
Actualmente, todas las industrias clave están acelerando la transformación de Xinchuang y están ingresando gradualmente a la "zona de aguas profundas" desde el negocio de prueba inicial y el negocio de producción de vanguardia hasta tratar de soportar cargas de trabajo importantes. La mayoría de los usuarios no están muy familiarizados con el rendimiento y las características de la solución ecológica de Xinchuang, e inevitablemente tienen preguntas e inquietudes sobre la transformación de Xinchuang del negocio principal: ¿Cuál es el nivel de rendimiento de la base de datos de Xinchuang y el hardware de Xinchuang? ¿Cómo funciona en una plataforma virtualizada o hiperconvergente? ¿Hay margen para la optimización del software y del hardware?
Con base en los requisitos anteriores, el centro de soluciones SmartX realizó pruebas de rendimiento en el producto de base de datos Xinchuang (Dameng DM8) en la plataforma hiperconvergente Xinchuang SmartX (servidor Xinchuang basado en chips Kunpeng) y utilizó la exclusiva tecnología de aceleración Boost para ajustar la base de datos. .excelente. Los resultados de la prueba muestran que, combinado con el ajuste de parámetros de la base de datos, la base de datos Dameng respaldada por la plataforma hiperconvergente Xinchuang SmartX en modo Boost ha logrado una mejora de rendimiento de casi el 100%.
Contenido clave
● Esta prueba utiliza BenchmarkSQL para realizar pruebas basadas en el punto de referencia TPC-C y compara la base de datos Dameng DM8 en servidores bare metal (basados en SATA SSD y NVMe SSD respectivamente), la plataforma hiperconvergente Xinchuang SmartX sin optimización del modo Boost y Rendimiento optimizado en plataformas hiperconvergentes.
● Los métodos de optimización en el modo Boost incluyen: optimización de los parámetros del BIOS, habilitación del modo Boost y optimización de la red RDMA, optimización de la configuración de la máquina virtual (incluida la habilitación de la función exclusiva de la CPU y el ajuste de las funciones multinúcleo de la CPU de almacenamiento en disco virtual para la optimización de la red), así como como optimización relacionada con la base de datos.
● Sin optimización, el rendimiento de la base de datos Dameng hiperconvergente SmartX basada en la arquitectura Xinchuang es el 80% del de un servidor bare metal (basado en SSD SATA). Después de ajustar el modo Boost, el rendimiento de la base de datos casi se duplica, alcanzando 1,77 veces el de un servidor básico (con SSD SATA como medio) y el 88 % del de un disco básico NVMe.
1 entorno de prueba
1.1 Base de datos Dameng DM8
DM8 es una nueva generación de bases de datos de desarrollo propio lanzada por Dameng Company sobre la base de resumir la experiencia de desarrollo y aplicación de los productos de la serie DM y adherirse a los conceptos de innovación abierta, simplicidad y practicidad. DM8 absorbe y aprovecha las ventajas de las ideas técnicas avanzadas actuales y los productos de bases de datos convencionales, integra las ventajas de la computación elástica distribuida y la computación en la nube, y realiza mejoras a gran escala en flexibilidad, facilidad de uso, confiabilidad, alta seguridad y otros aspectos. La arquitectura centralizada puede satisfacer completamente las necesidades de diferentes escenarios, admitir el procesamiento de transacciones concurrentes a gran escala y el procesamiento de negocios híbrido de análisis de transacciones, y asignar dinámicamente recursos informáticos para lograr una utilización más refinada de los recursos y una menor inversión de costos.
1.2 Hardware Xinchuang (chip Kunpeng)
El servidor Xinchuang utilizado en esta prueba es KunTai R722.
El servidor de prueba está equipado con una CPU de la serie Kunpeng 920, que actualmente es el procesador basado en ARM líder de la industria. El procesador utiliza un proceso de fabricación de 7 nm, tiene una licencia basada en la arquitectura ARM y está diseñado de forma independiente por Huawei.
Una característica obvia del Kunpeng 920 5250 es que tiene muchos núcleos de CPU: una CPU de un solo canal tiene 48 núcleos y una CPU de 2 canales tiene un total de 96 núcleos (las CPU de la serie Intel Xeon más utilizadas tienen alrededor de 20 núcleos). por canal). Por tanto, uno de los puntos clave de la optimización posterior del rendimiento es cómo aprovechar mejor las ventajas del multinúcleo.
La configuración detallada del servidor es la siguiente:

1.3 Infraestructura de nube Xinchuang hiperconvergente SmartX
Con el software hiperconvergente SMTX OS como núcleo, Zhilinghaina SmartX proporciona una cartera de productos de infraestructura de nube Xinchuang hiperconvergente de desarrollo propio, desacoplada y lista para producción, que ha ayudado a muchos usuarios de la industria a construir bases de nube Xinchuang livianas. SMTX OS es el software central para construir una plataforma hiperconvergente. Tiene virtualización de servidor nativo ELF y almacenamiento en bloques distribuido ZBS incorporado. Puede equiparse con funciones avanzadas como activo-activo, replicación asincrónica, copia de seguridad y recuperación, red y seguridad. Utilizando servidores comerciales, puede crear rápidamente un grupo de recursos en la nube potente y ágil. Para una comprensión más profunda, lea: Un artículo para comprender la infraestructura de nube hiperconvergente de Xinchuang .

El modo Boost es el modo de alto rendimiento del sistema operativo SMTX. Este modo utiliza tecnología de uso compartido de memoria para acortar la ruta de E/S de la máquina virtual, mejorando así el rendimiento de la máquina virtual y reduciendo la latencia de acceso a E/S. El modo Boost suele estar habilitado con la red RDMA para maximizar el rendimiento del almacenamiento. Si desea obtener más información sobre el principio de implementación del modo Boost, lea: Cómo el usuario SPDK Vhost ayuda a la arquitectura hiperconvergente a mejorar el rendimiento del almacenamiento de E/S , o escanee el código QR para descargar el libro electrónico "SmartX Hyper-converged Colección de análisis de características y principios tecnológicos (incluida la comparación de VMware)" )》 .

2 método de prueba
Esta prueba utiliza BenchmarkSQL para realizar la prueba basada en el punto de referencia TPC-C y compara la base de datos Dameng DM8 en servidores bare metal (basados en SATA SSD y NVMe SSD respectivamente), la plataforma Xinchuang hiperconvergente SmartX sin optimización del modo Boost e hiperconvergente optimizada. rendimiento de convergencia en la plataforma.
3 Estándar de prueba y referencia
3.1 Prueba TPC-C
TPC-C es un punto de referencia de rendimiento de procesamiento de transacciones reconocido en la industria. Es uno de los puntos de referencia estándar publicados por el Transaction Processing Performance Council (TPC) para probar el rendimiento de los sistemas de procesamiento de transacciones en línea (OLTP). La prueba TPC-C se basa en una aplicación virtual de procesamiento de pedidos en línea, que incluye una serie de operaciones transaccionales, como pedidos de clientes, gestión de inventario, procesamiento de entregas, etc. Los resultados de la prueba TPC-C se miden en transacciones por minuto (TPM).
