
Autor | Equipo EMR de Volcano Engine
Como todos sabemos, el sistema EMR basado en Hadoop ha pasado por muchas etapas en su desarrollo hasta el presente. Ha evolucionado desde la etapa 1.0, que se despliega a través de CDH basado en salas de cómputo IDC, hasta la etapa 2.0, que se realiza a partir de la separación del almacenamiento y la computación en la nube pública.
Sobre esta base, el equipo de EMR de la plataforma de inteligencia digital VeDI de Volcano Engine ha explorado la etapa de evolución de EMR 3.0 sin estado. A fines del mes pasado, Volcano Engine EMR lanzó oficialmente la nueva función de clúster transitorio, que se basa en el concepto sin estado EMR líder en la industria y puede lograr un escalado elástico a nivel de clúster, es decir, liberar el clúster cuando no hay negocios. demanda y luego retirar el clúster cuando haya demanda comercial, lo que ayuda a las empresas a reducir significativamente el uso de productos y los costos de operación y mantenimiento de la plataforma.
¿Qué es un clúster transitorio y cuál es el concepto Stateless?Este artículo presenta de manera integral los conceptos y aplicaciones innovadores de EMR Stateless desde múltiples perspectivas, como conceptos básicos, sistemas arquitectónicos, procesos de evolución, escenarios de aplicaciones prácticas y valor de uso.


¿Qué es apátrida?
Sin estado: su esencia es el concepto de un clúster transitorio, pero no es completamente un clúster transitorio, sino un clúster transitorio liviano y sin estado que se entrega. Entonces, ¿qué significa la agrupación transitoria sin estado?
En primer lugar, el clúster sin estado es un clúster transitorio que evoluciona aún más en función de la separación del almacenamiento y la informática. Los clústeres de separación informática y de almacenamiento ordinario, como el contenido relacionado en el sistema Hadoop, están vinculados al clúster, y este contenido con estado no está completamente separado en un servicio independiente. Servicios sin estado Hive Metastore y History Server, lo que significa que los separa del clúster informático.
Con el soporte de Stateless, Master, Core, Task y otros nodos en el sistema Hadoop, nos referimos a formar un clúster transitorio ligero y sin estado que se puede crear o lanzar en cualquier momento y tener múltiples copias, lo que sin duda puede hacer que el clúster tenga una mejor escalabilidad. En base a esto, podremos aumentar mejor las capacidades y optimizar los costos en función de la nube nativa y desde una perspectiva de clúster.

A continuación, comparemos el modo con estado y el modo sin estado ¿Cuáles son las diferencias típicas entre ellos?
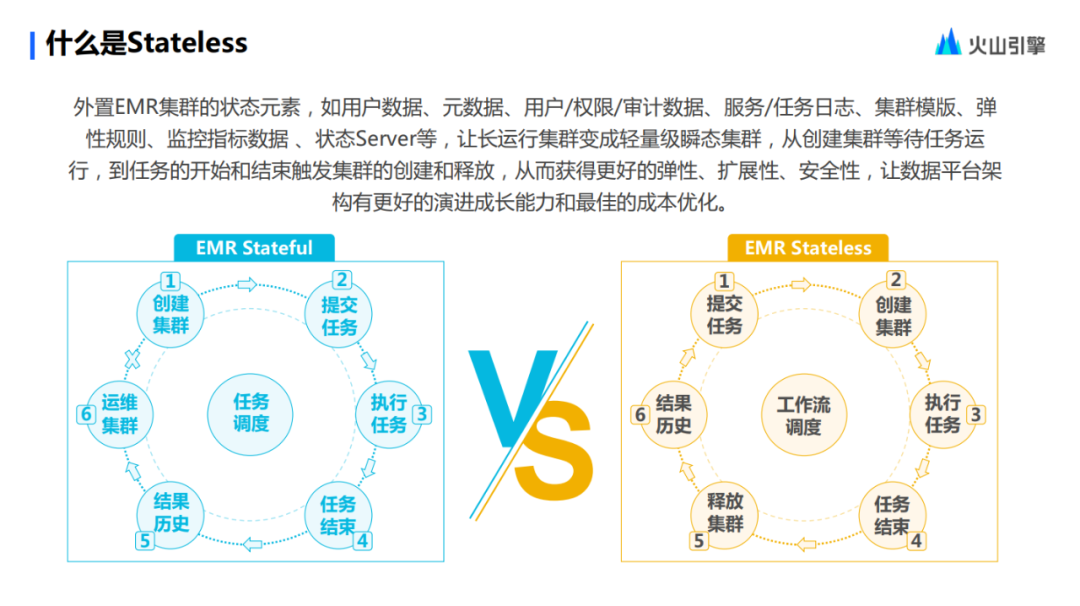
El diagrama de flujo de la izquierda es un modelo con estado tradicional.
En este modo, el proceso de datos para enviar una tarea suele ser así: primero, debe haber un clúster de larga ejecución, una vez establecido el clúster, se envía la tarea y luego, si se devuelve directamente a través de IO, se escribe los datos a HDFS o almacenamiento de objetos, y obtendrá los resultados históricos después de la ejecución.
Desde la perspectiva del mantenimiento de big data, una vez completado el proceso de envío de tareas, operar y mantener un clúster de larga ejecución incluye monitorear su estado de ejecución para ver si ha fallado o realizar mantenimiento en sus servicios existentes. generará una cierta cantidad de costos de operación y mantenimiento. Al mismo tiempo, una vez finalizada la tarea, estos grupos en realidad se convierten en un grupo vacío. Desde la perspectiva de la tolerancia al costo total, esta es en realidad una opción desventajosa. Lo anterior es un modelo Stateful típico.
En el modo sin estado, todo esto cambiará.
En primer lugar, el primer paso de la operación es enviar directamente la tarea. Después de enviar la tarea, el clúster se creará a tiempo y según demanda para ejecutar la tarea. Cuando se complete la tarea, se liberará el clúster. Una vez que el usuario obtiene los resultados del cálculo, significa que finaliza todo el proceso de envío de la tarea.
En este proceso, Stateless ha externalizado funciones con atributos de estado, como servicios de registro, en el clúster. Una vez que se lanza el clúster, los usuarios aún pueden consultar los resultados de cualquier tarea ejecutada en el clúster bajo la plantilla de clúster sin estado en cualquier período de tiempo a través del servicio de registro.
En tal proceso, los usuarios no necesitan operar ni mantener el clúster de ejecución. Ésta es la mayor diferencia entre Stateful y Stateless.

