Автор: Финансовая команда SmartX, глубоко вовлеченная в отрасль.
фон
В предыдущей статье « Независимые исследования и разработки распределенного блочного хранилища ZBS|Архитектура » мы кратко представили архитектурные принципы распределенного блочного хранилища SmartX ZBS. Далее мы предоставим читателям углубленный анализ одной из наиболее важных технологий хранения данных ZBS — «RDMA».
В настоящее время ZBS использует технологию RDMA на двух уровнях, а именно: сеть доступа к хранилищу и внутренняя сеть синхронизации данных хранилища. Чтобы читателям было легче понять и провести более целенаправленное сравнение производительности СХД, две независимые статьи представлены отдельно. В этом выпуске мы сосредоточимся на технологии прямого доступа к удаленной памяти RDMA и проведем подробное расширение в связи с синхронизацией данных внутренней памяти ZBS (ZBS поддерживает возможности RDMA и первой реализовала синхронизацию данных внутренней памяти).
Внутренняя синхронизация данных хранилища ZBS
Одним из наиболее важных различий между распределенными системами хранения и централизованным хранилищем является реализация архитектуры. Чтобы обеспечить согласованность хранения и надежность данных, распределенная архитектура должна полагаться на сеть для синхронизации данных. Вот пример кластера хранения данных ZBS, состоящего из 3 узлов (A/B/C).Данные защищены двумя копиями (данные хранятся в двух копиях, размещенных на разных физических узлах).Предположим, что данные хранятся в узел A и узел соответственно.На B, когда данные изменяются, распределенное хранилище ZBS должно завершить изменение данных на узлах A и B, а затем вернуть подтверждение. В этом процессе узлы A и B синхронизируют изменения данных, а используемая сеть является сетью хранения.
Я думаю, что благодаря примерам читатели поняли, что эффективность синхронизации данных оказывает большое влияние на производительность распределенного хранилища. Это одно из важных направлений оптимизации производительности распределенного хранилища, которому также посвящена данная статья.
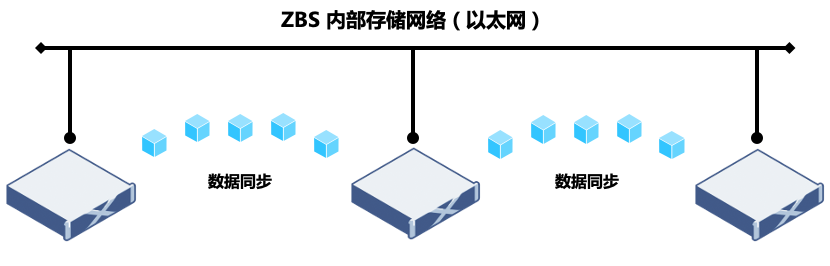
Рис. 1. Сеть синхронизации данных распределенного хранилища.
В соответствии с текущими требованиями к обычным рабочим нагрузкам сети хранения данных ZBS обычно настраиваются с использованием коммутаторов 10GbE Ethernet и серверных сетевых карт, а в качестве сетевого протокола передачи используют стандарт TCP/IP. Однако для бизнес-задач с высокой пропускной способностью и низкой задержкой такая конфигурация, очевидно, станет узким местом производительности при синхронизации данных внутреннего хранилища. В то же время, чтобы воспользоваться преимуществами более высокой производительности ввода-вывода новых высокоскоростных носителей данных (таких как диски NVMe), использование технологии RDMA в сочетании с сетевыми спецификациями 25GbE или выше является лучшим выбором для обеспечения более высокой емкости хранилища. требования к производительности бизнес-конца.
TCP/IP
Распределенное хранилище, реализованное посредством определения программного обеспечения и построенное на универсальном стандартном оборудовании, является одной из его важных особенностей, отличающих его от традиционного хранилища. В течение многих лет ZBS использовала стек сетевых протоколов TCP/IP в качестве метода внутренней связи хранилища. Преимущество состоит в том, что он имеет максимальную совместимость с существующим Ethernet и отвечает требованиям бизнес-задач подавляющего большинства клиентов. Однако сетевая связь TCP/IP постепенно неспособна адаптироваться к бизнес-требованиям высокопроизводительных вычислений.Ее основными ограничениями являются следующие два момента:
Задержка, вызванная обработкой стека протоколов TCP/IP.
Когда стек протоколов TCP получает/отправляет пакеты данных, ядру системы необходимо выполнить несколько переключений контекста, что, несомненно, увеличит задержку передачи. Кроме того, во время процесса передачи данных требуется несколько копий данных, а для обработки инкапсуляции протокола используется ЦП, что приводит к задержке в десятки микросекунд только для обработки стека протоколов.
Обработка стека протоколов TCP приводит к увеличению потребления ресурсов ЦП на сервере.
Помимо проблем с задержкой, сети TCP/IP требуют, чтобы центральный процессор несколько раз участвовал в копировании памяти стека протоколов. Чем больше масштаб распределенной сети хранения, тем выше требования к пропускной способности сети и тем больше нагрузка на процессор при отправке и получении данных, что приводит к более высокому потреблению ресурсов ЦП (что очень недружелюбно для гиперконвергентной архитектуры). .