BenchmarkSQL es una herramienta que puede ejecutar pruebas comparativas utilizando la especificación de prueba TPC-C. Específicamente, BenchmarkSQL puede utilizar operaciones de transacción y estructuras de datos definidas en la especificación de prueba TPC-C para simular un entorno de prueba TPC-C y realizar pruebas de rendimiento en el sistema de base de datos. Por lo tanto, BenchmarkSQL puede considerarse como una implementación de la prueba TPC-C.
Esta prueba utiliza BenchmarkSQL para realizar la prueba basada en el punto de referencia TPC-C para evaluar de manera más objetiva el rendimiento de la base de datos en la plataforma hiperconvergente Xinchuang.
Las versiones de software utilizadas en esta prueba son las siguientes:

3.2 Referencia de prueba
Es posible que los usuarios hayan conocido los datos de prueba TPC-C de algunas bases de datos en el pasado, pero la mayoría de estos datos se basan en entornos de servidor de arquitectura x86 y es posible que no necesariamente comprendan bien el rendimiento TPC-C de los chips Xinchuang. Teniendo esto en cuenta, primero implementamos directamente el software de base de datos Dameng (implementación de la máquina física) en el servidor básico (basado en el chip Kunpeng) y luego realizamos un conjunto de pruebas TPC-C como referencia para comparar con el rendimiento de el posterior hiperconvergente SmartX.
3.2.1 Rendimiento bajo diferentes medios de almacenamiento
Dado que la base de datos es sensible al rendimiento de E/S del disco, en el escenario de prueba utilizamos dos tipos diferentes de SSD como medios de almacenamiento y los probamos por separado. Primero, se realizó la prueba de esfuerzo de E/S (lectura y escritura aleatoria de 8k) en el SSD a través de la herramienta de prueba FIO como rendimiento de referencia de E/S de los dos SSD. Los resultados son los siguientes:


Luego, ejecutamos la prueba TPC-C (100 almacenes, 200 terminales) de la base de datos Dameng en los dos SSD respectivamente, y los resultados son los siguientes:
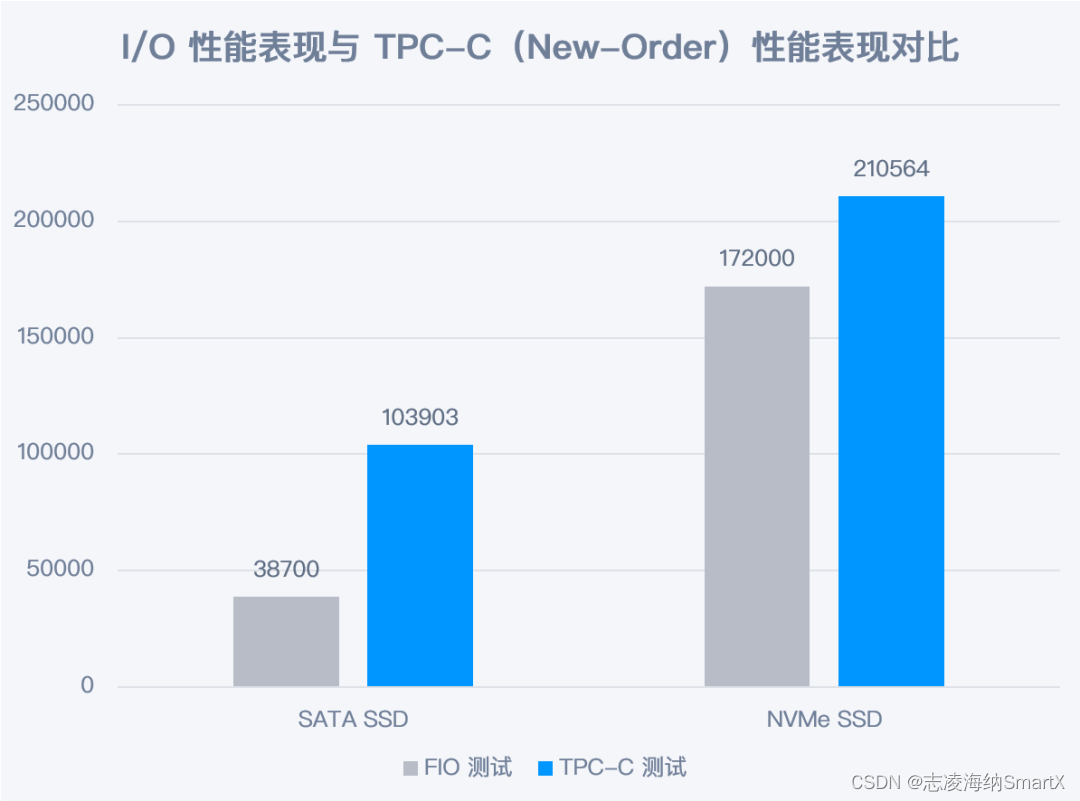

*Nota: En la prueba TPC-C, el valor de NewOrder se toma como resultado de la prueba, y lo mismo ocurre con los resultados posteriores, que no se describirán nuevamente.
Los dos conjuntos de datos se prueban en el mismo servidor y se pueden sacar las siguientes conclusiones: Los resultados de las pruebas TPC-C aumentan con el crecimiento de la capacidad de E/S de almacenamiento, pero la relación entre los dos no es completamente proporcional (la relación I/O La capacidad de escritura de O de NVMe SSD O mejora en un 340% en comparación con SATA SSD, pero TPC-C solo mejora en aproximadamente un 102%).
3.2.2 Impacto del grupo NUMA de CPU en el rendimiento
Las pruebas se dividen en dos grupos:
- Grupo A: el programa de base de datos está vinculado a 2 grupos NUMA (48 núcleos) de la misma CPU mediante el comando numactl.
- Grupo B: la base de datos no está vinculada a la CPU y utiliza todos los núcleos de la CPU (96 núcleos) en el servidor.
Los resultados de la prueba son los siguientes:


Los resultados de la prueba son un poco inesperados: el grupo A (48 núcleos) funciona mejor que el grupo B (96 núcleos). En general, el impacto de más núcleos de CPU en el rendimiento de la base de datos debería ser, en teoría, positivo. Pero hay dos factores en esta prueba que influyen en los resultados.
- El número máximo de parámetros de subprocesos de trabajo admitidos por la base de datos Dameng es 64 (el requisito oficial es que el número de subprocesos de trabajo sea el mismo que el número de núcleos de CPU), lo que no puede utilizar completamente los 96 núcleos de CPU.
- La base de datos funciona en grupos NUMA entre CPU y la eficiencia del acceso a la memoria disminuye.
