Amigos, chicos, nos volvemos a encontrar. En este número, les explicaré algunos puntos de conocimiento relevantes sobre los algoritmos de clasificación . Si tienen algo de inspiración después de leerlo, dejen sus tres enlaces y les deseo todo lo mejor. Está hecho. !
Columna de lenguaje C: lenguaje C: desde el nivel básico hasta el dominio
Columna de estructura de datos: estructura de datos
Página de inicio personal: stackY、

Tabla de contenido
1.2 Clasificación por selección directa
:: Código completo del algoritmo de clasificación directa
1.3 Características del algoritmo de clasificación por selección directa
:: Código completo del algoritmo de clasificación del montón
2.1 Características del algoritmo de clasificación del montón
3. Comparación de la eficiencia del algoritmo
Prefacio:
Continuando con este artículo: Algoritmo de clasificación: clasificación por inserción (clasificación por inserción directa, clasificación por colinas) En este artículo hemos aprendido sobre los tipos de algoritmos de clasificación y cómo implementar la clasificación por inserción, por lo que en este artículo volveremos a aprender un nuevo algoritmo de clasificación. : clasificación de selección.
1.Seleccione ordenar
1.1 Idea básica
Cada vez, se selecciona el elemento más pequeño (o más grande) de los elementos de datos que se van a ordenar y se almacena al comienzo de la secuencia hasta que todos los elementos de datos que se van a ordenar estén organizados.
1.2 Clasificación por selección directa
① Seleccione el elemento de datos con el código clave más grande (más pequeño) en el conjunto de elementos matriz[i]--matriz[n-1]
②Si no es el último (primer) elemento de este grupo de elementos, cámbielo por el último (primer) elemento de este grupo de elementos.
③En el conjunto restante de matriz[i]--array[n-2] (array[i+1]--array[n-1]), repita los pasos anteriores hasta que quede 1 elemento en el conjunto
En resumen (orden ascendente) es seleccionar el más pequeño de todos los datos y colocarlo en la posición frontal para completar la clasificación.
Este método de clasificación solo puede seleccionar un dato a la vez. Podemos realizar mejoras básicas nuevamente. Podemos seleccionar y ordenar dos datos a la vez: establecer dos subíndices. El subíndice anterior encuentra el número más pequeño de adelante hacia atrás, y el subíndice siguiente Encuentre el número más grande de atrás hacia adelante y ordénelos en orden. Este método es obviamente mejor que el método anterior, así que comencemos con este algoritmo:
:: Ideas de algoritmos
Primero, necesitamos tener dos subíndices iniciales, uno al principio de los datos y otro al final de los datos. Luego necesitamos dos subíndices más para registrar los valores máximo y mínimo. Se registrarán los valores máximo y mínimo. .El subíndice se establece inicialmente en el primero que pierde un juego, y luego comienza una comparación. El subíndice al comienzo de los datos se recorre desde el principio hasta el valor mínimo, y luego se encuentra el valor mínimo. El subíndice en el final de los datos es de Luego comience a recorrer el valor máximo y compárelo para encontrar el valor máximo. Luego intercambie el valor mínimo con el primer valor al principio y intercambie el valor máximo con el valor al final. De esta manera , el valor mínimo se ordena al frente. El valor máximo se clasifica al final y luego el intervalo se reduce. El subíndice ++ al principio se convierte en el nuevo comienzo y el subíndice -- al final se convierte en el nuevo final. Luego se realiza una nueva ronda de comparación. Cuando el principio y el subíndice suman La clasificación finaliza cuando los últimos subíndices se superponen.
Demostración de código:
void Swap1(int* p1, int* p2) { int tmp = *p1; *p1 = *p2; *p2 = tmp; } //选择排序 //排升序 void SelectSort1(int* a, int n) { int begin = 0, end = n - 1; while (begin < end) { //一趟选择排序 //先将第一个值设置为最大值和最小值 int mini = begin, maxi = begin; //遍历整个数据 for (int i = begin; i <= end; i++) { //找到最小值的下标 if (a[i] < a[mini]) { mini = i; } //找到最大值的下标 if (a[i] > a[maxi]) { maxi = i; } } //将最小值放到开头 Swap1(&a[begin], &a[mini]); //将最大值放到末尾 Swap1(&a[end], &a[maxi]); //缩小区间 begin++; end--; } }Podemos usar un conjunto de datos para demostrar: 9, 8, 5, 6, 3, 2, 1, 4, 7, 0.
Se puede encontrar que el resultado de esta clasificación no es el resultado que queremos, entonces, ¿cuál es la razón? Podemos encontrar el problema mediante la depuración:


Por lo tanto, para evitar la situación especial de superposición entre inicio y maxi, después de completar el primer intercambio, la posición de mini es la posición del valor máximo, por lo tanto, asigne directamente mini a maxi para completar el intercambio correcto.