Después de leer el contenido anterior, definitivamente tendrá algunas preguntas. Hay algunos problemas conceptuales comunes. Puedo explicárselos aquí primero.
1. ¿Cuál es la diferencia entre Stateless y Serverless?
En primer lugar, en comparación con Stateless, Serverless es en realidad la diferencia entre totalmente administrado y semiadministrado. En el caso de semiadministración, los usuarios necesitan operar y mantener algunos recursos del clúster y el contenido relacionado con la configuración del clúster por sí mismos. En el caso de alojamiento completo, los usuarios pueden omitir esta parte de la configuración, pero también perderán algunas configuraciones personalizadas. · Flexibilidad del cluster.
Stateless se encuentra en realidad en un escenario semiadministrado, un sistema de optimización nativo de la nube basado en forma de clúster, que no tiene ninguna conexión esencial con la forma totalmente administrada de Serverless. Se parecen en que utilizan relativamente todos los recursos y los recursos informáticos solo existen cuando se realizan tareas.
2. Clúster transitorio sin estado, ¿cómo se entiende transitorio?
Con respecto a este tema, un punto más profundo es el estado transitorio: ¿qué tipo de granularidad de tiempo se le puede llamar estado transitorio?
Primero, comparemos un clúster transitorio con un clúster EMR común en la nube. Los grupos de EMR ordinarios se implementan durante mucho tiempo y pueden implementarse durante una semana o dos, o incluso un mes o dos meses. El clúster transitorio significa que cuando llegan las tareas, creamos un clúster para estas tareas y lo liberamos después de que se ejecuta la tarea.
De manera similar, al crear por segunda vez, puede realizar directamente una operación similar a una copia, y la configuración y especificaciones del clúster son las mismas que antes. Para los usuarios, alcanzar este nivel no tiene ningún coste. Los usuarios solo necesitan definir este clúster, y Stateless puede crear dicho clúster transitorio bajo demanda, y la granularidad de tiempo de este clúster transitorio es de nivel de minutos, sin tener que considerar qué errores ocurrirán si el intervalo es demasiado largo.
3. ¿Para qué escenarios comerciales es adecuado Stateless?
Según nuestro escenario práctico, en primer lugar, es adecuado para usuarios que necesitan separar el almacenamiento y el cálculo, y es más adecuado para escenarios de ejecución por lotes sin conexión. Cuando la cantidad de cálculo es relativamente grande y tiene características de marea obvias, el ahorro de costos es muy obvio.
4. ¿Stateless requiere que los usuarios cambien sus hábitos de uso?
En términos de uso del usuario, no se requieren cambios en el proceso. Stateless solo está optimizado en el nivel de control nativo de la nube y está optimizado en el nivel de eliminación de servicios sin estado. En cuanto a la interfaz de usuario, ya sea la interfaz web de código abierto o la interfaz externa del motor de código abierto, no hay cambios en el proceso de envío de tareas. Estos son completamente compatibles con el código abierto. Todos siempre pueden disfrutar de los dividendos técnicos que brinda la iteración de la versión comunitaria de código abierto.

Sistema de big data sin estado
Después de comprender el contenido anterior, debe tener una comprensión preliminar de Stateless. A continuación, le presentaré cómo se implementa el sistema.

En primer lugar, en el sistema de arquitectura Stateless, los grupos de usuarios incluyen análisis fuera de línea (sistema Hadoop), computación en tiempo real (sistema Flink), análisis interactivo, base de datos NoSQL, aprendizaje automático y otros contenidos relacionados. Este es un clúster con funciones informáticas y se ha eliminado todo el contenido con partes de estado. Stateless separa el contenido relacionado con la interfaz de usuario y el servidor histórico en servicios independientes, incluidos Spark History Server, Presto History Server, YARN Timeline Server, etc. Estos servicios existen independientemente de si el clúster existe.
En segundo lugar, la programación unificada y el paquete de desarrollo se implementan a través de Open API. Al mismo tiempo, EMR Studio se convierte en un servicio (EMR Studio puede entenderse como un motor de programación similar a Oozie, Airflow, DolphinScheduler, etc.). Los usuarios pueden utilizar estos servicios directamente en Volcano Engine EMR sin enviar máquinas para su implementación.
Basándose en el rico ecosistema de nube de Volcano Engine, Stateless también puede conectarse sin problemas con productos de investigación y desarrollo de datos. Además, los metadatos de EMR, incluida la base de datos de metadatos integrada de Hive Metastore, RDS externo, etc., también se extraen en servicios unificados. Creo que los amigos que han usado Hive Metastore deben haber sido engañados por el RDS de Metastore. Si hay una perturbación en RDS, entonces Hive Metastore tendrá problemas, pero estos problemas ahora pueden resolverse efectivamente mediante servicios nativos de la nube.
Al mismo tiempo, el centro de configuración también ha creado una capa de agrupación para el clúster, como la configuración del clúster, los componentes requeridos, etc., que se almacenarán en forma virtual. Al mismo tiempo, los metadatos del motor están orientados a servicios, incluido el control de permisos, el sistema de usuario, etc.
Finalmente, Stateless resuelve un problema que es muy problemático para la operación y el mantenimiento: el registro llena el disco local. Ya no habrá tales problemas en el sistema sin estado. A través del almacenamiento de objetos TOS, los registros se colocan en un almacenamiento de objetos bajo demanda. El almacenamiento de objetos puede considerarse infinito, por lo que no hay que preocuparse por el espacio en disco que ocupa, siempre que se defina su ciclo de vida, este problema se puede solucionar.