Рисунок 2. Связь через сокет TCP/IP.
РДМА
RDMA — это аббревиатура удаленного прямого доступа к памяти. DMA относится к технологии непосредственного чтения и записи памяти устройством (без использования процессора).

Рисунок 3: Прямой доступ к памяти
RDMA 技术的出现,为降低 TCP/IP 网络传输时延和 CPU 资源消耗,提供了一种全新且高效的解决思路。通过直接内存访问技术,数据从一个系统快速移动到远程系统的内存中,无需经过内核网络协议栈,不需要经过中央处理器耗时的处理,最终达到高带宽、低时延和低 CPU 资源占用的效果。
目前实现 RDMA 的方案有如下 3 种:

图 4:RDMA 实现方案 (图片来源:SNIA)
InfiniBand(IB)是一种提供了 RDMA 功能的全栈架构,包含了编程接口、二到四层协议、网卡接口和交换机等一整套 RDMA 解决方案。InfiniBand 的编程接口也是 RDMA 编程接口的事实标准,RoCE 和 iWARP 都使用 InfiniBand 的接口进行编程。
RoCE(RDMA over Converged Ethernet)和 iWARP(常被解释为 Internet Wide Area RDMA Protocol,这并不准确,RDMA Consortium 专门做出解释 iWARP 并不是缩写),两个技术都是将 InfiniBand 的编程接口封装在以太网进行传输的方案实现。RoCE 分为两个版本,RoCEv1 包含了网络层和传输层的协议,所以不支持路由(更像是过渡协议,应用并不多);RoCEv2 基于 UDP/IP 协议,具有可路由能力。iWARP 是构建于 TCP 协议之上的。
跟 RoCE 协议继承自 Infiniband 不同,iWARP 本身不是直接从 Infiniband 发展而来的。Infiniband 和 RoCE 协议都是基于“Infiniband Architecture Specification”,也就是常说的“IB 规范”。而 iWARP 是自成一派,遵循着一套 IETF 设计的协议标准。虽然遵循着不同的标准,但是 iWARP 的设计思想受到了很多 Infiniband 的影响,并且目前使用同一套编程接口(Verbs*)。这三种协议在概念层面并没有差异。
* Verb 是 RDMA 语境中对网络适配器功能的一个抽象,每个 Verb 是一个函数,代表了一个 RDMA 的功能,实现发送或接收数据、创建或删除 RDMA 对象等动作。
RDMA 需要设备厂商(网卡和交换机)的生态支持,主流网络厂家的协议支持能力如下:

Infiniband 从协议到软硬件封闭,其性能虽然最优,但成本也最高,因为需要更换全套设备,包括网卡、光缆和交换机等。这对于通用标准化的分布式存储场景并不友好,在 ZBS 选择时首先被排除掉。
对于 RoCE 和 iWARP 选择上,虽然 RoCE 在数据重传和拥塞控制上受到 UDP 协议自身的限制,需要无损网络的环境支持,但在综合生态、协议效率和复杂度等多方面因素评估下,SmartX 更加看好 RoCE 未来的发展,在极致的性能诉求下,RoCE 也会比 iWARP 具有更强的潜力。当前 ZBS 存储内部数据同步网络采用的是 RoCEv2 的 RDMA 技术路线。
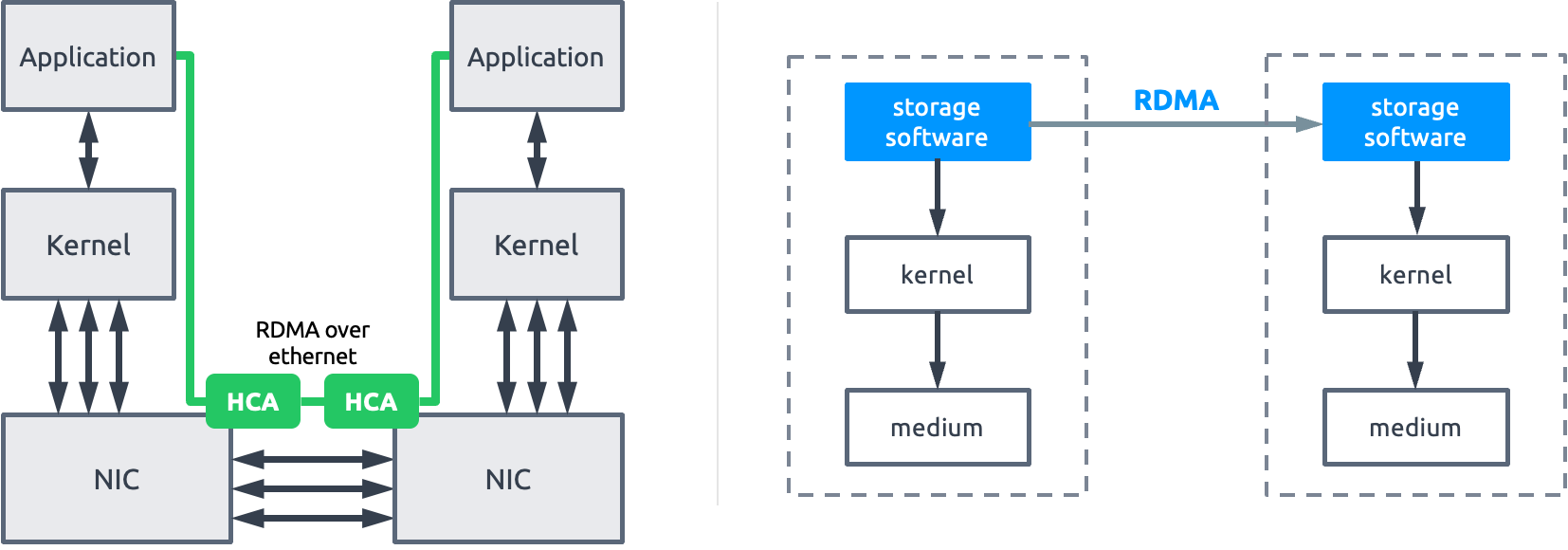
图 5:ZBS RDMA RoCEv2
性能验证数据
为了使测试数据有更直观的对比性(RDMA vs TCP/IP),将控制测试环境严格一致性,包括硬件配置、系统版本以及相关软件版本,唯一变量仅为开启/关闭存储内部数据同步 RDMA 能力,基于此,测试集群在两种状态下的性能表现。
环境信息
存储集群,由 3 节点组成,安装 SMTX OS 5.0,分层存储结构,所有存储节点的硬件配置相同,节点环境信息如下:

性能数据
在相同的测试环境和测试方法下,分别使用 RDMA 和 TCP/IP 协议进行性能验证。为了更好地观测读写 I/O 跨节点的性能表现(ZBS 分布式存储默认具有数据本地化特点,对读 I/O 模型有明显优化作用),本次测试基于 Data Channel 平面(ZBS 内部的 RPC 通道,用于节点间收发数请求)。本测试仅用于评估网络性能差异,I/O 读写操作并不落盘。
性能对比数据

测试结论
通过以上基准测试数据,可以看出,相同软硬件环境以及测试方法下,使用 RDMA 作为存储内部数据同步协议,可以取得更优的 I/O 性能输出。其表现为更高的 4K 随机 IOPS 和更低的延时,以及在 256K 顺序读写场景,充分释放网络带宽(25GbE)条件,提供更高的数据吞吐表现。
总结
通过本篇文章的理论介绍和客观的性能测试数据,希望读者能够对于 RDMA 协议有了更加全面的了解。RDMA 对于数据跨网络通信性能的优化,已经应用于很多企业场景中,分布式存储作为其中一个重要场景,借助 RDMA 实现了存储内部数据同步效率的提升,进而为更高工作负载需求的业务应用提供了更好的存储性能表现。
参考文章:
1. RDMA over Converged Ethernet. Wikipedia.
https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet
2. How Ethernet RDMA Protocols iWARP and RoCE Support NVMe over Fabrics.
https://www.snia.org/sites/default/files/ESF/How_Ethernet_RDMA_Protocols_Support_NVMe_over_Fabrics_Final.pdf
点击了解 SMTX ZBS 更多产品特性与技术实现亮点。