Teniendo en cuenta las características de la base de datos y el impacto de NUMA, la configuración de la máquina virtual en pruebas posteriores de plataforma hiperconvergente adopta una configuración de 48 vCPU (y asegurando que esté en la misma CPU) para las pruebas.
4 proceso de prueba
4.1 Condiciones de prueba
4.1.1 Configuración de recursos de la máquina virtual
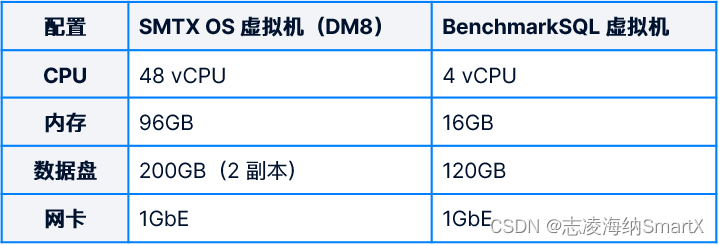

4.1.2 Equipo de prueba TPC-C
- Ajuste el valor del terminal para verificar el rendimiento de la base de datos bajo diferentes presiones de acceso simultáneo. Se realizaron en total entre 100 y 800 pruebas en 8 conjuntos de terminales.
- Ajuste los valores de los almacenes para verificar el rendimiento de la base de datos en diferentes tamaños de conjuntos de datos. Se realizaron un total de 3 series de pruebas de almacén de 100 a 300. Cada grupo de almacenes realiza un total de 24 grupos de pruebas en función del diferente número de terminales mencionado anteriormente.
4.2 Prueba 1: Rendimiento de la base de datos Dameng en ejecución hiperconvergente SmartX sin ninguna optimización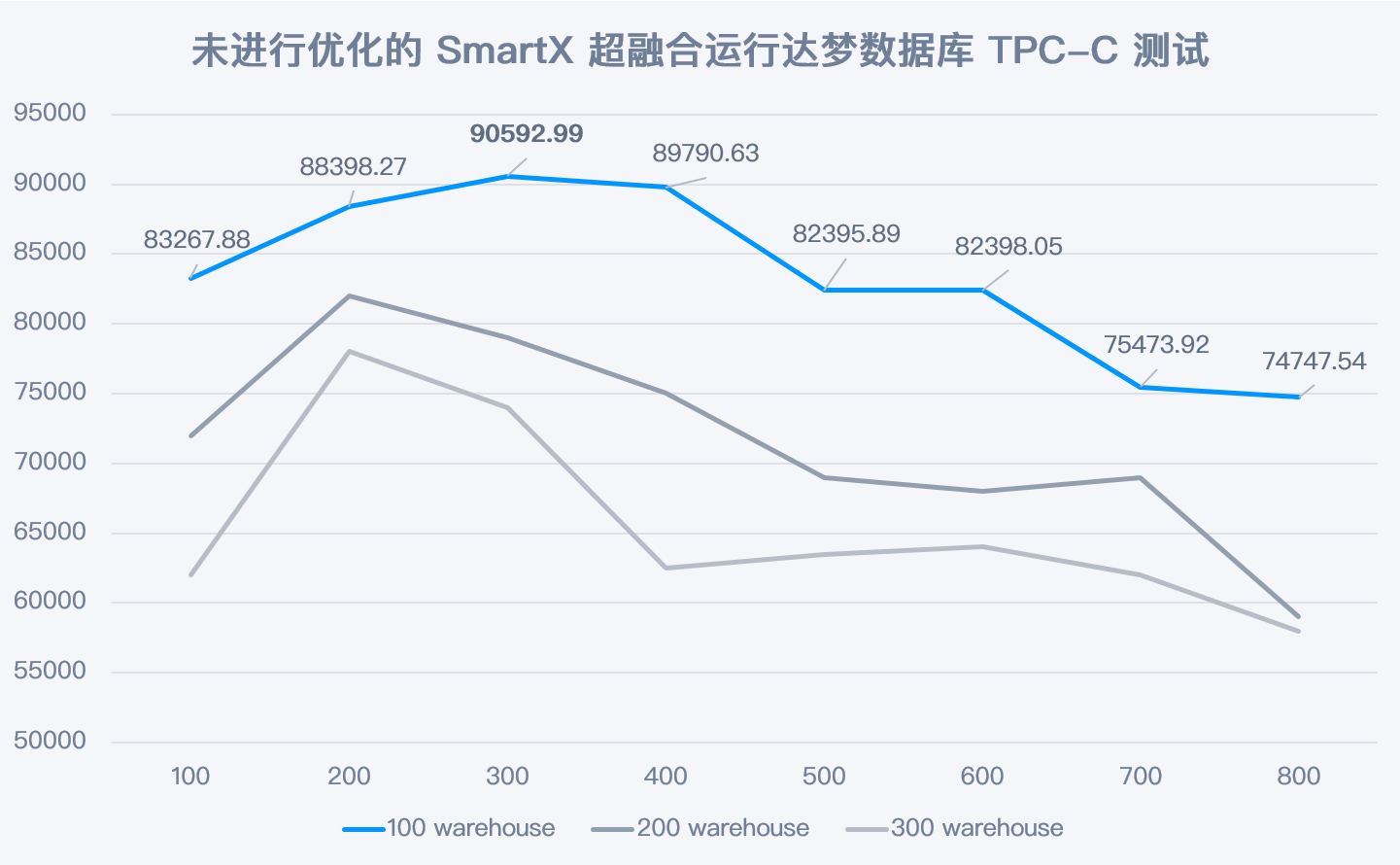
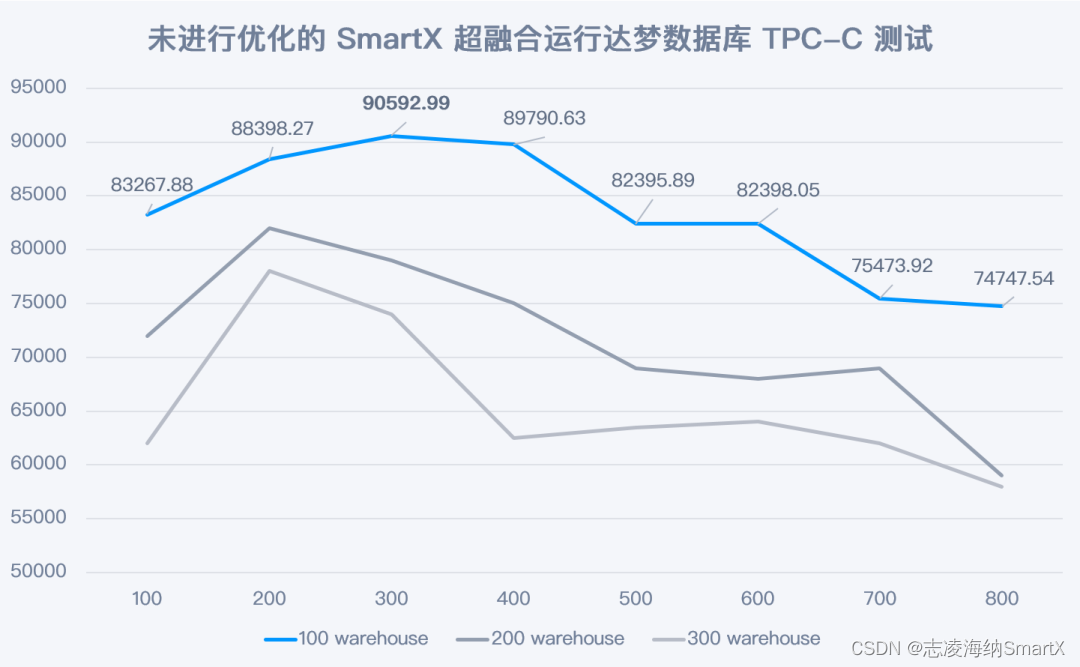
El valor máximo de TPC-C NewOrder se genera en 100 almacenes y 300 terminales, y se completan 90592 nuevos pedidos (NewOrder) cada minuto. Sin ninguna optimización, el rendimiento de la base de datos no es ideal y representa el 80% del rendimiento de implementación de un servidor básico (basado en SSD SATA) .