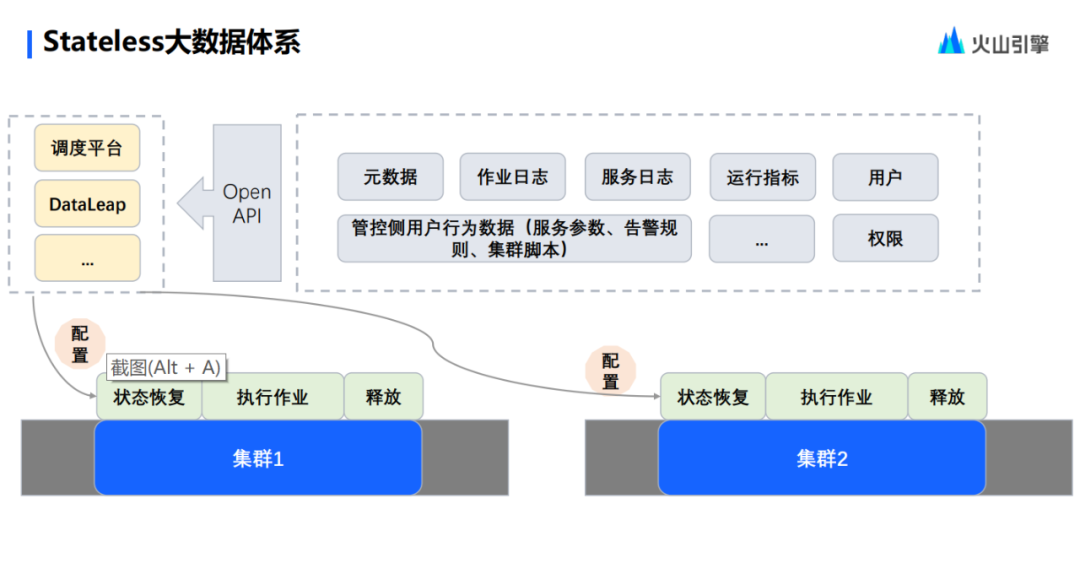
El sistema de big data basado en Stateless se mencionó anteriormente, ahora ingresaremos un enlace donde usaremos un caso sobre el flujo de estado para explicar el sistema en este momento.
En primer lugar, como puede ver en la imagen de arriba, lo que está encerrado en la línea de puntos es lo que Stateless abstrae del grupo de entidades, incluida una serie de servicios, como servicios de metadatos y servicios de gestión y control, incluida la interfaz de usuario web y la API abierta. . Estas API abiertas se utilizarán como activadores para controlar la creación y destrucción de clústeres, y las instrucciones relevantes se entregarán a la plataforma de programación, como Airflow, DolphinScheduler, etc. Al enviar tareas, la plataforma de programación tendrá algún impacto en el ciclo de vida del clúster a través de la interfaz.
En segundo lugar, en el nivel de activación, el clúster se puede controlar principalmente a través de la API abierta proporcionada por la nube nativa. Si desea enviar una tarea, creará un nuevo clúster y restaurará el estado del clúster, lo que se refiere al tipo de configuración del clúster que desea tener la tarea. Esta configuración puede ser un parámetro de versión o puede ser la configuración de algunos modelos. No importa cuál sea la configuración, Stateless puede restaurar fielmente el clúster a su estado inicial. Debido a que el clúster no tiene estado, una vez completado el trabajo de ejecución, el clúster de la entidad se liberará y su ciclo de vida finalizará.
El caso anterior se trata de la presentación de una sola tarea. Sin embargo, en la práctica, se pueden enviar varias tareas al clúster. En este caso, el clúster de entidades se liberará hasta que se ejecuten todas las tareas. Una vez liberado el clúster, si hay tareas que deben enviarse, de la misma manera, solo necesita iniciar un clúster con la misma configuración, ejecutar las tareas nuevamente y luego liberarlas una vez completada la ejecución. Este es el proceso general de funcionamiento del sistema apátrida.

Proceso de evolución sin estado
Después de comprender el contenido conceptual y estructural, compartamos el proceso de evolución de EMR Stateless. EMR Stateless suena como algo relativamente nuevo. ¿Por qué hacemos esto?
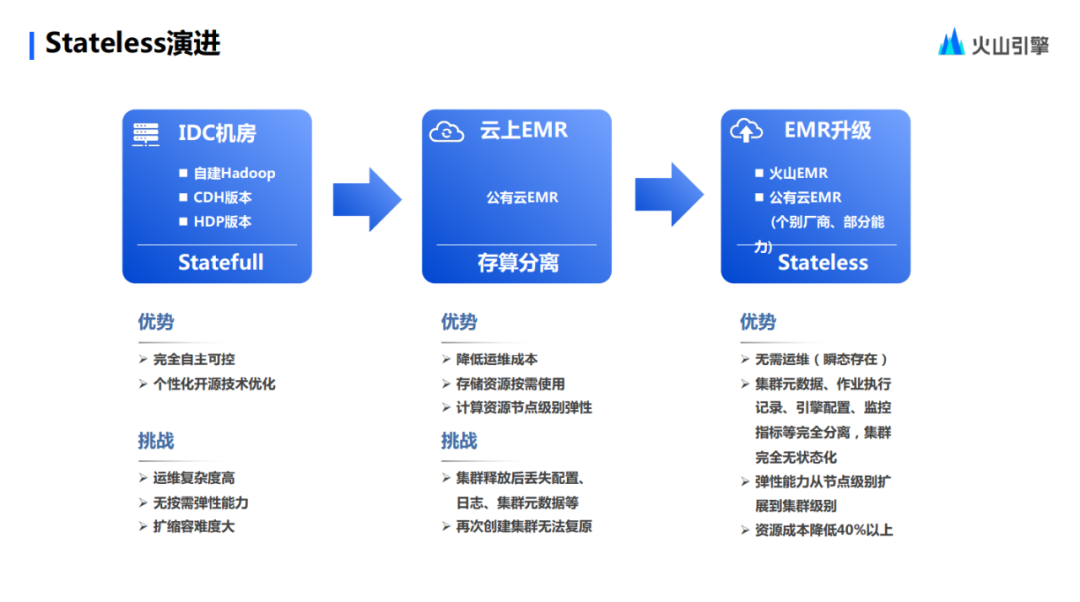
En el capítulo inicial, compartí con ustedes las muchas etapas del sistema EMR basado en Hadoop.
La primera es la etapa 1.0 de implementación basada en salas de computación IDC a través de CDH, hasta el momento muchos usuarios todavía operan en base al sistema 1.0. También tiene sus beneficios, ya sea agregando recursos u otras operaciones, es completamente controlable. Por supuesto, también hay muchos problemas: por ejemplo, la complejidad de la operación y el mantenimiento es muy alta y, debido a la arquitectura informática y de almacenamiento integrada, una gran cantidad de recursos informáticos están inactivos y no hay forma de realizarlos. Escenarios de computación de demanda.
A partir de estos problemas ha evolucionado la etapa 2.0 de construcción basada en la separación del almacenamiento y la computación en la nube pública. Al separar los recursos de almacenamiento y los recursos informáticos, los recursos informáticos se pueden asignar según la demanda tanto como sea posible. Por supuesto, esto también tiene limitaciones y requisitos previos: sus recursos informáticos son elásticos en función de los nodos. Por tanto, en la era 2.0, el problema más fundamental que resuelve es el desacople entre informática y almacenamiento.
