get_tx_detail_data():
url1 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'
}
r1 = requests.get(url1, headers)
res1 = json.loads(r1.text)
print(res1["data"])
data_all1 = {
}
try:
data_all1 = json.loads(res1["data"])
except:
return []
details = []
update_time = data_all1["lastUpdateTime"]
data_country = data_all1["areaTree"]
data_province = data_country[0]["children"]
for pro_infos in data_province:
province = pro_infos["name"]
for city_infos in pro_infos["children"]:
city = city_infos["name"]
confirm = city_infos["total"]["confirm"]
confirm_add = city_infos["today"]["confirm"]
heal = city_infos["total"]["heal"]
dead = city_infos["total"]["dead"]
details.append([update_time, province, city, confirm, confirm_add, heal, dead])
return details
def get_dx_detail_data():
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
# 省级正则表达式
provinceName_re = re.compile(r'"provinceName":"(.*?)",')
provinceShortName_re = re.compile(r'"provinceShortName":"(.*?)",')
currentConfirmedCount_re = re.compile(r'"currentConfirmedCount":(.*?),')
confirmedCount_re = re.compile(r'"confirmedCount":(.*?),')
suspectedCount_re = re.compile(r'"suspectedCount":(.*?),')
curedCount_re = re.compile(r'"curedCount":(.*?),')
deadCount_re = re.compile(r'"deadCount":(.*?),')
cities_re = re.compile(r'"cities":\[\{(.*?)\}\]')
# 爬虫爬取数据
datas = requests.get(url, headers=headers)
datas.encoding = 'utf-8'
soup = BeautifulSoup(datas.text, 'lxml')
data = soup.find_all('script', {
'id': 'getAreaStat'}) # 网页检查定位
data = str(data)
data_str = data[54:-23]
# print(data_str)
# 替换字符串内容,避免重复查找
citiess = re.sub(cities_re, '8888', data_str)
# 查找省级数据
provinceShortNames = re.findall(provinceShortName_re, citiess)
currentConfirmedCounts = re.findall(currentConfirmedCount_re, citiess)
confirmedCounts = re.findall(confirmedCount_re, citiess)
suspectedCounts = re.findall(suspectedCount_re, citiess)
curedCounts = re.findall(curedCount_re, citiess)
deadCounts = re.findall(deadCount_re, citiess)
details = []
current_date = datetime.datetime.now().strftime('%Y-%m-%d')
for index, name in enumerate(provinceShortNames):
# 备用历史区域获取接口,只获取省份的累计确诊、现有确诊、累计治愈、累计死亡
details.append([current_date, name, name, confirmedCounts[index], currentConfirmedCounts[index], curedCounts[index], deadCounts[index]])
return details
# 插入地区疫情历史数据
# 插入全国疫情历史数据
def update_history():
conn, cursor = get_conn()
try:
# li = get_tx_detail_data() # 1代表最新数据
li = get_dx_detail_data() # 1代表最新数据
if len(li) == 0:
print(f"[WARN] {
time.asctime()} 接口暂时异常,数据未获取到或解析地区历史疫数据异常...")
else:
sql = "insert into details(update_time,province,city,confirm,confirm_add,heal,dead) values(%s,%s,%s,%s,%s,%s,%s)"
sql_query = 'select %s=(select update_time from details order by id desc limit 1)'
# 对比当前最大时间戳
cursor.execute(sql_query, li[0][0])
if not cursor.fetchone()[0]:
print(f"[INFO] {
time.asctime()} 地区历史疫情爬虫已启动,正在获取数据....")
for item in li:
print(f"[INFO] {
time.asctime()} 已获取地区历史疫情数据:", item)
cursor.execute(sql, item)
conn.commit()
print(f"[INFO] {
time.asctime()} 地区历史疫情爬虫已完成,更新到最新数据成功...")
else:
print(f"[WARN] {
time.asctime()}地区历史疫情爬虫已启动,已是最新数据...")
except:
traceback.print_exc()
try:
dic = get_tx_history_data() # 1代表最新数据
if len(dic) == 0:
print(f"[WARN] {
time.asctime()} 接口暂时异常,数据未获取到或解析全国历史疫情数据异常...")
print(f"[INFO] {
time.asctime()} 全国历史疫情爬虫已启动,正在获取数据....")
conn, cursor = get_conn()
sql = "insert into history values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm from history where ds=%s"
for k, v in dic.items():
if not cursor.execute(sql_query, k):
print(f"[INFO] {
time.asctime()} 已获取全国历史疫情:",
[k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
cursor.execute(sql, [k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
conn.commit()
print(f"[INFO] {
time.asctime()} 全国历史疫情爬虫已完成,更新到最新数据成功...")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
# 爬取腾讯健康热搜数据
def get_tenxun_hot():
option = FirefoxOptions()
option.add_argument("--headless") # 隐藏游览器
option.add_argument("--no--sandbox")
browser = Firefox(options=option)
url = "https://feiyan.wecity.qq.com/wuhan/dist/index.html#/?tab=shishitongbao"
browser.get(url)
time.sleep(3)
c = browser.find_elements(By.XPATH,"//*[@id='app']/div/div[1]/div[3]/div[3]/div[2]/div/div[2]/div[1]/div/div[2]")
context = [i.text for i in c]
browser.close()
return context
def is_number(s):
try: # 如果能运行float(s)语句,返回True(字符串s是浮点数)
float(s)
return True
except ValueError: # ValueError为Python的一种标准异常,表示"传入无效的参数"
pass # 如果引发了ValueError这种异常,不做任何事情(pass:不做任何事情,一般用做占位语句)
try:
import unicodedata # 处理ASCii码的包
unicodedata.numeric(s) # 把一个表示数字的字符串转换为浮点数返回的函数
return True
except (TypeError, ValueError):
pass
return False
# 插入百度热搜实时数据
def update_hotsearch():
cursor = None
conn = None
try:
print(f"[INFO] {
time.asctime()} 新闻资讯爬虫已启动,正在获取数据...")
context = get_tenxun_hot()
conn, cursor = get_conn()
sql = "insert into hotsearch(dt,content) values(%s,%s)"
ts = time.strftime("%Y-%m-%d %X")
for i in context:
print(f"[INFO] {
time.asctime()} 已获取历史疫情:", [ts, i])
cursor.execute(sql, (ts, i))
conn.commit()
print(f"[INFO] {
time.asctime()} 新闻资讯爬虫已完成,更新到最新数据成功...")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
def online():
update_history()
update_hotsearch()
return 200
if __name__ == "__main__":
update_history()
update_hotsearch()
7. 소스코드 획득
이 프로젝트는 전염병이 끝나기 때문에 데이터는 오래된 데이터를 사용합니다! 크롤러를 통해 데이터를 얻을 수 없습니다!
소스 코드, 설치 튜토리얼 문서, 프로젝트 소개 문서 및 기타 관련 문서가 Yunyuan Practical Combat 공식 웹사이트에 업로드되었으며, 아래 공식 웹사이트를 통해 프로젝트를 얻을 수 있습니다!