Código optimizado:
:: Código completo del algoritmo de clasificación directa
void Swap1(int* p1, int* p2) { int tmp = *p1; *p1 = *p2; *p2 = tmp; } //选择排序 //排升序 void SelectSort1(int* a, int n) { int begin = 0, end = n - 1; while (begin < end) { //一趟选择排序 //先将第一个值设置为最大值和最小值 int mini = begin, maxi = begin; //遍历整个数据 for (int i = begin; i <= end; i++) { //找到最小值的下标 if (a[i] < a[mini]) { mini = i; } //找到最大值的下标 if (a[i] > a[maxi]) { maxi = i; } } //将最小值放到开头 Swap1(&a[begin], &a[mini]); //如果begin和maxi重叠,需要进行修正 if (begin == maxi) { maxi = mini; } //将最大值放到末尾 Swap1(&a[end], &a[maxi]); //缩小区间 begin++; end--; } }
1.3 Características del algoritmo de clasificación por selección directa
Resumen de características del tipo de selección directa:
1. El pensamiento de selección y clasificación directa es muy fácil de entender, pero la eficiencia no es muy buena. Rara vez utilizado en la práctica.
2. Complejidad del tiempo: O (N ^ 2)
3. Complejidad espacial: O (1)
4. Estabilidad: inestable
2. Ordenación del montón
La clasificación de montón se introdujo en artículos anteriores. Comencemos aquí. Si no comprende nada, puede leer los artículos anteriores: Algoritmo de clasificación: clasificación de montón
Sabemos que la mejor manera de ordenar el montón es ajustarlo hacia abajo para construir un montón. Lo que debe prestar atención al construir un montón es: construir un montón pequeño en orden descendente y construir un montón grande en orden ascendente. El uso del algoritmo de ajuste hacia abajo es el resultado del ajuste hacia abajo. Debajo del punto debe haber un montón.
:: Código completo del algoritmo de clasificación del montón
//交换函数
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//向下调整
void AdjustDown(int* a, int n, int parent)
{
//假设左孩子为左右孩子中最小的节点
int child = parent * 2 + 1;
while (child < n) //当交换到最后一个孩子节点就停止
{
if (child + 1 < n //判断是否存在右孩子
&& a[child + 1] > a[child]) //判断假设的左孩子是否为最小的孩子
{
child++; //若不符合就转化为右孩子
}
//判断孩子和父亲的大小关系
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
//更新父亲和孩子节点
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//O(N * logN)
void HeapSort(int* a, int n)
{
//建堆--向下调整算法建堆
//时间复杂度为O(N)
for (int i = ((n - 1) - 1) / 2; i >= 0; --i)
{// 这里的n-1表示最后一个叶子节点
// 最后一个叶子节点的父亲就是:
// (n-1)-1/2;
AdjustDown(a, n, i);
}
//O(N * logN)
int end = n - 1;
while (end > 0)
{
//交换堆顶和最后一个数据的位置
Swap(&a[0], &a[end]);
//向下调整,找次小的
AdjustDown(a, end, 0);
end--;
}
}
2.1 Características del algoritmo de clasificación del montón
1. La clasificación en montón utiliza un montón para seleccionar números, lo cual es mucho más eficiente.
2. Complejidad del tiempo: O (N * logN)
3. Complejidad espacial: O (1)
4. Estabilidad: inestable
3. Comparación de la eficiencia del algoritmo
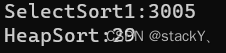
Para comparar la velocidad del algoritmo, todavía usamos este fragmento de código para detectar:
// 测试排序的性能对比 void TestOP() { srand(time(0)); const int N = 100000; int* a1 = (int*)malloc(sizeof(int) * N); int* a2 = (int*)malloc(sizeof(int) * N); for (int i = 0; i < N; ++i) { a1[i] = rand(); a2[i] = a1[i]; } int begin1 = clock(); SelectSort1(a1, N); int end1 = clock(); int begin2 = clock(); HeapSort(a2, N); int end2 = clock(); printf("SelectSort1:%d\n", end1 - begin1); printf("HeapSort:%d\n", end2 - begin2); free(a1); free(a2); }
Se puede ver que la clasificación de montón es más de 100 veces más rápida que la clasificación de selección directa, por lo que la clasificación de selección directa no se usa con frecuencia en tiempos normales. Solo necesitamos aprender sus ideas. Sin embargo, la clasificación de montón es un mejor algoritmo y necesitamos ser competente en ello.
Amigos y chicos, los buenos momentos siempre son cortos. Nuestro intercambio en este número termina aquí. No olviden dejar sus preciosas tres fotos después de leerlo. ¡Gracias a todos por su apoyo!