Sin embargo, el equipo EMR de Volcano Engine descubrió algunos problemas en la era 2.0, que afectaron la operación y el mantenimiento diarios y la estabilidad del clúster. Con base en estos dos puntos, primero consideramos la capacidad de elasticidad e hicimos un escalamiento elástico para todo el clúster. El requisito previo para hacer esto era desacoplar el clúster y los metadatos del clúster relacionados. Sobre esta base, hicimos que el clúster fuera sin estado. , es decir, el desmantelamiento de los servicios de cluster.
Hablando de esto, las ventajas de Stateless realmente se reflejan. En primer lugar, el clúster sin estado no requiere operación y mantenimiento al 100% porque solo aparece de forma transitoria durante el tiempo de ejecución. En segundo lugar, los usuarios no necesitan preocuparse por los servicios del clúster y también conserva las ventajas del modo semihospedado. Después de una investigación técnica y un juicio exhaustivo, en comparación con el modelo de implementación fuera de línea de las salas de computadoras IDC en la era EMR 1.0, el costo de recursos del uso de EMR Stateless se puede optimizar en más del 40%.
Lo anterior es el proceso de evolución de EMR Stateless, así como el pensamiento y el proceso del equipo de Volcano Engine EMR sobre Stateless.
A continuación, compartiré con ustedes en detalle cómo evoluciona cada característica.
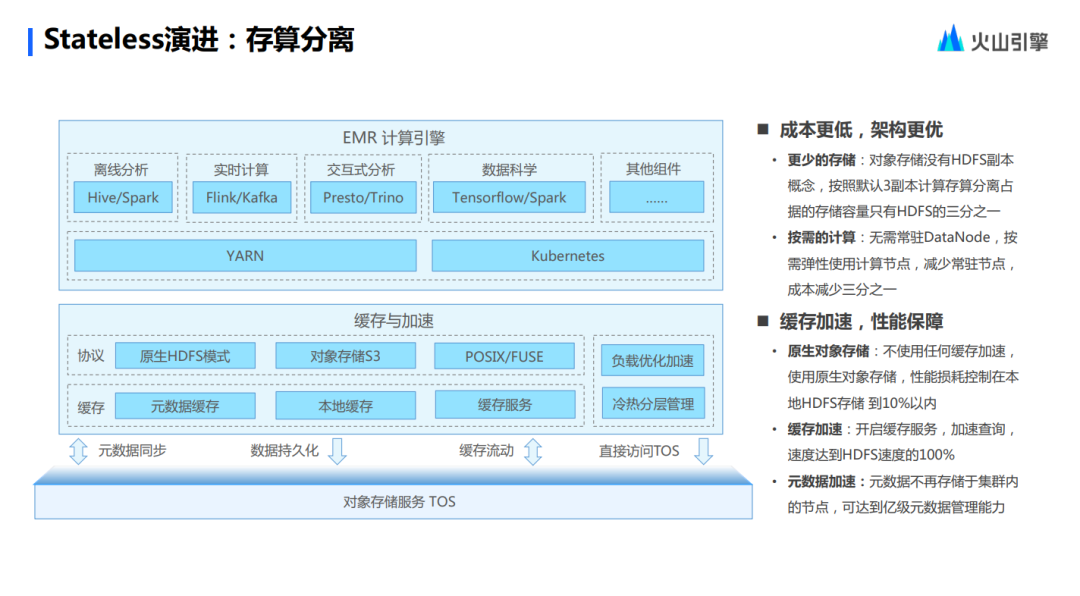
En primer lugar, la separación del almacenamiento y el cálculo es en realidad un producto de la era EMR 2.0. En el entorno sin estado, en primer lugar, se conservan algunas características de EMR 2.0. En la nueva capa, la función más importante es optimizar y acelerar la carga, esto puede considerarse como un búfer local, que acelerará la velocidad.
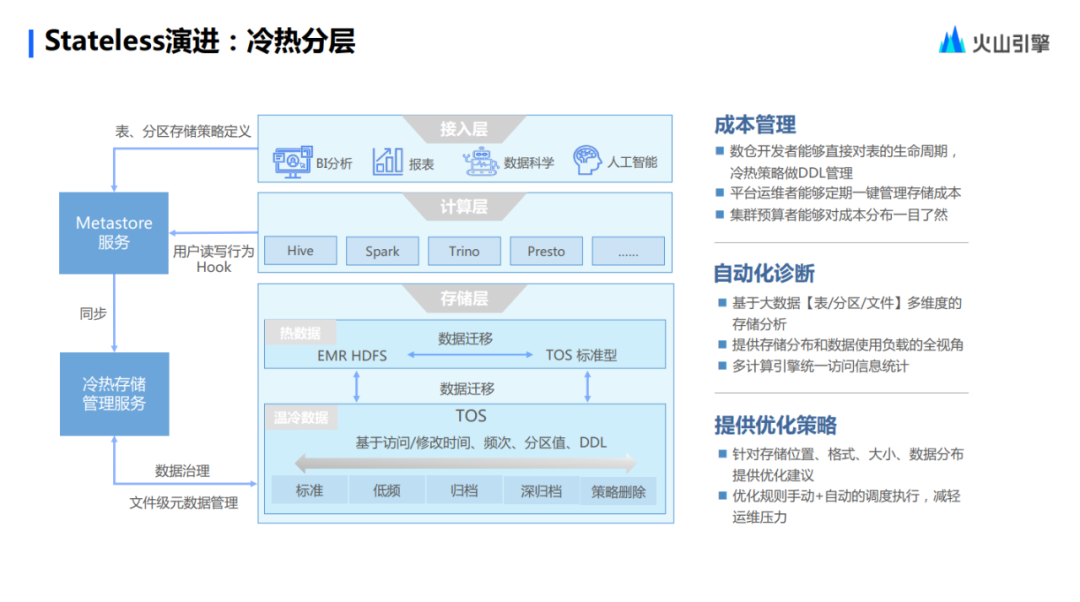
Además, proporciona gestión de la estratificación fría y caliente, que puede controlar y definir directamente el comportamiento de la estratificación fría y caliente, lo que también es un requisito previo para ahorrar costos. Los recursos informáticos se han optimizado al extremo, por lo que los recursos de almacenamiento también deben optimizarse en el tiempo.
En primer lugar, la plataforma diagnosticará automáticamente la estratificación fría y caliente del usuario ¿Cuál es el requisito previo para el diagnóstico? De la figura anterior, todos los comportamientos de lectura y escritura de los usuarios en el lado de Volcano EMR pasarán por el servicio Metastore para comprender qué datos son datos fríos y cuáles son datos calientes.