4.3 Prueba 2: Rendimiento de la base de datos Dameng en ejecución hiperconvergente SmartX después del ajuste en modo Boost
4.3.1 Métodos de optimización en el modo SMTX OS Boost
A continuación se mostrará cómo mejorar el rendimiento de la prueba Damon Database TPC-C en el modo SMTX OS Boost.
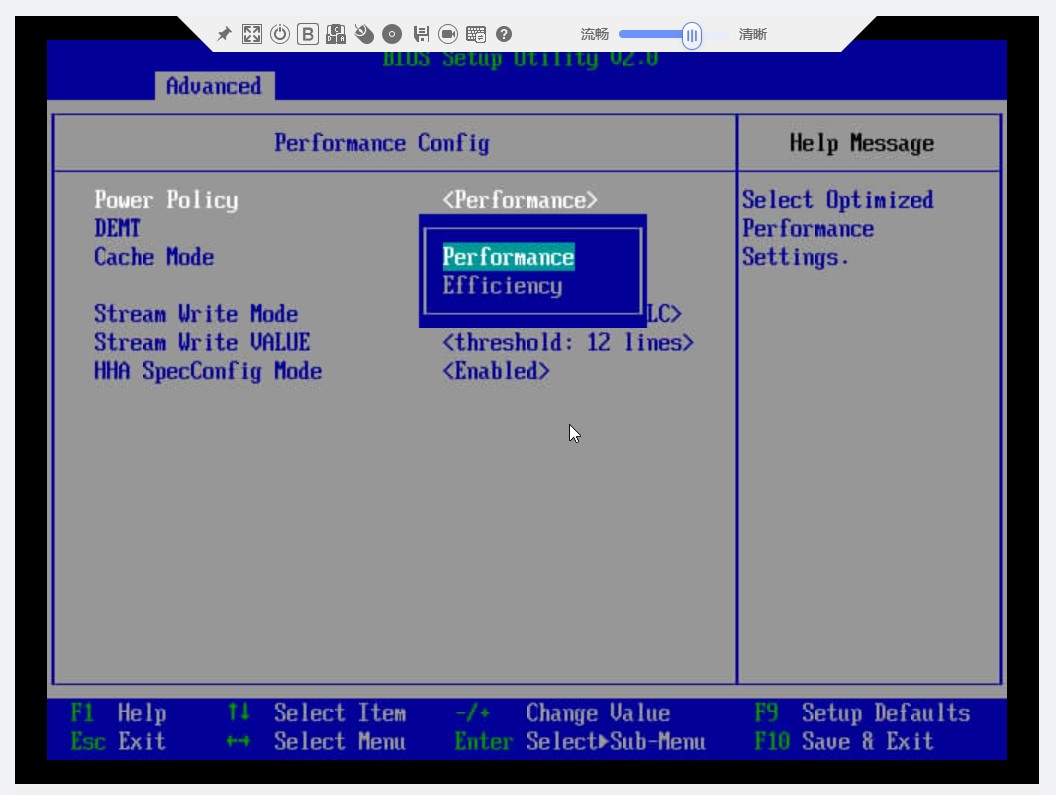
1) optimización de parámetros de BIOS
Antes de activar el modo Boost, es necesario cambiar la política de energía del "Modo de ahorro de energía" al "Modo de rendimiento" en el BIOS del servidor para garantizar que la energía del servidor tenga un rendimiento óptimo.
2) Habilite el modo Boost y la optimización de la red RDMA:
- En el primer paso de implementar un clúster de sistema operativo SMTX: la fase de configuración del clúster, seleccione la casilla de verificación Habilitar modo Boost .
- En el quinto paso de la implementación del clúster del sistema operativo SMTX: configuración de la red, al crear un conmutador distribuido virtual para la red de almacenamiento, haga clic en el botón Habilitar RDMA para habilitar la función RDMA del clúster.
3) Optimización de la configuración de la máquina virtual.
- Habilitar la función exclusiva de CPU
Al crear una máquina virtual de base de datos, verifique la función exclusiva de la CPU. El fondo realizará automáticamente el enlace NUMA en la vCPU de la máquina virtual, para que la máquina virtual pueda obtener un mejor rendimiento.

- La política de almacenamiento en disco virtual se ajusta al aprovisionamiento pesado
Configurar el disco virtual donde se encuentra la base de datos desde el aprovisionamiento ligero predeterminado al aprovisionamiento grueso mejorará ligeramente el rendimiento de E/S y reducirá el uso de la CPU.
4) Optimización de los parámetros del sistema operativo de la máquina virtual.
- Aproveche las funciones multinúcleo de la CPU para optimizar la red
Dado que la prueba TPC-C inicia una solicitud a través de la máquina virtual benchmarkSQL fuera del clúster del sistema operativo SMTX y prueba la base de datos a través de la red, es necesaria la optimización de la red para ejercer completamente el efecto del modo Boost. Basado en las ventajas multinúcleo de la CPU Kunpeng, asignar tareas de interrupción y cola de red a diferentes núcleos de la CPU puede reducir la contención de recursos y mejorar efectivamente el rendimiento de la transmisión de la red.