Con base en la definición de la tabla por parte del usuario, se realiza un diagnóstico automatizado y estos diagnósticos y predicciones se exponen al personal de operación y mantenimiento, lo que les permite ver los resultados del diagnóstico y brindar recomendaciones de la plataforma. Luego se utiliza el juicio manual para permitir que los datos fríos encuentren su destino final. Sobre este tema, Stateless proporciona muchos niveles de estratificación de datos fríos, desde estándar hasta baja frecuencia, pasando por archivado, refrigeración y finalmente eliminación, que pueden encontrar el punto de almacenamiento más adecuado para datos con diferentes características. Este es también un aspecto del empoderamiento de Stateless para los usuarios.
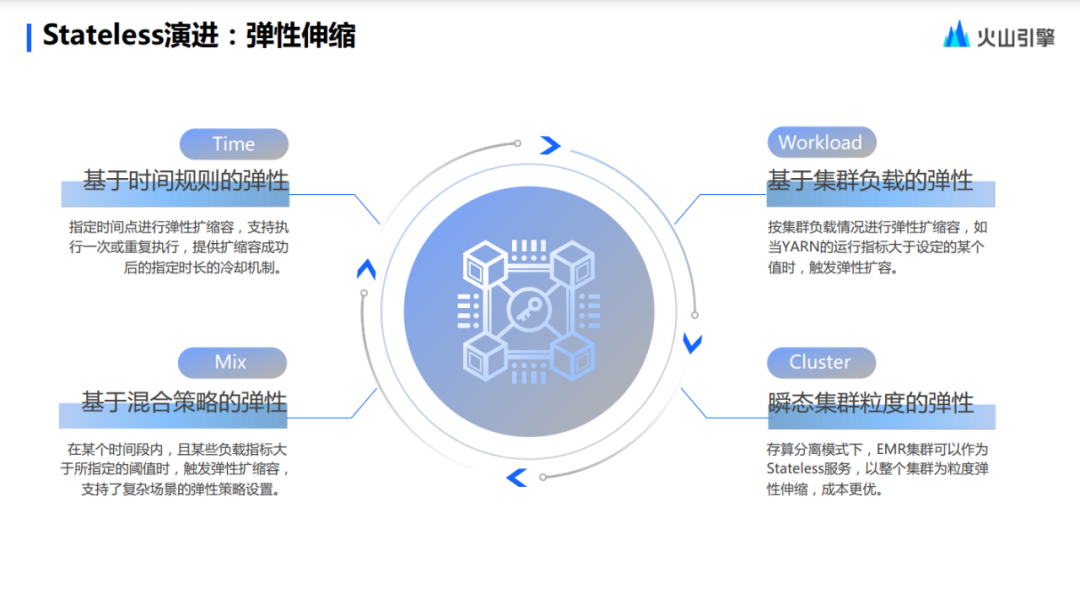
El escalado elástico también es una característica importante resultante de la evolución de Stateless.
Para el escalado elástico, la corriente principal se divide en dos tipos: el primero es el escalado elástico basado en el tiempo, por ejemplo, el personal de operación y mantenimiento sabe cuándo es el pico y cuándo es el valle. El segundo tipo es un escalamiento elástico basado en indicadores de carga, porque puede haber circunstancias especiales, como un valor que repentinamente aumenta o disminuye dentro de un rango de tiempo, o en función de las condiciones de carga.
En este sentido, Volcano Engine EMR tiene configuraciones únicas que se pueden usar para mezclar tiempo y carga. Además, además de actuar sobre los nodos del clúster Hadoop, dicho modo elástico híbrido también puede actuar sobre todo el clúster transitorio.
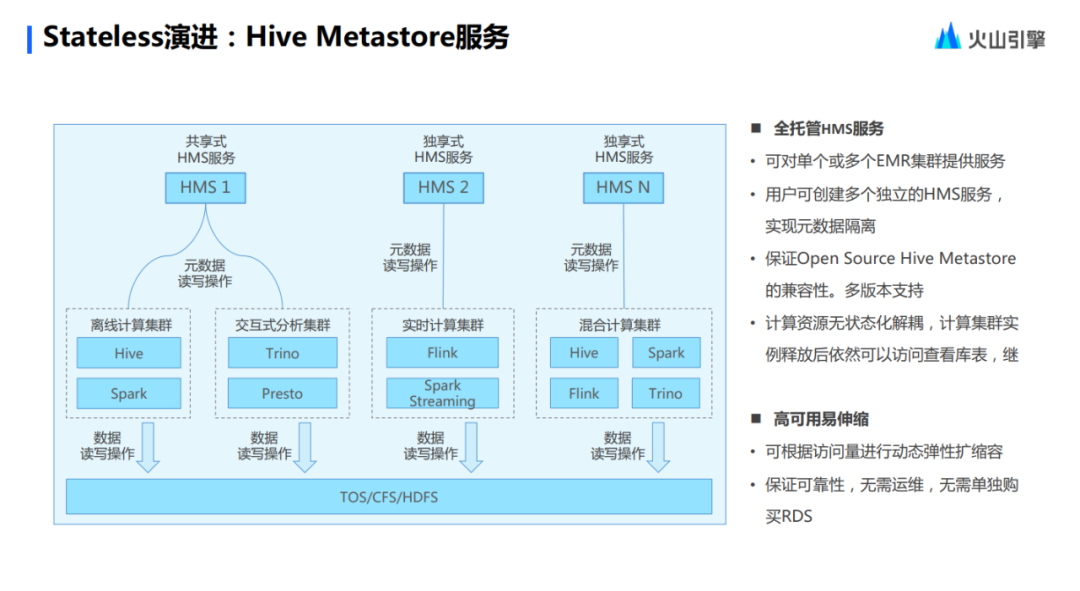
El servicio Hive Metastore también se mencionó anteriormente: ya sean metadatos de tareas fuera de línea o implementación mixta en tiempo real y fuera de línea, sus metadatos en realidad se pueden alojar en Hive Metastore.
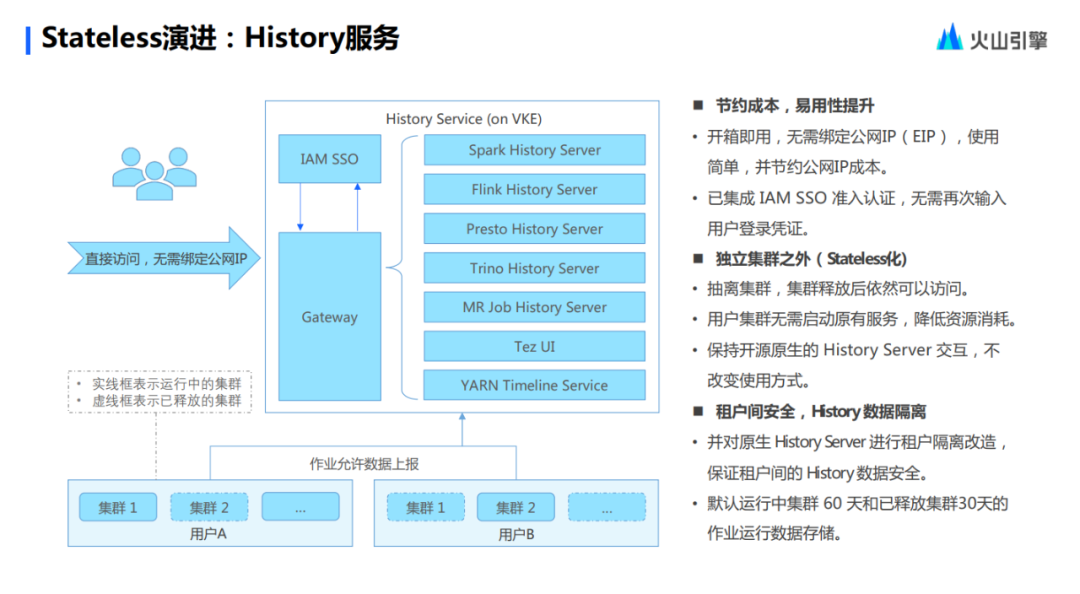
Actualmente, Stateless ha implementado una serie de servicios de Public History Server. Puede existir independientemente de la entidad del clúster y, cuando el clúster se esté ejecutando, estos trabajos informarán datos al servicio del Servidor de historial público. Los usuarios pueden acceder directamente a través de nombres de dominio sin los complicados pasos de vincular IP.
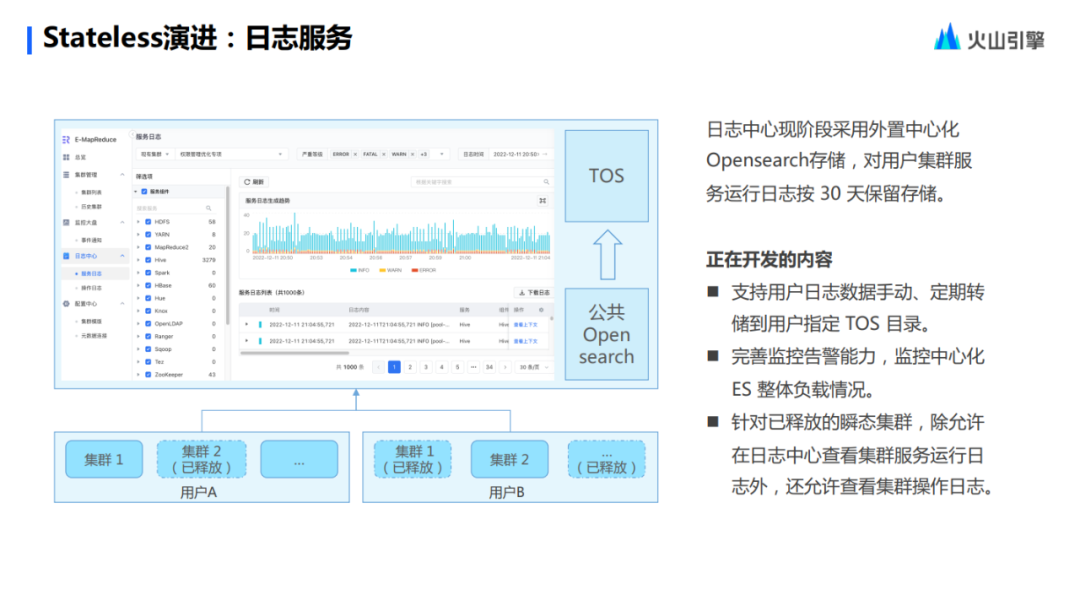
Basándose en el ecosistema de productos en la nube, Stateless también ha actualizado su servicio de registro, que se basa en OpenSearch, y los datos finales se implementan en TOS. Ante la pérdida de datos o el impacto del disco de datos, estos usuarios no necesitan considerarlo ni operarlo, sin embargo, esta parte de la función aún no está completamente madura y llevará algún tiempo mejorar.
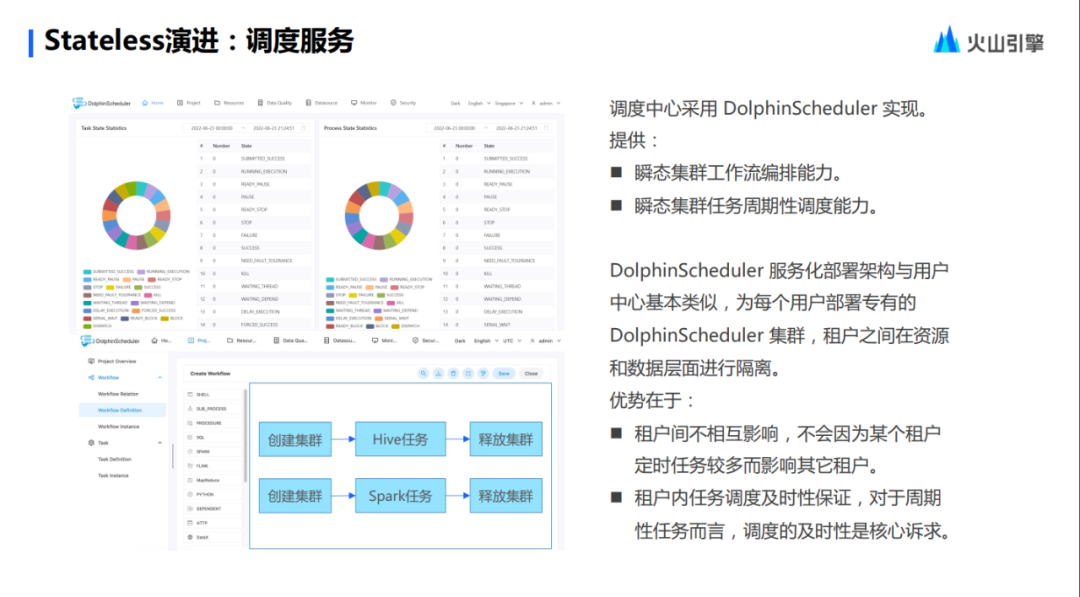
En cuanto a los servicios de programación, también hemos integrado DolphinScheduler, Airflow y otros servicios con capacidades de programación ¿Por qué integramos estos servicios? Esto se debe a que estos componentes programarán las tareas API para crear el clúster y se activarán cuando se envíen las tareas en el sistema de programación. Stateless integra todos estos métodos en los servicios. Los usuarios no necesitan implementarlos ellos mismos y pueden usarlos directamente. fuera de la caja. .