Método 1: especificar el núcleo de la CPU para la cola de tarjetas de red
a. Utilice ls /sys/class/net/enp1s0/queues/ para verificar el estado de la cola de la tarjeta de red:
![]()
En el entorno de prueba, puede ver que hay 4 grupos de colas de recepción y colas de envío correspondientes a la tarjeta de red, según la situación real.
b. Especifique los núcleos de CPU para varias colas de tarjetas de red respectivamente. El comando es el siguiente:
echo 1 > /sys/class/net/enp1s0/queues/rx-0/rps_cpus
echo 2 > /sys/class/net/enp1s0/queues/rx-1/rps_cpus
echo 4 > /sys/class/net/enp1s0/queues/rx-2/rps_cpus
echo 8 > /sys/class/net/enp1s0/queues/rx-3/rps_cpus
echo 16 > /sys/class/net/enp1s0/queues/tx-0/xps_cpus
echo 32 > /sys/class/net/enp1s0/queues/tx-1/xps_cpus
echo 64 > /sys/class/net/enp1s0/queues/tx-2/xps_cpus
echo 128 > /sys/class/net/enp1s0/queues/tx-3/xps_cpusEntre ellos, echo 1 > /sys/class/net/enp1s0/queues/rx-0/rps_cpus significa vincular la CPU 1 a la cola rx-0. Los valores correspondientes de las cuatro CPU CPU 0, 1, 2, y 3 son respectivamente 1(20), 2(21), 4(22), 8(23).
Método 2: especificar el núcleo de la CPU para la interrupción de la tarjeta de red
a. Utilice el siguiente comando para verificar el estado de interrupción de la tarjeta de red:
cat /proc/interrupts | grep virtio0|cut -f 1 -d ":"
b.Modifique el archivo de configuración para que el servicio irqbalance ya no programe estas interrupciones.
Modifique el archivo a través de vim /etc/sysconfig/irqbalance y cambie los siguientes parámetros a:
IRQBALANCE_ARGS=--banirq=91-99C. Asigne manualmente núcleos de CPU a cada interrupción de la tarjeta de red, de la siguiente manera:
echo 40 > /proc/irq/91/smp_affinity_list
echo 41 > /proc/irq/92/smp_affinity_list
echo 42 > /proc/irq/93/smp_affinity_list
echo 43 > /proc/irq/94/smp_affinity_list
echo 44 > /proc/irq/95/smp_affinity_list
echo 45 > /proc/irq/96/smp_affinity_list
echo 46 > /proc/irq/97/smp_affinity_list
echo 47 > /proc/irq/98/smp_affinity_list
echo 48 > /proc/irq/99/smp_affinity_listLa ejecución de las dos partes anteriores de la optimización de la red puede mejorar significativamente el rendimiento de la red en la prueba TPC-C, con un aumento de la velocidad máxima de envío hasta un 17,6 % y un aumento de la velocidad máxima de recepción de hasta un 27,1 % .
5) Optimización relacionada con la base de datos
- Ajuste los parámetros de registro de la base de datos para aprovechar al máximo la capacidad de simultaneidad de E/S
El número de archivos de registro de la base de datos (logfiles) de Dameng DM8 es 2 de forma predeterminada. Dado que SMTX OS obtiene capacidades de simultaneidad de E/S más sólidas después de activar el modo Boost, el rendimiento de simultaneidad de almacenamiento se puede aprovechar al máximo aumentando la cantidad de archivos de registro. En la prueba, cuando la cantidad de archivos de registro aumentó de 2 a 8, el rendimiento mejoró significativamente en todos los escenarios. El resultado es el que se muestra a continuación:
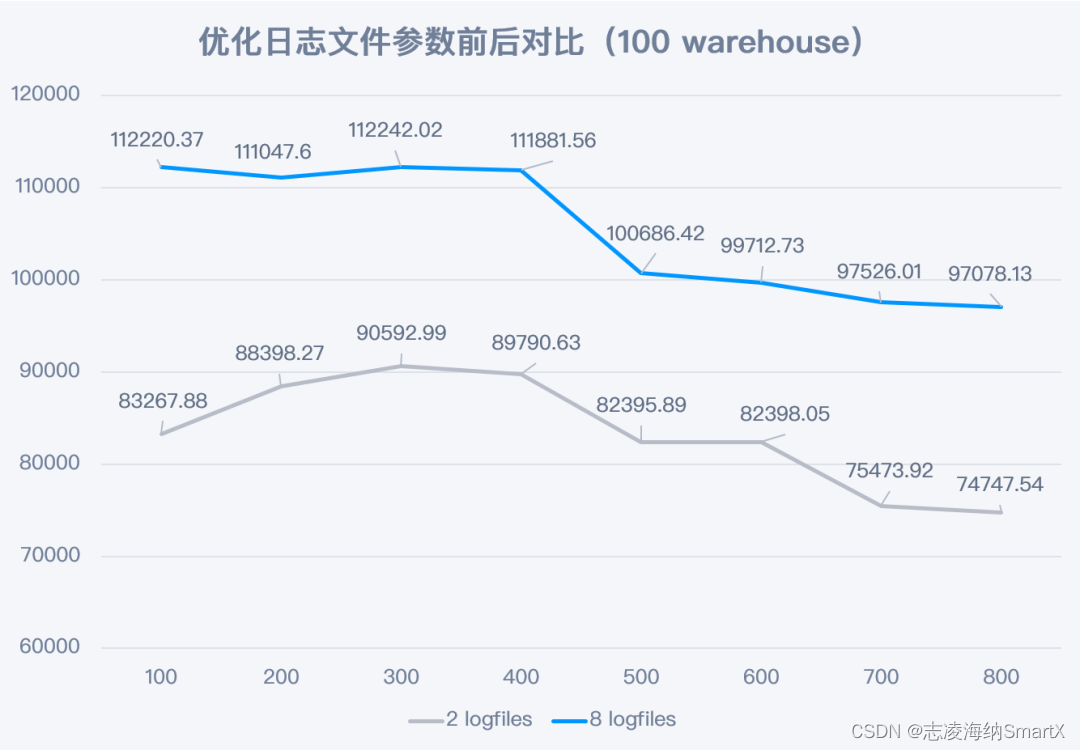
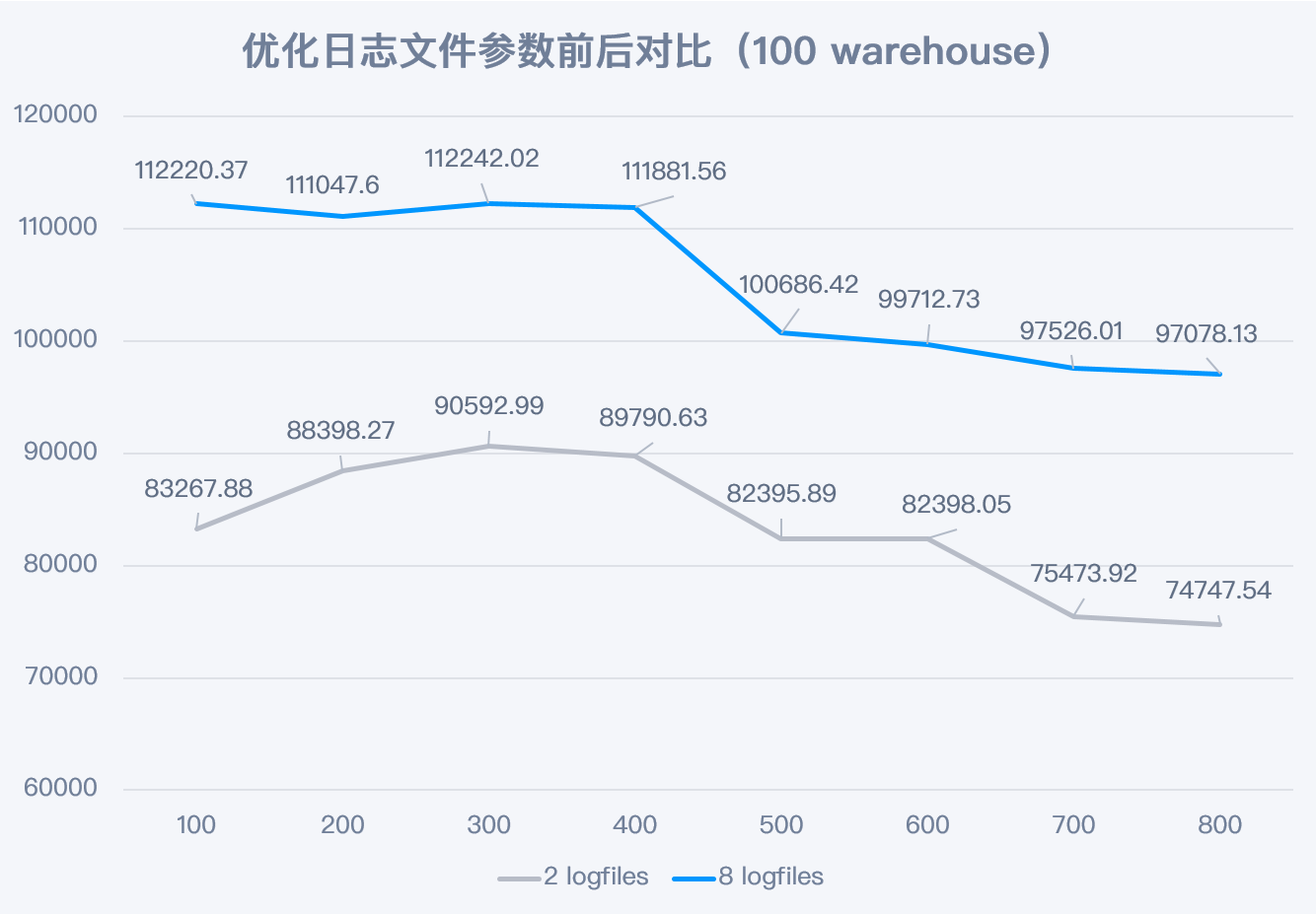