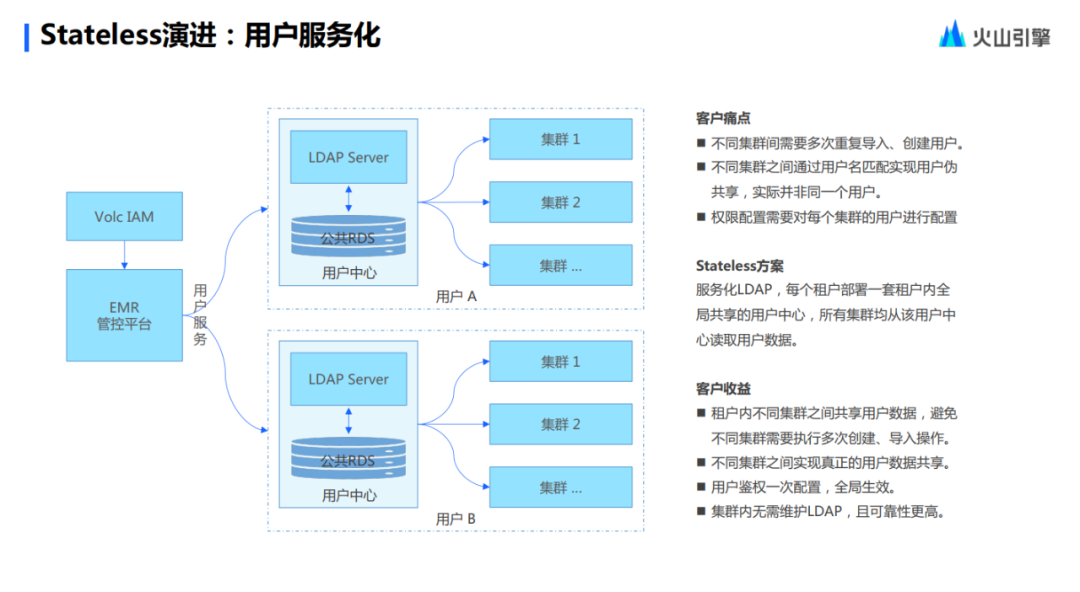
Finalmente, los contenidos del servicio de usuario y del servicio de autenticación se combinan y comparten con todos. La primera es la servitización de los usuarios y la servitización de los derechos de los usuarios. El servicio de usuario consiste en integrar LDAP en un servicio de gestión de usuarios unificado. Por supuesto, el nivel LDAP aún se conserva. Por ejemplo, si los usuarios están acostumbrados a usar la interfaz de usuario LDAP, no tendrán problemas para operarla ellos mismos. No tienen que operar repetidamente un clúster para importar el sistema del usuario. Esta es la mayor beneficio.
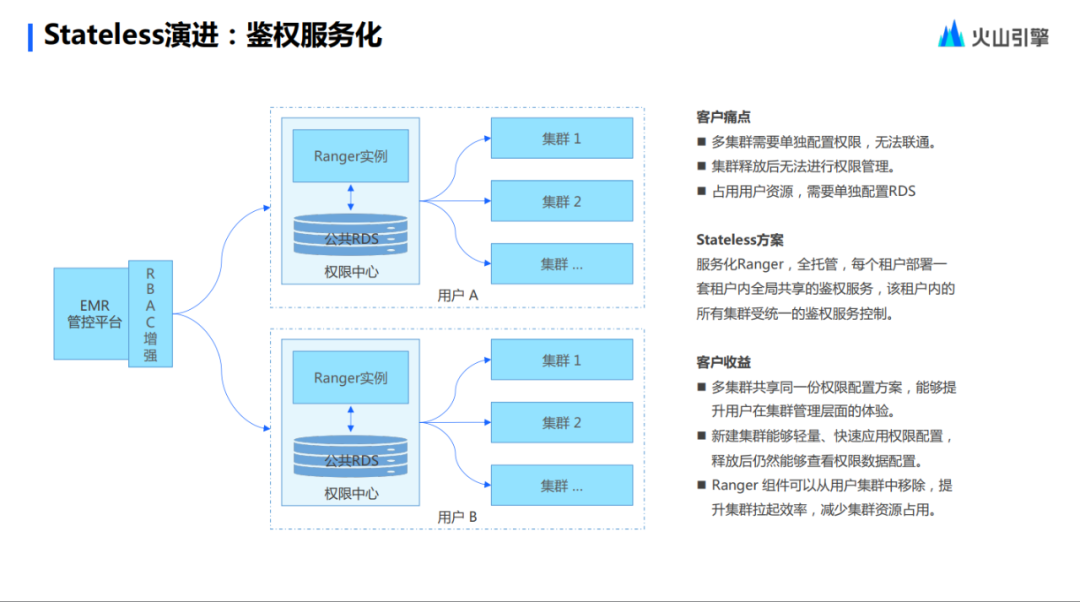
De la misma manera, el servicio de autenticación Stateless utiliza Ranger, porque Ranger es el concepto de RBAC y, además del concepto de RBAC, Stateless también abstrae el concepto de RBAC, lo que permite a los usuarios configurar un conjunto más rico de permisos. Además, este permiso es interoperable con el sistema del usuario, de modo que un conjunto de sistemas de usuario y un conjunto de permisos pueden cubrir todos los modelos RPC relacionados con permisos de usuarios y roles, lo que también es una capacidad muy importante en la evolución de Stateless.

Valor empresarial sin estado
Finalmente, me gustaría compartir con ustedes el valor comercial de Stateless.