Después de agregar archivos de registro, el índice de mejora del rendimiento en el escenario de 100 almacenes oscila entre el 21% y el 35% (como se muestra en la figura). En el escenario de 300 almacenes, la mejora máxima es del 47% (los datos de prueba relevantes están disponibles, pero no se muestra el gráfico).
- Ajuste los parámetros del área de caché de la memoria de la base de datos DM8 para optimizar la tasa de aciertos de la caché
Dado que la memoria asignada a la máquina virtual donde se encuentra la base de datos es de 96 GB, los parámetros del grupo de memoria y los parámetros de destino de la memoria se establecen en 90 GB (6G está reservado para el sistema operativo). Los parámetros relacionados se pueden ajustar modificando el archivo de parámetros de la base de datos a través de /dm8/data/DAMENG/dm.ini.
MEMORY_POOL = 90000 #Memory Pool Size In Megabyte
MEMORY_TARGET = 90000 #Memory Share Pool Target Size In MegabyteHay cuatro tipos de buffers de datos en la base de datos DM8, a saber, NORMAL, MANTENER, RÁPIDO y RECICLAR.
Se recomienda que el parámetro BUFFER correspondiente al búfer NORMAL sea lo más grande posible para garantizar una tasa de aciertos alta (superior al 90%). En esta prueba, ajuste el tamaño del búfer BUFFER a 70 GB y el número de BUFFER_POOLS a 48 (manténgalo coherente con el número de núcleos de CPU).
BUFFER = 70000 #Initial System Buffer Size In Megabytes
BUFFER_POOLS = 48 #number of buffer poolsAdemás, el espacio de tabla temporal utiliza el área de caché RECYCLE, por lo que también se deben ajustar los parámetros relacionados. Aquí, ajuste el tamaño del búfer RECYCLE a 12 GB y el número de RECYCLE_POOLS a 48 (manteniéndolo consistente con el número de núcleos de CPU).
RECYCLE = 12000 #system RECYCLE buffer size in Megabytes
RECYCLE_POOLS = 48 #Number of recycle buffer poolsFinalmente, debe ajustar el hilo de trabajo de la base de datos de acuerdo con la cantidad de núcleos de CPU, aquí ajuste el hilo de trabajo a 48 (manteniéndolo consistente con la cantidad de núcleos de CPU).
WORKER_THREADS = 48 #Number Of Worker Threads*Nota: Después de modificar los parámetros del archivo dm.ini, la base de datos debe reiniciarse para que surta efecto.
- El programa de base de datos establece el enlace NUMA.
Los programas de bases de datos DM8 pueden mejorar la eficiencia del acceso a la memoria al vincular programas limitados por NUMA en la misma CPU física, mejorando así el rendimiento de la base de datos.
a. Inicie sesión en el nodo del sistema operativo SMTX (el nodo donde se encuentra la máquina virtual de la base de datos) con ssh y ejecute sudo virsh list para verificar el número de identificación de la máquina virtual.

b. Ejecute sudo virsh vcpuinfo 1 de acuerdo con la ID de la máquina virtual para ver la correspondencia entre los núcleos de vCPU y los núcleos físicos de la CPU.

C. Ejecute sudo numactl –hardware para ver la relación de afinidad NUMA.

D. Inicie la base de datos mediante el comando numactl para lograr el propósito de vincular NUMA:
numactl -C 0-16,17-40,41-47 sh DmServiceDMSERVER startDespués de completar todas las operaciones de optimización anteriores, vuelva a ejecutar la prueba TPC-C y compárela con los datos de la prueba antes de la optimización.
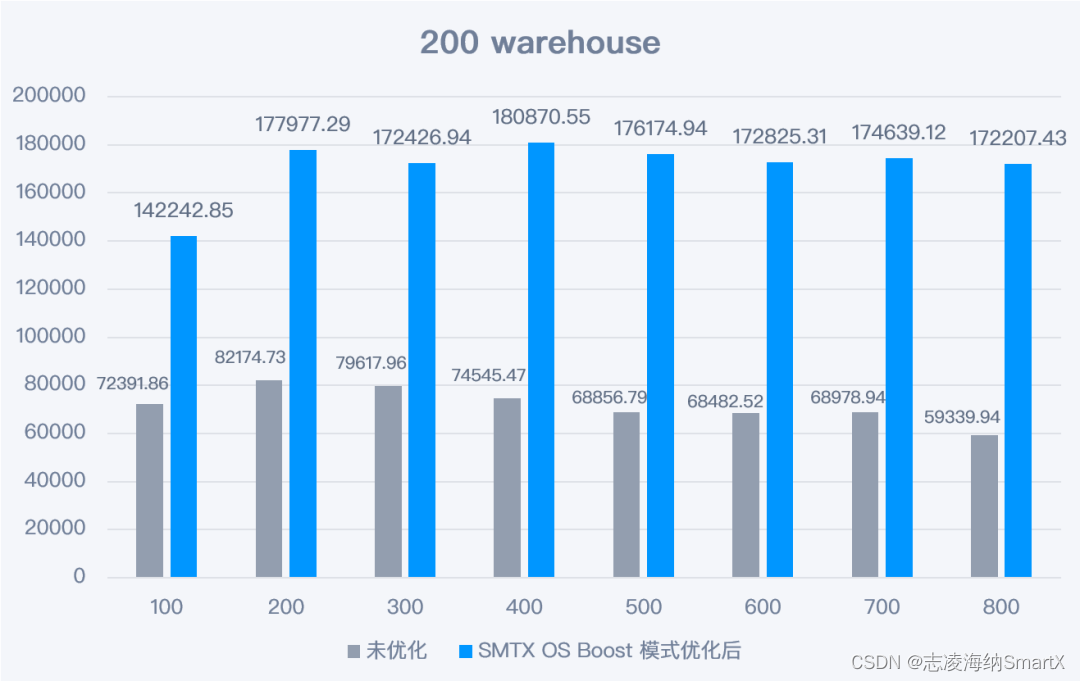
4.3.2 El rendimiento del modo SMTX OS Boost ha mejorado enormemente después de la optimización
Después de habilitar el modo SMTX OS Boost y las configuraciones de optimización relacionadas, el rendimiento de la base de datos mejora significativamente en cada escenario de prueba, casi se duplica. Los datos detallados son los siguientes:
1) Escena de 100 almacenes

2) Escena del almacén 200
3) Escena del almacén 300
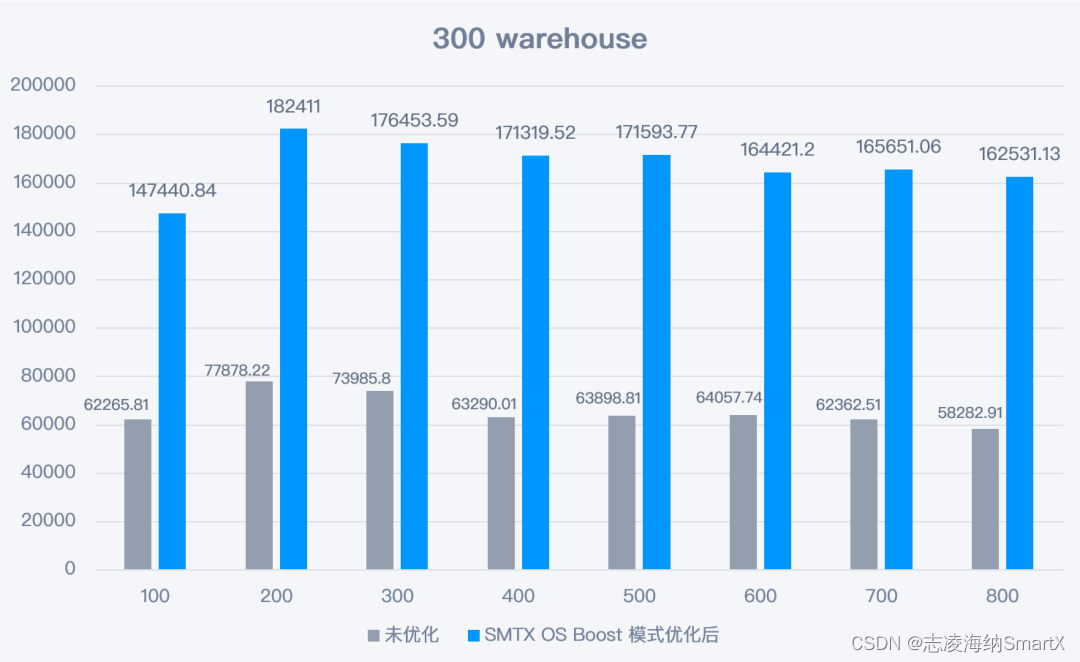
5 Conclusión de la prueba
A través del modo Boost y la optimización relacionada, ejecutar Dameng Database en la plataforma hiperconvergente Xinchuang SmartX puede obtener los siguientes beneficios:
- El rendimiento es 1,77 veces mayor que el de un servidor bare metal (que usa SSD SATA como medio) y se acerca al de un servidor bare metal (que usa SSD NVMe como medio), alcanzando el 87,6% del rendimiento de un disco desnudo NVMe. .
- SMTX OS proporciona 2 copias de protección de redundancia de datos (si bien los discos desnudos tienen un buen rendimiento, no tienen protección de redundancia de datos).
- SMTX OS solo ocupa el 50% de los recursos de CPU y memoria de un único servidor host , lo que significa que los recursos restantes pueden ejecutar más servicios y mejorar efectivamente la utilización de recursos.
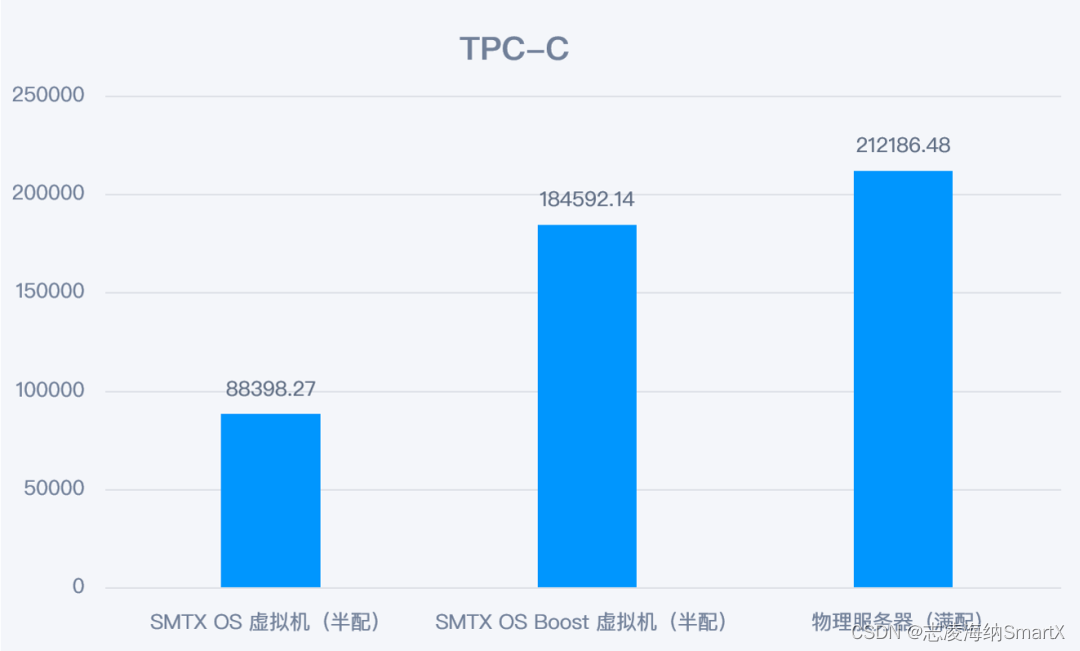
*Configuración completa: la base de datos utiliza todos los núcleos de CPU y recursos de memoria de un solo servidor, 96 CPU y 256G de memoria.