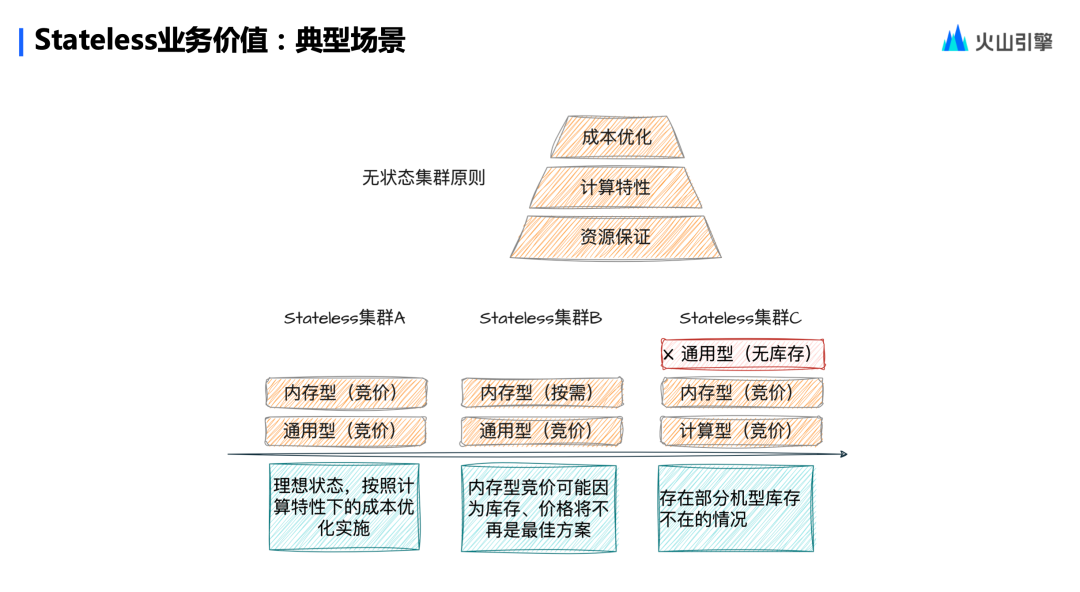
Primero, introduzcamos un escenario típico que refleje el valor comercial:
¿Qué tipo de clústeres son clústeres sin estado? ¿Cómo optimizar costes?
En primer lugar, al crear un clúster sin estado para un usuario, el modelo de servidor en la nube seleccionado puede ser diferente. En primer lugar, es una estructura piramidal: en el nivel inferior, primero se garantizan los recursos informáticos del usuario.
En segundo lugar, intentar satisfacer las características informáticas de los usuarios. Por ejemplo, el recuento de palabras o los cálculos que requieren un uso intensivo de la CPU no utilizan mucha memoria. Haremos todo lo posible para ayudar a los usuarios a ahorrar recursos de memoria y elegir modelos con una proporción cercana de CPU a memoria.
En tercer lugar, ayudar a los usuarios a optimizar los costos. Hay dos modelos de precios, uno es bajo demanda y el otro es de oferta. En principio, las ofertas son más baratas que las ofertas bajo demanda y, debido a que la agrupación sin estado lleva poco tiempo, haremos todo lo posible para elegir modelos más baratos para los usuarios. Por ejemplo, ¿qué debo hacer si un modelo que prefiere un usuario está agotado? Hacemos todo lo posible para seleccionar modelos similares a los definidos por los usuarios en términos de precio y configuración para garantizar que se puedan realizar las tareas informáticas de los usuarios.
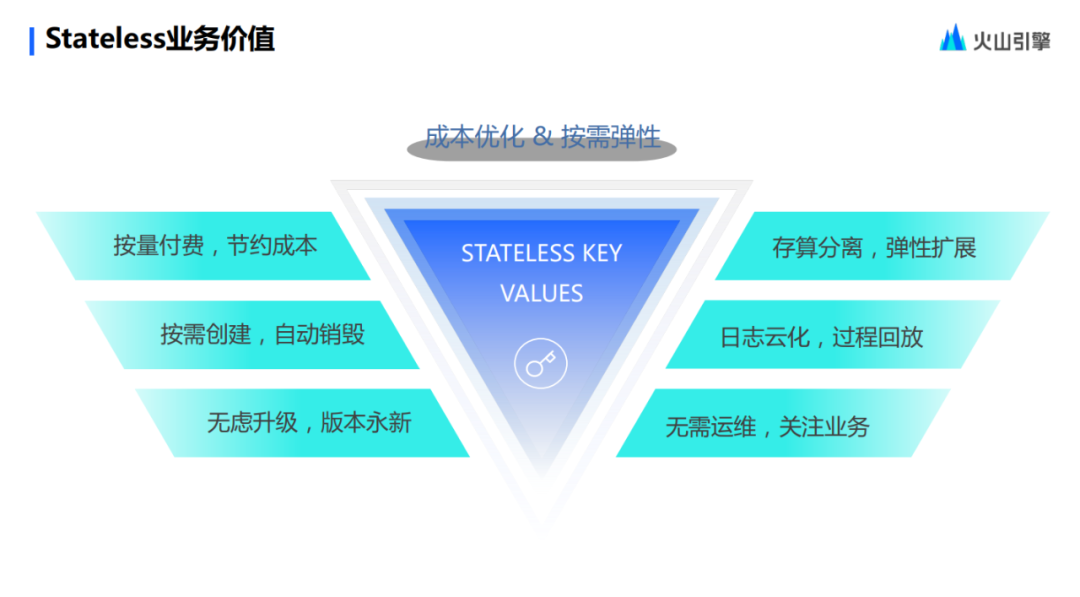
Finalmente, para hacer un breve resumen, ¿cuáles son los beneficios de Stateless?
En primer lugar, en realidad es muy sencillo pagar sobre la marcha. Creado bajo demanda y destruido automáticamente, los usuarios no necesitan preocuparse por el estado del clúster porque siempre estará ahí con la tarea. En segundo lugar, siempre está en un estado iterativo, y todos siempre pueden disfrutar de los dividendos generados por las iteraciones de la versión comunitaria de código abierto, porque siempre adoptaremos el código abierto, que también es una intención original a la que nuestro Volcano Engine EMR no renunciará. .
Luego está la separación del almacenamiento y el cálculo y la expansión elástica. La expansión elástica tiene ciertas características avanzadas y se puede completar con la fuerza del clúster. Los registros son idempotentes y se cargan en la nube. Se pueden ver en cualquier momento. Los usuarios no necesitan realizar operaciones ni mantenimiento excesivos en los registros.
Finalmente, cuando se trata de operación y mantenimiento, Stateless extrae servicios con estado. Los usuarios ya no necesitan preocuparse por el contenido relacionado con los servicios del clúster, solo deben preocuparse por ejecutar cálculos, depurar cálculos y diagnosticar cálculos.
Se ha lanzado la "Encuesta para desarrolladores de China 2022-2023". Bienvenido a escanear el código QR a continuación para participar en la encuesta. ¡También hay obsequios exquisitos como iPads esperándote!

☞蚂蚁集团强化与阿里隔离:马云不再是实际控制人;iPhone 15 Pro将独占6大功能;Linux 4.9正式EOL|极客头条
☞C++:在“替代”中迎来“转机”的 2022 年!
☞以防作弊,ChatGPT 遭教育部“拉黑”:师生禁用!