*Media configuración: la base de datos utiliza parte del núcleo de la CPU y los recursos de memoria de un solo servidor, 48 CPU, 96G de memoria.
Esta prueba no solo muestra a los lectores el rendimiento real de la base de datos Xinchuang en la plataforma hiperconvergente Xinchuang, sino que también verifica el efecto de optimización del rendimiento del modo Boost hiperconvergente SmartX en la base de datos. Para obtener más información sobre el rendimiento de la hiperconvergencia SmartX en escenarios de bases de datos , lea: Recopilación de evaluaciones de soporte de bases de datos de la industria financiera de hiperconvergencia SmartX y revisión de casos de implementación a largo plazo .
posdata
A juzgar por los resultados de las pruebas, la plataforma hiperconvergente SmartX puede mejorar significativamente el rendimiento de las pruebas de rendimiento de la base de datos Dameng TPC-C con su excelente rendimiento de E/S y la optimización específica relacionada. Dado que el modelo de prueba anterior se basa en un escenario de producción simulado, los parámetros de la base de datos se centran en la ubicación real de E/S (escritura en el medio de almacenamiento). Quizás tenga una pregunta: ¿Es posible mejorar aún más el rendimiento de la prueba de rendimiento de la base de datos TPC-C a través de la memoria caché sin salir del disco?
La respuesta es sí. Por un lado, los parámetros de la base de datos se pueden ajustar para reducir la carga del disco de E/S de la base de datos y, al mismo tiempo, expandir la memoria de la máquina virtual de la base de datos y acelerar la capacidad de respuesta de la base de datos mediante el uso de una gran cantidad de memoria. Por otro lado, dado que el modelo de prueba original es que la máquina virtual de presión externa envía una solicitud a través de la red Gigabit y finalmente llega a la máquina virtual de la base de datos para su procesamiento, pasará por múltiples enlaces: tarjeta de red virtual de la máquina de presión → conmutador virtual → tarjeta de red física → conmutador físico → tarjeta de red física → conmutador virtual → tarjeta de red virtual de la máquina de base de datos. Todo el enlace de transmisión de la red traerá ciertas pérdidas de rendimiento. Podemos simular el impacto de proteger la transmisión de la red y hacer una prueba adicional como referencia: instalar el programa de presión localmente en la máquina virtual de la base de datos, de modo que la presión de la solicitud se emita directamente dentro de la máquina virtual de la base de datos sin pasar por la red, y sea procesado dentro de la máquina virtual.
Después de la serie de cambios anterior, realizamos la prueba TPC-C nuevamente y los resultados son los siguientes:
Cuando warehouse= 100 , el valor tpmc (NewOrder) de TPC-C se prueba en diferentes escenarios de concurrencia:

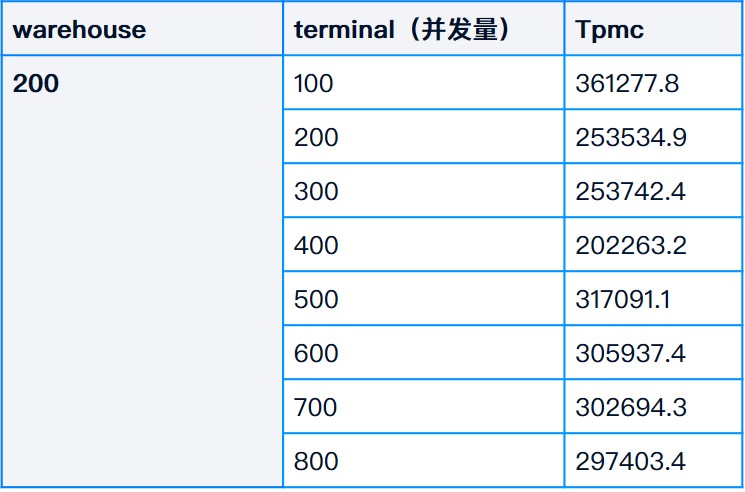
Cuando warehouse= 200 , el valor tpmc (NewOrder) de TPC-C se prueba en diferentes escenarios de concurrencia:
Cuando warehouse= 300 , el valor tpmc (NewOrder) de TPC-C se prueba en diferentes escenarios de concurrencia:
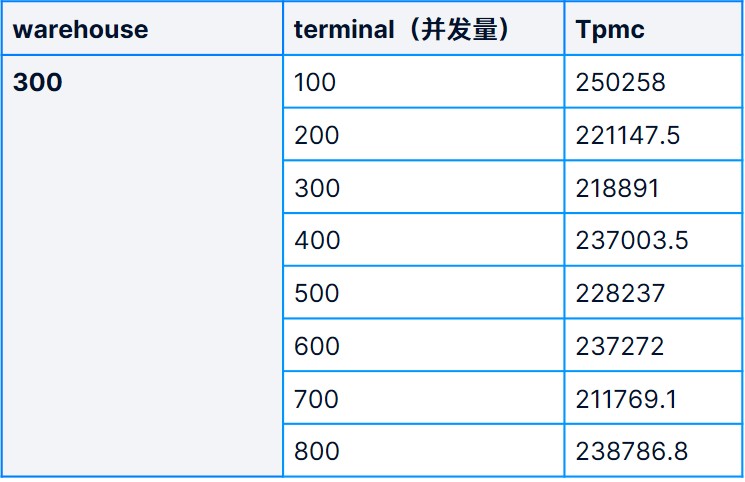
De los resultados de las pruebas se puede ver que el rendimiento de TPC-C ha mejorado significativamente, alcanzando 468113 TPM (el más alto) en el escenario de 100 almacenes/100 terminales . Sin embargo, este modelo de configuración de base de datos tiene una gran cantidad de datos almacenados en caché en la memoria y la E / S no se vacía a tiempo. Si el sistema encuentra un corte de energía repentino, puede causar inconsistencia en la base de datos, por lo que las bases de datos en el entorno de producción generalmente son rara vez se usa (a menos que sea una base de datos de solo lectura), los resultados de la prueba son solo como referencia.
Descargue la "Colección de análisis de características y principios de tecnología hiperconvergente de SmartX (incluida la comparación de VMware)" para obtener más información sobre cómo SmartX mejora el rendimiento y la confiabilidad de la infraestructura a través de la innovación tecnológica.
